1.概述
AniTalker是一款先进的AI驱动的动画生成工具,它超越了简单的嘴唇同步技术,能够精准捕捉并再现人物的面部表情、头部动作以及其他非言语的微妙动态。这不仅意味着AniTalker能够生成嘴型精准同步的视频,更重要的是,它还能够呈现自然流畅的表情变化和动作,使得最终的动画效果更加逼真,更具吸引力。
通过AniTalker,动画制作不再局限于专业的动画师或高昂的制作成本。现在,任何拥有一张人物照片和相应的音频文件的用户,都能够轻松制作出高质量的说话动画视频,这极大地拓宽了个人表达和创意创作的边界。无论是用于社交媒体内容的创作,还是教育、培训、娱乐等多个领域,AniTalker都提供了无限的可能性。
项目及演示::https://x-lance.github.io/AniTalker/
论文地址:https://arxiv.org/abs/2405.03121
代码下载:https://github.com/X-LANCE/AniTalker
数字人群:787501969

视频演示:
数字人解决方案——AniTalker声音驱动肖像生成生动多样
2. AniTalker
AniTalker代表了一项技术革新,它打破了传统界限,将静态肖像照片转化为动态的数字化身。以下是对您描述的AniTalker功能的润色和补充:
技术革新:AniTalker通过先进的人工智能技术,使得静态图像能够根据语音指令进行自然流畅的交谈和表情变化。
动态化身:该技术能够将普通的照片转变为具有丰富表情和动作的数字化身,为用户带来前所未有的互动体验。
自监督学习:AniTalker采用了自监督学习这一前沿机器学习策略,使模型能够自主学习并理解人脸动态的复杂性,而无需依赖于繁琐的标注数据。
自然表情:与早期的数字人相比,AniTalker生成的动画不再受限于预设的动作模板,能够展现出更加自然和逼真的面部表情。
灵活性:AniTalker的自监督学习方法赋予了模型强大的泛化能力,使其能够适应各种不同的语音和表情,从而创造出更加多样化和个性化的动画效果。
创新应用:这项技术的应用前景广阔,不仅可以用于娱乐和社交媒体,还可以应用于教育、培训、客户服务等多个领域,为数字内容创作和人机交互提供新的可能性。
易于使用:AniTalker的设计哲学是简化动画制作过程,使其更加易于访问和使用,让没有专业动画制作背景的用户也能够轻松创建高质量的动画视频。
2.1AniTalker 实现的效果
面部动画生成: AniTalker能够将静态人像照片和音频信号转化为生动的说话面部动画。这不仅涵盖了精确的口型同步,还包括与语音内容完美匹配的面部表情和头部动作,为观众提供了一种全新的交流体验。
多样化和可控性: 用户可以根据不同的需求调整输入和参数设置,从而生成一系列表情丰富、动作各异的面部动画。这种高度的定制性使得AniTalker能够满足从娱乐到专业应用的各种需求。
真实感和动态表现: AniTalker擅长捕捉面部的微妙动态,包括眨眼、微笑等复杂非言语信息,这些细节的精确再现极大地增强了动画的真实感和表现力。
长视频生成能力: 该技术不仅限于短片段的生成,还能制作超过3分钟的长篇面部动画视频。这使得AniTalker非常适合用于虚拟助理、数字人物表演以及其他需要长篇动画内容的应用场景。
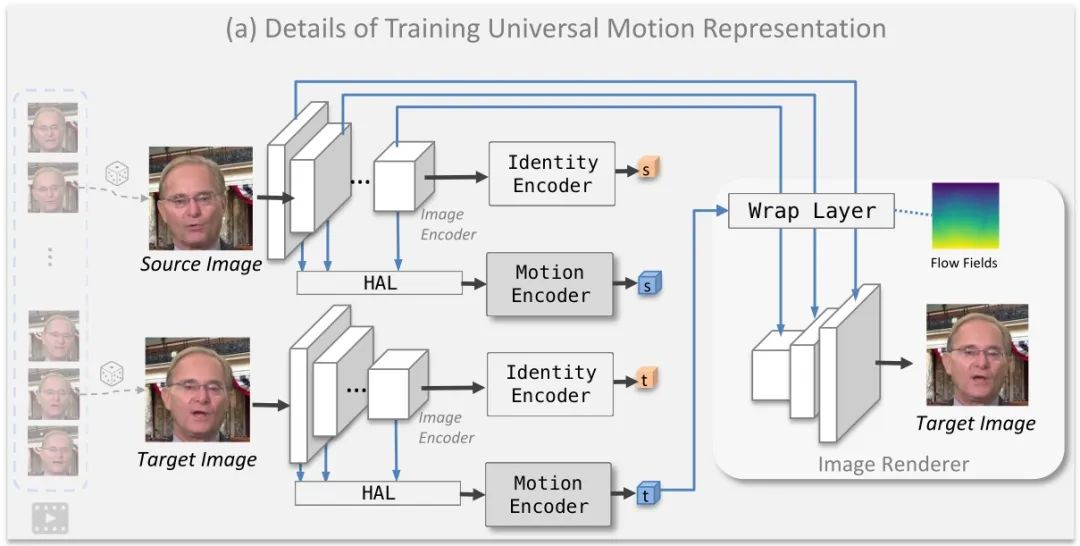
AniTalker 像一位细致入微的观察者,从大量肖像和视频片段中提炼出每个微笑、眨眼、点头的微妙之处,并将其转化为一种精细的“表情运动编码”。
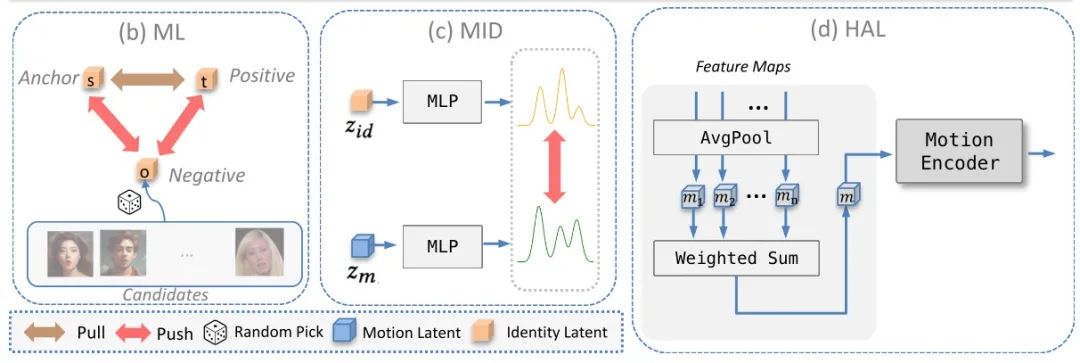
身份和运动编码器的细节,以及层次聚合层(HAL)的工作方式如下图:
更重要的是,AniTalker 精妙地实现了“人物身份”与“动作表现”的分离。它不仅利用“身份识别技术”来区分不同人物的独特性,还通过“身份与动作分离技术”,确保在捕捉动作的同时,不混入任何身份特征,保证了动作的通用性,并维持肖像原貌。
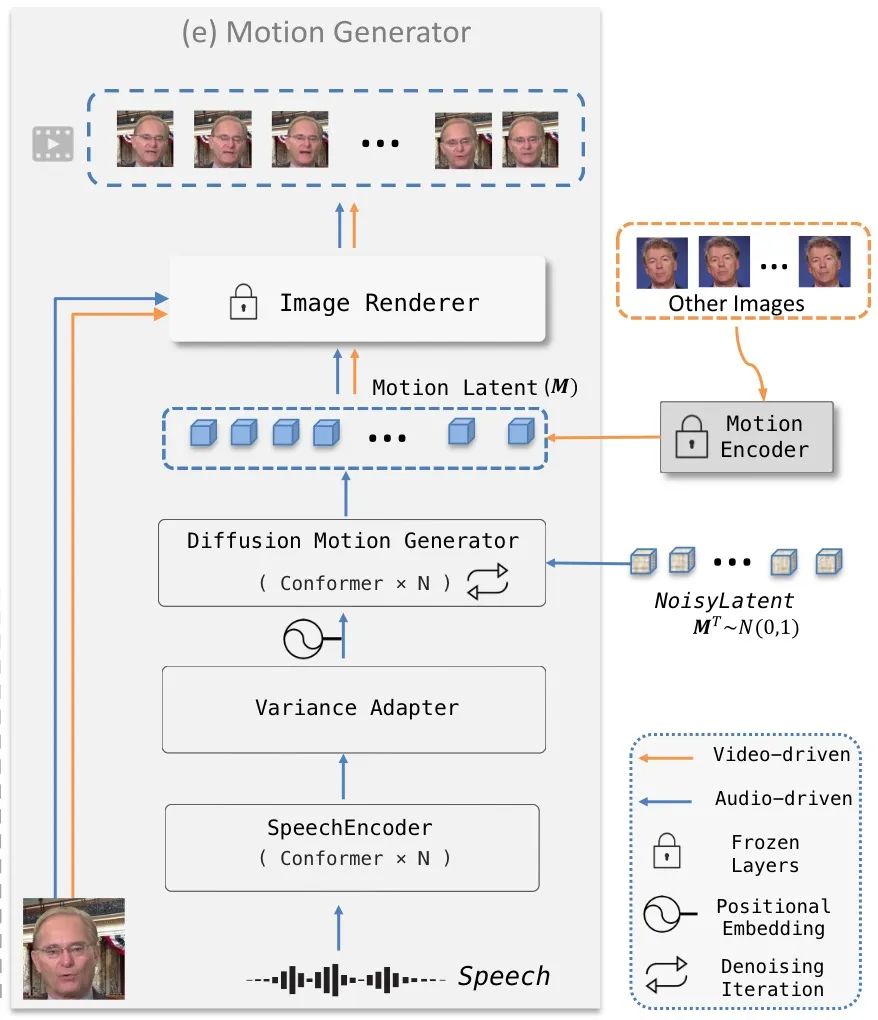
为了使数字人的动作表现更加多样且自然,AniTalker 引进了“动作控制功能”。这项技术巧妙地在基础动作框架上加入微调,让最终的动画效果既自然流畅又富含个性。同时,AniTalker 还能根据指令精细调控数字人的每个动作与表情,如同一位导演精确控制演员的表演。
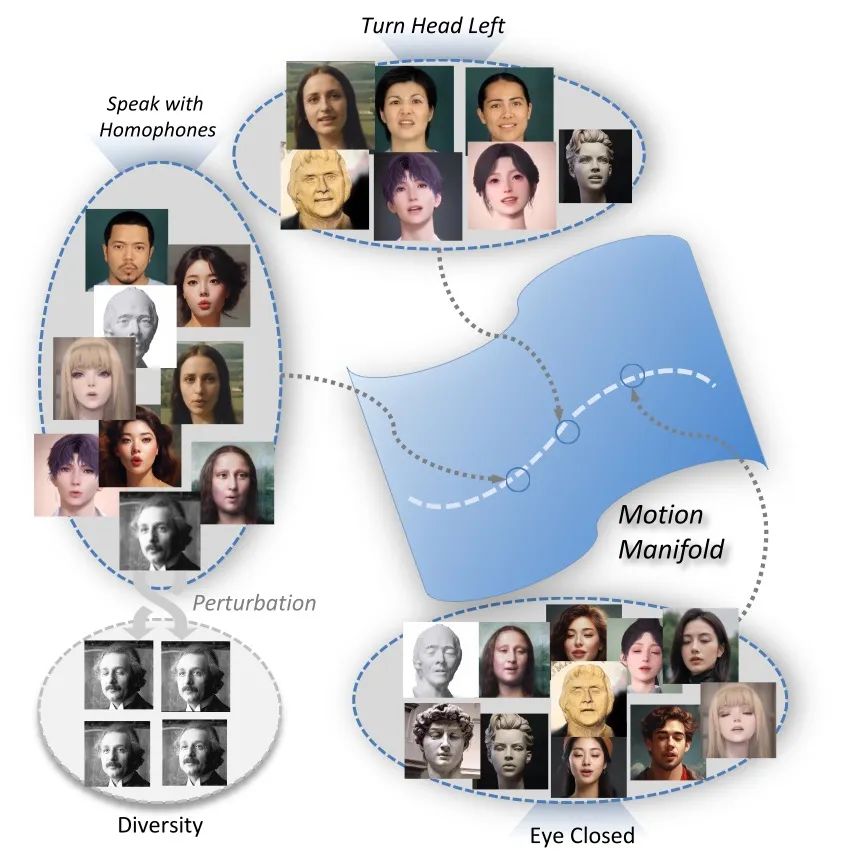
这些丰富的实验成果证实了 AniTalker 的强大效果,所创造出的数字人不仅表情自然、动作连贯,而且适应性强,无论是真实人物还是卡通、雕塑等风格都能完美适应,展示了其卓越的通用性。
连续运动空间的运动流形:

3.项目部署
环境创建:
git clone https://github.com/X-LANCE/AniTalker.git
cd AniTalker
conda create -n anitalker python==3.9.0
conda activate anitalker
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
pip install -r requirements.txt
演示1:
Keep pose_yaw, pose_pitch, pose_roll to zero.
python ./code/demo_audio_generation.py \
--infer_type 'mfcc_pose_only' \
--stage1_checkpoint_path 'ckpts/stage1.ckpt' \
--stage2_checkpoint_path 'ckpts/stage2_pose_only.ckpt' \
--test_image_path 'test_demos/portraits/monalisa.jpg' \
--test_audio_path 'test_demos/audios/english_female.wav' \
--result_path 'results/monalisa_case1/' \
--control_flag True \
--seed 0 \
--pose_yaw 0 \
--pose_pitch 0 \
--pose_roll 0

演示2:
Changing pose_yaw from 0 to 0.25
python ./code/demo.py \
--infer_type 'mfcc_pose_only' \
--stage1_checkpoint_path 'ckpts/stage1.ckpt' \
--stage2_checkpoint_path 'ckpts/stage2_pose_only.ckpt' \
--test_image_path 'test_demos/portraits/monalisa.jpg' \
--test_audio_path 'test_demos/audios/english_female.wav' \
--result_path 'results/monalisa_case2/' \
--control_flag True \
--seed 0 \
--pose_yaw 0.25 \
--pose_pitch 0 \
--pose_roll 0
演示3:
Talking in Free-style

python ./code/demo.py \
--infer_type 'mfcc_pose_only' \
--stage1_checkpoint_path 'ckpts/stage1.ckpt' \
--stage2_checkpoint_path 'ckpts/stage2_pose_only.ckpt' \
--test_image_path 'test_demos/portraits/monalisa.jpg' \
--test_audio_path 'test_demos/audios/english_female.wav' \
--result_path 'results/monalisa_case3/'