写在前面
最近一段时间在看 deflicker(banding) 的相关,目前对 2023 年的文章《Blind Video Deflickering by Neural Filtering with a Flawed Atlas》比较中意,这里在翻译的同时写一些相关的理解,有错误或者不对的望指正!
翻译与理解
Abstract:
Many videos contain flickering artifacts; common causes of flicker include video processing algorithms, video gener-
ation algorithms, and capturing videos under specific situations. Prior work usually requires specific guidance such
as the flickering frequency, manual annotations, or extra consistent videos to remove the flicker. In this work, we
propose a general flicker removal framework that only receives a single flickering video as input without additional
guidance. Since it is blind to a specific flickering type or guidance, we name this “blind deflickering.” The core of
our approach is utilizing the neural atlas in cooperation with a neural filtering strategy. The neural atlas is a unified representation for all frames in a video that provides temporal consistency guidance but is flawed in many cases.
To this end, a neural network is trained to mimic a filter to learn the consistent features (e.g., color, brightness) and
avoid introducing the artifacts in the atlas. To validate our method, we construct a dataset that contains diverse real-
world flickering videos. Extensive experiments show that our method achieves satisfying deflickering performance
and even outperforms baselines that use extra guidance on a public benchmark. The source code is publicly available at
https://chenyanglei.github.io/deflicker.
翻译与理解:
许多视频包含了isp 处理中常见的 flicker(频闪)。造成flicker的原因有:
1 视频处理算法(video processing algorithms)ps: 后面作者说的processed 视频都指的是算法处理的这种
2 视频生成算法(video generation algorithms)
3 特殊拍摄的视频(capturing videos under specific situations)
先前的工作通常要求一些明确的导向信息,例如flicker的频率,人工标注 或者 额外的连续的视频进行辅助。
在本文,我们提出了一种通用的flicker去除框架,并且该框架之接受一个带有flicker的是in作为输入,不需要任何其他的辅助。 因为这个框架不需要特殊的flicker 类型的先验信息,因此我们命名“盲导 deflicker”。我们方法的核心就是利用 “网络图谱” (neural atlas)和 网络滤波 联合的测策略。 “网络图谱” (neural atlas) 是视频中所有帧的统一概括(unified representation)且这个 neural atlas 虽然可以在时域上提供连惯性指导(consistency guidance)但是对于很多情况是有缺陷的。到这里,神经网络会用来模仿(mimic)和学习视频的连惯性特征(例如颜色和亮度)避免在atlas中引入伪影。
为了验证我们的方法,我们构建了一个包含各种真实世界闪烁视频的数据集。大量实验证明,我们的方法实现了令人满意的去闪效果,甚至在公共基准测试中超过了使用额外指导的基线方法。源代码可以在https://chenyanglei.github.io/deflicker上公开获取。
————————————————————————————————————————————————————————
1. Introductio(导论)
A high-quality video is usually temporally consistent, but many videos suffer from flickering for various reasons, as shown in Figure 2. For example, the brightness of old movies can be very unstable since some old cameras cannot set the exposure time of each frame to be the same with low-quality hardware [16]. Besides, indoor lighting changes with a certain frequency (e.g., 60 Hz) and highspeed cameras with very short exposure time can capture the rapid changes of indoor lighting [25]. Effective processing algorithms such as enhancement [38, 45], colorization [29, 60], and style transfer [33] might bring flickering artifacts when applied to temporally consistent videos.Video from video generations approaches [46, 50, 61] also might contain flickering artifacts. Since temporally consistent videos are generally more visually pleasing, removing the flicker from videos is highly desirable in video processing [9, 13, 14, 54, 59] and computational photography. In this work, we are interested in a general approach for deflickering: (1) it is agnostic to the patterns or levels of flickering for various reasons (e.g., old movies, highspeed cameras, processing artifacts), (2) it only takes a single flickering video and does not require other guidances (e.g., flickering types, extra consistent videos). That is to say, this model is blind to flickering types and guidance, and we name this task as blind deflickering. Thanks to the blind property, blind deflickering has very wide applications.
翻译与理解
高质量的视频在时间上是一致的,但由于各种原因,许多视频会出现闪烁问题,如图2所示。例如,由于一些老旧相机无法将每帧的曝光时间设置为相同且硬件质量低劣,因此老电影的亮度可能非常不稳定[16]。此外,室内照明以一定频率变化(例如60 Hz),而高速相机使用非常短的曝光时间可以捕捉到室内照明的快速变化[25]。当应用于时间上一致的视频时,有效的处理算法(例如增强[38, 45]、上色[29, 60]和风格转换[33])可能会引入闪烁伪影。视频生成方法([46, 50, 61])生成的视频也可能包含闪烁伪影。由于时域上连贯性好的视频通常更具视觉吸引力,在视频处理[9, 13, 14, 54, 59]和计算摄影中体现出去除视频中的频闪在业内的强烈需求。在这项工作中,我们对于去闪的一般方法感兴趣:(1)它不依赖于各种原因导致的闪烁模式或级别(例如老电影、高速相机、处理伪影),(2)它只需要一个闪烁视频,不需要其他的指导(例如闪烁类型、额外一致的视频)。也就是说,这个模型对于闪烁类型和指导是无感的,我们将这个任务称为“盲导去频闪”(blind deflicker)。由于其盲目特性,盲目去频闪具有广泛的应用。
————————————————————————————————————————————————————————
Blind deflickering is very challenging since it is hard to enforce temporal consistency across the whole video without any extra guidance. Existing techniques usually design specific strategies for each flickering type with specific knowledge. For example, for slow-motion videos captured by high-speed cameras, prior work [25] can analyze the lighting frequency. For videos processed by image processing algorithms, blind video temporal consistency [31, 32] obtains long-term consistency by training on a temporally consistent unprocessed video. However, the flickering types or unprocessed videos are not always available, and existing flickering-specific algorithms cannot be applied in this case. One intuitive solution is to use the optical flow to track the correspondences. However, the optical flow from the flickering videos is not accurate, and the accumulated errors of
optical flow are also increasing with the number of frames due to inaccurate estimation [7].
翻译与理解
“盲导去flicker”非常具有挑战性,因为在没有任何额外指导的情况下,很难实现整个视频的时域上的连贯性。现有的技术通常针对每种flicker类型设计特定的策略,并需要具备特定的先验知识。例如,对于高速相机捕捉的慢动作视频,之前的工作[25]可以分析照明频率。对于经过图像处理算法处理的视频,为保持未知视频(blind video)时域上的连贯性,在[31, 32]中的方法通过在时间上一致的未处理视频上进行训练来获得长期连贯性。然而,flicker类型或未处理视频并不总是可用的,而且现有的针对特定flicker的算法无法在这种情况下应用。一种直观的解决方案是使用光流来跟踪对应关系。然而,闪烁视频中的光流并不准确,并且由于估计不准确,光流的累积误差也随着帧数的增加而增加[7]。
————————————————————————————————————————————————————————
With two key observations and designs, we successfully propose the first approach for the new problem blind deflickering that can be used to remove various types of flickering artifacts without extra guidance or prior knowledge of flickering.
First, we utilize a unified video representation named neural atlas [26] to solve the major challenge of solving long-term inconsistency. This neural atlas tracks all pixels in the video, and correspondences in different frames share the same pixel in this atlas. Hence, a sequence of consistent frames can be obtained by sampling from the shared atlas.
Secondly, while the frames from the shared atlas are consistent, the structures of images are flawed: the neural atlas cannot easily model dynamic objects with large motion; the optical flow used to construct the atlas is not perfect.
Hence, we propose a neural filtering strategy to take the treasure and throw the trash from the flawed atlas. A neural network is trained to learn the invariant under two types of distortion, which mimics the artifacts in the atlas and the flicker in the video, respectively. At test time, this network works well as a filter to preserve the consistency property and block the artifacts from the flawed atlas.
翻译与理解
在两个关键的观察结论和设计的帮助下,我们成功提出了第一种除未知flicker的方法并且该方法可以在没有多于引导信息和先验知识的情况下去除多种类型的flicker。
首先,我们利用一种名为“网络图谱”(neural atlas)的“整体视频表达”(unified video representation)[26]来解决解决长期不一致性的主要挑战。这个“网络图谱”跟踪视频中的所有像素,并且不同帧之间的对应关系在这个图谱中共享相同的像素。因此,通过从共享的图谱中进行采样,可以获得一系列连贯的帧。
其次,虽然来自共享图谱的帧是连贯的,但图像的结构是有缺陷的:网络图谱不能轻易地建模具有大运动(large motion)的动态对象;同时常用的光流在处理构建“全图”(atlas)也不完美。
因此,我们提出了一种神经滤波策略,从有缺陷的图谱中提取关键信息并且将错误信息从带有缺陷的“网络图谱”去除(这里用的是atlas 其实就是指 nerual atlas)。我们训练了一个神经网络来学习两种类型的失真下的不变性:
1模拟了图谱中的伪影(artifacts)
2 视频中的闪烁。
在测试时,这个网络可以作为一个滤波器,有效地保留一致性特性并阻止有缺陷的图谱中的伪影。
————————————————————————————————————————————————————————
We construct the first dataset containing various types of flickering videos to evaluate the performance of blind
deflickering methods faithfully. Extensive experimental re sults show the effectiveness of our approach in handling different flicker. Our approach also outperforms blind video temporal consistency methods that use an extra input video
as guidance on a public benchmark. Our contributions can be summarized as follows:
• We formulate the problem of blind deflickering and construct a deflickering dataset containing diverse flickering videos for further study.
• We propose a blind deflickering approach that can remove diverse flicker. We introduce the neural atlas to the deflickering problem and design a dedicated strategy to filter the flawed atlas for satisfying deflickering performance.
• Our method outperforms baselines on our dataset and even outperforms methods that use extra input videos on a public benchmark.
翻译与理解
我们构建了第一个包含各种类型flicker视频的数据集,以忠实地评估“盲导去flicker”方法的性能。大量的实验结果表明了我们方法在处理不同闪烁方面的是有效的。我们的方法在公共基准测试中也超过了使用额外输入视频作为指导的盲目视频时间一致性方法。我们的贡献可以总结如下:
• 我们对“盲导去flicker”问题进行了明确表述,并构建了一个包含多种闪烁视频的除闪数据集,以进行进一步研究。
• 我们提出了一种可以去除各种闪烁的盲目除闪方法。我们引入了“网络图谱”(neural atlas)来解决除闪问题,并设计了一种专门的策略来过滤有缺陷的图谱,以实现令人满意的除闪性能。
• 我们的方法在我们的数据集上表现优于基线方法,甚至超过了在公共基准测试中使用额外输入视频的方法。
————————————————————————————————————————————————————————
2.Related Work(这里我主要采用软件翻译,因为我们了解行业现状就可以)
Task-specific deflikcering. Different strategies are designed for specific flickering types. Kanj et al. [25] propose a strategy for high-speed cameras. Delon et al. [16]present a method for local contrast correction, which can be utilized for old movies and biological film sequences.Xu et al. [56] focus on temporal flickering artifacts from GAN-based editing. Videos processed by a specific imageto-image translation algorithm [6, 18, 24, 30, 33, 41, 60, 62] can suffer from flickering artifacts and blind video temporal consistency [7, 27, 28, 31, 32, 57] is designed to remove the flicker for these processed videos. These approaches are blind to a specific image processing algorithm. However, the temporal consistency of generated frames is guided by a temporal consistent unprocessed video. Bonneel et al. [7] compute the gradient of input frames as guidance. Lai etal. [27] input two consecutive input frames as guidance. Lei et al. [31] directly learn the mapping function between input and processed frames. While these approaches achieve satisfying performance on many tasks, a temporally consistent video is not always available. For example, for many flickering videos such as old movies and synthesized videos from video generation methods [19, 50, 61], the original videos are temporal inconsistent. A concurrent preprint [2] attempts to eliminate the need for unprocessed videos during inference. Nonetheless, it still relies on optical flow for local temporal consistency and does not study other types of flickering videos. Our approach has a wider application compared with blind temporal consistency.
翻译与理解
针对不同的类型的flicker,设计了特定的策略进行任务特定的去频闪处理。Kanj等人[25]提出了针对高速相机的策略。Delon等人[16]提出了一种用于局部对比度修正的方法,可用于老电影和生物片段。Xu等人[56]专注于基于GAN网络的编辑中的时间闪烁伪影。经过特定图像到图像转换算法处理的视频[6, 18, 24, 30, 33, 41, 60, 62]可能会出现闪烁伪影,而无视flicker视频(blind video,我这里翻译为了无视)时域上的一致性[7, 27, 28, 31, 32, 57]被设计去除这些处理(processed 我认为作者指经过算法或者某些过程的意思)视频的flicker。这些方法对于特定的图像处理算法是无感的(blind 我翻译为无感,我认为是7,27,28,31等 这些方法可以对不同flicker 无感)的。然而,生成帧的时域的一致性是由一个时域上连贯的未处理视频(unprocessed video)引导的。Bonneel等人[7]使用输入帧的梯度作为引导。Lai等人[27]将连续的两个输入帧作为引导。Lei等人[31]直接学习输入帧和处理后帧之间的映射函数。虽然这些方法在许多任务上取得了令人满意的性能,但并不能处理时域上连续的的视频。例如,对于许多闪烁视频,如老电影和通过视频生成方法生成的合成视频[19, 50, 61],原始视频在时间上是不一致的。一份同时期的预印本[2]试图在推理过程中消除对未处理视频的需求。尽管如此,它仍然依赖光流进行局部时间一致性,并且不研究其他类型的闪烁视频。与无视(blind)时域连贯性的方法相比,我们的方法具有更广泛的应用
————————————————————————————————————————————————————————
Also, some commercial software [3, 47] can be used for deflickering by integrating various task-specific deflickering approaches. However, these approaches require users to have a knowledge background of the flickering types. Our approach aims to remove this requirement so that more videos can be processed efficiently for most users. Video mosaics and neural atlas. Inheriting from panoramic image stitching [8], video mosaicing is a technique that organizes video data into a compact mosaic representation, especially for dynamic scenes. It supports various applications, including video compression [23], video indexing [22], video texture [1], 2D to 3D conversion [48, 49], and video editing [44]. Building video mosaics based on homography warping often fails to depict motions. To handle the dynamic contents, researchers compose foreground and background regions by spatiotemporal masks [15], or blend the video into a multi-scale tapestry in a patch-based manner [5]. However, these approaches heavily rely on image appearance information and thus are sensitive to lighting changes and other flicker.
翻译与理解
此外,一些商业软件[3, 47]可以通过整合各种任务特定的去闪处理方法来进行去闪处理。然而,这些方法要求用户具有对flicker类型的知识背景。我们的方法旨在消除这种要求,以便更多的视频可以被大多数用户高效处理。视频镶嵌和网络图谱。视频镶嵌继承自全景图像拼接[8],是一种将视频数据组织成紧凑镶嵌表示的技术,尤其适用于动态场景。它支持各种应用,包括视频压缩[23]、视频索引[22]、视频纹理[1]、2D到3D转换[48, 49]和视频编辑[44]。基于单应性变换构建视频镶嵌通常无法描绘动态内容。为了处理动态内容,研究人员通过时空掩码[15]组合前景和背景区域,或者以基于补丁的方式将视频融合成多尺度的织锦[5]。然而,这些方法严重依赖图像外观信息,因此对光照变化和其他flicker非常敏感
————————————————————————————————————————————————————————
Recently, aiming for consistent video editing, Kasten etal. [26] propose Neural Layered Atlas (NLA), which decomposes a video into a set of atlases by learning mapping networks between atlases and video frames. Editing on the atlas and then reconstructing frames from the atlas can achieve consistent video editing. Follow-up work validates its power on text-driven video stylization [4, 37] and face video editing [36]. Directly adopting NLA to blind deflickering tasks is not trivial and is mainly limited by two-fold: (i) its performance on the complex scene is still not satisfying with notable artifacts. (ii) it requires segmentation masks as guidance for decomposing dynamic objects, and each dynamic object requires an additional mapping network. To facilitate automatic deflickering, we use a singlelayered atlas without the need for segmentation masks by designing an effective neural filtering strategy for the flawed atlas. Our proposed strategy is also compatible with other atlas generation techniques.
翻译与理解
最近,针对一致的视频编辑,Kasten等人提出了神经层级图谱(Neural Layered Atlas,NLA)[26],它通过学习图谱与视频帧之间的映射网络,将视频分解为一组图谱。在图谱上进行编辑,然后从图谱中重构帧可以实现一致的视频编辑。后续工作验证了其在基于文本驱动的视频风格化[4, 37]和人脸视频编辑[36]方面的能力。直接将NLA应用于盲目去闪任务并不容易,主要存在两个限制:
(i) 在复杂场景中的性能仍然不理想,存在明显的伪影。
(ii) 它需要分割掩码作为分解动态对象的指导,并且每个动态对象需要额外的映射网络。
为了便于自动去闪,我们使用单层图谱而无需分割掩码,通过为有缺陷的图谱设计一种有效的神经滤波策略。我们提出的策略还与其他图谱生成技术兼容
Implicit image/video representations. With the success of using the multi-layer perceptron (MLP) as a continuous implicit representation for 3D geometry [39, 40, 42], such representation has gained popularity for representing images and videos [10, 34, 51, 52]. Follow-up work extends these models to various tasks, such as image superresolution [12], video decomposition [58], and semantic segmentation [21]. In our work, we follow [26] to employ a coordinate-based MLP to represent the neural atlases.
随着使用多层感知器(MLP)作为三维几何的连续隐式表示的成功[39, 40, 42],这种表示方式在表示图像和视频方面变得流行起来[10, 34, 51, 52]。后续的工作将这些模型扩展到各种任务,如图像超分辨率[12]、视频分解[58]和语义分割[21]。在我们的工作中,我们遵循[26]的方法,使用基于坐标的MLP来表示神经图谱。
》》》》》 注意:这里 [26]将是后面工作的重点work!
————————————————————————————————————————————————————————
3. Method
3.1. Overview(因为部分公式格式乱掉,我这里用截图)
Let {It}T,t=1 be the input video sequences with flickering artifacts where T is the number of video frames. Our approach aims to remove the flickering artifacts to generate a temporally consistent video {Ot}T,t=1. Flicker denotes a type of temporal inconsistency that correspondences in different frames share different features (e.g., color or brightness). The flicker can be either global or local in the spatial dimension, either long-term or short-term in the temporal dimension. Figure 3 shows the framework of our approach. We tackle the challenges in blind deflickering through the following key designs: (i) We first propose to use a single neural atlas (Section 3.2) for the deflickering task. (ii) We design a neural filtering (Section 3.3) strategy for the neural atlas as the single atlas is inevitably flawed.
翻译与理解
我们的方法旨在去除具有闪烁伪影的输入视频序列 {It}T t=1,其中 T 是视频帧数。我们的方法旨在去除闪烁伪影,生成一个在时间上连续的视频 {Ot}T t=1。闪烁表示一种时间上的不一致性,不同帧之间的对应关系具有不同的特征(例如颜色或亮度)。闪烁可以是空间维度上的全局或局部的,也可以是时间维度上的长期或短期的。
图3展示了我们方法的框架。我们通过以下关键设计来解决盲目去闪烁的挑战:
(i)我们首先提出使用单个神经图谱(第3.2节)进行去闪烁任务。
(ii)我们为神经图谱设计了神经过滤策略(第3.3节),因为单个图谱不可避免地存在缺陷。
————————————————————————————————————————————————————————
3.2. Flawed Atlas Generation
Motivation. A good blind deflickering model should have the capacity to track correspondences across all the video
frames. Most architecture in video processing can only take a small number of frames as input, which results in a limited
receptive field and is insufficient for long-term consistency. To this end, we introduce neural atlases [26] to the deflickering task as we observe it perfectly fits this task. A neural atlas is a unified and concise representation of all the pixels
in a video. As shown in Figure 3(a), let p = (x, y, t) ∈ R^3 be a pixel that locates at (x, y) in frame It. Each pixel p is fed into a mapping network M that predicts a 2D coordinate (up, vp) representing the corresponding position of the pixel in the atlas. Ideally, the correspondences in different frames should share a pixel in the atlas, even if the color of the input pixel is different. That is to say, temporal consistency is ensured.
翻译与理解
动机:一个好的盲导deflicker模型应该具备跟踪整个视频序列中的对应关系的能力。大多数视频处理的架构只能接受少量帧作为输入,这导致感受野有限,对于长时间一致性性来说是不足够的。为了达到这个目标,我们引入网络图谱 [26] 到去闪烁任务中,因为我们观察到它完美地适用于这个任务。网络图谱是视频中所有像素的统一而简洁的表示。如图3(a)所示,假设 p = (x, y, t) ∈ R3 是位于帧 It 中坐标为 (x, y) 的像素。每个像素 p 被输入到一个映射网络 M 中,预测出一个二维坐标 (up, vp),表示在图谱中对应像素的位置。理想情况下,不同帧中的对应关系应该在图谱中共享一个像素,即使输入像素的颜色不同。这样可以确保时间上的一致性。
————————————————————————————————————————————————————————
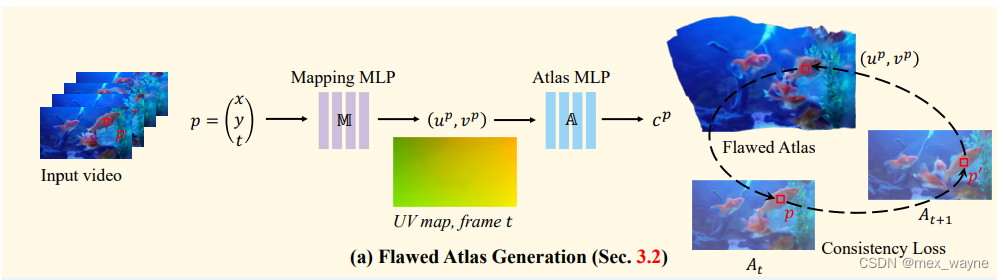
Training. Figure 3(a) shows the pipeline to generate the
atlas. For each pixel p, we have:
The 2D coordinate (up, vp) is fed into an atlas network A with positional encoding function ϕ(·) to estimate the RGB
color cp for the pixel. The mapping network M and the atlas network A are trained jointly by optimizing the loss
between the original RGB color and the predicted color cp. Besides the reconstruction term, a consistency loss is also
employed to encourage the corresponding pixels in different frames to be mapped to the same atlas position. We follow
the implementation of loss functions in [26]. After training the networks M and A, we can reconstruct the videos {At}T,t=1 by providing all the coordinates of pixels in the whole video. The reconstructed atlas-based video {At}T,t=1 is temporally consistent as all the pixels are mapped from a single atlas. In this work, we utilize the temporal consistency property of this video for blind deflickering.
翻译与理解
训练:图3(a)表示了产生网络图谱的过程。对于me各个像素p,我们有:
2D坐标(up,vp)是用坐标级的编码函数ϕ(·) 的图谱网络 A 来估计像素的 RGB 颜色 cp。映射网络 M 和图谱网络 A 通过优化原始 RGB 颜色和预测颜色 cp 之间的损失进行联合训练。除了重构项之外,还使用一致性损失来鼓励不同帧中的对应像素映射到相同的图谱位置。我们遵循[26]中的损失函数的实现方式。在训练网络 M 和 A 后,通过提供整个视频中像素的所有坐标,我们可以重构视频 {At}T,t=1(原文那种太难写了,我用这个替代)。重构的基于图谱的视频 {At}T,t=1 具有时域上的一致性,因为所有的像素都映射自同一个网络图谱。在这项工作中,我们利用这个视频的时域一致性特性来进行无视flicker的deflicker 过程。
注:
这里根据本人尝试,altlas 可以完成 视频频闪
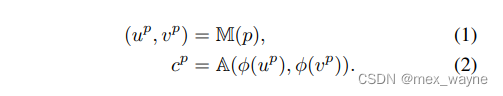
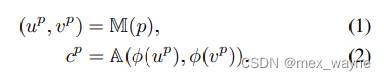
Winter_Scenes_in_Holland_atlas
但是 atlas 会存在 扭曲,所以还需要一个 Neural Filtering 进行处理
————————————————————————————————————————————————————————
Considering the trade-off between performance and efficiency, we only use a single-layer atlas to represent the whole video, although using two layers (background layer and foreground layer) or multiple layers of atlases might slightly improve the performance. First, in practice, we notice the number of layers is quite different, which varies from a single layer to multiple layers (more than two), making it challenging to apply them to diverse videos automatically. Besides, we notice that artifacts and distortion are inevitable for many scenes, as discussed in [26]. We discuss how to treat the artifacts in the flawed atlas with the
following network designs in Secion 3.3.
翻译与理解
考虑到性能和效率之间的权衡,尽管使用两层(背景层和前景层)或多层图谱可能会略微提高性能,但我们只使用单层图谱来表示整个视频。首先,在实践中,我们注意到从单层到多层(超过两层)变化时,不同层数的结果是非常不同的,这些不同结果使得将它们自动应用于各种视频变得具有挑战性。此外,我们注意到许多场景中不可避免地会出现伪影和失真,正如[26]中所讨论的
那样。在第3.3节中,我们将讨论如何使用以下网络设计来处理有缺陷的图谱中的伪影。
————————————————————————————————————————————————————————
3.3. Neural Filtering and Refinement
Motivation. The neural atlas contains not only the treasure but also the trash. In Section 3.2, we argue that an atlas is a strong tool for blind deflickering since it can provide consistent guidance across the whole video. However, the reconstructed frames from the atlas are flawed. First, as analyzed in NLA [26], it cannot performs well when the Motivation. The neural atlas contains not only the treasure but also the trash. In Section 3.2, we argue that an atlas is a strong tool for blind deflickering since it can provide consistent guidance across the whole video. However, the reconstructed frames from the atlas are flawed. First, as analyzed in NLA [26], it cannot performs well when the object is moving rapidly, or multiple layers might be required for multiple objects. For blind deflickering, we need to remove the flickering and avoid introducing new artifacts. Secondly, the optical flow obtained by the flickering video is not accurate, which leads to more flaws in the atlas. At last, there are still some natural changes, such as shadow changes, and we hope to preserve the patterns.
翻译与理解
动机:神经图谱中既包含关键信息(treasure)又包含错误信息(trash)。在第3.2节中,我们认为网络图谱是盲导去flicker的强大工具,因为它可以在整个视频中提供一致的指导。然而,通过网络图谱(atlas)重建的视频帧的过程存在缺陷。首先,如NLA [26]中所分析的,当物体移动迅速时,图谱的表现不佳,或者需要为多个物体使用多个图层。对于盲导deflicker,我们需要消除频闪并避免引入新的伪影。其次,通过闪烁视频获得的光流不准确,这导致图谱中存在更多缺陷。最后,仍然存在一些自然变化,例如阴影变化,我们希望保留这些模式。
————————————————————————————————————————————————————————
Hence, we design a neural filtering strategy that utilizes the promising temporal consistency property of the atlasbased video and prevents the artifacts from destroying our output videos.
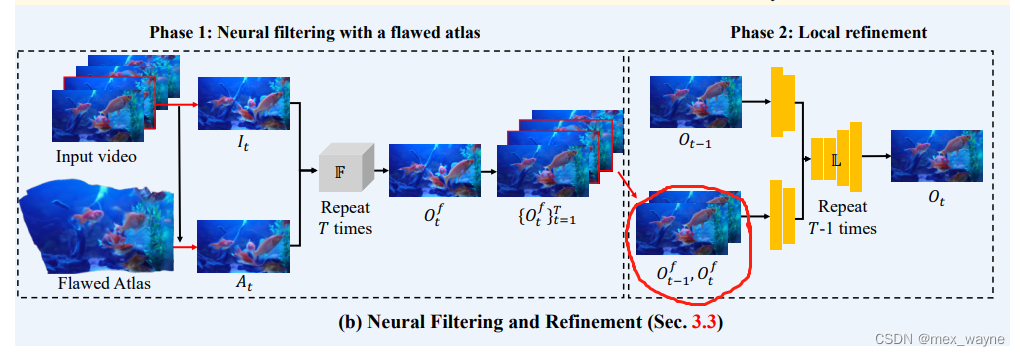
Training Strategy. Figure 3(b) shows the framework to use the atlas. Given an input video {It}T,t=1 and an atlas A,
in every iteration, we get one frame It from the video and input it to the filter network F:
where At is obtained by fetching pixels from the shared atlas A with the coordinates of It.
We design a dedicated training strategy for the flawed atlas, as shown in Figure 4. We train the network using only a
single image X instead of consecutive frames. In the training time, we apply a transformation τa(·) to distort the appearance, including color, saturation, and brightness of the image, which mimics the flickering pattern in It. We apply another the L2 loss function L between prediction F(τa(X), τs(X)) and the clean ground truth X (i.e., the image before augmentation):where θF is the parameters of filtering network F.transformation τs(·) to distort the structures of the image, mimicking the distortion of a flawed atlas-based frame in At. At last, the network is trained by minimizing
翻译与理解
因此,我们设计了神经网络滤波策略,该策略可以利用网络图谱在时域连较好的贯性这一特证同时还能防止伪影出现在我们的输出视频中。
训练策略:图3(b) 展示了我们怎么使用网络图谱,给定输入视频{It}T,t=1和一个图谱A,在每次迭代中,我们从视频中获取一个帧It并将其输入到滤波网络F中:
图3(b)
其中:At是通过使用It的坐标从共享的图谱A中提取像素得到的。我们为有缺陷的图谱设计了专门的训练策略,如下图4所示。
图4 (神经网络滤波策略的训练流图。我们的训练数据是将干净图的图片上加载两种变换来模仿在去flicker时输入帧和有缺陷的atlas帧)
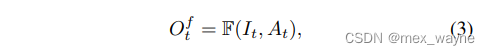
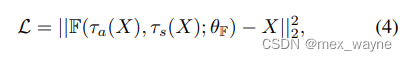

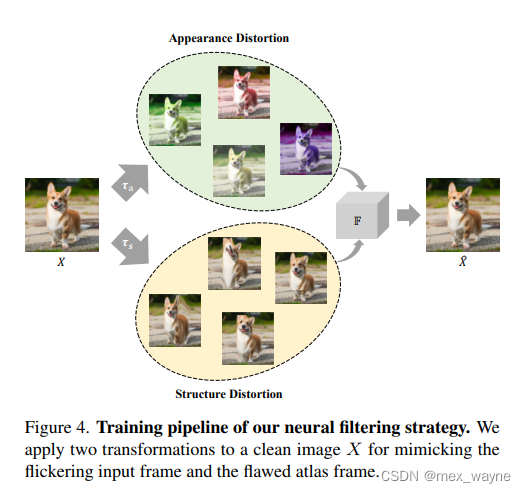
我们仅使用单个图像X而不是连续的帧来训练网络。在训练过程中,我们应用变换τa(·)来扭曲图像的外观,包括颜色、饱和度和亮度,这模拟了It中的闪烁模式。我们应用另一个变换τs(·)来扭曲图像的结构,模拟有缺陷的基于图谱的帧At的扭曲。最后,网络通过最小化预测值F(τa(X), τs(X))与干净的真实图像X(即增强之前的图像)之间的L2损失函数L来进行训练:
其中, θF是框架F的参数.
注意:
phase1 完成了 解 扭曲和 错误颜色
phase2 是作者发现phase 还有一些局部的flicker 没有解干净,加了个带lstm 的 unet
左图为原图输入,中间是stage1 的atlas 结果,有图是 stage2 额结果
其中,还要注意的是作者在训练代码中用了 vgg用来学习特征迁移,是个不错的 训练方法
本人尝试了将lstm+unet 的网络抠出来,单独训练,发现如不能解有些局部flicker,文中作者提出的局部flicker 其实是一种风格迁移,和真正ISP的局部flicker 还有差别





————————————————————————————————————————————————————————
The network tends to learn the invariant part from two distorted views respectively. Specifically, F learns the structures from the input frame It and the appearance (e.g., brightness, color) from the atlas frame At as they are invariant to the structure distortion τs. At the same time, the distortion of τs(X) would not be passed through the network F. With this strategy, we achieve the goal of neural filtering with the flawed atlas.
翻译与理解
网络F倾向于从两个扭曲的视图中学习不变部分。具体来说,F从输入帧It中学习结构,从图谱帧At中学习外观(如亮度、颜色),因为它们对结构扭曲τs是不变的。同时,τs(X)的扭曲不会通过网络F传递。通过这种策略,我们实现用神经网络滤波处理有缺陷的网络图谱。
————————————————————————————————————————————————————————
Note that while this network F only receives one frame, long-term consistency can be enforced since the temporal information is encoded in the atlas-based frame At.
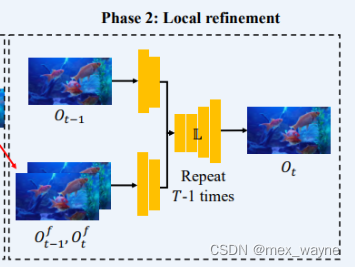
Local refinement.
The video frames {Oft }Tt=1 are consistent with each other globally in both the short term and the long term. However, it might contain local flicker due to the misalignment between input and atlas-based frames. Hence, we use an extra local deflickering network to refine the results further. Prior work has shown that local flicker can be well addressed by a flow-based regularization. Hence, we choose a lightweight pipeline [27] with modification. As shown in Figure 3(b), we predict the output frame Ot by providing two consecutive frames Oft, Oft−1 and previous output Ot−1 to our local refinement networkL. Two consecutive frames are firstly followed by a few convolution layers and then fused with the Ot−1. The local flickering network is trained with a simple temporal consistency loss Llocal to remove local flickering artifacts:
翻译与理解
要注意的是虽然网络F只接收一个帧,但由于时域信息(temproal information)编码(encoded)在网络图谱的帧At中 因此长时间的连贯性是可以被网络获得的(enforced,这里我采取了意义加了自己的理解)。
局部精细训练。
视频帧{Oft}Tt=1在短期和长期内彼此之间是一致的。然而,由于输入和基于图谱的帧之间的不对齐,它可能包含局部闪烁。因此,我们使用额外的局部去闪烁网络进一步优化结果。先前的工作表明,基于流的正则化可以很好地解决局部闪烁问题。因此,我们选择了一个轻量级的流程[27]并进行了修改。如图3(b)所示,我们通过提供两个连续帧Oft、Oft−1和上一个输出帧Ot−1给我们的局部优化网络L来预测输出帧Ot。首先对两个连续帧进行几个卷积层处理,然后与Ot−1融合。局部闪烁网络使用简单的时间一致性损失“Llocal”进行训练,以去除局部闪烁伪影。
图3(b)
————————————————————————————————————————————————————————
where Oˆt−1 is obtained by warping the Ot−1 with the optical flow from frame t to frame t − 1. Mt,t−1 is the corresponding occlusion mask. For the frames without local artifacts, the output should Ot be the same as Oft. Hence, we also provide a reconstruction loss by minimizing the distance between Ot and Oft to regularize the quality.
Implementation details.
The network F is trained on the MS-COCO dataset [35] as we only need images for training. We train it for 20 epochs with a batch size of 8. For the network L, we train it on the DAVIS dataset [43] for 50 epochs with a batch size of 8. We adopt the Adam optimizer and set the learning rate to 0.0001. We notice train.
翻译与理解
其中,Oˆt−1通过使用从帧t到帧t−1的光流对Ot−1进行变形获得。Mt,t−1是相应的遮挡掩模。对于没有局部伪影的帧,输出应该与Oft相同。因此,我们还通过最小化Ot和Oft之间的距离来提供重构损失以规范质量。
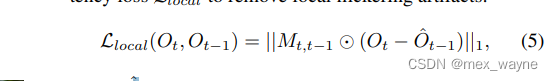
实现细节。
网络F在MS-COCO数据集[35]上进行训练,因为我们只需要图像进行训练。我们使用批量大小为8,在20个周期内对其进行训练。对于网络L,我们在DAVIS数据集[43]上进行了50个周期的训练,批量大小为8。我们采用Adam优化器,并将学习率设置为0.0001。我们注意到train。
————————————————————————————————————————————————————————
4. Blind Deflickering Dataset.
We construct the first publicly available dataset for blind deflickering. Real-world data. We first collect real-world videos that contain various types of flickering artifacts. Specifically, we collect five types of real-world flickering videos:
(1) Old movies contain complicated flickering patterns. The flickering is caused by multiple reasons, including unstable exposure time, grading of film materials, and so on. Hence, the flickering can be high-frequency or low-frequency, globally and locally.
(2)Old cartoons are similar to old movies, but the structures are very different from natural videos.
(3)Time-lapse videos capture a scene for a long time, and the environment illumination usually changes a lot.
(4)Slow-motion videos can capture high-frequency changes in lighting.
(5) Processed videos denote the videos processed by various types of processing algorithms. The patterns of videos are usually decided by the specific algorithm. We follow the setting in [27].
Synthetic data. While real-world videos are good for evaluating perceptual performance, they do not have ground truth for quantitative evaluation. Hence, we create synthetic dataset that provides ground truth for quantitative analysis. Let {Gt}Tt=1 be the clean video frames, the flickered video{Gt}Tt=1 can be obtained by adding the flickering artifactsFt for each frame at time t:
where {Ft}Tt=1 is the synthesized flickering artifacts. For the temporal dimension, we synthesize short-term flickering images and their difference maps are placed at the third column. and long-term flickering. Specifically, we set a window size W, which denotes the number of frames that share the same flickering artifacts. Summary. We provide 20, 10, 10, 10, 157, and 90 for old movies, old cartoons, slow-motion videos, time-lapse videos, processed videos, and synthetic videos.
翻译与理解
我们构建了第一个公开可用的盲去闪烁数据集。真实世界数据。首先,我们收集了包含各种类型闪烁伪影的真实世界视频。具体而言,我们收集了五种类型的真实世界闪烁视频:
(1)旧电影包含复杂的闪烁模式。闪烁是由多种原因引起的,包括曝光时间不稳定、电影材料分级等。因此,闪烁可以是高频或低频的,在全局和局部上都存在。
(2)旧卡通片与旧电影类似,但结构与自然视频非常不同。
(3)延时摄影视频长时间捕捉场景,环境照明通常会发生很大变化。
(4)慢动作视频可以捕捉到光照的高频变化。
(5)经过处理的视频表示经过各种处理算法处理过的视频。视频的模式通常由特定算法决定。我们遵循[27]中的设置。
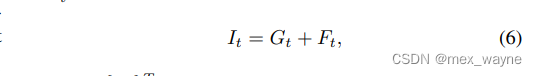
合成数据。虽然真实世界视频适合评估感知性能,但它们没有用于定量评估的准确标准。因此,我们创建了合成数据集,为定量分析提供了准确标准。令{Gt}Tt=1为清晰的视频帧,通过为每一帧的时间t添加闪烁伪影Ft,可以获得闪烁视频{Gt}Tt=1:
(其实这里说白了就是往真实的视频上加闪烁)
公式(6)
其中{Ft}Tt=1是合成的闪烁伪影。对于时间维度,我们合成了短期闪烁图像,并将它们的差异图放置在第三列,以及长期闪烁。具体而言,我们设置了一个窗口大小W,表示共享相同闪烁伪影的帧数。总结一下。对于旧电影、旧卡通片、慢动作视频、延时摄影视频、经过处理的视频和合成视频,我们提供了20、10、10、10、157和90个样本。
后面的翻译就省略了
————————————————————————————————————————————————————