目录
前言:DataFrame是Pandas库中的一种数据结构,它是由多种类型的列组成的二维表数据结构,类似于Excel、SQL或Series对象构成的字典。DataFrame是最常用的Pandas对象,它与Series对象一样支持多种类型的数据
一.图解DataFrame
DataFrame是一个二维表数据结构,由行、列数据组成的表格。DataFrame既有行索引也有列索引,它可以看做是由Series对象组成的字典,不过这些Seies对象共用一个索引,如下图所示:
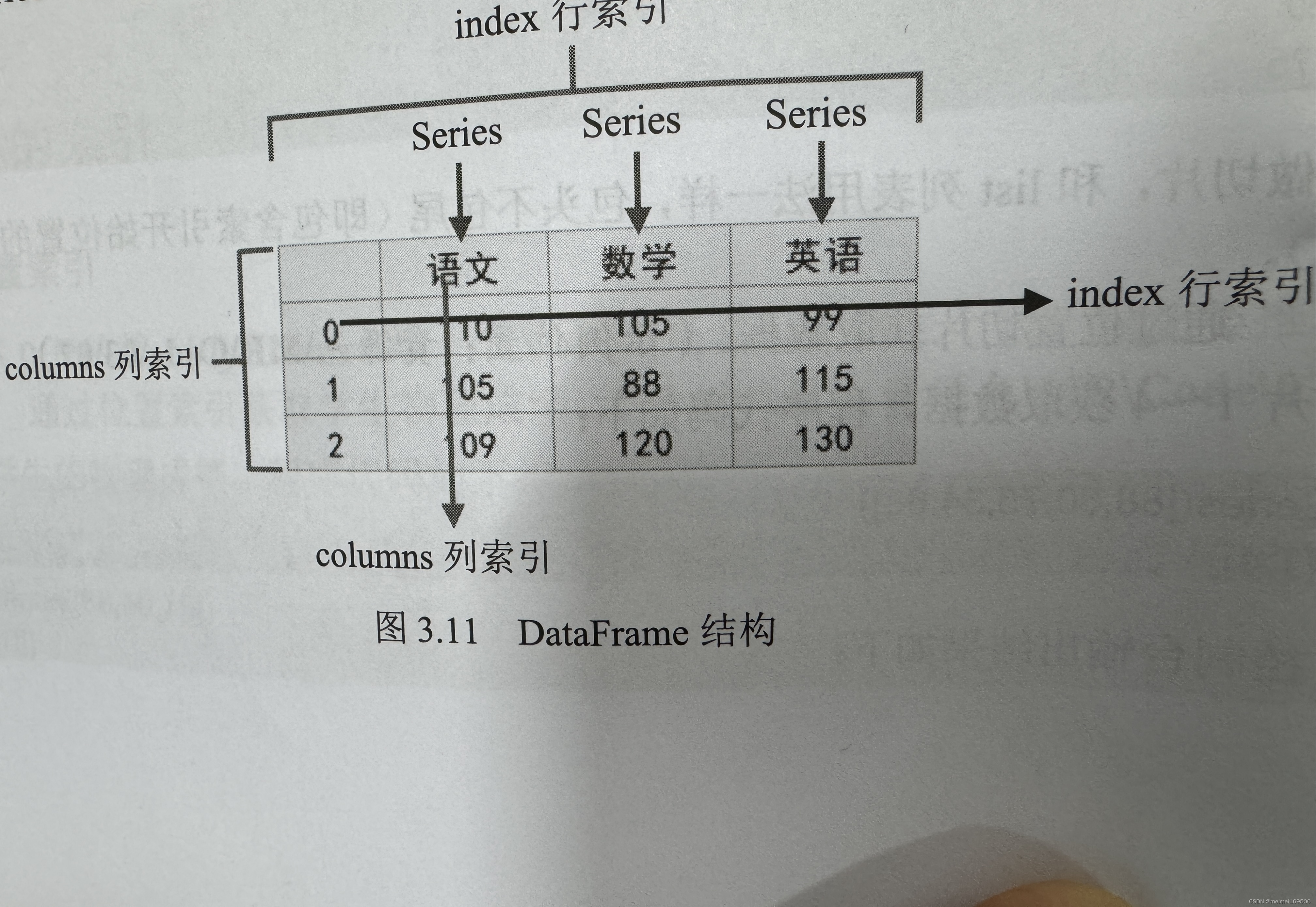
处理DataFrame表格数据时,用index表示行或用columns表示列更直观。用这种方法迭代DataFrame的列,代码更易读懂。
遍历DataFrame数据,输出成绩表的每一列数据,程序代码如下:
import pandas as pd
data = [[110,105,99],[105,88,115],[109,120,130]]
index = [0,1,2]
columns=['语文','数学','英语']
#创建DataFrame数据
df = pd.DataFrame(data=data,index=index,columns=columns)
print(df)
#遍历DataFrame数据的每一列
for col in df.colums:
series = df[col]
print(series)运行程序,控制台输出结果如下:
语文 数学 英语
0 110 105 99
1 105 88 115
2 109 120 130从运行结果得知,上述代码返回的其实是Series,如图所示。Pandas之所以提供多种数据结构,其目的是为了代码易读、操作更加方便。
| 语文 | 数学 | 英语 | |
| 0 | 110 | 105 | 99 |
| 1 | 105 | 88 | 115 |
| 2 | 109 | 120 | 130 |
二..创建一个DataFrame对象
创建DataFrame主要使用Pandas的DataFrame()方法,语法如下:
pandas.DataFrame(data,index,columns,dtype,copy)
参数说明:
data:表示数据,可以是ndarray数组、Series对象、列表、字典等
index:表示行标签(索引)。
columns:列标签(索引)
dtype:每一列的数据类型,其与python数据类型有所不同,如object数据类型对应的是python的字符型。如下为Pandas数据类型与python数据类型的对应表。

copy:用于复制数据
返回值:DataFrame
下面通过两种方法来创建DataFrame,即通过二维数组创建和通过字典创建。
1.通过二维数组组建DataFrame
示例如下:通过二维数组创建成绩表,包括语文、数学和英语,程序代码如下:
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)
data = [[110,105,99],[105,88,115],[109,120,130]]
columns = ['语文','数学','英语']
df = pd.DataFrame(data=data=data,columns=columns)
print(df)运行程序,控制台输出结果如下:
语文 数学 英语
0 110 105 99
1 105 88 115
2 109 120 1302.通过字典创建DataFrame
通过字典创建 DataFrame,需要注意:字典中的value值只能是一维数组或单个的简单数据类型如果是数组,要求所有数组长度一致:如果是单个数据,则每行都添加相同数据。
示例如下:通过字典创建成绩表,包括语文、数学、英语和班级,程序代码如下:
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width',True)
df = pd.DataFrame({
'语文':[110,105,99],
'数学':[105,88,115],
'英语':[109,120,130],
'班级':'高一7班'
},index=[0,1,2]
print(df)运行程序,控制台输出如下:
语文 数学 英语 班级
0 110 105 109 高一7班
1 105 88 120 高一7班
2 99 115 130 高一7班上述代码中,“班级”的value值是一个单个数据,所以每一行都添加了相同的数据“高一7班”。
三.DataFrame重要属性和函数
DataFrame是Pandas一个重要的对象,它的属性和函数很多,下面先简单了解 DataFrame的几个重要属性和函数。重要属性介绍如表3.2所示,重要函数介绍如表3.3所示。
DataFrame是Pandas库中最常用的数据结构之一,它是一个二维的表格型数据结构,类似于电子表格或关系型数据库中的表。下面是一些DataFrame的重要属性和函数的解释说明:
1. 属性:
- `shape`:返回一个元组,表示DataFrame的维度,即行数和列数。
- `columns`:返回一个列表,包含DataFrame的列名。
- `index`:返回一个表示DataFrame索引的列表或数组。
- `dtypes`:返回一个Series,其中包含DataFrame每列的数据类型。
- `values`:返回一个二维的NumPy数组,包含DataFrame的数据。
- `head(n)`:返回DataFrame的前n行,默认为前5行。
- `tail(n)`:返回DataFrame的后n行,默认为后5行。
2. 函数:
- `info()`:打印DataFrame的基本信息,包括索引类型、列名、非空值数量和每列的数据类型。
- `describe()`:计算DataFrame每列的统计摘要信息,包括计数、均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值。
- `head(n)`:返回DataFrame的前n行。
- `tail(n)`:返回DataFrame的后n行。
- `loc[]`:通过标签获取行或列的数据。例如,`df.loc[2]`返回索引为2的行数据,`df.loc[:, 'column_name']`返回名为'column_name'的列数据。
- `iloc[]`:通过位置获取行或列的数据。例如,`df.iloc[2]`返回位置为2的行数据,`df.iloc[:, 1]`返回位置为1的列数据。
- `dropna()`:删除包含缺失值(NaN)的行或列。
- `fillna(value)`:用指定的值替换缺失值。
- `sort_values(by)`:按照指定的列对DataFrame进行排序。
- `groupby(by)`:按照指定的列对DataFrame进行分组。
- `merge(other_df)`:将两个DataFrame按照共同的列进行合并。
- `pivot_table(values, index, columns)`:根据指定的值、索引和列创建一个数据透视表。
这些属性和函数只是DataFrame提供的众多功能的一小部分。通过使用这些属性和函数,你可以对DataFrame进行数据操作、统计分析、数据清洗和转换等操作。详细了解Pandas文档中的DataFrame部分可以帮助你更好地利用DataFrame进行数据处理和分析。
重要属性和重要函数如下图所示:


四.python中DataFrame对象的注意事项
在使用DataFrame对象时,有一些注意事项需要考虑。以下是一些常见的注意事项:
1. 列名和索引:确保DataFrame的列名和索引是唯一的,避免出现重复命名的列或索引,这可能导致数据访问和操作时的混淆。
2. 缺失值处理:DataFrame中可能存在缺失值(NaN或None),在进行数据分析或建模之前,需要考虑如何处理这些缺失值,可以选择删除包含缺失值的行或列,或者使用填充方法进行处理。
3. 数据类型转换:DataFrame中的列具有不同的数据类型,确保每列的数据类型正确,以便进行适当的计算和分析。可以使用`astype()`方法将列转换为特定的数据类型。
4. 内存使用:DataFrame对象可能占用大量的内存空间,特别是当数据集非常大时。在处理大型数据集时,可以考虑使用适当的数据类型和压缩方法来减少内存占用。
5. 数据排序:DataFrame中的数据排序是一种常见的操作,但需要注意排序的顺序和基准列。确保在排序时指定正确的列名和排序顺序,以避免数据的不一致性。
6. 数据修改:DataFrame是可变对象,可以对其进行修改。但需要注意,对DataFrame进行原地修改可能会导致意外的结果,建议使用副本或复制DataFrame进行修改,以避免原始数据的丢失或混淆。
7. 性能考虑:在处理大型数据集时,一些操作可能会比较耗时,例如数据合并、分组聚合等。在进行这些操作时,可以考虑使用适当的优化技术,如使用适量化操作(vectorized operations)或使用并行计算来提高性能。
这些是使用DataFrame对象时需要注意的一些事项。了解这些注意事项可以帮助您更好地处理和分析数据,并避免一些常见的错误和问题。
五.python中DataFrame对象的总结内容
DataFrame是Pandas库中最常用的数据结构之一,它是一个二维的表格型数据结构,类似于电子表格或关系型数据库中的表。下面是关于Python中DataFrame对象的总结内容:
1. 创建DataFrame:
- 使用Pandas的`DataFrame()`函数从列表、字典、NumPy数组等数据结构创建DataFrame。
- 从CSV、Excel文件或数据库中读取数据创建DataFrame。
2. 属性:
- `shape`:返回DataFrame的维度,即行数和列数。
- `columns`:返回DataFrame的列名。
- `index`:返回DataFrame的索引。
- `dtypes`:返回DataFrame每列的数据类型。
- `values`:返回DataFrame的数据。
- `head(n)`:返回DataFrame的前n行,默认为前5行。
- `tail(n)`:返回DataFrame的后n行,默认为后5行。
3. 基本操作:
- 访问列:使用列名或属性访问DataFrame的列数据。
- 访问行:使用`loc[]`或`iloc[]`通过标签或位置访问DataFrame的行数据。
- 添加列:使用赋值操作或`insert()`函数添加新的列。
- 删除列:使用`drop()`函数删除指定的列。
- 筛选行:使用布尔条件筛选满足条件的行。
4. 数据操作:
- 缺失值处理:使用`dropna()`删除包含缺失值的行或列,使用`fillna()`填充缺失值。
- 排序:使用`sort_values()`按照指定的列对DataFrame进行排序。
- 分组和聚合:使用`groupby()`对DataFrame进行分组,使用聚合函数计算汇总统计。
- 合并和连接:使用`merge()`将两个DataFrame按照共同的列进行合并,使用`concat()`进行连接操作。
- 透视表:使用`pivot_table()`创建数据透视表。
5. 数据统计与描述:
- `describe()`:计算DataFrame每列的统计摘要信息。
- `mean()`、`median()`、`min()`、`max()`:计算DataFrame每列的均值、中位数、最小值和最大值。
- `sum()`、`count()`、`std()`、`var()`:计算DataFrame每列的和、计数、标准差和方差。
这些是DataFrame对象的一些重要特性和常用操作。DataFrame提供了丰富的功能,可以进行数据处理、分析和转换等操作,使数据操作变得更加灵活和方便。详细了解Pandas文档中的DataFrame部分可以更好地利用DataFrame进行数据处理和分析。
本文链接:写文章-CSDN创作中心