ELK日志系统
是一套完整的日志集中处理方案
E:ElasticSearck ES 分布式索引型非关系数据库 存储logsstash输出的日志,全文检索引擎,保持的格式是json格式
L:logstash 基于Java开发的,数据收集引擎。日志的收集,可以对数据进行过滤,分析,汇总,已标准格式输出
K:kiabana 是es的可视化工具,对es存储的数据进行可视化展示,分析和检索
数据流向
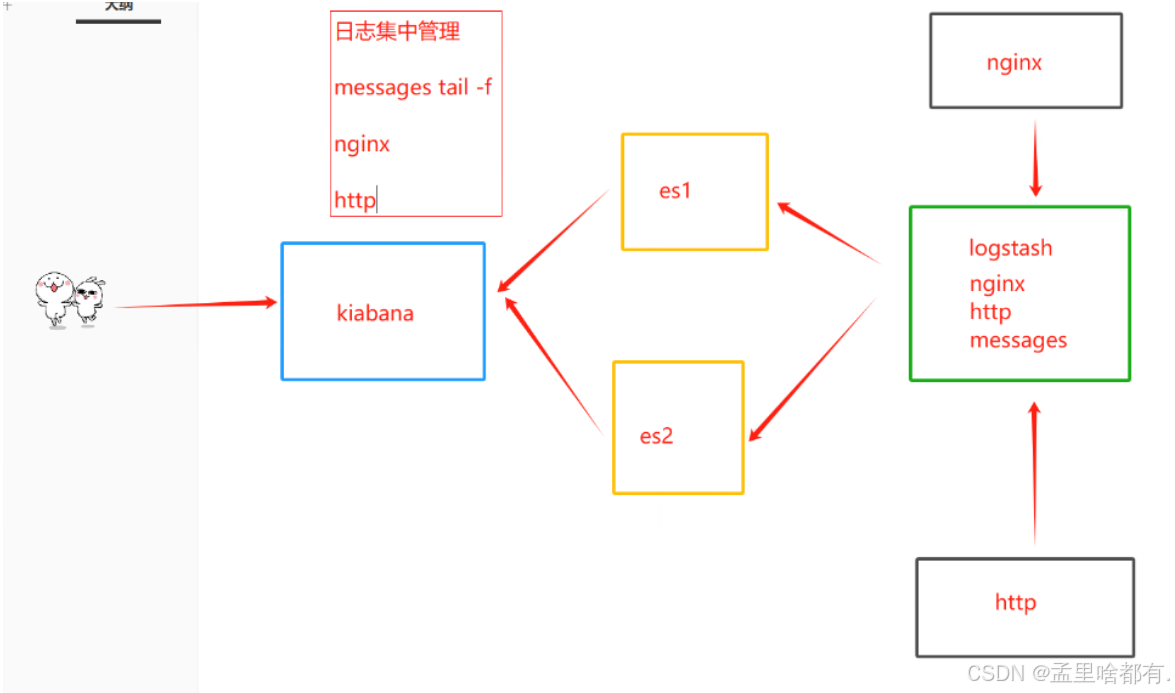
ELKF K
f
filebeat:轻量级的开源日志文件数据收集器。logstash占用系统资源比较大,属于重量级。有了filebeat可以节省资源,可以通过filebeat和logstash实现远程数据收集
filebeat 不能对数据进行标准输出,不能输出为es格式的数据,所以需要logstash吧filebeat数据和标准化处理
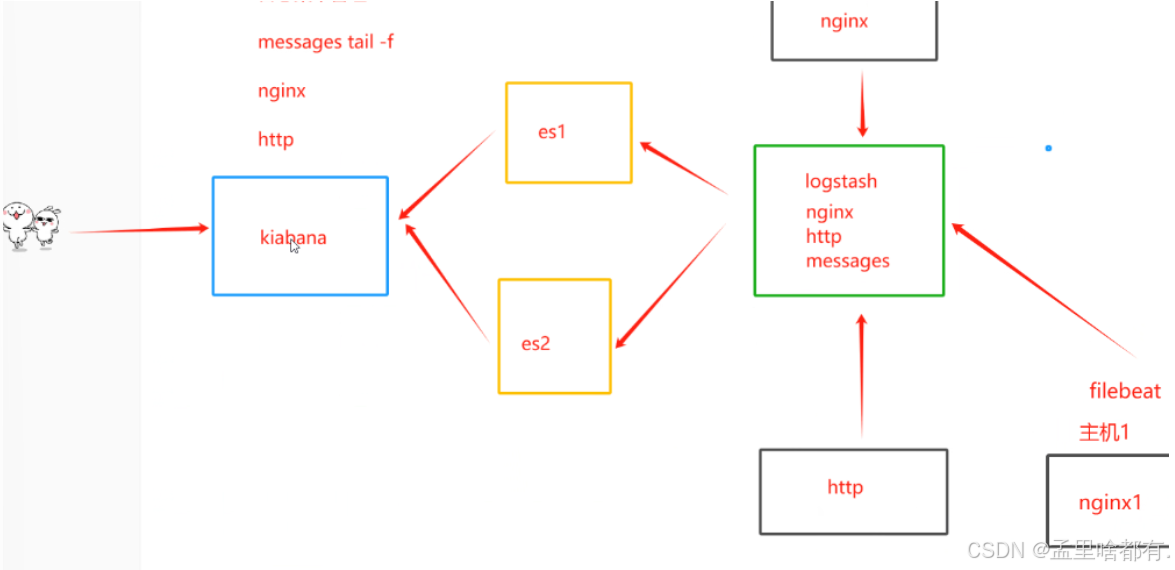
K
kafka 消息队列?
架构
主4核8G
20.0.0.13
20.0.0.14
20.0.0.15
关防火墙 安全机制
yum -y install java
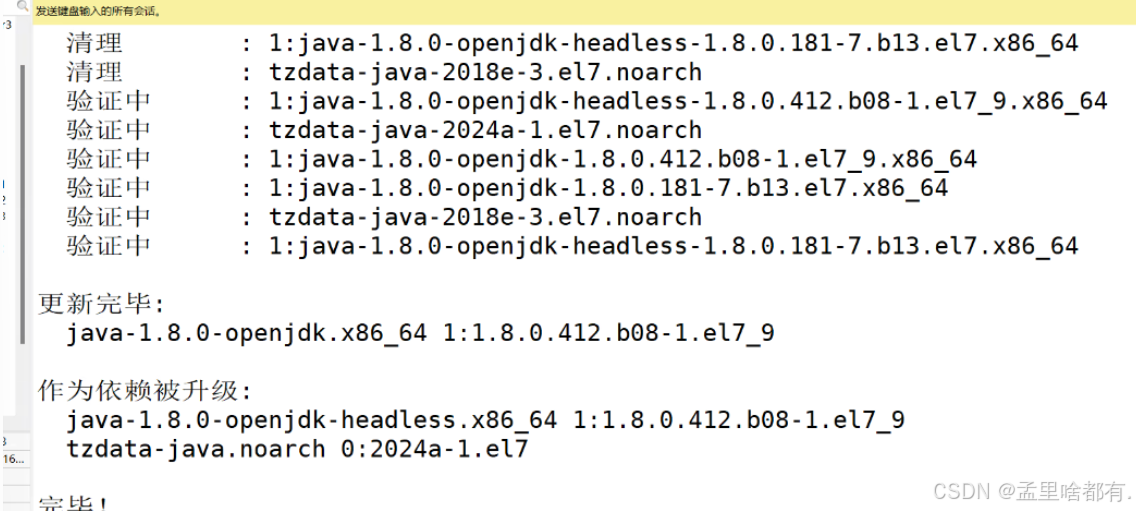
rpm -ivh elasticsearch-6.7.2.rpm
取消同步

以上两台一样操作
第一台
两台一致
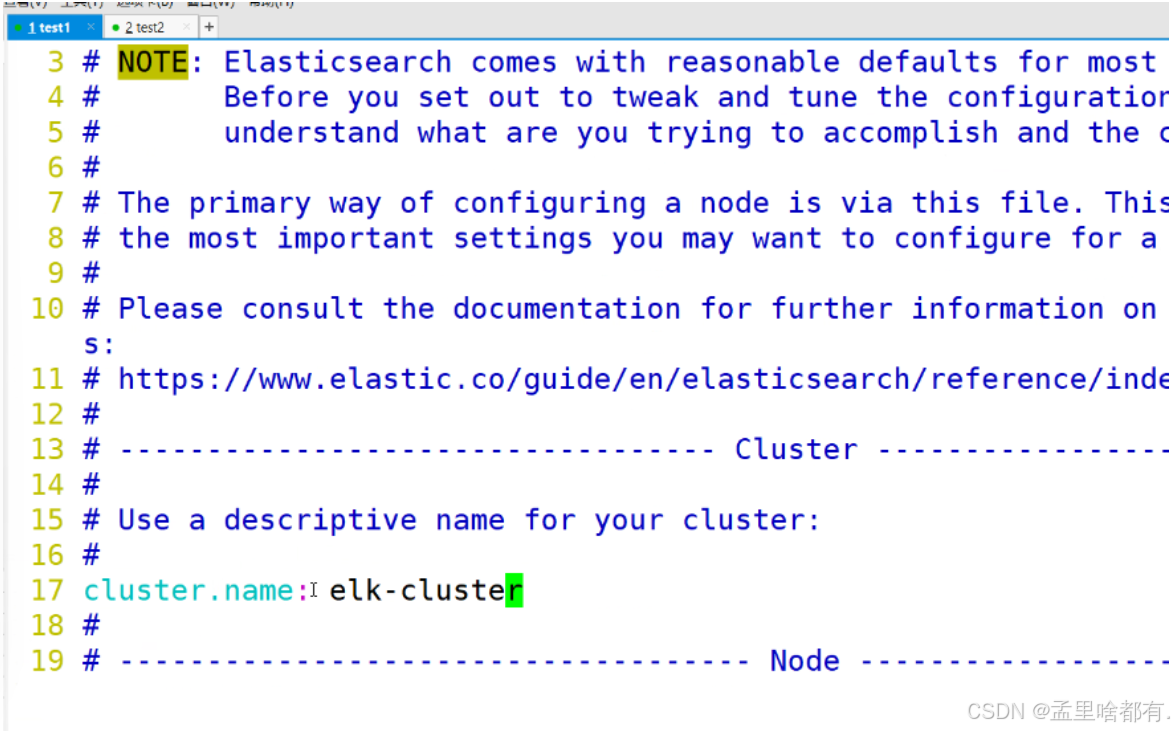
名字不可一样
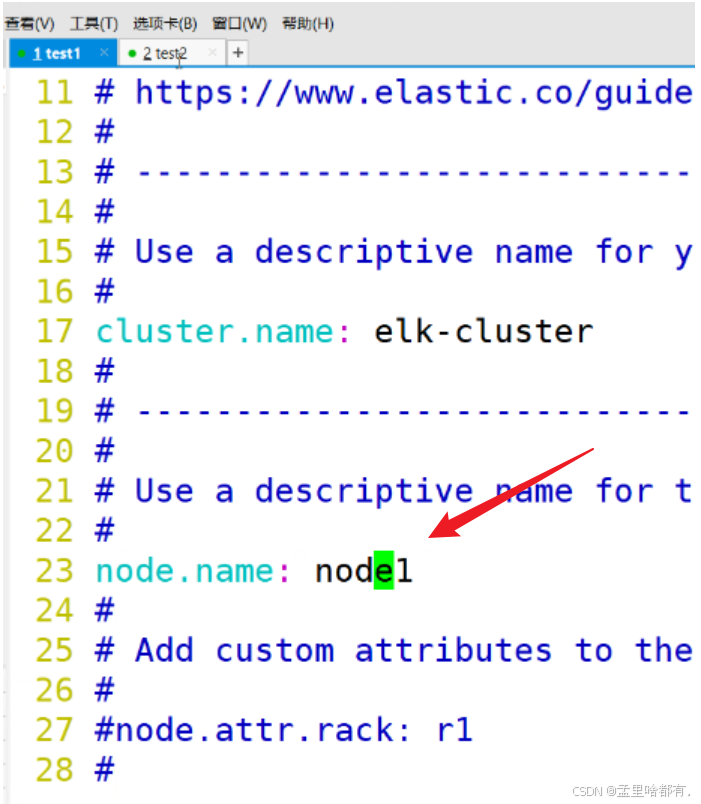
两台一样操作
1

第二台
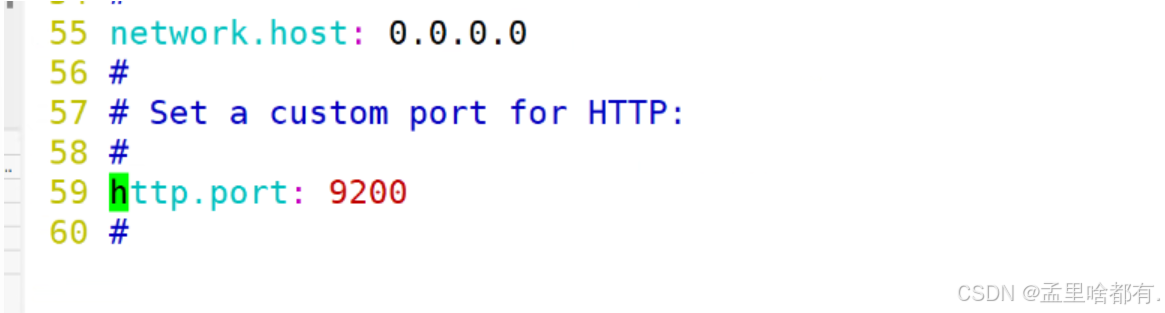
设置内部通信端口
两台一样
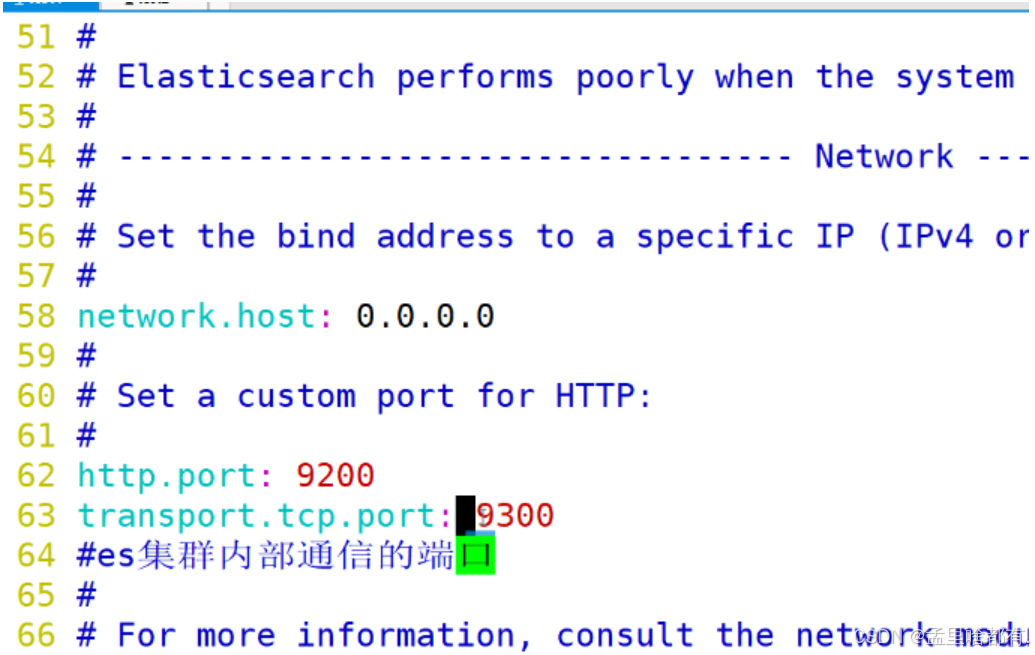
监听IP地址加端口
两台一样操作
discovery.zen.ping.unicast.hosts: ["20.0.0.13:9300", "20.0.0.14:9300"]
grep -v "^#" /etc/elasticsearch/elasticsearch.yml
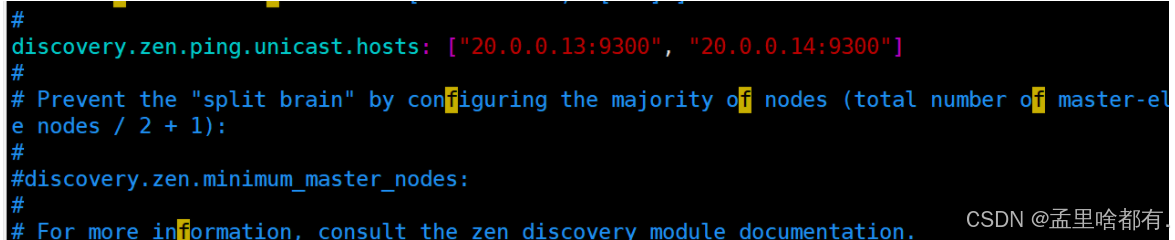
查看一下刚才的设置
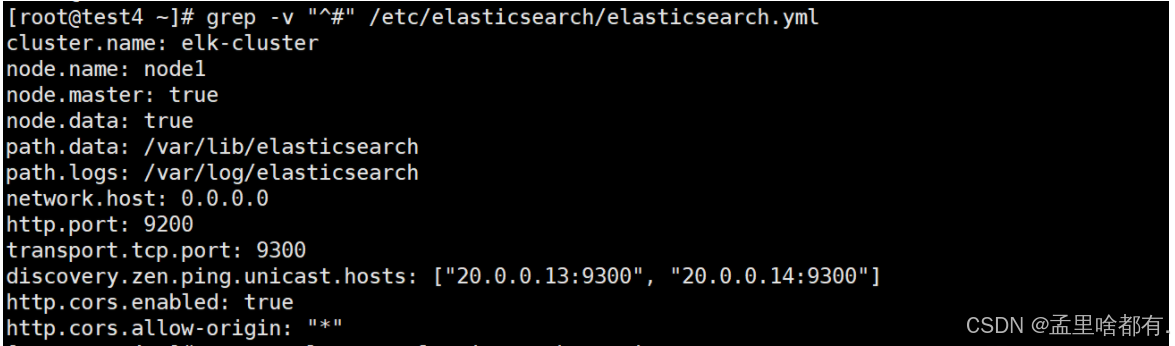
两台重启 查看端口

如果没启动查看他的日志
tail -f /var/log/elasticsearch/elk-cluster.log

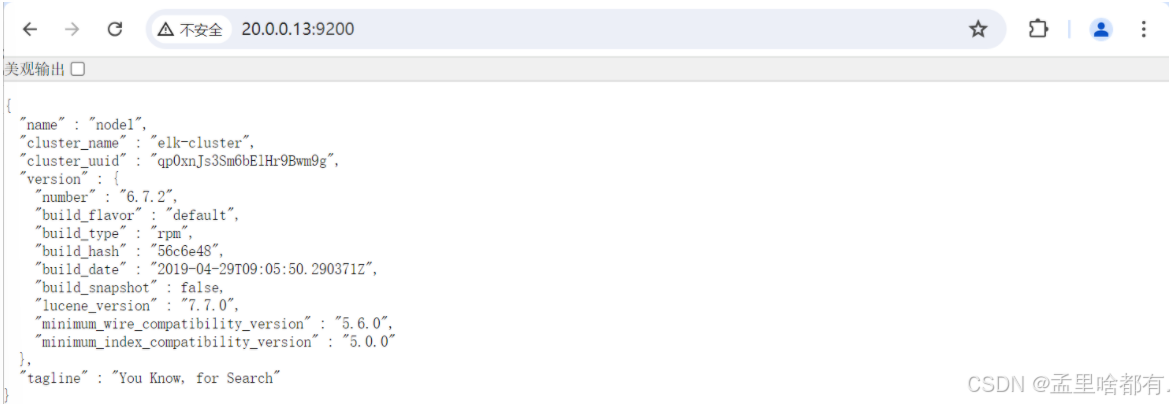
页面查看 浏览器访问IP加端口
访问查看
再次上传这三个
安装环境
yum -y install gcc gcc-c++ make 以下同步操作
解包

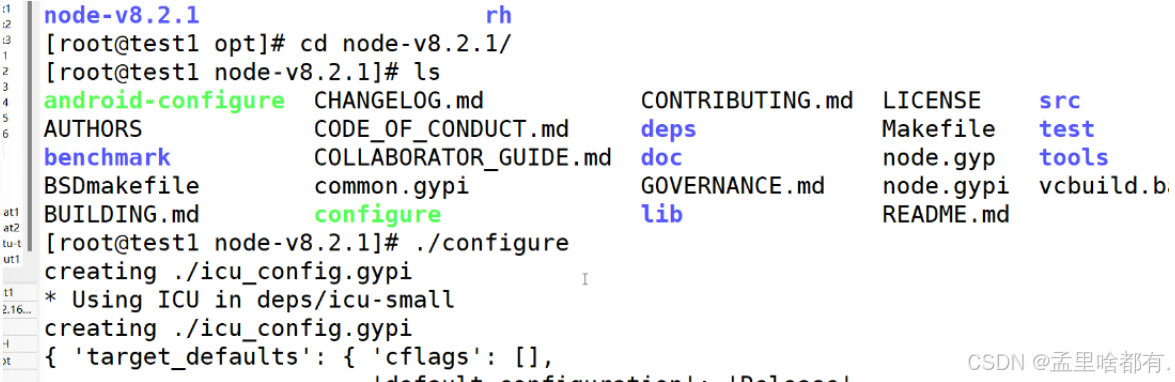
可以配置两个核

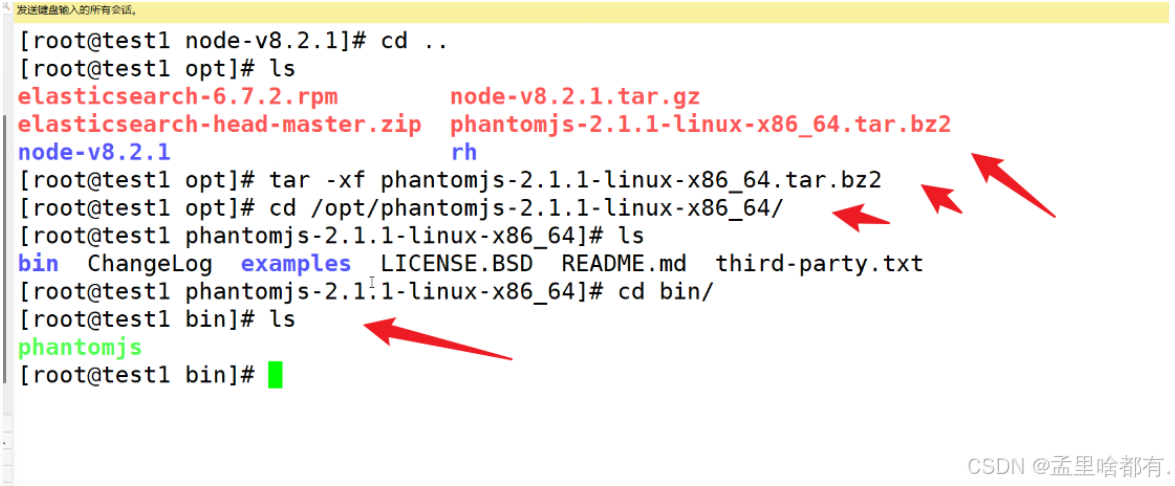
进行复制
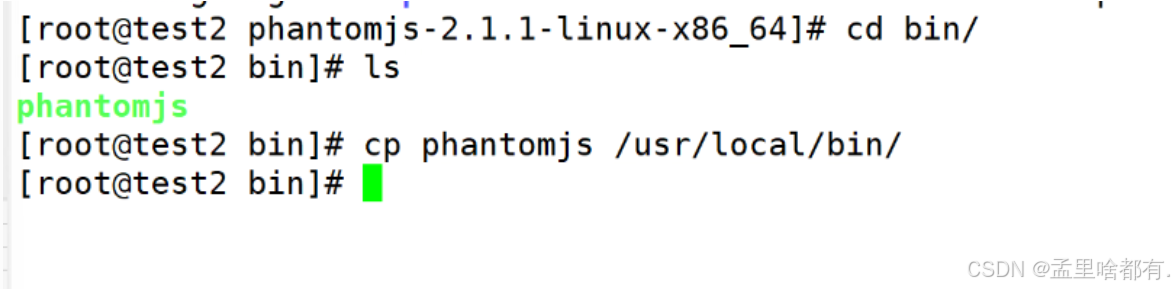
指定镜像
npm config set registry http://registry.npm.taobao.org/
安装
npm install

修改配置文件
vim /etc/elasticsearch/elasticsearch.yml

末尾添加两行
两边同步
http.cors.enabled: true
http.cors.allow-origin: "*"
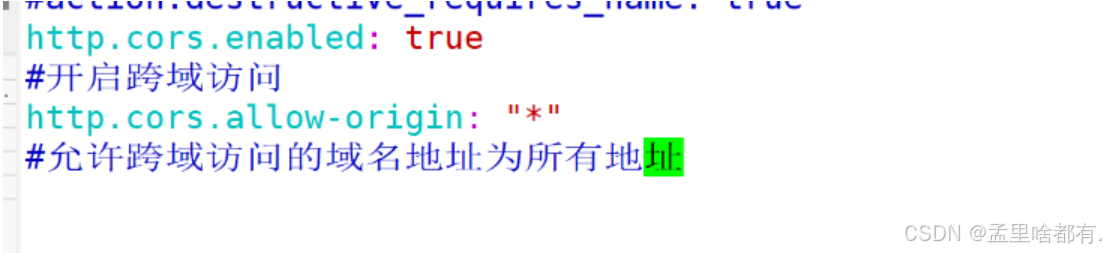
然后重启服务查看端口

两台同步启用
cd /opt/elasticsearch-head-master
npm run start &

浏览器查看

命令行回车 传参
(7)插入索引
#通过命令插入一个测试索引,索引为 index-demo,类型为 test。
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
//输出结果如下:
{
"_index" : "index-demo",
"_type" : "test",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"created" : true
}
回到浏览器查看数据切片
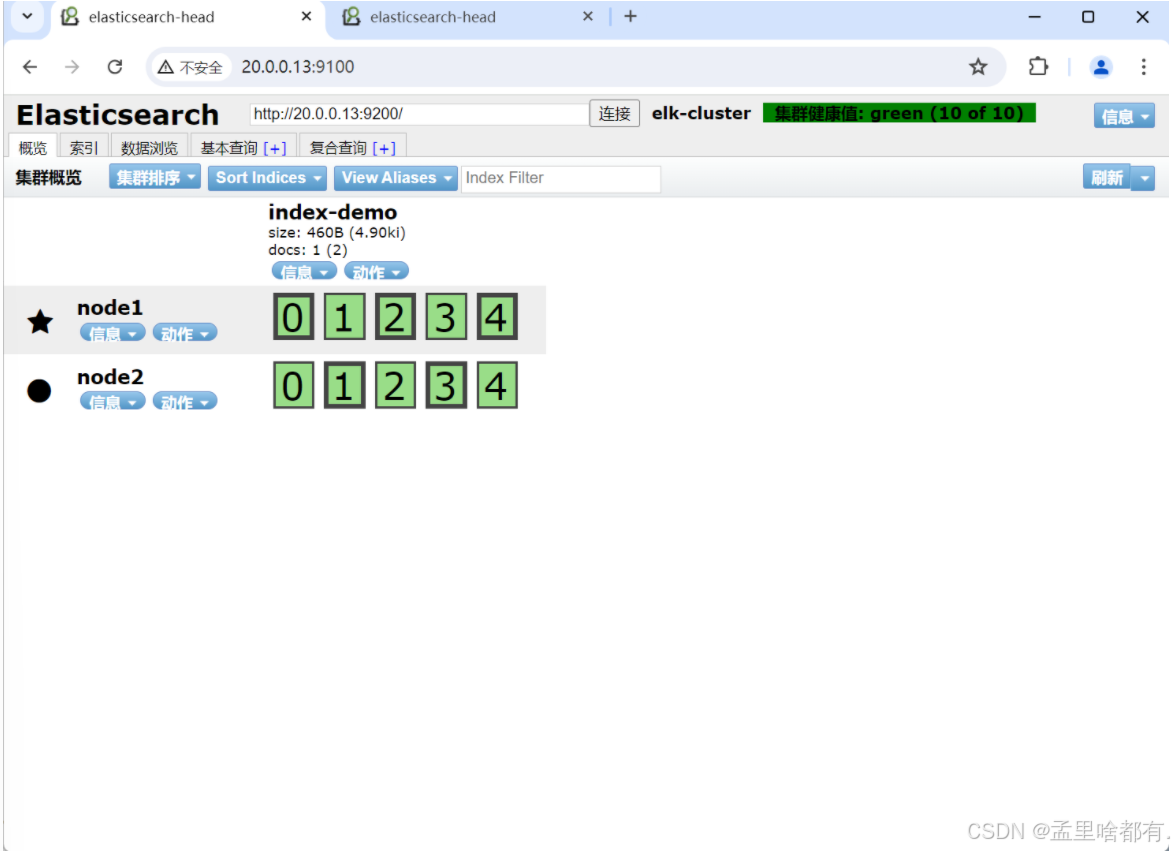

切换到另一台

安装java环境 安装httpd
yum -y install java
yum -y install httpd
查看版本

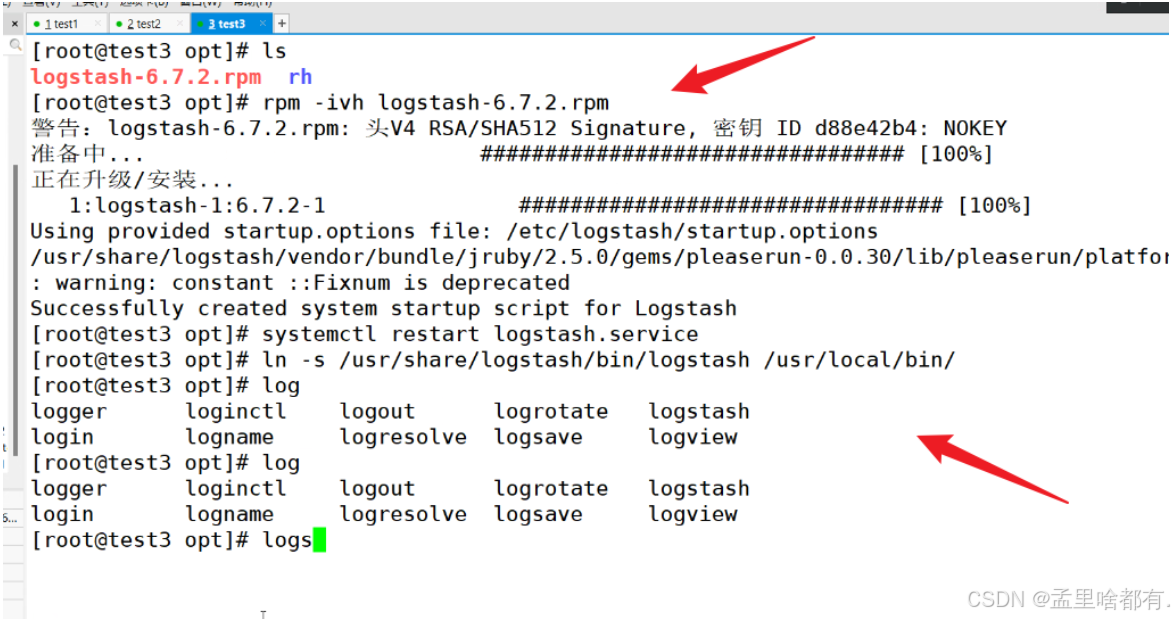
解包安装 创建软连接
ln -s /usr/share/locale/bin/logstash /usr/local/bin/
默认文件存放位置
不修改默认存放在在这里
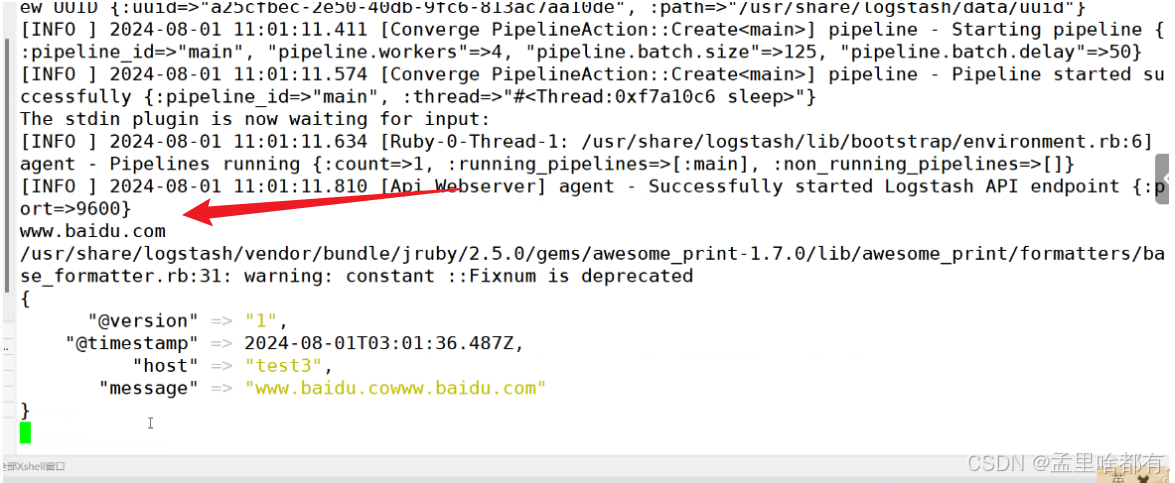
测试
logstash -e 'input { stdin{} } output { stdout{} }'

查看结果
这样表示成功
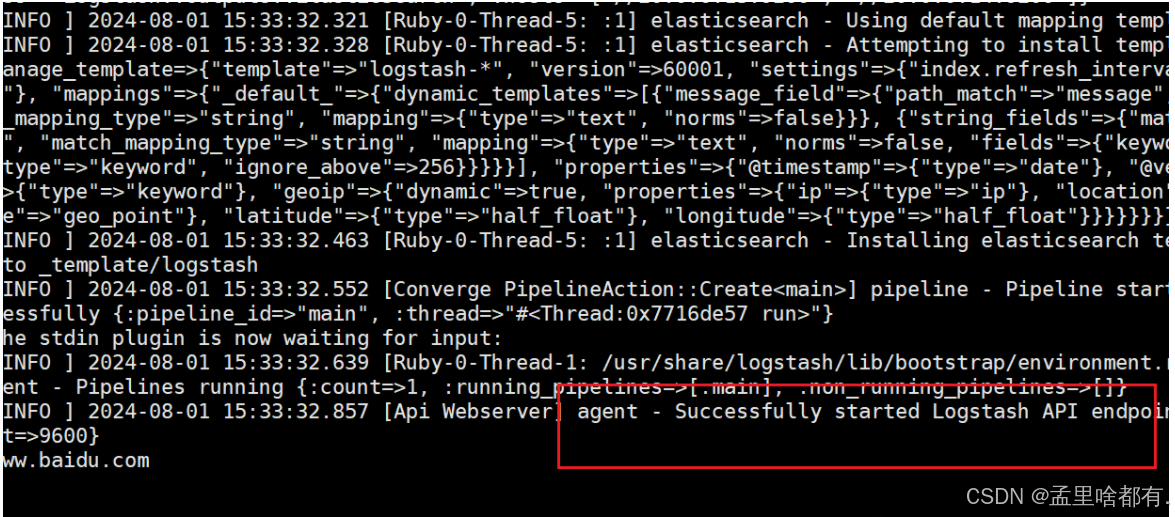
报错输入下面内容
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["20.0.0.13:9200","20.0.0.14:9200"] } }' --path.data /opt/test1

测试这个 发到实例上
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["20.0.0.13:9200","20.0.0.14:9200"] } }'
输入 输出 对接
没显示结果 去网页查看
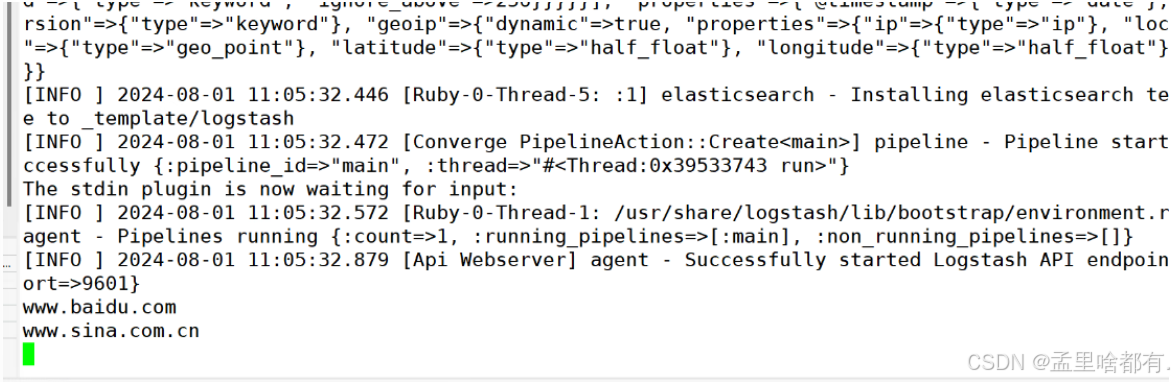
然后页面访问
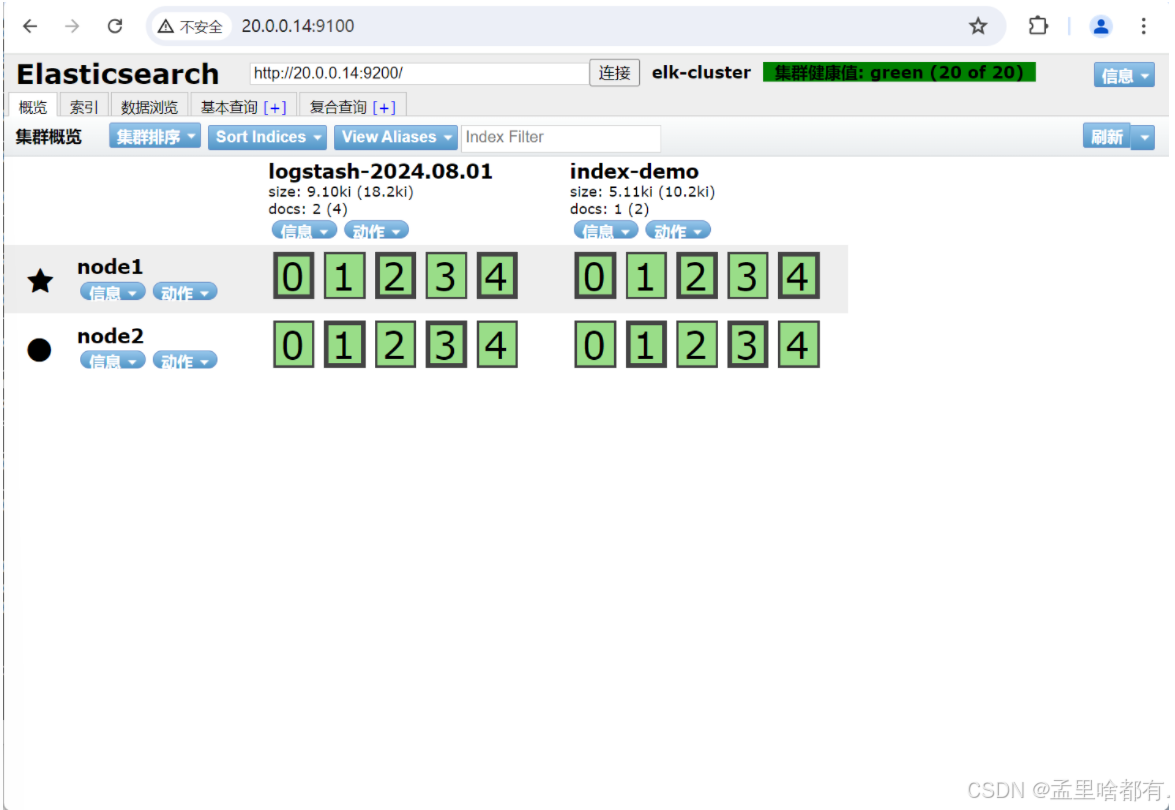

es的主从和数据模式
node.master: true #是否master节点,false为否
node.data: true
数据节点,是否保存数据logstash发送数据,节点是否接受以及保存。
es如何创建,修改,删除数据 数据管理
通过http的方式
post方式修改数据
创建数据
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
对应的就是本地数据库加端口
index-demo
创建索引分片的名称
test
数据的名称
1
数据的id字段
pretty&pretty
参数设定为json格式
-d
数据的具体内容
“user”:“zhangsan”,“mesg”:“hello world”
修改数据
[root@test1 elasticsearch-head-master]# curl -X POST 'localhost:9200/index-demo/test/1/_update?pretty' -H 'Content-Type: application/json' -d '{ "doc": { "user": "zhangsan", "mesg": "hello1 world1" } }'
删除数据
curl -X DELETE 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
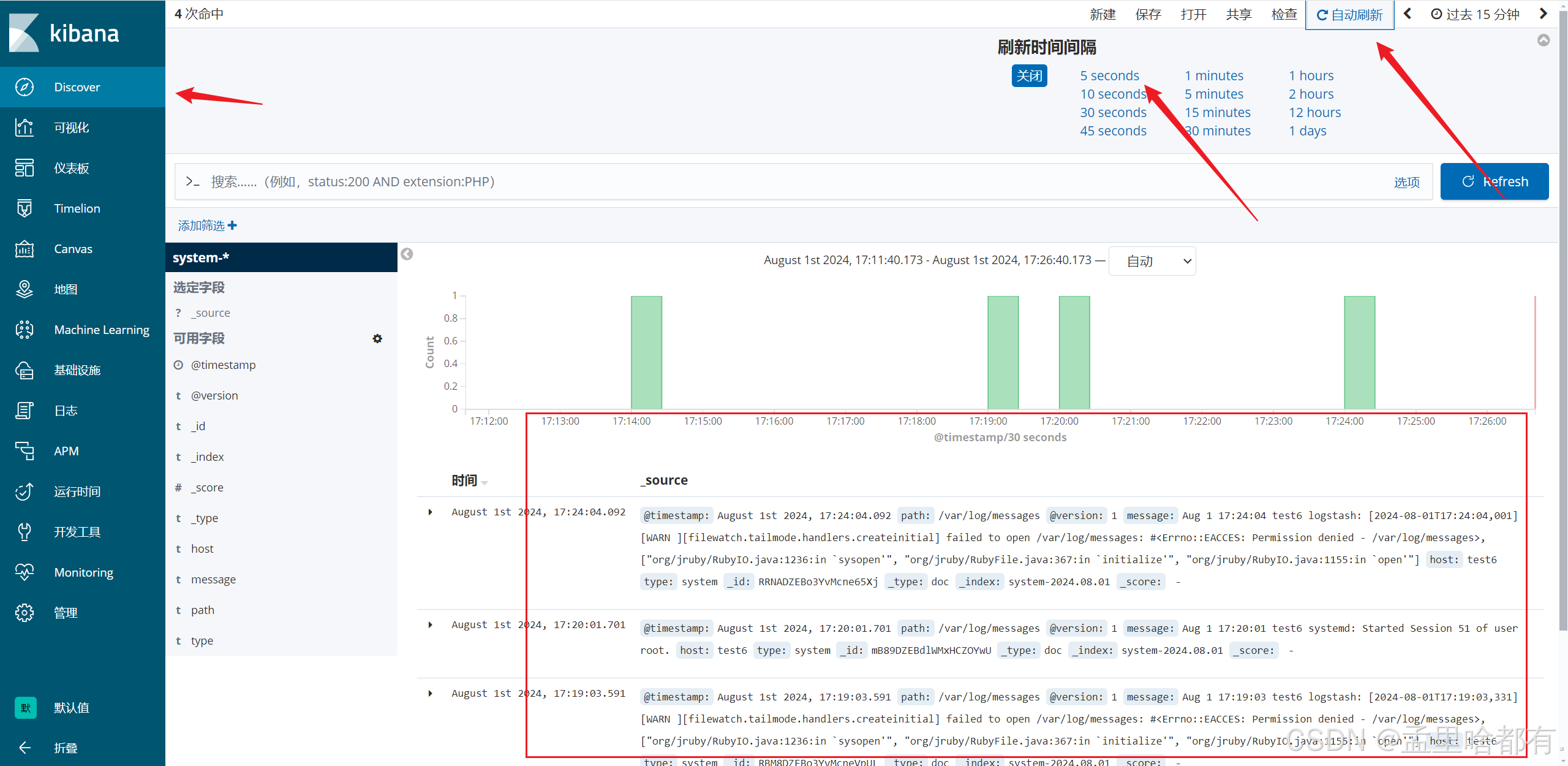
图形化工具 test6
当前目录是存放日志文件的目录
日志收集文件必须要以.conf为结尾
文件内添加内容
从头收集日志内容

保存加当前日期

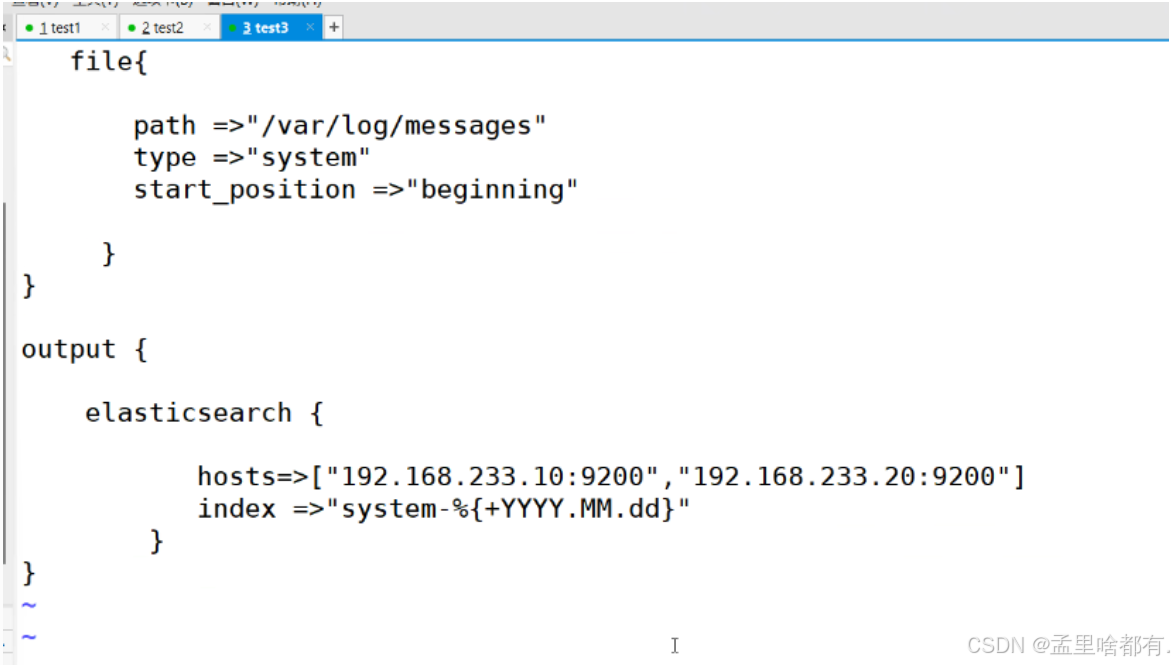
input {
file {
path =>"/var/log/messages"
type =>"system"
start_position =>"beginning"
}
}
output {
elasticsearch {
hosts=>["20.0.0.13:9200","20.0.0.14:9200"]
index =>"system-%{+YYYY.MM.dd}"
}
}
这段配置的作用是从/var/log/messages文件中读取系统日志,然后将这些日志以每天为单位写入到Elasticsearch中,每天创建一个新的索引,索引名包含了日期信息
启动脚本收集日志
logstash -f system.conf --path.data /opt/test2 &

回车即可退出

页面查看
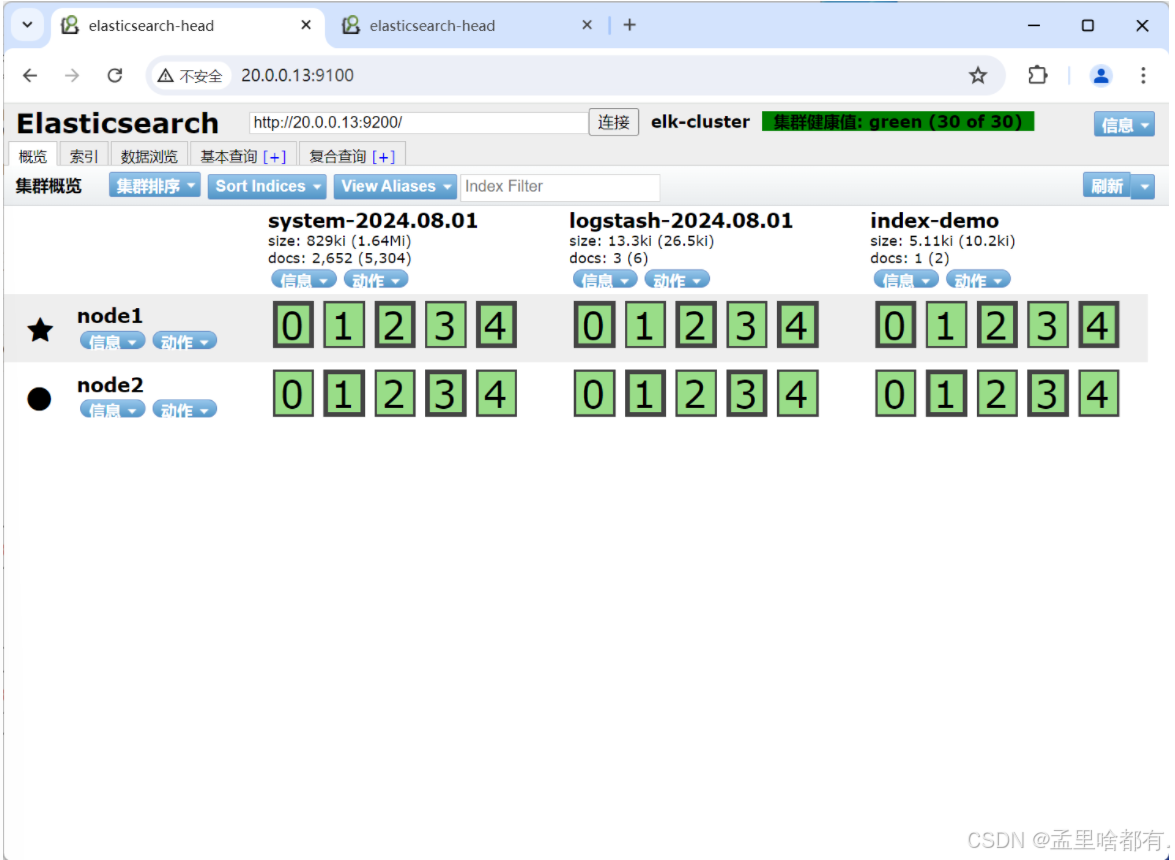
解包 安装图形化界面
修改配置文件
2 7

示例数据库的地址
在这里插入图片描述
96 日志
logging.dest: /var/log/kibana.log

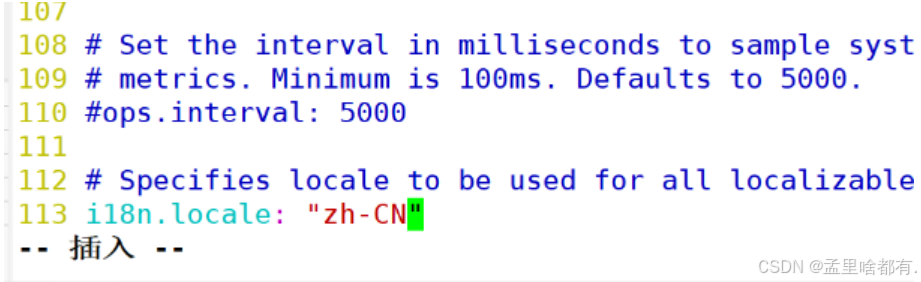
131 修改语言
37 打开索引名

创建日志文件 修改所有者 赋权
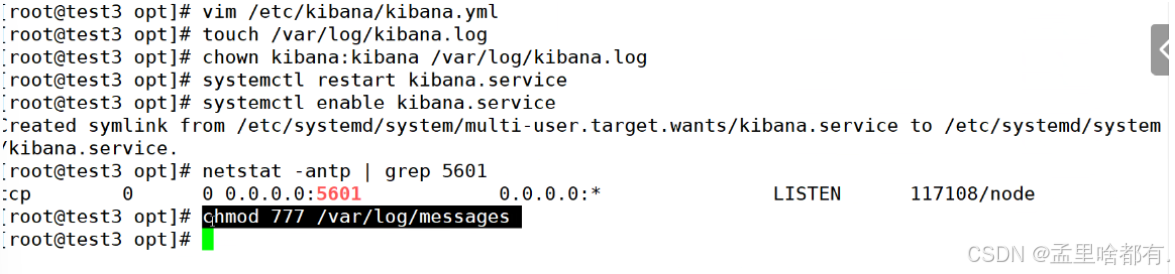
网页产看 ip+端口
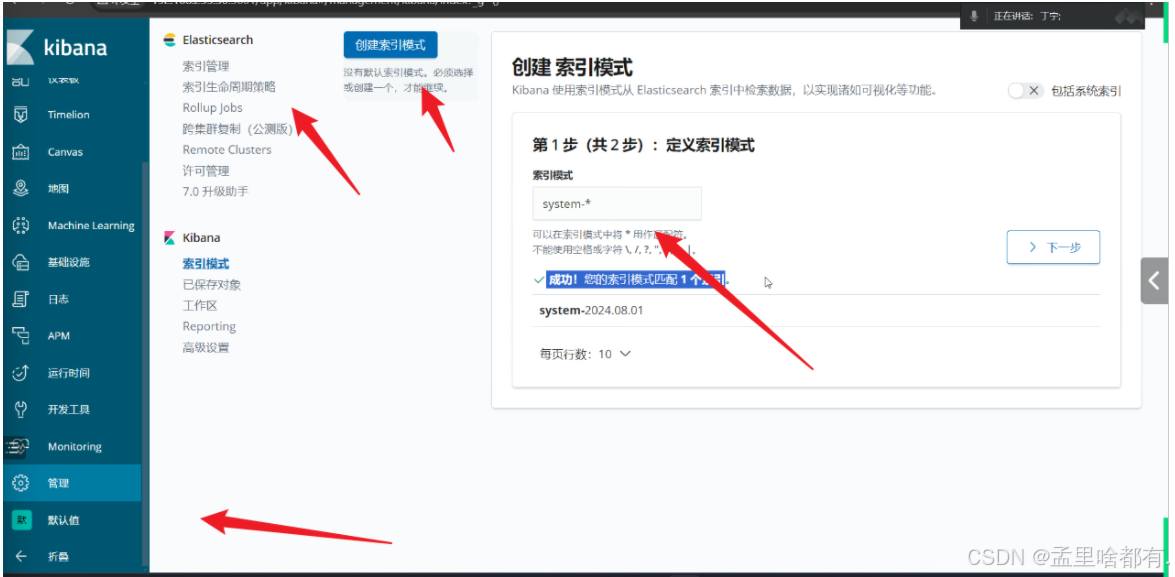
默认
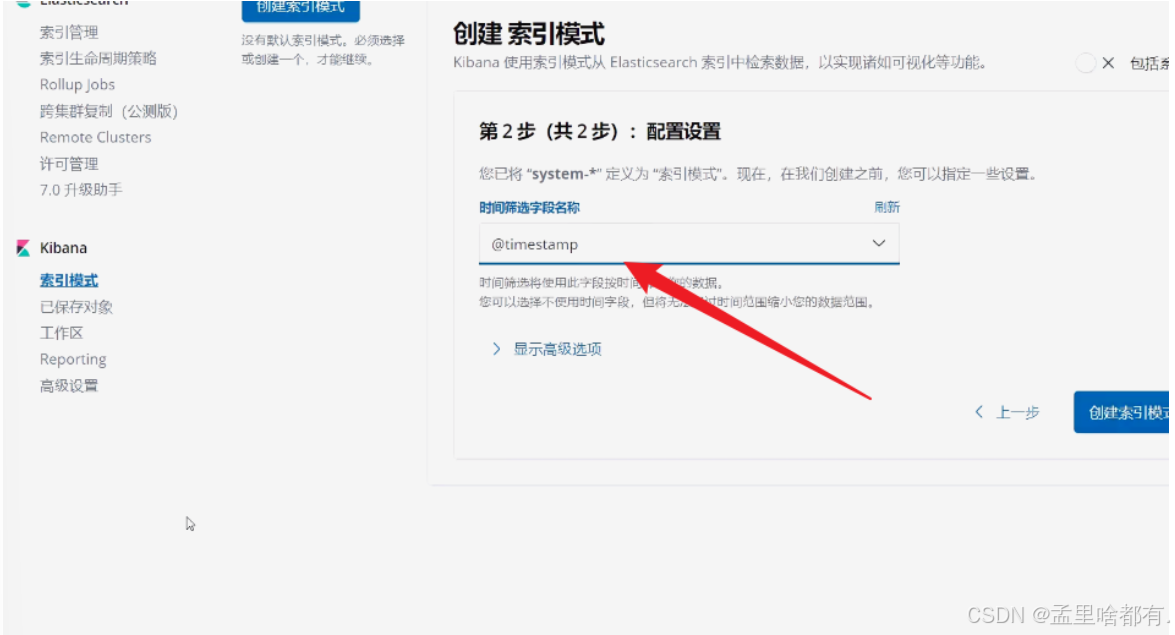
查看即可
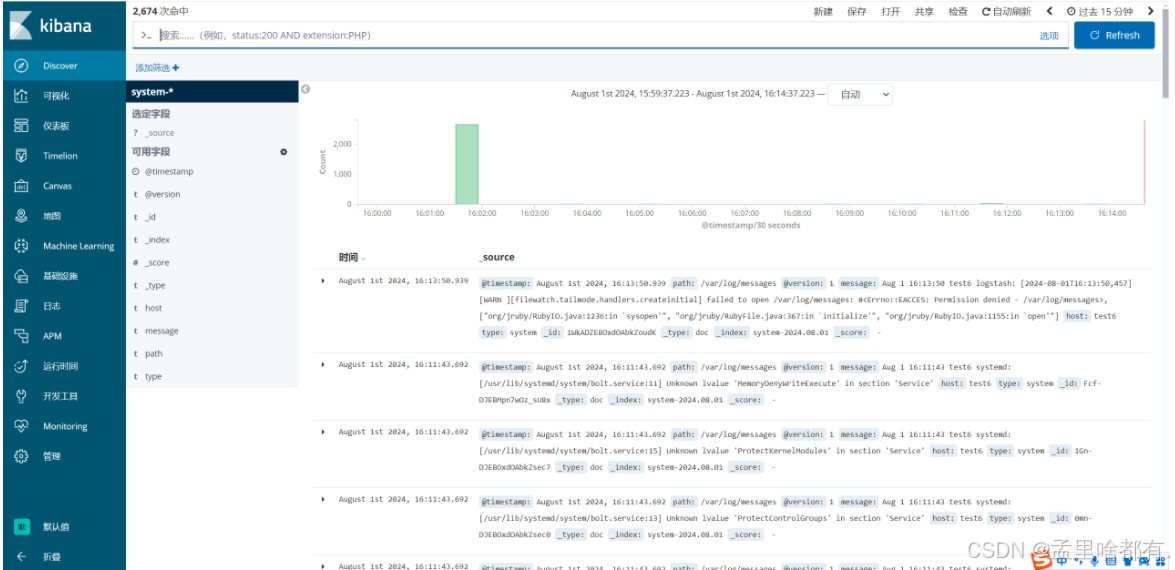
启用http
然后在网页上设置刷新时间和查看情况