实验名称:朴素贝叶斯分类
实验目的:
1. 实现一个简单的朴素贝叶斯分类算法,包括先验概率和条件概率的计算。
2. 使用合适的数据集进行实验,可以选择经典的鸢尾花(iris)数据集或其他公开数据集。
3. 划分数据集为训练集和测试集,保证实验的可验证性。
4. 在训练集上训练朴素贝叶斯模型,计算各类别的先验概率和属性的条件概率。
5. 在测试集上评估朴素贝叶斯模型的性能,包括准确率、精确率、召回率等指标。
6. 分析实验结果,包括朴素贝叶斯模型的分类效果和对不同类别样本的预测性能。
实验步骤与要求:
1. 数据准备:导入数据集、数据预处理、划分数据集
2. 定义感知机模型:初始化参数:确定类别先验概率和属性条件概率
3. 训练模型:计算每个类别的先验概率和每个类别下的条件概率
4. 根据朴素贝叶斯公式进行分类预测
5. 可视化模型
6. 实验结果分析:分析朴素贝叶斯模型的分类效果,讨论其有效性
一.实验目的
朴素贝叶斯模型的简单性和高效性使其成为许多实际问题的首选方法之一,尤其是在数据量大、特征独立性高或需要快速原型开发的场景中表现突出。
1. 文本分类
朴素贝叶斯在文本分类中表现优异,常用于:
垃圾邮件过滤器:区分垃圾邮件和非垃圾邮件。
情感分析:判断文本是正面、负面还是中性情感。
新闻分类:将新闻文章归类到不同的类别(例如政治、体育、科技)。
2. 信息检索与推荐系统
朴素贝叶斯可以用于信息检索和推荐系统中:
信息检索:根据用户的查询将文档进行排序和推荐。
产品推荐:基于用户历史行为和偏好推荐相关产品或服务。
3. 医学和生物信息学
在医学和生物信息学领域,朴素贝叶斯常用于:
疾病诊断:基于患者的症状数据预测可能的疾病。
基因组学:分析基因数据,识别与疾病相关的基因组特征。
4. 金融领域
在金融领域,朴素贝叶斯可以应用于:
信用风险评估:根据借款人的个人信息和信用历史预测其违约风险。
欺诈检测:识别可能的欺诈交易或行为。
5. 社交网络分析
在社交网络分析中,朴素贝叶斯可用于:
用户分类:将用户分为不同的群体或社区。
影响力分析:识别在社交网络中具有影响力的用户或内容。
6. 其他领域
朴素贝叶斯还可以应用于许多其他领域,如环境科学(例如气象预测)、工业过程控制、客户关系管理(CRM)等,只要问题能够被表达为特征之间条件独立的形式,朴素贝叶斯就可以成为一个强大的工具。
二.实验步骤
- 导入必要的库和模块
在代码中导入需要的库和模块,例如 pandas 用于数据处理,sklearn 中的朴素贝叶斯模型和评估函数等。
2. 数据加载与预处理
加载数据集并进行必要的预处理,例如将分类标签编码(如果是字符串),划分训练集和测试集。
3. 模型训练与预测
实例化朴素贝叶斯模型(例如高斯朴素贝叶斯),并在训练集上进行训练,然后在测试集上进行预测。
4. 模型评估
使用适当的评估指标来评估模型性能,最常见的是准确率 accuracy_score。
5. 结果分析和优化
分析模型的表现,可以考虑调整模型参数、特征工程或使用其他评估指标(如精确率、召回率等),以进一步优化模型。
6. 应用与部署
根据实验结果,将模型部署到实际应用中,或者进一步迭代和改进模型。
三.实验结果分析
- 结果展示
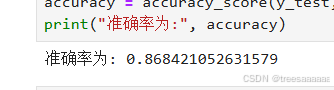
2.结果分析
1. 参数设置和调整
平滑参数 (1e-9): 在计算条件概率时,使用了一个很小的平滑参数 1e-9,这是为了避免概率为零的情况,以防止出现无限大的对数值。这个值的选择可能会影响模型的准确性和稳定性,可以尝试不同的值来优化模型的性能。特征处理: 对于特征的处理方式是关键。当前的代码中并未进行特征缩放或其他预处理步骤,这在某些机器学习算法中可能会影响性能。可以考虑添加特征缩放或标准化等预处理步骤,以确保不同特征的尺度不会影响模型的计算。
2. 实验结果和性能分析
准确率评估: 通过使用 accuracy_score 函数计算了模型在测试集上的准确率。这个指标反映了模型预测的准确程度,但是在实际应用中,可能需要考虑其他评估指标,如精确率、召回率、F1 分数等,特别是在类别不平衡的情况下。
模型泛化能力: 考虑模型在未见过的数据上的表现,即模型的泛化能力。可以通过交叉验证或者其他评估方法来评估模型在不同数据集上的表现,以确定模型是否过拟合或欠拟合。
3. 应用场景
朴素贝叶斯模型在实际中有许多应用场景,尤其是在文本分类、垃圾邮件过滤、情感分析等领域中,常常表现出色。具体的应用包括但不限于:
- 文本分类: 判断一段文本属于哪个类别,如垃圾邮件分类、新闻分类等。
- 情感分析: 分析文本中的情感倾向,如正面、负面、中性情感。
- 医学诊断: 利用病历信息进行疾病分类或者预测患病风险。
- 金融欺诈检测: 根据客户的交易信息来判断是否存在欺诈行为。
四.源代码
import math
from collections import Counter
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
class NaiveBayes:
def __init__(self):
self.classes = None
self.priors = None
self.conditionals = None
def fit(self, X, y):
# 获取类别数量
self.classes = set(y)
num_classes = len(self.classes)
# 计算先验概率
self.priors = {}
for c in self.classes:
self.priors[c] = sum(1 for label in y if label == c) / len(y)
# 计算条件概率
self.conditionals = {}
for c in self.classes:
# 获取属于该类别的样本
class_samples = X[y == c]
# 计算每个特征的条件概率
self.conditionals[c] = []
for i in range(X.shape[1]):
feature_samples = class_samples[:, i]
counts = Counter(feature_samples)
total = sum(counts.values())
probs = {value: (count / total) for value, count in counts.items()}
self.conditionals[c].append(probs)
def predict(self, X):
# 预测样本的分类
predictions = []
for sample in X:
posteriors = {}
for c in self.classes:
# 计算后验概率
posterior = math.log(self.priors[c])
for i, value in enumerate(sample):
likelihood = self.conditionals[c][i].get(value, 1e-9)
posterior += math.log(likelihood)
posteriors[c] = posterior
prediction = max(posteriors, key=posteriors.get)
predictions.append(prediction)
return predictions
# 加载 iris 数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 创建朴素贝叶斯分类器
nb = NaiveBayes()
# 训练模型
nb.fit(X_train, y_train)
# 预测测试集
y_pred = nb.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率为:", accuracy)