计算学部
目 录
第1章 实验基本信息
1.1 实验目的
理解程序优化的10个维度
熟练利用工具进行程序的性能评价、瓶颈定位
掌握多种程序性能优化的方法
熟练应用软件、硬件等底层技术优化程序性能
1.2 实验环境与工具
1.2.1 硬件环境
X64 CPU;2GHz;2G RAM;256GHD Disk 以上
1.2.2 软件环境
Windows7/10 64位以上;VirtualBox/Vmware 11以上;Ubuntu 16.04 LTS 64位/优麒麟 64位 以上
1.2.3 开发工具
Visual Studio 2010 64位以上;CodeBlocks 64位;vi/vim/gedit+gcc
1.3 实验预习
上实验课前,必须认真预习实验指导书
了解实验的目的、实验环境与软硬件工具、实验操作步骤,复习与实验有关的理论知识。
请写出程序优化的十个维度
如何编写面向编译器、CPU、存储器友好的程序。
性能测试方法
time()/gettimeofday():返回自Epoch(1970年1月1日00:00:00 UTC)以来的秒数/获取当前的时间(包括秒和微秒部分)和时区
RDTSC指令:CPU自启动以来的时钟周期数
clock():clock函数返回的是处理器时钟计时器所经过的时钟周期数
性能测试准确性的文献查找:流水线、超线程、超标量、向量、多核、GPU、多级CACHE、编译优化Ox、多进程、多线程等多种因素对程序性能的综合影响。
第2章 实验预习
总分20分
2.1 程序优化的十个维度(5分)
(1)更快
(2)更省(存储空间、运行空间)
(3)更美(UI交互)
(4)更正确
(5)更可靠
(6)可移植
(7)更强大(功能)
(8)更方便(使用)
(9)更符合编程规范和接口规范
(10)更易懂(能读明白、有注释、模块化)
2.2性能优化的方法概述(5分)
- 一般有用的优化(编译选项-O1、-O2等)
- 代码移动
- 复杂指令简化
- 公共子表达式
- 面向编译器的优化(解决编译器的优化障碍)
- 函数副作用
- 内存别名
- 面向超标量CPU的优化
- 流水线、超线程、多功能部件、分支预测投机执行、乱序执行、多核:分离的循环展开
- 只有保持能够执行该操作的所有功能单元的流水线都是满的,程序才能达到这个操作的吞吐量界限
- 面向向量CPU的优化(MMX/SSE/AVX)
- CMOVxx,串指令等指令
- 代替test/cmp+jxx,for循环
- 嵌入式汇编
- 面向编译器的优化:On:O1、O2、O3、Og
- 面向存储器的优化:Cache无处不在
- 重新排列提高空间局部性
- 分块提高时间局部性
- 内存作为逻辑硬盘ramdisk:内存够用的前提下
- 多进程优化
- fork,每个进程负责各自的工作任务,通过mmap共享内存或磁盘等进行交互
- 文件访问优化:带Cache的文件访问
- 并行计算:多线程优化
- 网络计算优化:分布式计算、云计算
- GPU编程、算法优化
- 超级计算
2.3 Linux下性能测试的方法(5分)
(1)使用自己构造的函数测出程序运行时间,进而测试性能
(2)Linux下使用Oprofile等工具(gprof、google-perftools)
a.https://blog.csdn.net/Blaider/article/details/7730792
b.https://www.cnblogs.com/jkkkk/p/6520381.html
c.https://www.cnblogs.com/MYSQLZOUQI/p/5426689.html
(3)Linux下的valgrind: callgrind/Cachegrind
a.https://www.jianshu.com/p/1e423e3f5ed5
b.https://blog.csdn.net/u010168781/article/details/84303954
2.4 Windows下性能测试的方法(5分)
(1)使用自己构造的函数测出程序运行时间,进而测试性能
(2)Windows下VS,本身就有性能评测的组件,调试:性能探测器:CPU、RAM、GPU
第3章 性能优化的方法
总分20分
逐条论述性能优化方法名称、原理、实现方案(至少10条)
3.1 一般有用的优化
原理:
通过减少重复运算的低效代码以及一部分死代码来减少程序运行时间来提高性能
实现方案:
代码移动:减少计算执行的频率,如果它总是产生相同的结果,将代码从循环中移出
复杂指令简化:用移位、加来替换乘法或者除法,实际效果依赖于机器,取决于乘法或除法指令的成本
公共子表达式:重用表达式的一部分,gcc使用-O1选项来实现这个优化
3.2面向编译器的优化(解决编译器的优化障碍)
原理:
如果程序中有别名使用,两个不同的内存引用很容易指向同一个位置导致程序出现错误,而编译器为了保守,这种情况不会选择自动优化
实现方案:
函数副作用:函数每次调用都可能改变全局变量或者状态,这需要我们合理地在函数内修改全局变量的值
内存别名:两个不同的内存引用指向相同的位置,编译器不知道函数什么时候被调用,不知道内存会不会被别的函数修改,这要求我们养成引入局部变量的习惯
3.3面向超标量CPU的优化
原理:
超标量试图在一个周期取出多条指令并行指令,通过内置多条流水线来同时执行多个处理,实质上是空间换时间
实现方案:
流水线、超线程、多功能部件、分支预测投机执行、乱序执行、多核
3.4面向向量CPU的优化
原理:
CPU有向量寄存器,指令集内有向量计算的指令,使用向量计算可以加速较大数据的计算
实现方案:
MMX/SSE/AVR
3.5CMOVxx等指令
原理:
test/cmp+jxx指令是使用控制的条件转移,这种方法要先测试数据值,再根据测试结果来改变控制流或者数据流。而采用CMOVxx等指令是使用数据的条件转移,当可行时,可以直接使用一条简单的条件传送指令实现,比较高效
实现方案:
使用CMOVxx等指令来代替test/cmp+jxx指令
3.6嵌入式汇编
原理:
在不改变程序功能的情况下,通过修改原来程序的算法或结构,并利用软件开发工具对程序进行改进,使修改后的程序运行速度更高或代码尺寸更小
实现方案:
嵌入式汇编程序优化可分为运行速度优化和代码尺寸优化,其中运行速度优化是指在充分掌握硬件特性的基础上,通过应用程序结构调整等手段来缩短完成指定任务所需要的运行时间,代码尺寸优化则是指应用程序在能够正确实现所需功能的前提下,尽可能减小程序的代码量
3.7面向编译器的优化(选择优化模式)
原理:
指定优先级别,获取每个优化标识所启用的优化选项,根据不同的优化选项来进行不同程度的优化
实现方案:
利用O1、O2、O3、Og等优化模式来对内存和速度等进行不同程度的优化
3.8面向存储器的优化
原理:
通过合理划分得到合适的工作集使得工作集可以尽可能地由高速缓存L1、L2、L3来缓存以提高读吞吐量,从而优化程序性能
实现方案:
重新排列提高空间局部性,分块提高时间局部性,通过优化来降低Cache的不命中率
3.9内存作为逻辑磁盘
原理:
在计算机这个系统中,高速小容量的内存和低速大容量的磁盘进行协同作业,计算机在运行程序时,必须将磁盘中的内容加载到内存中才能运行
实现方案:
当内存足够大时,使用大量内存充当磁盘缓存
3.10多进程优化
原理:
使用多线程可以使得CPU的多个核心同时处理任务,提升程序的并发执行性能,提高计算资源利用率
实现方案:
fork,每个进程负责各自的工作任务,通过mmap共享内存或者磁盘等来进行交互
第4章 性能优化实践
总分60分
4.1 原始程序及说明(10分)
- #include <stdio.h>
- #include <time.h>
- #define HEIGHT 8192
- #define WIDTH 5120
- #define NUMBER 20
- long src[HEIGHT][WIDTH];
- long res[HEIGHT][WIDTH];
- void original();
- int main()
- {
- //初始化数组
- long a = 0;
- for (int i = 0; i < HEIGHT; i++)
- for (int j = 0; j < WIDTH; j++)
- src[i][j] = a++;
- clock_t start = clock(); //开始计时
- for (int i = 0; i < NUMBER; i++) //执行循环
- original();
- clock_t end = clock(); //停止计时
- printf("original_time:%lf(s)", (double)(end - start) / CLOCKS_PER_SEC);
- }
- void original()
- {
- for (int j = 1; j < WIDTH - 1; j++)
- for (int i = 1; i < HEIGHT - 1; i++)
- res[i][j] = (src[i - 1][j] + src[i + 1][j] + src[i][j - 1] + src[i][j + 1]) / 4;
- }
功能:图像处理程序实现图像的平滑并且输出平滑20次所需要的时间。忽略边缘数据,平滑20次是为了放大程序执行时间,更明显地比较优化效果。
流程:先在main函数中给原始数组赋值,并获取初始时间,随后调用original函数来平滑处理,最终输出用时。
可能瓶颈:循环使用先列后行遍历和跳行访存的方式,可能会大大增加花费的时间,算法中多次用到除法,可能会增加时间。
运行时间如下:

4.2 优化后的程序及说明(20分)
(1)Cache优化(符合空间局部性)
- void Cache()
- {
- for (int i = 1; i < HEIGHT - 1; i++)
- for (int j = 1; j < WIDTH - 1; j++)
- res[i][j] = (src[i - 1][j] + src[i][j - 1] + src[i][j + 1] + src[i + 1][j]) / 4;
- }
由于数组在电脑中按行进行存储,根据上课讲过的命中和不命中的知识可以知道,对于数组来说,一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之内,这是因为指令通常是顺序存放、顺序执行的,数据也一般是以向量、数组、表等形式簇聚存储的。如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。如果其访问顺序和存储顺序一致,程序性能会提升很多。
运行时间如下,发现速度有非常大的提升

- 一般有用的方法(复杂运算简化)
- void Common()
- {
- for (int j = 1; j < WIDTH - 1; j++)
- for (int i = 1; i < HEIGHT - 1; i++)
- res[i][j] = (src[i - 1][j] + src[i + 1][j] + src[i][j - 1] + src[i][j + 1]) >> 2;
- }
由于从效率上看,使用移位指令有更高的效率,因为移位指令占2个机器周期,而乘除法指令占4个机器周期。从硬件上看,移位对硬件更容易实现,所以会用移位,左移一位就乘2,右移一位除以2,这种乘除法考虑移位实现会更快。
运行时间如下,发现速度略微提高

- CPU优化(循环展开)
- void CPU()
- {
- int i, j;
- for (j = 1; j < WIDTH - 4; j += 4)
- for (i = 1; i < HEIGHT - 1; i++)
- {
- res[i][j] = (src[i - 1][j] + src[i + 1][j] + src[i][j - 1] + src[i][j + 1]) / 4;
- res[i][j + 1] = (src[i - 1][j + 1] + src[i + 1][j + 1] + src[i][j] + src[i][j + 2]) / 4;
- res[i][j + 2] = (src[i - 1][j + 2] + src[i + 1][j + 2] + src[i][j + 1] + src[i][j + 3]) / 4;
- res[i][j + 3] = (src[i - 1][j + 3] + src[i + 1][j + 3] + src[i][j + 2] + src[i][j + 4]) / 4;
- }
- for (; j < WIDTH - 1; j++)
- for (i = 1; i < HEIGHT - 1; i++)
- res[i][j] = (src[i - 1][j] + src[i + 1][j] + src[i][j - 1] + src[i][j + 1]) / 4;
- }
流水线只要流起来可以大大提高CPU的工作效率,循环的时候,每次可以使用更多变量参与运算,能使流水线更好地流。这样可以使硬件能让流水线很好地运作,即使在少数情况下也只牺牲一点效率。
运行时间如下,发现速度大大提升
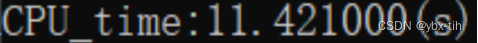
- 超标量CPU优化(优化指令级别并发)
- void Instruction()
- {
- for (int j = 1; j < WIDTH - 1; j++)
- {
- for (int i = 1; i < HEIGHT - 1; i += 8)
- {
- res[i][j] = (src[i - 1][j] + src[i + 1][j] + src[i][j - 1] + src[i][j + 1]) / 4;
- res[i + 2][j] = (src[i + 1][j] + src[i + 3][j] + src[i + 2][j - 1] + src[i + 2][j + 1]) / 4;
- res[i + 4][j] = (src[i + 3][j] + src[i + 5][j] + src[i + 4][j - 1] + src[i + 4][j + 1]) / 4;
- res[i + 6][j] = (src[i + 5][j] + src[i + 7][j] + src[i + 6][j - 1] + src[i + 6][j + 1]) / 4;
- }
- for (int i = 2; i < HEIGHT - 1; i += 8)
- {
- res[i][j] = (src[i - 1][j] + src[i + 1][j] + src[i][j - 1] + src[i][j + 1]) / 4;
- res[i + 2][j] = (src[i + 1][j] + src[i + 3][j] + src[i + 2][j - 1] + src[i + 2][j + 1]) / 4;
- res[i + 4][j] = (src[i + 3][j] + src[i + 5][j] + src[i + 4][j - 1] + src[i + 4][j + 1]) / 4;
- res[i + 6][j] = (src[i + 5][j] + src[i + 7][j] + src[i + 6][j - 1] + src[i + 6][j + 1]) / 4;
- }
- }
- }
这是由于现代处理器中对不同部分指令拥有一点并发性(跟流水线有关,比如Pentium处理器就有U/V两条流水线)。这使得CPU在同一时刻可以访问L1两处内存位置,或者执行两次简单算数操作。操作相互独立,可以两条流水一起跑。
运行时间如下

发现时间增加,主要是因为空间局部性的限制,下面改进一下
- void Instruction()
- {
- for (int i = 1; i < HEIGHT - 1; i++)
- {
- for (int j = 1; j < WIDTH - 1; j += 8)
- {
- res[i][j] = (src[i - 1][j] + src[i + 1][j] + src[i][j - 1] + src[i][j + 1]) / 4;
- res[i + 2][j] = (src[i + 1][j] + src[i + 3][j] + src[i + 2][j - 1] + src[i + 2][j + 1]) / 4;
- res[i + 4][j] = (src[i + 3][j] + src[i + 5][j] + src[i + 4][j - 1] + src[i + 4][j + 1]) / 4;
- res[i + 6][j] = (src[i + 5][j] + src[i + 7][j] + src[i + 6][j - 1] + src[i + 6][j + 1]) / 4;
- }
- for (int j = 2; j < WIDTH - 1; j += 8)
- {
- res[i][j] = (src[i - 1][j] + src[i + 1][j] + src[i][j - 1] + src[i][j + 1]) / 4;
- res[i + 2][j] = (src[i + 1][j] + src[i + 3][j] + src[i + 2][j - 1] + src[i + 2][j + 1]) / 4;
- res[i + 4][j] = (src[i + 3][j] + src[i + 5][j] + src[i + 4][j - 1] + src[i + 4][j + 1]) / 4;
- res[i + 6][j] = (src[i + 5][j] + src[i + 7][j] + src[i + 6][j - 1] + src[i + 6][j + 1]) / 4;
- }
- }
- }
运行时间如下,发现速度明显提升

- 存储器优化(分块来提高时间局部性)
首先用CPU-Z来查看L1 Cache的相关参数
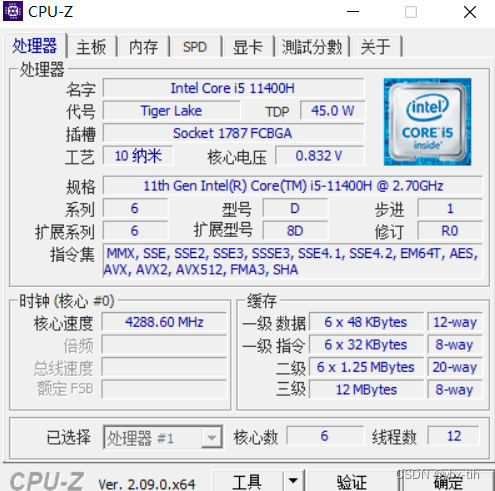
可以看到L1数据Cache为12路相连,可以存下一个8*8的矩阵,所以取块大小为8*8。
- void Block()
- {
- int x, y, i, j;
- for (x = 1; x < HEIGHT - 1; x += 8)
- for (y = 1; y < WIDTH - 1; y += 8)
- {
- int boundi = (HEIGHT - 1) < (x + 8) ? (HEIGHT - 1) : (x + 8);
- int boundj = (WIDTH - 1) < (y + 8) ? (WIDTH - 1) : (y + 8);
- for (i = x; i < boundi; i++)
- for (j = y; j < boundj; j++)
- res[i][j] = (src[i - 1][j] + src[i][j - 1] + src[i][j + 1] + src[i + 1][j]) / 4;
- }
- }
运行时间如下,速度大幅度提高

- 编译器优化
使用Visual Studio来进行编译器优化
未优化:
O1优化:
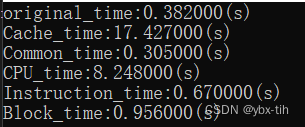
O2优化:
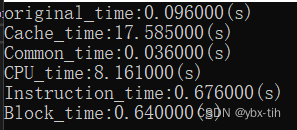
Ox优化:
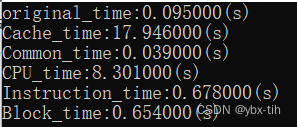
可以看到除了对Cache和CPU的优化之外,其余速度都得到非常大的提升
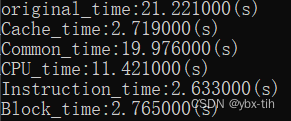
4.3 优化前后的性能测试(10分)
测试方法:在保证运算结果相同情况下,使用C语言中的库函数clock来测量
测试结果:下图为未使用编译器优化的各优化方法性能
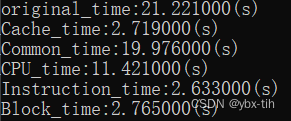
从测试结果来看,采用的各种优化方法确实提高了程序性能,减少了程序运行时间。
| 采用方法描述 | 运行时间(s) |
| 初始状态 | 21.221 |
| Cache优化(符合空间局部性) | 2.719 |
| 除法变为移位运算 | 19.976 |
| CPU优化(循环展开) | 11.421 |
| 指令级别并发 | 2.633 |
| 分块操作(时间局部性) | 2.765 |
4.4 面向泰山服务器优化后的程序与测试结果(15分)
在泰山服务器测试结果如下:

经分析,同一程序,在泰山服务器上运行时间较长
| 采用方法描述 | 运行时间(s) |
| 初始状态 | 114.524 |
| Cache优化(符合空间局部性) | 9.34 |
| 除法变为移位运算 | 114.673 |
| CPU优化(循环展开) | 40.310 |
| 指令级别并发 | 8.812 |
| 分块操作(时间局部性) | 10.759 |
与Windows相比,泰山服务器在CPU循环展开为4以及8*8分块操作上优化效果更好一些,在除法变移位运算上效果更差一些。现在考虑将循环展开更多一些以及分块大小更大一些来提高优化效果。
将CPU循环展开为10,运行时间如下:

发现优化效果大大提升,现在再考虑将CPU循环展开为12,运行时间如下::,

发现优化效果又进一步提高,再将CPU循环展开为16,运行时间如下:

效果不是太好。所以CPU循环展开采取12。
接下来将分块大小调整为12*12,运行时间如下:

效果不好,将分块大小调整为16*16,运行时间如下:

效果不好,将分块大小调整为32*32,运行时间如下:

效果不是太好。所以分块大小采取8*8。
综上所述,CPU循环展开采取12,分块大小采取8*8可以取得比较好的效果。
4.5 还可以采取的进一步的优化方案(5分)
线程是计算资源的最小调度单位,也就是说,操作系统在分配计算资源时,是以线程为单位的,所以控制线程的数量和状态,就等于控制计算资源的分配和使用。 多线程和异步计算有紧密的联系,因为多线程的本质就是利用异步计算的方式,让多个线程在同一时间段内执行不同的任务,从而提高计算效率,一般能用异步计算的场景,都能用多线程来实现,反之亦然。而多线程加速也依靠异步计算的原理,利用多线程来同时处理多个任务,提高计算资源的使用率,也可以优化我们的程序,从而提高程序性能。

用如上命令检测逻辑核的个数,线程数最好不要超过这个数。
第5章 总结
5.1 请总结本次实验的收获
在实验实现了很多优化方案,对老师课上内容理解更透彻,掌握时间函数使用方法,提升数学思维,锻炼编程能力,了解了图像平滑算法。
5.2 请给出对本次实验内容的建议
暂无,感觉这次实验很充实。
参考文献
为完成本次实验你翻阅的书籍与网站等
[1] 林来兴. 空间控制技术[M]. 北京:中国宇航出版社,1992:25-42.
[2] 辛希孟. 信息技术与信息服务国际研讨会论文集:A集[C]. 北京:中国科学出版社,1999.
[3] 赵耀东. 新时代的工业工程师[M/OL]. 台北:天下文化出版社,1998 [1998-09-26]. http://www.ie.nthu.edu.tw/info/ie.newie.htm(Big5).
[4] 谌颖. 空间交会控制理论与方法研究[D]. 哈尔滨:哈尔滨工业大学,1992:8-13.
[5] KANAMORI H. Shaking Without Quaking[J]. Science,1998,279(5359):2063-2064.
[6] CHRISTINE M. Plant Physiology: Plant Biology in the Genome Era[J/OL]. Science,1998,281:331-332[1998-09-23]. http://www.sciencemag.org/cgi/ collection/anatmorp.