目录
1. 软件包管理器yum
1.1 概念介绍
在Linux下安装软件,一个通常的办法是下载程序的源代码,并进行编译,得到可执行程序。但是这样太麻烦,于是把一些常用的软件提前编译好,做成软件包(可理解成windows下的安装程序)放在一个服务器上,通过包管理器可以很方便的获取到这个编译好的软件包,直接进行安装:
软件包和软件包管理器 <——> ''App"和“应用商店”
yum(Yellow dog Updater,Modified) 是 Linux 系统中常见的包管理器之一,特别是在 RHEL(Red Hat Enterprise Linux)、CentOS、Fedora 等基于 RPM(Red Hat Package Manager)系统的发行版上广泛使用。
系统中的软件仓库配置文件(.repo),即软件源的获取和更新途径:/etc/yum.repos.d/
示例(云服务器):
1.2 更换镜像源(可选)
通常,base和epel可配置第三方镜像源:优化下载速度,获得更多软件包选择和满足特定应用的需求。
特别是由于,目前市场上个人和企业的主流使用版本Centos7, 官方团队已于2024年6月30暂停对其维护和更新(转而投入不同于 稳定版的 “滚动更新模式Stream”),官方源不再可用!
导致国内的某些开源镜像网站对此也不再 同步维护更新,甚至直接删除下架(比如:USTC,TUNA)。
这里列几个可用的稳定获取源镜像:
(sudo 或 root用户)
1. 先备份配置文件:
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2. 下载新的 CentOS-Base.repo 到 /etc/yum.repos.d/
查看系统版本:uname -r 查看内核版本和硬件架构 或 cat /etc/redhat-release
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.tencent.com/repo/centos7_base.repo 或 centos8_base.repo 或 centos8-stream.repocurl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo 或者 Centos-vault-6.10.repo 或者 Centos-vault-8.5.2111.repo
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.huaweicloud.com/repository/conf/CentOS-7-anon.repo 或者 CentOS-8-anon.repocurl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.163.com/.help/CentOS7-Base-163.repo 或者 CentOS6-Base-163.repo 或者 CentOS5-Base-163.repo3. 执行yum clean all清除原有 yum 缓存
4. 执行yum makecache(刷新缓存)或者yum repolist all(查看所有配置可以使用的文件,会自动刷新缓存)
同样的,其它仓库,如 epel* 也可换第三方镜像源 。
(注意:上述URL地址配置可能会由于镜像提供商的更改调整导致错误或失效,具体可以厂商的官方文档为主)
1.3 工具的搜索/查看/安装/卸载
通过 yum list 命令可以罗列出当前一共有哪些软件包,但由于包的数目可能非常之多, 通常搭配 grep 命令只筛选出我们关注的包。
比如:pv (Pipe Viewer)工具,显示管道传输的数据进度
yum list | grep pv
示例输出:

说明: 软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
1. "x86_64" 后缀表示64位系统的安装包
2."el7" 表示的是 centos7/redhat7
3. 最后一列, epel (扩展) 表示的是 "软件源" 的名称, 类似于 "小米应用商店", "华为应用商店" 这样的概念
然后选择合适的版本安装:
yum install -y pv.x86_64 或者直接 pv 系统会自主选择合适的版本 //-y的作用:直接安装,跳过询问出现 "complete" 字样, 说明安装完成;可用 which指令 查看所在位置,通常是 /usr/bin/ 【包含了绝大多数用户可以直接执行的二进制文件和脚本,比如:ls,cp,mv,......】;使用时也需要带必要的选项 和 参数。
注意:安装软件时由于需要向系统目录中写入内容, 需要 sudo 或者切到 root 用户下才能完成; yum安装软件只能一个装完了再装另一个,正在yum安装一个软件的过程中, 如果再尝试在另一终端用yum安装另外 一个软件, yum会报错。
演示一下使用效果:
搭配其它软件工具 fortune(显示一个随机的有趣的或富有哲理的名言或者笑话);cowsay(将文本放在一个 ASCII 风格的牛的对话框内)
fortune | cowsay | pv -qL 70 //-q:静默模式(它会关闭进度条的显示);-L:传输速率限制
其它有趣的小软件,比如:sl(显示一个动画的蒸汽火车从屏幕上驶过,选项-alFc 有不同的显示效果);toilet和figlet(将文本转换为大型的 ASCII 艺术字);cmatrix(在终端中显示一个类似《黑客帝国》中那种“数字雨”的动画效果);asciiquarium(在终端上创建一个 ASCII 风格的水族馆,里面有鱼游来游),......,有兴趣的可以自己玩一玩
另外有用的工具,比如:lrzsz(跨平台的文件传输,可鼠标直接拖拽),htop(一个交互式的进程查看器,可以动态地查看和管理系统的进程;与 top 类似,但界面更友好,带有彩色图表显示);一些编译环境工具,比如gcc/g++,jdk等等,也都有不同程度的镜像源提供,可按需选择
. . . . . .
如何卸载:
yum remove -y 工具名 //root用户或sudo 1.4 优势
除了上面说的,yum包管理器可以自动检测和解决包的依赖关系,具有高效的搜索功能,实现便捷的安装和卸载,很大程度上避免了用户自己手动处理可能遇到的错误和麻烦,提高生产开发效率外;和用户可以自定义和添加新的仓库,使软件的获取渠道更加灵活外。其好处还有:
1. 可以通过 yum update 命令自动获取和安装最新版本的包,保持系统和软件的安全性和最新状态
2. 通过 yum history 命令可以查看之前的操作记录,并且可以还原之前的系统状态或撤销某些操作,增加了系统的可维护性
3. 支持群组安装(group install),可以一键安装一组相关的包;例如,使用 yum groupinstall "Development Tools" 可以安装开发环境所需的所有工具,大幅减少手动安装每个开发工具的工作量,为项目开发和构建提供完整的支持,比如:
- gcc:GNU 编译器,用于 C 语言和 C++ 的编译。
- make:自动化构建工具,常用于编译软件。
- gdb:GNU 调试器,用于程序调试。
- binutils:二进制工具,包括
as(汇编器)、ld(链接器)等。 - 其他库和开发工具:为构建复杂的软件项目提供依赖。
4. 由于 yum 支持命令行操作,可以很方便地用于自动化管理和配置,尤其适合用于大规模系统中批量管理软件包
5. 清理和优化,比如 yum clean all 可以清除系统缓存,节省空间;yum makecache 刷新 yum 包管理器的缓存,从系统配置的仓库中下载最新的元数据(关于可用软件包的信息),这样可以加快后续 yum 命令的执行速度,因为它们不需要即时从仓库获取元数据,保证包管理器的效率
2. vim编辑器
2.1 vi和vim
-
vi:是一种经典的、基础的文本编辑器,最初用于 Unix 系统。它功能简单,提供了多模式编辑(正常模式、插入模式、命令模式等),常用于基本的文本编辑。 -
vim:全称 Vi IMproved,是vi的增强版,兼容vi的所有指令,同时增加了许多新的特性,例如:- 语法高亮:支持代码的语法加亮,便于阅读和编辑。
- 多级撤销:支持多次撤销操作,而
vi通常只支持一次撤销。 - 可视模式:允许在选中块的基础上进行复制、删除等操作。
- 跨平台支持:除了在终端运行,
vim也支持在 GUI 环境(如 X Window、macOS、Windows)中运行,具有更友好的图形界面。
因此,vim 可以被视为功能更强大、用户体验更佳的 vi。
2.2 三种常用模式和操作
编辑文件指令:vim 文件名 (命令模式)

说明:
1. 命令模式(正常模式):
1.1 移动光标
vim可以直接用键盘上的光标来上下左右移动,但正规的vim是用小写英文字母「h」、「j」、「k」、 「l」,分别控制光标左、下、上、右移一格
按「G」:移动到文本的最后
按[gg]:移动到文本开始
按[#gg]或者 「#G」:移动到第#行的开头,比如20gg,56G
按「$」:移动到光标所在行的“行尾”
按「^」:移动到光标所在行的“行首”
按「w」:光标跳到下个字(空格,分号等分隔的字符串被判断成一个字词,后面提到的字都是这意思)的开头
按「e」:光标跳到下个字的字尾
按「b」:光标回到上个字的开头
按「#l」:光标移到该行光标后的第#个字符位置,如:5l,56l
按「ctrl」+「b」:屏幕往“后”移动一页;按「ctrl」+「f」:屏幕往“前”移动一页 按「ctrl」+「u」:屏幕往“后”移动半页 按「ctrl」+「d」:屏幕往“前”移动半页
1.2 删除
「x」:每按一次,删除光标所在位置的一个字符
「#x」:例如,「6x」表示删除光标所在位置的“后面(包含自己在内)”6个字符
「X」:大写的X,每按一次,删除光标所在位置的“前面”一个字符
「#X」:例如,「20X」表示删除光标所在位置的“前面”20个字符
「dd」:删除光标所在行
「#dd」:从光标所在行开始删除#行
1.3 复制
「yw」:将光标所在之处到字尾的字符复制到缓冲区中
「#yw」:复制#个字符到缓冲区
「yy」:复制光标所在行到缓冲区
「#yy」:例如,「6yy」表示拷贝从光标所在的该行“往下数”6行
「p」:将缓冲区内的字符贴到光标所在位置
「#p」:粘贴几次
注意:所有与“y”有关的复制命令都必须与“p”配合才能完 成复制与粘贴功能!
1.4 替换
「r」:替换光标所在处的字符
「R」:替换光标所到之处的字符,直到按下「ESC」键为止
1.5 撤销上一次操作
「u」:如果误执行一个命令,可以马上按下「u」,回到上一个操作;按多次“u”可以执行多次回 复
「ctrl + r」: 撤销的恢复
1.6 更改
「cw」:更改光标所在处的字符到字尾处
「c#w」:例如,「c3w」表示更改3个字
1.7 「ctrl」+「g」列出光标所在行的行号
2. 底行模式(末行模式):
2.1 在文件中的每一行前面列出行号:[set nu]
2.2 跳到文件中的某一行首: 「#」:「#」号表示一个数字
2.3 查找字符 「/关键字」(往后)或 [?关键字](往前);如果第一次找的关键字不是您想要的,可以一直按 「n」,直到文本末尾或开始
2.4 新建并打开指定路径的文件:
:vsp filename " 垂直分屏并打开指定文件
:sp filename " 水平分屏并打开指定文件
如果文件不存在,Vim 会自动创建一个新文件,并在分屏窗口中打开它。
ctrl + ww :在所有分屏中依次切换。
并且,可以通过命令模式实现跨屏复制粘贴!
2.5 保存文件 「w」
离开vim 「q」:如果无法离开vim,可以在「q」后跟一个「!」强制离开vim
「wq!」:一般建议离开时,搭配「w!」一起使用,这样在退出的时候还可以保存文件
3. 批量化注释和去注释
注释:命令模式下ctrl + v,然后hjkl选择区域,shift+i插入//,最后ESC
去注释: 命令模式下ctrl + v,然后hjkl选择区域,接着 d
2.3 配置vim
在目录 /etc/ 下面,有个名为vimrc的文件,这是系统中公共的vim配置文件,对所有用户都有效。 而在每个用户的主目录下,都可以自己建立私有的配置文件,命名为“.vimrc”。例如,/root/目录下, 通常已经存在一个.vimrc文件,如果不存在,则可自行创建。
为 Vim 增加自定义配置可以显著提升编辑效率,优化操作体验,使其符合个性需求,比如:自定义快捷键、行号(set nu),语法高亮(syntax on)、代码补全和缩进(set shiftwidth=4)等,可以让文本更易读、编辑更流畅;特别是其支持多文件分屏和标签页导航,则让复杂项目的管理更加灵活。此外,结合插件扩展功能与自动化配置,Vim 能成为一个跨平台一致、持久高效的开发环境,从而大幅提高工作的效率和舒适性。
一键式安装(同时安装依赖的程序,包括 git, neovim, ctags等):VimForCpp
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh【支持Centos7 x86_64】
注意:在 shell 中执行指令,按照提示输入 root 密码(想在哪个用户下让vim配置生效, 就在哪个用户下执行这个指令. 强烈 "不推荐" 直接在 root 下执行)
卸载方法:
在安装了 VimForCpp 的用户下执行:
~/.VimForCpp/uninstall.sh3. Linux编译器-gcc/g++
gcc 和 g++ 都属于 GNU 编译器集合(GNU Compiler Collection),它们有着密切的关系:
-
gcc是一个编译器驱动程序,通常用于编译 C 语言程序。 但作为一个多语言编译器,可以支持不同的编程语言,如 C、C++、Objective-C、Fortran 等;尽管gcc可以用于 C++ 编译,但它的默认行为是按照 C 语言的规则进行编译和链接,不会启用特定的 C++ 语法处理规则,会导致编译出错或无法正确链接 C++ 的标准库。解决办法:显式链接 C++ 标准库,比如: -
gcc t.cpp -o t.out -lstdc++ -
g++是gcc的一个专用版本,专门用于编译 C++ 程序。与gcc不同,g++具有特定的默认行为,如自动链接 C++ 标准库,使其更适合用于 C++ 编程;g++对 C++ 的语法、类型检查和链接特性进行了优化;也可以编译.c文件。
所以,g++ 实际上是 gcc 的一个子命令或前端,专用于处理 C++ 源代码;使用相同的编译工具链和后端。
安装:
sudo yum install -y gcc gcc-c++验证版本:
gcc 或 g++ --version使用格式:
gcc/g++ [选项] 要编译的文件 [选项] [目标文件]-E 预处理【注释删除,文件包含,符号替换和宏扩展】后停止,不生成文件,需要把它重定向(-o)到一个输出文件里面(一般命名为后缀是 .i 的文件)
-S 把高级语言代码(.i文件)翻译成汇编指令【语法,语义,此法分析,符号汇总】,默认生成到 .s 文件
-c 把汇编代码转化成机器可识别的二进制指令【形成符号表】(不可执行)
-o 结果输出到某文件
-O0 -O1 -O2 -O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
-w 不生成任何警告信息
-Wall 生成所有警告信息
-g 附加生成调试信息,GNU 调试器(gdb)需要利用该信息
-static 此选项对生成的可执行文件采用静态链接
-shared 此选项将尽量使用动态库,所以生成文件比较小,即动态链接
函数库的概念和分类:
在C/C++程序中,并没有定义例如:“printf” 的函数实现,且在预编译中包含的 “stdio.h”头文件中也只有该函数的声明, 而没有定义函数的实现。
系统把这些函数实现到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到 系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数“printf”的正常调用了。【链接实现:段表的合并;符号表的合并和重定向】
函数库一般分为静态库和动态库两种:
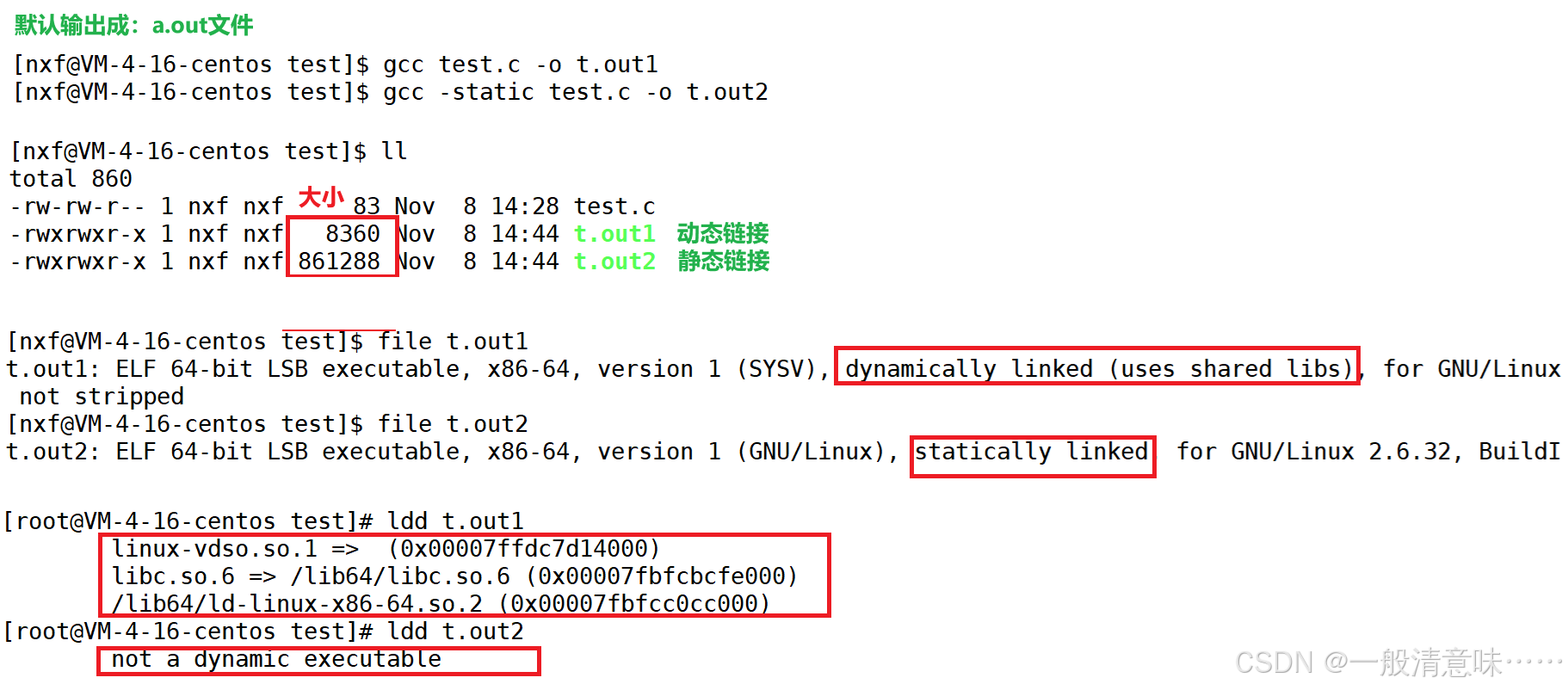
静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要依赖库文件了,其后缀名一般为“.a” 。
动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中, 而是在程序执行时再加载库,这样可以节省系统的开销,动态库一般后缀名为“.so”,如前面所述的 libc.so.6 就是动态 库。
gcc 在编译时默认使用动态库。完成了链接之后,就生成可执行二进制文件;可用 file 或 ldd指令验证
在安装gcc/g++时,为了节省磁盘空间和利于更新,通常不会默认安装静态库,可用以下指令安装:
sudo yum install -y glibc-static libstdc++-static如下示例:
4. Linux调试器-gdb
程序的发布方式有两种,debug模式和release模式 ,gcc/g++编译链接生成的可执行二进制程序,默认是release模式。
要使用gdb调试,必须在源代码生成二进制程序的时候, 加上-g选项,附带调试信息。 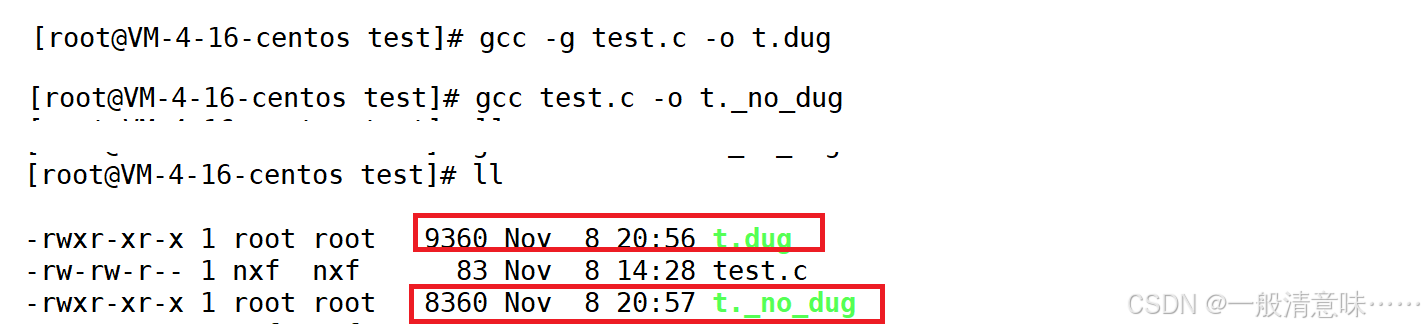
常用指令:
l或list (可选:行号):默认显示下一个10行源代码(指定位置附近的源代码)
b或break 行号或函数名: 在指定位置打断点
i b或 info breakpoints:列出所有断点
d或delete 断点编号: 删除指定断点
disable / enable 断点编号: 禁用/启用断点
r或run:启动被调试程序,在第一个断点处停下
q或quit:退出调试
help <command> :查看具体命令的描述
n或next:逐过程
s或step:逐语句,可进入函数内部
c或continue:继续执行程序,直到下一个断点或程序结束
finish:继续执行,直到退出当前函数
until 行号:运行到指定位置
p或print 表达式:打印其值,可以是变量、结构体成员、计算表达式等,例如 print x,p 1+1
set variable <var>=<value>:设置变量的值。例如,set variable x=10
info locals:显示当前堆栈帧中的所有局部变量
x/<n><fmt> <address(&变量)>:查看内存内容,其中 <n> 是显示的单位数,<fmt> 指定格式(x:十六进制,d:十进制,s:字符串,c:字符等)
比如:(gdb) x/5dw 0x7fffffffdb30 查看数组中的 5 个整数,十进制显示,w表示字大小(4byte)
(gdb) x/20xb 0x7fffffffdb30 显示 20 个字节,以十六进制格式展示,b表示子大小(1byte)
【h:半字(halfword,2 bytes);g:双字(giant word,通常是 8 bytes)】
bt 或 backtrace:显示当前调用堆栈 。比如:
f或frame <frame-number>:切换到指定帧
i f或info frame <frame-number>:显示当前或指定帧的意思
up / down:在调用堆栈中向上或向下移动一个栈帧
info functions:列出程序中所有的函数
info variables:列出所有的全局和静态变量
watch <expression>:设置一个观察点,当表达式的值发生变化时暂停程序
【栈帧(Stack Frame)是程序在函数调用时用来存储函数的局部变量、参数、返回地址等信息的一块内存区域。每次函数调用都会在栈(stack)上分配一个新的栈帧,当函数返回时,该栈帧会被销毁。栈帧主要用来维护函数调用之间的上下文信息,使得程序在多次函数调用之间能够正确地保存和恢复现场状态(返回地址)】
5. make和Makefile
make是一条命令,Makefile或makefile 是一个文件!
一个工程项目中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,解释makefile中的指令,整个工程完全自动编译,极大的提高了软件开发的效率。 一般来说,大多数的IDE都有这个命令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。
makefile的编辑格式: 示例:

//main.c
#include"../source.h/arithmetic.h"
int main()
{
int a = 10;
printf("这是一个测试!sub(10, 30)=%d\n", sub(a, 30));
return 0;
}
//arithmetic.h
#include<stdint.h>
int sub(int, int);
//func_arith.c
int sub(int left, int right)
{
return left - right;
}
makefile:

保存退出。
执行指令:make 默认情况下,读取当前所在目录下的makefile文件,并构建目标(执行第一条依赖方法)。
make <目标>:执行指定的目标规则。例如,make clean 将执行 clean 目标。
此指令的常用选项有:
-f <文件名>:指定要使用的 makefile 文件
-C <目录>:切换到指定目录执行 makefile
-n:仅显示将执行的命令,而不实际执行它们。用于调试和查看构建过程中会运行哪些命令
B:强制重新构建所有目标,而不管它们是否是最新的(默认依赖文件内容有更改才重新编译链接,较少消耗) 类似设置伪目标
-s:执行时不显示执行的命令(静默模式)
-v:显示 make 的版本信息
工作原理:
make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错, 而对于所定义的命令的错误,或是编译不成功,make根本不关注,它只管文件的依赖性。
比如:

6. git
Git 是一个分布式版本控制系统,用于跟踪几乎所有格式文件的更改。它由 Linus Torvalds 于 2005 年为管理 Linux 内核开发而创建,现在广泛用于软件开发中。
它的主要优势在于支持快速分支和合并操作,允许多个开发者在同一个项目上高效协作,而不会轻易引发冲突,所以,成为开源项目和许多企业的标准版本控制工具。
下面,小编将分两步,通过 本地管理和远程协作进行操作演示学习。
工具安装:
sudo yum install -y git6.1 本地管理
6.1.1 创建测试仓库并初始化
mkdir git-test.repo
cd git-test.repo
git init
//配置用户名和邮箱
git config [可选:--global 之后的新建仓库会自动使用本次设置] user.name “***”
git config [同理...] user.email "*********"
//可通过:git config [--global] -l 查看
//删除后重新设置:git config [--global] --unset user.name 或 user.email生成 .git 文件:
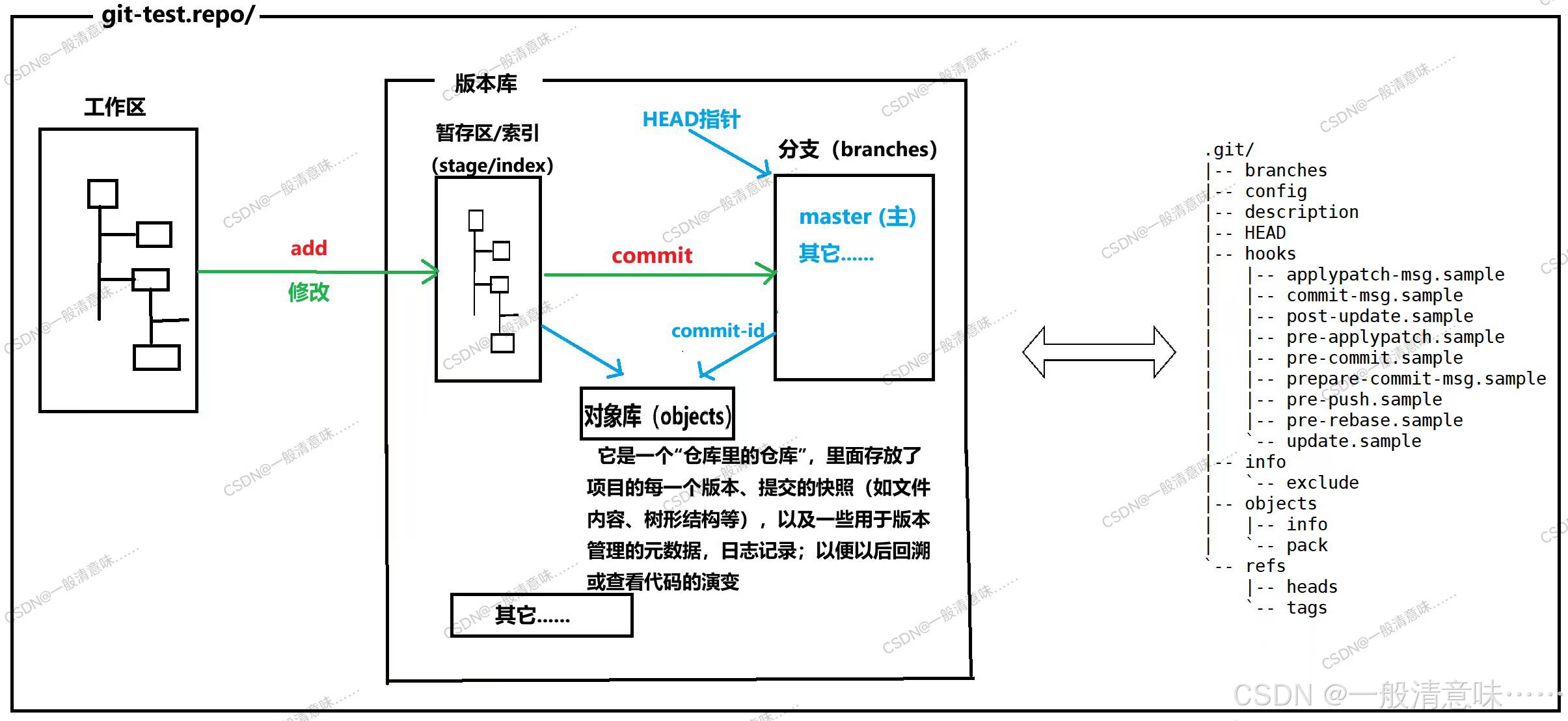
只有经过commit后,某个版本文件的更改才 真正 被git追踪管理!
当前演示并未进行任何提交修改,.git未生成index索引和object对象;并且,通过 cat .git/HEAD 输出当前指向:refs/heads/master 主分支
6.1.2 提交管理
新建文件file.txt,保存内容:"This is a test!"
git status 命令用于显示当前工作目录中已修改的文件和未跟踪的文件;它会列出文件的状态,以确定哪些文件需要被提交到版本控制系统中。
创建 .gitignore 文件用来定义哪些文件或目录不被纳入版本控制 ,从而帮助开发者更好地管理项目,比如:
#忽略文件类型
*.so
*.lib
*.out
*.exe
(也支持前加 ‘ ! ’ 打破忽略规则,特殊处理一些文件,但不常用)
#查看为什么文件被忽略追踪
git check-ignore -v <file-name>
接着:
格式:git commit -m "对本次修改提交的描述"
比如:git commit -m "这是一个新建测试文件v1.0"输出解释:
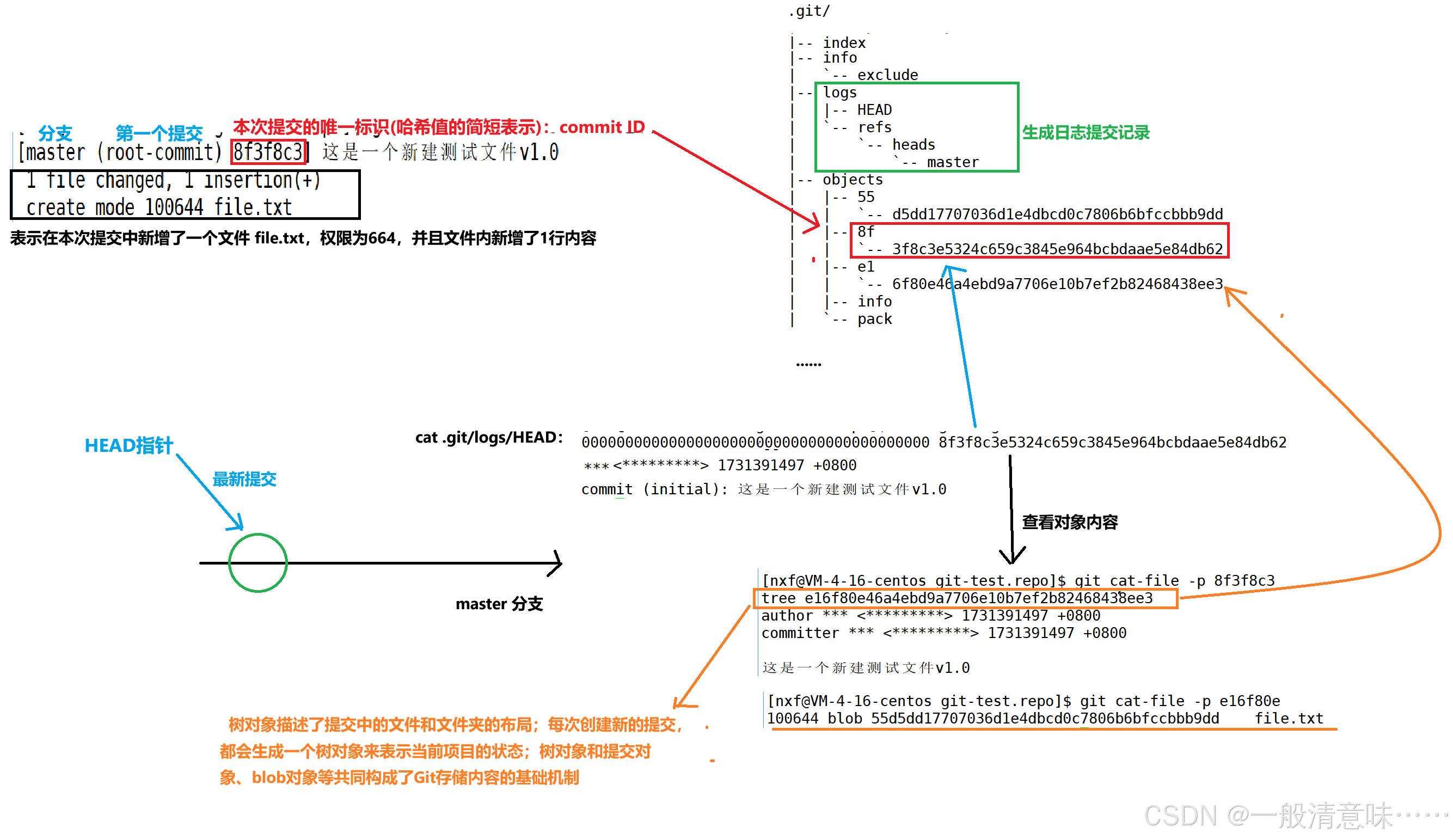
日志查看:
git log [branches 默认是当前所在分支] [选项]
常用选项:
[--graph] 提交线可视化
[--oneline] 仅显示简短的commit-id和描述,相当于:--pretty=oneline --abbrev-commit
[--decorate] 显示提交的分支引用,标签等信息
[--color] 添加颜色显示
[--first-parent] 合并时不会显示合并分支的提交,只显示主分支的提交比如,现在对 file.txt 修改后再提交,查看日志:

查看更详细的信息,可以使用:git show --color [commit-id 省略后默认为当前分支上的最新提交]

关于 diff 命令工具, 它是一个标准的 Unix/Linux 命令,用于比较文件或目录之间的差异,格式:
diff [选项] 文件/目录1 文件/目录2
选项:
-w :忽略空格差异
-i :忽略大小写差异
-u :输出为简介的统一格式,常用于生成补丁
-r :递归比较所有子文件和子目录
一般来说,diff 输出会使用 - 和 + 符号来表示内容的差异。
-表示文件中被删除或被修改的行。+表示新增的行。
git 通过将 diff 概念与版本控制集成, 并扩展其功能,来比较提交、文件和工作树之间的差异,为开发者提供了丰富的差异比较功能.
#显示工作目录中尚未提交的更改
git diff
#比较特定提交或分支之间的更改
git diff [--color] commit-id1 commit-id2 #1相较于2的更改
git diff [--color] branch1 branch26.1.3 版本回退
如果在 工作区 对一个文件进行了修改但还未暂存(git add),可使用 git checkout [branch-name] -- <file-name> 会将文件的更改撤销到某个分支的状态(暂存区的最新add版本)。
如果已经 add 甚至 commit 了,就要使用:
git reset [选项] <commit-id> #更改HEAD指针到指定的commit-id
选项说明:
--soft : 保留所有更改到暂存区(即 git add 的内容仍然保留)
场景: 当你想改变最近几次提交的历史记录,并重新组织这些更改(比如合并提交)时使用 --soft,你可以在重置后重新提交。
--mixed (默认选项):保留工作区中的文件更改(未提交的内容依然存在)
场景:当你希望取消已经暂存的更改,但保留工作目录的修改时使用
--hard(慎用):完全丢弃所有更改并重置为指定提交的状态 也可以用 git reset HEAD <file-name>/* 来将某些文件或所有已暂存的文件从暂存区移出,相当于撤销 git add 操作 。
注意:
即使使用 git reset --hard 进行版本回退,git 的对象库中的 objects对象依然存在。这是因为 git 采用了一种称为 "不可变对象存储" 的机制,所有的提交、文件和对象都会存储为唯一的哈希值。即使 HEAD 指针移动并且工作目录的状态更改了,git 仍然会保留对象库中的原始数据,只不过被“隐藏”了,因为没有任何分支或标签指向它们,直到它们被垃圾回收。
这些提交在一定时间内可以被找到并恢复,通过 reflog 显示所有的 HEAD 改动历史记录(如 reset、checkout、commit 等),比如:

如果此时想回退,依旧使用:git reset [选项] <commit-id>
git 会定期清理对象库中的“无引用对象”,这通常通过 git gc 命令进行;无引用的对象可能会在一定时间后被清理掉,但这通常取决于你配置的 git 存储策略和操作频率.
也可手动强 立即 进行垃圾回收,但这会永久删除这些对象,使用:
git gc --prune=now
单独的 git gc 指令,可能只是优化对象存储,比如合并和压缩对象包以提高效率,从而节省存储空间,并不删除任何无引用对象!
6.1.4 分支管理和合并冲突
#列出所有本地分支,当前所在分支会用 * 标记
git branch
#基于当前分支创建新分支
git branch <branch-name>
#删除本地分支,确保分支已被合并到当前分支或主分支中,否则会提示错误,若要强制删除,可以用 -D
git branch -d <branch-name>
#重命名当前分支
git branch -m <new-branch-name>
#显示当前分支的最后一次提交信息
git branch -v
#查看分支的合并状态
git branch --merged #显示已合并到当前分支的分支,可用来检查哪些分支可以安全删除
git branch --no-merged #显示未合并到当前分支的分支
#切换操作分支
git checkout <branch-name>
#创建新分支并切换
git checkout -b <branch-name>#为分支添加描述
git config branch.<branch-name>.description '描述内容'
#查看分支描述
git config branch.<branch-name>.description如下图示:
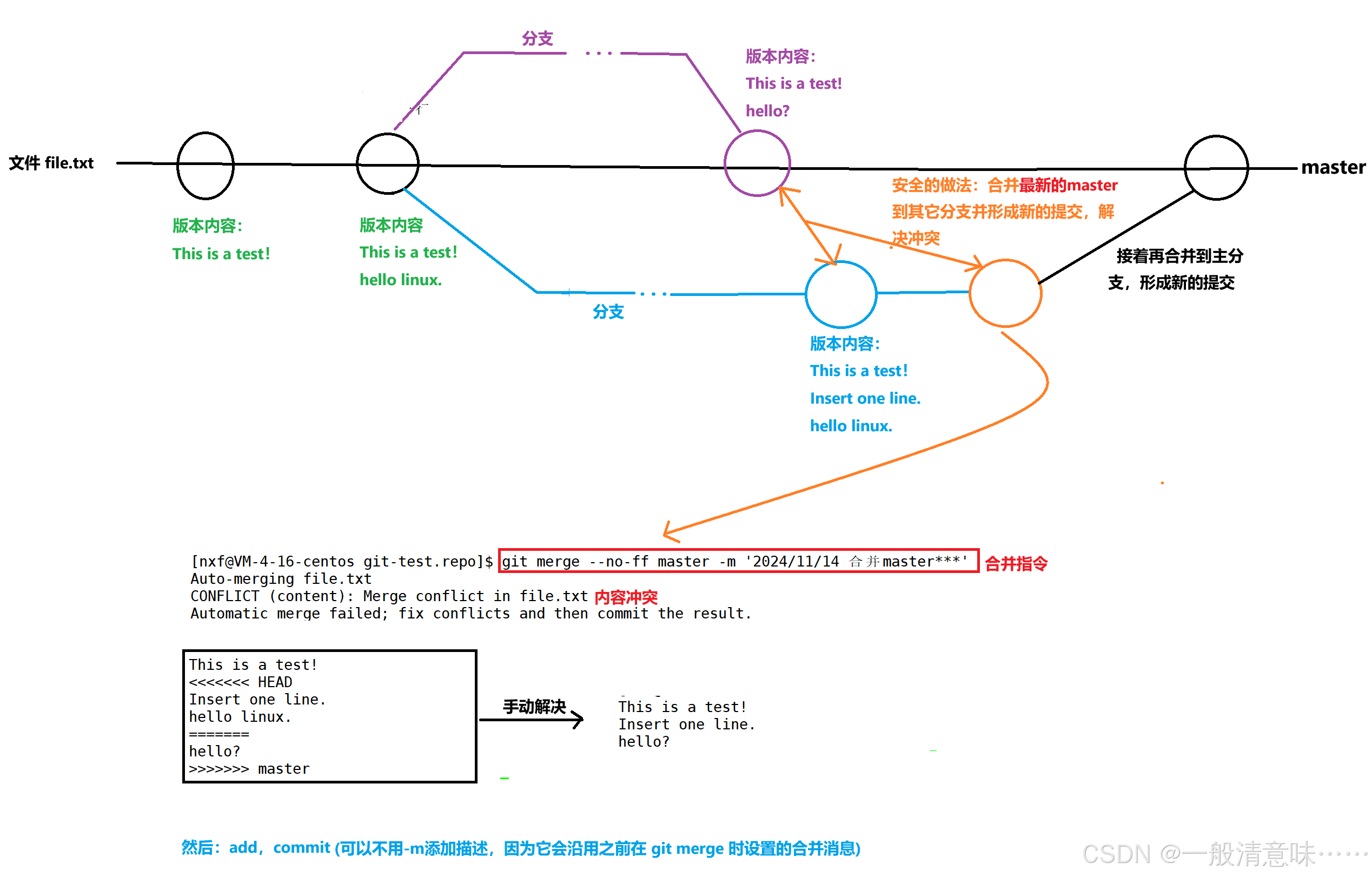
git merge 是用来合并分支的命令,它会合并目标分支中所有的更改到当前分支(包括日志记录)
如果只想合并某些特定的文件,可以使用:
git checkout <目标分支> -- <文件路径>
或者
git cherry-pick <commit-hash>
通常在完成 feature (需求开发)分支的开发并合并到 develop 或 master 分支之后,如果不再需要该 feature 分支,可以安全地删除它,有助于保持仓库的整洁,并避免过多的分支累积;甚至基于master主分支上某个版本创建的develop分支不再维护支持,也可视情况进行删除清理。
git stash
作用:临时保存工作进度,方便在不同任务分支间切换,而不需要提交中途的修改,避免和他人共享中间工作 。
git 将这些更改存储为一个特殊的对象(stash 对象),这个对象被保存在 .git/objects/
具体来说,它可以保存:工作区和暂存区的修改(默认),未追踪和.gitignore忽略的文件:
#保存当前更改,恢复工作区目录到上次提交状态
git stash [save "描述"]
#列出所有的stash条目
git stash list #输出示例:stash@{0}: On master: 修改
#显示当时与stash前的区别
git stash show [默认是 stash@{0}]
#恢复
git stash apply [默认是 stash@{0}]
git stash pop [默认是 stash@{0}] #恢复并删除此stash条目
#删除指定的stash条目
git stash drop stash@[*]
#清空所有条目
git stash clear
#暂存区保持不变,只是工作区目录被清空(返回到最新的commit-id HEAD)
git stash --keep-index
#包含未跟踪的文件一起暂存
git stash -u 或者 git stash --include-untracked
#包含未跟踪的文件和忽略文件一起暂存
git stash -a 或者 git stash -all
6.1.5 标签
打标签(tagging)是一种给特定提交打上标识的方法,通常用于标记发布版本或者重要的提交点(master,release分支)。
git 提供了两种类型的标签:
- 轻量标签(lightweight tag):它只是一个指向某个提交的引用,类似一个分支。
- 附注标签(annotated tag):除了指向某个提交外,它还包含额外的元数据,如标签的创建者、日期和标签信息,通常用于发布版本的标记。
#轻量标签
git tag <tag-name> <commit-id> 省略时默认为当前分支上的最新提交>
#附注标签
git tag -a <tag-name> <commit-id 同理> -m "标签描述"
#列出所有标签
git tag
#查看某个标签的详细信息(包括标签的作者、创建日期、标签信息,教上版本的差别等)
git show [--summary 摘要] [--color] <tag-name>
#删除标签
git tag -d <tag-name>
标签名可以直接用于 版本回退 和 分支管理 中,比如: git checkout <tag-name> 或 git reset [选项] <tag-name> 或 git checkout -b new-branch <tag-name> (基于标签创建新分支并切换)
要注意的是:标签不能像分支一样进行常规的开发,标签是不可变的标识符(静态的),而分支则是活动的、可变的,并且会随代码的提交和更新而变化。
标签 具有全局属性,即同一分支或不同分支间 不能命名同名的分支!
6.2 远程协作 --- gitee
6.2.1 git和gitee的区别和联系
Git 本身不提供代码托管功能,只是一个工具,仅仅允许用户在本地管理版本控制。
而 Gitee 是一个基于Git的代码托管网页服务平台,类似于 GitHub,但主要面向中国用户,提供远程服务器上的 Git 仓库托管服务,提供在线界面:
- 在线代码托管: 允许用户通过网页界面创建、管理、分享 Git 仓库
- 可视化界面:通过 Gitee 的网页界面,用户可以方便地进行代码查看、版本管理、提交记录查看、分支管理等操作,类似于 GitHub 的功能
- 协作和团队管理:提供了项目管理功能,如 pull requests、issue 跟踪、代码审查等
- 集成开发工具:支持与 CI/CD(持续集成/持续交付)工具的集成,帮助自动化构建和部署
- 私有仓库:提供了私有仓库功能,适合需要保护代码隐私的用户
通过克隆远程仓库到本地进行开发推送,建立绑定联系,实现代码的同步(push,pull)!
6.2.2 push和pull
克隆到本地:进入仓库,‘代码’——> 按钮‘克隆/下载’
1. 查看远程仓库的名称:
git remote默认:origin
2. 显示远程仓库 origin 的信息
git remote -v
通常输出:
origin 克隆方式(https@... 或 git@... 或 ...)(fetch)和(push)
fetch权限:用于从远程仓库获取更新的内容
push权限:用于将本地的更改推送到远程仓库3. 查看并建立本地和远程间的分支追踪关系
git branch -r #仅查看远程分支,比如:origin/master origin/develop
git branch -a #查看所有分支(本地+远程)
#查看本地已经和远程建立追踪关系的分支,比如:* master cfa88b0 [origin/master] Initial commit (master分支在克隆时已经默认建立追踪)
git branch -vv
#基于远程分支建立新分支,并自动建立追踪关系
git branch <newbranch-name> origin/<branch-name>
或者:git checkout -b <newbranch-name> origin/<branch-name>
#手动建立追踪关系
git branch --set-upstream-to=origin/<branch> [本地分支,省略时默认为当前所在分支]4. 拉取和推送
#已经建立追踪关系的分支,可直接使用短命令
git pull #从origin拉取当前分支的最新提交并将更改合并到当前分支(可能需要手动解决冲突)
git push #将当前分支的内容推送到远程仓库的对应分支
#手动指定
git pull origin <remote-branch>
git pull origin <remote-branch>:<指定的本地分支>
git push origin <本地分支>
git push origin <本地分支>:<指定的remote-branch>
#将本地的 <branch-name> 分支推送到远程 origin 仓库,并建立跟踪关系
git push -u origin <branch-name>
#拉取远程新建分支
git pull [origin]
或者指定分支 git pull origin <remote-branch-name>
#清理和修剪本地显示的 "stale"(陈旧、不再存在的)远程分支
git remote prune origin
#自动在拉取远程更新时修剪陈旧分支
git pull --prune
#本地删除远程分支(不推荐甚至不允许,慎用!!!)
git push origin --delete <remote-branch>
#推送本地的新建标签到远程
git push origin tag-name 或者 :refs/tags/tag-name 或者所有 --tags
#本地删除远程标签(不推荐的)
git push origin --delete tag-name
其它的仓库设置,表单申请,权限限制,在线管理等可点击以下链接浏览官方详细帮助文档:
https://help.gitee.com/repository
6.3 DevOps
起源和产生背景:
DevOps 的产生是为了解决传统软件开发和运维之间的种种问题。过去,开发团队负责开发新功能和代码,而运维团队负责部署、维护和管理这些应用。由于两个团队目标不同(开发追求速度和创新,而运维追求稳定和安全),导致沟通障碍、效率低下和频繁冲突。典型问题包括:
- 部署周期漫长:开发新功能后需要等待很长时间才能上线。
- 手动流程复杂:发布、测试和部署等步骤依赖于繁琐的手动操作,出错概率大。
- 缺乏协作:团队之间的分工常导致信息孤岛,影响产品的稳定性和交付速度。
因此,DevOps 文化逐渐兴起。
其特点和优势在于:
提高交付速度:通过自动化构建、测试和部署流水线,大幅缩短了开发到上线的周期,能够更快速地响应用户需求和市场变化。
持续集成和交付(CI/CD):确保代码变更能够频繁地集成、测试和发布,从而减少发布风险。
改进协作与沟通:打破开发和运维的隔阂,强调团队协作、共享责任和共同目标,从而减少冲突、提高效率。
提高稳定性和质量:自动化测试和部署减少了人为错误,系统监控和反馈循环帮助团队快速发现并解决问题。
更好的资源利用率:通过容器化、基础设施即代码(IaC)等技术, 实现了更高效的资源管理和部署。
快速回滚能力:出现问题时,DevOps 流程中的自动化工具可以帮助快速回滚,减少故障时间。
目前国际上主流的 DevOps 平台服务提供商有比如:GitHub、GitLab、Azure DevOps、AWS、Google Cloud Platform (GCP)、IBM Cloud等;国内有:gitee(码云)和 华为,阿里,腾讯,百度等大厂提供的云服务。
......
它们为本地开发团队提供优化的性能和服务,同时深度集成云平台的基础设施,帮助企业实现高效的开发、运维和交付流程。