目录
Linux文件操作基础
引入
在Linux第一章提到过,在Linux中,一切皆文件,而文件由文件内容和文件属性组成,在C语言中可以使用相应的接口打开文件,例如fopen函数
文件最开始在磁盘中,但是因为磁盘的速度远低于CPU的执行速度,根据冯诺依曼体系结构,CPU与内存进行交互,所以可以推出文件要被程序读取,就需要与程序加载到内存变成进程一样,文件也需要加载到内存,而加载到内存中的文件包括其内容和属性,内容可以类比为进程的代码和数据,而因为操作系统也需要管理加载到内存的文件,所以文件属性也被存储到一个结构中,可以类比为进程的PCB
所以,在研究Linux文件系统部分主要研究两种文件:
- 加载到内存的文件
- 存储在磁盘中的文件
回顾C语言文件操作
在C语言中,常见的处理文件的步骤如下:
- 打开文件:
fopen函数 - 读取/写入内容:
fwrite函数或者fread函数 - 关闭文件:
fclose函数
示例代码如下:
#include <stdio.h>
#include <string.h>
int main()
{
// 以写的方式打开
FILE* fp = fopen("test.txt", "w");
// 向文件中写数据
const char* content = "hello linux\n";
fwrite(content, 1, strlen(content), fp);
// 关闭文件
fclose(fp);
return 0;
}在上面的代码中,使用fopen函数以w的方式打开当前目录下名为test.txt的文件,通过fwrite函数向文件中写入一个字符串,最后调用fclose函数关闭文件
在C语言部分学到过,一切以w方式打开的文件,不论是否向该文件写入数据,都会优先清空文件中的数据,而如果指定的文件不存在,不论之后是否会写入都会先创建文件,下面是文档对w方式的介绍:
w Truncate file to zero length or create text file for writing. The stream is positioned at the beginning of the file.
这一段描述中第一个需要关注的就是「truncate」,该单词的含义为「截断」,此段描述中的「truncate file to zero length」表现的效果就是清空文件内容
第二个需要关注的是「create」,该单词的含义为「创建」,此段描述中的「create text file for writing」表现的效果就是如果指定文件不存在就创建文件
除了w方式以外,还有一个a方式,以a方式打开的文件,不论是否向该文件写入数据,都不会清空数据,如果需要写入,则是在文件已有的内容之后进行追加,同样如果指定的文件不存在,不论之后是否会写入都会先创建文件,下面是文档对a方式的介绍:
a Open for appending (writing at end of file). The file is created if it does not exist. The stream is positioned at the end of the file.
这一段描述中第一个需要关注的就是「append」,该单词的含义为「追加」,此段描述中的「opening for appending」表现的效果就是在文件已有内容之后追加写新的内容
第二个需要关注的是「create」,该单词的含义为「创建」,此段描述中的「The file is created if it does not exist」表现的效果就是如果指定文件不存在就创建文件
除了上面的操作性知识回顾以外,在C语言中也学到,默认情况下,程序在启动时默认会开启三个流:
stdin:标准输入流,一般认为是从键盘文件读取stdout:标准输出流,一般认为是写入显示器stderr:标准输出流,一般认为是写入日志文件或者写入显示器
系统调用接口
在操作系统基础部分提到过,操作系统上层存在一个系统调用接口部分,实际上C语言提供的文件操作函数都是语言级的函数,对于不同的操作系统,系统调用接口部分也会提供不同的函数供上层调用,为了更加便捷,C语言针对操作系统封装了对应的系统接口形成对应的函数,例如在Linux中,C语言的fopen实际上封装的就是Linux系统接口open函数
open函数
根据Linux的操作手册,下面是open函数的两种函数原型:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);参数解释:
pathname:文件路径名flags:打开文件的方式mode:创建文件是,文件所拥有的权限
需要注意的是,对于第一种方式,因为没有参数可以传递文件创建时的权限,所以一般不会用第一种方式创建文件,更多得可能还是使用第二种方式
返回值解释:
两个函数都返回文件描述符,该值唯一代表一个加载到内存的文件
在Linux中,flags有下面几种常用的值,这些值都是被定义的宏:
O_RDONLY:只读模式O_WRONLY:只写模式O_RDWR:读写模式O_TRUNC:覆写模式O_CREAT:文件不存在时创建文件O_APPEND:追加模式
注意,上面的所有模式只有给出的文字描述中的一种效果,没有其他效果
在给open函数的flags参数传递实参时,如果只传递五种模式的其中一种,一个参数完全可以胜任,但是如果想一次传递多个模式,比如以只写并且文件不存在时创建文件模式打开,此时就涉及到两个模式,一个形参如果通过直接赋值的形式,则无法同时识别两个模式。为了解决这个问题,实际上在Linux中,这个flags是个32个比特位的位图结构,此时传递参数就可以按照位运算的方式传递,在open函数中,只需要判断位图中为1的部分就可以知道指定了哪些模式,下面以一个例子帮助理解这一个思路:
- 定义一些宏模拟上面的模式
// 1左移0位,结果还是1(二进制位01)
#define AONE (1 << 0)
// 1左移1位,结果是2(二进制位10)
#define ATWO (1 << 1)
// 1左移2位,结果是4(二进制100)
#define ATHREE (1 << 2)- 创建函数,参数设置为一个整数,内容为打印指定模式
void print(int flag)
{
// 与运算取出二进制中的1判断指定模式是否选择
if (flag & AONE)
{
printf("AONE模式\n");
}
if (flag & ATWO)
{
printf("ATWO模式\n");
}
if (flag & ATHREE)
{
printf("ATHREE模式\n");
}
}- 测试
#include <stdio.h>
int main()
{
// 1种模式
print(AONE);
printf("************\n");
// 2种模式,将为0的比特位置为1
print(AONE | ATWO);
printf("************\n");
// 3种模式
print(AONE | ATWO | ATHREE);
}
输出结果:
AONE模式
************
AONE模式
ATWO模式
************
AONE模式
ATWO模式
ATHREE模式read函数和write函数
在Linux中,read函数和write函数读和写的系统调用接口,其原型如下:
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);参数解释:
fd:文件描述符,对应open函数返回值buf:指向指定数组,对于read函数来说,代表存入读取到的内容的起始地址;对于write函数来说,代表待输出的内容的起始地址count:代表期望内容个数,对于read函数来说,代表最大读取内容的个数;对于write函数来说,表示最大输出内容的个数
返回值解释:
两个函数均返回实际的内容个数,对于read函数来说,代表实际读取内容的个数;对于write函数来说,表示实际输出内容个数
close函数
在Linux中,close函数是关闭文件的系统调用接口,其原型如下:
int close(int fd);参数解释:fd代表文件描述符,与open函数的返回值对应
返回值解释:0代表关闭成功,小于0代表失败
模拟C语言接口
有了上面的铺垫,现在考虑open函数的使用模拟w的方式,根据前面C语言中w方式的描述:以写模式打开并且不存在指定文件时创建该文件,若指定文件中有内容就清除文件内容,需要使用到只写模式、文件不存在时创建模式和覆写模式
先观察三个模式依次搭配的特点:
O_WRONLY
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
// 以只写模式打开文件
int fd = open("test.txt", O_WRONLY);
// 向文件中写入
const char* content = "hello linux\n";
int num = write(fd, content, strlen(content));
printf("%d\n", num);
// 关闭文件
close(fd);
return 0;
}向当前目录中的test.txt文件输出内容:

如果此时将写入的内容变短为3个字符,观察下面代码的运行结果:
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
// 以只写模式打开文件
int fd = open("test.txt", O_WRONLY);
// 向文件中写入
const char* content = "bye";
write(fd, content, strlen(content));
// 关闭文件
close(fd);
return 0;
}向当前目录中的test.txt文件输出内容:

可以看到,只写模式打开一个有内容的文件默认不会清除原始内容,而是覆盖写
O_TRUNC和O_WRONLY
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
// 以只写模式打开文件
int fd = open("test.txt", O_WRONLY | O_TRUNC);
// 向文件中写入
const char* content = "hello\n";
write(fd, content, strlen(content));
// 关闭文件
close(fd);
return 0;
}向当前目录中的test.txt文件输出内容:

可以看到加了O_TRUNC宏后,就可以达到打开文件后不论文件是否有内容都会先清空再写入内容
O_TRUNC、O_WRONLY和O_CREAT
前面两个选项都只展示了在有指定文件的情况下正常运行,但是C语言的fopen函数以w方式打开指定文件,当该文件不存在会自动创建,所以此时就需要在系统调用接口加上O_CREAT,例如下面的代码:
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
// 以只写模式打开文件
int fd = open("test.txt", O_WRONLY | O_TRUNC | O_CREAT);
// 向文件中写入
const char* content = "hello, this is linux\n";
write(fd, content, strlen(content));
// 关闭文件
close(fd);
return 0;
}删除当前目录的test.txt文件后执行上面的代码:

可以看到会自动创建test.txt文件再写入指定的内容
此时就简单实现了C语言中的w方式打开的效果
文件描述符
前面的系统调用接口函数中,四个函数均涉及到了文件描述符,该描述符在Linux中是对每一个加载到内存的唯一标识,打印指定的文件观察open函数返回值:
#include <stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
// 以只写模式打开文件
int fd = open("test.txt", O_WRONLY | O_TRUNC | O_CREAT);
printf("%d\n", fd);
// 关闭文件
close(fd);
return 0;
}
输出结果:
3根据Linux操作手册,对于open函数的返回值具体描述如下:
open() returns the new file descriptor, or -1 if an error occurred (in which case, errno is set appropriately).
可以看到,当open函数打开文件成功时返回-1,否则返回打开的文件对应的文件描述符,为了知道何为文件描述符,这里就需要深入了解在Linux具体是如何描述和管理文件的
首先,有了前面学习进程的基础可以知道每一个进程需要被管理就需要先描述再组织,而描述对应的就是进程PCB(task_struct),组织就是双向链表,对于文件也是如此,描述对应的就是struct file,组织也是双向链表
但是,如果直接让进程访问文件结构file就会增加耦合度,导致操作系统的管理工作会变得繁重,所以在内存中,进程结构在单独的一个区域,文件结构也在单独的一个区域,而为了进程可以访问到文件,进程结构中就存在一个结构体指针struct files_struct *files,该结构体指针类型是struct files_struct *,所谓的files_struct就是将文件和进程建立连接的结构,该结构中存在一个属性:struct file * fd_array[NR_OPEN_DEFAULT],该数组的每一个成员就是指向每一个文件file结构的指针,因为是数组,所以可以通过下标访问指定的元素,在当前这个条件下,访问到的就是指向每一个文件file结构的指针
所以所谓的文件描述符,就是fd_array数组的下标,示意图如下:
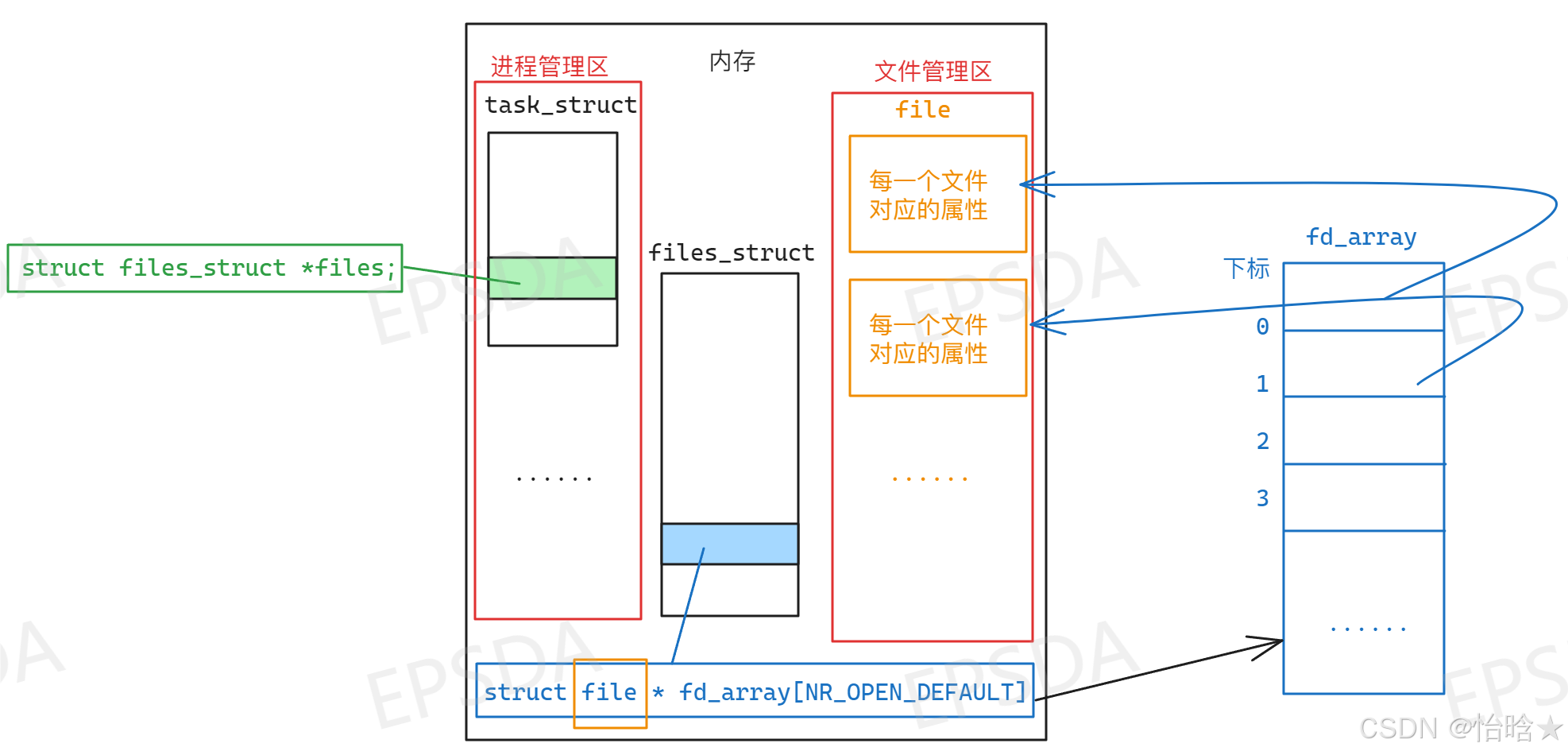
此时就会有第二个问题:为什么在程序中打开的文件默认下标是3,错误是-1,中间的0、1和2表示什么?
前面提到,在C语言程序启动时,会自动加载3种文件流:
stdin:标准输入流,一般认为是从键盘文件读取stdout:标准输出流,一般认为是写入显示器stderr:标准输出流,一般认为是写入日志文件或者写入显示器
在Linux手册中,这三个流的原型如下:
#include <stdio.h>
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;可以看到三者均是FILE类型,这个类型实际上是语言级上的封装,因为在Linux中文件描述符是访问文件的唯一方式,所以C语言的接口想访问文件就必须要访问到指定文件的文件描述符,所以FILE结构中一定可以有文件描述符属性,根据下面代码可以验证(下面的代码中_fileno对应的就是文件描述符):
#include <stdio.h>
int main()
{
printf("%d\n", stdin->_fileno);
printf("%d\n", stdout->_fileno);
printf("%d\n", stderr->_fileno);
return 0;
}
输出结果:
0
1
2所以,之所以显式打开的文件对应的文件描述符为3是因为默认打开的三个文件占用了fd_array数组前面三个空间
如何理解Linux下一切皆文件
前面提到多次「在Linux下一切皆文件」,对于保存在计算机硬盘中的文件来说,说其是文件再合适不过,但是对于硬件来说,如果再说硬件是文件难免有些不妥,但是如果硬件不属于文件,那么就不会出现「在Linux下一切皆文件」的表述,所以硬件为什么在Linux下硬件也算文件
要理解为什么在Linux下硬件也算文件,需要先回顾操作系统的作用。在开始进程部分之前,提到过操作系统实际上是一个管理者,上层提供调用接口,下层通过调用接口中的具体实现操控硬件,此处为了理解硬件也算文件,就需要研究下层中接口的实现
此处不讨论接口中具体的代码实现,只讨论这整个过程是如何形成的
根据冯诺依曼体系结构,除了内存、CPU以外,其他设备均称为外设,也称为输入输出设备,而这些设备在接入计算机时,需要在计算机中安装驱动,而安装驱动的本质就是为了将对应的硬件信息加载到属于硬件的信息表中,而操作系统为了管理这些表,就需要创建一个结构体,这一个过程符合「先描述,再组织」的「描述」,此处的每一个结构体都是通过双向链表进行连接,这一个过程符合「先描述,再组织」的「组织」。有了硬件信息的结构体和对应的数据结构,操作系统就可以开始通过管理这一个硬件信息数据结构来管理硬件,这一个过程就可以理解为实现「硬件即文件」的初步过程
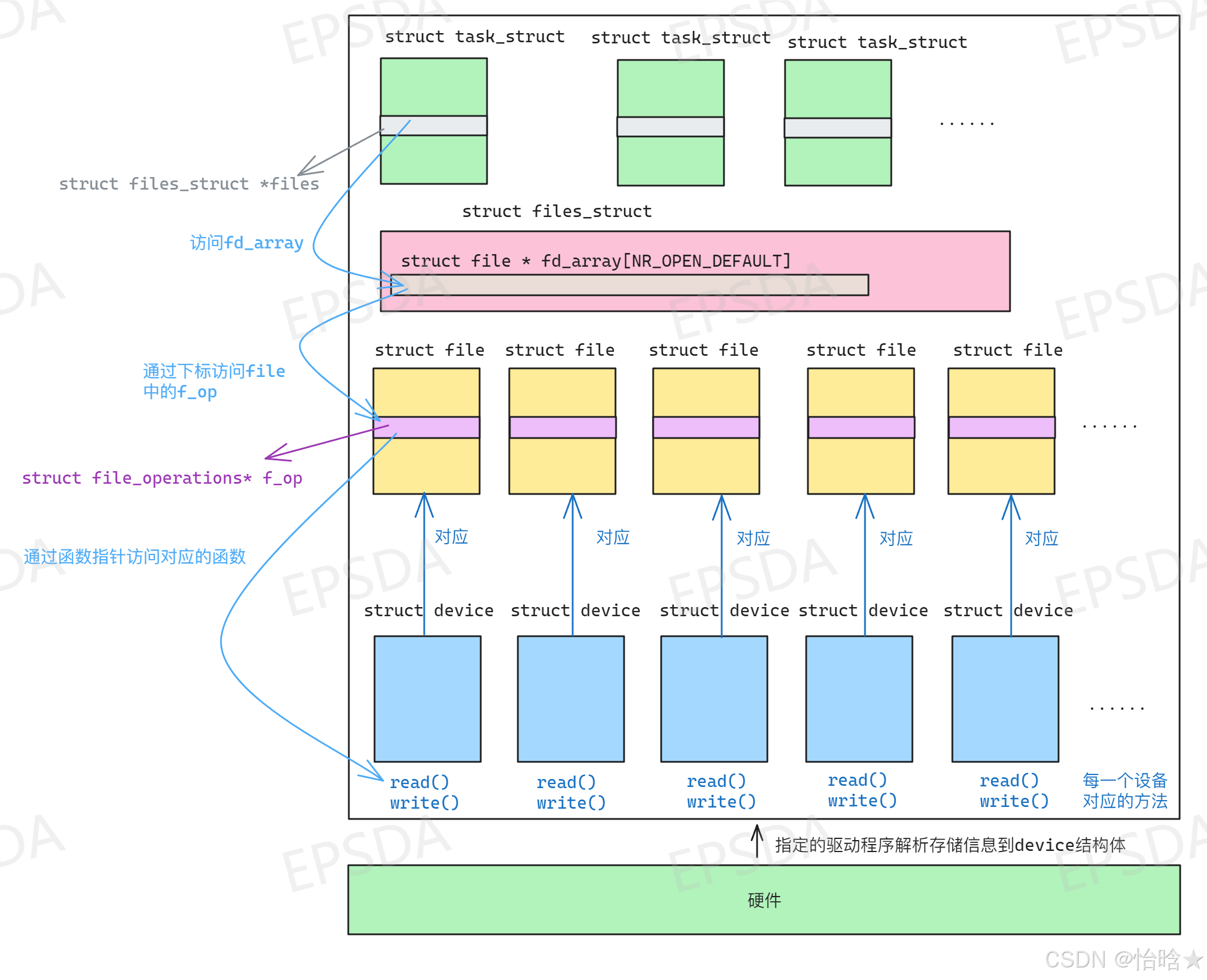
但是上面的过程只是完成了硬件信息之间的联系,这些联系只能做到简单的增删查改,操作系统不可能一直停留在添加设备和删除设备的行为中,这也没有意义。上文提到这些硬件本身都属于输入输出设备,最基本的行为就是输入和输出,即I/O行为,所以每一个硬件都有属于自己的一套I/O行为方法,尽管有的只有输出,有的只有输入,而因为方法的实现不同,导致操作硬件的方法就不同,在C语言中,不允许在结构体中定义方法(也称函数),所以每一个设备的方法都独立于设备结构外,此时如果进程需要调用就会显得不方便(调用顺序:task_struct->file_struct->file访问到指定硬件信息,单独调用指定方法传参),为了简化这一步骤,考虑将指定方法的地址作为file结构的成员(即结构体中存储函数指针),此时进程调用即可通过file结构调用指定文件,而不需要再访问指定的硬件结构以及单独调用指定的方法,所以此时每一个结构体的属性和方法就可以通过file结构来进行管理和访问,最终做到了「硬件即文件」
在上面的过程中,使用file结构描述所有文件,包括硬件视为文件在内的系统称为Linux下的虚拟文件系统(Virtual File System,简称VFS),有了前面的介绍,现在基本介绍一下虚拟文件系统的作用:虚拟文件系统是操作系统的文件系统虚拟层,在其下是实体的文件系统。虚拟文件系统的主要作用在于让上层的软件,能够用单一的方式,来跟底层不同的文件系统沟通。在操作系统与之下的各种文件系统之间,虚拟文件系统提供了标准的操作接口,让操作系统能够很快的支持新的文件系统
简单理解这个作用就是让每一个进程访问每一个文件都认为是同一种文件,而不是每一个文件都是独立的个体
补充:在上面的描述中提到一个点:file结构体中保存了函数指针和文件属性字段,而其他文件只需要实现自己对应的函数即可,这个过程非常像C++面向对象三大特性中的一大特性:多态,多态的基本形式为父类提供方法名但不实现,由具体的子类去实现,所以上面C语言中的思路也可以理解为是C语言中实现多态的一种方式
下面是前面的描述对应的示意图:
Linux 2.6.0内核源代码中的file_operations结构体如下:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, char __user *, size_t, loff_t);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_write) (struct kiocb *, const char __user *, size_t, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*sendfile) (struct file *, loff_t *, size_t, read_actor_t, void __user *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
};文本读写与二进制读写
在语言层面会看到大多数编程语言会提供文本读写的函数和二进制读写的函数,在计算机中,所有文件实际上都是以二进制的形式存储在内存中,文本文件也不例外,但是为什么需要将文本读写和二进制读写分开而不直接使用一套的二进制读写
为了回答上面的问题,首先解释为什么语言层面需要对底层的系统调用进行封装
观察前面提到的系统调用接口write函数和read函数,原型如下:
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);可以看到,这两个函数在指定写入和读取的内容时都是void*,说明这两个函数可以接受任意数据的指针,将任意数据写入或读取到指定位置,如果此时要向指定位置写入一个12345会出现下面的情况:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("test1.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);
int a = 12345;
write(fd, &a, sizeof(int));
close(fd);
return 0;
}编译执行上面的代码查看test1.txt文件中的内容:

可以看到并非是写入的12345,那为什么是90:write(fd, &a, sizeof(int));这一行会把整数 12345 的字节序列写入文件。整数12345在大多数系统上(小端序)会被存储为四个字节,在一个小端序Linux系统上运行这段代码,那么整数12345(即 0x3039或0x00003039补充高位零)会被分解成字节0x39, 0x30, 0x00, 0x00 并按此顺序写入文件,而字节0x39对应ASCII字符'9',而0x30对应 ASCII 字符'0'
如果想向文件中写入真正的12345,则必须按照下面的方案进行:
- 将12345封装为字符串
- 将该字符串写入
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("test1.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);
const char* a = "12345";
write(fd, a, sizeof(a));
close(fd);
return 0;
}编译执行上面的代码查看test1.txt文件中的内容:

而如何想用系统调用接口read函数进行读取,为了保证读取的内容也是真正的12345,需要单独创建一个数组存储到读取的数据
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("test1.txt", O_RDONLY, 0666);
char buffer[1024] = {0};
ssize_t num = read(fd, buffer, sizeof(buffer));
buffer[num] = 0; // 尾部置为\0
printf("%s\n", buffer);
close(fd);
return 0;
}编译执行上面的代码可以看到下面的结果:

可以看到,不论是读还是写,使用系统调用接口都需要用户自己先处理数据的转换,否则就会出现写入或读取的内容不是预期的内容
所以,为了保证用户想输入指定的内容而不希望其被转换为各种奇奇怪怪的内容,语言层就提供了对系统调用接口封装后的函数,比如写入的sprintf和读取的sscanf等
现在再来解释为什么语言层面要区分文本读写和二进制读写,从前面的例子可以看到,如果想写入一个12345必须先转换为字符串才能继续写入,实际上很多情况下都需要将内容原样写入原样读取,例如将指定内容打印到显示器,显示器实际上就是字符设备,12345并不是以数字形式显示在显示器上,而是按照一个一个字符依次显示使其看起来是一个整体,所以语言层单独封装一层文本输入和输出就是因为文本输入和输出使用频率很高
总结起来,语言层对系统调用接口进行封装的主要原因有以下几点:
- 方便用户使用:封装可以提供更高层次的抽象,使得接口更加简洁易懂,降低使用难度
- 便于跨平台,实现语言的可移植性:封装(Linux下的C语言的标准库为
glibc)可以创建一个抽象层,屏蔽掉不同操作系统之间的差异,使得代码能够在多种平台上运行。通过封装,开发人员可以编写一次代码,然后在多个操作系统上运行,减少了针对不同平台进行调整的工作量