Abstract
Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approachperforms competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
现代人工智能(AI)系统由基础模型驱动。本论文介绍了一组新的基础模型,称为Llama 3。这是一组语言模型,原生支持多语言、编码、推理和工具使用。我们最大的模型是一个拥有4050亿参数的密集Transformer,支持最长128K的上下文窗口。本论文对Llama 3进行了广泛的实证评估。我们发现,Llama 3在大量任务上提供了与GPT-4等领先语言模型相当的质量。我们公开发布了Llama 3,包括预训练和后训练版本的4050亿参数语言模型,以及用于输入和输出安全的Llama Guard 3模型。
本论文还展示了将图像、视频和语音能力集成到Llama 3中的实验结果,采用了组合方法。我们观察到,这种方法在图像、视频和语音识别任务上的表现可以与当前最先进的技术相媲美。这些模型尚未广泛发布,因为它们仍处于开发阶段。
总结:
主要卖点:1.Dense架构,与其他模型的MOE架构不同
2.先训练出文本的能力后,加一些图像、视频等能力,偏保守的方案,因为加其他模态以后训练难收敛
Introduction
在预训练阶段,用大量的数据做预测下一个词的任务
在后训练阶段,让模型按照指令去做一些事情,或者对齐到一个人的喜好上,或者提升一些特定能力
Llama3数据堆到15T,而且是在多语言上。15T已经够大了,之后专注于提升数据质量就行,没必要扩充数据集了
没有使用MOE架构,就是对传统方法做大,后训练就做一个SFT、reject sampling和DPO
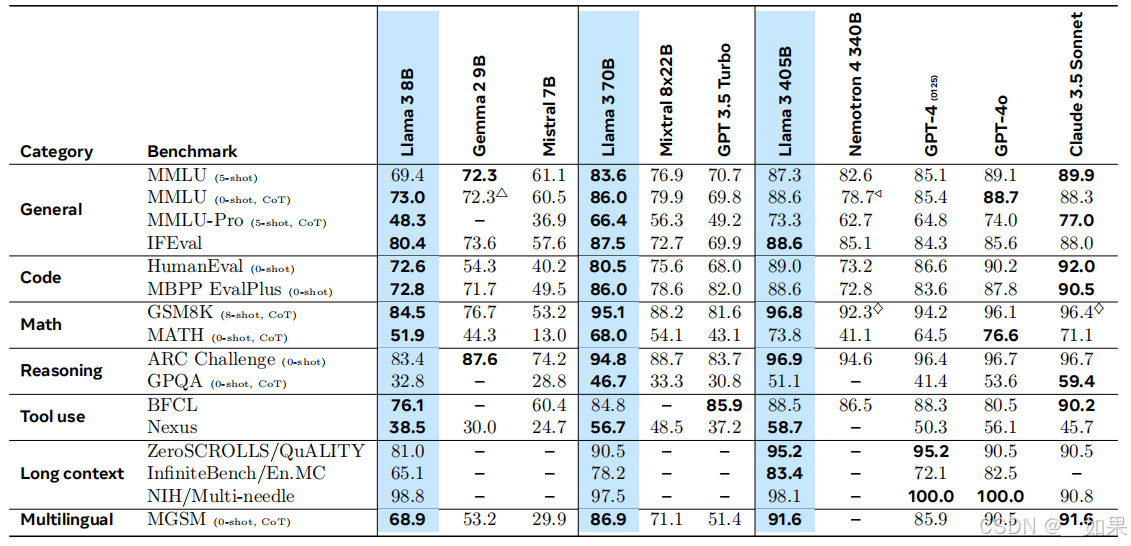
这里玩小心机,benchmark的对比是经过了不同的shot和CoT的,Llama系列缺乏调教,需要shot和CoT辅助后效果会更好,然而现实使用中还是希望zero-shot的
评价指标解读:
MMLU:各个考试里的多选题,考察知识面
IFEval:听从指令的程度
Pretrain
Pretrain-Data
清洗
数据更新到23年末
从多个数据源抓取数据,可能包括视频的字幕、书籍、互联网数据等
当数据含有大量PII信息或标记为危害网站时把信息扔掉
自己做了个parser,因为纯文字的信息不是大多数,html清洗容易洗掉很多数据;对数学公式和代码块针对性清洗
说markdown对模型有害,所以把markdown都扔了,但GPT等模型的输入输出都支持markdown;因为Llama的训练数据是爬取的web html信息,数据的格式以html template的方式呈现,所以markdown在这里对模型有影响
去重
按URL去重、正文抽出来相似度高于阈值去重(MinHash)、重复字数超过6个的行去重
启发式过滤
计算n-gram,如果n很大且重复比较多,就丢掉
设计一个dirty words列表放训练效果不好的词
计算文档与总体文档之间的KL散度,差太多说明这篇文档内容比较奇怪
模型分类
训练模型判断文章质量,用FastText或Roberta
推理数据
训练模型判断文章是否有推理性的数据,对其进行更细致的提取
多语言
抓了176个语言
Data Mix
知识分类
把网上爬取到的数据分类,进行加权
Scaling Law
采取多个混合比例
Summary
50%通用数据,25%数学和reasonable token,17%代码,8%多语言
Annealing data
在少数量的代码和数学上退火能帮助提升效果
预训练完之后的后训练阶段,开放一点学习率对高质量少量的代码和数学数据进行训练
Model Architecture
使用dense架构的transformer
GQA
节省内存
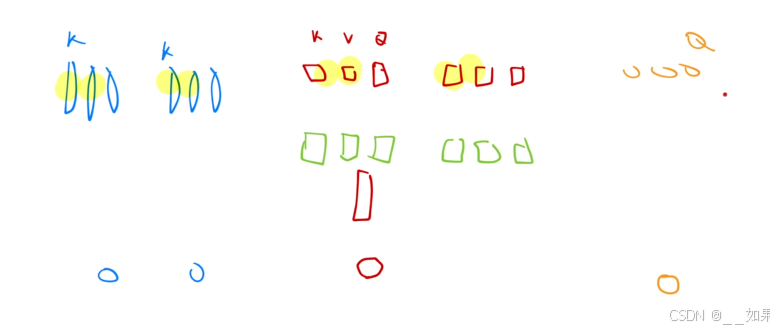
蓝色代表self attention,红色代表多头注意力,绿色是权重矩阵,红色是不同长度的也就是不同头算出的qkv
当需要计算一个新的注意力时,需要用新的q和之前的每个k计算注意力分数,如果讲之前的k和v保留,则需要放入内存中,这就是kv cache
GQA就将多头注意力的kv分组存成一个矩阵,因为他俩几乎是一样的
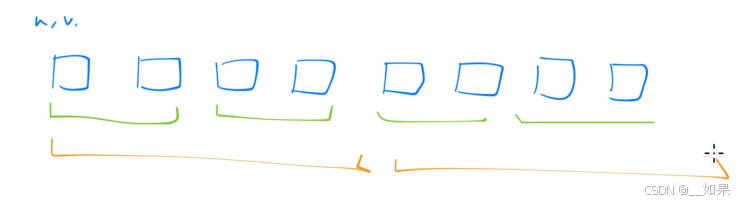
Attention Mask
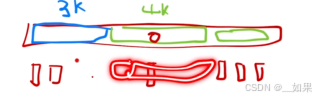
对于一个消息窗口,例如8k,可能窗口中的输入来自多个文档,当计算注意力时,多个文档相互计算,但解码时只关注自己的文档,把其他的mask掉
Vocabulary
128K,相较于GPT4的100K,多了28K支持多语言
一个单词占用的token数变少
RoPE
使用RoPE做位置编码,超参数theta调大,从而支持比较长的上下文窗口
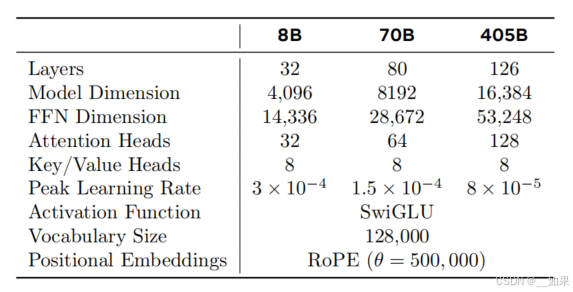
Scaling Law
小模型的验证误差可以用来预测一个大模型的验证误差,但预测下一个token的能力并不代表解决问题的能力,且小模型也并不能完全代表大模型性能
改进1.预测模型在downstream上的loss,也就是更关心具体任务
改进2.把Llama2的预测也拿过来训练
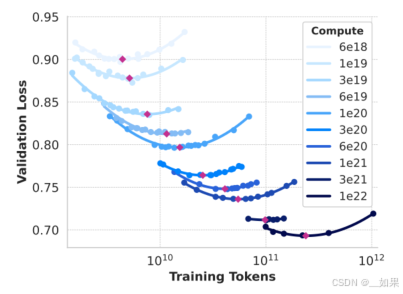
固定算力时,模型变小,可以训练的token数就变多
红色点连起来可以看到,loss随着模型增大差不多算是线性下降
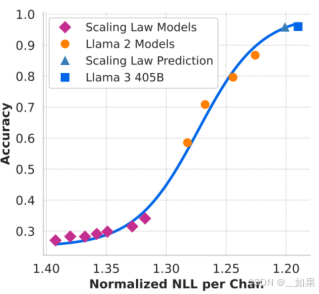
x轴是预测下个词的似然估计
紫色的是Llama3用来做实验的小模型,中间用了Llama2的模型你和一条曲线,最后来预测Llama3 405B似然估计
Infrastructure, Scaling, and Efficiency
Llama1、2是在SuperCluster上训练出来的,里面主要是A100,架构成熟
但是Llama3是在H100上训练出来,最大16000张
数据切分:
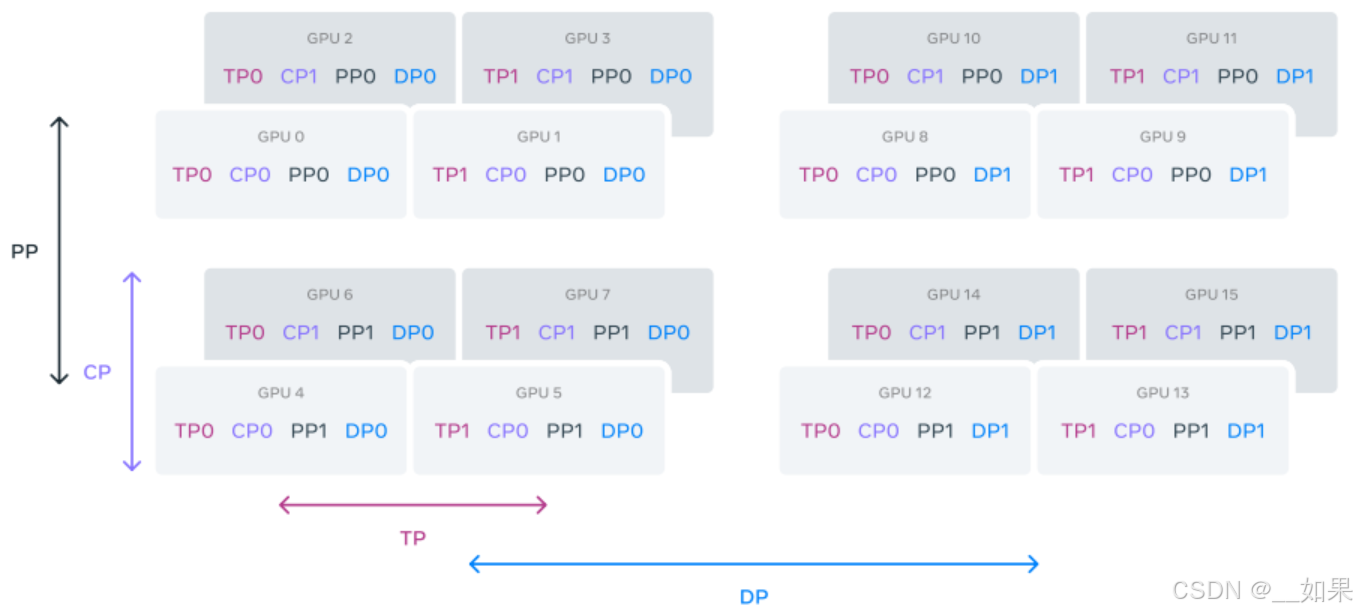
Training Recipe
预训练
lr_rate 8e-5
线性warm up 8000步,然后用cos将学习率下降100倍到8e-7,再走120w步
一开始用一个比较小的批量大小,后面慢慢变大
mix后面把非英语比例调大
在最后的4M个token上退火,lr_rate线性地降到0
pass