前言:在身边计算资源有限的情况下,又需要GPU来训练自己的深度学习模型,可以租用网上现有的GPU算力,比如常见的AutoDL等,除此之外也有一些特殊的免费平台,笔者所知的有谷歌的Colab,移动的九天·毕昇,还有比赛用的kaggle平台,其中各有优劣,总的来说免费的总是有各种限制条件的,但都有一定的免费额度,感兴趣的同学可以自行搜索比较。这里以阿里云天池平台为例,描述笔者的使用过程,适用于一些小型项目或者初次使用云平台的同学拿来练手(此类平台的操作逻辑和控制台页面可谓如出一辙)。
1.使用网址:
天池实验室_实时在线的数据分析协作工具,享受免费计算资源-阿里云天池 (aliyun.com)
2.目前使用规则

CPU免费使用,GPU总计60小时,每次使用均限时8小时。
3.Notebook和数据集
使用此类平台一般需要明白两个概念,Nootbook类似于自己开发项目时的ide或者cmd终端,用来操作和部署相关的环境,数据集用来存储自己的项目和训练用的数据集。
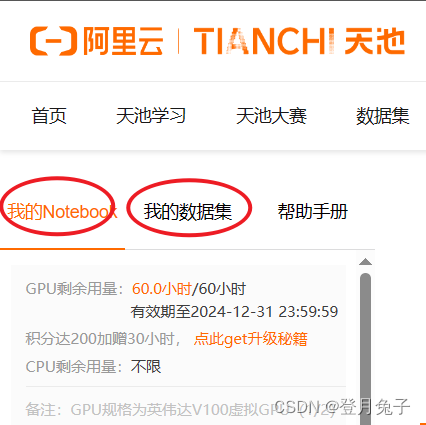
需要说明的是,Notebook里也能上传数据,但是速度非常慢,适合项目代码文件上传,但是为了方便,一般将项目和数据集一次性打包上传,然后在Notebook中挂载数据集。
4.新建数据集
在上面截图页面点击我的数据集——新建——编辑,进入以下页面
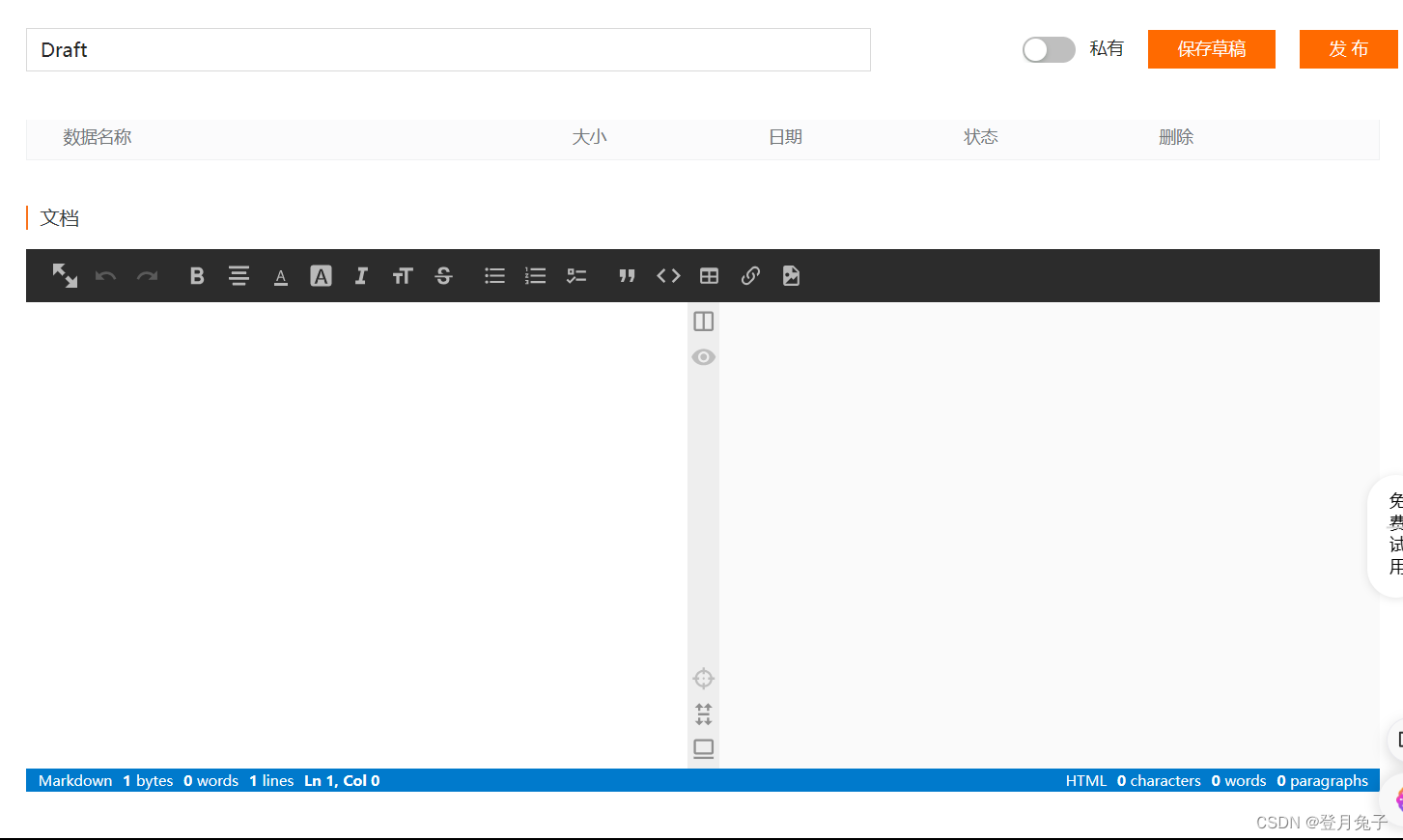
按照要求填写相关信息,上传自己的压缩包文件即可,文件大小及类型规则如下。

若是大小超出限制,建议拆分文件建立多个数据集,在Nootbook中挂载多个即可。
5.Nootbook使用
我的Nootbook——新建——挂载数据(选择自己创建的数据集)——编辑,进入以下页面。

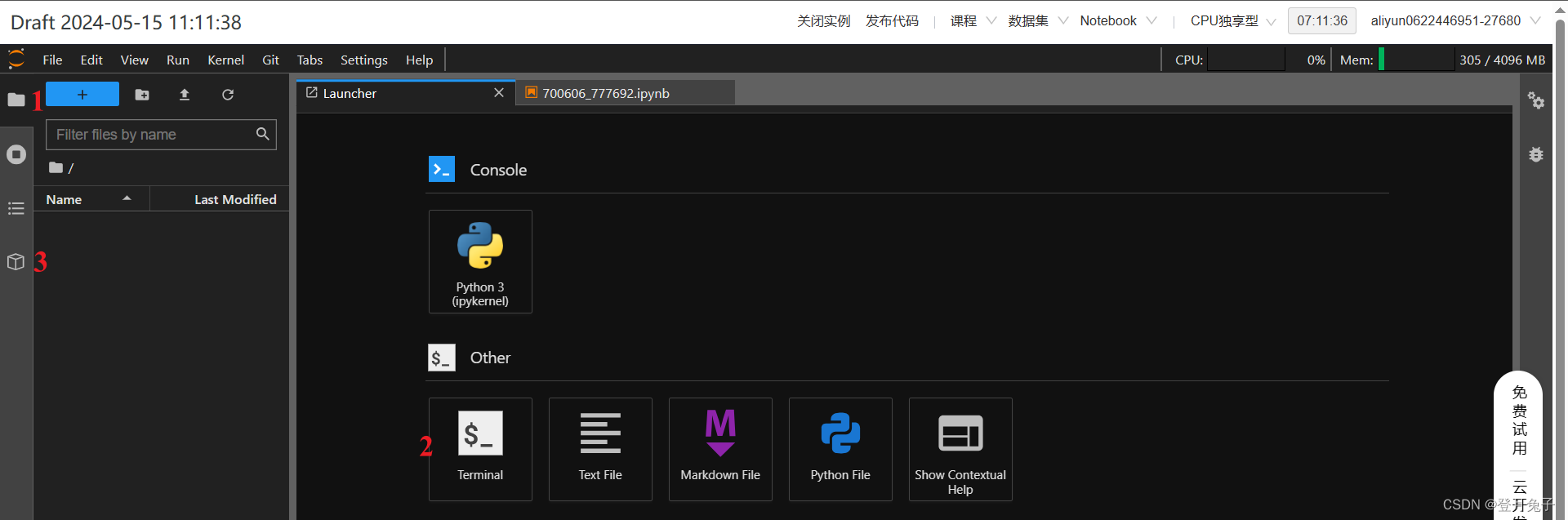
上图中,1为工作文件夹,你的项目文件和数据集将在这里呈现,2是terminal(笔者习惯使用terminal指令完成操作,也可以在已打开的ipynb页面完成操作控制),3是数据管理单元,在这里进行挂载数据的下载和公共数据集的下载,挂载的数据集出现在RELATED栏目下,下载即可,已下载的数据将出现在1中的download文件夹下。
解压文件:
右键zip文件是没有解压操作的,需要使用指令完成,以terminal为例:
cd download
unzip (your_dataset)6.环境配置
按照自己在电脑上的配置环境的要求,在terminal使用pip指令安装即可,一般不会出现任何问题,而且服务器下载的速度非常快。如果由requirements.txt,cd到相应的目录下,使用指令安装即可:
pip install -r requirements.txt7.使用GPU
在之前的版本中,GPU和CPU可以无缝切换,并不会影响当前实例的数据,但是当前版本切换GPU实例相当于重新进入一个新的容器实例,十分不方便,需要按照上面的操作重新来一遍即可。
笔者注:
我的使用中用到了Pytorch,需要安装与平台Cuda版本相对应的torch,否则无法调用GPU。这里一并展示,需要的同学可以借鉴。
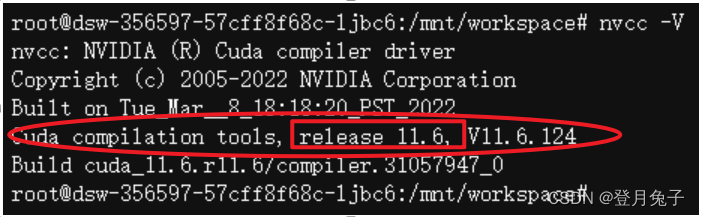
- 查看平台Cuda版本
nvcc -V此处Cuda版为11.6 - Pytorch官网查找对应版本
Previous PyTorch Versions | PyTorch
使用浏览器搜索功能查找相应的Cuda版本,复制对应的安装命令到平台安装即可。pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116