Pandas -dataframe学习-01
前提
已经完成了Series 相关知识学习。
dataframe是什么
DataFrame 是 pandas 库中的一种数据结构,它是 Python 中用于数据分析、处理和存储表格型数据的核心组件。DataFrame 可以被形象地理解为一个二维表格,它既有行索引也有列标签,并且每一列可以包含不同类型的数据(如整数、浮点数、字符串等)。
在 DataFrame 中,每行代表一个观察样本或记录,而每列则表示一个特定的变量或特征。这种结构使得 DataFrame 成为了处理和分析结构化数据的理想工具,例如在统计分析、机器学习以及商业智能应用中非常常见。
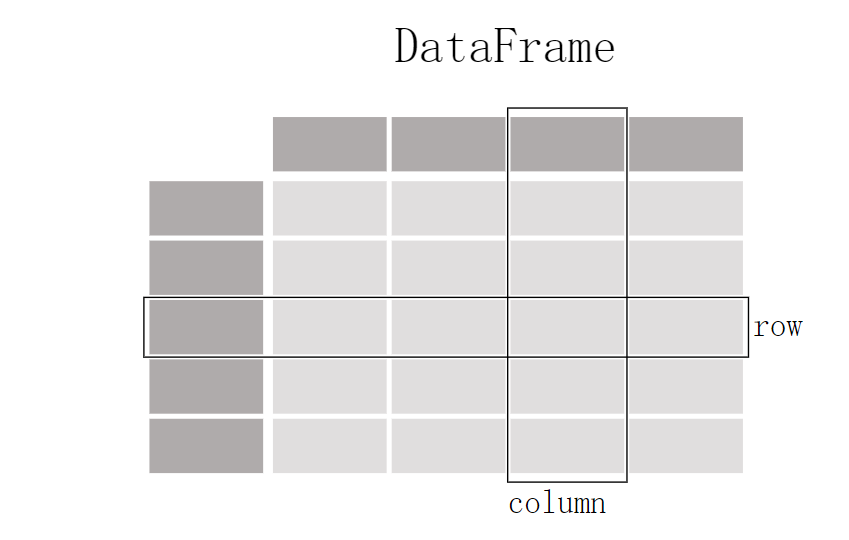
dataframe与Series关联
- DataFrame是Pandas中更复杂、二维的数据结构,可以理解为多个Series对象的集合。
- DataFrame由列组成,每一列都是一个Series,具有相同的行索引。因此,DataFrame实质上可以看成许多Series列按照共享的索引堆叠在一起形成的。
如何获取数据
在我们的实际中我们往往更多的需要读取外部文件并将数据读入我们的pandas中,存储为dataFrame格式分析。
Q:我们如何获取我们的数据
A:各城市都有免费的数据开发平台,我们可以通过开放平台获取我们需要的数据,而且数据格式支持xlsx、xml、csv、json等多种格式。
本次我们就去成都市公共数据开发平台下载了一份成都市税务局的双公示_行政处罚文件,并将下载的数据上传到jupyter上。
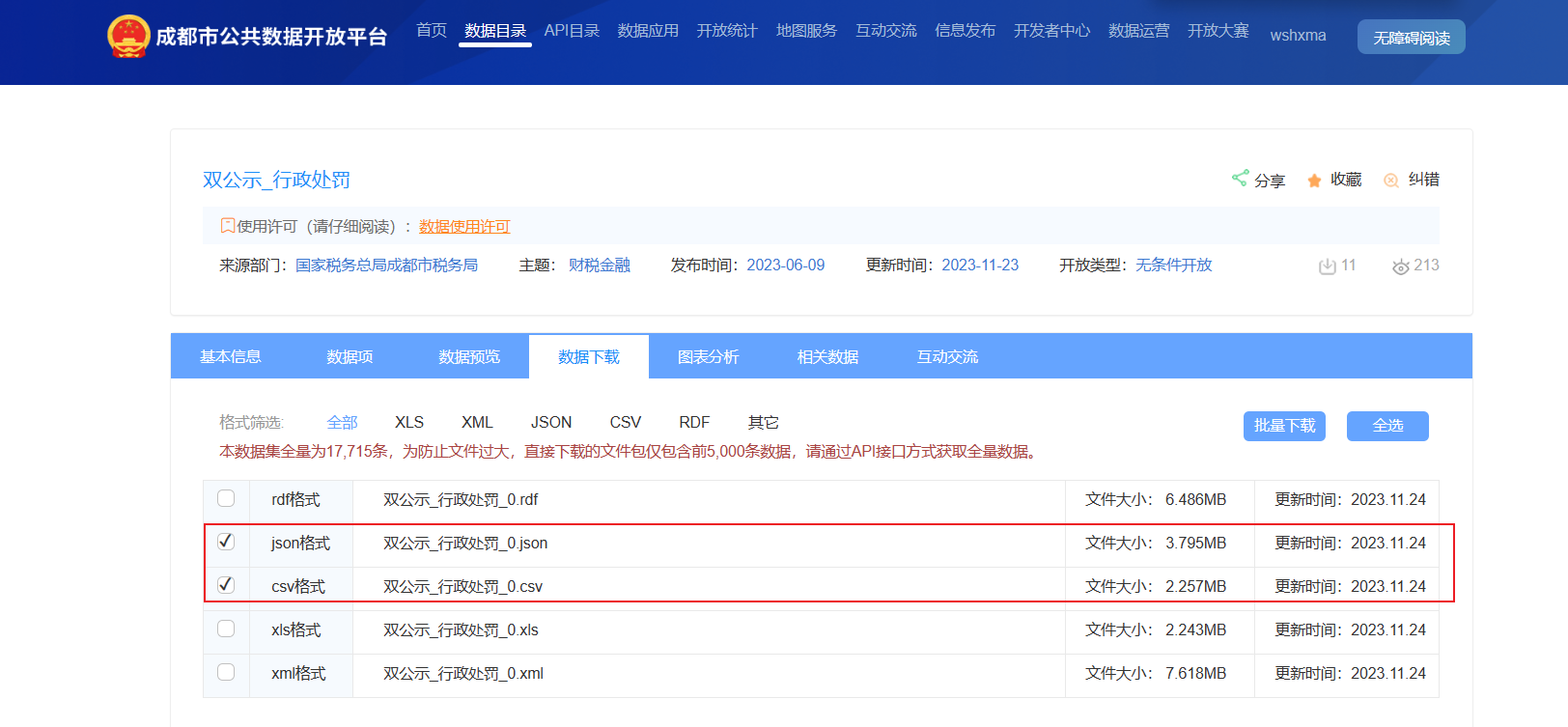
Q:我们下载数据后怎样把数据用我们Pandas dataFrame存储呢?
A:
我们可以通过pd.read_xxx('')的方式把我们的数据载入进我们的pandas中。
因为下载的csv文件是gbk编码,所以再读取文件类型时候需指定文件编码,否则与jupyter默认的utf-8编码冲突,读取时候报
UnicodeDecodeError错误
pandas文件的载入
当然pandas 正如下图所示,pandans支持多种数据源的读取,我们在读取数据源的时候可以通过 pd.read_xxx()这种格式实现数据的读入。
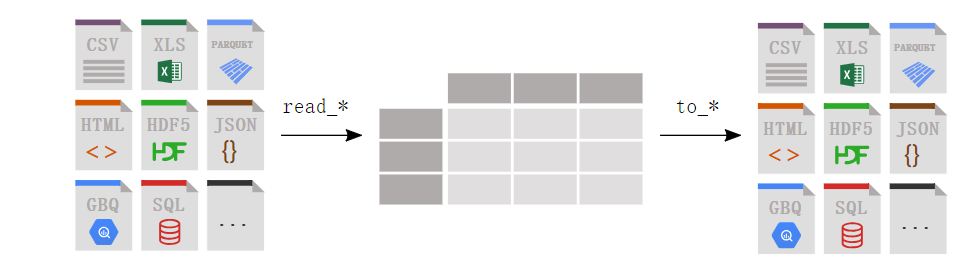
例如上面我们就是用了最基本的csv文件
csv读取示例:
# 带参数的例子,包括指定分隔符、跳过某些行、指定列名等
df_csv_advanced = pd.read_csv(
'data.csv',
sep=';', # 分隔符,默认是逗号 ','
header=0, # 表头行,默认为0(第一行),也可以设置为 None 表示无表头
names=['A', 'B', 'C'], # 自定义列名
skiprows=[1], # 跳过指定行数(从0开始计数)
index_col='A' # 将某一列作为索引列
)
# 如果文件不是 UTF-8 编码,需指定 encoding 参数
df_csv_encoding = pd.read_csv('data.csv', encoding='gbk')
excel读取示例:
# 读取 Excel 文件,默认读取第一个工作表
df_excel = pd.read_excel('data.xlsx')
# 指定工作表名称或索引编号
df_excel_sheet = pd.read_excel('data.xlsx', sheet_name='Sheet2')
# 使用 openpyxl 引擎并指定其他参数
df_excel_advanced = pd.read_excel(
'data.xlsx',
sheet_name='Sheet1',
engine='openpyxl', # 引擎选项:openpyxl, xlrd 等
na_values=['N/A'] # 指定哪些值应视为缺失值
)
json读取示例:
# 读取本地 JSON 文件,默认 orient 参数为 'columns'(适用于记录型数组)
df = pd.read_json('data.json')
# 如果 JSON 文件中的数据结构不同,可能需要调整 orient 参数:
# - 'records':适合每行是一个对象的 JSON 数组
# - 'split':键在列中,值在行中
# - 'index':索引是 JSON 对象的键,值是 Series
# - 'values':只包含一维数组(如 CSV 样式的扁平化数据)
df_records = pd.read_json('data.json', orient='records')
例如我们可以读取双公示_行政处罚_0.json文件
with open('./双公示_行政处罚_0.json','r',encoding='utf-8') as f:
content=f.read()
json_str = content.split('\n') # 直接下载的json文件中有两个json数组,一个是表头,一个是数据
col_json=json_str[0]
data_json=json_str[1]
df_col=pd.read_json(col_json)
df_data=pd.read_json(data_json)
df_data

这儿要注意哈直接下载的这个json文件,其实是由表头跟数据两个json数组成的,而
pd.read_json()一次性只能读取单个的 JSON 对象或数组,所以我们要拆解哈,分开读取哦。
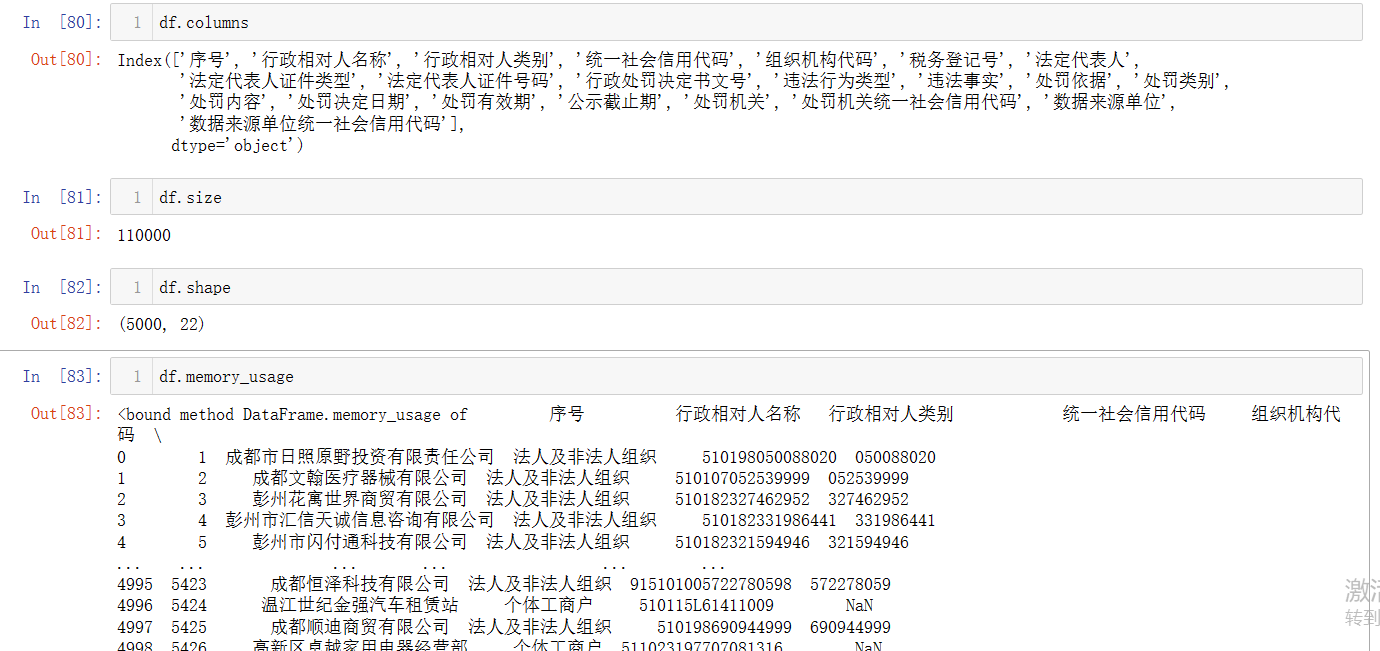
dataFrame的属性
当然我们把数据存为dataFrame我们就可以像sereis一样,得到它的一些基本属性,这儿我们再把series的属性列举哈,与dataFrame做个对比。
Series基本属性:
.values获取series中的value值.index获取series中的index.name获取series的名字.dtype获取series 值的类型.sizeseries中值的个数。
dataFrame的基本属性:
-
.values:返回包含 DataFrame 中所有数据的 NumPy 数组。 -
.index:返回一个包含所有行索引的 Index 对象。 -
.columns:返回一个包含所有列名的 Index 对象。 -
.dtypes:返回一个 Series,其中显示了每列的数据类型。 -
.size:DataFrame 的总元素数量,相当于.shape属性两个数值的乘积。 -
.shape:返回一个包含行数和列数的元组(行数, 列数)。 -
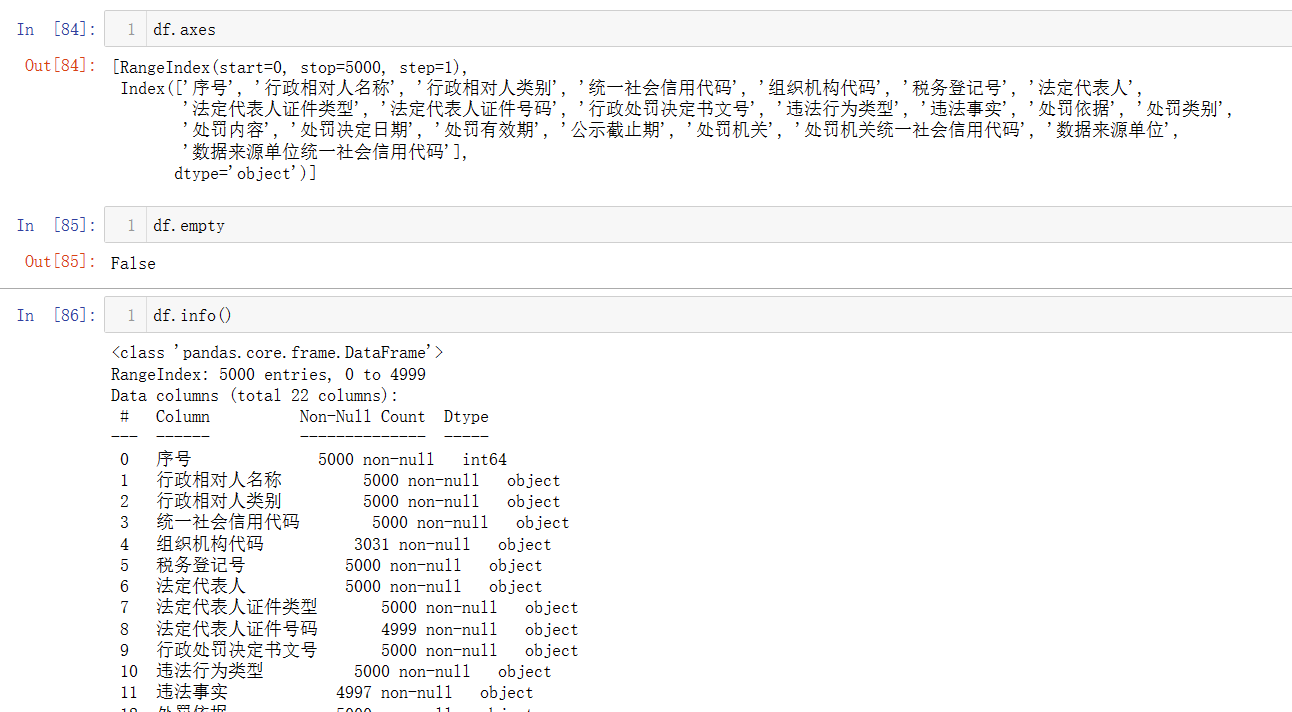
.axes:返回一个包含行索引、列标签以及它们各自的名称的元组(Index, Index)。 -
.empty:布尔值,表示 DataFrame 是否为空(即无任何数据)。 -
.ndim:返回 DataFrame 的维度,对于 DataFrame 总是 2。 -
.memory_usage:返回 DataFrame 占用内存的大小(以字节为单位),可选包括索引或不包括索引。
使用时可以根据这些属性来了解 DataFrame 的结构、内容及占用资源情况。
我们通过对比,可以发现,series有的属性,当然dataFrame也有,但dataFrame要比Series多一维,所以 多了一些获取二维信息的属性(columns、shape、axes)
dataFrame查询
index方式查询
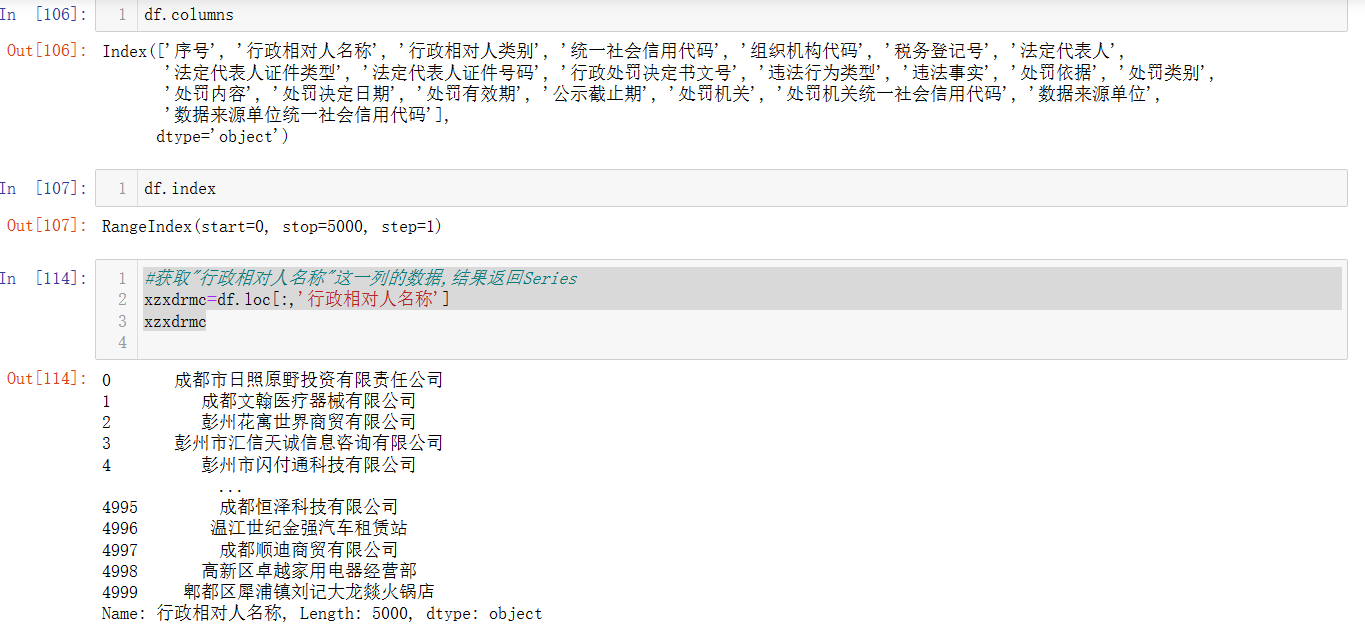
Q:我们如何按我们想要的方式查询?如只想查询指定列?查询指定行?查询指定的每个单元格值?
A:
#获取"行政相对人名称"这一列的数据,结果返回Series
xzxdrmc=df.loc[:,'行政相对人名称']
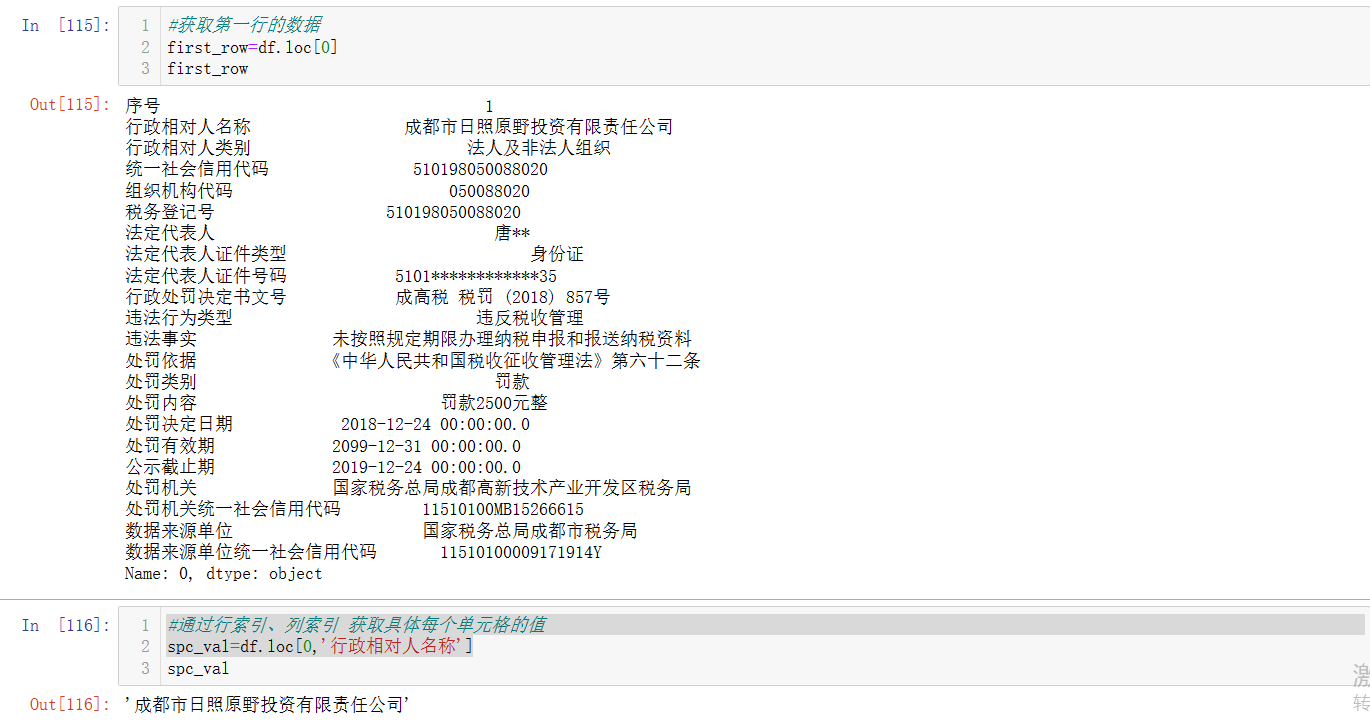
#获取第一行的数据
first_row=df.loc[0]
#通过行索引、列索引 获取具体每个单元格的值
spc_val=df.loc[0,'行政相对人名称']
这儿我们没有指定dataframe的行索引,所以默认行索引就是一个数字序列。
pandas 中,df.loc[] 是一个用于基于标签(索引)进行数据选取的方法。可以通过 df.loc实现按列、行查询,其查询方式类似于excel的处理方式。
df.loc['row_index','col_index'] #查询具体某个单元格的值
df.loc['row_index'] #查询某行的值
df.loc[:,'col_index'] #查询某列的值
需要注意的是。
df.loc[row_indexer, column_indexer]的语法中,冒号:是一种快捷方式,用来选取一个连续的全部区间,上面的:表示选择所有行(即行索引的所有值)。
通过上面的列子我们知道可以通过之前 的.loc[]方法来实现按行查询,按列查询,按单元格位置查询,当然df.loc[]也是支持多行多列查询的。
df.loc[[0,1,2]] #查询1、2、3行的数据
df.loc[:,['行政相对人名称','行政相对人类别']] #查询2,3列的数据
df.loc[[0,1],['行政相对人名称','行政相对人类别']] #查询某1,2行,2,3列的数据
位置方式的查询
dataframe与Series一样也是支持位置查询的,我们通过iloc[] 可以选取 DataFrame 中的数据子集,不过它是根据行号和列号来定位数据。
df.iloc[row_indexer, column_indexer]
row_indexer:指定要选择的行的位置,可以是一个整数、切片对象、列表。column_indexer:指定要选择的列的位置,同样可以是一个整数、切片对象、列表。
示例用法:
-
单个值:
- 获取第一行第一列的值:
df.iloc[0, 0] - 获取第三行第四列的值:
df.iloc[2, 3]
- 获取第一行第一列的值:
-
切片:
- 获取前两行的所有列:
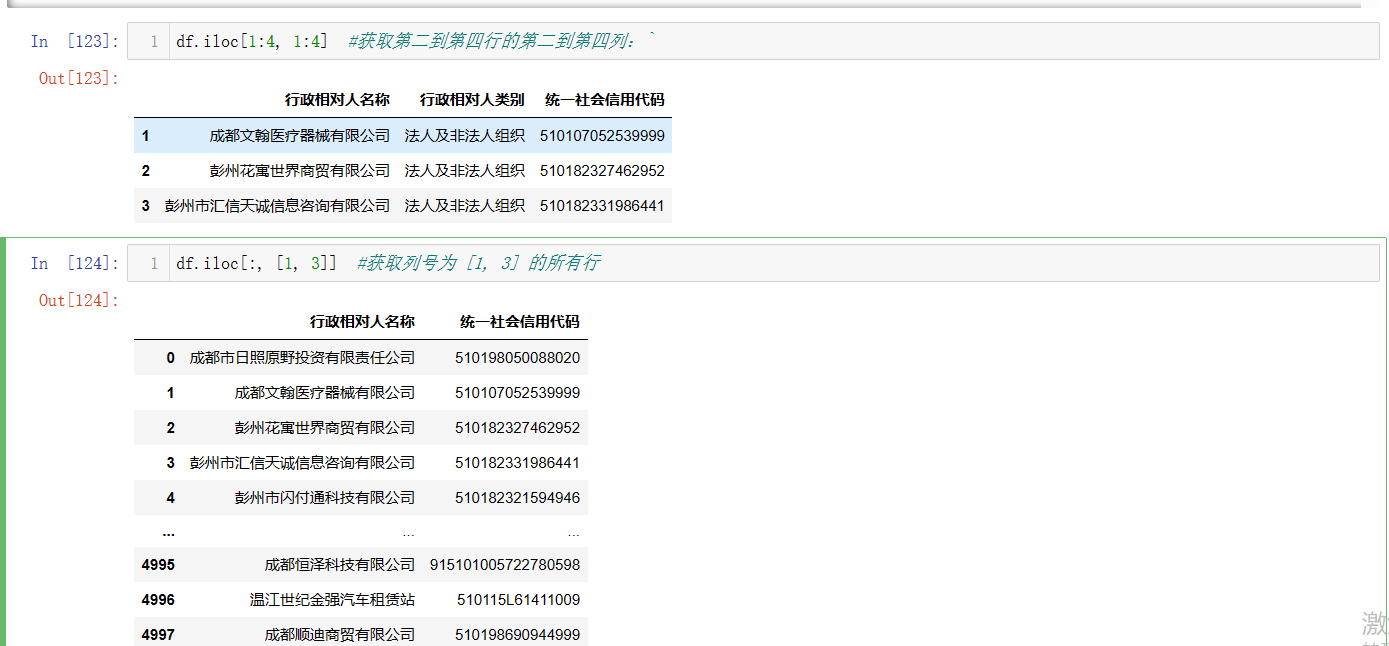
df.iloc[:2, :] - 获取第二到第四行的第二到第四列:
df.iloc[1:4, 1:4]
- 获取前两行的所有列:
-
列表:
- 获取行号为 [0, 2, 5] 的所有列:
df.iloc[[0, 2, 5], :] - 获取列号为 [1, 3] 的所有行:
df.iloc[:, [1, 3]]
- 获取行号为 [0, 2, 5] 的所有列:
在使用iloc有以下几点需要注意
iloc的索引是从 0 开始的,也就是说第一行是 0,第一列也是 0。- 当传入负数时,
iloc将从后向前计数,例如-1表示最后一行/列。 - 如果传入的索引超出实际范围,将会抛出
IndexError异常。
按值查询
Q:以上我们都是具有dataframe的位置、标签查询。但我们在实际使用更多的是根据值做查询?那我们如何实现?
1.布尔查询我们在pandas-Series学习-02已经学习了什么是布尔查询与基本用法,。dataFrame中当然也可以直接使用。
1.单条件查询
#查询行政相对人名称 为 成都市日照原野投资有限责任公司的记录
df[df['行政相对人名称']=='成都市日照原野投资有限责任公司']
#仅仅查询成都市日照原野投资有限责任公司的名称,处罚类别、处罚内容
df[df['行政相对人名称']=='成都市日照原野投资有限责任公司'].loc[:,['行政相对人名称','处罚类别','处罚内容']]

2.多条件查询
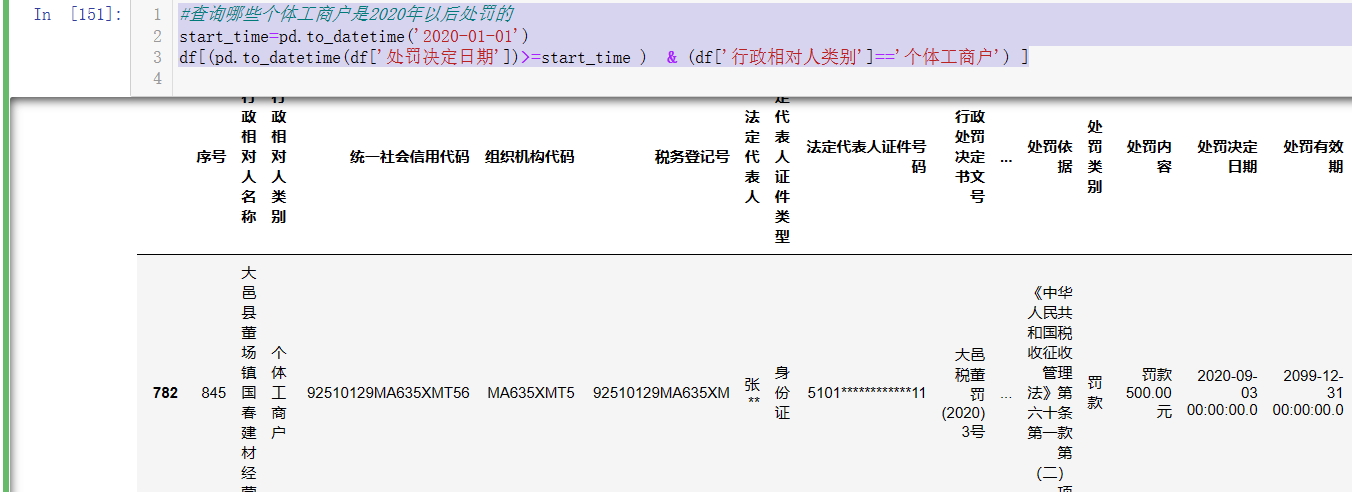
#查询哪些个体工商户是2020年以后处罚的
start_time=pd.to_datetime('2020-01-01')
df[(pd.to_datetime(df['处罚决定日期'])>=start_time ) & (df['行政相对人类别']=='个体工商户') ]
“&” 表示逻辑与操作,"| "表示逻辑或操作。注意:必须用括号将每个条件包裹起来以确保正确的优先级。
这儿我们将我们的处罚决定日期转成 日期格式,并通过日期进行比较,在pandas我们主要通过datetime 类型来处理日期和时间。
而通过字符串转成datetime主要通过pd.to_datetime()来实现。这个函数可以解析各种格式的日期时间字符串,并将其转换为 datetime 类型。
基本示例:
# 假设有一个包含 'date_str' 列的 DataFrame,该列存储的是日期字符串
df = pd.DataFrame({
'date_str': ['2021-01-01', '2021-02-02', '2021-03-03']
})
# 将 'date_str' 列转换为 datetime 类型
df['date'] = pd.to_datetime(df['date_str'])
# 如果字符串中的日期格式不是默认的 ISO 8601 格式(YYYY-MM-DD),则需要明确format 参数指定日期格式
df['date'] = pd.to_datetime(df['date_str'], format='%Y-%m-%d')
3. 使用 isin() 查询:
Q:上面的处罚名单中,我想查询’成都文翰医疗器械有限公司’,‘成都齐鸿源科技有限公司’,‘彭州市闪付通科技有限公司’ 这三家公司的行政处罚情况。
A:
comp_list=['成都文翰医疗器械有限公司','成都齐鸿源科技有限公司','彭州市闪付通科技有限公司']
df[df['行政相对人名称'].isin(comp_list)]
4.空值查询:
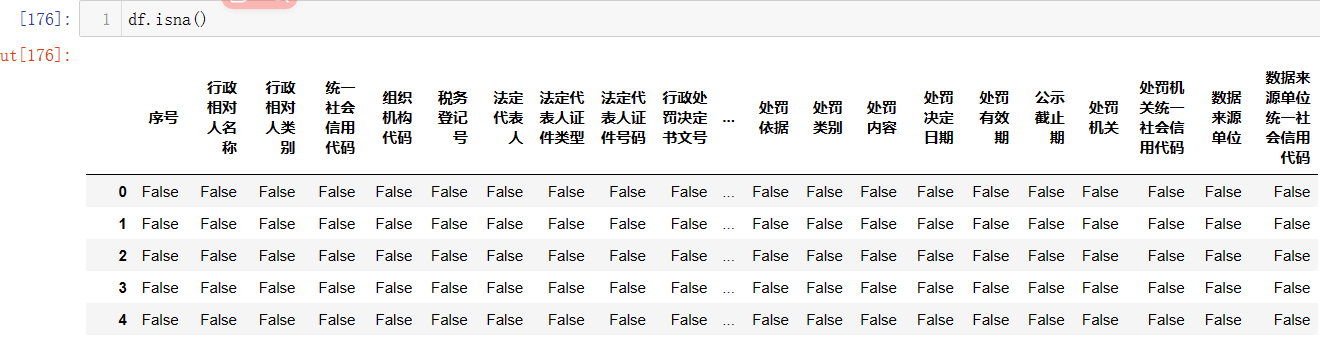
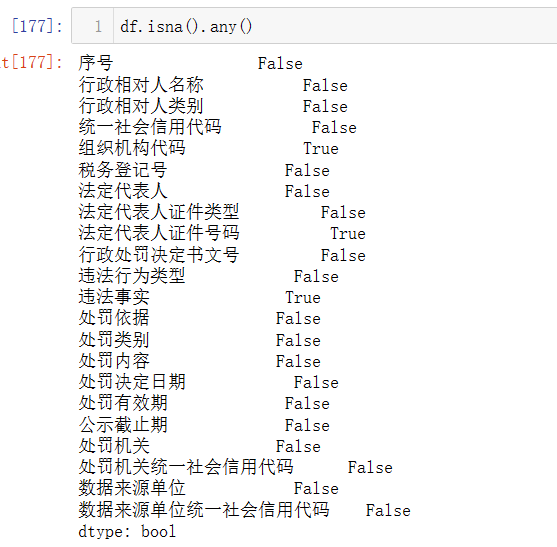
Q:查询组织机构代码为空的公司,查询所有列中有哪些为空?
A-1:
df[df['组织机构代码'].isna()]

A-2:
df.columns[df.isna().any()]

在pandas 中查询空值主要使用isna() 或 isnull()方法,当然非空也是有的notna()或notnull方法。
df.isna()就是对dataFrame所有数据进行空值判断,返回一个bool数组。
关于any()这个是一个聚合函数,作用是对调用它的数据的行或列执行逻辑“与”(and)操作,并返回一个是否为空的布尔值。默认是按列聚合
5.复杂的布尔表达式
Q:我想筛选罚款金额超过2000元的公司、个体工商户有哪些?
A:我们可以通过之前学的apply()、map()方法来实现。
分析,因为我们的处罚金额中带有文字,所以我们先要利用正则把金额提取出来,然后转成数字类型才能与2000做比较
import re
def get_money(str):
pattern=re.compile(r'(\d+(\.\d+)?)元')
amount=0
match = re.search(pattern, str)
if match:
amount =float(match.group(1))
return amount
df[df['处罚内容'].apply(get_money)>2000]
#df[df['处罚内容'].map(get_money)>2000]
正则表达式
r'(\d+(\.\d+)?)元'匹配一个或多个连续的数字 (\d+),后面可能跟着一个小数点和一个或多个数字 ((\.\d+)?),最后是“元”字。由于小数部分是非必填的,所以使用了非贪婪量词?表示前面的小数部分出现0次或1次
6.query() 方法
在 pandas 中,query() 方法提供了一种灵活且直观的方式来查询 DataFrame。该方法使用类似于 SQL 的语法来执行布尔表达式,并返回满足条件的行。
基本用法如下:
filtered_df = df.query("expression")
expression是一个字符串,其中可以包含列名、比较运算符以及逻辑运算符(如and、or等)。
通过 query() 方法,我们可以轻松地构造和执行复杂的布尔表达式来筛选数据。这种方法的一个优势是能够保留原始列名的引用而无需引号,使得代码更加易读和简洁,但需要注意的是该种方式并不直接支持复杂的列变换或函数应用。
为方便学习,这我们直接新建一个dataFrame来做语句的学习。
import pandas as pd
# 新建一个 DataFrame
df = pd.DataFrame({ 'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'Los Angeles', 'Chicago', 'San Francisco']
})
# 使用 query() 进行筛选
filtered_df = df.query("Age > 30 and City == 'New York'")
# 或者多个条件组合查询 c
omplex_query = "((Age < 35) | (City == 'Chicago')) & (Name != 'Charlie')"
filtered_df_complex = df.query(complex_query)
结束语
在这片学习博客中,我们学习了 pandas 库中的 DataFrame 的数据导入、查询与基本属性。从基础的 .loc 和 .iloc 索引操作,到利用布尔表达式进行复杂筛选的 .query() 方法,再到对日期时间、缺失值和正则表达式的灵活应用。 事实上,这只是学习 pandas 强大功能的一个开始。希望本文能对你学习pandas有所帮助,让我们一起在数据的世界里持续学习,不断进步!!。