目录
1.ORACLE源端信息
| 调研项 | 调研结果 |
| 数据库后台操作系统 | Red Hat Linux |
| 数据库架构 | 单机 |
| 数据库版本 | Oracle 12c |
| 待迁移数据库名 | ywdb |
| 带迁移的模式名 | OT |
| IP/端口信息 | 192.168.64.129/1521 |
| 用户名/密码 | xxxxx |
| 字符集编码 | AL32UTF8 |
| 需要移植的对象 | 表(数据量)、物化视图、触发器、存储过程、函数 |
迁移对象统计:
--迁移对象统计
select a.username "SCHEMA",
(select count(1) from dba_tables b where b.owner = a.username) "TABLE_NUMS",
( SELECT COUNT(1) FROM DBA_INDEXES I WHERE UNIQUENESS = 'UNIQUE' AND OWNER =A.USERNAME OR INDEX_NAME NOT LIKE 'SYS_%' AND OWNER =A.USERNAME) "INDEX_NUMS",
(select count(distinct c.table_name)
from dba_tab_partitions c
where c.table_owner = a.username) "PATI_TABLE_NUMS",
(select count(1)
from dba_tab_cols d
where d.OWNER = a.username
and d.DATA_TYPE like '%LOB%') "LOB_TABLE_NUMS",
(select round(sum(e.bytes) / 1024 / 1024 / 1024,3)
from dba_extents e
where exists (select 1
from dba_lobs f
where f.owner = a.username
and f.segment_name = e.segment_name)) "LOB_BYTES_GB",
(select count(1) from dba_views g where g.OWNER = a.username) "VIEW_NUMS",
(select count(1) from dba_triggers h where h.owner = a.username) "TRIGGER_NUMS",
(select count(DISTINCT I.NAME)
from DBA_SOURCE I
WHERE I.OWNER = A.username
AND I.TYPE = 'FUNCTION') "FUNC_NUMS",
(select COUNT(1)
FROM DBA_SEQUENCES j
WHERE j.sequence_owner = A.username) "SEQUENCE_NUMS",
(select count(1) from dba_synonyms where owner= A.username) "SYNONYM_NUMS",
(select COUNT(1) FROM DBA_MVIEWS K WHERE K.owner = A.username) "MVIEW_NUMS",
(select count(DISTINCT l.NAME)
from DBA_SOURCE L
WHERE L.OWNER = A.username
AND L.TYPE = 'PROCEDURE') "PROCEDURE_NUMS",
(select COUNT(1) FROM DBA_DB_LINKS M WHERE M.owner = A.username) "DBLINK_NUMS",
(select max(n.DATA_LENGTH)
from dba_tab_cols n
where n.OWNER = a.username) "MAX_DATA_LENGTH",
(select SUM(O.DATA_LENGTH)
from dba_tab_cols o
where o.OWNER = a.username
and o.DATA_TYPE not like '%LOB%') "SUM_DATA_LENGTH"
from dba_users a where username in ('MOCHA_DB');

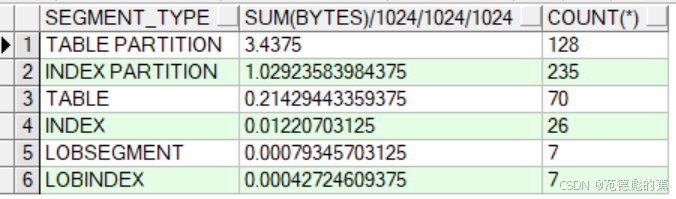
--数据量
select distinct segment_type, sum(BYTES) / 1024 / 1024 / 1024, COUNT(*)
FROM DBA_SEGMENTS
where owner = 'MOCHA_DB'
group by segment_type
order by 2 desc;
--字符集编码
SELECT value FROM NLS_Database_Parameters WHERE PARAMETER='NLS_NCHAR_CHARACTERSET';
select userenv('language') from dual;
--是否以字节为单位
show parameter NLS_LENGTH_SEMANTICS
--归档保留策略
select * from v$archived_log;
--定时作业
select * from user_jobs;
--权限查询语句
--查看用户系统权限
select PRIVILEGE from dba_sys_privs WHERE GRANTEE='MOCHA_DB';
--查看用户对象权限
select * from dba_tab_privs WHERE GRANTEE='MOCHA_DB';
--查看用户角色权限
select GRANTED_ROLE from dba_role_privs where grantee='MOCHA_DB';
--表空间相关信息查询语句
--查询每个表空间的数据文件路径、实际使用大小,上限等及所属用户
select ee.username,dd.* from (select aa.*, bb.file_name, cc.NEXT_EXTENT
from (select tbs_used_info.tablespace_name,
tbs_used_info.alloc_mb,
tbs_used_info.used_mb,
tbs_used_info.max_mb,
tbs_used_info.free_of_max_mb,
tbs_used_info.used_of_max || '%' used_of_max_pct
from (select a.tablespace_name,
round(a.bytes_alloc / 1024 / 1024) alloc_mb,
round((a.bytes_alloc - nvl(b.bytes_free, 0)) / 1024 / 1024) used_mb,
round((a.bytes_alloc - nvl(b.bytes_free, 0)) * 100 /
a.maxbytes) used_of_max,
round((a.maxbytes - a.bytes_alloc +
nvl(b.bytes_free, 0)) / 1048576) free_of_max_mb,
round(a.maxbytes / 1048576) max_mb
from (select f.tablespace_name,
sum(f.bytes) bytes_alloc,
sum(decode(f.autoextensible,
'YES',
f.maxbytes,
'NO',
f.bytes)) maxbytes
from dba_data_files f
group by tablespace_name) a,
(select f.tablespace_name, sum(f.bytes) bytes_free
from dba_free_space f
group by tablespace_name) b
where a.tablespace_name = b.tablespace_name(+)) tbs_used_info
order by tbs_used_info.used_of_max desc) aa,
dba_data_files bb,
dba_tablespaces cc
where aa.tablespace_name = bb.tablespace_name
and aa.tablespace_name = cc.tablespace_name) dd
right join dba_users ee on dd.tablespace_name=ee.default_tablespace
where ee.username in ('MOCHA_DB');
--查询每个用户对象所占的表空间大小
select *
from (select owner, tablespace_name, sum(b) GB
from (select owner,
t.segment_name,t.partition_name,round(bytes / 1024 / 1024/1024 , 2) b,tablespace_name
from dba_segments t)
where owner in ('MOCHA_DB')
group by owner,tablespace_name);
2.DM目的端信息
| 调研项 | 调研命令 |
| 服务器品牌/型号 | dmidecode |
| 服务器操作系统 | cat /etc/os-release |
| 内存容量 | cat /proc/meminfo |
| CPU 型号/核数 | cat /proc/cpuinfo |
| 端口策略 | 是否与目的端网络、端口互通 |
| 安全策略 | 是否有软件、硬件相关安全限制(比如堡垒机、网闸、文件摆渡) |
| 是否具备可视化界面 | 可视化提供的方式(直连、Xmanager、VNC、BMC 等) |
| 是否安装 ODBC | odbcinst -j |
3.DTS 迁移评估

选择评估模块。右键新建评估

连接到源端数据库后,可以选择不同的评估项目,点击下一步

选择需要评估的模式,点击下一步
选择评估的具体数据对象,点击下一步
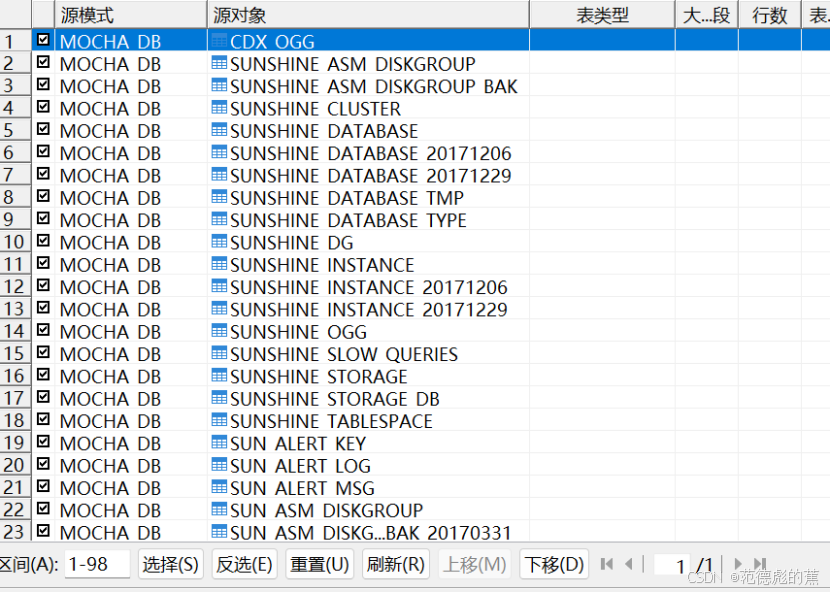
迁移评估对象详情总览,点击完成
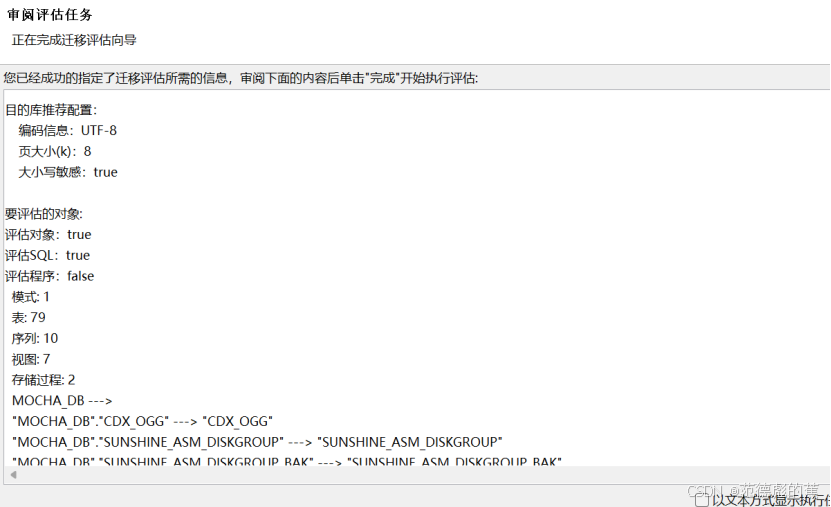
等待评估结束,查看评估结果
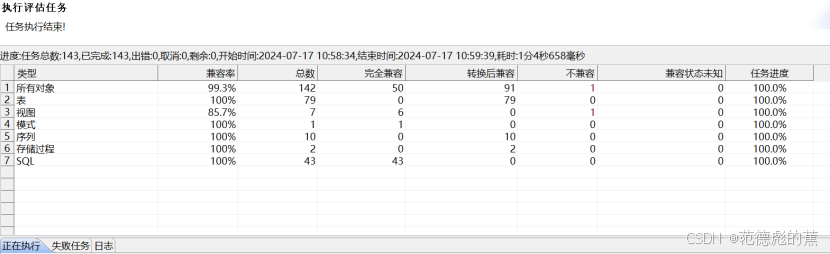
点击【查看评估报告】,可以查看评估概述、数据库信息、对象兼容详细、SQL 兼容详情,并且根据需要选择对应的导出报告类型

对于不兼容情况,可以点击“不兼容”,查看详情

4.数据库迁移
4.1 Oracle 源端数据库准备
正式开始移植前需要停止所有对源端数据库的操作
4.2 目的端达梦数据库准备
初始化参数设置
初始化参数建议配置如下:
| 数据库参数 | 参数值 |
| DB_NAME(数据库名) | DAMENG(根据需求设置) |
| INSTANCE_NAME(实例名) | DMSERVER(根据需求设置) |
| PORT_NUM(端口) | 5236(正式移植环境下,为保证数据库安全,不建议使用默认端口 5236) |
| 管理员、审计员、安全员密码(安全版本特有) | 不推荐使用默认密码 |
| EXTENT_SIZE(簇大小) | 32 |
| PAGE_SIZE(页大小) | 32 |
| LOG_SIZE (日志大小) | 2048M |
| CHARSET(字符集) | GB18030(根据实际要求设置) |
| CASE_SENSITIVE(大小写敏感) | 敏感(根据实际要求设置) |
| BLANK_PAD_MODE(尾部空格填充) | 否 |
部分参数说明:
(1)EXTENT_SIZE:簇大小默认为 16 页,建议设置成 32 页。
(2)CASE_SENSITIVE:默认是大小写敏感,源端为 Oracle 情况下,建议保持默认大小写敏感即可。
(3)BLANK_PAD_MODE:空格填充参数,是否要兼容 Oracle 进行设置,即在 BLANK_PAD_MODE = 0 的情况下,’A’ 和 ’A ’ 被认为是相同的值,参数为 1 的情况下,认为是两个不同的值,根据现场具体应用的需求进行设置。此为初始化参数,只能在初始化时候指定,后续不可以修改,需要提前做好评估,但是源端为 Oracle 数据库的时候,建议设置为 1。
(4)CHARSET:字符集编码,可选 GB18030、UTF-8,默认为 GB18030,如果只存储中文和字母数字,使用 GB18030 更节省空间。
(5)PAGE_SIZE:页大小默认为 8K,建议设置成 32K,一条记录的长度,受到页大小的限制,不可以超过页大小的一半,所以建议一开始规划页大小为 32K。
兼容性参数设置
| 参数名 | 含义 | 建议值 |
| COMPATIBLE_MODE | 是否兼容其他数据库模式。0:不兼容,1:兼容 SQL92 标准 2:兼容 ORACLE 3:兼容 MS SQL SERVER 4:兼容 MYSQL 5:兼容 DM6 6:兼容 TERADATA。 | 推荐值:2,重启数据库生效。 |
表空间规划
参照源库表空间使用情况即可,目的端则需要创建单独的业务表空间(包括数据表空间以及索引表空间)。
需要根据源端表空间使用情况进行规划目的端数据文件初始大小,避免在迁移过程中频繁自动扩展。
用户规划
参照源库用户进行创建,对于权限设置、资源限制要求等内容需要按照目的端达梦实际上线要求进行设置。
创建用户授予权限,不建议授予 DBA 角色,一般的权限,授予 resource、public、vti、soi、svi 这几个角色即可满足使用要求。
| 角色 | 权限 |
| DBA | DM 数据库系统中对象与数据操作的最高权限集合,拥有构建数据库的全部特权,只有 DBA 才可以创建数据库结构。 |
| RESOURCE | 可以创建数据库对象,对有权限的数据库对象进行数据操纵,不可以创建数据库结构。 |
| PUBLIC | 不可以创建数据库对象,只能对有权限的数据库对象进行数据操纵。 |
| VTI | 具有系统动态视图的查询权限,VTI 默认授权给 DBA 且可转授。 |
| SOI | 具有系统表的查询权限。 |
| SVI | 具有基础 v 视图的查询权限。 |
设置用户的资源限制参数
| 资源设置项 | 说明 | 最大值 | 最小值 | 缺省值 |
| CONNECT_IDLE_TIME | 会话最大空闲时间(单位:1 分钟)。 | 1440(1 天) | 1 | 无限制 |
| FAILED_LOGIN_ATTEMPS | 将引起一个账户被锁定的连续注册失败的次数。 | 100 | 1 | 3 |
| PASSWORD_LIFE_TIME | 一个口令在其终止前可以使用的天数。 | 365 | 1 | 无限制 |
| PASSWORD_REUSE_TIME | 一个口令在可以重新使用前必须经过的天数。 | 365 | 1 | 无限制 |
| PASSWORD_REUSE_MAX | 一个口令在可以重新使用前必须改变的次数。 | 32768 | 1 | 无限制 |
| PASSWORD_LOCK_TIME | 如果超过 FAILED_LOGIN_ATTEMPS 设置值,一个账户将被锁定的分钟数以天为单位的口令过期宽限时间,过期口令超过该期限后,禁止执行除修改口令以外的其他操作。 | 1440(1 天) | 1 | 1 |
| PASSWORD_GRACE_TIME | 以天为单位的口令过期宽限时间,过期口令超过该期限后,禁止执行除修改口令以外的其他操作。 | 30 | 1 | 10 |
设置用户口令策略
0:无策略。
1:禁止与用户名相同。
2:口令长度不小于 9。
4:至少包含一个大写字母(A-Z)。
8:至少包含一个数字(0-9)。
16:至少包含一个标点符号(英文输入法状态下,除“和空格外的所有符号)口令策略可单独应用,也可组合应用。组合应用时,如需要应用策略 2 和 4,则设置口令策略为 2+4=6 即可。
默认PWD_POLICY=2,该参数不可以在 dm.ini 中直接修改,需要用 SP_SET_PARA_VALUE 系统过程来修改,如 SP_SET_PARA_VALUE(1, 'PWD_POLICY',8)。
创建迁移用户和表空间
要先创建好待使用的用户和这个用户的表空间
- DM中创建表空间
create tablespace MOCHA_TBS datafile '/dm/data/DAMENG/mocha_tbs01.dbf' size 5120 autoextend on next 128 maxsize 10240;
- 创建用户并授予权限
create user mocha_db identified by "mocha_db123" default tablespace mocha_tbs;
grant public,resource,soi,svi,vti to mocha_db;
4.3迁移步骤
创建迁移

配置数据源

配置迁移对象及策略
迁移对象方式及迁移策略中勾选“保持对象名大小写”
当勾选了“使用默认数据类型映射关系”后在迁移时 DTS 会将源端 Oracle 数据库中相应的数据类型采用默认的映射关系映射到目的端 DM 数据库中。如果在这里勾选了“使用默认数据类型映射关系”,后面又自定义了数据类型映射关系,DTS 会优先选择使用自定义的数据映射关系。

勾选源端待迁移的模式
通过是否勾选“创建模式”、“表”、“视图”、“存储过程/函数”、“触发器”来指定目的端 DM 是否要迁入源端 Oracle 中的这些对象
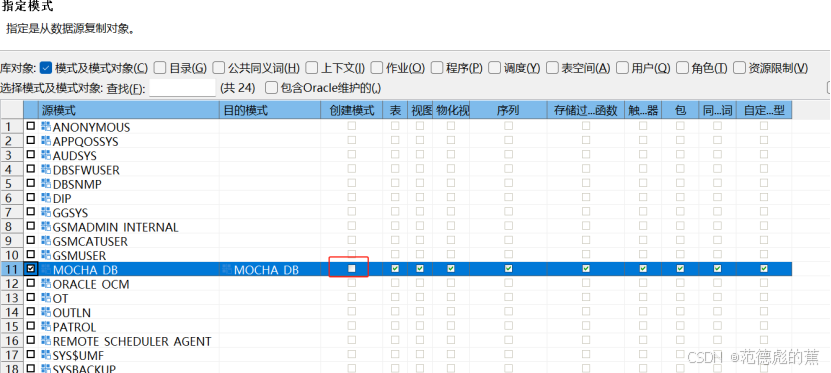
勾选源端数据库中需要迁移的模式下的数据对象
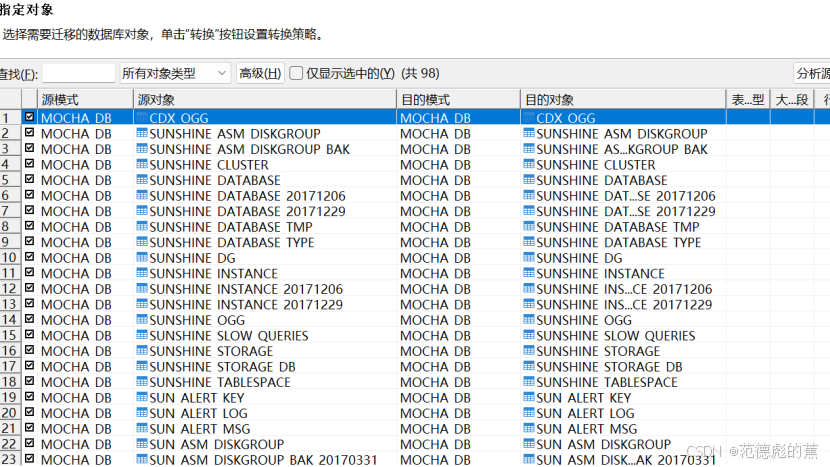
在 SQL 评估阶段不兼容的对象不需要勾选,待其它对象迁移完成后,再手动修改和导入这些不兼容的对象。
自定义对象迁移策略
点击转换后可以设置表的映射关系,包括迁移策略和列映射选项。
- 迁移策略
一般先迁移表,再迁移主键、索引和约束
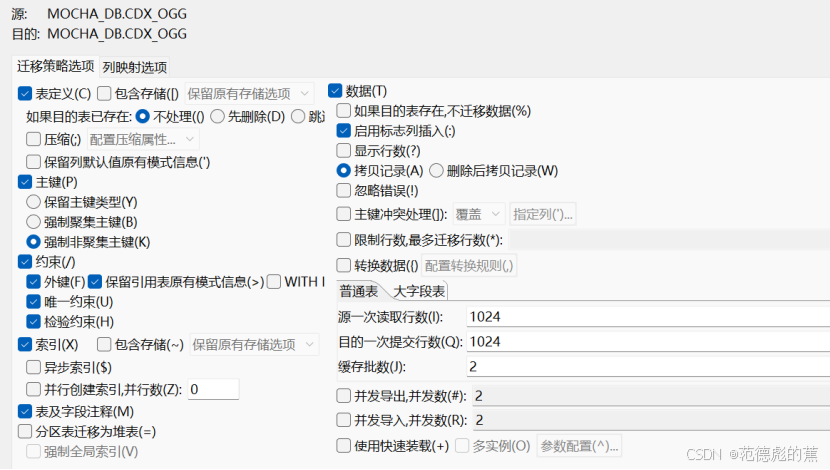
部分选项说明:
a. 压缩:指定迁移的目的表是否按照压缩方式存储。
b. 强制聚集索引:即使源表的主键为非聚集主键,创建目的表时也会被转换为聚集主键。
c. 强制非聚集索引:即使源表的主键为聚集主键,创建目的表时也会被转换为非聚集主键。
d. 启用标志列插入:如果表上有标志列,则迁移数据时会强制向标志列插入值,以保证源和目的数据完全一致
e. 显示行数:将在迁移任务过程中,显示数据的行数。
f. 拷贝记录:如果目的表已存在,直接拷贝记录,不需要创建表。
g. 删除后拷贝记录:迁移过程中先删除已存在的目的表,再重新创建新目的表。
h. 源一次读取行数:设置从数据源中读取数据时每次读取数据的行数,该参数决定内存中缓存结果集的大小,对于数据量很大的数据源,设置该参数,可以控制内存的使用。
i. 目的一次提交行数:设置向目的数据库中每次写入数据的行数。当数据量比较大时,减小该参数的值可以减少内存的使用。但会影响迁移的速度。
j. 缓存批数:设置缓存队列的长度。调整该参数可以调整迁移过程中内存的使用。
(2)列映射选项

可根据需求修改源端迁移到目的端表的列名、数据类型、精度、小数位数、默认值、是否可空、主键、自增列、起始值、增量信息等。
开始迁移
检查迁移任务,确认迁移对象是否正确。
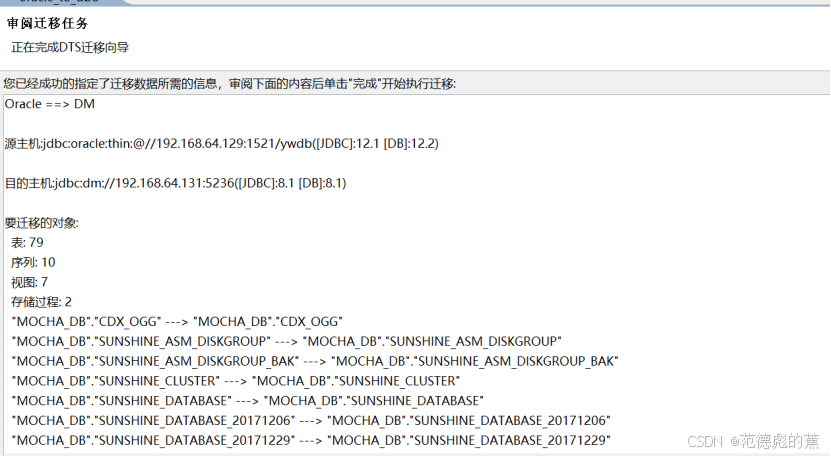
检查确认后点击“完成”即可开始迁移。
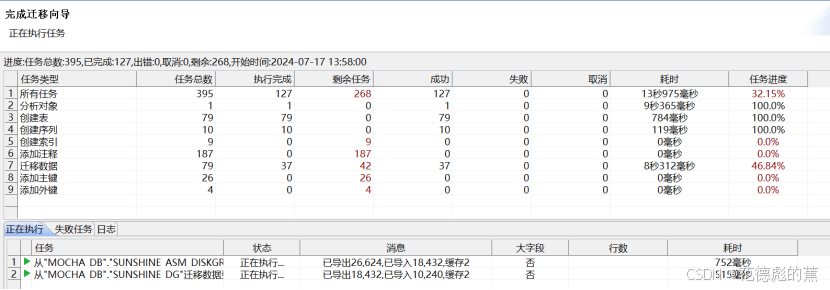
对象补迁
由于 Oracle 和 DM 数据库在某些语法使用上存在差异,导致某些对象可能会迁移失败,用户需要根据 DM 语法手动修改这些无法使用工具迁移的对象再导入到 DM 数据库中。
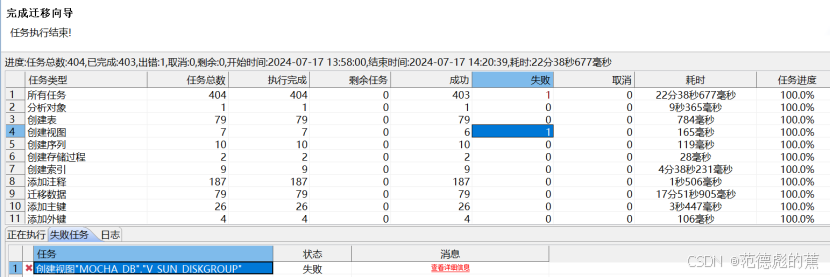
以上示例中,出现视图失败的情况,经查询是由于视图的查询字段中“percent”,是达梦中的关键字,在Oracle中不会出现报错,解决办法是把percent大写,双引号引起来,拿到达梦数据库中执行。
5.数据校验
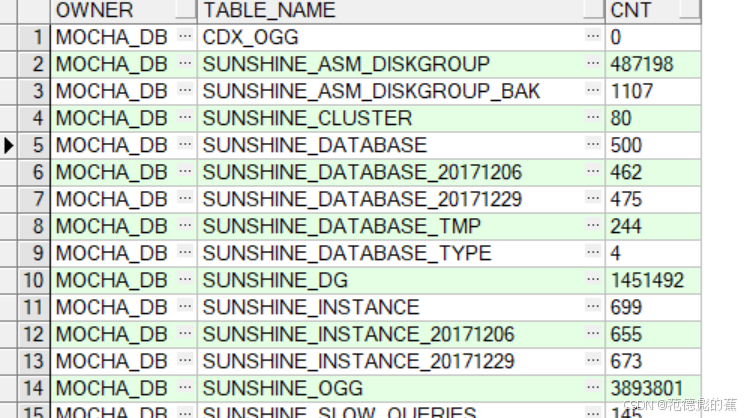
统计源端对象及数据
1.统计各个表的数据量
(1)在源端创建辅助表 table_count 用来统计模式下所有表的数据量。
create table table_count (owner varchar(100),table_name varchar(100),cnt int);
(2)在源端执行脚本,将模式下表的数据量插入到辅助表 table_count 中
declare
v_owner VARCHAR2(100);
v_tabname VARCHAR2(100);
stmt VARCHAR2(200);
num_rows number;
begin
for rec in (select owner,table_name from dba_tables where owner='MOCHA_DB' order by 1, 2)---owner根据实际情况调整
loop
select rec.owner,rec.table_name into v_owner,v_tabname from dual;
stmt := 'select count(*) from "' || v_owner || '"."' || v_tabname || '"';
EXECUTE IMMEDIATE stmt INTO num_rows;
EXECUTE IMMEDIATE 'insert into table_count values('''||v_owner||''','''||v_tabname||''','''||to_number(num_rows)||''')';
end loop;
end;
SELECT * FROM TABLE_COUNT;
统计各种对象的数量
Oracle端执行:
SELECT
A.USERNAME "SCHEMA",
(SELECT COUNT(1) FROM DBA_TABLES B WHERE B.OWNER = A.USERNAME) "TABLE_NUMS",
( SELECT COUNT(1) FROM DBA_VIEWS G WHERE G.OWNER = A.USERNAME ) "VIEW_NUMS",
(SELECT COUNT(1) FROM DBA_MVIEWS K WHERE K.OWNER = A.USERNAME) MVIEW_NUMS,
( SELECT COUNT(1) FROM DBA_TRIGGERS H WHERE H.OWNER = A.USERNAME ) "TRIGGER_NUMS",
( SELECT COUNT(DISTINCT I.NAME) FROM DBA_SOURCE I WHERE I.OWNER = A.USERNAME AND I.TYPE = 'FUNCTION' ) "FUNC_NUMS",
( SELECT COUNT(1) FROM DBA_SEQUENCES J WHERE J.SEQUENCE_OWNER = A.USERNAME ) "SEQUENCE_NUMS",
( SELECT COUNT(DISTINCT L.NAME) FROM DBA_SOURCE L WHERE L.OWNER = A.USERNAME AND L.TYPE = 'PROCEDURE' ) "PROCESURE_NUMS",
( SELECT COUNT(1) FROM DBA_DB_LINKS M WHERE M.OWNER = A.USERNAME ) "DBLINK_NUMS",
--( SELECT COUNT(1) FROM DBA_INDEXES I WHERE UNIQUENESS = 'UNIQUE' AND OWNER =A.USERNAME OR INDEX_NAME NOT LIKE 'SYS_%' AND OWNER =A.USERNAME) "INDEX_NUMS",
( SELECT COUNT(1) FROM DBA_INDEXES I WHERE INDEX_TYPE <> 'LOB' AND OWNER = A.USERNAME) "INDEX_NUMS",
( SELECT COUNT(1) FROM DBA_OBJECTS WHERE OBJECT_TYPE='TYPE' AND OWNER =A.USERNAME ) "TYPE_NUMS",
( SELECT COUNT(1) FROM DBA_OBJECTS WHERE OBJECT_TYPE='PACKAGE' AND OWNER =A.USERNAME) "PKG_NUMS" FROM
DBA_USERS A WHERE A.USERNAME IN ('MOCHA_DB');
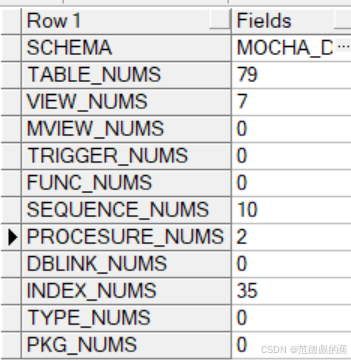
统计目的端对象及数据
统计各个表的数据量
在目的端创建辅助表 table_count
create table table_count (owner varchar(100),table_name varchar(100),cnt int;
在目的端执行脚本,将模式下表的数据量插入到辅助表 table_count 中。
declare
v_owner VARCHAR2(100);
v_tabname VARCHAR2(100);
stmt VARCHAR2(200);
num_rows number;
begin
for rec in (select owner,table_name from dba_tables where owner='MOCHA_DB' order by 1, 2)---owner根据实际情况调整
loop
select rec.owner,rec.table_name into v_owner,v_tabname from dual;
stmt := 'select count(*) from "' || v_owner || '"."' || v_tabname || '"';
EXECUTE IMMEDIATE stmt INTO num_rows;
EXECUTE IMMEDIATE 'insert into table_count values('''||v_owner||''','''||v_tabname||''','''||to_number(num_rows)||''')';
end loop;
end;

统计各种对象的数量
SELECT
A.USERNAME "用户名",
(SELECT COUNT(1) FROM DBA_TABLES B WHERE B.OWNER = A.USERNAME) "TABLE_NUMS",
( SELECT COUNT(1) FROM DBA_VIEWS G WHERE G.OWNER = A.USERNAME ) "VIEW_NUMS",
( SELECT COUNT(1) FROM DBA_TRIGGERS H WHERE H.OWNER = A.USERNAME ) "TRIGGER_NUMS",
( SELECT COUNT(DISTINCT I.OBJECT_NAME) FROM DBA_OBJECTS I WHERE I.OWNER = A.USERNAME AND I.OBJECT_TYPE = 'FUNCTION' ) "FUNC_NUMS",
( SELECT COUNT(1) FROM DBA_SEQUENCES J WHERE J.SEQUENCE_OWNER = A.USERNAME ) "SEQUENCE_NUMS",
( SELECT COUNT(DISTINCT L.OBJECT_NAME) FROM DBA_PROCEDURES L WHERE L.OWNER = A.USERNAME and L.OBJECT_TYPE='PROCEDURE') "PROCEDURE_NUMS",
( SELECT COUNT(1) FROM DBA_DB_LINKS M WHERE M.OWNER = A.USERNAME ) "DBLINK_NUMS",
( SELECT COUNT(1) FROM DBA_INDEXES I WHERE UNIQUENESS = 'UNIQUE' AND OWNER =A.USERNAME OR INDEX_NAME NOT LIKE 'INDEX335%' AND OWNER =A.USERNAME) "INDEX_NUMS",
( SELECT COUNT(1) FROM DBA_OBJECTS WHERE OBJECT_TYPE='TYPE' AND OWNER =A.USERNAME OR OBJECT_TYPE='CLASS' AND OWNER =A.USERNAME ) "TYPE_NUMS",
( SELECT COUNT(1) FROM DBA_OBJECTS WHERE OBJECT_TYPE='PACKAGE' AND OWNER =A.USERNAME) "PKG_NUMS" FROM
DBA_USERS A WHERE A.USERNAME IN ('MOCHA_DB');
检查 DM 目的端的查询结果和 ORACLE 源端是否一致。
非分区表:
每一个表都会有一个聚簇索引
分区表:
每个分区都会有一个聚簇索引
比如,源端有两个字段做分区表,每个字段有9个分区,源端一共有18个索引分区
目标端也是两个字段做分区,每个字段9个分区,18个普通分区,还有9个聚簇索引,在dba_indexes里查一共27个索引分区。
注意含LOB字段索引的迁移,含LOB字段会有一个默认LOB类型的索引,以SYS开头,在达梦数据库中不含这个索引。
6.数据库移植完毕后收尾工作
索引补录
更新统计信息
当迁移后全库数据量较小时,可以使用全模式更新的方法:
DBMS_STATS.GATHER_SCHEMA_STATS( '模式名',100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
对于需要单独收集统计信息的表,可以按照如下方式收集:
DBMS_STATS.GATHER_TABLE_STATS('模式名','表名',NULL,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
当全库数据量较大时,按模式更新统计信息比较慢,可以使用全列收集统计信息的方式进行收集:
--更新指定表的所有列的统计信息可使用 SYSDBA 或者用户自身--DROP TABLE SYSDBA.stat_history;--SELECT * FROM SYSDBA.stat_history;--创建日志记录表create table SYSDBA.stat_history (beg_time TIMESTAMP,end_time timestamp,sql_str varchar2(500),table_name varchar2(200),col_name VARCHAR2(200));
--创建存储过程CREATE OR REPLACE PROCEDURE "SYSDBA"."TABLE_STATS"
AUTHID DEFINERAS
declare --更新所有列的统计信息
v_sql varchar(4000);
v_begtime VARCHAR2(200);
v_endtime varchar2(200);CURSOR c1 IS SELECT
SCH.NAME AS SCHEMA_NAME,
TAB.NAME AS TABLE_NAME ,
SYSCOL.NAME AS COLUMN_NAMEFROM
SYSOBJECTS AS TAB,
SYSOBJECTS AS SCH,
SYSCOLUMNS AS SYSCOLWHERE
SCH.ID =TAB.SCHID
AND TAB.ID =SYSCOL.ID
AND SCH.NAME in ('SYSDBA') --填写实际用户名
AND SYSCOL.TYPE$ NOT IN ('BLOB','CLOB','TEXT')
and TAB.NAME IN(select TABLE_NAME from ALL_TABLES WHERE OWNER in ('SYSDBA') and TABLE_NAME not like '%BM$_%' AND TABLE_NAME NOT LIKE 'MTAB$%'); begin
execute immediate 'truncate table SYSDBA.STAT_HISTORY;';
for i in c1
loop
v_sql='stat 100 on '||i.SCHEMA_NAME||'."'||i.TABLE_NAME||'"("'||i.COLUMN_NAME||'");';
begin
v_begtime := sysdate();
execute immediate v_sql;
v_endtime := sysdate();
insert into SYSDBA.stat_history VALUES (v_begtime,v_endtime,v_sql,i.TABLE_NAME,i.COLUMN_NAME);
commit;
EXCEPTION WHEN OTHERS THEN
PRINT SQLERRM;
end;
end loop;
end; --调用存储过程call "SYSDBA"."TABLE_STATS" ();
select * from SYSDBA.stat_history;
备份
完成整体的迁移工作后,如果为正式迁移,需要对系统做一次全库备份。