我开发了一个用于自动评教的工具,大家可以试着用用,下面是链接。
https://github.com/restrain11/auto_teachingEvaluate
可以点个星吗,感谢!🫡
以下是我在开发过程中学到的知识 以及 碰到的部分问题
动态爬虫和静态爬虫的区别
1. 静态爬虫
静态爬虫是指通过直接发送 HTTP 请求,获取静态网页的 HTML 源码,并从中提取数据的一种爬取方式。适用于页面内容在服务器端渲染的场景。
特点
- HTML 源码直接包含数据:
- 发送请求后,服务器返回的 HTML 已包含所有需要的数据。
- 无需执行 JavaScript:
- 页面内容在服务器端渲染完成,浏览器无需额外加载和运行脚本。
- 速度较快:
- 不需要加载 JavaScript、CSS 等资源,只提取 HTML 内容即可。
技术实现
- 使用库如
requests、urllib等发送 HTTP 请求获取页面源码。 - 使用解析库如
BeautifulSoup或lxml提取所需数据。
示例代码
import requests
from bs4 import BeautifulSoup
# 发送 HTTP 请求
url = "https://example.com"
response = requests.get(url)
# 解析 HTML 内容
soup = BeautifulSoup(response.text, "html.parser")
# 提取数据
title = soup.find("title").text
print("页面标题:", title)
适用场景
- 数据直接嵌在 HTML 中。
- 网站不依赖 JavaScript 动态加载内容。
- 需要快速高效的爬取。
2. 动态爬虫
动态爬虫是指通过模拟浏览器行为(如执行 JavaScript 脚本),获取动态加载的页面内容的一种爬取方式。适用于页面内容由客户端(浏览器)通过 JavaScript 加载的场景。
特点
- 依赖 JavaScript 渲染:
- 发送初始 HTTP 请求后,返回的 HTML 可能是一个框架,具体数据需要通过 JavaScript 动态加载。
- 需要模拟浏览器操作:
- 使用工具(如 Selenium、Playwright 等)模拟浏览器执行 JavaScript 脚本并加载内容。
- 速度较慢:
- 由于需要模拟浏览器加载和渲染页面,爬取效率较低。
技术实现
- 使用 Selenium 或 Playwright 等工具启动浏览器,加载页面并提取渲染后的内容。
- 解析渲染完成的 HTML 提取所需数据。
示例代码
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动浏览器
driver = webdriver.Chrome()
driver.get("https://example.com")
# 等待页面加载完成并提取数据
title = driver.title
print("页面标题:", title)
# 关闭浏览器
driver.quit()
适用场景
- 页面内容由 JavaScript 动态加载。
- 需要处理复杂的交互操作(如点击、滚动)。
- 数据直接请求无法获取,需模拟用户操作。
3. 对比
| 特性 | 静态爬虫 | 动态爬虫 |
|---|---|---|
| 数据加载方式 | 数据直接包含在 HTML 中 | 数据由 JavaScript 动态加载 |
| 技术实现 | 直接请求 HTML 并解析 | 模拟浏览器行为,执行 JavaScript |
| 执行效率 | 快速 | 较慢(需加载页面和执行脚本) |
| 技术复杂度 | 较低 | 较高(需处理浏览器模拟和脚本加载) |
| 适用场景 | 静态页面,数据直接返回 | 动态页面,数据通过异步加载 |
selenium
Selenium 是一个开源的自动化测试工具,用于模拟用户在浏览器中的操作。它支持多种浏览器(如 Chrome、Firefox、Edge)和多种编程语言(如 Python、Java、C#、Ruby、JavaScript 等),适用于 Web 应用程序的自动化测试。
主要功能
浏览器自动化:
- 可以模拟人类在浏览器中的操作,例如点击、输入、滚动、拖放等。
跨浏览器测试:
- 支持多种主流浏览器(如 Chrome、Firefox、Safari、Edge 等)。
支持多种编程语言:
- 提供多语言绑定接口(如 Python、Java 等),方便开发者根据需求选择。
动态内容测试:
- 支持测试现代 Web 应用中的动态内容(如 AJAX、JavaScript 加载的内容)。
灵活的元素定位:
- 支持多种方式定位页面元素,包括 ID、名称、类名、标签名、XPath、CSS 选择器等。
核心组件
Selenium WebDriver:
- Selenium 的核心,用于直接与浏览器交互,执行自动化操作。
- 适用于现代 Web 应用测试。
Selenium IDE:
- 一个简单的浏览器扩展,可记录和回放用户操作,适合初学者使用。
Selenium Grid:
- 用于分布式测试,允许在多个设备上同时运行测试,适合大型项目。
Selenium RC(已废弃):
- Selenium 的早期版本,现已被 WebDriver 替代。
工作原理
WebDriver 驱动:
- WebDriver 是 Selenium 的核心,它通过驱动程序(如 ChromeDriver、GeckoDriver)与浏览器进行通信。
- Selenium 使用 WebDriver API 向浏览器发送指令,如打开页面、查找元素、模拟操作等。
执行自动化操作:
- Selenium 脚本中包含测试用例逻辑。
- WebDriver 将脚本中的操作翻译成浏览器能理解的命令。
- 浏览器执行这些命令,完成测试。
示例代码
以下是使用 Selenium 的一个简单示例:
Python 示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 设置 WebDriver(以 Chrome 为例)
driver = webdriver.Chrome()
# 打开网页
driver.get("https://www.google.com")
# 查找搜索框并输入关键字
search_box = driver.find_element(By.NAME, "q")
search_box.send_keys("Selenium WebDriver")
# 提交搜索
search_box.submit()
# 打印页面标题
print(driver.title)
# 关闭浏览器
driver.quit()
应用场景
Web 应用自动化测试:
- 测试用户登录、注册、支付流程等功能。
跨浏览器测试:
- 验证 Web 应用在不同浏览器上的兼容性。
抓取动态内容:
- 配合工具进行简单的 Web 爬取,特别是动态加载的内容。
回归测试:
- 自动化测试重复性工作,如检查新功能是否影响已有功能。
优缺点
优点:
- 开源免费:
- 无需付费,社区活跃。
- 支持多浏览器和语言:
- 灵活性强,适配性广。
- 灵活的元素定位:
- 可精确定位复杂页面上的元素。
缺点:
- 对动态页面支持有限:
- 对于高度动态化页面(如 React、Angular 应用),需要与等待机制结合使用。
- 执行速度较慢:
- 比较适合功能测试,不适合性能测试。
- 维护成本高:
- 页面结构变化可能导致测试脚本需要频繁更新。
iframe
iframe 是 HTML 内联框架(Inline Frame),用于在网页中嵌入另一个 HTML 文档。通过 iframe,一个网页可以显示另一个独立的网页,类似于窗口中的窗口。
主要特性
- 独立的上下文:
iframe中的内容独立于外部网页的 DOM(Document Object Model)。- 它有自己的 HTML 文档、CSS 样式和 JavaScript 环境。
- 跨域限制:
- 如果
iframe中加载的是与主网页不同域的内容(跨域),会受到浏览器的安全限制,无法直接访问内容。
- 嵌套网页:
- 通过
iframe,可以嵌套第三方网页、广告或动态内容。
常见用途
- 加载第三方内容:
- 比如:加载 YouTube 视频、Google Maps。
- 广告显示 :
- 网页中插入广告内容。
- 单点登录系统 :
- 嵌套外部的登录页面(正如你的代码中使用)。
- 嵌入其他网站的组件或服务 :
- 比如支付系统的嵌入。
iframe 的 HTML 结构
一个基本的 iframe 结构如下:
<iframe src="https://example.com" width="600" height="400" frameborder="0">
浏览器不支持 iframe。
</iframe>
-
src- 作用:指定
iframe要加载的页面的 URL。 - 用法:
src="https://example.com"表示iframe将嵌入https://example.com的内容。- 你可以指定绝对路径(如
https://example.com)或相对路径(如/about.html)。
- 注意事项:
- 如果
src的 URL 指向的资源不可用或加载失败,iframe会显示备用内容(如浏览器不支持 iframe)。 - 加载的内容可能受限于 跨域策略,例如一些网站可能禁止被嵌入。
- 如果
- 作用:指定
-
width和height: 控制iframe的宽度和高度。 -
frameborder: 是否显示边框。
Selenium 中的 iframe
- 为什么需要切换到 iframe?
- 当网页中的元素被包含在
iframe内时,Selenium 无法直接访问这些元素。 - 必须先切换到
iframe,才能操作其内容。
XPath?
XPath(XML Path Language)是一种在 XML 或 HTML 文档中定位元素的语言,常用于在 Web 自动化测试(如 Selenium)中查找页面元素。
功能
- 定位 HTML 中的元素。
- 支持层级关系、属性筛选、文本内容匹配等。
- 适合复杂的页面结构。
基本语法
基本符号及其解释
1. //
-
作用:表示从文档的任意位置开始查找节点(无论节点深度如何)。
-
用法:
//tagname:匹配文档中所有名为tagname的节点。
-
示例:
<div> <span>Example</span> <p>Sample</p> </div>XPath 查询:
//p- 匹配:
<p>Sample</p>
- 匹配:
2. /
-
作用:表示查找直接子节点。
-
用法:
parent/child:匹配指定父节点下的直接子节点。
-
示例:
<div> <p>Direct child</p> <span> <p>Nested child</p> </span> </div>XPath 查询:
/div/p- 匹配:
<p>Direct child</p>
- 匹配:
3. [ ]
-
作用:用于条件筛选,通常指定节点的属性值、文本内容或索引。
-
用法:
tagname[@attribute="value"]:匹配具有特定属性和值的节点。tagname[index]:匹配指定位置的节点(索引从 1 开始)。
-
示例:
<div> <p id="first">Paragraph 1</p> <p id="second">Paragraph 2</p> </div>XPath 查询:
//p[@id="second"]- 匹配:
<p id="second">Paragraph 2</p>
XPath 查询:
//p[2]- 匹配:第二个
<p>节点,即:<p id="second">Paragraph 2</p>
- 匹配:
4. @
-
作用:表示节点的属性。
-
用法:
tagname[@attribute="value"]:匹配具有指定属性和值的节点。//@attribute:匹配文档中所有包含指定属性的节点。
-
示例:
<input type="text" name="username" /> <input type="password" name="password" />XPath 查询:
//input[@type="password"]- 匹配:
<input type="password" name="password" />
XPath 查询:
//@name- 匹配:所有具有
name属性的节点。
- 匹配:
组合与扩展用法
1. 多条件筛选
-
作用:通过逻辑操作符组合多个条件。
-
用法:
and:同时满足多个条件。or:满足任一条件。
-
示例:
<div> <p class="active" id="first">Active Paragraph</p> <p class="inactive" id="second">Inactive Paragraph</p> </div>XPath 查询:
//p[@class="active" and @id="first"]- 匹配:
<p class="active" id="first">Active Paragraph</p>
XPath 查询:
//p[@class="active" or @id="second"]- 匹配:
<p class="active" id="first">Active Paragraph</p><p class="inactive" id="second">Inactive Paragraph</p>
- 匹配:
2. 包含条件
-
作用:匹配属性值或文本内容包含某些字符的节点。
-
用法:
contains(@attribute, "value"):属性值包含指定文本。contains(text(), "value"):文本内容包含指定文本。
-
示例:
<div> <p class="class1">Hello World</p> <p class="class2">Welcome to XPath</p> </div>XPath 查询:
//p[contains(@class, "class")]- 匹配:所有包含
class属性值的<p>标签。
XPath 查询:
//p[contains(text(), "Welcome")]- 匹配:
<p class="class2">Welcome to XPath</p>
- 匹配:所有包含
3. 位置筛选
-
作用:根据节点的相对位置筛选。
-
用法:
first():匹配第一个节点。last():匹配最后一个节点。position() = n:匹配特定位置的节点。
-
示例:
<ul> <li>Item 1</li> <li>Item 2</li> <li>Item 3</li> </ul>XPath 查询:
//li[position()=1]- 匹配:
<li>Item 1</li>
XPath 查询:
//li[last()]- 匹配:
<li>Item 3</li>
- 匹配:
完整的 XPath
完整的 XPath是从 HTML 文档的根节点(html)开始,精确地描述元素路径的 XPath 表达式。
特点
- 从根节点逐级到目标节点,路径是唯一的。
- 更加可靠,但较长且不易维护。
示例
假设有以下 HTML:
<html>
<body>
<div>
<form>
<input id="username" type="text">
</form>
</div>
</body>
</html>
完整 XPath 表达式:
/html/body/div/form/input[@id='username']
- 解释:从
html根节点开始,逐级到body->div->form->input,并通过id='username'确定目标元素。
优缺点
- 优点:路径唯一,不容易受到页面动态变化的影响。
- 缺点:路径较长,维护困难,一旦页面结构发生改变,可能失效。
两者区别
| 特点 | 绝对 XPath | 相对 XPath |
|---|---|---|
| 路径起点 | 从根节点(<html>)开始,路径固定。 | 从任意位置开始,路径灵活。 |
| 路径表示 | 以 / 开头,逐级描述路径。 | 以 // 开头,直接定位目标元素。 |
| 路径长度 | 路径较长,嵌套深时尤其明显。 | 路径较短,表达更简洁。 |
| 页面变化的影响 | 页面结构变化会导致路径失效。 | 页面结构变化时适应性较强。 |
| 灵活性 | 固定且不灵活。 | 灵活,支持多种条件筛选。 |
| 适用场景 | 适用于简单页面或需要唯一路径的场景。 | 适用于复杂页面或需要灵活定位的场景。 |
推荐在 Web 自动化测试中优先使用相对XPath
如果 XPath 匹配到多个元素,会发生什么?
当一个 XPath 表达式在页面中匹配到多个元素时,行为取决于你如何使用该 XPath 表达式:
在 Selenium 中的行为
- 如果你使用
find_element方法:
element = driver.find_element(By.XPATH, "XPath表达式")
-
结果
- 只返回匹配到的第一个元素。
- 如果你需要的是多个元素,可能会导致结果不符合预期。
-
如果你使用
find_elements方法:
elements = driver.find_elements(By.XPATH, "XPath表达式")
- 结果
- 返回一个列表,包含所有匹配到的元素。
- 列表中的元素顺序与它们在 HTML 文档中的顺序一致。
匹配多个的使用场景
有些情况下,匹配多个元素是有意义的。例如:
- 遍历一个表格中的所有行。
- 获取页面中所有的按钮或输入框。
在这些场景下,可以用 find_elements 方法获取一个列表,并对每个匹配到的元素进行逐一操作。
代码示例:处理多个匹配
elements = driver.find_elements(By.XPATH, "//input")
for index, elem in enumerate(elements, start=1):
print(f"第 {index} 个元素类型: {elem.get_attribute('type')}")
输出:
第 1 个元素类型: text
第 2 个元素类型: password
第 3 个元素类型: submit
Selector?
Selector(选择器)是通过一种特定的规则来查找页面元素的方式。CSS Selector 是 Web 自动化中常用的一种选择器。
功能
- 它类似于 CSS 样式规则,通过样式规则快速定位 HTML 元素。
- 易于阅读,特别适合简单的页面结构。
示例
div.example # 定位类名为 'example' 的所有 <div> 元素
#username # 定位 id 为 'username' 的元素
input[name="password"] # 定位 name 属性为 'password' 的 <input> 元素
table > tbody > tr:first-child td:nth-child(2) # 定位表格第一行第二列的单元格
button.btn-primary # 类名包含 'btn-primary' 的按钮
XPath和Selector区别
| 特性 | XPath | CSS Selector |
|---|---|---|
| 支持层级关系 | 支持父节点、祖先节点定位(..) | 不支持 |
| 语法复杂度 | 相对复杂,功能强大 | 简单直观,易用 |
| 浏览器兼容性 | Selenium 支持所有主流浏览器 | Selenium 支持所有主流浏览器 |
| 速度 | 通常较慢,因为功能强大,支持更多匹配规则 | 通常更快,适用于简单的查找规则 |
| 文本定位 | 支持通过 text() 定位,比如://button[text()='登录'] | 不支持,需通过类名或属性定位 |
什么时候选择 XPath?
- 页面结构复杂,需要精确定位元素。
- 元素没有
id、class等可用的属性。 - 需要根据层级关系定位父子节点。
什么时候选择 CSS Selector?
- 页面结构简单。
- 目标元素有
id或class。 - 需要高效且易维护的选择器。
窗口句柄?
窗口句柄(Window Handle)是一个由浏览器分配的唯一标识符,用来标识和操作当前浏览器实例中打开的各个窗口或标签页。
在 Selenium 中,窗口句柄是通过 WebDriver 提供的,用于在多个浏览器窗口或标签页之间切换。
特性
- 唯一性:
- 每个窗口或标签页都有一个唯一的句柄。
- 不同窗口的句柄永远不会重复。
- 动态分配:
- 打开新的窗口或标签页时,WebDriver 会为其分配一个新的句柄。
- 存储方式:
- Selenium 使用
window_handles属性返回所有当前窗口的句柄列表。 - 使用
current_window_handle属性获取当前窗口的句柄。
如何获取窗口句柄
- 获取当前窗口句柄:
current_handle = driver.current_window_handle
print(f"当前窗口句柄: {current_handle}")
- 获取所有窗口句柄:
all_handles = driver.window_handles
print(f"所有窗口句柄: {all_handles}")
- 切换窗口句柄:
- 使用
driver.switch_to.window(handle)切换到指定窗口。
driver.switch_to.window(all_handles[1]) # 切换到第二个窗口
窗口句柄的常见操作
- 新窗口的打开与切换:
- 当执行操作(如点击一个链接)后,新窗口或标签页会打开。
- Selenium 不会自动切换到新窗口,需要显式切换。
# 等待新窗口打开
# 等待窗口数量增加(从现有窗口数 + 1)
current_window_count = len(driver.window_handles)
WebDriverWait(driver, 10).until(lambda d: len(d.window_handles) > current_window_count)
# 切换到最新打开的窗口
driver.switch_to.window(driver.window_handles[-1])
# 检查新窗口的标题或 URL
WebDriverWait(driver, 10).until(lambda d: "目标标题" in d.title or "目标URL片段" in d.current_url)
print(f"新窗口已成功加载,标题: {driver.title}")
为什么判断新窗口是否加载是重要的?
1. **避免不完整的句柄切换:** 在 `driver.switch_to.window()` 之前,新窗口可能尚未完全加载,导致操作 DOM 时出错。
2. **新窗口的加载时机:** 浏览器可能会在窗口句柄生成后延迟加载内容,所以需要等待标题、URL 或特定 DOM 元素出现以确保内容可用。
3. **超时错误的可能性:** 如果仅等待窗口句柄变化,而不验证新窗口内容,可能导致未加载完成的页面被误认为加载成功。
- 关闭窗口并返回主窗口:
- 可以通过
driver.close()关闭当前窗口。 - 然后用
switch_to.window切换回主窗口。
# 关闭当前窗口
driver.close()
# 切换回主窗口
driver.switch_to.window(handles[0])
- 切换回原始窗口:
- 在切换到新窗口后,可以通过记录最初的窗口句柄返回主窗口。
original_handle = driver.current_window_handle
# 执行其他窗口的操作后切回
driver.switch_to.window(original_handle)
实际应用场景
- 多窗口/标签页操作:
- 用户点击链接后,打开新窗口。
- 需要切换到新窗口进行操作,再返回主窗口。
示例:
# 记录主窗口句柄
main_window = driver.current_window_handle
# 点击按钮,打开新窗口
driver.find_element(By.ID, 'open-new-window').click()
# 等待新窗口打开并切换到新窗口
WebDriverWait(driver, 10).until(lambda d: len(d.window_handles) > 1)
handles = driver.window_handles
driver.switch_to.window(handles[-1])
print(f"新窗口标题: {driver.title}")
# 关闭新窗口并返回主窗口
driver.close()
driver.switch_to.window(main_window)
print(f"返回主窗口,标题: {driver.title}")
- 处理第三方登录或支付:
- 如点击“使用第三方登录”或“跳转支付”,会打开新窗口,需在新窗口操作后切回原窗口
将来我会采用PyAutoGUI来实现自动评教的功能。友友们也可以自己尝试哦😉
PyAutoGUI
PyAutoGUI 是一个用于 GUI 自动化的 Python 库,可以模拟人类在计算机上的操作。它可以控制鼠标和键盘,执行点击、拖动、键盘输入、截屏等操作,常用于简单的桌面应用程序自动化任务。
特点
跨平台支持:
- 支持 Windows、macOS 和 Linux。
易用性:
- 提供了简单的 API,可以快速实现鼠标、键盘的自动化操作。
丰富的功能:
- 支持屏幕坐标操作、图像匹配、消息框等功能。
轻量级:
- 易于集成到各种项目中。
主要功能
1. 鼠标操作
PyAutoGUI 提供了多种方式来控制鼠标,包括移动、点击、拖动等。
1.1 获取屏幕尺寸
import pyautogui
# 获取屏幕分辨率
screen_width, screen_height = pyautogui.size()
print(f"屏幕分辨率: {screen_width}x{screen_height}")
1.2 获取鼠标当前位置
# 获取鼠标当前位置
x, y = pyautogui.position()
print(f"鼠标当前位置: ({x}, {y})")
1.3 移动鼠标
# 将鼠标移动到屏幕 (100, 100) 坐标
pyautogui.moveTo(100, 100, duration=1) # duration 是移动时间(秒)
1.4 点击
# 单击
pyautogui.click(100, 100)
# 双击
pyautogui.doubleClick(200, 200)
# 右键单击
pyautogui.rightClick(150, 150)
1.5 鼠标拖动
# 从 (100, 100) 拖动到 (400, 400)
pyautogui.moveTo(100, 100)
pyautogui.dragTo(400, 400, duration=2)
2. 键盘操作
PyAutoGUI 提供模拟键盘输入和快捷键的功能。
2.1 输入文本
# 模拟键盘输入
pyautogui.typewrite("Hello, PyAutoGUI!", interval=0.1) # interval 控制每个字符的间隔时间
2.2 模拟按键
# 按下一个键
pyautogui.press("enter")
# 同时按下多个键(组合键)
pyautogui.hotkey("ctrl", "c") # 模拟 Ctrl+C 复制
3. 屏幕截图与匹配
PyAutoGUI 支持截取屏幕和图像匹配功能。
我觉得这是最让人惊艳的!
3.1 截屏
# 截取整个屏幕
screenshot = pyautogui.screenshot()
screenshot.save("screenshot.png") # 保存为文件
3.2 图像匹配
1、基于图像的定位
- PyAutoGUI 能够在屏幕上搜索目标图像的位置,并返回图像所在区域的坐标。
- 这对于定位动态元素、没有固定坐标的 UI 元素非常有用。
2、操作与图像匹配结合
- PyAutoGUI 可以通过匹配找到的图像位置来执行点击、拖动等操作。
3、 灵活性
- 支持指定精度(容忍度)和多个匹配结果,适应不同的屏幕分辨率或图像质量。
关键方法
1. pyautogui.locateOnScreen()
- 功能:查找屏幕上与指定图像匹配的区域。
- 返回值:返回一个
Box对象,包含图像在屏幕上的位置和尺寸。
import pyautogui
# 在屏幕上查找 button.png 图像
location = pyautogui.locateOnScreen('button.png')
if location:
print(f"图像位置: {location}") # Box(left=100, top=200, width=50, height=30)
else:
print("未找到匹配图像")
2. pyautogui.locateAllOnScreen()
- 功能:查找屏幕上所有与指定图像匹配的区域。
- 返回值:返回一个生成器,包含所有匹配结果。
# 查找所有匹配 button.png 的位置
for loc in pyautogui.locateAllOnScreen('button.png'):
print(f"找到图像位置: {loc}")
3. pyautogui.center()
- 功能:获取
Box对象的中心坐标,便于直接点击或其他操作。
# 找到图像的中心点
location = pyautogui.locateOnScreen('button.png')
if location:
center = pyautogui.center(location)
print(f"图像中心点: {center}") # Point(x=125, y=215)
4. pyautogui.click() 与图像匹配结合
- 通过找到图像的中心点后直接点击:
# 查找图像并点击其中心
location = pyautogui.locateOnScreen('button.png')
if location:
pyautogui.click(pyautogui.center(location))
print("已点击图像")
5. 设置精度(容忍度)
- 默认匹配精度是完全匹配,但可以通过
confidence参数调整容忍度(需要 OpenCV 支持)。 - 适用场景:目标图像可能因分辨率、缩放或样式变化略有不同。
# 查找屏幕上与 button.png 匹配度 >= 0.8 的区域
location = pyautogui.locateOnScreen('button.png', confidence=0.8)
if location:
print(f"图像位置: {location}")
注意:使用
confidence参数需要安装opencv-python:pip install opencv-python
4. 消息框
PyAutoGUI 还提供简单的消息框功能,适合调试或通知用户。
# 显示一个消息框
pyautogui.alert("这是一个消息框!")
# 确认对话框
response = pyautogui.confirm("是否继续?", buttons=["是", "否"])
print(f"用户选择: {response}")
注意事项
屏幕分辨率限制:
- 鼠标移动的坐标必须在屏幕分辨率范围内,超出范围会引发错误。
鼠标和键盘阻断:
- 如果脚本运行过程中出错可能会导致系统无法操作。可通过快速移动鼠标到屏幕左上角(默认热键)强制中断脚本。
性能:
- 图像匹配功能较为耗时,适用于简单场景,不适合复杂实时性要求。
安全性:
- 模拟操作易被检测到,无法完全应用于反自动化保护机制严格的场景。
应用场景
桌面自动化测试:
- 测试桌面应用程序的基本功能。
办公自动化:
- 自动填写表单、复制粘贴内容、执行批量操作等。
游戏辅助:
- 实现简单的鼠标和键盘自动操作。
简单图像识别与操作:
- 基于屏幕内容的动态响应(如点击按钮、拖动文件等)。
以下是我解决的部分bug 或 遇到的问题
问题1
# 切换到 iframe
evaluation_iframe = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.XPATH, '//iframe[@id="FrameNEW_XSD_JXPJ_JXPJ_XSPJ"]'))
)
driver.switch_to.frame(evaluation_iframe)
print("已切换到‘学生评价’iframe")
为什么需要 switch_to.frame?
- 页面中 iframe 的内容是一个独立的 DOM 上下文,与主页面的 DOM 是分开的。
- 当你需要操作 iframe 内部的元素时,Selenium 必须先切换到这个 iframe。
- 不管你是用 XPath 还是 CSS Selector 定位,如果元素在 iframe 内,未切换到 iframe 会导致 Selenium 抛出
NoSuchElementException错误。
问题2
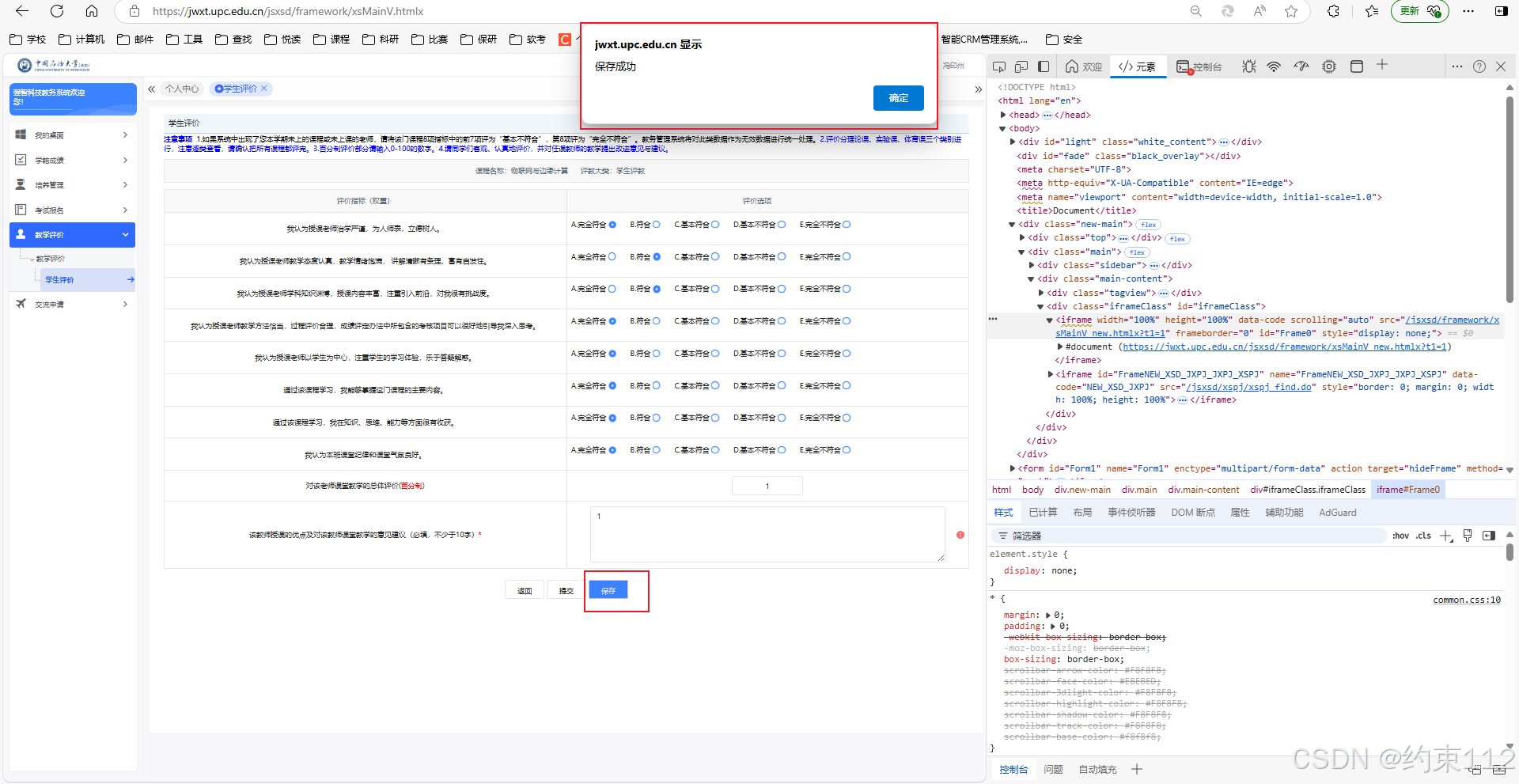
点击保存后弹出的“jwxt.upc.edu.cn 显示 保存成功” 为何无法在元素中查到其html代码?
在点击“保存”后弹出的“jwxt.upc.edu.cn 显示 保存成功”对话框属于 JavaScript 的 alert 对话框,而不是页面中的 HTML 元素。这类对话框是通过浏览器原生功能实现的,因此无法通过开发者工具或 Selenium 的常规方法找到其 HTML 代码。
JavaScript Alert 的特点
- 原生对话框: 这是通过 JavaScript 的
alert()、confirm()或prompt()函数创建的原生对话框。 - 独立于 HTML DOM: 这些对话框不是 HTML 元素的一部分,它们由浏览器本身渲染,直接覆盖在页面上。
- 阻塞行为: 当弹出对话框时,JavaScript 的执行会暂停,直到对话框被用户手动关闭。
如何检测和处理此类对话框?
使用 Selenium,可以通过 switch_to.alert 访问并处理这些对话框。
代码示例:处理 Alert 对话框
from selenium.webdriver.common.alert import Alert
# 等待并切换到 alert 对话框
alert = WebDriverWait(driver, 10).until(EC.alert_is_present())
# 获取 alert 对话框中的文本
alert_text = alert.text
print(f"Alert 对话框内容: {alert_text}")
# 点击 "确定" 按钮关闭对话框
alert.accept()
如何确认这是一个 alert 对话框?
-
点击“保存”按钮后,观察页面是否暂停(阻塞行为)。
-
使用 Selenium 的
switch_to.alert
检测是否存在 alert:
try:
alert = driver.switch_to.alert
print("检测到 alert 对话框")
except Exception as e:
print("未检测到 alert 对话框")
注意事项
- 弹出框类型: 确保是浏览器原生的 alert,对话框。否则,可能是自定义的 HTML 弹出框。
- 等待 alert: 如果对话框在点击后延迟出现,可以用
WebDriverWait等待alert_is_present()。 - 区分多个对话框: 如果页面存在多种弹出框(例如
confirm和prompt),需要根据具体行为(例如获取输入或确认操作)处理。
问题3
已切换到 iframe
登录成功!当前页面URL: https://i.upc.edu.cn/dcp/forward.action?path=/portal/portal&p=home
当前页面包含'/portal/portal',继续执行后续操作
已切换回主页面
找到 container 元素
找到 container > div[1]
找到 appMenuWidget-content
成功点击教学应用
成功点击教务系统链接
成功切换到新窗口,新页面URL: https://jwxt.upc.edu.cn/jsxsd/framework/xsMainV.htmlx
新页面标题: 首页
成功点击‘教学评价’主菜单
成功点击‘教学评价’子菜单
成功点击‘学生评价’
已切换到‘学生评价’iframe
表格已加载
找到 2 行数据(除表头)
第 1 行找到链接:https://jwxt.upc.edu.cn/jsxsd/xspj/xspj_list.do?pj0502id=BDCCA6651BFB47888F0507B1B571A3B1&pj01id=C96FD3FC03074117A35BF8FB146A6BAE&xnxq01id=2024-2025-1
成功点击进入评价
课程表格已加载
找到 10 行课程数据(除表头)
第 1 行找到课程链接:https://jwxt.upc.edu.cn/jsxsd/xspj/xspj_edit.do?xnxq01id=2024-2025-1&pj01id=C96FD3FC03074117A35BF8FB146A6BAE&pj0502id=BDCCA6651BFB47888F0507B1B571A3B1&jx02id=93BB4083C534484D85049A6C6E31527D&jx0404id=202420251001810&xsflid=&zpf=92.4&jg0101id=00692&ifypjxx=&pageIndex=1
成功点击进入课程评价
评价表已加载
Alert 对话框内容: 保存成功
第 2 课程行操作失败,跳过。错误: Message: stale element reference: stale element not found
(Session info: chrome=131.0.6778.265); For documentation on this error, please visit: https://www.selenium.dev/documentation/webdriver/troubleshooting/errors#stale-element-reference-exception
Stacktrace:
GetHandleVerifier [0x0043FD53+23747]
(No symbol) [0x003C7D54]
(No symbol) [0x0029BE53]
(No symbol) [0x002AB889]
(No symbol) [0x002AA945]
(No symbol) [0x002A22B3]
(No symbol) [0x002A0578]
(No symbol) [0x002A387A]
(No symbol) [0x002A38F7]
(No symbol) [0x002DF8B9]
(No symbol) [0x002DFEEB]
(No symbol) [0x002D5A81]
(No symbol) [0x00301E44]
(No symbol) [0x002D59A4]
(No symbol) [0x00302094]
(No symbol) [0x0031B41E]
(No symbol) [0x00301B96]
(No symbol) [0x002D3F3C]
(No symbol) [0x002D4EBD]
GetHandleVerifier [0x0071AC73+3017699]
GetHandleVerifier [0x0072B93B+3086507]
GetHandleVerifier [0x007240F2+3055714]
GetHandleVerifier [0x004D5AF0+637536]
(No symbol) [0x003D0A5D]
(No symbol) [0x003CDA28]
(No symbol) [0x003CDBC5]
(No symbol) [0x003C07F0]
BaseThreadInitThunk [0x755D5D49+25]
RtlInitializeExceptionChain [0x774CCEBB+107]
RtlGetAppContainerNamedObjectPath [0x774CCE41+561]
...
从日志信息来看,问题的核心是 “stale element reference”(陈旧的元素引用) 错误。该错误的原因是,页面发生了更新或重载,而 Selenium 仍然尝试操作在页面更新前找到的 DOM 元素。
可能的原因
- 页面重新加载或局部更新:
- 在你点击链接并加载新内容时,页面的 DOM 结构可能发生了变化。
- 原来的
WebElement引用已经无效,因此在后续操作中会引发stale element reference错误。
- 表格重新渲染:
- 表格可能是动态渲染的,加载课程数据后,所有的行 (
<tr>) 被刷新,这导致 Selenium 缓存的元素引用失效。
- 切换窗口或 iframe 的问题:
- 如果页面切换了窗口或 iframe,未正确切换上下文,之前的 DOM 元素引用也会失效。
问题4
页面使用了 JavaScript 来控制用户交互,点击操作可能需要触发 JavaScript 绑定的事件,直接 .click() 或 send_keys() 可能不起作用。
所以改成执行js脚本的方式交互。
if norm_index == 1:# 第一行选择 B
b_option = norm_operation_td.find_element(By.XPATH, './label[2]/input') driver.execute_script("arguments[0].click();", b_option) # 使用 JavaScript 点击. 如果使用b_option.click()的话会出现异常:Message: element not interactable
问题5
textaerea 可清除但是无法输入。
jynr_textarea = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//*[@id="jynr"]'))
)
# 清空原有内容
jynr_textarea.clear()
jynr_textarea.send_keys("希望老师再接再励,老师再见!!!!!!")
print("已输入教师建议:希望老师再接再励,老师再见!!!!!!")
jynr_textarea = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//*[@id="jynr"]'))
)
# 清空原有内容
jynr_textarea.clear()
# 使用 JavaScript 设置值并触发事件
driver.execute_script("arguments[0].value = arguments[1];", jynr_textarea, "希望老师再接再励,老师再见!!!!!!")
print("已输入教师建议:希望老师再接再励,老师再见!!!!!!")
以上均无法实现
【日常】爬虫技巧进阶:textarea的value修改与提交问题(以智谱清言为例)_textarea value修改没生效-CSDN博客
也没成功,最后发现,原来是
for norm_index in range(1, len(evaluation_rows)-1):
这里写错了,最后一行根本就没执行到,怪不得一直成功不了,也怪不得打断点的时候根本就不阻塞。太粗心了!!!!!
把-1删了就好了。
特么的
希望大家批评指正