一、计算机网络基础
1.1 网络分层模型
计算机网络分层模型是为了实现不同系统之间的互联互通,简化网络的设计、实现和维护。主要有两个著名的分层模型:OSI七层模型和TCP/IP协议栈。
1.1.1 OSI七层模型
OSI(Open Systems Interconnection)模型是一个理论参考模型,定义了网络通信的七个层次,每一层都有特定的功能和协议。
| 层次 | 功能概述 | 常见协议/设备 |
|---|---|---|
| 物理层 | 定义硬件设备接口,传输原始的二进制数据(比特流)。 | 光纤、网线、交换机 |
| 数据链路层 | 提供可靠的点到点数据传输(帧),负责纠错和数据帧控制。 | 以太网(Ethernet)、PPP、MAC地址 |
| 网络层 | 负责数据在不同网络之间的传输(分组、路由)。 | IP(IPv4/IPv6)、ICMP、ARP |
| 传输层 | 提供端到端的可靠传输,控制数据流量和传输质量。 | TCP、UDP |
| 会话层 | 管理会话连接(建立、维护、终止)。 | PPTP、SIP |
| 表示层 | 数据的格式化、加密解密和压缩解压。 | SSL/TLS、JPEG、MPEG |
| 应用层 | 面向用户的应用服务,提供具体的网络功能。 | HTTP、FTP、SMTP |
封装与解封装过程(在OSI模型中的体现)
- 封装过程:数据从应用层向下传递,每一层都会添加对应的头部信息(Header)。
- 应用层生成应用数据。
- 表示层和会话层处理格式、加密及连接管理。
- 传输层添加传输头部(如TCP头部)。
- 网络层添加IP头部。
- 数据链路层添加帧头和帧尾。
- 物理层将帧转换为比特流并发送。
- 解封装过程:比特流到达接收端,物理层接收数据后逐层剥去头部,直至还原出应用数据。
1.1.2 TCP/IP协议栈
TCP/IP是一个更简化、更实际的四层模型,与OSI模型存在一定的对应关系。它被广泛用于互联网中。
| 层次 | 功能描述 | 对应OSI层 | 常见协议/设备 |
|---|---|---|---|
| 应用层 | 提供网络应用服务,直接与用户交互。 | 应用层、表示层、会话层 | HTTP/HTTPS、FTP、SMTP |
| 传输层 | 负责端到端的通信,保证数据传输的可靠性。 | 传输层 | TCP、UDP |
| 网络层 | 负责数据的寻址和路由。 | 网络层 | IP、ICMP、ARP |
| 网络接口层 | 处理数据链路层和物理层的细节,完成数据的实际传输。 | 数据链路层、物理层 | Ethernet、Wi-Fi |
数据封装与解封装(TCP/IP模型中的体现)
-
封装过程:
- 应用层:生成应用数据并封装为消息。
- 传输层:添加传输层头部,形成段(TCP段或UDP段)。
- 网络层:添加IP头部,形成数据包。
- 网络接口层:添加帧头和帧尾,形成数据帧。
-
解封装过程: 接收端从物理层开始逐层剥离头部,最终在应用层还原数据。
1.1.3 OSI模型与TCP/IP模型的对比
| 对比点 | OSI模型 | TCP/IP模型 |
|---|---|---|
| 层次数量 | 七层 | 四层 |
| 起源 | 理论模型 | 实际应用 |
| 复杂度 | 更详细,适合教学和理解 | 更简化,适合实践 |
| 应用场景 | 理论研究、标准制定 | 互联网、实际网络通信 |
1.2 传输层协议详细讲解
传输层协议负责实现主机之间的端到端通信,保证数据能够从发送方正确到达接收方。传输层有两个核心协议:TCP(传输控制协议)和UDP(用户数据报协议)。
1.2.1 TCP协议
TCP(Transmission Control Protocol)是一种面向连接、可靠的传输协议,主要特点包括:
- 面向连接:通信前必须建立连接(三次握手),断开时需释放连接(四次挥手)。
- 可靠传输:通过确认应答、超时重传等机制保证数据准确无误地传递。
- 流量控制和拥塞控制:通过调整发送速率防止网络拥堵或接收端处理不过来。
1 三次握手详细分析
三次握手是建立TCP连接的过程,确保双方准备就绪且连接可靠。
三次握手过程:
-
第一次握手(SYN):
- 客户端发送一个SYN(Synchronize Sequence Number)包,请求建立连接,并发送初始序列号(Seq=x)。
- 进入 SYN-SENT 状态。
-
第二次握手(SYN-ACK):
- 服务端接收到SYN包后,向客户端发送SYN和ACK(Acknowledge)包,确认收到客户端的SYN,同时发送自己的初始序列号(Seq=y)。
- 进入 SYN-RECEIVED 状态。
-
第三次握手(ACK):
- 客户端收到服务端的SYN-ACK包后,发送一个确认ACK包,告知服务端SYN包已接收。
- 客户端进入 ESTABLISHED 状态,连接建立。
- 服务端收到ACK后也进入 ESTABLISHED 状态。
三次握手示意图:
为什么需要三次握手?
- 防止旧连接的数据干扰:避免客户端重传的旧SYN包误导致服务端开启连接。
- 双方确认状态:确保客户端和服务端都已准备好通信。
2 四次挥手详细分析
四次挥手是释放TCP连接的过程。
四次挥手过程:
-
第一次挥手(FIN):
- 客户端发送FIN(Finish)包,表示不再发送数据,请求关闭连接。
- 客户端进入 FIN-WAIT-1 状态。
-
第二次挥手(ACK):
- 服务端收到FIN后,发送ACK包确认,表示同意关闭连接。
- 服务端进入 CLOSE-WAIT 状态,客户端进入 FIN-WAIT-2 状态。
-
第三次挥手(FIN):
- 服务端处理完剩余数据后,向客户端发送FIN包,表示可以关闭连接。
- 服务端进入 LAST-ACK 状态。
-
第四次挥手(ACK):
- 客户端收到FIN后,发送ACK包确认,进入 TIME-WAIT 状态,等待一段时间后关闭连接。
- 服务端收到ACK后进入 CLOSED 状态。
四次挥手示意图:
为什么需要四次挥手?
- 半关闭机制:双方通信独立,发送和接收可以分开关闭。
- 确保剩余数据传输完成:避免服务端数据未发完连接就被关闭。
3 数据可靠性
TCP通过以下机制保证数据传输的可靠性:
-
确认应答(ACK):
- 接收方收到数据后发送ACK,通知发送方数据已到达。
-
超时重传:
- 如果发送方在一定时间内未收到ACK,会认为数据丢失并重传。
- 超时时间根据网络条件动态调整。
-
滑动窗口:
- 控制发送的数据量,确保接收方有足够的缓冲空间。
- 发送窗口移动时,可以动态调整传输速率,提高传输效率。
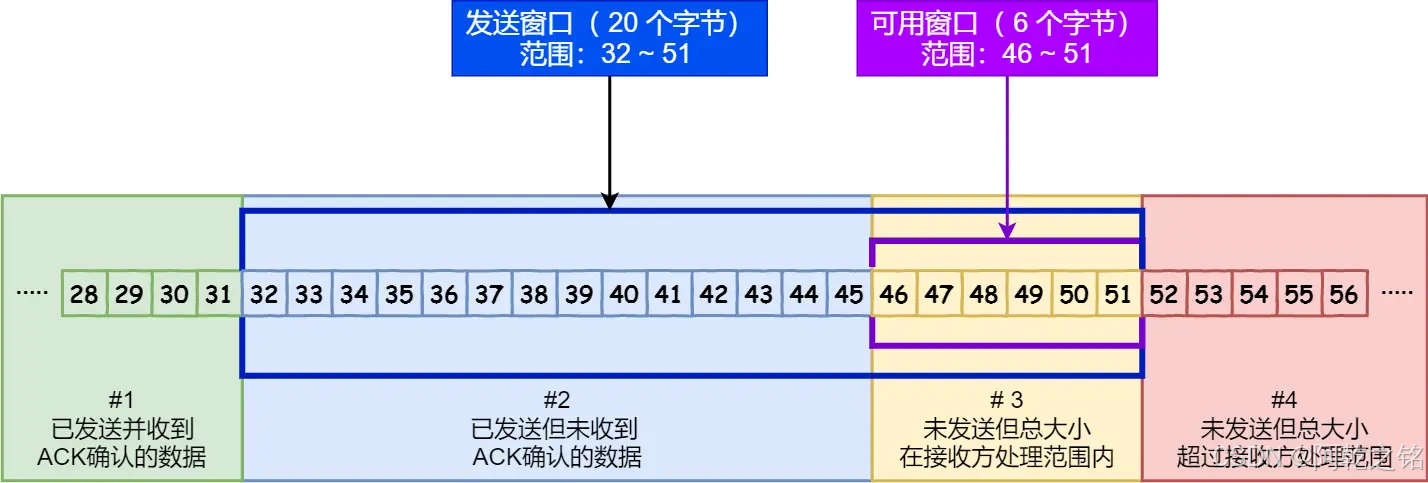
滑动窗口的基本概念
滑动窗口是一种 控制数据发送范围的窗口机制,可以简单理解为一个“允许发送的范围”。发送方可以连续发送窗口范围内的数据,而无需等待每一个数据包的确认。
- 发送窗口:发送方维护的窗口,用于控制允许发送但尚未被确认的数据范围。
- 接收窗口:接收方维护的窗口,表示当前接收缓存的大小,限制发送方的最大数据发送量。
- 窗口大小:窗口的大小由接收方决定,它会在 TCP 报文的头部通过
Window Size字段通知发送方。
滑动窗口的工作原理
1. 窗口范围与状态
发送窗口是一个动态滑动的范围,分为三部分:
- 已发送并确认的数据:这些数据已经被接收方收到并确认,不再需要保留。
- 已发送但未确认的数据:发送方需要等待接收方的 ACK 确认。
- 可发送但尚未发送的数据:发送方可以立即发送的数据。
2. 滑动过程
- 每当接收方确认一个数据包(发送 ACK),发送窗口就会向前滑动,腾出新的空间供发送方发送更多的数据。
- 如果接收方的接收能力(窗口大小)减小,发送窗口的范围也会相应减小。
4 拥塞控制与流量控制
-
流量控制:
- 目的是防止接收端处理不过来。
- 使用滑动窗口机制动态调整发送数据量。
-
拥塞控制:
- 目的是防止网络拥堵。
- 主要算法:
- 慢启动:初始阶段发送数据量较小,逐步增加。
- 拥塞避免:到达阈值后缓慢增长。
- 快速重传与快速恢复:检测到丢包后,快速降低发送速率并恢复。
1.2.2 UDP协议
UDP(User Datagram Protocol)是一种无连接、不可靠的传输协议,适用于需要快速传输的场景。
UDP的特点
- 无连接:无需建立连接,数据直接发送到目标。
- 不可靠:不保证数据一定能到达,不提供重传机制。
- 面向报文:每个UDP数据报都是独立的,大小在64KB以内。
- 快速:由于无连接和不保证可靠性,传输效率高。
UDP使用场景
- DNS查询:快速查询域名的IP地址,对可靠性要求低。
- 实时视频流:如在线视频、直播,对时延要求高,允许少量数据丢失。
- 在线游戏:实时性优先,可靠性次要。
1.2.3 TCP与UDP对比
| 特性 | TCP | UDP |
|---|---|---|
| 是否面向连接 | 面向连接(需三次握手、四次挥手) | 无连接 |
| 传输可靠性 | 可靠(确认应答、超时重传、滑动窗口) | 不可靠(无确认应答,可能丢包、乱序) |
| 传输效率 | 较低(有连接管理和数据校验的开销) | 高(无额外开销) |
| 流量控制与拥塞控制 | 有(滑动窗口、拥塞控制) | 无 |
| 适用场景 | 文件传输、电子邮件、网页浏览 | 实时视频、语音通话、DNS查询 |
1.3 网络层协议
1.3.1 IP协议
IP协议是网络层的核心,用来给每台设备分配一个“地址”,并通过这些地址实现设备之间的通信。
IPv4
IPv4 是我们最熟悉的 IP 地址版本。你可以把 IPv4 想象成“家庭住址”。
IPv4的格式
IPv4 地址是一个 32 位的数字,用“点”分隔成 4 段,每段可以是 0 到 255 之间的数字。
- 例子:
192.168.1.1 - 每台设备都需要有一个这样的地址,才能在网络上通信。
地址的两部分
IPv4 地址分为两部分:
- 网络部分:就像一个城市名称,表示设备在哪个网络。
- 主机部分:就像一条街道的门牌号,表示网络里的具体设备。
- 例子:
192.168.1.1,如果网络部分是192.168.1,主机部分就是最后的1。
IPv4的分类
IPv4 地址可以分为几类,就像城市规模大小不一样:
-
A类地址:超大的网络,适合几百万台设备。
- 地址范围:
1.0.0.0到126.255.255.255 - 例子:
10.0.0.1
- 地址范围:
-
B类地址:中型网络,适合几万台设备。
- 地址范围:
128.0.0.0到191.255.255.255 - 例子:
172.16.0.1
- 地址范围:
-
C类地址:小型网络,最多支持 256 台设备。
- 地址范围:
192.0.0.0到223.255.255.255 - 例子:
192.168.1.1
- 地址范围:
-
D类地址:专用于组播,表示一群设备一起接收消息。
IPv4的局限
IPv4 地址总共有 43 亿个,但今天全球有数十亿设备连上互联网,地址早就不够用了。为了解决这个问题,我们需要用到 IPv6。
IPv6
IPv6 是一种新版本的 IP 地址,使用 128 位来表示,比 IPv4 的 32 位多得多。你可以把它看成是“全球地址升级版”,确保每个设备都有独立的地址。
IPv6的格式
IPv6 的地址非常长,分为 8 组,用冒号 : 分隔。每组是 16 位,表示为 4 个十六进制数。
- 例子:
2001:0db8:85a3:0000:0000:8a2e:0370:7334
为了方便,IPv6 允许省略某些部分:
- 前面的零可以省略。
例子:2001:db8:85a3:0:0:8a2e:370:7334 - 连续的全零可以用
::代替一次。
例子:2001:db8:85a3::8a2e:370:7334
IPv6的优势
- 地址空间大到几乎用不完。每粒沙子都能分到几十个地址。
- 内置更强的安全性,支持数据加密和认证。
- 更高效:IPv6 消除了 IPv4 的广播机制,更加适合现代网络。
1.3.2 子网划分与CIDR
网络有大有小,有时候需要把一个大的网络划分成多个小网络,或者把几个小网络合并起来,这就需要用到 子网划分 和 CIDR。
-
IP地址本身不能单独区分网络部分和主机部分。
例如:192.168.1.1是一个 IP 地址,但光看这个地址,你无法知道它的网络范围是192.168.1.0还是192.168.0.0。 -
子网掩码的作用是帮助划分网络部分和主机部分。
- 它像一个标尺,告诉网络设备:
- 哪些位属于“网络部分”(网络地址)。
- 哪些位属于“主机部分”(主机地址)。
- 它像一个标尺,告诉网络设备:
举例:如果一个 IP 地址是 192.168.1.1,你需要知道它属于哪个子网:
- 如果子网掩码是
255.255.255.0,网络范围是192.168.1.0/24(前 24 位是网络部分)。 - 如果子网掩码是
255.255.0.0,网络范围是192.168.0.0/16(前 16 位是网络部分)。
CIDR
CIDR(无分类域间路由)是用一种更灵活的方式来管理网络地址。
CIDR格式
CIDR 用一个斜杠 / 后面跟数字表示网络的大小。
- 例子:
192.168.1.0/24/24表示前 24 位是网络部分,剩下的 8 位是主机部分。
CIDR的好处
- 更灵活:不再受传统 A/B/C 类地址限制,可以根据需要分配地址。
- 节省资源:避免浪费地址。
1.3.3 路由协议基础
路由的作用是帮忙“导航”。就像你用地图软件,路由器的工作就是决定“数据包”应该走哪条路。
静态路由
静态路由就是手动指定一条固定的路径,就像给快递员一个纸质地图。
优缺点
- 优点:简单可靠,适合小型网络。
- 缺点:如果路被堵(网络变化),快递员不知道该怎么办。
例子
假设你有两条网络:
192.168.1.0/2410.0.0.0/8
你可以告诉路由器:“所有去 10.0.0.0 的数据,都走 192.168.1.1 这条路”。
动态路由
动态路由更像是导航软件,能根据实时路况自动调整路线。它通过路由协议完成。
常见动态路由协议
- RIP(路由信息协议):
- 像快递员数路口,走最少路口的路(跳数最少)。适合小网络。
- OSPF(开放最短路径优先):
- 就像导航软件计算最短时间的路线。适合大型网络。
- BGP(边界网关协议):
- 专门为互联网设计,负责管理不同网络之间的路由。
1.3.4 ARP协议
ARP(地址解析协议)是一个帮忙“查找门牌号”的工具。
ARP的作用
在局域网里,数据需要通过 MAC 地址(设备的物理地址)发送,但我们通常只知道对方的 IP 地址。ARP 的作用是把 IP 地址“翻译”成 MAC 地址。
ARP的工作过程
假设你要寄信到 192.168.1.2:
- 你问:“谁是 192.168.1.2?告诉我你的门牌号(MAC 地址)。”
- 这个请求会广播给局域网的所有设备。
- 192.168.1.2 回答:“我是 192.168.1.2,我的 MAC 地址是 AA:BB:CC:DD:EE:FF。”
- 你记住这个地址,下一次寄信直接用,不用再问了。
1.4 应用层协议
应用层协议负责为用户提供直接的网络服务,如网页浏览、电子邮件、文件传输等。以下详细讲解 DNS协议、HTTP/HTTPS 和 电子邮件协议(SMTP、POP3、IMAP)。
1.4.1 DNS协议
DNS(Domain Name System)是“域名解析系统”,其作用是将 域名(如 www.google.com) 转换为 IP地址(如 142.250.185.206),方便人类记忆。
域名与IP地址
- 域名:供人类使用的地址,如
www.google.com。 - IP地址:供计算机通信使用的地址,如
142.250.185.206。 - 问题:因为人类记忆域名更方便,但计算机只能识别 IP 地址,因此需要一种“翻译服务”来将域名转换为 IP 地址,这就是 DNS 的作用。
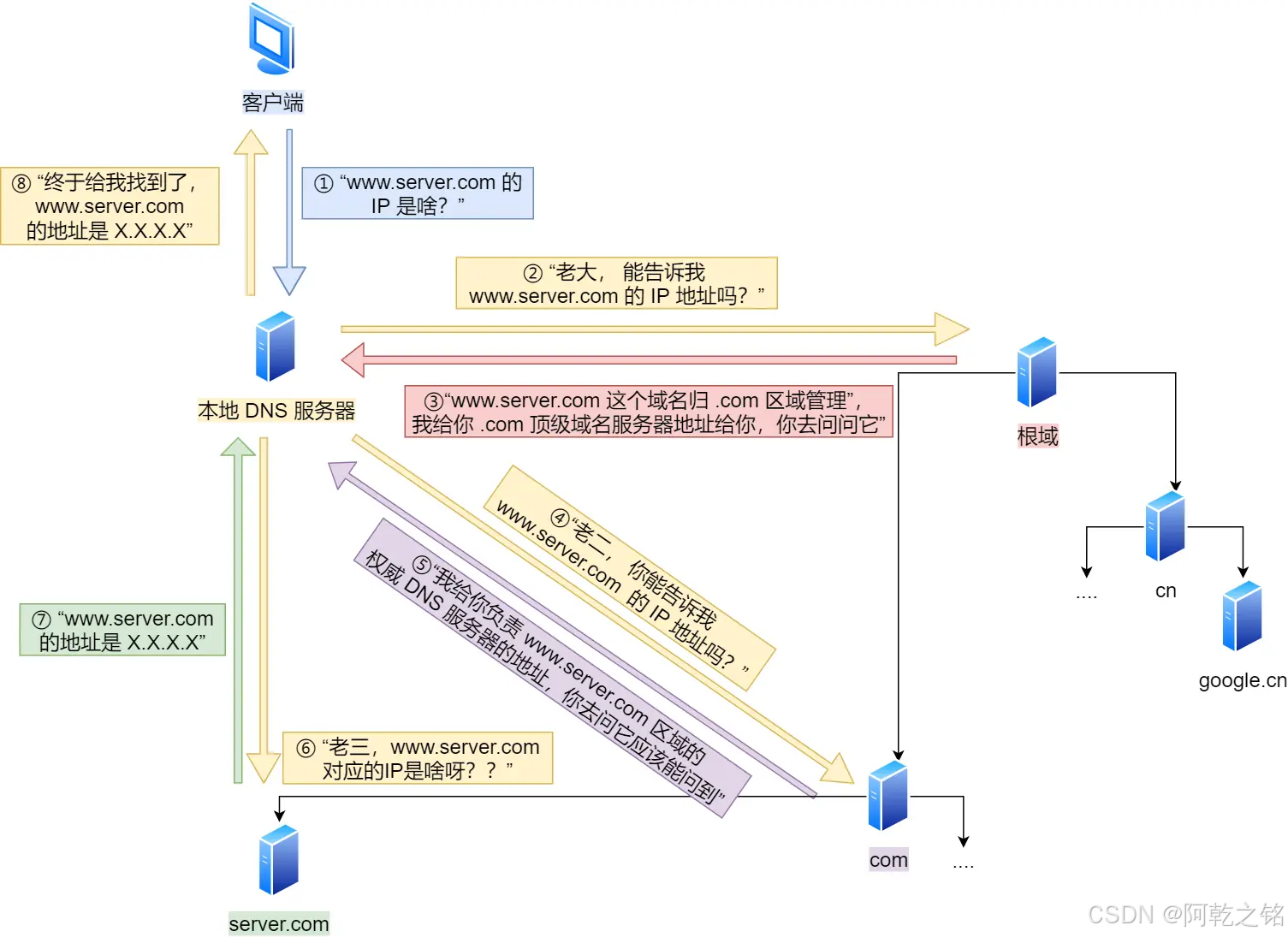
DNS的查询过程
-
客户端向本地 DNS 服务器发起请求
- 用户的设备(如浏览器)向运营商提供的本地 DNS 服务器发送查询请求,要求解析
www.google.com。本地 DNS 服务器称为 递归解析器,负责处理查询。
- 用户的设备(如浏览器)向运营商提供的本地 DNS 服务器发送查询请求,要求解析
-
本地 DNS 服务器检查缓存
- 本地 DNS 服务器会先检查自己的缓存中是否已有
www.google.com对应的 IP 地址:- 如果有,直接返回结果给客户端。
- 如果没有,向上级 DNS 服务器发起逐级查询。
- 本地 DNS 服务器会先检查自己的缓存中是否已有
-
逐级查询域名解析
本地 DNS 服务器开始查询:- 查询根服务器:
本地 DNS 服务器向根 DNS 服务器查询www.google.com。根服务器返回.com顶级域名服务器(TLD 服务器)的地址。 - 查询顶级域名服务器(TLD):
本地 DNS 服务器向.comTLD 服务器查询,TLD 服务器返回google.com的权威 DNS 服务器地址。 - 查询权威 DNS 服务器:
本地 DNS 服务器向google.com的权威 DNS 服务器查询,获取www.google.com的最终 IP 地址。
- 查询根服务器:
-
本地 DNS 服务器返回结果给客户端
- 本地 DNS 服务器将获取到的 IP 地址缓存起来(用于处理未来的相同查询),然后将结果返回给客户端。
1.4.1.3 常见 DNS 记录类型
-
A记录:
- 将域名解析为 IPv4 地址。
- 例子:
www.example.com -> 192.168.1.1
-
AAAA记录:
- 将域名解析为 IPv6 地址。
- 例子:
www.example.com -> 2400:cb00:2048:1::c629:d7a2
-
CNAME记录:
- 将一个域名指向另一个域名(别名记录)。
- 例子:
cdn.example.com -> www.example.com
-
MX记录:
- 指定域名的邮件服务器地址。
- 例子:
example.com -> mail.example.com
1.4.2 HTTP与HTTPS协议
1.4.2.1 HTTP协议
HTTP(HyperText Transfer Protocol)是应用层协议,用于传输网页内容。
-
特点:
- 无状态:每次请求独立,服务器不记住用户。
- 明文传输:数据不加密,容易被窃取。
- 使用 TCP 传输,默认端口 80。
-
工作过程:
- 客户端(如浏览器)向服务器发送 HTTP 请求(如 GET、POST 请求)。
- 服务器返回 HTTP 响应(如网页内容)。
-
应用场景:访问网页、接口通信等。
1.4.2.2 HTTPS协议
HTTPS 是 HTTP 的加密版,使用 SSL/TLS 协议对数据进行加密,增强安全性。
-
区别:
- 数据加密:HTTPS 使用 SSL/TLS 对数据加密,防止数据被窃听。
- 身份认证:HTTPS 通过数字证书验证服务器身份,防止伪装。
- 端口不同:HTTPS 默认使用 443 端口。
-
工作过程:
- 客户端向服务器发起 HTTPS 请求。
- 服务器返回数字证书,客户端验证证书。
- 建立加密连接,数据加密传输。
-
应用场景:银行网站、电商平台等需要保护用户隐私的场景。
1.4.3 电子邮件协议
电子邮件系统有三种常用协议:SMTP、POP3 和 IMAP,它们负责 发送 和 接收 邮件。
1.4.3.1 SMTP协议
SMTP(Simple Mail Transfer Protocol)是用来 发送邮件 的协议。
-
特点:
- 基于 TCP 协议,默认端口 25 或 587(加密)。
- 只能发送邮件,不能接收邮件。
-
工作过程:
- 客户端将邮件内容交给 SMTP 服务器。
- SMTP 服务器查找收件人的邮件服务器(使用 MX 记录)。
- SMTP 服务器将邮件传递到收件人的邮件服务器。
1.4.3.2 POP3协议
POP3(Post Office Protocol 3)是用来 接收邮件 的协议。
-
特点:
- 邮件会从服务器下载到本地,并在服务器中删除。
- 基于 TCP 协议,默认端口 110 或 995(加密)。
-
优点:
- 用户可以离线访问邮件。
- 适合只需在一个设备上管理邮件的场景。
-
缺点:
- 多设备之间无法同步邮件状态。
1.4.3.3 IMAP协议
IMAP(Internet Message Access Protocol)是另一种 接收邮件 的协议。
-
特点:
- 邮件保存在服务器上,客户端访问邮件的副本。
- 基于 TCP 协议,默认端口 143 或 993(加密)。
-
优点:
- 支持多设备同步邮件状态(如已读、未读)。
- 邮件不会被删除,适合多人协作管理。
-
缺点:
- 需要网络连接才能查看邮件内容。
总结
| 协议 | 作用 | 特点 | 常用端口 |
|---|---|---|---|
| DNS | 域名解析 | 将域名转换为 IP 地址 | 53 |
| HTTP | 网页传输 | 无状态、明文传输 | 80 |
| HTTPS | 安全网页传输 | 加密通信、身份认证 | 443 |
| SMTP | 发送邮件 | 用于传递邮件到邮件服务器 | 25/587 |
| POP3 | 接收邮件(下载) | 邮件从服务器下载到本地,不支持多设备同步 | 110/995 |
| IMAP | 接收邮件(同步) | 邮件保存在服务器,支持多设备同步 | 143/993 |
1.5 网络相关技术
1.5.1 NAT与端口映射
什么是 NAT?
NAT 的全称是 网络地址转换。它就像一个“地址翻译器”,让家里或公司里的多台设备通过一个公共地址访问互联网。
问题背景:为什么需要 NAT?
- IP 地址不够用:互联网用的是 IPv4 地址,但可用的 IPv4 地址非常有限,而全球有几十亿设备需要联网。
- 私有地址和公共地址的区别:
- 私有地址:家里或公司内部的设备,比如
192.168.1.1,只能在局域网内使用。 - 公共地址:可以在互联网中直接使用,比如
203.0.113.1。
- 私有地址:家里或公司内部的设备,比如
NAT 的作用是将内网(私有地址)转换成外网(公共地址),这样内网中的多台设备可以共享一个公共地址访问互联网。
NAT 是如何工作的?
假设你家里有三台设备(电脑、手机、平板),IP 地址分别是:
- 电脑:
192.168.1.2 - 手机:
192.168.1.3 - 平板:
192.168.1.4
你的路由器有一个公网 IP 地址,比如 203.0.113.1。当这些设备通过路由器访问互联网时,路由器会进行 NAT 翻译:
-
出站流量(内网到外网):
- 当你用手机(
192.168.1.3)访问www.google.com,路由器会把手机的私有 IP 地址换成203.0.113.1。 - 同时,路由器会记录下 手机的请求来源和端口号,以便稍后把返回的数据送回正确的设备。
- 当你用手机(
-
入站流量(外网到内网):
- 当 Google 的服务器返回数据时,数据先到达路由器的
203.0.113.1。 - 路由器通过记录找到最初发出请求的手机(
192.168.1.3),并把数据送到它。
- 当 Google 的服务器返回数据时,数据先到达路由器的
什么是端口映射?
端口映射是 NAT 的一种扩展功能,让外部设备可以主动访问内网设备。
例子:你想在外网访问家里的监控摄像头
- 你的摄像头 IP 是
192.168.1.100,端口号是8080。 - 你的路由器有公网 IP
203.0.113.1。 - 设置端口映射规则:
- 当外网设备访问
203.0.113.1:8080时,路由器会把请求转发给192.168.1.100:8080。
- 当外网设备访问
这样,你就能从外网访问家里的摄像头了。
1.5.2 防火墙与网络安全
什么是防火墙?
防火墙是一种保护网络的工具,可以阻止不安全的流量进入你的网络。
防火墙的作用
- 屏蔽恶意攻击:比如黑客想入侵你的电脑,防火墙会阻止它。
- 过滤流量:只允许合法的数据通过,不安全的数据被丢弃。
- 保护隐私:防止内部网络信息泄露。
防火墙的种类
- 硬件防火墙:像一个设备,用于保护整个网络,比如路由器上的防火墙功能。
- 软件防火墙:安装在电脑或手机上,比如 Windows 自带的防火墙。
防火墙是如何工作的?
防火墙就像“门卫”,每个数据包(互联网中的信息)都必须经过它的检查:
- 如果数据符合规则,就允许通过。
- 如果数据不符合规则,就拒绝通过。
例子:拦截恶意流量
- 规则:只允许端口 80(网页流量)通过,拒绝其他端口。
- 如果有人试图通过端口 22(SSH)连接到你的网络,防火墙会直接拒绝。
1.5.3 CDN 与内容分发
什么是 CDN?
CDN(内容分发网络)是一种技术,用来加速网站内容的访问速度。
问题背景:为什么需要 CDN?
- 网站服务器可能离用户很远,比如服务器在美国,而用户在中国,这会导致访问速度慢。
- 如果很多人同时访问一个网站,服务器可能会过载,导致无法响应。
CDN 是如何工作的?
- 分布式节点:CDN 在全球部署了许多服务器节点,就像“缓存站点”。
- 就近访问:当用户访问网站时,CDN 会引导用户连接到离自己最近的节点,而不是连接到原始服务器。
例子:访问一个大流量网站
- 你访问
www.example.com,实际连接到的是离你最近的 CDN 节点。 - CDN 节点上缓存了网站的内容(如图片、视频),你可以快速加载这些内容,而不用等待源服务器的响应。
1.5.4 负载均衡
什么是负载均衡?
负载均衡是一种技术,用来把用户的请求分配到多台服务器上,防止某一台服务器过载。
问题背景:为什么需要负载均衡?
- 如果只有一台服务器,可能无法处理大量用户请求,导致崩溃。
- 多台服务器可以提高系统的可靠性和性能,但需要一种方法来均匀分配流量。
负载均衡是如何工作的?
假设有 3 台服务器(A、B、C),你运行了一个负载均衡器,它会接收所有用户请求,然后根据某种规则分配请求:
常见的分配策略
-
轮询(Round Robin):
- 请求依次分配到 A、B、C,然后循环。
- 优点:简单,适合服务器性能差不多的场景。
-
最小连接数(Least Connections):
- 请求分配给当前负载最轻(连接数最少)的服务器。
- 优点:适合服务器性能不均的场景。
-
IP 哈希(IP Hash):
- 根据用户的 IP 地址计算哈希值,固定分配到某台服务器。
- 优点:用户每次请求都分配到同一台服务器,适合需要“会话保持”的场景(如购物车功能)。
二、HTTP协议基础
2.1 HTTP协议原理详细讲解
HTTP(HyperText Transfer Protocol)是应用层的核心协议,负责客户端(如浏览器)和服务器之间的数据交换。以下从 HTTP 的 无状态特性、报文结构、常见方法 和 状态码分类 四个方面详细讲解。
2.1.1 HTTP协议的无状态特性及状态保持
1. 什么是 HTTP 的无状态特性?
无状态:每次 HTTP 请求是独立的,服务器不会记住之前发生的请求。
例子:当你访问某个网站的页面 A,再访问页面 B,服务器并不知道你之前访问过页面 A。
优点:简化了服务器的设计,方便扩展。
缺点:无法直接跟踪用户状态(如登录状态、购物车)。
2. 如何通过 Session 和 Cookie 实现状态保持?
为了弥补 HTTP 无状态的缺陷,使用 Session(会话) 和 Cookie(小数据存储) 来保存用户的状态。
1)Cookie
- Cookie 是存储在客户端的小数据,由服务器生成并发送给客户端。
- 浏览器在后续的请求中会自动携带 Cookie 发送给服务器,用来标识用户。
- 例子:
- 服务器发送一个 Cookie:
Set-Cookie: session_id=12345; Expires=Wed, 21 Oct 2024 07:28:00 GMT - 浏览器后续访问时会携带:
Cookie: session_id=12345
- 服务器发送一个 Cookie:
2)Session
- Session 是存储在服务器端的数据结构,用来记录用户状态。
- 浏览器通过 Cookie 保存一个唯一的
Session ID,服务器根据这个 ID 找到用户的会话数据。 - 例子:
- 用户登录后,服务器为其创建一个 Session,分配 ID
12345。 - 用户的购物车信息保存在服务器的 Session 中。
- 用户登录后,服务器为其创建一个 Session,分配 ID
2.1.2 HTTP报文结构
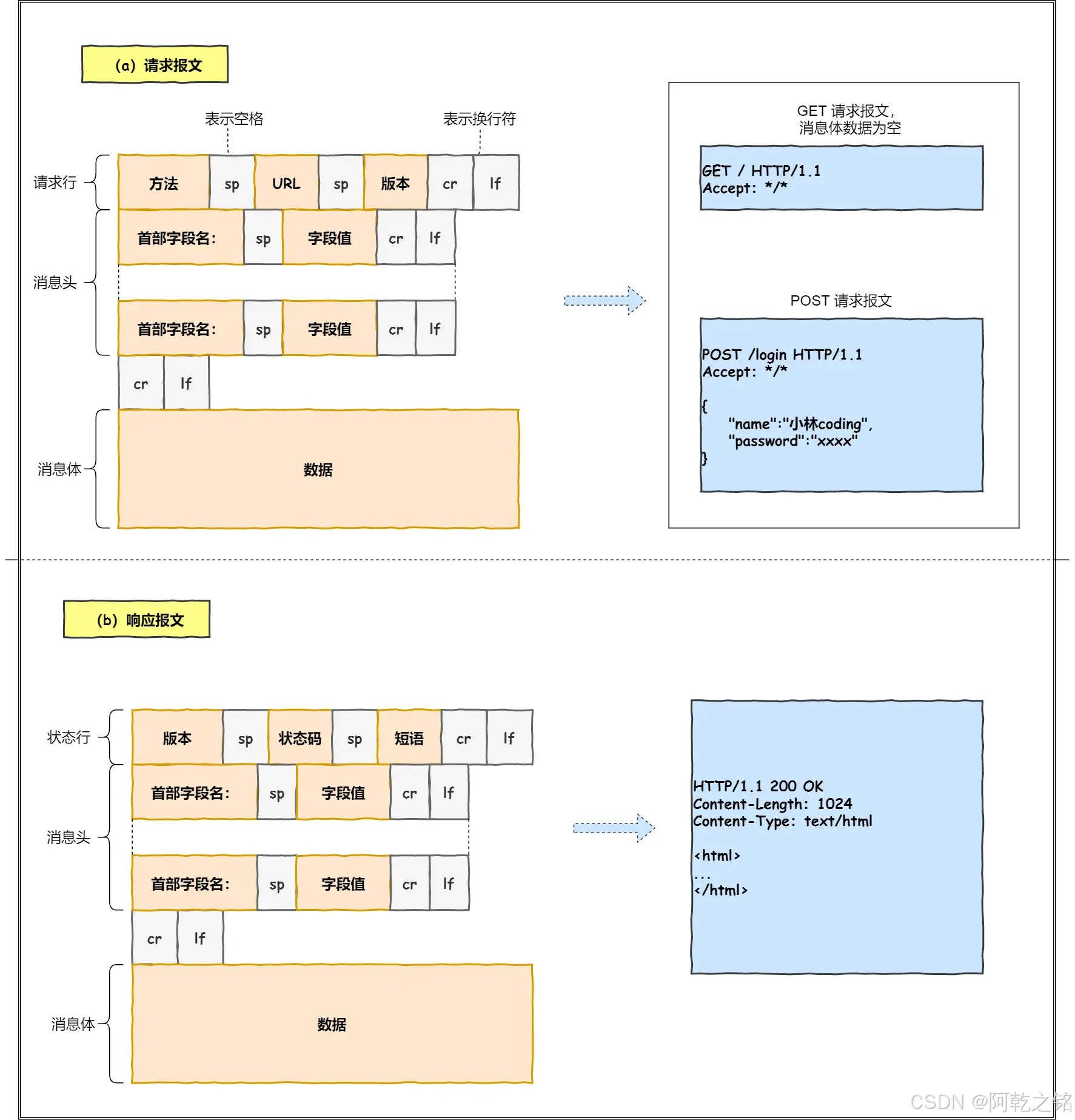
HTTP 报文是客户端和服务器之间通信的数据格式,分为 请求报文 和 响应报文。
1. 请求报文结构
请求报文是客户端发送给服务器的内容,结构如下:
1)起始行
描述请求的基本信息,包括 方法、URL 和 协议版本。
- 格式:
<方法> <请求URL> <协议版本> - 例子:
GET /index.html HTTP/1.1
2)请求头
提供请求的附加信息(元数据)。
常见字段:
- Host:指定目标主机,如
Host: www.example.com - User-Agent:客户端信息,如浏览器版本
- Accept:客户端可接受的内容类型
- Content-Type(POST 请求常用):请求体的数据格式,如
application/json
3)请求体
包含实际的数据内容(通常在 POST 或 PUT 请求中)。
例子(POST 提交表单数据):
Content-Type: application/x-www-form-urlencoded
username=alice&password=1234
2. 响应报文结构
响应报文是服务器返回给客户端的内容,结构如下:
1)状态行
描述响应的状态,包括 协议版本、状态码 和 原因短语。
- 格式:
<协议版本> <状态码> <原因短语> - 例子:
HTTP/1.1 200 OK
2)响应头
提供响应的附加信息。
- 常见字段:
- Content-Type:返回内容类型,如
text/html - Content-Length:内容长度
- Set-Cookie:服务器设置的 Cookie
- Content-Type:返回内容类型,如
3)响应体
返回的实际数据内容(如网页 HTML、JSON 数据)。
例子(返回一个简单网页):
<html>
<body>
<h1>Welcome!</h1>
</body>
</html>
| 符号 | 含义 | 用途 | ASCII 值 |
|---|---|---|---|
| SP | 空格(Space) | 用于分隔起始行或状态行中的字段 | 32 |
| CR | 回车(Carriage Return) | 标志行的结束,与 LF 配合使用 | 13 |
| LF | 换行(Line Feed) | 与 CR 一起完成行的终止操作 | 10 |
2.1.3 常见 HTTP 方法
HTTP 定义了多种方法,用于描述客户端的操作。
| 方法 | 功能 | 说明 |
|---|---|---|
| GET | 请求数据 | 用于获取资源,不修改服务器数据。 |
| POST | 提交数据 | 用于发送数据给服务器(如表单数据)。 |
| PUT | 更新数据 | 替换服务器上的资源(幂等操作)。 |
| DELETE | 删除数据 | 删除服务器上的资源。 |
| HEAD | 请求头信息 | 类似 GET,但只返回响应头,不返回响应体。 |
| OPTIONS | 查询支持的方法 | 获取服务器支持的 HTTP 方法,用于跨域请求预检等场景。 |
2.1.4 HTTP状态码分类及应用场景
状态码是服务器在响应报文中返回的数字,用来描述请求的处理结果。
2xx 成功
- 200 OK:请求成功,服务器返回请求的资源。
- 例子:用户成功打开网页。
- 201 Created:资源成功创建(常用于 POST)。
- 例子:用户成功提交表单,创建了一条记录。
3xx 重定向
- 301 Moved Permanently:资源已永久移动到新地址。
- 例子:网站域名变更,将旧域名重定向到新域名。
- 302 Found:资源临时移动到新地址。
- 例子:用户访问一个链接,服务器临时引导到另一个页面。
4xx 客户端错误
- 400 Bad Request:请求无效,可能是语法错误或参数不正确。
- 例子:用户提交了格式错误的表单数据。
- 404 Not Found:请求的资源不存在。
- 例子:用户访问了一个不存在的页面。
5xx 服务器错误
- 500 Internal Server Error:服务器内部错误,无法完成请求。
- 例子:服务器代码崩溃导致请求失败。
- 503 Service Unavailable:服务器暂时过载或维护。
- 例子:高并发时服务器无法响应请求。
2.2 HTTP性能优化
2.2.1 HTTP长连接与短连接
HTTP通信中,客户端(比如浏览器)和服务器需要通过网络连接来传输数据。这种连接可以分为 短连接 和 长连接。
1. 短连接(Connection: close)
短连接是什么?
-
短连接的特点是:每次请求完成后,连接就关闭了。
-
每当客户端想请求新的数据,就需要重新建立连接,这包括一个耗时的 TCP三次握手 过程。
短连接的流程:
-
浏览器向服务器发起一个请求,比如加载网页的 HTML 文件。
-
服务器处理请求并返回 HTML 文件后,连接关闭。
-
如果浏览器还要加载网页上的图片、CSS、JS 文件,则需要重新建立连接。
缺点:
-
每次请求都需要建立和关闭连接,增加了额外的时间消耗。
-
对服务器压力较大,因为频繁的连接和断开需要耗费资源。
例子:
浏览器加载一个网页,网页包含 HTML、5 张图片、CSS 文件。短连接模式下,浏览器需要 建立 7 次连接(HTML + 5 图片 + CSS),每次连接都需要三次握手,浪费时间。
2. 长连接(Connection: keep-alive)
长连接是什么?
-
长连接的特点是:一个连接可以重复使用,直到客户端或服务器主动关闭。
-
在一个连接上,可以传输多个请求和响应。
长连接的流程:
-
浏览器建立一个连接,请求网页的 HTML 文件。
-
同一个连接上,继续请求网页中的图片、CSS 文件等资源。
-
浏览器加载完成后,连接保持一段时间,等待是否还有新的请求。
优点:
-
避免了频繁建立和关闭连接的开销。
-
提升了网页加载速度,特别是多资源网页(比如图片多的页面)。
例子:
浏览器加载同样的网页时,长连接模式下只需 建立一次连接,所有资源(HTML、图片、CSS)都在这个连接上完成传输。
如何实现?
通过 HTTP 报文中的 Connection 字段实现:
-
短连接:
Connection: close -
长连接:
Connection: keep-alive
长连接是现代 HTTP 的默认模式(从 HTTP/1.1 开始),因此多数情况下不需要手动设置。
2.2.2 HTTP缓存机制
HTTP缓存是性能优化的关键,它能让浏览器直接从本地缓存中加载资源,而不需要每次都向服务器请求。
1. 强缓存
强缓存是什么?
-
浏览器在缓存有效期内,直接从本地加载资源,而无需发送请求到服务器。
-
特点:浏览器直接加载资源,不与服务器通信。
实现方式
Expires(HTTP/1.0):
-
指定资源的到期时间,格式是一个绝对时间。
例子:
Expires: Wed, 22 Nov 2024 08:00:00 GMT
-
问题:如果客户端的本地时间不准确,可能导致缓存失效或过期。
Cache-Control(HTTP/1.1):
-
使用相对时间,表示资源的有效期,弥补了
Expires的不足。 -
常见指令:
-
max-age=3600:资源缓存 3600 秒(1 小时)。 -
no-cache:每次使用前需要与服务器验证(即协商缓存)。 -
no-store:不缓存资源。
-
强缓存的优点
-
浏览器不需要发送请求,直接从本地加载资源,速度非常快。
-
减少了服务器的负担。
2. 协商缓存
协商缓存是什么?
-
当强缓存失效时,浏览器会向服务器验证缓存是否有效。
-
如果缓存有效,服务器返回 304 Not Modified 状态码,客户端继续使用本地缓存。
-
如果缓存无效,服务器返回新的资源。
实现方式
-
Last-Modified 和 If-Modified-Since:
-
Last-Modified:服务器返回资源的最后修改时间。
-
If-Modified-Since:浏览器在请求中携带
Last-Modified时间,询问服务器资源是否更新。 -
问题:如果资源内容没变,但文件时间戳更新了,会导致缓存失效。
-
-
ETag 和
If-None-Match:-
ETag:服务器返回资源的唯一标识(如哈希值)。
-
If-None-Match:浏览器携带 ETag 值请求服务器验证资源是否更新。
-
优点:更精确,内容不变时缓存不会失效。
-
强缓存和协商缓存的关系
-
浏览器先检查 强缓存 是否有效。
-
如果强缓存失效,再发起 协商缓存 请求。
2.2.3 使用 Gzip 压缩减少传输数据量
1. 什么是 Gzip 压缩?
-
Gzip 是一种压缩算法,用来减少 HTTP 响应数据的大小。
-
它将原始数据压缩后发送给客户端,客户端解压后再使用。
2. 如何实现 Gzip 压缩?
-
客户端声明支持压缩: 浏览器通过请求头
Accept-Encoding告诉服务器支持哪些压缩算法:Accept-Encoding: gzip, deflate -
服务器压缩内容并返回: 如果服务器支持 Gzip 压缩,会在响应头中添加:
Content-Encoding: gzip -
客户端解压: 浏览器解压收到的内容,显示给用户。
3. Gzip 的优势
-
减少传输数据量:特别是对 HTML、CSS、JavaScript 等文本文件效果显著。
- 加快加载速度:数据更小,传输时间更短。
2.2.4 CDN 优化传输路径
1. 什么是 CDN?
CDN(内容分发网络)通过分布式的缓存服务器,将内容传输到离用户最近的节点,从而加快加载速度。
2. CDN 的工作原理
-
用户请求网站内容时,DNS 会将请求指向离用户最近的 CDN 节点。
-
CDN 节点返回缓存的内容(如图片、视频、网页)。
-
如果 CDN 节点没有内容,则从源服务器获取,并缓存下来供后续请求使用。
3. CDN 的优势
-
加速访问:
-
用户连接到最近的 CDN 节点,减少网络延迟。
-
-
分担服务器压力:
-
CDN 节点承担了大部分流量,源服务器的负载大大降低。
-
-
提高可靠性:
-
即使某些节点故障,其他节点仍可提供服务。
-
三、HTTPS协议与安全
3.1 HTTPS基本原理详细讲解
HTTPS(HyperText Transfer Protocol Secure)是基于 HTTP 的安全通信协议,使用加密技术保障数据传输的 保密性、完整性 和 真实性。它的核心是加密与认证
3.1.1 非对称加密与对称加密的区别
在 HTTPS 中,加密技术分为两种:对称加密 和 非对称加密。两者各有优缺点,通常配合使用。
1. 对称加密
什么是对称加密?
- 加密和解密使用同一个密钥。
- 特点:
- 加密和解密速度快,适合大规模数据传输。
- 但密钥必须在通信双方之间安全传输,一旦密钥泄露,数据就不再安全。
例子:
- 假设你用密码
123456加密消息Hello,对方也需要用同样的密码解密:Copy code
加密:Hello + 密钥123456 = 加密数据 解密:加密数据 + 密钥123456 = Hello
优缺点:
| 优点 | 缺点 |
|---|---|
| 加密速度快 | 密钥的传输与管理不安全 |
| 算法简单,资源占用少 | 无法实现多方安全通信 |
2. 非对称加密
什么是非对称加密?
- 加密和解密使用不同的密钥:公钥(Public Key)和私钥(Private Key)。
- 公钥公开,用于加密。
- 私钥保密,用于解密。
工作原理:
- 数据加密:发送方用对方的 公钥 加密数据。
-
数据解密:接收方用自己的 私钥 解密数据。
例子:
-
假设服务器生成了一对密钥:
-
公钥(公开):用于加密。
-
私钥(秘密):用于解密。
-
-
浏览器向服务器发送敏感数据时,使用服务器的公钥加密,只有服务器能用私钥解密。
优缺点:
| 优点 | 缺点 |
|---|---|
| 无需共享密钥,安全性更高 | 加密解密速度较慢 |
| 适合多方通信 | 算法复杂,占用更多资源 |
3. HTTPS 中如何结合使用?
- 非对称加密 用于安全地传输 对称加密的密钥。
- 对称加密 用于高效传输实际的数据。
3.1.2 数字证书与 CA 机构的作用
1. 数字证书是什么?
数字证书是由权威机构签发的一种电子文档,用于证明网站的真实性,防止中间人攻击。
数字证书的内容
- 网站的域名。
- 网站的公钥。
- 证书的有效期。
- 证书颁发机构(CA)的信息。
- 颁发机构的数字签名。
2. 为什么需要 CA 机构?
CA(Certificate Authority,证书颁发机构)是数字证书的签发方,用来证明证书的合法性。
- 问题:如果一个网站告诉你它的公钥,如何确认这个公钥是可信的?
- 解决:CA 机构通过数字签名证明该公钥确实属于这个网站。
CA 的作用
- 颁发数字证书。
- 验证证书的合法性。
- 确保网站的身份真实可靠。
工作流程
- 网站向 CA 提交申请,证明其身份(如域名所有权)。
- CA 验证身份后,签发数字证书。
- 浏览器在访问网站时,验证证书是否由受信任的 CA 签发。
3.1.3 HTTPS 握手过程
HTTPS 的核心是 SSL/TLS 协议。在浏览器和服务器建立安全连接前,会进行一次 TLS/SSL 握手。握手过程中完成 加密算法协商、身份认证 和 对称密钥的生成。
1. HTTPS 握手的主要步骤
假设用户的浏览器(客户端)访问某个 HTTPS 网站(服务器),握手过程如下:
1. 客户端向服务器发送加密能力信息
浏览器发送一个请求,包含:
-
支持的 加密算法(如 AES、RSA)。
-
一个随机数(
Client Random),用于生成对称密钥。
2. 服务器响应,并发送数字证书
服务器从中选择一个加密算法。
服务器返回:
-
数字证书,包含网站的公钥和域名信息。
-
一个随机数(
Server Random),用于生成对称密钥。
3. 客户端验证数字证书的合法性
浏览器检查证书是否由受信任的 CA 签发:
-
验证 CA 的签名。
-
确认证书的域名和有效期。
如果验证失败,浏览器会警告用户网站不安全。
4. 客户端生成对称密钥并加密发送
-
浏览器生成一个随机数(对称密钥种子)。
-
使用服务器的公钥加密该种子,并发送给服务器。
5. 服务器用私钥解密对称密钥种子
-
服务器用私钥解密,得到对称密钥种子。
-
通过客户端和服务器双方的随机数以及种子,生成最终的对称密钥。
6. 使用对称加密开始传输数据
-
握手完成后,浏览器和服务器使用协商好的 对称密钥 加密后续的通信内容(如网页内容、用户数据)。
2. HTTPS 握手过程的安全性
- 公钥加密确保密钥传输安全:即使中间人截获数据,也无法解密对称密钥种子。
- 对称加密提高传输效率:数据传输中只使用对称加密,速度更快。
- 证书认证防止中间人攻击:CA 签名确保公钥的可信性。
3.2 HTTPS常见问题详细讲解
HTTPS 在提供安全通信的同时,也面临一些常见问题,比如 中间人攻击、性能优化 和 混合内容问题。以下从这三方面详细展开讲解,并提供解决思路。
3.2.1 中间人攻击与证书校验
1. 什么是中间人攻击?
中间人攻击(Man-In-The-Middle Attack,MITM)是指攻击者插入客户端和服务器之间,拦截和篡改双方的通信内容。
中间人攻击的工作原理
-
攻击者伪装成服务器:
-
用户访问 HTTPS 网站时,中间人提供伪造的证书,使客户端误以为自己连接的是目标服务器。
-
-
攻击者截获通信内容:
-
攻击者通过伪造证书解密用户数据后,再将篡改或重新加密的数据转发给真正的服务器。
-
中间人攻击的危害
-
窃取敏感信息(如密码、信用卡号)。
-
篡改通信内容,导致数据不可信。
2. 如何防止中间人攻击?
HTTPS 防止中间人攻击的关键在于 证书校验 和 密钥加密。
2.1 证书校验
浏览器通过以下方式验证数字证书:
-
证书链验证:检查证书是否由受信任的 CA 签发。
-
域名匹配:确保证书中的域名与访问的域名一致。
-
有效期检查:验证证书是否过期。
如果证书不合法,浏览器会警告用户,显示“不安全的连接”。
2.2 密钥加密
-
在握手过程中,客户端使用服务器的公钥加密敏感信息,只有持有私钥的服务器才能解密。
-
即使中间人截获加密数据,也无法解密。
3. 中间人攻击的防御措施
-
强制使用 HTTPS:通过 HTTP Strict Transport Security(HSTS)防止用户访问 HTTP 版本。
-
正确配置证书:
-
选择权威 CA 签发的证书。
-
定期更新证书,确保在有效期内。
-
-
启用证书透明度(Certificate Transparency):
-
防止恶意 CA 签发伪造证书。
-
-
DNSSEC(域名系统安全扩展):
-
防止 DNS 劫持引导用户到错误的服务器。
-
3.2.2 HTTPS性能优化:减少握手延迟
1. HTTPS 握手的延迟来源
HTTPS 握手相比 HTTP 增加了额外的通信步骤,主要延迟包括:
-
TCP 握手:浏览器和服务器建立连接,耗时 1 RTT(Round-Trip Time,单程往返时间)。
-
TLS/SSL 握手:完成加密算法协商、证书校验和密钥交换,耗时 1~2 RTT。
2. HTTPS 性能优化方法
2.1 启用 TLS 1.3
-
优势:TLS 1.3 简化了握手流程,将耗时从 2 RTT 减少到 1 RTT。
-
如何实现:升级服务器和客户端支持 TLS 1.3。
2.2 会话复用
-
什么是会话复用?
-
如果客户端与服务器已经建立过 TLS 会话,后续连接可以复用会话信息,而无需重新握手。
-
-
实现方法:
-
Session ID:服务器保存会话信息,客户端通过 ID 复用。
-
Session Ticket:会话信息保存在客户端,由服务器解密使用。
-
2.3 启用 HTTP/2
-
HTTP/2 的优势:
-
支持多路复用(Multiplexing),允许一个连接同时传输多个请求和响应。
-
减少了连接数量,提升传输效率。
-
-
实现方法:确保服务器支持 HTTP/2。
2.4 使用 CDN
-
优化点:
-
缓存内容:减少服务器负载。
-
就近节点:降低网络延迟。
-
-
实现方法:将网站内容托管到 CDN 服务上。
2.5 缓存证书链
-
原理:浏览器缓存服务器的证书链,减少重复验证的开销。
-
实现方法:启用 OCSP Stapling,服务器主动提供证书状态,无需客户端每次查询。
3.2.3 配置 HTTPS 时混合内容(Mixed Content)问题
1. 什么是混合内容?
混合内容是指在 HTTPS 页面中加载了不安全的 HTTP 资源(如图片、CSS、JS 文件)。这些不安全的资源会破坏 HTTPS 的安全性。
混合内容的分类
- 主动混合内容:影响页面结构或行为的资源(如 JS 文件)。
- 危害:攻击者可能篡改 JS 文件,执行恶意代码。
- 被动混合内容:不影响页面结构的资源(如图片)。
- 危害:攻击者可能篡改图片内容,但不会直接危害页面功能。
2. 混合内容的危害
- 降低页面安全性:攻击者可以通过 HTTP 资源注入恶意代码,绕过 HTTPS 加密。
- 用户信任受损:浏览器会警告用户页面不安全,影响用户体验。
3. 如何解决混合内容问题?
3.1 确保所有资源使用 HTTPS
- 解决方式:
- 将资源链接从
http://改为https://。 - 如果资源不支持 HTTPS,替换为其他安全的资源。
- 将资源链接从
3.2 使用 Content Security Policy(CSP)
- 作用:通过 CSP 指定页面允许加载的资源源。
- 配置示例: 在 HTTP 响应头中添加:
Content-Security-Policy: upgrade-insecure-requests; - 作用:自动将 HTTP 请求升级为 HTTPS。
3.3 配置自动重定向
- 解决方式:
- 在服务器端配置规则,将所有 HTTP 请求重定向到 HTTPS。
- 示例(Nginx 配置):
server { listen 80; server_name example.com; return 301 https://$host$request_uri; }
四、Java开发中的网络通信
4.1 基础网络通信详细讲解
网络通信是通过 Socket(套接字)建立连接并传输数据的,主要分为两种协议:TCP(可靠、面向连接) 和 UDP(无连接、快速)。
4.1.1 使用 Socket 和 ServerSocket 实现 TCP 通信
1. TCP协议简介
-
TCP(Transmission Control Protocol) 是面向连接的协议,保证数据传输的可靠性。
-
通信双方在传输数据前需要建立连接,数据传输后需要释放连接。
-
适用于需要数据完整性和可靠性的场景,例如文件传输、Web 服务。
2. TCP 通信的基本原理
-
服务器端:
-
创建
ServerSocket,绑定指定端口。 -
监听客户端连接请求。
-
客户端连接后,通过
Socket对象进行数据交互。
-
-
客户端:
-
创建
Socket,指定服务器地址和端口。 -
连接服务器后,发送或接收数据。
-
4.1.2 使用 DatagramSocket 实现 UDP 通信
1. UDP协议简介
-
UDP(User Datagram Protocol) 是无连接的协议,数据以独立的数据包形式发送。
-
传输速度快,但不保证数据可靠性。
-
适用于实时通信场景,如视频直播、在线游戏。
2. UDP 通信的基本原理
-
服务器端:
-
创建
DatagramSocket,绑定指定端口。 -
等待接收客户端发送的 数据包(DatagramPacket)。
-
-
客户端:
-
创建
DatagramSocket。 -
发送数据包到指定的服务器地址和端口。
-
4.1.3 Java NIO(非阻塞 I/O 模型)(处理 TCP 通信)
Java NIO 是对传统阻塞 I/O 的改进,采用 非阻塞模型,提高了多客户端处理的效率。
- 非阻塞 I/O:一个线程处理多个客户端连接,避免线程阻塞。
- 高效并发:适合高并发场景。
NIO 的核心组件
Selector
-
Selector 是 NIO 的核心:通过一个线程管理多个通道(Channel)。
-
允许同时处理多个连接,提高了服务器的并发能力。
Channel
-
Channel 类似于传统的 Socket,但支持非阻塞模式。
-
常见的通道类型:
-
SocketChannel:处理 TCP 客户端连接。 -
ServerSocketChannel:处理 TCP 服务端连接。
-
Buffer
- Buffer 是数据的容器,用于读取或写入数据。
- 代替传统 I/O 的流(Stream)模型,支持更灵活的数据管理。
4.1.4.总结
| 通信方式 | 特点 | 适用场景 |
|---|---|---|
| Socket+ServerSocket | 简单、可靠,适合小规模 TCP 通信。 | 文件传输、聊天应用。 |
| DatagramSocket | 快速,无连接,但数据不可靠。 | 视频直播、在线游戏。 |
| Java NIO | 高性能、非阻塞,支持多客户端并发通信。 | 大规模并发服务器,如 Web 服务。 |
4.2 HTTP协议的Java实现
4.2.1 使用 HttpURLConnection 发送 HTTP 请求
简介
-
HttpURLConnection是 Java 标准库提供的类,用于发送 HTTP 请求和处理响应。 -
它支持常见的 HTTP 方法(如 GET、POST、PUT、DELETE)。
实际应用
-
适用于非 Spring 项目或轻量级任务,例如独立工具类程序中发送 HTTP 请求。
-
在现代 Spring 应用中,推荐使用更高级的工具如
RestTemplate或WebClient。
使用步骤
-
创建
URL对象,并调用openConnection()获取连接。 -
设置请求方法(如
GET或POST)和请求头。 -
如果是 POST 或 PUT 请求,写入请求体数据。
-
读取服务器的响应。
注意:HttpURLConnection 需要手动管理流和连接,代码较为冗长,且不支持现代特性如异步编程或响应式流。
4.2.2 使用 RestTemplate 和 WebClient(Spring)
1. SpringMVC 与 HTTP 客户端的区别
SpringMVC 的作用
-
SpringMVC 是服务端的“入口”,负责接收外部客户端(如浏览器或其他服务)的 HTTP 请求,并返回响应。
-
例如,当用户访问
/users接口时,SpringMVC 通过控制层(@RestController)接收请求并处理业务逻辑。
HTTP 客户端的作用
-
RestTemplate和WebClient是用于主动发送 HTTP 请求的工具。 -
它们是服务端作为“客户端”调用其他服务的 API,例如:
-
调用支付网关的接口。
-
从天气 API 获取实时天气数据。
-
微服务间通信。
-
2. 使用 RestTemplate(同步阻塞模式)
简介
-
RestTemplate是 Spring 提供的同步 HTTP 客户端工具。 -
它采用阻塞模式:调用线程会等待请求完成后,才继续执行后续任务。
实际场景
-
微服务之间的调用,例如从订单服务获取用户信息。
-
调用第三方 API,例如物流服务的接口。
使用步骤
1.配置 RestTemplate。
2.使用以下常用方法发送请求:
-
getForObject():发送 GET 请求并返回响应体。 -
postForEntity():发送 POST 请求并返回响应。 -
exchange():支持自定义请求头、方法等内容。
代码示例:实际使用 RestTemplate
配置 RestTemplate 在 Spring Boot 中,将 RestTemplate 注册为一个 Bean:
@Configuration
public class RestTemplateConfig {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
发送 GET 请求 在控制层调用远程 API:
@RestController
@RequestMapping("/api")
public class ApiController {
private final RestTemplate restTemplate;
public ApiController(RestTemplate restTemplate) {
this.restTemplate = restTemplate;
}
@GetMapping("/get-data")
public String getData() {
String url = "https://jsonplaceholder.typicode.com/posts/1";
return restTemplate.getForObject(url, String.class); // 获取 JSON 响应
}
}
发送 POST 请求 通过 RestTemplate 提交数据到远程服务:
@PostMapping("/create-data")
public String createData() {
String url = "https://jsonplaceholder.typicode.com/posts";
String requestBody = "{ \"title\": \"foo\", \"body\": \"bar\", \"userId\": 1 }";
return restTemplate.postForObject(url, requestBody, String.class); // 提交数据并返回结果
}
3. 使用 WebClient(异步非阻塞模式)
简介
-
WebClient是 Spring WebFlux 提供的响应式 HTTP 客户端工具。 -
它采用异步非阻塞模式,线程不会等待请求完成,可以并行处理多个任务。
实际场景
-
高并发场景,例如实时流数据处理。
-
微服务间通信,需要组合多个 API 调用结果。
使用步骤
1.配置 WebClient。
2.使用以下常用方法发送请求:
-
get():发送 GET 请求。 -
post():发送 POST 请求。 -
retrieve():触发请求并获取响应。
代码示例:实际使用 WebClient
配置 WebClient 在 Spring Boot 中,通过 WebClient.Builder 配置:
@Configuration
public class WebClientConfig {
@Bean
public WebClient webClient() {
return WebClient.builder().build();
}
}
发送 GET 请求 通过 WebClient 以异步方式获取数据:
@RestController
@RequestMapping("/api")
public class ApiController {
private final WebClient webClient;
public ApiController(WebClient webClient) {
this.webClient = webClient;
}
@GetMapping("/get-data")
public Mono<String> getData() {
String url = "https://jsonplaceholder.typicode.com/posts/1";
return webClient.get()
.uri(url)
.retrieve()
.bodyToMono(String.class); // 返回 Mono 响应
}
}
发送 POST 请求 通过 WebClient 提交数据并异步处理结果:
@PostMapping("/create-data")
public Mono<String> createData() {
String url = "https://jsonplaceholder.typicode.com/posts";
String requestBody = "{ \"title\": \"foo\", \"body\": \"bar\", \"userId\": 1 }";
return webClient.post()
.uri(url)
.bodyValue(requestBody)
.retrieve()
.bodyToMono(String.class); // 返回 Mono 响应
}
4. RestTemplate 与 WebClient 的区别
| 特性 | RestTemplate | WebClient |
|---|---|---|
| 模式 | 同步阻塞模式 | 异步非阻塞模式 |
| 线程利用 | 线程会等待请求完成,资源利用率较低 | 线程立即返回,可高效处理更多任务 |
| 适用场景 | 简单、传统的 API 调用场景 | 高并发、高性能场景,或实时数据处理 |
| 响应数据 | 返回直接的数据对象(如 String) | 返回响应式对象(如 Mono 或 Flux) |
| 复杂性 | 简单易用,逻辑直观 | 需要理解响应式编程,复杂性较高 |
| Spring 推荐 | 推荐逐步淘汰,用 WebClient 替代 | 推荐用于现代化微服务开发 |
4.2.3 配置 Spring Boot 处理跨域(CORS)
1. 什么是跨域(CORS)
-
CORS(跨域资源共享)允许不同来源的客户端访问你的服务。
-
默认情况下,浏览器限制跨域请求,需要通过 CORS 配置解决。
2. 配置方法
全局配置
通过 addCorsMappings() 配置跨域规则:
@Configuration
public class CorsConfig {
@Bean
public WebMvcConfigurer corsConfigurer() {
return new WebMvcConfigurer() {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("http://localhost:3000")
.allowedMethods("GET", "POST", "PUT", "DELETE")
.allowedHeaders("*")
.allowCredentials(true);
}
};
}
}
单个接口配置
通过 @CrossOrigin 注解解决特定接口的跨域问题:
@RestController
public class SingleCorsController {
@CrossOrigin(origins = "http://localhost:3000")
@GetMapping("/cors-enabled")
public String handleCors() {
return "CORS enabled for this endpoint!";
}
}
4.3 HTTPS 在 Java 中的实现
HTTPS 是基于 HTTP 协议加上加密层(SSL/TLS)的通信方式,它能够确保数据传输的安全性,防止信息被窃听或篡改。在实际开发中,为了让 Spring Boot 应用支持 HTTPS,我们需要准备证书并进行相关配置。同时,在生产环境中,通常会使用 Nginx 作为反向代理处理 HTTPS 请求。
4.3.1. 配置 Spring Boot 使用 HTTPS
1 为什么要配置 HTTPS?
默认情况下,Spring Boot 使用 HTTP 协议监听请求。HTTP 是明文传输的,容易被中间人攻击,特别是在涉及登录、支付等敏感数据时,使用 HTTPS 是非常必要的。
2 Spring Boot 支持 HTTPS 的关键
-
HTTPS 需要 SSL/TLS 加密。
-
SSL/TLS 依赖证书,Spring Boot 需要通过一个密钥库文件(如
keystore.jks)加载这些证书。
3 配置步骤
-
准备证书
Spring Boot 使用 Java KeyStore(JKS)文件存储密钥和证书。您可以生成一个自签名证书用于开发和测试,也可以使用 CA 签发的证书用于生产环境。 -
配置 Spring Boot 的 application.properties
在application.properties文件中,设置 HTTPS 的相关参数:server.port=8443 # 设置 HTTPS 服务端口 server.ssl.key-store=classpath:keystore.jks # 密钥库文件路径 server.ssl.key-store-password=your-password # 密钥库密码 server.ssl.key-store-type=JKS # 密钥库类型 server.ssl.key-alias=your-alias # 密钥别名 -
启动应用
启动后,通过https://localhost:8443访问应用,Spring Boot 会监听 HTTPS 请求。
4.3.2. 加载自签名证书与 CA 证书
1 什么是证书?
证书是用来证明服务器身份的文件。浏览器在访问 HTTPS 网站时,会验证这个证书是否可信。
-
自签名证书:由自己生成,适合测试环境,但不被浏览器信任。
-
CA 签发证书:由权威证书机构颁发,适合生产环境,浏览器会自动信任。
2 如何生成自签名证书?
我们可以使用 Java 自带的 keytool 工具生成自签名证书。
打开终端,运行以下命令:
keytool -genkeypair -alias mycert -keyalg RSA -keysize 2048 -keystore keystore.jks -validity 365
-
mycert是证书的别名。 -
keystore.jks是生成的密钥库文件名。 -
365表示证书有效期为 365 天。
按提示输入信息,例如姓名、组织、地区等。
生成的 keystore.jks 文件放置在项目的 src/main/resources 目录下。
3 如何使用 CA 签发的证书?
-
生成证书请求文件(CSR)
向 CA 提交 CSR 文件以获取签名的证书:keytool -certreq -alias mycert -file certreq.csr -keystore keystore.jks -
提交到 CA
将生成的certreq.csr文件提交到证书机构(如 Let’s Encrypt),等待证书签发。 -
导入 CA 签名的证书
当您获得签名的证书文件(如server.crt)后,使用以下命令将其导入密钥库:keytool -import -trustcacerts -alias mycert -file server.crt -keystore keystore.jks
4.3.3. 使用 Java KeyStore 工具生成证书
什么是 Java KeyStore?
Java KeyStore(JKS)是一个文件格式,用于存储加密密钥和证书。它是 Spring Boot 默认支持的密钥库格式。
生成密钥库
创建密钥库并生成密钥对:
keytool -genkeypair -alias your-alias -keyalg RSA -keysize 2048 -keystore keystore.jks -validity 365
查看密钥库内容:
keytool -list -v -keystore keystore.jks
这些命令可以生成密钥库文件和自签名证书,供开发环境使用。
4.3.4. 配置 Nginx 作为反向代理,启用 HTTPS
1 为什么使用 Nginx?
在生产环境中,Spring Boot 的 HTTPS 通常只作为开发和测试用途。在实际部署中:
-
Nginx 作为反向代理接收 HTTPS 请求,并将流量转发到 Spring Boot 应用。
-
Nginx 提供更好的性能、负载均衡支持,并简化证书管理。
2 配置 Nginx 支持 HTTPS
Step 1: 安装 Nginx
sudo apt update
sudo apt install nginx
Step 2: 准备证书
-
获取 SSL 证书(自签名或 CA 签发的证书)。
-
将证书文件(如
server.crt和server.key)放置到/etc/nginx/ssl/目录下。
Step 3: 配置 Nginx
编辑 Nginx 配置文件(通常是 /etc/nginx/sites-available/default),示例如下:
server {
listen 443 ssl;
server_name yourdomain.com;
ssl_certificate /etc/nginx/ssl/server.crt; # 证书路径
ssl_certificate_key /etc/nginx/ssl/server.key; # 私钥路径
location / {
proxy_pass http://localhost:8080; # 转发到 Spring Boot 应用
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
server {
listen 80;
server_name yourdomain.com;
return 301 https://$host$request_uri; # 将 HTTP 强制重定向到 HTTPS
}
Step 4: 测试并重启 Nginx
测试配置是否正确:
sudo nginx -t
重启 Nginx 服务:
sudo systemctl reload nginx
Step 5:验证 HTTPS
-
在浏览器中访问
https://yourdomain.com。 -
确认页面能够正确加载,且浏览器地址栏显示安全锁图标。
五、Java Web开发中的实际应用
5.1 使用 Servlet 处理 HTTP 请求
HttpServletRequest:用于解析客户端发送的请求参数,处理 GET 和 POST 数据。HttpServletResponse:用于设置返回的响应头和响应体。- Cookie 和 Session:提供会话管理功能,Cookie 存储在客户端,Session 存储在服务器端,分别适用于不同的应用场景。
5.1.1 HttpServletRequest 解析 GET/POST 参数
- HttpServletRequest 是 Servlet 提供的接口,用于封装 HTTP 请求的信息。它包含请求的头部信息、请求参数、请求体以及客户端的信息。
- 通过
HttpServletRequest,我们可以访问客户端发送的参数、Cookie、表单数据等。
怎样获取GET 请求的参数
- GET 请求 是最常见的请求方式,参数通过 URL 的查询字符串传递。
HttpServletRequest提供了以下方法解析这些参数:getParameter(String name):获取指定名称的参数值。getParameterMap():获取所有参数的键值对,返回Map<String, String[]>。getQueryString():获取原始查询字符串(name=John&age=25)。
代码示例
@WebServlet("/hello")
public class HelloServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
// 获取单个参数
String name = request.getParameter("name");
String age = request.getParameter("age");
// 获取完整的查询字符串
String queryString = request.getQueryString();
// 返回解析结果
response.getWriter().write("Query String: " + queryString + "\n");
response.getWriter().write("Name: " + name + ", Age: " + age);
}
}
代码解释:
request.getParameter("name")获取指定的参数值,例如John。request.getParameterMap()返回所有参数的键值对。- 使用
response.getWriter().write()输出响应内容。
访问 URL:/hello?name=John&age=25&city=NewYork
返回结果:
Query String: name=John&age=25
Name: John, Age: 25
怎样获取POST 请求的参数
- POST 请求 的参数通常位于请求体中,例如表单数据或 JSON 数据。
HttpServletRequest提供以下方法解析:getParameter(String name):用于解析表单参数。getInputStream()或getReader():用于解析原始请求体数据。
代码示例:解析表单参数
@WebServlet("/submit")
public class SubmitServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws IOException {
// 获取表单参数
String username = request.getParameter("username");
String password = request.getParameter("password");
// 返回解析结果
response.getWriter().write("Username: " + username + ", Password: " + password);
}
}
代码解释:
request.getParameter("username")获取表单中的参数值。response.setContentType("text/plain")设置响应类型为纯文本。
访问表单:
<form action="/submit" method="POST">
<input name="username" value="admin">
<input name="password" value="1234">
<button type="submit">Submit</button>
</form>
返回结果:
Username: admin, Password: 1234
5.1.2 HttpServletResponse 设置响应头与响应体
推荐使用 Spring 提供的
ResponseEntity,可以同时设置响应头和响应体
- HttpServletResponse 用于封装服务器向客户端返回的数据,包括响应头、响应体以及状态码。
- 响应头:通知客户端有关响应的信息(例如内容类型、缓存策略)。
- 响应体:实际返回给客户端的数据,例如 HTML、JSON 或文件。
1.设置响应头
常用方法:
setHeader(String name, String value):设置单个响应头。addHeader(String name, String value):添加一个多值响应头。setContentType(String type):设置响应内容类型。
代码示例:设置响应头
@WebServlet("/set-headers")
public class HeaderServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
response.setHeader("Content-Type", "application/json");
response.setHeader("Cache-Control", "no-cache");
response.addHeader("Custom-Header", "CustomValue");
response.getWriter().write("{\"message\":\"Headers have been set!\"}");
}
}
代码解释:
setHeader("Content-Type", "application/json")设置响应的 MIME 类型为 JSON。setHeader("Cache-Control", "no-cache")禁用缓存。
2.设置响应体
常用方法:
getWriter():用于写入文本数据(如 HTML、JSON)。getOutputStream():用于写入二进制数据(如文件或图片)。
代码示例:设置响应体
@WebServlet("/response-body")
public class BodyServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
response.setContentType("text/html");
response.getWriter().write("<h1>This is the response body</h1>");
}
}
代码解释:
response.setContentType("text/html")设置响应类型为 HTML。response.getWriter().write()输出 HTML 内容到客户端。
5.1.3 使用 Cookie 和 Session 实现会话管理
使用 Cookie
- 概念:Cookie 是存储在客户端的键值对,用于保存用户的状态信息。
- 方法:
HttpServletResponse.addCookie(Cookie cookie):设置 Cookie。HttpServletRequest.getCookies():获取客户端发送的所有 Cookie。
代码示例
@WebServlet("/cookie")
public class CookieServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
Cookie cookie = new Cookie("username", "JohnDoe");
cookie.setMaxAge(3600); // 有效期 1 小时
response.addCookie(cookie);
response.getWriter().write("Cookie has been set!");
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws IOException {
Cookie[] cookies = request.getCookies();
if (cookies != null) {
for (Cookie c : cookies) {
response.getWriter().write("Cookie: " + c.getName() + " = " + c.getValue() + "\n");
}
}
}
}
使用 Session
- 概念:Session 是存储在服务器端的会话数据,使用唯一的 Session ID 标识客户端。
- 方法:
HttpServletRequest.getSession():获取当前会话。setAttribute()和getAttribute():设置和获取会话属性。
代码示例
@WebServlet("/session")
public class SessionServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
HttpSession session = request.getSession();
session.setAttribute("user", "JohnDoe");
response.getWriter().write("Session has been set!");
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws IOException {
HttpSession session = request.getSession();
String user = (String) session.getAttribute("user");
response.getWriter().write("Session user: " + user);
}
}
5.2 RESTful Web服务
RESTful Web 服务是一种设计风格,基于 HTTP 协议,将资源作为核心,通过标准的 HTTP 方法(如 GET、POST、PUT、DELETE 等)对资源进行操作。在 Spring Boot 中,RESTful Web 服务的实现主要依赖于注解和自动配置。
-
@RestController 与 @RequestMapping
@RestController用于创建 RESTful 控制器。@RequestMapping结合@GetMapping等用于映射路径和方法。
-
@PathVariable 和 @RequestParam
@PathVariable从路径中提取动态参数。@RequestParam从查询字符串中提取参数。
-
返回 JSON 数据
- Spring Boot 自动将对象序列化为 JSON。
- 通过自定义响应格式,可以封装统一的返回结果结构,增强系统的可维护性和一致性。
5.2.1 Spring Boot 中的 @RestController 与 @RequestMapping
@RestController
- 是 Spring MVC 提供的注解,用于标识该类为 REST 控制器。
- 它相当于
@Controller和@ResponseBody的组合,表示所有方法的返回值都会直接作为 HTTP 响应体。
示例
@RestController
public class HelloController {
@GetMapping("/hello")
public String sayHello() {
return "Hello, RESTful Web Service!";
}
}
解释:
@RestController声明了一个 RESTful 控制器。@GetMapping是对 HTTP GET 请求的映射,返回的字符串直接作为响应体。
@RequestMapping
@RequestMapping是 Spring 提供的注解,用于映射 HTTP 请求到指定的控制器方法。- 支持指定路径、HTTP 方法、请求参数等。
- 它可以作用在类和方法上:
- 类级别:为整个控制器定义一个基础路径。
- 方法级别:为每个具体的操作定义路径。
示例
@RestController
@RequestMapping("/api")
public class ApiController {
@GetMapping("/users")
public String getUsers() {
return "Returning all users";
}
@PostMapping("/users")
public String createUser() {
return "User created";
}
}
解释:
- 类级别的
@RequestMapping("/api")为该控制器的所有方法设置了基础路径。 @GetMapping和@PostMapping分别映射 GET 和 POST 请求。
5.2.2 使用 @PathVariable 和 @RequestParam 处理动态参数
@PathVariable
- 用于从 URL 路径中提取动态参数。
- 常用于操作特定资源,例如获取指定用户的信息。
示例
@RestController
@RequestMapping("/api")
public class UserController {
@GetMapping("/users/{id}")
public String getUserById(@PathVariable("id") String userId) {
return "User ID: " + userId;
}
}
解释:
{id}是路径中的动态参数。@PathVariable("id")将路径中的id值绑定到方法参数userId。
访问 URL:/api/users/123
返回结果:User ID: 123
@RequestParam
- 用于从请求参数中提取值,例如 URL 查询参数。
- 常用于过滤、分页等操作。
示例
@RestController
@RequestMapping("/api")
public class ProductController {
@GetMapping("/products")
public String getProducts(@RequestParam("category") String category,
@RequestParam(value = "page", defaultValue = "1") int page) {
return "Category: " + category + ", Page: " + page;
}
}
解释:
@RequestParam("category")绑定请求参数category到方法参数。@RequestParam(value = "page", defaultValue = "1")设置了分页的默认值。
访问 URL:/api/products?category=electronics&page=2
返回结果:Category: electronics, Page: 2
5.2.3 返回 JSON 数据与自定义响应格式
返回 JSON 数据
- Spring Boot 默认使用 Jackson 库将对象序列化为 JSON。
- 在 RESTful Web 服务中,通常通过返回对象而不是直接返回字符串。
- Spring Boot 自动将返回的对象序列化为 JSON。
示例
@RestController
@RequestMapping("/api")
public class UserController {
@GetMapping("/users/{id}")
public User getUserById(@PathVariable("id") int userId) {
return new User(userId, "John Doe", "[email protected]");
}
}
class User {
private int id;
private String name;
private String email;
// 构造函数、getter 和 setter
public User(int id, String name, String email) {
this.id = id;
this.name = name;
this.email = email;
}
public int getId() { return id; }
public String getName() { return name; }
public String getEmail() { return email; }
}
解释:
User是一个简单的 Java 对象(POJO)。- Spring Boot 自动将返回的
User对象序列化为 JSON。
访问 URL:/api/users/1
返回结果:
{
"id": 1,
"name": "John Doe",
"email": "[email protected]"
}
自定义响应格式
- 可以使用自定义对象封装响应数据,例如统一返回结果的格式。
示例
@RestController
@RequestMapping("/api")
public class ProductController {
@GetMapping("/products/{id}")
public ApiResponse getProductById(@PathVariable("id") int productId) {
Product product = new Product(productId, "Smartphone", 699.99);
return new ApiResponse(200, "Success", product);
}
}
class Product {
private int id;
private String name;
private double price;
public Product(int id, String name, double price) {
this.id = id;
this.name = name;
this.price = price;
}
// Getter 和 Setter
}
class ApiResponse {
private int status;
private String message;
private Object data;
public ApiResponse(int status, String message, Object data) {
this.status = status;
this.message = message;
this.data = data;
}
// Getter 和 Setter
}
访问 URL:/api/products/101
返回结果:
{
"status": 200,
"message": "Success",
"data": {
"id": 101,
"name": "Smartphone",
"price": 699.99
}
}
解释:
ApiResponse是一个通用响应对象,封装了状态码、消息和实际数据。Product是返回的具体业务数据。
5.3 拦截器与过滤器
拦截器(Interceptor)和过滤器(Filter)是 Web 应用中的两个重要组件,它们都可以在 HTTP 请求到达控制器之前或返回响应之前执行特定的逻辑。两者的功能有所重叠,但应用场景和实现方式不同。
5.3.1 自定义过滤器处理 HTTP 请求
1.过滤器的概念
- 过滤器(Filter) 是 Servlet 提供的组件,位于请求的入口,可以对所有请求进行预处理或对响应进行后处理。
- 常用于日志记录、请求参数校验、编码设置等场景。
2.过滤器的特点
- 可以拦截所有进入 Servlet 容器的 HTTP 请求和响应。
- 在过滤器链中按顺序执行。
3.自定义过滤器的实现步骤
- 实现
javax.servlet.Filter接口。 - 重写
doFilter方法。 - 注册过滤器到 Spring Boot 应用中。
5.3.2 使用拦截器记录请求日志或验证用户权限
拦截器的概念
- 拦截器(Interceptor) 是 Spring 提供的机制,可以拦截 HTTP 请求和响应,通常用于实现跨模块的业务逻辑。
- 应用场景包括:
- 验证用户权限。
- 记录请求和响应日志。
- 修改请求或响应内容。
拦截器的特点
- 基于 Spring 的
HandlerInterceptor接口,紧密结合 Spring MVC。 - 作用于特定的控制器或路径。
拦截器的实现步骤
- 实现
HandlerInterceptor接口。 - 配置拦截器并指定拦截路径。
代码示例:记录请求日志的拦截器
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@Component
public class LoggingInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("PreHandle: Request URI: " + request.getRequestURI());
return true; // 返回 true 继续执行后续处理,返回 false 阻止请求
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("PostHandle: Request URI: " + request.getRequestURI());
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("AfterCompletion: Request URI: " + request.getRequestURI());
}
}
代码解释
preHandle:在请求到达控制器之前执行,适合处理权限验证或记录日志。postHandle:在控制器方法执行后,渲染视图之前执行,可以修改返回的数据。afterCompletion:在请求完成(视图渲染完成)后执行,适合资源清理或异常处理。
配置拦截器 使用 Spring 的 WebMvcConfigurer 配置拦截器:
@Configuration
public class WebConfig implements WebMvcConfigurer {
private final LoggingInterceptor loggingInterceptor;
public WebConfig(LoggingInterceptor loggingInterceptor) {
this.loggingInterceptor = loggingInterceptor;
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(loggingInterceptor)
.addPathPatterns("/**") // 拦截所有路径
.excludePathPatterns("/auth/**"); // 排除特定路径
}
}
5.3.3.拦截器与过滤器的对比
| 特点 | 过滤器(Filter) | 拦截器(Interceptor) |
|---|---|---|
| 依赖 | Servlet 规范,独立于 Spring MVC | Spring MVC 框架的一部分 |
| 作用范围 | 所有 HTTP 请求,包括静态资源 | 仅作用于动态请求(经过 Spring MVC 的控制器) |
| 执行顺序 | 在拦截器之前执行 | 在过滤器之后执行,控制器处理之前或之后执行 |
| 典型用途 | 编码设置、日志记录、通用请求过滤 | 权限验证、业务逻辑处理、数据处理 |
六、HTTP协议的调试与优化
6.1 调试工具
在 Web 开发和调试中,合适的工具能够高效地帮助开发者查看请求、分析响应,以及调试问题。以下介绍三种常用工具:浏览器开发者工具、Postman 和 Fiddler/Charles。
6.1.1 使用浏览器开发者工具查看 HTTP 请求与响应
概述
现代浏览器(如 Chrome、Firefox、Edge)内置开发者工具,可以捕获和分析 HTTP 请求及响应,帮助开发者优化页面性能、排查问题。
主要功能
- 网络监控:实时显示所有 HTTP 请求,包含请求方法、状态码、响应时间等。
- 请求和响应详情:查看每个请求的头信息、请求参数及响应数据。
- 性能分析:通过瀑布图等方式分析资源加载顺序及时间。
操作步骤(以 Chrome 为例)
1.打开开发者工具
按 F12 或 Ctrl + Shift + I(Windows)/Cmd + Option + I(Mac)。
或者右键页面 → 选择“检查”。
2.切换到“网络”面板
点击顶部的“网络”(Network)选项卡。
3.捕获网络请求
刷新页面,网络面板会显示所有网络请求。
4.查看请求详情
点击某个请求,在右侧查看具体信息,包括:
- Headers:请求头和响应头信息。
- Payload:POST 请求的提交数据。
- Preview:响应内容的预览。
- Timing:资源加载的时间分布。
6.1.2 使用 Postman 发送调试 HTTP 请求
概述
Postman 是功能强大的 API 调试和测试工具,支持发送各种 HTTP 请求(如 GET、POST、PUT、DELETE),便于测试后端接口。
主要功能
- 发送请求:支持设置请求方法、URL、参数和请求头。
- 查看响应:直观展示状态码、响应头及返回数据。
- 自动化测试:通过测试脚本自动验证 API 的正确性。
操作步骤
1.安装 Postman
从 Postman 官网 下载适合您操作系统的版本。
2.创建请求
- 打开 Postman,点击“New”→“HTTP Request”。
- 输入 URL,例如
https://jsonplaceholder.typicode.com/posts/1。 - 设置请求方法(如 GET)。
3.发送请求
点击“Send”按钮,Postman 会发送请求并显示响应结果。
4.查看响应
响应内容包括状态码、响应头、响应体(JSON、HTML 等)。
6.1.3 使用 Fiddler 或 Charles 抓包分析
概述
Fiddler 和 Charles 是专业的抓包工具,可以拦截计算机的所有 HTTP/HTTPS 流量,适合调试网络问题和复杂的请求分析。
主要功能
- 抓包:拦截记录所有进出计算机的 HTTP/HTTPS 流量。
- 修改请求:可动态修改请求或响应数据,测试不同的场景。
- SSL 解密:解密 HTTPS 流量,查看加密的数据内容。
操作步骤(以 Fiddler 为例)
1.安装 Fiddler
从 Fiddler 官网 下载并安装。
2.启动抓包
打开 Fiddler,默认捕获所有网络流量。
3.设置 HTTPS 解密
- 点击菜单栏的“Tools” → “Options” → “HTTPS”。
- 勾选“Decrypt HTTPS traffic”,启用 HTTPS 解密。
4.查看请求和响应
- 在左侧会话列表中选择一个请求。
- 查看右侧的详细信息,包括请求头、响应头和响应体。
5.修改请求
右键点击某个请求,选择“Edit Request”,修改后重新发送。
注意事项
- 启用 HTTPS 解密可能会引发安全警告,仅在受信环境中使用。
- 持续抓包可能影响性能,建议调试完成后停止抓包。
6.2 性能优化
Web 性能优化的核心是提升页面加载速度、减少服务器压力和提高用户体验。以下内容将详细讲解如何通过减少请求数、使用浏览器缓存和配置 CDN 加速资源加载来优化性能。
6.2.1 减少请求数:合并 CSS 和 JS 文件
为什么减少请求数?
-
每个 HTTP 请求都会有一定的开销,包括 DNS 解析、TCP 连接建立等。
-
请求数过多会导致浏览器对同一域名的并发连接数限制(通常是 6 个),从而拖慢资源加载。
-
合并文件可以减少 HTTP 请求数,从而加快页面加载。
实现方式
合并 CSS 文件
-
将多个 CSS 文件合并成一个文件,减少 HTTP 请求。
合并前
<link rel="stylesheet" href="/styles/reset.css">
<link rel="stylesheet" href="/styles/layout.css">
<link rel="stylesheet" href="/styles/theme.css">
合并后
<link rel="stylesheet" href="/styles/all.css">
-
使用工具:可以手动合并,也可以使用 Webpack 或 Gulp 等构建工具自动处理。
合并 JS 文件
-
将多个 JS 文件合并成一个文件。
合并前
<script src="/scripts/jquery.js"></script>
<script src="/scripts/main.js"></script>
<script src="/scripts/analytics.js"></script>
合并后
<script src="/scripts/all.js"></script>
在 Spring Boot 项目中的实现
-
静态资源管理: 将合并后的 CSS 和 JS 文件放置在
src/main/resources/static下,Spring Boot 默认会加载此目录的静态资源。 -
配置示例:
-
<link rel="stylesheet" href="/static/styles/all.css"> <script src="/static/scripts/all.js"></script>
额外优化:启用 HTTP/2
-
HTTP/2 协议支持多路复用,可以同时加载多个资源,部分缓解请求数的问题。
-
配置 HTTPS 后,Spring Boot 支持 HTTP/2:
server.http2.enabled=true
6.2.2 使用浏览器缓存优化页面加载速度
为什么使用浏览器缓存?
-
缓存允许浏览器直接从本地加载资源,而不是每次都请求服务器。
-
可以显著减少 HTTP 请求数,缩短页面加载时间,提高用户体验。
实现方式
1.配置强缓存
强缓存通过 Cache-Control 和 Expires 头控制。浏览器在缓存有效期内直接使用本地缓存,不向服务器发送请求。
在 Spring Boot 中配置强缓存:
-
使用
WebMvcConfigurer设置静态资源缓存:@Configuration public class CacheConfig implements WebMvcConfigurer { @Override public void addResourceHandlers(ResourceHandlerRegistry registry) { registry.addResourceHandler("/static/**") .addResourceLocations("classpath:/static/") .setCachePeriod(31536000); // 缓存时间:1 年 } }
2.配置协商缓存
协商缓存通过 ETag 和 Last-Modified 头控制。浏览器会向服务器发送请求并带上这些头部,服务器通过判断资源是否更新来返回新资源或 304 状态码。
在 Spring Boot 中配置协商缓存:
-
静态资源的协商缓存可以通过
application.properties配置:spring.resources.cache.cachecontrol.max-age=31536000 spring.resources.cache.cachecontrol.must-revalidate=true
结合使用强缓存与协商缓存
-
设置强缓存优先减少请求。
-
当强缓存失效后,使用协商缓存判断资源是否更新。
6.2.3 配置 CDN 加速资源加载
什么是 CDN?
-
内容分发网络(CDN)是分布式的服务器网络,用于将静态资源缓存到多个节点中,让用户可以从最近的节点加载资源。
-
通过减少网络延迟和服务器压力,提升资源加载速度。
CDN 的优势
-
加速加载:用户请求会路由到地理位置最近的节点,减少延迟。
-
分布式可靠性:节点之间可以互为备份,提升资源的可用性。
-
减轻服务器压力:通过将资源分发到 CDN 节点,减少主服务器的请求压力。
在 Spring Boot 项目中使用 CDN
将静态资源托管到 CDN
-
上传资源到 CDN:可以手动将 CSS、JS 文件上传到 CDN,或者通过 CI/CD 工具自动上传。
-
更新资源路径:在 HTML 中替换资源 URL
<link rel="stylesheet" href="https://cdn.example.com/styles/all.css"> <script src="https://cdn.example.com/scripts/all.js"></script>
使用 CDN 加速动态资源
-
动态内容(如 API 数据)通常不能直接缓存,但可以通过 CDN 的动态加速功能提升响应速度。
-
配置 CDN 服务提供商(如 Cloudflare、阿里云 CDN)的反向代理功能,将动态请求加速到主服务器。
示例:配置阿里云 CDN
登录阿里云 CDN 控制台。
创建加速域名:
-
绑定您的主服务器域名(如
example.com)。 -
配置加速路径(如
/static/**)。
同步资源到 CDN:
-
上传静态资源到主服务器,CDN 会自动同步和缓存。
更新资源路径: 在 HTML 中替换资源 URL:
七、HTTP/2与HTTP/3
HTTP/2 和 HTTP/3 是现代互联网中的两种关键通信协议,分别在性能和效率上相较 HTTP/1.1 进行了重大改进。
-
HTTP/2
- 核心特性:多路复用、Header 压缩、服务器推送。
- 适用场景:目前主流的 Web 应用,解决了 HTTP/1.1 的主要性能瓶颈。
- 局限:依然受到 TCP 的队头阻塞问题影响。
-
HTTP/3
- 核心特性:基于 QUIC 协议,消除队头阻塞,连接建立更快。
- 适用场景:需要低延迟、高并发、或运行在弱网环境下的应用(如实时视频流、游戏服务器)。
- 局限:部署和兼容性逐步完善中,但已成为未来趋势。
7.1 HTTP/2
HTTP/2 是 HTTP 协议的第二个正式版本,于 2015 年发布。它主要解决了 HTTP/1.1 的性能问题,提升了数据传输效率。
7.1.1 核心特性
1.多路复用
- 定义:在单个 TCP 连接内同时处理多个请求和响应,无需为每个请求单独建立连接。
- 传统问题:
- 在 HTTP/1.1 中,每个请求需要单独的 TCP 连接。
- 如果一个请求卡住(如等待服务器响应),后续请求也会受阻(队头阻塞)。
- HTTP/2 的改进:
- 将每个请求分成帧(Frame)并赋予唯一的流标识符(Stream ID)。
- 帧交错传输后,客户端和服务器根据标识符重新组装数据。
- 效果:
- 同一连接可并行处理多个请求和响应。
- 减少延迟,提高资源加载速度。
2.Header 压缩
- 定义:通过 HPACK 算法压缩 HTTP 头部信息,减少数据冗余。
- 传统问题:
- HTTP/1.1 中,每次请求都需要传输完整的头部(如
Host、User-Agent等)。 - 多个请求的头部信息常常重复,导致浪费带宽。
- HTTP/1.1 中,每次请求都需要传输完整的头部(如
- HTTP/2 的改进:
- 使用头部表(Header Table)维护已发送的头部信息。
- 对于重复的头部,只需发送索引号,而非完整字段。
- 效果:
- 大幅减少传输的数据量,尤其在大量小资源请求时显著提升效率。
3.服务器推送(Server Push)
- 定义:服务器可以在客户端未请求某些资源时主动推送资源。
- 优势:
- 提前发送可能需要的资源(如 CSS 文件、JS 文件),减少页面加载延迟。
- 限制:
- 需合理控制推送资源,避免带宽浪费。
7.1.2 优缺点
优点
- 支持多路复用,解决了 HTTP/1.1 的队头阻塞问题。
- Header 压缩减少了传输冗余,提高带宽利用率。
- 服务器推送功能能主动加速页面资源加载。
缺点
- 依赖 TCP 协议,丢包时需要重传整个连接的数据。
- 复杂性增加,部分实现需要调整网络设备配置。
7.2 HTTP/3
HTTP/3 是基于 QUIC 协议的下一代 HTTP 协议,旨在解决 HTTP/2 的不足,特别是 TCP 队头阻塞问题。
7.2.1 核心特性
1.基于 QUIC 协议
- 定义:QUIC 是 Google 开发的传输协议,基于 UDP 实现,结合了 TCP 的可靠性和 UDP 的灵活性。
- 特性:
- 内置加密功能,传输默认安全。
- 消除了 TCP 的队头阻塞问题。
2.流级别的多路复用
- HTTP/2 的局限:
- 多路复用虽然解决了应用层的队头阻塞,但 TCP 连接的丢包依然会阻塞所有流。
- HTTP/3 的改进:
- QUIC 实现了流级别的多路复用,丢包只会影响某个流,不影响其他流的传输。
- 效果:
- 在弱网环境中,传输效率显著提升。
3.快速连接建立
- 传统问题:
- TCP 需要三次握手,而 TLS 加密又引入了额外的握手延迟。
- HTTP/3 的改进:
- QUIC 将连接建立和 TLS 握手合并为一次操作。
- 支持 0-RTT 重连(无需等待,即可发送数据)。
- 效果:
- 减少连接建立时间,显著降低延迟。
7.2.2 优缺点
优点
- 基于 UDP,无队头阻塞问题。
- 流级别的多路复用和快速连接建立显著降低延迟。
- 更适合高并发和弱网环境。
缺点
- 基于 UDP,可能受到防火墙限制。
- 兼容性尚在逐步完善,部分设备和浏览器需要升级。
7.3 HTTP/2 与 HTTP/3 对比
| 特性 | HTTP/2 | HTTP/3 |
|---|---|---|
| 底层协议 | TCP | UDP + QUIC |
| 多路复用 | 应用层支持,依赖 TCP,可能受队头阻塞影响 | 流级别支持,无队头阻塞问题 |
| 连接建立 | TCP 三次握手 + TLS | QUIC 一次握手,支持 0-RTT |
| 头部压缩 | HPACK | QPACK |
| 丢包处理 | 丢包需重传整个连接 | 丢包仅影响单个流 |
| 适用场景 | 适用于大多数现代 Web 应用 | 更适合高并发、低延迟和移动网络的场景 |
- HTTP/2 已被广泛支持,适合立即部署的场景。
- HTTP/3 是未来方向,适合在对性能要求极高的场景中优先尝试。