o1
o1 模型在训练过程中混合了多种奖励函数的设计方法,并且尝试从结果监督转向过程监督,在中间过程进行打分
使用的搜索策略:基于树的搜索和基于顺序修改的搜索
R1-Zero
R1-Zero 是从基础模型开始,完全由强化学习驱动
探索在没有任何监督数据的情况下,提升LLM模型的推理能力:
-
为了节省RL的训练成本,采用群体相对策略优化(GRPO):奖励本身往往是离散且比较稀疏的,要让价值网络去学习每个token的价值,可能并不划算。而如果我们在同一个问题 q 上采样多份输出,对它们进行奖励对比,就能更好地推断哪些输出更好。由此,就能对每个输出的所有 token 做相对评分,无须明确地学到一个价值函数
-
在RL训练过程中,采用Rule-based奖励,主要由两种奖励构成:
-
Accuracy rewards:评估模型的输出是否正确。
-
Format rewards:强制模型将其思考过程置于指定标签之间。
-
-
设计训练模版,指导基模型在训练过程中遵守设定的指令:A conversation between User and Assistant, The user asks a question, and the Assistant solves it.The assistant first thinks about the reasoning process in the mind and then provides the userwith the answer. The reasoning process and answer are enclosed within <think> </think> and<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>.User: 这里放不同的prompt. Assistant:.
随着强化学习训练进程的深入,模型的思考时间在增加,并自发出现了诸如reflectio(反射,模型重新审视和重新评估其先前步骤)以及探索解决问题的替代方法等更加复杂的行为
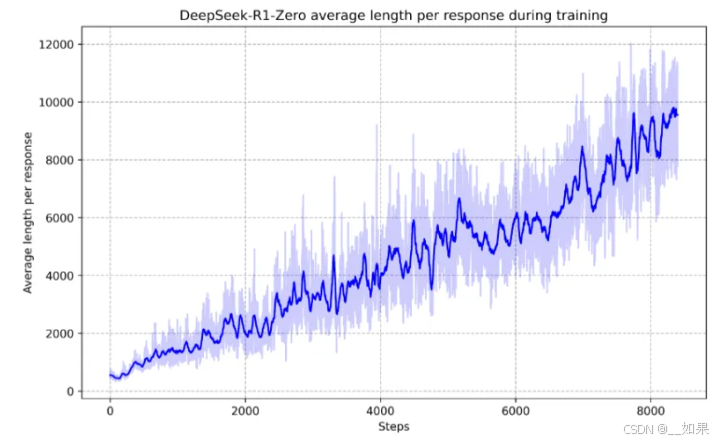
训练过程中出现了Aha Moment(顿悟时刻),代表RL有可能在人工系统中解锁新的智能水平,为未来更加自主和自适应的模型铺平道路

R1
核心问题:
-
相对于完全不使用有监督数据,使用少量高质量数据作为冷启动,是否可以进一步提高推理性能或加速收敛?
-
针对DeepSeek-R1-Zero存在的输出内容可读性差的问题进行优化。
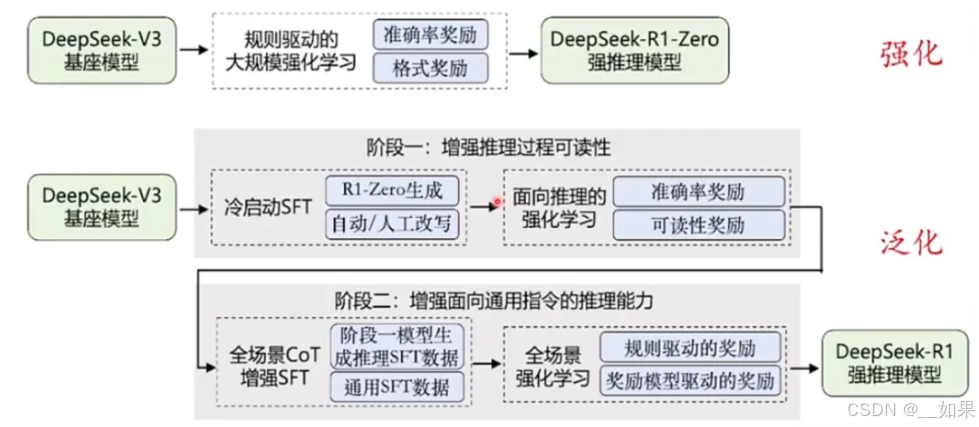
R1 的训练分为四个关键阶段:冷启动阶段、推理导向的强化学习阶段、拒绝抽样与监督微调阶段,以及全任务强化学习阶段。
在冷启动阶段,使用下述方法构建少量的(约几千条)长COT数据,作为冷启动数据对DeepSeek-V3-Base进行微调:
-
以few-shot的长COT prompt作为例子,让DeepSeek-R1-Zero通过反射和验证生成详细的答案;
-
将DeepSeek-R1-Zero的结果进行格式化;
-
让人工标注人员进行后处理。
第二阶段采用与DeepSeek-R1-Zero一致的强化学习训练过程,同时针对DeepSeek-R1-Zero存在的语言混合,导致模型输出可读性差的问题,在RL训练期间引入语言一致性奖励(目标语言单词在 CoT 中的比例)
第三阶段2中的RL过程趋于收敛时,利用checkpoint生产用于下一轮训练的SFT数据。与1中的冷启动数据区别在于,冷启动数据针对推理能力提升,此阶段既包含用于推理能力提升的600k数据,也包含200k推理无关的数据。使用上述约800k样本的精选数据集继续对DeepSeek-V3-Base进行了两个epoch的微调
最后阶段设计了二级强化学习阶段以同时提高模型的helpfulness(有用性) 和harmlessness(无害性):
-
helpfulness:只评估模型最终的结果,而不关注模型的推理过程。
-
harmlessness:既评估模型最终的结果,也评估模型的推理过程。
R1 虽然没有显式强调 MCTS 搜索,但最终报告显示,通过 majority vote,能够大幅提高推理效果,这也说明搜索在推理过程中依然具有提升模型能力的作用
R1 在写作任务上有明显的提升。这可能意味着,强推理技术可以帮助模型在创作任务中发挥更大的潜力
DeepSeek 是全球首个通过纯强化学习技术,成功复现了 o1 的能力;而在许多 o1 的复现工作中,业界有很多复现是基于 SFT 或者蒸馏 o1 的路线
端侧模型
直接对小模型进行DeepSeek-R1-Zero同款的强化学习,得到的DeepSeek-R1-Zero-Qwen-32B模型性能弱于蒸馏模型,即蒸馏>强化学习
v3
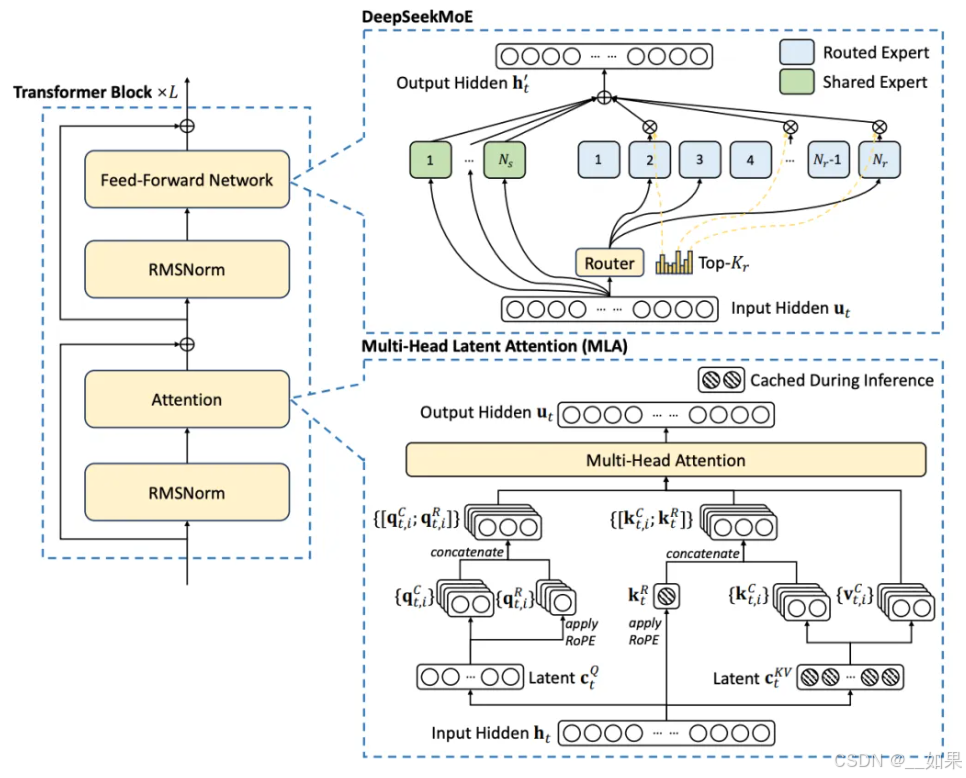
DeepSeek-V3继续沿用V2中的MLA和MoE结构,其中前者是为了降低kv cache/token开销,后者是为了降低flops/param开销。
1)MLA技术 简单来说就是通过类似LoRA的方式对kv进行降维压缩,同时将升维操作转移到Q和O上,避免反复解压缩。遗憾的是,MLA并没有收获太多关注。一个可能的原因是,它跟MQA相比似乎没有表现出什么优势,反而增加了系统复杂度。
2)MoE结构 不同于Mixtral中大专家的设计(将稠密模型中的MLP结构复制8份),DeepSeek-V3采用大量“小专家”的设计,能够显著提升模型的稀疏程度。相比V2的236B总参数(21B激活参数),V3更加激进地引入256个专家,总参数量达到惊人的671B,而激活参数量仅仅增加到37B。
DeepSeek 创新性地提出了“auxiliary loss free”负载均衡策略,通过引入 Expert Bias 动态调节负载分配。当发现某个专家负载过重时,系统会降低其 bias 值;当专家负载不足时,则增加其 bias 值
CUDA 作为一个相对高层的接口,为用户提供编程接口,而 PTX 则隐藏在驱动背后。DeepSeek 的突破性创新在于它直接深入到 PTX 层面,编写和调用 PTX 代码,更精确地控制底层硬件,实现更高效的计算
FP8伴随着数值溢出的风险,而MoE的训练又非常不稳定,这导致实际大模型训练中BF16仍旧是主流选择。然而,DeepSeek 采用了混合精度训练策略,在核心计算层使用 FP8 精度格式。为了解决低精度可能带来的收敛问题,团队设计了细粒度的量化方案,将 Activation 按 1*128 Tile 分组,Weight 按 128*128 block 分组,并通过提高累积精度来保证训练的稳定性