pandas学习-Series-01
文章目录
什么是pandas
pandas是一个数据处理的python 包,无论是数据分析,还是数据科学都离不开pandas
- 主要还是处理结构化的数据
- 数据清理
- 数据合并,整合多个不同的数据源转换输出一个
- 数据分析
- 读取多种结构的数据
为什么要用pandas
虽然我们已经有了Excel和SQL这两种强大的数据处理工具,但Pandas在Python生态系统中提供了以下优势,使得它在许多数据分析场景下成为理想的选择:
- Pandas具有高度灵活和可扩展的API,支持复杂的数据清洗、转换、分析流程,并且这些流程可以通过编写脚本或程序的形式自动化执行,大大提高了工作效率。
- Pandas可以方便地读取和写入各种数据格式,包括CSV、Excel、SQL数据库、JSON、HDF5等,以及直接从Web API获取数据,这使其成为一个统一的数据接口层。
- 在Python的机器学习和数据科学领域,Pandas是Scikit-learn、TensorFlow、PyTorch等框架广泛使用的底层数据结构,可以直接将预处理后的Pandas DataFrame传递给模型训练。
pandas的两种数据结构
series 结构
它是一个一维数组对象,可以存储任何数据类型(整数、浮点数、字符串、Python对象等)的数据。每个元素在Series中都有一个对应的标签(index),类似于有序字典或带有标签的一维数组。

dataframe 结构
dataFrame是Pandas更复杂也更常用的数据结构,它可以看作由多个Series组成的二维表格型数据结构,每一列都是一个Series,所有Series共享同一个行索引。dataFrame允许每列的数据类型不同,非常适合处理具有混合类型的结构化数据。
Series学习
下面我将用一个具体的列子来说明series的一些用法,学习series的一些基本用法
前提:
- 已经完成pandas、juputer notebook的安装
背景:
我们有以下部分手机的价格,现在我们要基于以下数据来进行一些数据处理工作。
| 手机名称 | 价格(人民币 |
|---|---|
| OnePlus 11 Pro Max | 4999 |
| Xiaomi Mi 14 Ultra | 5499 |
| Samsung Galaxy S23 Ultra | 7999 |
| Apple iPhone 15 Pro Max | 8999 |
| Google Pixel 8 Pro | 8999 |
| Huawei Mate 60 Pro+ | 6999 |
| Vivo X90 Pro+ | 6499 |
| Oppo Find X6 Pro | 5999 |
| Realme GT Neo5 Ultimate Edition | 5699 |
| Lenovo Legion Y90 Gaming Phone | 3999 |
Series的创建:
1.我们如何用以上数据读入pandas,并存储为 series格式?
import pandas as pd
s=pd.Series([4999,5499,7999,8999,8999,6999,6499,5999,5699,3999],
index=['OnePlus 11 Pro Max','Xiaomi Mi 14 Ultra','Samsung Galaxy S23 Ultra','Apple iPhone 15 Pro Max','Google Pixel 8 Pro','Huawei Mate 60 Pro+','Vivo X90 Pro+','Oppo Find X6 Pro','Realme GT Neo5 Ultimate Edition','Lenovo Legion Y90 Gaming Phone']
,name='phone_price')
s
输出:

通过上述举例我们创建一个series,下面就Series的创建进行学习 。
import pandas as pd
pd.Series(data, index, dtype,name="A name")
从上面的语法我们可以看出 Series主要有三部分组成
- data: 我们从上面的图可以知道Series就相当于一维数组,所以 data就是我们的值,这儿需要注意一点的是 这个data是强类型的,所以data中存储的数据类型建议一致,不一致,pandas会根据我们的值自动推断dtype ,但这个推断动作肯定有代价的!
- index:就是我们每个值的标签,我们可以通过标签去引用data中的值,当我们不指定时候,pandas会创建默认的序列。
- dtype: 这也是一个可选参数,用于指定 series中的data中的数据类型,如果我们不指定,pandas也会自动推断其数据类型(我们在上面列子就没有指定)
- name:可以先简单的看成是Series的列名,当然name也可以不指定。

空的 series
import pandas as pd
s1 = pd.Series(dtype='float64') # 创建一个空的浮点型 Series
s2=pd.Series() #报警提示 FutureWarning: The default dtype for empty Series will be 'object' instead of 'float64' in a future version. Specify a dtype explicitly to silence this warning.
s2.info # <bound method Series.info of Series([], dtype: float64)>
注意:创建空的series指定时候,建议指定dtype否则会报警告,当然从上面的提示可知,在以后的pandas版本中,pandas生成空的series中会用
object替换到现在默认的float64
series的一些基本属性
一旦我们完成了series的创建,我们就可以获取series的一些基本属性
.values获取series中的value值.index获取series中的index.name获取series的名字.dtype获取series 值的类型.sizeseries中值的个数。

Series的筛选
Q: 我们如何查看Apple iPhone 15 Pro Max的价格?
A:
iphone_price=s.loc['Apple iPhone 15 Pro Max']
iphone_price

知识引入:
其实series主要可以通过两种方式来筛选我们的数据,第一种是 index方式筛选,第二种就是位置筛选。
index方式筛选
主要是通过·loc[]来实现,我们上面的列子就是通过该种方式来实现,当然我们以可以直接通过s['Apple iPhone 15 Pro Max']
来解决上面的问题,但是我们还是更加推荐.loc[]的方式。
那是因为`[]`这种直接使用很容易造成混乱,series中还好,但如果是dataFrame,直接使用 [] 进行行选择可能会由于隐式行为导致意外的结果。
位置筛选
位置筛选主要通过iloc[]来实现,之所以可以采取这种方式,那是因为series是有序的。当然这里的位置起始也与数组一样从零开始的
比方说,我们获取上述表格第1个手机的价格
number_1_price=s.iloc[0]
number_1_price

当然,无论是loc[]方式,还是 iloc[]方式其实都支持多个选择的。
phones=s.loc[['Apple iPhone 15 Pro Max','Huawei Mate 60 Pro+']]
phones

这儿要注意的是,多重选择时候,loc里面是传入的数组
.loc[[]],而且返回的也是一个series类型
iloc当然也支持切片的方式。
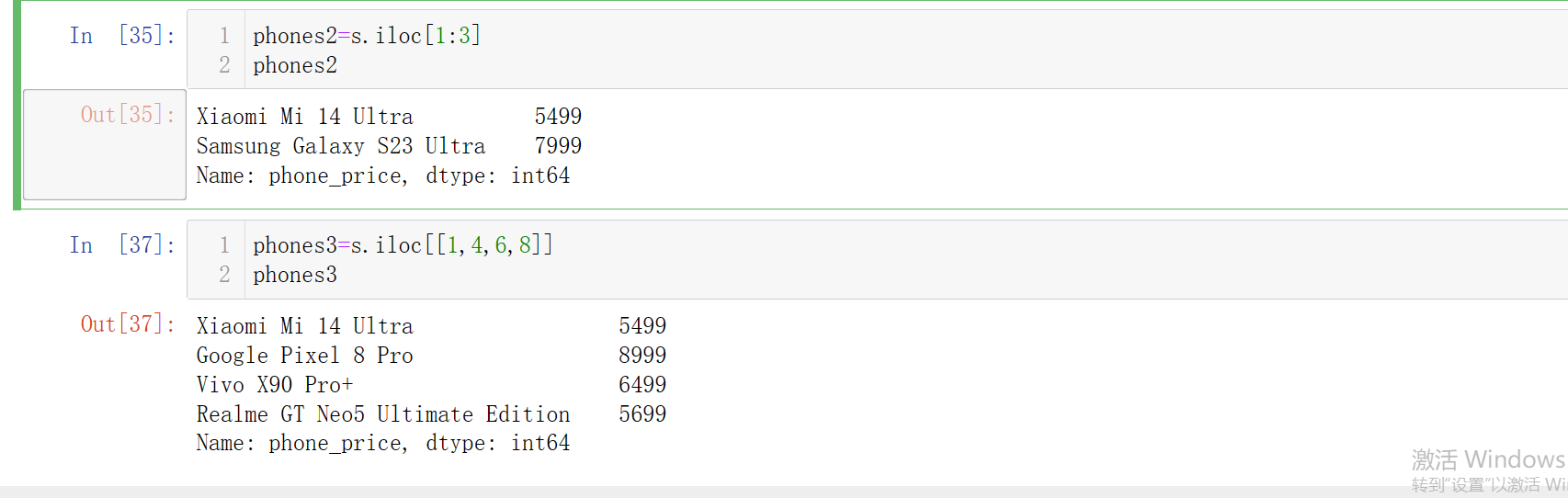
phones2=s.iloc[1:3]
phones2
phones3=s.iloc[[1,4,6,8]]
phones3
Series的常用方法
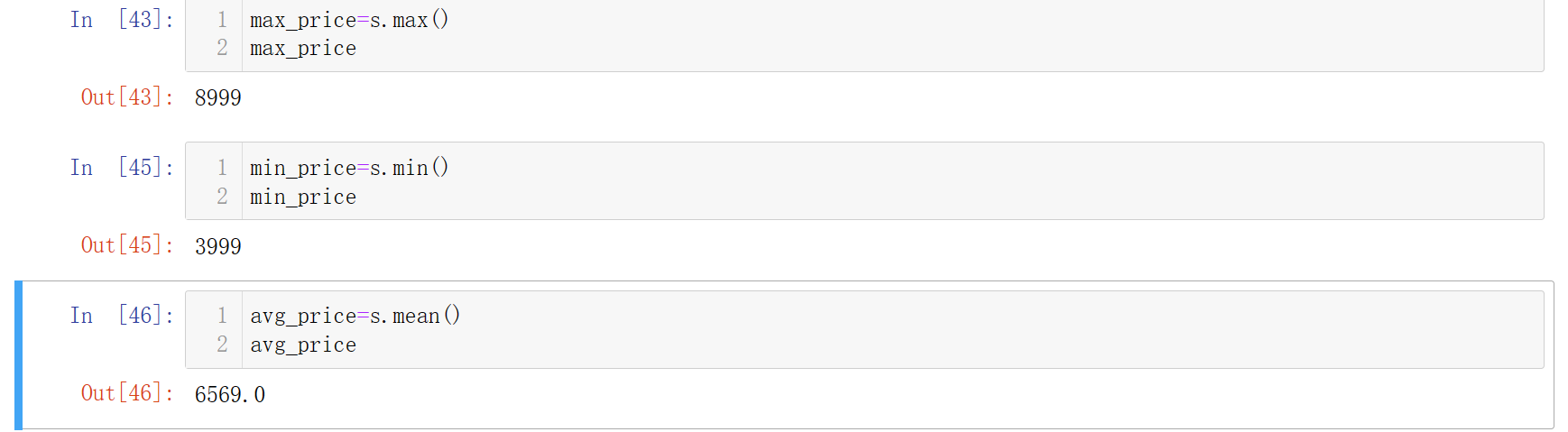
Q:如何获取最高的手机价格?最低价格?价格的平均数?价格排名前三的手机是那几个?
A-1: 最高手机价格,最低手机价格,价格的平均数
A-2:价格排名前三的手机

series中有一些非常有用的方法,通过这些方法我们可以很方便的进行数据分析,像比较常用的head() tail()
这两个方式认默认返回Series或DataFrame对象开头或结尾的5个元素(行),当然我们亦可以自定义要显示的行数,例如,series.head(3)将显示前三行。
当然series也内置了一些统计类方法,通过这些统计类方法我们可以很容易进行数据分析。
-
基本统计量:
series.mean(): 计算Series所有非缺失值(NaN除外)的平均数。series.median(): 计算Series所有非缺失值的中位数。series.mode(): 返回Series中出现次数最多的元素及其频率(如果有多个,则返回所有)。series.min(): 找到Series中的最小值。series.max(): 找到Series中的最大值。series.sum(): 计算Series所有非缺失值的总和。series.std(): 计算Series所有非缺失值的标准差。series.var(): 计算Series所有非缺失值的方差。
-
计数与唯一性:
series.count(): 返回Series中非缺失值的数量。series.nunique(): 返回Series中不重复值的数量
-
排序相关:
series.sort_values(ascending=True): 对Series进行按值升序排列,默认为True;若设置为False,则降序排列。series.sort_index(ascending=True):对 Series按照index升序排列,默认为True;若设置成False ,则降序排列。series.idxmax(): 返回Series中最大值对应的index。series.idxmin(): 返回Series中最小值对应的index。
我们也可以使用 series.describe() 来实现一个方法综合展示以下几个统计类信息,这个方法对于快速了解Series数据集的整体分布特征非常有用。
- count:非缺失值(不包括NaN)的数量。
- mean:所有非缺失值的平均数。
- std:所有非缺失值的标准差,衡量数据的离散程度。
- min:Series中的最小值。
- 25%、50%、75%:四分位数,分别代表数据分布中25%、50%和75%位置上的数值,其中50%即为中位数。
- max:Series中的最大值。
Q:如何获取价格最高的手机是哪个?价格最低的手机是哪个?

Series 的算式运算
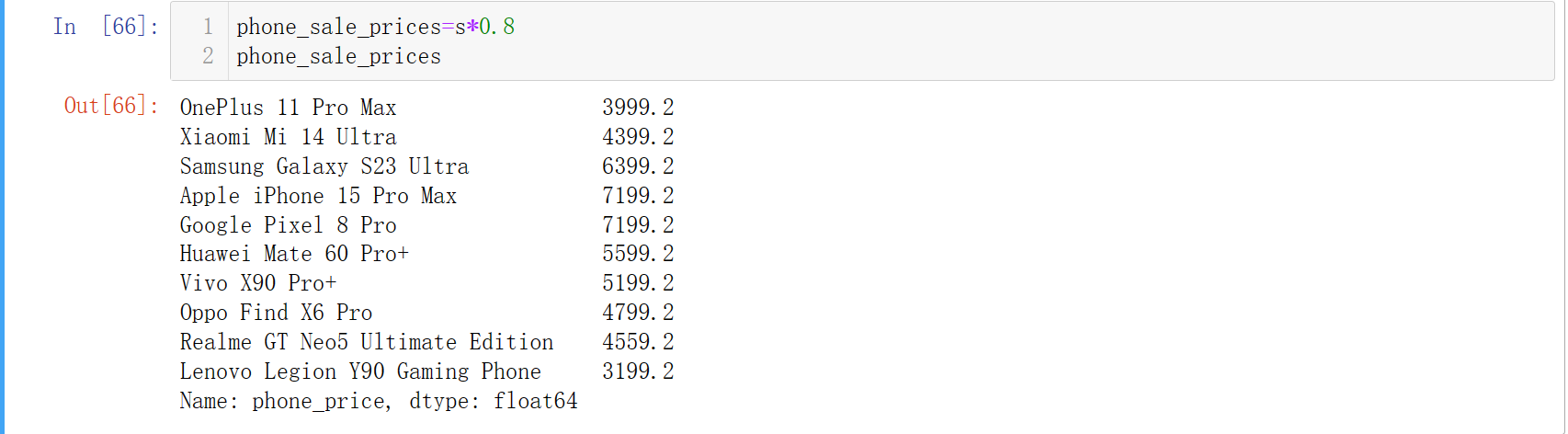
Q:现在双十二,所以手机都有折扣,都打八折,请问现在的手机价格是多少?那如果每个手机打折的力度不一样,又怎么用pandas实现?
A:
所有手机打八折,现在最新的价格:
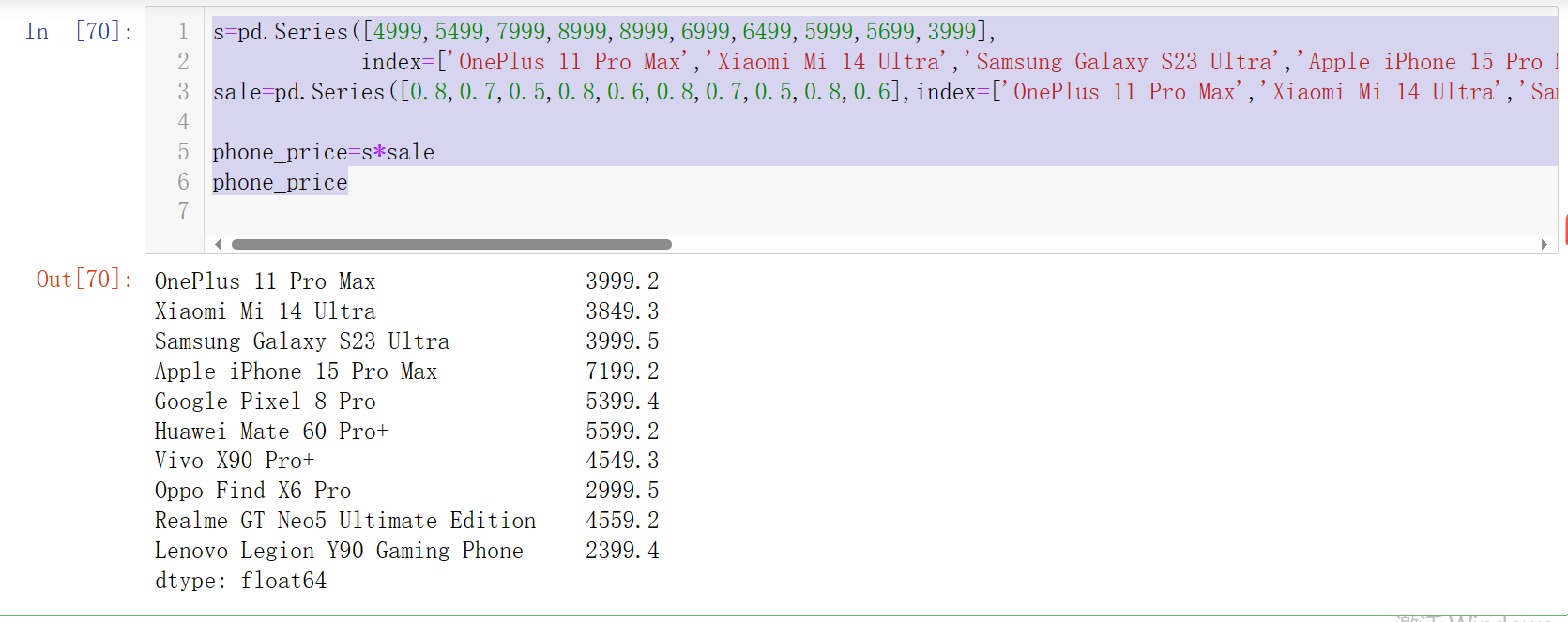
每种手机打折的力度不一样,实现:
s=pd.Series([4999,5499,7999,8999,8999,6999,6499,5999,5699,3999],
index=['OnePlus 11 Pro Max','Xiaomi Mi 14 Ultra','Samsung Galaxy S23 Ultra','Apple iPhone 15 Pro Max','Google Pixel 8 Pro','Huawei Mate 60 Pro+','Vivo X90 Pro+','Oppo Find X6 Pro','Realme GT Neo5 Ultimate Edition','Lenovo Legion Y90 Gaming Phone'],name='phone_price')
sale=pd.Series([0.8,0.7,0.5,0.8,0.6,0.8,0.7,0.5,0.8,0.6],index=['OnePlus 11 Pro Max','Xiaomi Mi 14 Ultra','Samsung Galaxy S23 Ultra','Apple iPhone 15 Pro Max','Google Pixel 8 Pro','Huawei Mate 60 Pro+','Vivo X90 Pro+','Oppo Find X6 Pro','Realme GT Neo5 Ultimate Edition','Lenovo Legion Y90 Gaming Phone'],name='phone_sale')
phone_price=s*sale
phone_price
知识扩展:
其实在Pandas的Series中,我们可以进行基本的算术运算,包括加法(+)、减法(-)、乘法(*)和除法(/)。这些运算可以是Series与Series之间的操作,也可以是Series与其他标量值(如整数、浮点数或Python数值类型)之间的运算。以下是基本的使用示例:
s1 = pd.Series([1, 2, 3, 4]) #不指定index 会生成 一个默认index [0,1,2,3]
s2 = pd.Series([5, 6, 7, 8]) #不指定index 会生成 一个默认index [0,1,2,3]
result_add = s1 + s2 # Series间的加法
pd.Series.concat(s1,s2) # 等价于Series间的加法
result_subtract = s1 - s2 # Series间的减法
result_multiply = s1 * s2 #Series间的乘法
result_divide = s1 / s2 #Series间的除法
result_add_scalar = s1 + 1 #Series 加上一个常量
result_multiply_number=s1*0.11 #Series 乘上一个常量
当然,以上的举得列子太完美了,两个Series长度相同,索引也一样,我们都知道了会逐元素进行相应的运算,并返回一个新的Series,但当我们Series长度相同,索引也不一样,会怎么样呢?



结论:只会对共享索引的位置进行计算,对于关联不上的索引会给一个默认空值(NaN),当进行除法运算时,如果分母包含0值,会导致inf默认值的出现。
Series的变与不变
关于Series 的一些其他补充:
我们在上面以10种手机的价格为列,完成了 Series对象s的创建,并针对其进行了一系列的操作。但我们要强调一点,尽量不要去修改原有的Series,尽量保持原Series只读。我们针对 series 上的一些方法,跟加减乘除,其实并没有修改原来的Series 对象,而仅仅是生成了一个新的Series对象。
当然,我们通过一些方法,也是可以去修改原来的series对象 ,但这些方法我们基本不怎么使用。
- 更新
series中的值
s[index]=new_value
s['Xiaomi Mi 14 Ultra']=2999
- 删除series中的值
del s[index]
del s['Samsung Galaxy S23 Ultra']