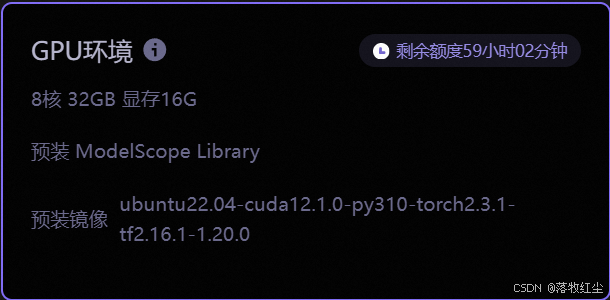
一.环境
1.使用了modelscope的云服务
这是modelscope的官网
魔搭社区汇聚各领域最先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。
这个服务需要绑定阿里云,没注册的还要注册阿里云
2.注册
modelscope社区的账号,后续方便使用。
3启动
进入modelscope社区的首页
1.点击我的Notebook
2.选择阿里云弹性加速计算EAIS
3.选择方式二
4.启动(我这里是启动成功了的,启动成功后点击查看Notebook)

4.创建
点击查看Notebook后选择下面的第一个创建一个Notebook
并将其重命名为如下
更新和安装
将 pip 升级到最新版本
安装或升级 bitsandbytes Python 库,要求版本大于 0.39.0
!pip3 install --upgrade pip
!pip3 install bitsandbytes>=0.39.0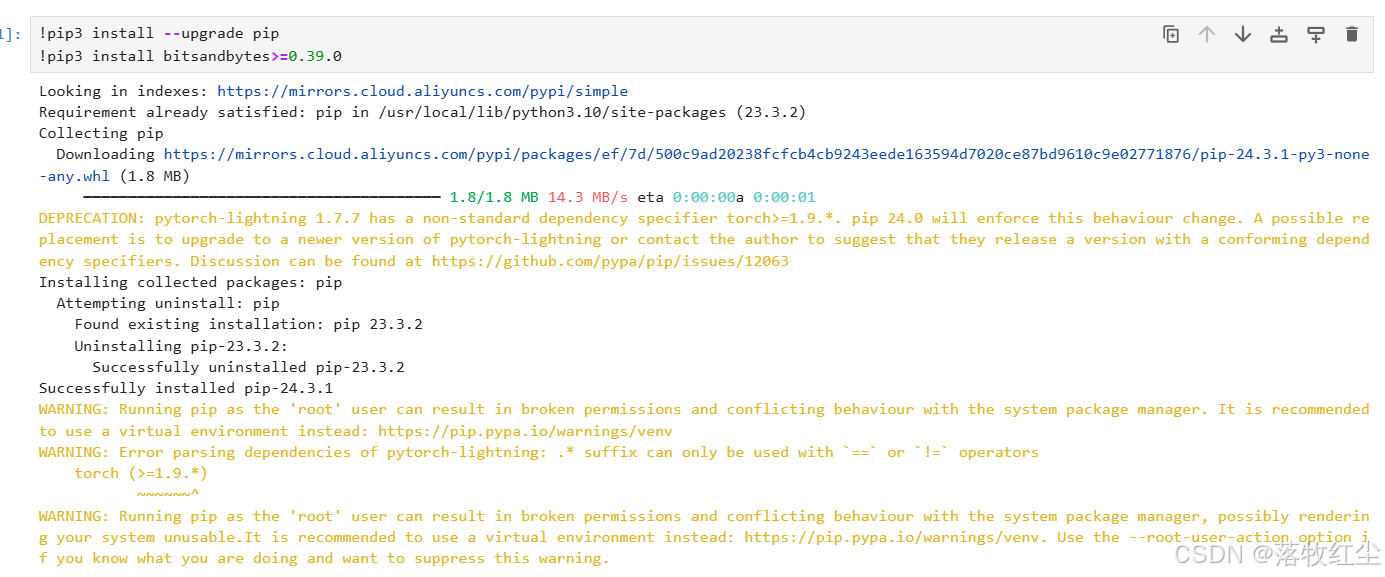
执行完成后左侧资源管理会多一个文件

下载LLaMA-Factory
!git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
执行完成后左侧资源管理会多一个文件
下载qwen2.5模型
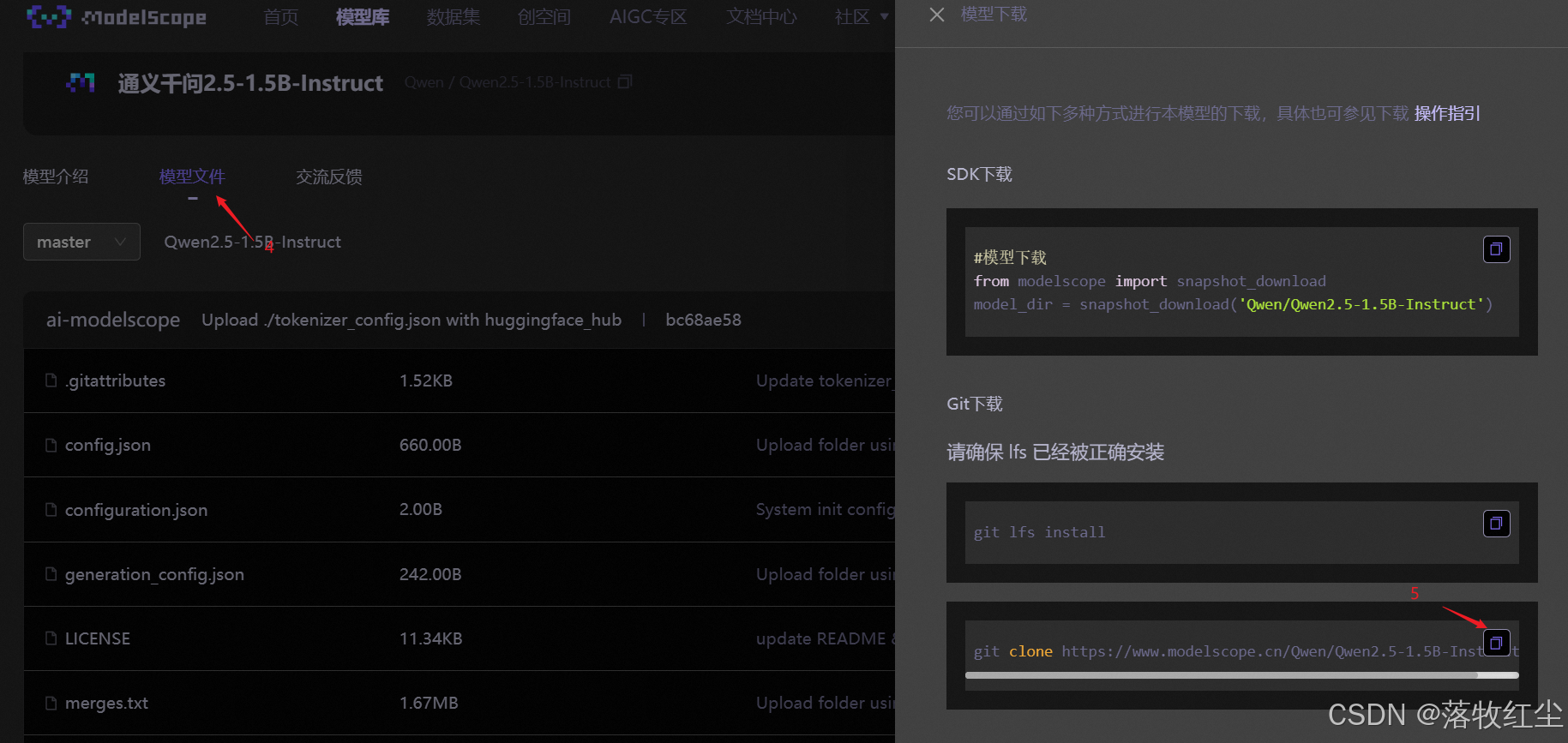
1.在魔搭点击模型
2.在搜索框搜索qwen2.5
3.找到1.5B版本的

4.进入后点击模型文件
5.复制下载地址
注:在notebook中执行要在前面加一个英文的感叹号
!git clone https://www.modelscope.cn/Qwen/Qwen2.5-1.5B-Instruct.git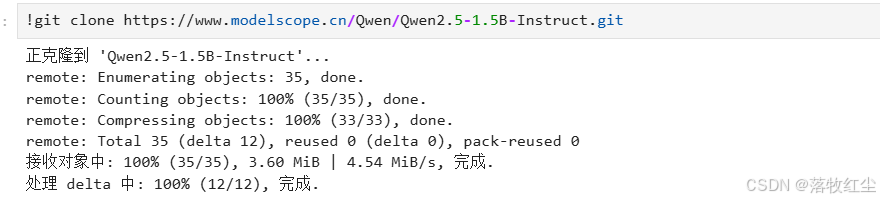
这里模型下载需要时间,我们先去配置以下其他东西
打开一个终端
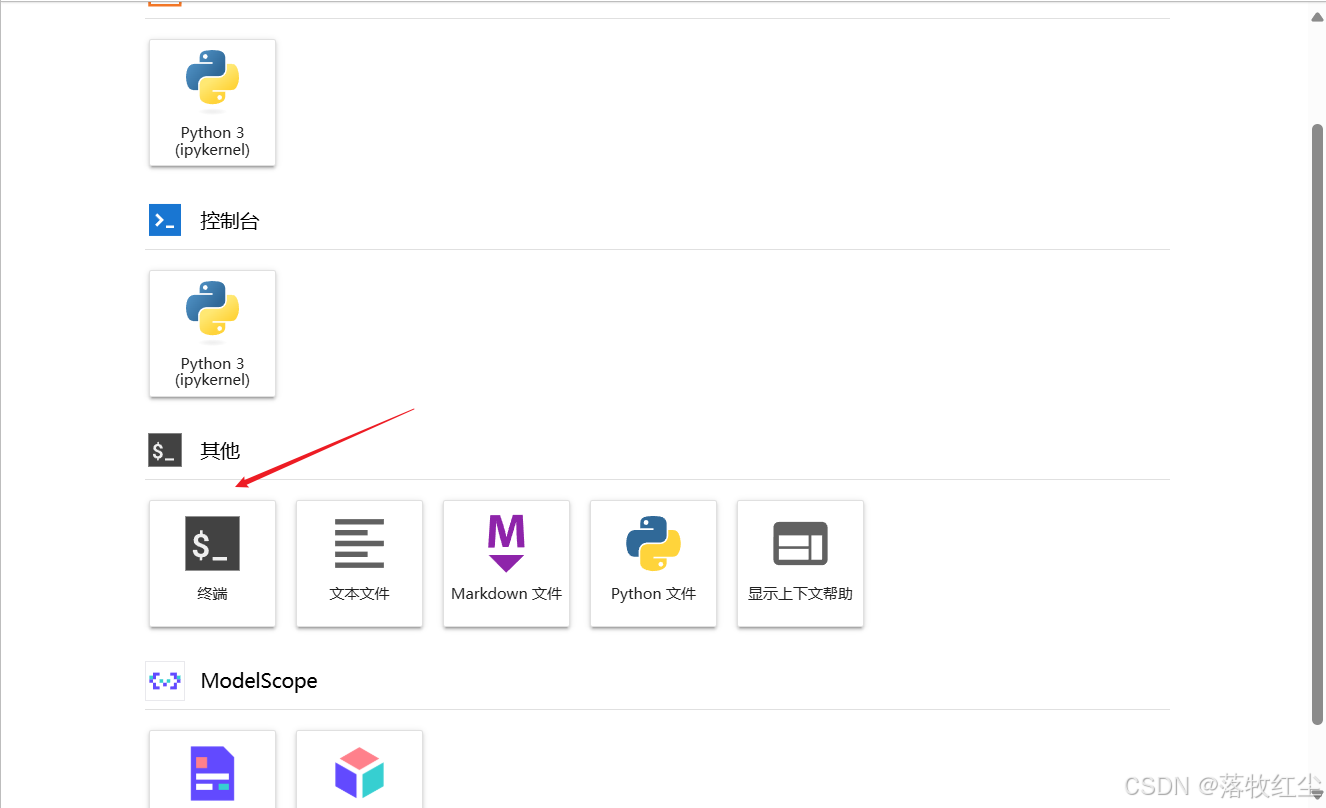
进入LLaMA-Factory目录
cd LLaMA-Factory
然后执行这个命令
pip3 install -e ".[torch,metrics]"
微调设置
进入这个目录LLaMA-Factory/examples/train_qlora/
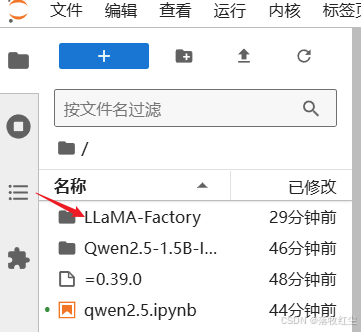
找到这个文件llama3_lora_sft_awq.yaml复制一份重命名为qwen_lora_sft_bitsandbytes.yaml
将其内容修改为以下内容并保存
### model
model_name_or_path: ../Qwen2.5-1.5B-Instruct
quantization_bit: 4
### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset
dataset: identity
template: qwen
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/qwen2.5-1.5b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
添加模板
然后进入这个目录LLaMA-Factory/src/llamafactory/data/
打开template.py
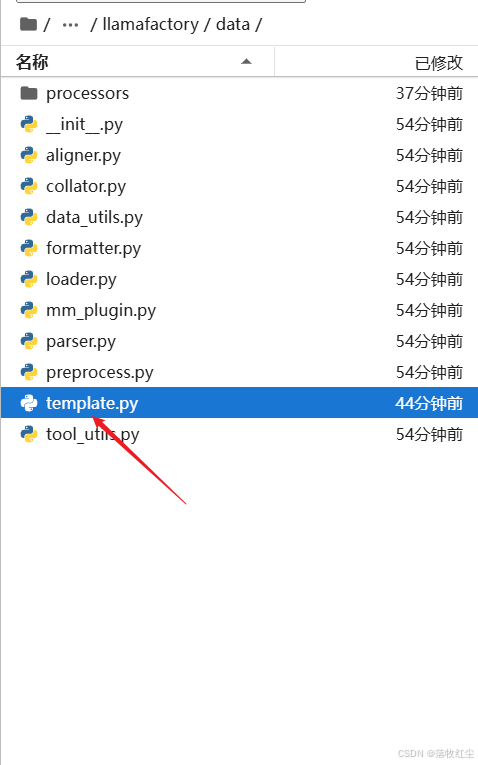
划到408行左右添加一个qwen模板
将下面内容复制粘贴就行
_register_template(
name="qwen",
format_user=StringFormatter(slots=["<|im_start|>user\n{{content}}<|im_end|>\n<|im_start|>assistant\n"]),
format_system=StringFormatter(slots=["<|im_start|>system\n{{content}}<|im_end|>\n"]),
format_observation=StringFormatter(slots=["<|im_start|>tool\n{{content}}<|im_end|>\n<|im_start|>assistant\n"]),
format_separator=EmptyFormatter(slots=["\n"]),
default_system="You are a helpful assistant.",
stop_words=["<|im_end|>"],
replace_eos=True,
)修改训练数据
数据修改数据,我这里的数据是我朋友给我的
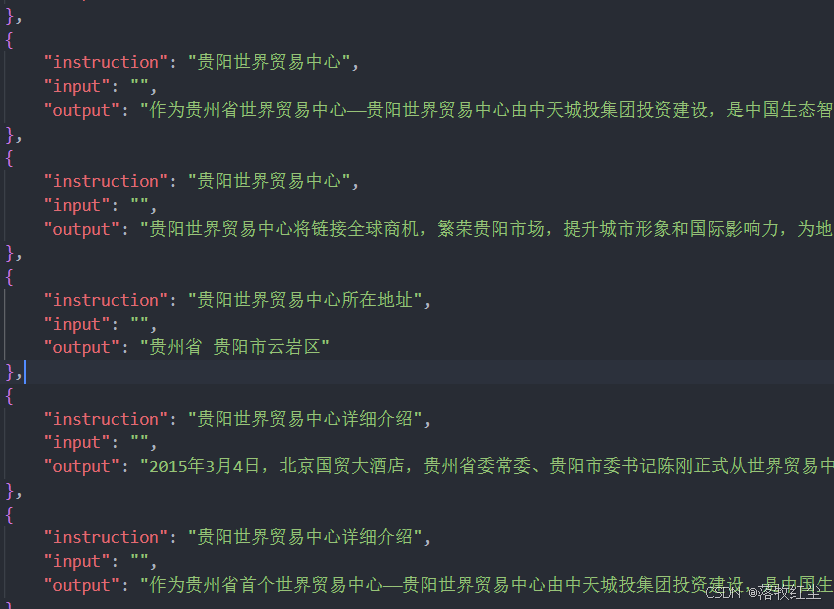
进入目录LLaMA-Factory/data/
找到 identity.json
打开后呈以下模样
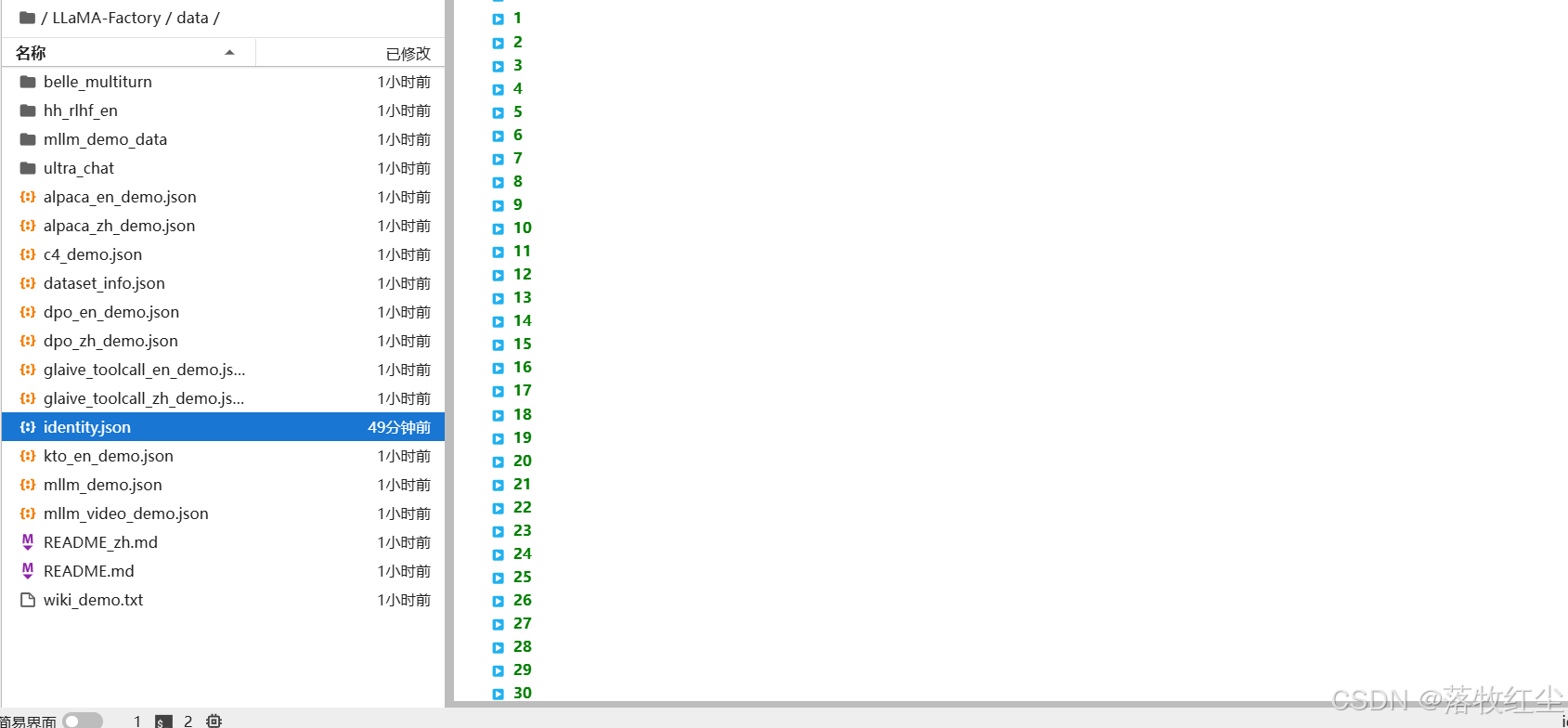
这里不能修改,我们将文件后缀改为md
将准备好的数据全部复制过来
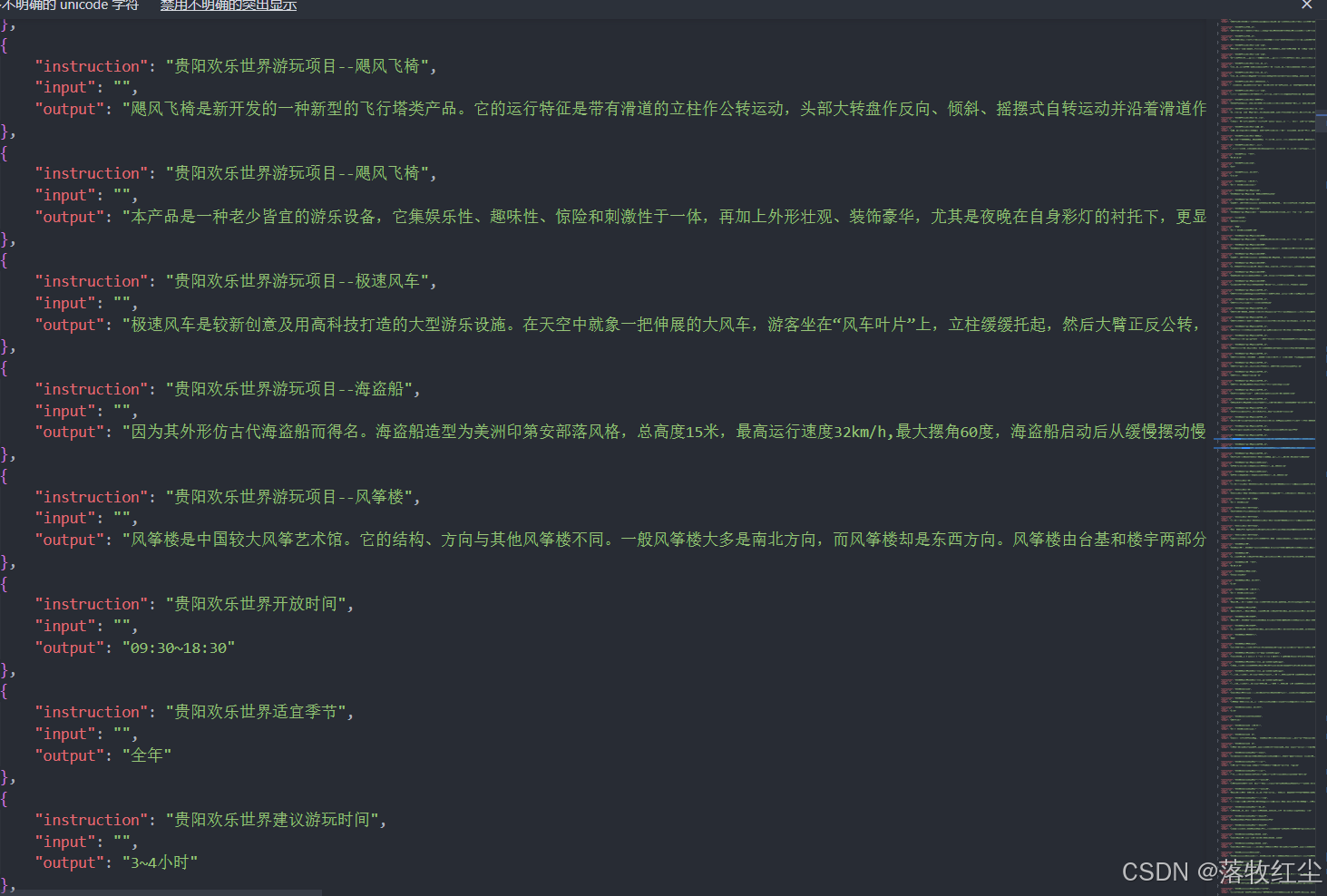

再将后缀改为json

数据的修改就完成了
二.微调
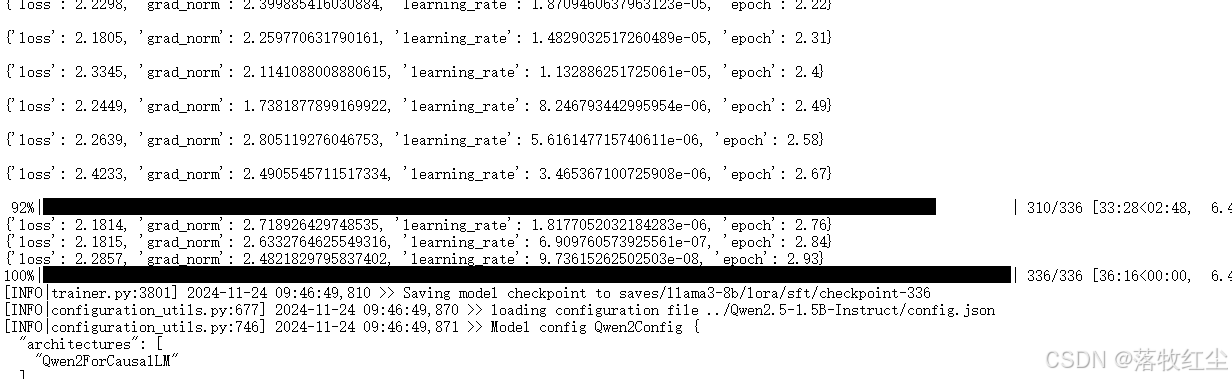
在 LLaMA-Factory 目录下,输入以下命令启动微调脚本
llamafactory-cli train examples/train_qlora/yi_lora_sft_bitsandbytes.yaml
呈现下面这个就是启动成功,这个过程耗时需要耐心等待
三.推理测试
当进度条到达100%后就表示微调成功
下面我们开始测试
首先找到目录
LLaMA-Factory/examples/inference/
将llama3_lora_sft.yaml复制一份重命名为qwen_lora_sft.yaml
将其中内容修改为
model_name_or_path: ../Qwen2.5-1.5B-Instruct
adapter_name_or_path: saves/qwen2.5-1.5b/lora/sft
template: qwen
finetuning_type: lora
保存后在终端执行下面的命令
llamafactory-cli chat examples/inference/qwen_lora_sft.yaml
运行成功后就可以开始对话测试了(可能回答得有点牛头不对马嘴)
