一、应用场景
基于知识库的电影问答系统中的问句分类模块。
例如,用户可以提问“成龙演过哪些电影”“xx电影的评分是多少”等等问题,该系统基于知识库对问句进行分类。
该流程图如下:
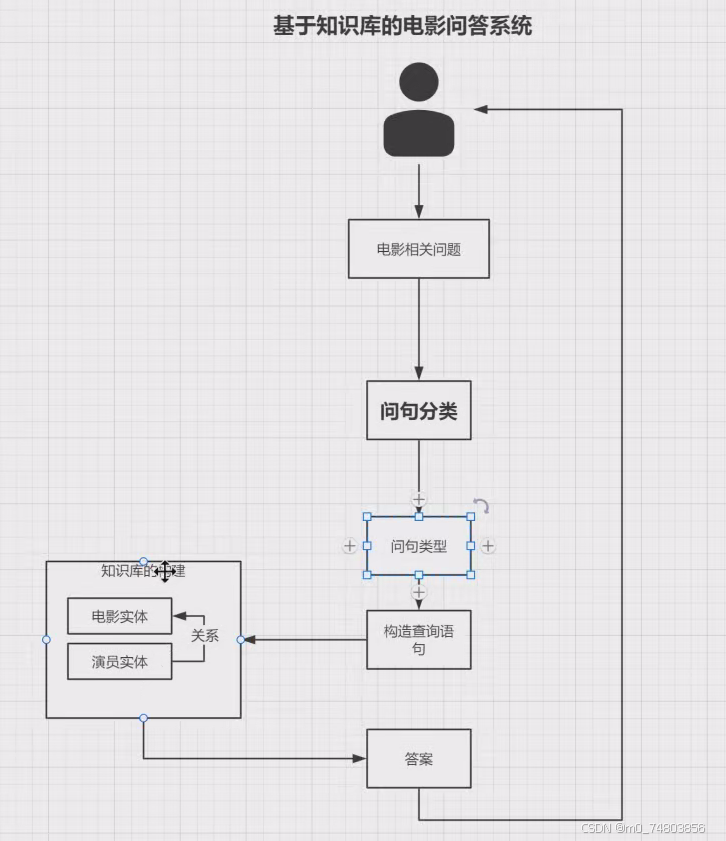
本文章只探讨问句分类部分。
二、核心任务
1. 自动识别问句类型:
"《英雄》的剧情是什么?"——分类为“电影剧情查询”
"章子怡的详细介绍?"——分类为“演员信息查询'”
问句类型包括:

2. 将自然语言问句转换为数据库查询语句:
自然语言问句:“《英雄》的剧情是什么?”
SQL查询语句:SELECT description FROM movie WHERE movie name ='英雄';
三、特征工程
实体类型
nm 表示演员 nnt 表示电影 ng 表示电影类型
使用到的工具
1. 实体标注工具——jieba分词库
2. TF-IDF文本向量化——sk-learn库
四、模型训练
1. 使用朴素贝叶斯模型(MultinomialNB)
sk-learn库模型类的构造
2. 训练模型并优化超参数
sk-learn库模型类的使用
五、模型推理
模型推理是利用己训练好的模型对新数据进行预测或分类的过程。
步骤1:数据预处理
去除特殊符号(如标点符号)。对新问句进行分词和词性标注
步骤2:特征提取
将新问句转化为特征向量
步骤3:分类推理
使用训练好的朴素贝叶斯模型对新问句进行分类输出问句所属的类别