分类问题是人类所面临的一个非常重要且具有普遍意义的问题,我们生活中的很多问题归根到底都是分类问题。
文本分类就是根据文本内容将其分到合适的类别,它是自然语言处理的一个十分重要的问题。文本分类主要应用于信息检索,机器翻译,自动文摘,信息过滤,邮件分类等任务。

文本分类技术发展历史


1960-1970:那时主要通过人工+规则(关键词或者正则表达式)的方式,制定规则的人需要对某类目领域有足够的认知和了解。举个栗子:类目词是厨师,涉及到的规则可能是关于美食的、烹饪技巧的(刀工/炒锅/烘焙)或者厨师工种的(水台/砧板/打荷),需要涉及到方方面面,繁琐复杂。
1970-1990:出现了利用知识工程建立的专家系统,即,信息检索概率模型VSM(如向量空间模型Vector Space Model),以及相关评价指标如准确率、召回率的引入。
1990-2000:研究主要集中在了文本特征(即词语)的提取、选择以及分类器模型的设计方面。
2000年至今:多采用词向量以及深度神经网络来进行文本分类。
有监督分类的主流程

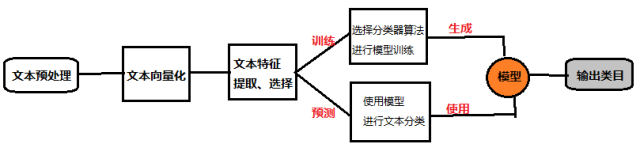
文本预处理:分词,取出停用词,过滤低频词,编码归一化等;
文本向量化:如使用向量空间模型VSM或者概率统计模型对文本进行表示,使计算机能够理解计算,用的方法基于集合论模型、基于代数轮模型、基于频率统计模型等等;
文本特征提取和选择:特征提取对应着特征项的选择和特征权重的计算。是文本分类的核心内容,常用的特征提取方法:
1)用映射或者变换的方法对原始特征降维(word2vec);
2)从原始的特征中挑选出一些最具代表性的特征;
3)根据专家的知识挑选出最具影响力的特征;
4)基于数学的方法选取出最具分类信息的特征。
分类器选择:回归模型,二元独立概率模型,语言模型建模IR模型。
在小编看来,不同的特征提取方法,会有自己的特点,用不同的分类的方法,效果也不一样,不能一概而论(遇到过数据集特征提取后,性能反而下降了,应该是数据集本身比较小的原因)。

分类的算法、文本的特征、所使用的数据集,我认为就像上图的三角关系一样,并不是每一个越长越好,正如可以表征文本的特征有很多,但并不是在构建特征越多,其分类效果越好。
传统的向量空间模型(VSM)假设特征项之间相互独立,这与实际情况是不相符的。本文主要分享基于词向量的文本分类,什么是Word2Vec?如何有效的表征文本的?
Word2Vec
2013年,Google开源了一个用于生成词向量的工具,因其简单实用高效而引起广泛关注。
若有兴趣的读者,可阅读作者的原论文[8]。
Word2Vector本质上有两个学习任务,还有两套模型分别是:
CBOW(Continuous Bag-Of-Words,即连续的词袋模型):对于每个词,用其周围的词,来预测该词生成的概率。
Skip-Gram:对于每个词,用其自身去预测周围其他词生成的概率。
这两套模型,将词语映像到同一坐标系,输出为数值型向量的方法。简而言之,就是将人类才可以看懂的文字,转换为机器也可以识别、操作、处理的数值,将一串文字转化为一个数值型向量的过程。
Word2vec的产生是一个必然的过程,随着人类对非结构化数据(文字、语音、图像等)分析的需求,尤其是大量文本类数据的分析,必然需要一些让计算机“理解”文字的方法,最直接有效的自然就是将文字转化为数字;换言之,将全部的文本映射到数值空间中就是word2vec做的事情。这里需要引入一个概念——语言模型,我们不会在此深入的去探索语言模型,只是简单向读者介绍这个概念。
语言最大的特征就是上下文的联系,比如中文当中,两个特定的字会组成一个词语,若干词语和字组成句子,多个句子组成文章,如果文章中的全部文字都随机的打乱顺序排列,那么我想哪怕正在读文章的你是中文系的高材生,要完全看懂这篇文章也要费九牛二虎之力,请看下面这两段文字:
“自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。”
“与言将学处处方联及数言理语言信理各、语区工计系别这之和论切领所因人使中间究密的它有然的的与涉有自的要一言算语要效现体进的机融,语学究科科的计然行的学、但实又研是然。与重门能,究然常语域们语科是。自通人种日。言用领域机领域一智着机一人有即言用以言于能研方学的学它自重算向。算学自,计法此研个理一,语”
好吧,看到这里你可能要骂人了,第二段是人话么?答案是,第二段话就是第一段话,只是对第一段话随机打乱了顺序,这个不倒150字的段落,也许你用30分钟一个小时可以将它还原成“人话”,如果是长篇大论的呢?这里就看出了语言的逻辑性,词语前后关系的重要性。语言模型就是在做这样的事情,考察一个句子出现的可能性(也就是概率)。如果一个句子S由n个词w1~wn,那么S出现的概率就应该等于P(w1,w2,…,wn),用条件概率的公式即得到共识①如下:
P(S)=P(w1,w2,…,wn)=P(w1)P(w2│w1)…P(wn|w1,w2,…,w(n−1))
不懂这个公式丝毫不影响后面的学习,这个公式翻译成白话就是:词语wn出现的概率依赖于它前面n−1个词。当n很大时,P(wn│w1,w2,…,w(n−1))的计算是非常麻烦甚至无法估算,于是产生了一个叫做马尔科夫假设的概念并由此得到“二元模型”。马尔科夫假设的意思是“任意一个词w_k只与它前面的词即w(k−1)有关”。那么这样,公式①就可以写作下面的公式②的形式:
P(S)=P(w1)P(w2│w1)…P(wn|w(n−1))
语言模型正是为了考察句子,或者说由词a到词b存在在句子中的概率而存在的。如果将我们的语言模型即为f,那么word2vec就是去训练这个f,不关注这个模型是否完美,而是要获取模型产生的参数,对于word2vec,就是神经网络的权重参数,将这些参数作为句子S的替代,由这些参数组成的向量,就是我们所谓的“词向量”。这也就是word2vec的输出。
word2vec从大量文本语料中以无监督的方式学习语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。比如“机器”和“机械”意思很相近,而“机器”和“猴子”的意思相差就很远了,那么由word2vec构建的这个数值空间中,“机器”和“机械”的距离较“机器”和“猴子”的距离而言是要近很多的。
附:Skip-gram 和 CBOW
不要被这两个看起来高大上的词吓到,其实很简单。由word2vec思想,即考察前后文的关联性产生了这两个模型:Skip-gram是通过一个词a去预测它周围的上下文;而CBOW相反,是通过上下文来预测其间的词。CBOW一般用于数据,而Skip-Gram通常用在数据量较大的情况。

图1比较直接的展示了比较常规的CBOW和Skip-gram,图1左侧的CBOW给出了文本中一个词语wt左右各两个词,输出为wt。然后通过单隐藏层的神经网络去输出文本中每个词按照这个输入数据,输出为wt的概率。右侧的Skip-gram相反,用一个输入词wt去预测左右两个词语,同样输出概率值。
前文说过,word2vec输出是神经网络的权重值,用这些值组成词向量,它的输入就是我们文本中的词(将文本按一定颗粒度切分为词语和字),但是输入进计算机的文字依然是无法被计算机识别啊?该怎么进入这个过程呢?答案就是——one hot encoder。one hot encoder就是一个只含有1个1,其他都为0的值构成的向量。如果全世界的词一共有N个,为了简单起见,假设N是3,这3个词分别是“我”、“是”、“帅哥”(别骂我不要脸~~~),那么很显然,“我”就可以被编码为(1,0,0),“是”编码为(0,1,0),“帅哥”编码为(0,0,1)。这样的数值向量是完全可以被计算机识别和处理的。
言归正传,我们先来看一看Skip-gram模型。我们的输入已经明确了,再明确一下我们的输出:Skip-gram是一个单隐藏层的神经网络结构,那么我们要找的词向量其实就是输入层到第一个隐藏层的权重(也就是图1中Project层的权重值)。
这里,引入“窗口”和“skip-num”的概念,举个例子,比如有这么一句话:“中秋月亮比往常圆”,“中秋”、“月亮”、“比”、“往常”、“圆”作为6个独立的词,如果我们的输入是“月亮”,窗口设为2,skip-num也是2,那么我们会得到两组输入-输出:(月亮,中秋)和(月亮,比),假如先使用(月亮,中秋)作为神经网络的输入和输出进行训练,那么神经网络会输出整个文本中每个词作为“月亮”的输出的概率,也就是给定这组输入输出数据时,输入是“月亮”,输出结果是“中秋”的概率,即文本中每个词与输入值“月亮”相邻出现的概率(当然,这个例子没用对文本进行one hot encoder,是为了方便解释和理解,读着可以自行把它们假想为0-1向量,不想也没关系,小编觉得这样看得见摸得着不抽象的例子才能让大家都看懂)。
现在假设我们的Skip-gram是一个最简单的情况,用一个输入词去预测它相邻的一个词,如图2和图3所示(图3是图2的展开、细化模式)。那么请接着看图4,如果我们的词表中有10000个词,那么每个词进行one-hot编码后,就会是一个10000维的向量,其中9999个都是0,只有一个是1。从输入层到隐藏层没有使用激活函数,但在输出层中使用了softmax(不用怕,这个东西很简单,后面会介绍的,目前你只要把它简单理解成为类似逻辑回归中的logstic变换即可)。
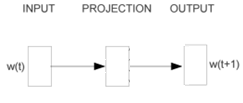
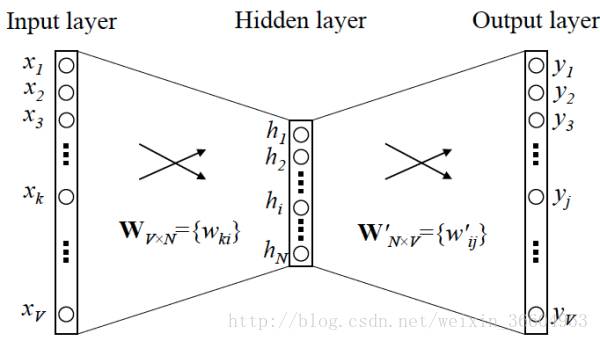
图3
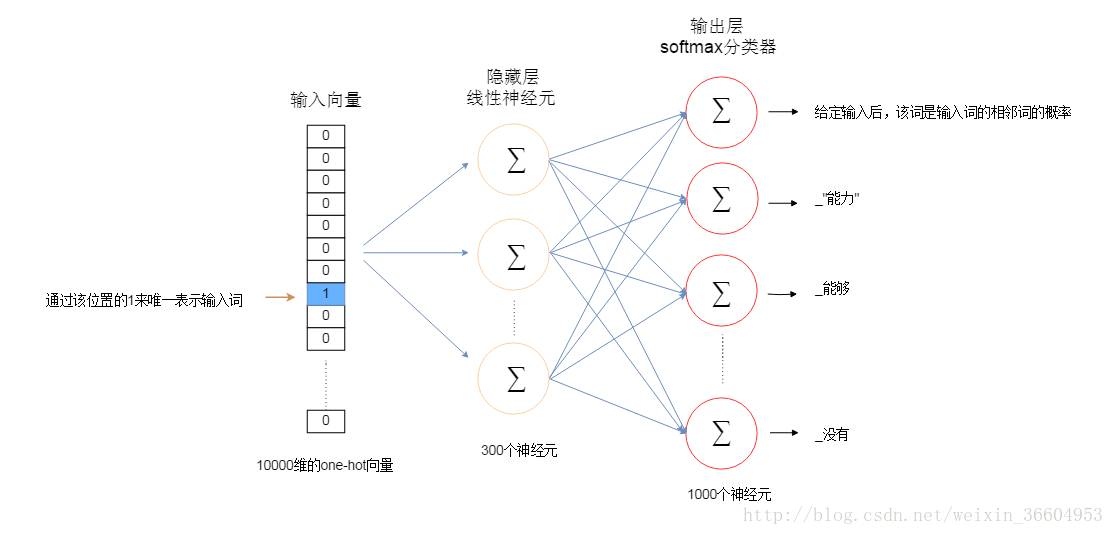 图4
图4
输出层理所当然也是10000维的向量,每个值就是按照输入的这个词,可以得到自己本身的概率,这个10000维的向量其实就是一个概率分布。
我们关注的点在隐藏层,如果我们想用将每个词表示为一个维度为100的向量,即每个词有100个特征,那么隐藏层就是一个10000行×100列的矩阵(也就是隐藏层有100个结点),这个10000×100的矩阵就是我们最后想要的结果,它会将10000个词中的每一个表示为一个100维的向量,有木有发现,10000维的词瞬间被降维到了100维,当然这个权重矩阵中的值就不是0-1了。输入是一个1×10000的向量,隐藏层是一个10000×100的矩阵,这两个矩阵做乘法运算看似需要耗费很多的计算资源,其实并没有,计算机根本没有在运算(也没有在偷懒哈),它只是做了一个“查表”的工作,也就是对权重矩阵做了一个“提取”的动作,只提识别1×10000的向量中那个不为0的值对应的索引,并且从10000×100的矩阵中提取该索引所对应的行。简单展示如下:
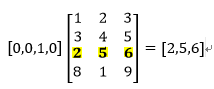
最终得到这个1×100的向量。在输出层通过softmax进行变换,使输出层每个结点将会输出一个0-1之间的值(概率),这些所有输出层结点的概率之和为1。
CBOW是同样的道理(如果按照最简单的情况,Skip-gram用一个输入词预测它后面的词,CBOW用一个输出词去预测它前面的一个词,其实是一模一样的套路)。
一点补充:理论部分的最后一点就是对前文的softmax进行一点简单的说明:softmax函数如下所示,zj是原始向量的某一个值,σ(z)j是它变换后的值,分母就是一个正则项,是对于每个z对应的e的z次幂求和,这样的变换会使得σ(z)j是一个属于(0,1)范围内的实数,也就是word2vec的神经网络输出层所输出的概率值。

总结
文本分类的一般步骤,基本上都是在大量有数据集上做的有监督学习,需要大量人工标注数据(对于有些任务,标注数据获取成本极高)。从上面的分析看出,Word2Vec模型不需要标注数据,其能自发的学习出词与词之间的相似性和某些概念之间的内在联系。
免责声明,如若侵犯到您的原创保护,请联系我们并立即处理。本人才疏学浅,如有不当之处,欢迎高手不吝赐教。
参考资料
https://www.read138.com/archives/732/f13js0re9wu6zyi7/
https://www.cnblogs.com/DjangoBlog/p/7903683.html
Mikolov T, Sutskever I, Chen K, et al.Distributed representations of words and phrases and theircompositionality[C]//Advances in neural information processing systems. 2013:3111-3119.
更多资料
书单下载 | 关于算法、编程、机器学习等书籍,也许正是你所需要的
... ...
当你的才华撑不起你的野心时,只有静下心来好好学习

更多干货内容请关注微信公众号“AI 深入浅出”
长按二维码关注