概述

提出了一种提高人工智能生成的图像质量的方法 Latent Diffusion模型该方法侧重于视觉突出区域 图像中最有可能引起人们注意的区域。

新研究发现,显著性图(左侧第四列)可用作过滤器或“掩码”,用于将去噪过程中的注意力集中到人类最有可能关注的图像区域
传统方法,优化整个图像而新方法利用显著性检测器来识别和优先处理更“重要”的区域,就像人类一样。在定量和定性测试中,研究人员的方法在图像质量和文本提示的保真度方面都能够胜过以前基于扩散的模型。
自然选择
显著性是指对现实世界和图像中的信息进行优先排序的能力,是一种 重要组成部分 人类视觉。
一个简单的例子是古典艺术更加注重绘画中重要区域的细节,比如肖像画中的脸部,或者海上主题中的船桅杆;在这样的例子中,艺术家的注意力集中在中心主题上,这意味着诸如肖像背景或远处风暴波涛之类的广泛细节比详细细节更粗略,更具广泛代表性。
在人类研究的启发下,过去十年来出现了机器学习方法,可以在任何图片中复制或至少近似人类感兴趣的轨迹。
对象分割(语义分割)可以帮助区分图像的各个方面,并开发相应的显著图

在研究文献中,过去五年中最流行的显着图检测器是 2016 Grad-CAM 计划,后来演变为改进的 Grad-CAM++ 系统以及其他变体和改进。
Grad-CAM 使用 梯度激活 语义标记(例如“狗”或“猫”)来生成概念或注释可能在图像中表示的视觉图。
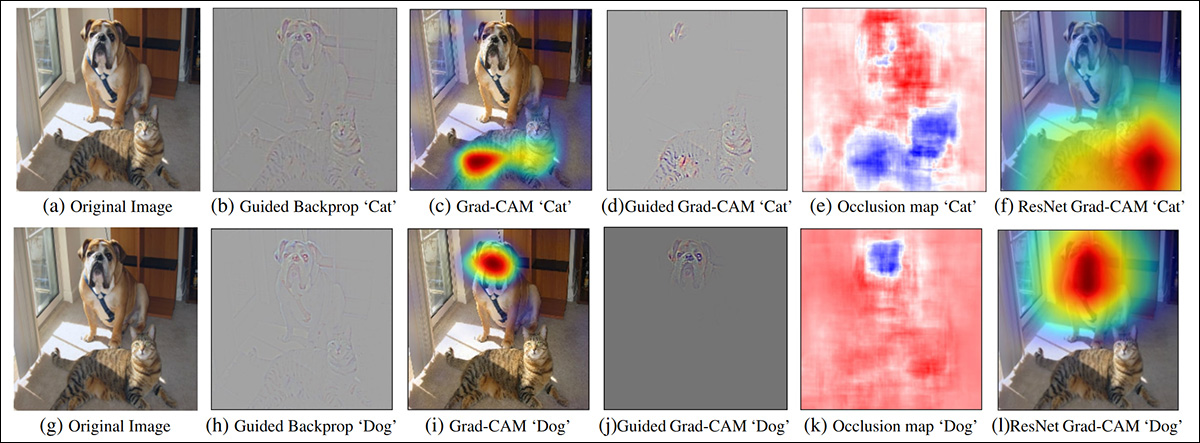
来自原始 Grad-CAM 论文的示例。在第二列中,引导反向传播将所有贡献特征单独化。在第三列中,针对“狗”和“猫”这两个概念绘制了语义图。第四列表示前两个推理的串联。第五列是与推理相对应的遮挡(掩蔽)图;最后,在第六列中,Grad-CAM 可视化了 ResNet-18 层。
对这些方法获得的结果进行的人工调查揭示了图像中关键兴趣点的数学个体化与人类注意力(扫描图像时)之间的对应关系。
这篇新论文探讨了显著性(saliency)能够为诸如稳定扩散(Stable Diffusion)和通量(Flux)等文本到图像(而且可能还包括文本到视频)系统带来什么。
在解读用户的文本提示时,潜在扩散模型(Latent Diffusion Models)会在其经过训练的潜在空间中探寻与所使用的单词或短语相对应的已习得的视觉概念。然后,它们会通过一个去噪过程对这些找到的数据点进行解析,在这个过程中,随机噪声会逐渐演变成对用户文本提示的一种创造性解读。
然而,到目前为止,该模型对图像的每一个部分都给予同等的关注。自 2022 年扩散模型因 OpenAI 推出可用的 Dall - E 图像生成器以及随后 Stability.ai 的稳定扩散(Stable Diffusion)框架开源而得到推广以来,用户发现图像的 “关键” 部分往往得不到充分呈现。
考虑到在对一个人的典型描绘中,人物的面部(对观看者来说至关重要)在整幅图像中所占比例可能不超过 10% 到 35%,这种平均分配关注度的方法既不符合人类的感知特性,也不符合艺术及摄影的发展历程。
当一个人牛仔裤上的纽扣与他的眼睛获得同等的计算权重时,就可以说资源分配并非最优。
因此,作者提出的名为 “基于显著性引导的扩散潜在变量优化(Saliency Guided Optimization of Diffusion Latents,简称 SGOOL)” 的新方法,利用一个显著性映射器来增加对图片中被忽视区域的关注,而将较少的资源分配到那些可能处于观看者注意力边缘的部分。
实现方法
SGOOL 管道包括图像生成、显著性映射和优化,对整体图像和显著性细化图像进行联合处理。

扩散模型的潜在嵌入(latent embeddings)通过微调直接进行优化,从而无需再训练一个特定的模型。斯坦福大学的去噪扩散隐式模型(Denoising Diffusion Implicit Model,简称DDIM)采样方法——稳定扩散(Stable Diffusion)的用户所熟悉的那种方法,经过调整后被用于融入由显著性图(saliency maps)所提供的辅助信息。
该论文指出:
“我们首先使用一个显著性检测器来模拟人类视觉注意力系统,并标记出显著区域。为避免重新训练额外的模型,我们的方法直接对扩散潜在变量进行优化。
“此外,基于显著性引导的扩散潜在变量优化(SGOOL)方法利用了一个可逆的扩散过程,并赋予其恒定内存实现的优点。因此,我们的方法成为一种参数高效且即插即用的微调方法。我们已经通过多项指标和人工评估开展了大量实验。”
由于这种方法需要对去噪过程进行多次迭代,作者采用了扩散潜在变量直接优化(Direct Optimization Of Diffusion Latents,简称DOODL)框架,该框架提供了一个可逆的扩散过程——尽管它仍然会对整个图像施加关注。
为了界定人类感兴趣的区域,研究人员采用了邓迪大学2022年的跨域网络(TransalNet)框架。

经跨域网络(TransalNet)处理过的显著区域随后会被裁剪,以生成最终的显著部分,这些部分很可能是实际人群最感兴趣的内容。
在定义一个能够判定该过程是否有效的损失函数时,必须考虑用户文本与图像之间的差异。为此,研究人员使用了 OpenAI 的对比语言 - 图像预训练(CLIP)的一个版本 —— 目前它已经是图像合成研究领域的中流砥柱,同时还考虑了文本提示与整体(非显著)图像输出之间的估计语义距离。
作者声称:
“最终的损失函数会同时兼顾显著部分与整体图像之间的关系,这有助于在生成过程中平衡局部细节和整体一致性。”
“这种具有显著性感知的损失被用来优化图像潜在变量。梯度是在含噪的潜在变量上进行计算的,并被用于增强输入提示对原始生成图像的显著部分和整体方面的调节作用。”
数据与测试
为了测试基于显著性引导的扩散潜在变量优化(SGOOL)方法,作者使用了稳定扩散 V1.4 的 “原始” 版本(在测试结果中记为 “SD”)以及带有 CLIP 引导的稳定扩散(在测试结果中记为 “基线”)。
该系统针对三个公开数据集进行了评估,这三个数据集分别是:通用句法过程(CSP)数据集、绘图工作台(DrawBench)数据集以及每日 DallE * 数据集。
其中,每日 DallE * 数据集包含了来自 OpenAI 一篇博客文章中所介绍的一位艺术家给出的 99 条精心构思的提示语,绘图工作台数据集提供了涵盖 11 个类别的 200 条提示语,而通用句法过程数据集则由基于 8 种不同语法情况的 52 条提示语组成。
对于 SD、基线以及 SGOOL,在测试过程中,都是使用视觉 Transformer/ B - 32(ViT/B - 32)上的 CLIP 模型来生成图像和文本嵌入。使用了相同的提示语和随机种子,输出尺寸设定为 256×256,并且采用了跨域网络的默认权重和设置。
除了 CLIP 评分指标外,还使用了估计的人类偏好评分(HPS),此外还开展了一项有 100 名参与者的实际研究。

将 SGOOL 与之前的配置进行比较的定量结果。
对于上表所示的定量结果,论文指出:
“[我们的]模型在所有数据集上的表现都明显优于 SD 和 Baseline,无论是在 CLIP 分数还是 HPS 指标上。我们的模型在 CLIP 分数和 HPS 上的平均结果分别比第二名高出 3.05 和 0.0029。”
作者进一步根据以前的方法估计了 HPS 和 CLIP 分数的箱线图:
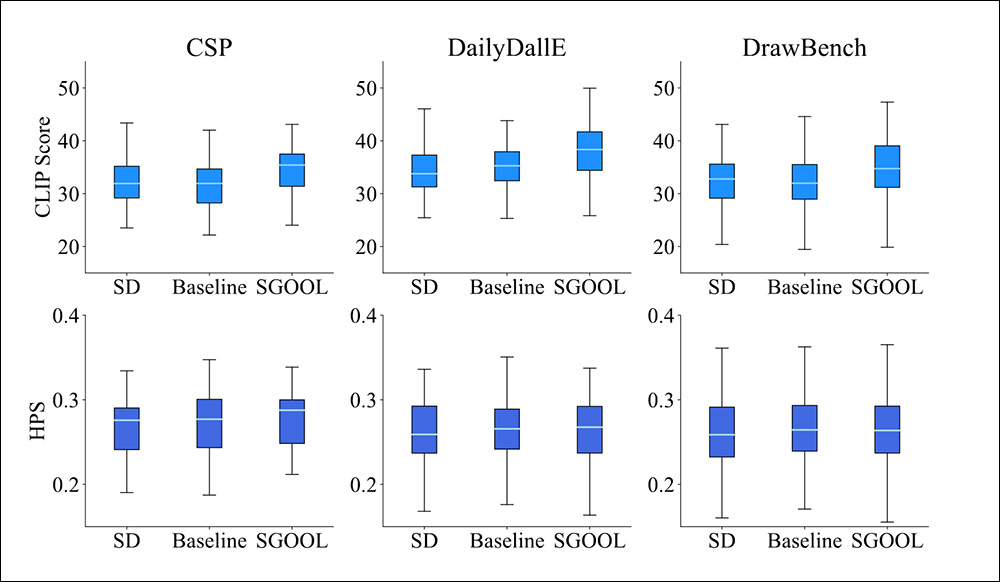
测试中获得的 HPS 和 CLIP 分数的箱线图。
他们评论说:
'可以看出,我们的模型优于其他模型,这表明我们的模型更能够生成与提示一致的图像。
'然而,在箱线图中,由于此评估指标的大小为 [0, 1],因此不容易从箱线图中直观地看到比较。因此,我们继续绘制相应的条形图。
“可以看出,SGOOL 在 CLIP 分数和 HPS 指标下的所有数据集上都优于 SD 和 Baseline。定量结果表明,我们的模型可以生成语义上更加一致且更受人类青睐的图像。”
研究人员指出,虽然基线模型能够提高图像输出的质量,但它没有考虑图像的显著区域。他们认为,SGOOL 在全局和显著图像评估之间达成妥协,从而获得了更好的图像。
在定性(自动)比较中,SGOOL 和 DOODL 的优化次数设置为 50。


测试的定性结果。请参阅源论文以获得更好的定义。
作者在此指出:
'在[第一行]中,提示的主题是“一只唱歌的猫”和“一个理发店四重奏”。 SD 生成的图像中有四只猫,图像内容与提示的匹配度很差。
“Baseline 生成的图像中猫被忽略了,脸部的刻画和图像中的细节都缺乏。DOODL 试图生成与提示一致的图像。
“然而,由于 DOODL 直接优化了全局图像,因此图像中的人是针对猫进行优化的。”
他们进一步指出,相比之下,SGOOL 生成的图像与原始提示更加一致。
在人类感知测试中,100 名志愿者评估测试图像的质量和语义一致性(即它们与源文本提示的一致性)。参与者有无限的时间来做出选择。

人类感知测试的结果。
正如论文所指出的,作者的方法明显比之前的方法更受欢迎。
总结
本文提到的缺点在稳定扩散的本地安装中显现出来后不久,各种定制方法(如 细节之后) 的出现,迫使系统对人类更感兴趣的领域给予更多的关注。
然而,这种方法要求扩散系统首先经历其正常过程,即对图像的每个部分给予同等的关注,而增加的工作则作为额外的阶段完成。
SGOOL 的证据表明,将基本的人类心理学应用于图像部分的优先排序可以大大增强初步推断,而无需后期处理步骤。