注释:
单行注释:一般用于变量
语法://单行注释
int num = 12;
多行注释:一般用于函数
语法: /*
多行注释
*/
int main()
{
....
}
文档注释:一般用于函数、结构体、类等等,是多行注释的一种扩展的方法,本质上还是多行注释
/**
*文档注释
* @params 参数说明
*@author 编写作者
*@date 编写日期
*return 返回类型
*/
int main()
{
.....
}
花括号格式
1.左右花括号{ }要独立一行
2.左{ 的下一行代码必须要换行和缩进(一个tab键,或者偶数个空格)
3.右 } 和它匹配的左 { 要垂直对齐
标识符
组成:数字、英文字母大小写、下划线_,$
注意事项:不能以数字开头
不能是关键字
(如:int、double、main、include、stdio、if、for)
命名规范
变量名,函数名---小驼峰命名或者下划线命名
1.小驼峰命名法:如果只有一个单词,全部小写。如果超过两个单词,从第二个单词开始,首字目均大写。
eg:getAge()/userId等
2.下划线命名法:如果只有一个单词,全部小写,如果超过两个单词,单词与单词之间使用“_”进行分隔
eg:get_age()/user_id等
3.结构体名,共用体---大驼峰命名法:
大驼峰命名法:要求每个首字母都大写
eg:GetName/Stdudent/Person
4.枚举常量、自定义常量(宏符号):每个字目都大写,多个单词之间可以用“_”分割
eg:CLASS_NAME
C语言中的数据类型
基本类型
数值类型:
整 型:
短整型:short
*基本整形:int
*长整型:long
长长整型:long long
......
浮点型:
单精度浮点型:float
双精度浮点型:double
字符类型:char
自定义/构造类型[后续学]
结构体:struct
共用体:union
枚 举:enum
指针类型【后续学】:*
空类型:void
常量与变量
在C语言中数据的基本表现形式是常量与变量
常量:在程序执行过程当中其值不能改变的量称之为常量
分类:数值常量:
整数常量:
二进制常量:以0b开头由0、1两个数字构成
eg:0b1111、0b0110、0b0111
八进制常量:以0开头,有0~7八个数字构成
eg:012345、07654、-075
* 十进制常量:默认,由0~9十个数字构成
eg:1234、9876、-87654
十六进制常量:以0x(x不区分大小写)开头,由0~9,A~F共十六个字符构成,一般用于嵌入式开发
eg:0xFFFFFF(代表白色)、0xFFFF00(代表红色)
小数常量:
单精度:常常给单精度的数值后加F作为标记
eg:12.34F、-45.444F
双精度:默认是双精度
eg:12.24、-45.444(后面无标记)
字符常量
用' '(单引号)引起来的单个字符
eg:'a'、'1'
注意:'马'是错误;'ma'是正确
转义符:'\n':换行符
'\t ': 制表符
'\ \':反斜线,
'\0':0字符对应的ASCII码值是0
符号常量
使用#define定义的宏:
eg:#define PI 3.1415926 定义圆周率(Π)、
使用:2*PI
字符串常量
使用“内容...”引起来的字符序列称之为字符串常量
注意:C语言常量支持字符串,C语言变量不支持字符串(需要字符数组或者字符指针进行模拟)
eg:printf(“hello world!”)、printf(1)|printf("1")第一个输出数值常量,第二个输出字符串常量
空(null)常量
用于给指针变量作为默认初始值初始化:int*p=NULL;
注意:*前面是常量或者变量,此时*是数学运算符,*前面是数据类型,表示指针符号
补充:
长整型一般在数值后加L或l,最好用大写;
长长整型一般在数值后加LL或者ll
eg:long a=90L
long long b =99LL
变量:
概念:
表面理解:程序运行过程中取值可以改变的数据
实质:变量其实代表了一块内存区域/单元/空间。变量名可视为该区域的标识
整个变量分为三部分:
1.变量名:这个只是变量的一个标识。我们借助变量名来存取数据
2.变量空间/内存单元:这个就是内存中分配的一块用来才能出数据的空间/区域
3.数据/变量值:这个就是存放在变量空间中的数据
注意:我们把数据存放在变量名对应的空间的过程称之为赋值操作
语法:[修饰符] 数据类型 变量列表;
命名规范:1.变量名可以由数字、字母(区分大小写)、下划线、$组成,不能以数字开头
- 不建议使用中文、拼音
- 变量名不能与系统中已有的标识符重名(比如关键字、保留字... eg:int、signed、if,break....)
案例://方式一:先声明,再赋值,注意:赋值操作顺序,从右往左
int num1;
num1 = 21;//将21赋值给num1(num1对应的内存单元)
//方式二:声明并赋初始值
int num2 =21;//这句代码执行做了两件事①向内存申请了一块存储单元(分配内存)②将21赋值给num2对应的存储单元
//方式三:覆盖初始值
int num3 = 21;
num3 = 22;
//方式四:逗号在C语言中可以作为分隔符和运算符使用
int a=10,b=12,c=13;
说明:1.变量定义是利用一个类型标识符可同时定义多个变量,各变量之间使用’ , ’,分割
2.定义变量后,如果未对变量进行初值的赋予,则变量所代表的内存空间中的数据是随机安排的
3.可以在变量定义的同时给变量赋值,这个操作成为变量的初始化,C语言允许对变量进行初始化
4.初始化变量是尽量做到类型相同eg:long l =56L
5.整数数据在内存中存放的方式:按照补码方法存放
6.浮点型数据在内存中的存放方式:采用指数方式存放。注意:浮点型数据在内存中存放的是一个近似值
7.字符数据在内存中存放的方式:以ASCII码存放,字符的存在分为两种形式,ASCII码(编号,从0开始的正整数)和ASCII码值(数据,包括英文字母大小写、数字、特殊符号)。注意:ASCII码是可以和整数进行运算的(每一个英文的小写字母比它相应的大写字母的ASCII码大32)
各类数值型数据间的混合运算:
数据类型之间的转换
规则:不同的数据类型参与运算,需要转换为同一类型后运算
数值比较由小到大简单排序:short<char<int<long<float<double
- 隐式类型转换(自动类型转换)
说明:编译系统自动完成,一般是低优先级类型向高优先级类型转换,这种被称作为自动类型转换(由小到大)
语法:大数据类型 变量 = 小数据类型
eg:char c = ‘A’;
int num =c;
printf(“%d”,num);
- 强制类型转换
说明:程序员自己实现,一般是高优先级类型向低优先级类型转换,这种被操作为强制类型转换(由大到小)
语法:小数据类型 变量名 = (小数据类型)大数据类型变量;
注意:强制类型转换过程中,可能会出现精度丢失问题。如果大类型数据范围<=小类型数据范围,此时数据不会丢失,正常转换,如果大类型数据范围>小类型数据范围,此时会丢失超出部分数据,精度缺失
eg: int num1 =65;
char c1 = (char)num1;
printf(“%c”,c1);//输出”A”
运算符:
算术运算符:
单目运算符:
说明:++、--、+(正)、-(负)、*(解引用运算符)
++a与a++的区别:,int a = 1,int x =a++; ++在后,先运算,后自加(+1)
int a = 1,int x =++a;++在前,先自加(+1),后运算
案例:
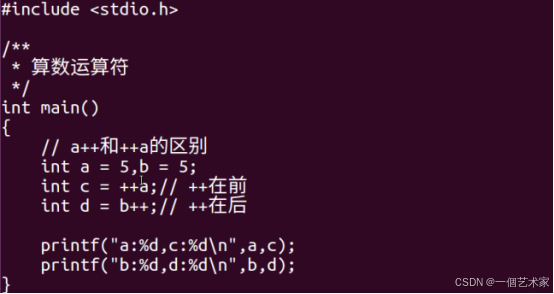
结果:
总结:无论++在前还是在后,计算数自身都会+1,区别在于运算结果不一样
练习:
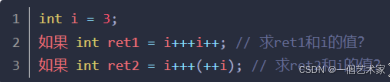
代码:
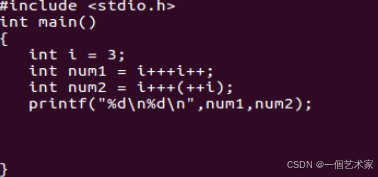
结果:
--a与a--的区别:,int a = 1,int x =--; --在后,先运算,后自加(-1)
int a = 1,int x =--a;--在前,先自加(-1),后运算
双目运算符:
说明:+、-、*、/、%(加、减、乘、除、取余)
举例:
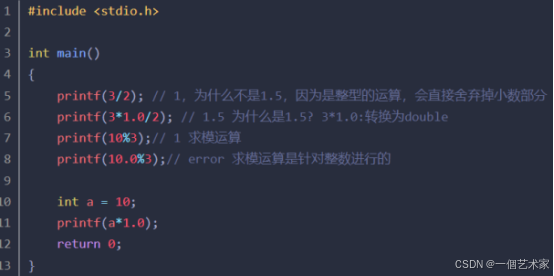
注意:
- 两个整数相除的结果是整数,小数部分舍弃。要想其结果是实数,可在分子*1.0(隐式转换)
- 求模运算(取余运算)左右两边的操作数都必须是整形,如果是类似与3.0这样的数,是错误的
三目运算符:
语法:表达式1?表达式2:表达式3,其实就是if.....else的简化版
求值顺序:如果表达式1的值为真(1),则整个条件运算表达式的值为表达式2的值
如果表达式1的值为假(0),则整个条件运算表达式的值为表达式3的
练习:使用三目运算符比较三个任意整型数的最大值
关系运算符:
说明:>、<、>=、<=、!=、==
案例:
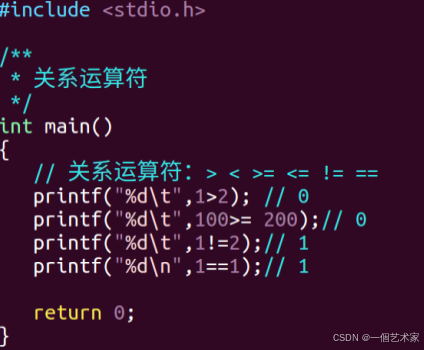
结果:
什么是表达式?
表达式就是表达某种意思的式子,在C语言中表达式指的是 运算符 连接 操作数(变量、常量等)的式子
注意:由关系运算符构成的表达式称为关系表达式,关系表达式的值为boolean(布尔值)非0(关系成立/为真),反之
逻辑运算符:
说明:&&(与)、 ||(或)、 !(非)
&&:逻辑与(且),符号两边的表达式(操作数)都为真,结果才为真
||:逻辑或(或),符号两边的表达式(操作数)其中一个为真,结果就为真
!:逻辑非(反),取反,非0为真。 eg:!(!(5>4)),结果为1*(真)
注意:算术运算符运算结果是数值类型;关系运算符运算结果是boolean类型;逻辑运算符运算结果是boolean类型
惰性运算
所谓的惰性运算,就是减少运算次数
短路与:&&两边的操作数,只要左边的不成立,直接返回假,不在校验右边
短路或:||两边的操作数,只要左边的成立,直接返回真,不要再校验右边
位运算符
说明:按照位(bit)来进行运算操作的运算符。
语法:~(按位取反)、&(按位与)、|(按位或)、^(按位异或)、<<(左移)、>>(右移)
1、~:按位取反
说明:单目运算符,数据的每一个bit位取反,也就是二进制数位上的1变0,0变1
e g: unsigned char ret = ~0x05;//0000 0101----> 1111 1010
2、&:按位与
语法:a & b
说明:首先将参与计算的操作数转化为二进制,然后按照每一位进行对齐,处理结果如下:
1 & 1-->1
1 & 0-->0
0 & 0-->0
0 & 1-->0
总结:如果我们前后两个操作数对齐位置上的二进制数字都是1,否则结果都是0
- |:按位或
语法:a | b
说明:首先将参与计算的操作数转化为二进制,然后按照每一位进行对齐,处理结果如下:
1 | 1-->1
1 | 0-->1
0 | 0-->0
0 | 1-->1
总结:如果我们前后两个操作数对齐位置上的二进制数字只要有1,否则结果为0
- ^按位异或
语法:a ^ b
说明:首先将参与计算的操作数转化为二进制,然后按照每一位进行对齐,处理结果如下:
总结:不同为真1,相同为假0

1 ^ 1-->0
1 ^ 0-->1
- <<:左移,按bit位往左偏移
①无符号的左移:
语法:操作数 << 移动位数(bit位)
unsigned int a = 3<<3
printf(“%d\n”,a);//24
②有符号位左移:
语法:操作数 << 移动位数(bit位)
int a = -3<<3
printf(“%d\n”,a);//-24
- >>:右移,按bit位往右偏移
①无符号的右移:
语法:操作数 >> 移动位数(bit位)
unsigned int a = 3>>3
printf(“%d\n”,a);
②有符号位右移:
语法:操作数 >> 移动位数(bit位)
int a = -3>>3
printf(“%d\n”,a);
案例:

结果:

注意:1.在进行以为移位运算的时候,凡是被移除出去的位统统被丢弃,凡是空出来的位统统补0,移位运算针对的是无符号位
2.如果非要进行有符号的移位运算,那么左移的时候,空出来的补0,右移的时候,空出来的补符号位(原码阶段)
扩展:

其他运算符:
说明:=、+=、-=、/=、%=
赋值运算符:
包含:=,由右向左,优先级排倒数第二
注意:赋值运算符的左边(左操作数)必须是可写的地址
复合赋值运算符:
包含:+=、-=、/=、%=,由右向左,优先级排倒数第二
int i =1;
i+=1;//等价于i=i+1
i*=5//等价于i=i*5
sizeof(int)
说明:用来计算某种或者变量所占字节数
逗号运算符(,)
说明:优先级最低,左-->右,有多个运算符将多个不同的式子连接起来的表达式称之为逗号表达式
语法:(表达式1,表达式2....);
求值顺序:先求表达式1,再求表达式2,以此类推...
注意:逗号表达式的优先级最低
运算顺序从左往右
整个逗号表达式的值取决于最右边的表达式的值
举例:
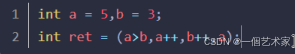
结果为:6
优先级的顺序:
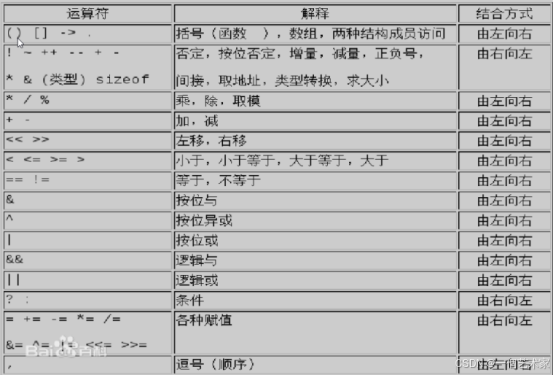
扩展:
ASCII:字符集,C语言字符就是以ASCII码进行存储,针对程序内部存储
GBK(国标):一个字符等于两个字节,表示简体,繁体及其符号。针对文件内容。\xced2
Unicode:四个字节表示,全球统一编码,囊括了全世界所有的字符。\u6211
UTF-8(全球标准):长度变化的字符集,是对Unicode字符集的优化,提高效率。针对文件内容。表示\xe68891
ISO-8859-1:西欧语言字符集。针对文件内容。
扩展:
常见的字符编码
ASCII:一个字符等于一个字节,总共256个字符,针对程序内部
GBK:一个字符等于两个字节,表示简体,繁体及其符号。\xced2
Unicode:四个字节表示,全球统一编码,囊括了全世界所有的字符。\u6211
UTF-8:长度变化的字符集,是对Unicode字符集的优化,提高效率,表示\xe68891
ISO-8859-1:西欧语言字符集
如果代码中有字符乱码---编码和解码的字符集不一致
解决方案:
1.修改成一致编码
2.换成英文或者数字,只有中文会乱码
进制转换(见pdf笔记)
其他进制转十进制:按权相加(其他进制为几就乘几)
十进制转其他进制:辗转相除法(转几进制除几),将会需要转换的数据不停的除以转换的进制数,直到商为0
八进制转十六进制:借助于十进制/二进制,将八进制转换为十进制/二进制,再将十进制/二进制转换为十六进制
十六进制转八进制:十六进制转换为二进制/十进制,将二进制/十进制转换为八进制
有符号数和无符号数
在C语言中,整数是可以带符号的(有符号,signed)或不带符号的(无符号 unsigned)。这两种类型的整数在内存中以二进制形式表示。并使用不同的模式
有符号数(Signed Numbers)
有符号数是来表示正数、负数、0的整数类型,有符号数使用最高位(通常是符号位)来表示正负,如果最高位为0则该数表示是整数或0,如果最高位为1,表示及这个数是负数。其余为用于表示数值本身。
eg:例如一个八位有符号整数可以表示的范围是-128~127,这是因为1位用于表示符号(正/负),剩下的7位
注意:有符号位是默认的,在C语言中基本整数类型如int、short、long默认为有符号数,除非明确指定为无符号
无符号数(Unsigned Numbers)
无符号数是只能表示非负整数的的数据类型。在内存中无符号数不使用符号位,所有位都用于表示数值,因此无符号数的范围比有符号数的范围大
eg:例如一个八位的无符号整数可以表示的范围是0~255,这是因为所有的八位都用来表示(存储)数值3
注意:在C语言中通过关键字后添加unsigned,来指定无符号类型,如unsigned int、unsigned short、unsigned long.....