
编者按:在视频物体检测任务中,由于相机失焦、物体遮挡等问题,仅基于图像的目标检测器很可能达不到令人满意的效果。针对此类问题,微软亚洲研究院提出了基于记忆增强的全局-局部整合网络(Memory Enhanced Global-Local Aggregation, MEGA),它可以在只增加非常小的计算开销的前提下,整合大量的全局信息和局部信息来辅助关键帧的检测,从而显著地提升了视频物体检测器的性能。在广泛使用的 ImageNet VID 数据集中,此方法达到了截至目前的最好结果。
视频物体检测(video object detection),即在一段视频中检测出每一帧上的所有物体。相对于在静止的图像中寻找物体而言,在一段视频中找到物体会面临更多的困难:物体可能会遭遇相机失焦,物体遮挡等问题(图1),因此如果只是简单地将一个图像检测器用于视频检测,效果通常是不尽如人意的。

图1:视频中一些常见的问题
但反过来,在视频中检测物体意味着我们可以利用时序上的相关性来辅助我们进行检测:人们可以根据一些历史信息(比如说位置信息、语义信息),来判断这个被遮挡的物体是什么。因此在视频物体检测中,如何利用好时序信息来辅助质量比较差的帧上的检测是一个重要的研究方向。
一般来说,人类主要会通过两类信息来辅助对质量较差的帧进行物体检测,即局部定位信息与全局语义信息。
如果物体在当前帧中难以定位,我们可以通过相邻帧之中的类似物体或帧的差异来辅助定位,我们称之为局部定位信息。
如果我们难以判断这一帧的物体的类别,我们可以通过从任意其他帧中找出与当前的模糊物体具有高度相似性(比如说颜色、形状很像)的物体来辅助定位,此类信息被定义为全局语义信息。具体如下图2所示。

图2:人类可以利用的信息规模
从这个角度出发,我们发现目前的视频物体检测方法都仅单独考虑了其中一种信息进行辅助目标检测,虽然它们各自都取得了不错的效果,但是如果能够设计一种更加高效的信息融合方式来同时利用好两类信息,那么模型的表现应该能够更加出色。
除此之外,另一个在现存方法中存在的问题就是整合规模(aggregation scale),也就是关键帧能够使用信息的范围。因为计算资源的限制,不管是局部类还是全局类的方法,他们使用的帧的数量通常都只有20-30帧,换算成秒也就是1-2秒,整合规模的不足也局限了这些方法的有效性。

解决方案
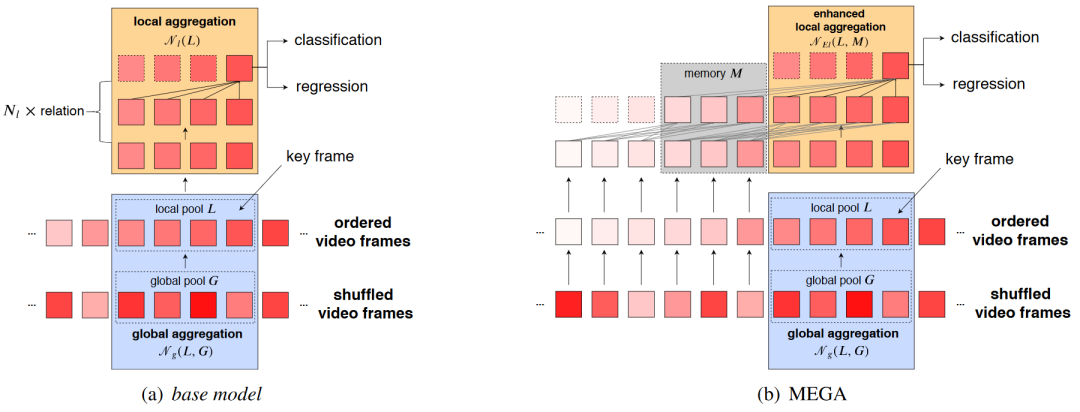
图3:模型结构示意图
我们分两步来解决上文提到的两个问题。
第一步:解决全局信息和局部信息单独考虑的问题。我们设计了简洁的基础模型(图3a)来完成这项任务。
首先,我们使用区域候选网络从关键帧的相邻帧和全局帧中生成一些候选区域。
第二是使用关联模块(relation module)将全局帧中候选区域对应的特征给整合到局部帧的候选区域的特征中。
之后,局部帧内部会再过若干层关联模块得到增强后的关键帧特征。由此,我们的关键帧特征就同时得到了全局和局部两方面的信息。
第二步:解决整合规模太小的问题。如果只有基础模型,我们关键帧能够得到的全局和局部信息仍然很少,以图3a为例,全局和局部信息都只有4帧。
为了解决这个问题,我们设计了一个简洁高效的长时记忆模块(Long Range Memory,LRM),在做完对某一帧的检测后将其特征保存下来,并在下一帧的检测中使用该特征来辅助检测,由于关系模块的多层结构,可以极大地增加了关键帧能够看到的范围,以图3b为例,我们保留了长度为3帧的记忆,而由于其具有两层的关系模块,使得其整合规模从之前的8帧增长到20帧。
不仅如此,这两部分结构还互相受益:长时记忆模块使得关键帧能够获得更多的全局和局部信息,反过来,这些帧又能够提供更加强大的记忆。
实验结果
我们在广泛使用的视频物体检测数据集 ImageNet VID 上对我们的方法进行了实验,表1总结了我们的方法与其他方法相比的表现。在本文新提出的模块的辅助下,我们训练出来的视频物体检测器取得了在该数据集上的至今最佳结果。
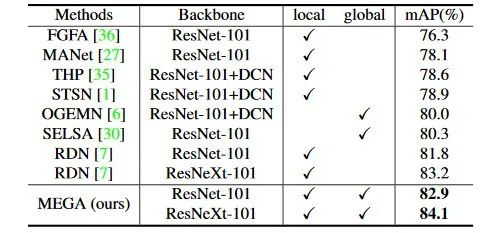
表1:总体实验结果
为了验证我们方法的有效性,我们做了充足的消融实验。表2展示了我们的模型中各个模块的作用,表3展示了全局信息和局部信息两个缺一不可,表4则说明了超参数对模型整体表现的影响。

表2:各个模块的作用
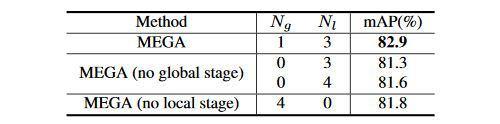
表3:全局信息与局部信息的作用

表4:超参数的设置
图4是模型的一些可视化结果。可以看到我们的方法能够克服许多困难的情形,得出不错的检测结果。

图4:可视化结果
结语
在本文中,我们提出了基于记忆增强的全局-局部整合网络(MEGA),它从全局和局部两方面出发,共同解决视频物体检测的问题。
首先, 我们将全局特征整合到局部特征中,以解决无效的问题。
之后,我们引入了新的长时记忆模块(Long Range Memory, LRM)来解决整合规模太小的问题。在视频物体检测数据集 ImageNet VID 上进行的实验表明,我们的方法取得了在该数据集上的至今最佳结果。
更多细节请参考原文:
https://arxiv.org/abs/2003.12063
代码请参考:
https://github.com/Scalsol/mega.pytorch
END

备注:目标检测

目标检测交流群
2D、3D目标检测等最新资讯,若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到
