七、正则表达式
正则表达式是一种强大的文本匹配工具,用于在字符串中搜索和匹配特定模式的文本。
在Java中,正则表达式由java.util.regex包提供支持。它可以用于验证输入的格式、提取文本中的特定部分、替换文本等操作。
7.1 格式
7.1.1 字符类
字符类用于匹配一组字符中的任意一个字符。字符类用方括号[]括起来,表示在这些字符中匹配一个字符。
[abc]:匹配字符a、b或c。[^abc]:匹配除a、b、c之外的任何字符。[a-zA-Z]:匹配从a到z或从A到Z的任意一个字符。[a-d[m-p]]:匹配a到d或m到p的任意一个字符。[a-z&&[def]]:匹配a到z和def的交集,即d、e、f。[a-z&&[^bc]]:匹配a到z并且不包括b和c的字符(即[ad-z])。[a-z&&[^m-p]]:匹配a到z并且不包括m到p的字符(即[a-lq-z])。
注意
[a-z&&[def]]:匹配a到z和def的交集,即d、e、f。- 像这样的&&,必须是两个,如果是一个&,就只是说明其是一个‘&’字符符号
字符类示例代码1
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class CharClassExample {
public static void main(String[] args) {
// 匹配a、b或c中的任意一个字符
String regex1 = "[abc]";
String input1 = "apple";
System.out.println(matchesPattern(regex1, input1)); // true
// 匹配除a、b、c之外的任何字符
String regex2 = "[^abc]";
String input2 = "def";
System.out.println(matchesPattern(regex2, input2)); // true
// 匹配从a到z或从A到Z的任意一个字符
String regex3 = "[a-zA-Z]";
String input3 = "Hello";
System.out.println(matchesPattern(regex3, input3)); // true
// 匹配a到d或m到p的任意一个字符
String regex4 = "[a-d[m-p]]";
String input4 = "cat";
System.out.println(matchesPattern(regex4, input4)); // true
// 匹配a到z和def的交集,即d、e、f
String regex5 = "[a-z&&[def]]";
String input5 = "dog";
System.out.println(matchesPattern(regex5, input5)); // true
// 匹配a到z并且不包括b和c的字符
String regex6 = "[a-z&&[^bc]]";
String input6 = "apple";
System.out.println(matchesPattern(regex6, input6)); // true
// 匹配a到z并且不包括m到p的字符
String regex7 = "[a-z&&[^m-p]]";
String input7 = "hello";
System.out.println(matchesPattern(regex7, input7)); // true
}
private static boolean matchesPattern(String regex, String input) {
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
return matcher.find();
}
}
例2
public class CharClassExample {
public static void main(String[] args) {
// 只能是 a b c
System.out.println("----------1----------");
System.out.println("a".matches("[abc]")); // true
System.out.println("k".matches("[abc]")); // false
// 不能出现 a b c
System.out.println("----------2----------");
System.out.println("a".matches("[^abc]")); // false
System.out.println("z".matches("[^abc]")); // true
System.out.println("zz".matches("[^abc]")); // false
System.out.println("zz".matches("[^abc][^abc]")); // true
// a到z A到Z (包括头尾的范围)
System.out.println("----------3----------");
System.out.println("a".matches("[a-zA-Z]")); // true
System.out.println("Z".matches("[a-zA-Z]")); // true
System.out.println("aa".matches("[a-zA-Z]")); // false
System.out.println("zz".matches("[a-zA-Z]")); // false
System.out.println("0".matches("[a-zA-Z]")); // false
}
}
7.1.2 预定义字符
匹配一组字符中的任意一个字符,其用于简化正则表达式的书写。
.:匹配任意字符。\d:匹配一个数字字符,相当于[0-9]。\D:匹配一个非数字字符,相当于[^0-9]。\s:匹配一个空白字符,包括空格、制表符、换行符等,相当于[\t\n\x0B\f\r]。\S:匹配一个非空白字符,相当于[^\s]。\w:匹配一个单词字符,包括字母、数字和下划线,相当于[a-zA-Z_0-9]。\W:匹配一个非单词字符,相当于[^\w]。
通过使用这些字符类和预定义字符,可以构建出复杂的正则表达式来匹配特定的文本模式。
预定义字符示例代码
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class PredefinedCharExample {
public static void main(String[] args) {
// 匹配任意字符
String regex1 = ".";
String input1 = "a";
System.out.println(matchesPattern(regex1, input1)); // true
// 匹配一个数字字符
String regex2 = "\\d";
String input2 = "5";
System.out.println(matchesPattern(regex2, input2)); // true
// 匹配一个非数字字符
String regex3 = "\\D";
String input3 = "a";
System.out.println(matchesPattern(regex3, input3)); // true
// 匹配一个空白字符
String regex4 = "\\s";
String input4 = " ";
System.out.println(matchesPattern(regex4, input4)); // true
// 匹配一个非空白字符
String regex5 = "\\S";
String input5 = "a";
System.out.println(matchesPattern(regex5, input5)); // true
// 匹配一个单词字符
String regex6 = "\\w";
String input6 = "a";
System.out.println(matchesPattern(regex6, input6)); // true
// 匹配一个非单词字符
String regex7 = "\\W";
String input7 = "!";
System.out.println(matchesPattern(regex7, input7)); // true
}
private static boolean matchesPattern(String regex, String input) {
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
return matcher.find();
}
}
例2
public class PredefinedCharExample {
public static void main(String[] args) {
// 匹配任意字符
System.out.println("----------1----------");
System.out.println("a".matches(".")); // true
System.out.println("1".matches(".")); // true
System.out.println(" ".matches(".")); // true
System.out.println("\n".matches(".")); // false
// 匹配一个数字字符
System.out.println("----------2----------");
System.out.println("5".matches("\\d")); // true
System.out.println("a".matches("\\d")); // false
// 匹配一个非数字字符
System.out.println("----------3----------");
System.out.println("a".matches("\\D")); // true
System.out.println("5".matches("\\D")); // false
// 匹配一个空白字符
System.out.println("----------4----------");
System.out.println(" ".matches("\\s")); // true
System.out.println("\t".matches("\\s")); // true
System.out.println("a".matches("\\s")); // false
// 匹配一个非空白字符
System.out.println("----------5----------");
System.out.println("a".matches("\\S")); // true
System.out.println(" ".matches("\\S")); // false
// 匹配一个单词字符
System.out.println("----------6----------");
System.out.println("a".matches("\\w")); // true
System.out.println("1".matches("\\w")); // true
System.out.println("_".matches("\\w")); // true
System.out.println("!".matches("\\w")); // false
// 匹配一个非单词字符
System.out.println("----------7----------");
System.out.println("!".matches("\\W")); // true
System.out.println("a".matches("\\W")); // false
}
}
在Java中,使用正则表达式进行字符串匹配时,字符类和预定义字符的写法有一些区别。以下是两种写法的主要区别:
7.1.3 区别总结
-
字符类:
- 使用方括号
[]定义。 - 可以包含单个字符、字符范围或字符集的交集和补集。
- 适用于需要匹配特定字符集合的情况。
- 使用方括号
-
预定义字符:
- 使用反斜杠
\加特定字符定义。 - 是常用字符类的简写形式。
- 适用于匹配常见字符类型(如数字、字母、空白字符等)的情况。
- 使用反斜杠
7.2 使用Pattern和Matcher类与直接使用String类的matches方法的区别。
(1) 使用Pattern和Matcher类
这种方法适用于需要多次复用同一个正则表达式的情况。通过编译正则表达式为Pattern对象,然后使用Matcher对象进行匹配,可以提高效率。
示例代码
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class PatternMatcherExample {
public static void main(String[] args) {
String regex1 = "[abc]";
String input1 = "apple";
System.out.println(matchesPattern(regex1, input1)); // true
}
private static boolean matchesPattern(String regex, String input) {
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
return matcher.find();
}
}
(2)直接使用String类的matches方法
这种方法适用于简单的、一次性的正则表达式匹配。String类的matches方法会在内部编译正则表达式并进行匹配,适合于不需要复用正则表达式的情况。
示例代码
public class StringMatchesExample {
public static void main(String[] args) {
// 只能是 a b c
System.out.println("----------1----------");
System.out.println("a".matches("[abc]")); // true
System.out.println("k".matches("[abc]")); // false
}
}
(3)区别总结
-
使用
Pattern和Matcher类:- 适用于需要多次复用同一个正则表达式的情况。
- 通过编译正则表达式为
Pattern对象,然后使用Matcher对象进行匹配。 - 提高了效率,特别是在需要多次匹配的情况下。
-
直接使用
String类的matches方法:- 适用于简单的、一次性的正则表达式匹配。
- 每次调用
matches方法时,都会编译正则表达式并进行匹配。 - 适合于不需要复用正则表达式的情况。
(4)示例对比
使用Pattern和Matcher类
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class PatternMatcherExample {
public static void main(String[] args) {
String regex1 = "[abc]";
String input1 = "apple";
System.out.println(matchesPattern(regex1, input1)); // true
}
private static boolean matchesPattern(String regex, String input) {
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
return matcher.find();
}
}
直接使用String类的matches方法
public class StringMatchesExample {
public static void main(String[] args) {
// 只能是 a b c
System.out.println("----------1----------");
System.out.println("a".matches("[abc]")); // true
System.out.println("k".matches("[abc]")); // false
}
}
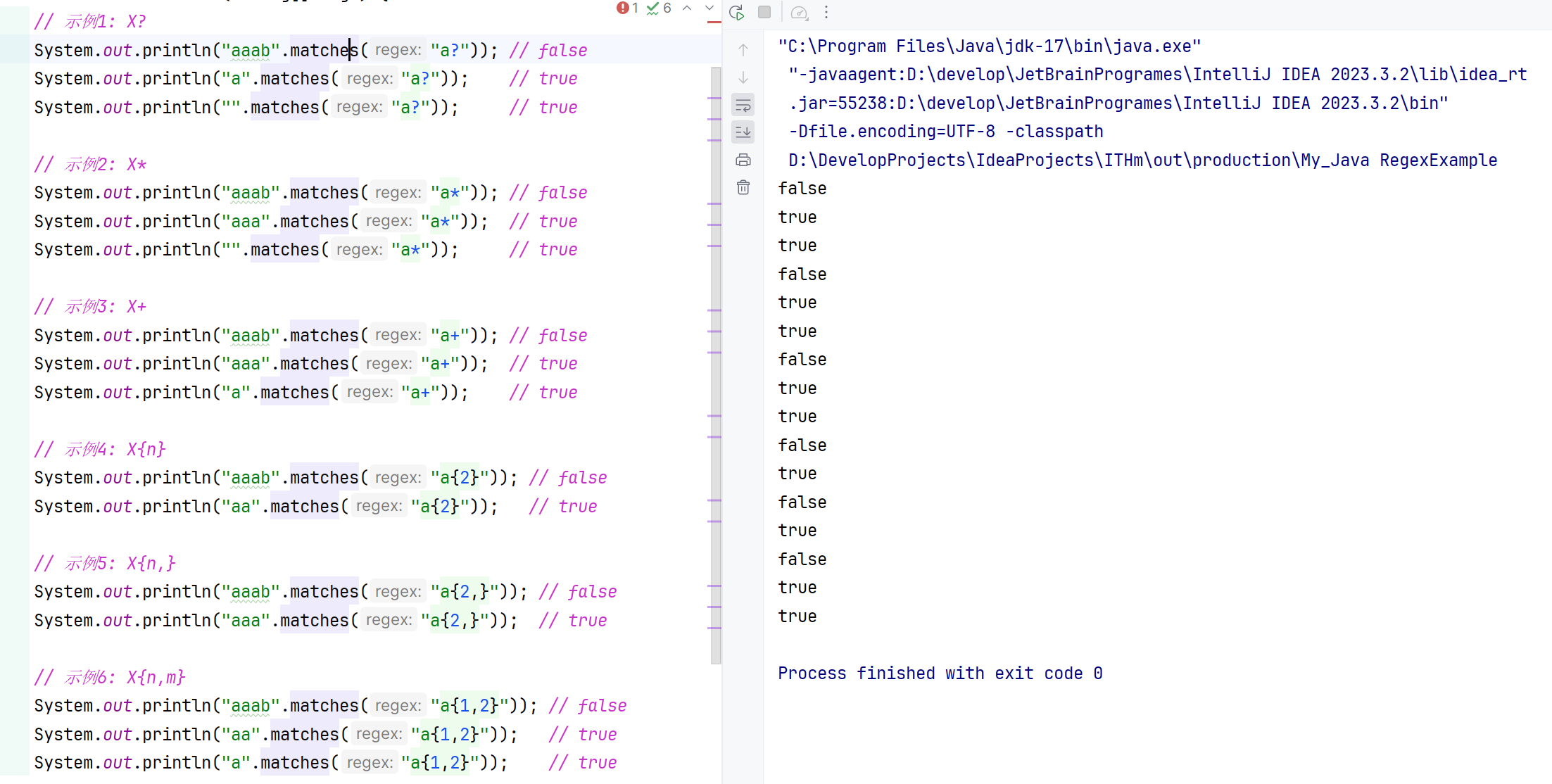
7.3 数量词
X?:X,一次或0次X*:X,零次或多次X+:X,一次或多次X{n}:X,正好n次X{n,}:X,至少n次X{n,m}:X,至少n但不超过m次
这些量词用于正则表达式中来指定字符或子模式的重复次数。
public class RegexExample {
public static void main(String[] args) {
// 示例1: X?
System.out.println("aaab".matches("a?")); // false
System.out.println("a".matches("a?")); // true
System.out.println("".matches("a?")); // true
// 示例2: X*
System.out.println("aaab".matches("a*")); // false
System.out.println("aaa".matches("a*")); // true
System.out.println("".matches("a*")); // true
// 示例3: X+
System.out.println("aaab".matches("a+")); // false
System.out.println("aaa".matches("a+")); // true
System.out.println("a".matches("a+")); // true
// 示例4: X{n}
System.out.println("aaab".matches("a{2}")); // false
System.out.println("aa".matches("a{2}")); // true
// 示例5: X{n,}
System.out.println("aaab".matches("a{2,}")); // false
System.out.println("aaa".matches("a{2,}")); // true
// 示例6: X{n,m}
System.out.println("aaab".matches("a{1,2}")); // false
System.out.println("aa".matches("a{1,2}")); // true
System.out.println("a".matches("a{1,2}")); // true
}
}
(?i):这是一个正则表达式的模式修饰符,用于忽略大小写。
public class RegexExample {
public static void main(String[] args) {
// 忽略大小写的书写方式
// 在匹配的时候忽略abc的大小写
String regex = "a(?i)bc";
System.out.println("----------------------------");
System.out.println("abc".matches(regex)); // true
System.out.println("ABC".matches(regex)); // true
System.out.println("aBC".matches(regex)); // true
}
}
同样的忽略
(X|x)与 [Xx]
注意()的使用
()立大功
public class RegexExample {
public static void main(String[] args) {
// 忽略大小写的书写方式
// 在匹配的时候忽略b的大小写
String regex = "a((?i)b)c";
System.out.println("----------------------------");
System.out.println("abc".matches(regex)); // true
System.out.println("ABC".matches(regex)); // false
System.out.println("aBc".matches(regex)); // true
}
}
7.4这是一个正则表达式符号的总结表。
7.4.1 各个符号
| 符号 | 含义 | 示例 |
|---|---|---|
[] | 里面的内容出现一次 | [0-9] [a-zA-Z0-9] |
() | 分组 | a(bc)+ |
^ | 取反 | [^abc] |
&& | 交集,不能写单个的& | [a-z&&m-p] |
| ` | ` | 写在方括号外面表示并集 |
. | 任意字符 | \n 回车符号不匹配 |
\ | 转义字符 | \\d |
\d | 0-9 | \\d+ |
\D | 非0-9 | \\D+ |
\s | 空白字符 | [ \t\n\x0B\f\r] |
\S | 非空白字符 | [^\\s] |
\w | 单词字符 | [a-zA-Z_0-9] |
\W | 非单词字符 | [^\\w] |
解释
[]:匹配方括号内的任意一个字符。例如,[0-9]匹配任何一个数字。():用于分组。例如,a(bc)+匹配a后面跟一个或多个bc。^:在方括号内表示取反。例如,[^abc]匹配任何不是a、b或c的字符。&&:表示交集。例如,[a-z&&m-p]匹配m到p之间的字符。|:表示并集。例如,x|X匹配x或X。.:匹配任意字符(除了换行符)。\:转义字符,用于转义特殊字符。\d:匹配任何一个数字(0-9)。\D:匹配任何一个非数字字符。\s:匹配任何一个空白字符(包括空格、制表符、换行符等)。\S:匹配任何一个非空白字符。\w:匹配任何一个单词字符(包括字母、数字和下划线)。\W:匹配任何一个非单词字符。
这些符号和示例可以帮助你更好地理解和使用正则表达式。
7.4.2 量词总结表。
| 符号 | 含义 | 示例 |
|---|---|---|
? | 0次或1次 | \\d? |
* | 0次或多次 | \\d* (abc)* |
+ | 1次或多次 | \\d+ (abc)+ |
{} | 具体次数 | a{7} \\d{7,19} |
(?i) | 忽略后面字符的大小写 | (?i)abc |
a((?i)b)c | 只忽略b的大小写 | a((?i)b)c |
解释
?:匹配前面的字符0次或1次。例如,\\d?匹配0个或1个数字。*:匹配前面的字符0次或多次。例如,\\d*匹配0个或多个数字,(abc)*匹配0个或多个abc。+:匹配前面的字符1次或多次。例如,\\d+匹配1个或多个数字,(abc)+匹配1个或多个abc。{}:匹配前面的字符具体的次数。例如,a{7}匹配7个a,\\d{7,19}匹配7到19个数字。(?i):忽略后面字符的大小写。例如,(?i)abc匹配abc、ABC、aBc等。a((?i)b)c:只忽略b的大小写。例如,a((?i)b)c匹配abc、aBc,但不匹配ABC。
八、爬虫
8.1 条件爬取
8.1.1 正向预查
要匹配的内容后面加上一个正向预查,指定后面的数据需要存在但不包含在匹配结果中。
String text = "前面的数据后面的数据";
String pattern = "前面的数据(?=后面的数据)";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(text);
if (m.find()) {
System.out.println(m.group());
}
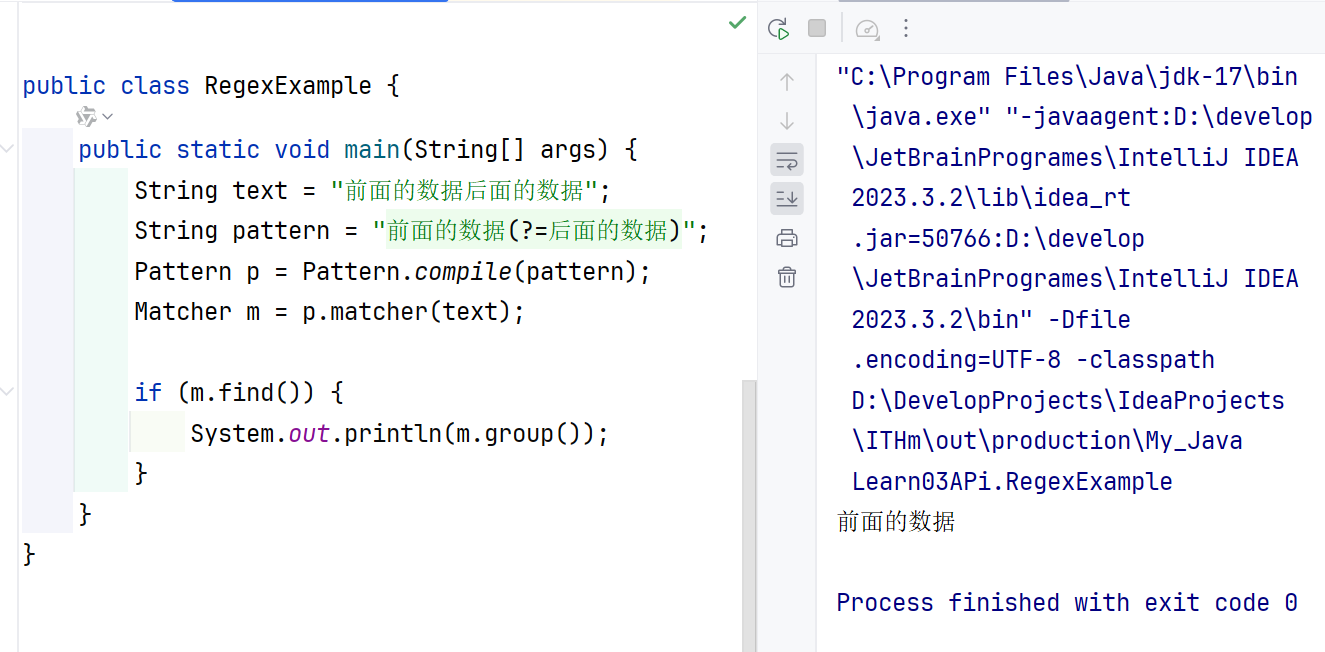
在这个示例中,正则表达式(?=后面的数据)表示匹配"前面的数据"后面紧跟着"后面的数据",但只返回"前面的数据"部分。
8.1.2 其他的
String text = "前面的数据后面的数据";
String pattern = "前面的数据(?:后面的数据)";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(text);
if (m.find()) {
System.out.println(m.group());
}
非捕获分组不需要再用本组数据,仅仅把数据括起来,不占组号。
(?:)(?=)(?!)
| 符号 | 含义 |
|---|---|
?:正则 | 获取所有 |
?=正则 | 获取前面 |
?! 正则 | 获取不是指定内容的前面的部分 |
8.2贪婪爬取
只写+或者·*·就是贪婪爬取
+?非贪婪爬取
*?非贪婪爬取

以下是使用贪婪匹配和非贪婪匹配的正则表达式示例:
- 使用贪婪匹配
+:
String text = "aaaaaab";
String pattern = "a+";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(text);
while (m.find()) {
System.out.println("贪婪匹配结果:" + m.group());
}
- 使用非贪婪匹配
+?:
String text = "aaaaaab";
String pattern = "a+?";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(text);
while (m.find()) {
System.out.println("非贪婪匹配结果:" + m.group());
}
- 使用贪婪匹配
*:
String text = "aaaaaab";
String pattern = "a*";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(text);
while (m.find()) {
System.out.println("贪婪匹配结果:" + m.group());
}
- 使用非贪婪匹配
*?:
String text = "aaaaaab";
String pattern = "a*?";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(text);
while (m.find()) {
System.out.println("非贪婪匹配结果:" + m.group());
}
这些示例演示了贪婪匹配和非贪婪匹配在正则表达式中的应用。
8.3 正则表达式中的方法
在Java中,正则表达式的常用方法包括matches、replaceAll和split。下面是它们的简要介绍:
matches:用于检查整个字符串是否匹配正则表达式。返回一个布尔值,表示是否完全匹配。
String text = "Hello, World!";
boolean isMatch = text.matches("Hello.*");
System.out.println(isMatch); // true
replaceAll:用于替换字符串中匹配正则表达式的部分。可以用指定的字符串替换匹配的部分。
String text = "apple, orange, banana";
String replacedText = text.replaceAll("\\b\\w+\\b", "fruit");
System.out.println(replacedText); // fruit, fruit, fruit
split:根据正则表达式将字符串拆分为子字符串数组。返回一个字符串数组,包含根据正则表达式拆分的子字符串。
String text = "apple,orange,banana";
String[] fruits = text.split("a");
for (String fruit : fruits) {
System.out.println(fruit);
}
//pple,or
//nge,b
//n
//n
这些方法可以帮助你在Java中使用正则表达式进行匹配、替换和拆分字符串。
8.4 分组
在Java中,可以使用圆括号()来创建一个分组。
在正则表达式中,分组可以对匹配的部分进行逻辑分组,以便后续引用或操作。
组号是连续的,从1开始不间断的。以左括号为基准。
非捕获分组不需要再用本组数据,仅仅把数据括起来,不占组号。
(?:)(?=)(?!)

public class SimplifyString {
public static void main(String[] args) {
// 定义原始字符串
String s = "aabbbbbbcccc";
// 使用正则表达式替换重复的字符
// (.) 捕获组匹配任意字符
// \\1+ 量词匹配捕获组1的一次或多次出现
// $1 引用捕获组1的内容(即匹配的单个字符)进行替换
String simplified = s.replaceAll("(.)\\1+", "$1");
// 输出简化后的字符串
System.out.println(simplified); // 输出: abc
}
}
8.4.1 首尾相同单字符 abc123cba
\\组号意味着吧X组的东西在拿来用一次
String regex1="(.).+\\1";
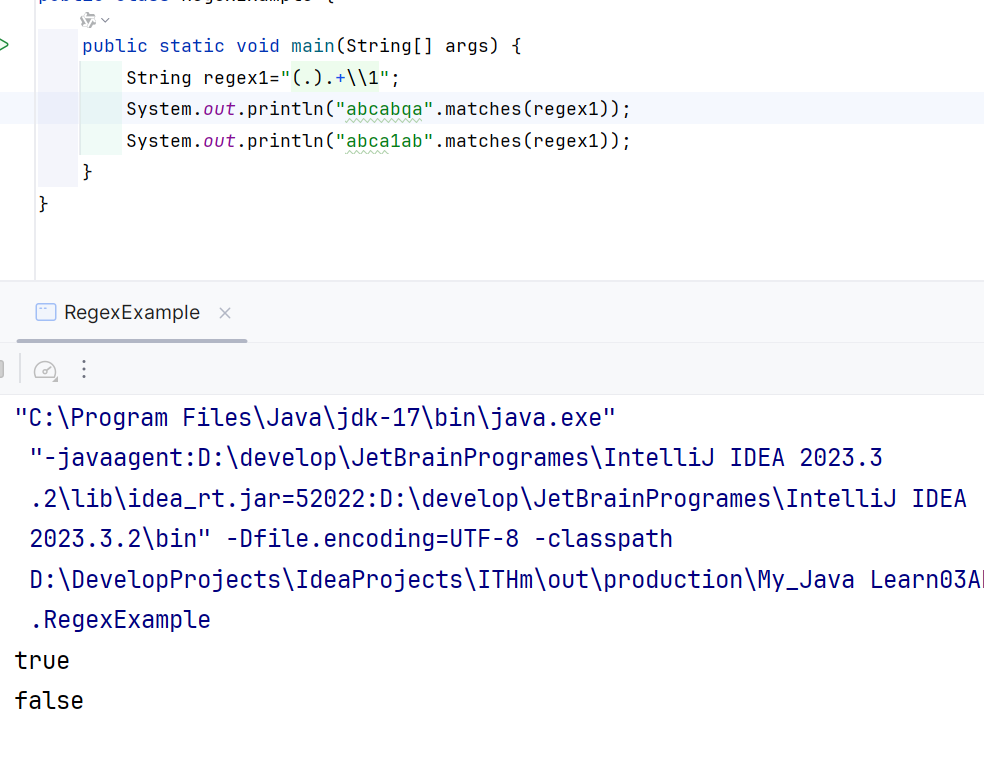
8.4.2 首尾相同多字符abc123abc
String regex1="(.+).+\\1";
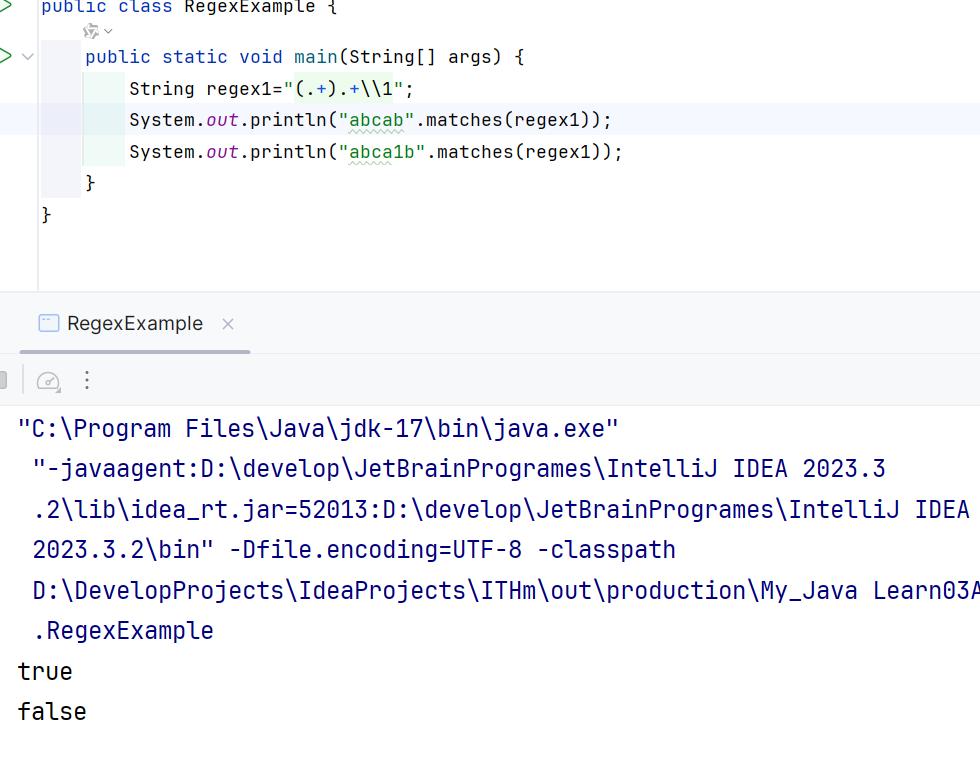
8.4.3 开始的样式和结束的样式一样aaa12aaa
(.)是把字母看做一组
\\2是把首字母重复
*是把\\2, ——— 0次或者多次
String regex1="((.)\\2*).+\\1";