
揭秘英伟达H20:核心价值和高效运用的双重解读
2023年,ChatGPT的问世引爆了AIGC领域。在这场"百模大战"中,国内外头部企业纷纷以训练为主。随着模型训练逐渐成熟,大规模应用阶段到来,推理成为了大模型落地的主旋律。
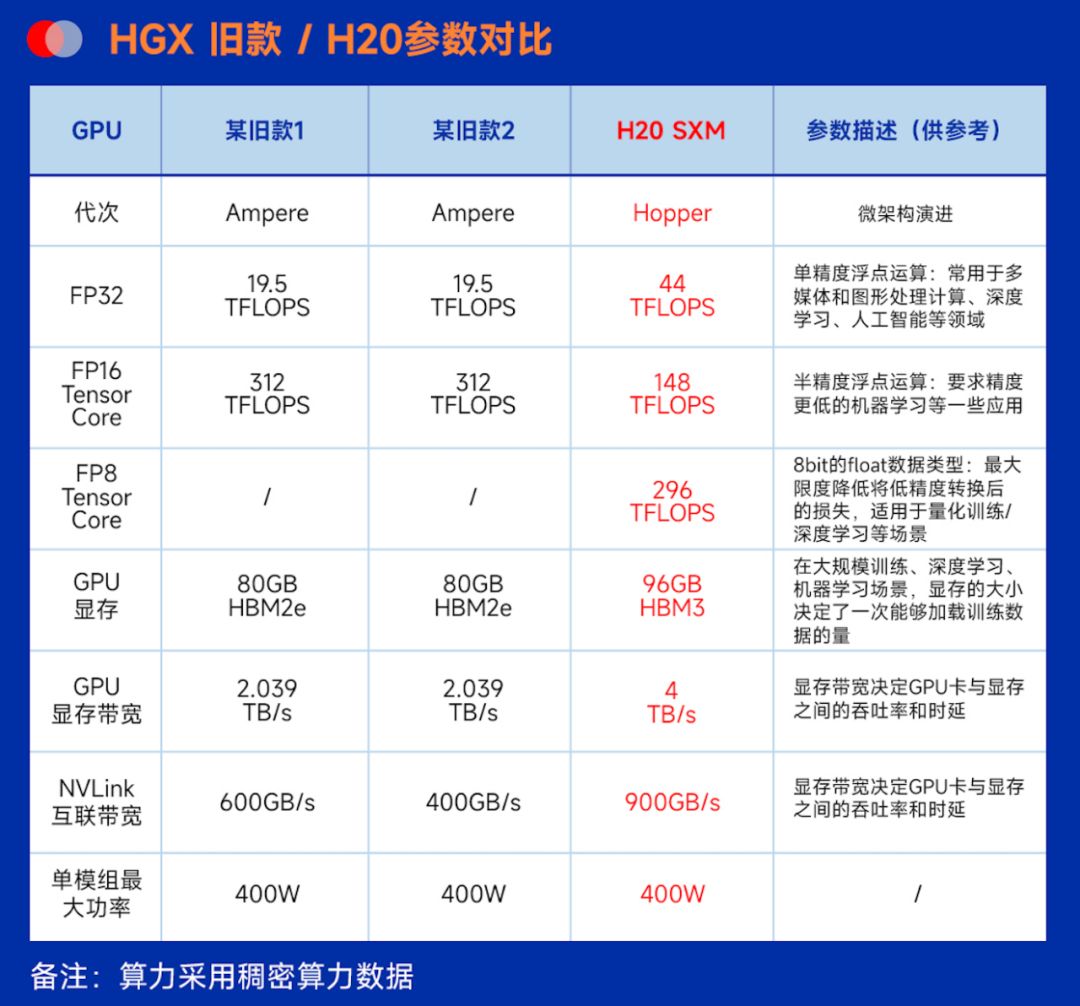
作为新一代明星机型,NVIDIA HGX H20备受瞩目。尽管其FP16、INT8等主要参数相较前辈有所降低,但仍具有显著优势。
2、支持NVLink 900GB/s高速互联,兼容8路HGX,助力构建AI集群,大幅提升大模型训练效果;在推理测试中表现卓越,超越前代。
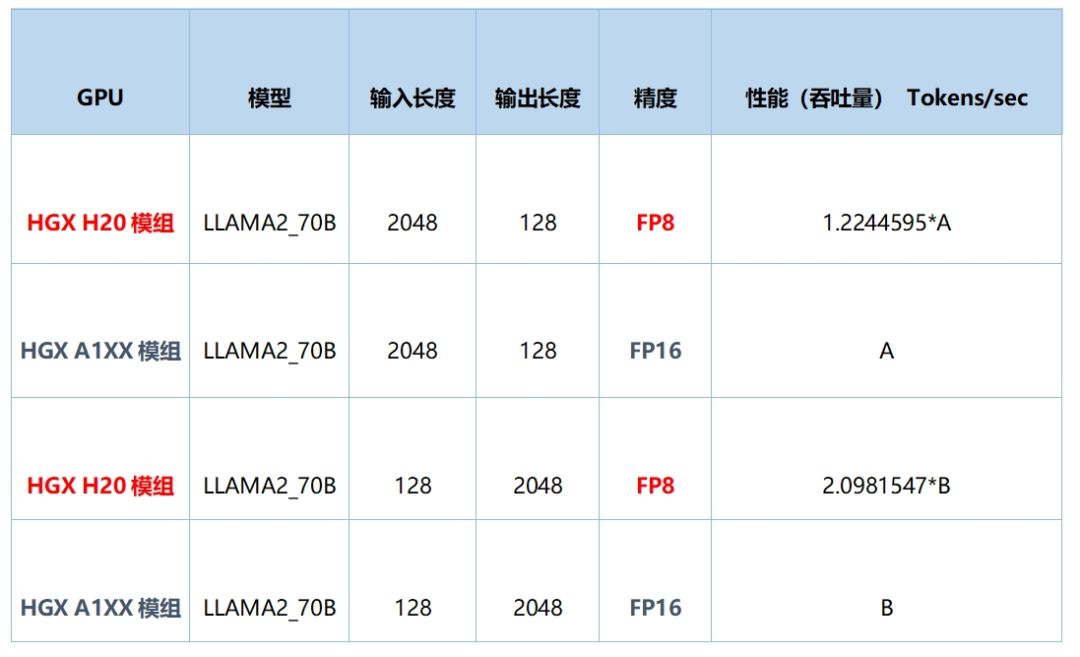
H20 for 大模型训练
H20凭借卓越的卡间互联带宽和PCIe Gen5支持,搭配400GbE集群网络,实现线性加速比近1,为大规模集群搭建提供了理想之选。
根据当前测试结果,H20在执行大型模型训练任务时,采用BF16混合精度训练。在集群规模较小(如512 x H20)的情况下,H20的训练吞吐量可达到A8XX训练吞吐量的62%,即在集群规模较小时,H20性能约为A8XX性能的60%。而在集群规模较大(如4096 x H20)的情况下,H20的训练吞吐量可达到A8XX训练吞吐量的70%,即在集群规模较大时,H20性能约是A8XX性能的70%。
Huawei 910B-A2(over A8XX)
Nvidia H20(over A8XX)
Nvidia A8XX
较小集群规模(~512卡)
75% ~ 85%
60% ~ 70%
100%
较大集群规模(~4096卡)
60% ~ 70%
65% ~ 75%
90%(线性加速比)
FP8计算
不支持
大于100%
100%
值得注意的是,FP8混合精度训练尚处于发展阶段,目前仅适用于规模较小的LLM模型(如34B及以下)。然而,随着技术的持续创新,FP8混合精度训练有望在未来成为主流技术。
H20 for 大模型推理
H20以其卓越的显存配置和出色的FP8峰值算力,成为LLM推理任务的理想之选。相较于A8XX,H20在大模型推理任务中(特别是LLM推理),性能提升高达20%(例如,对比显存带宽:4/3.35 ≈ 1.19 = 120%)。
"随着LLM模型参数规模的急速扩大,具备大容量显存的AI芯片在推理任务中的优势将更加突出。这意味着,H20用于执行大型LLM模型的推断,不仅更高效,而且更具性价比。"
Huawei 910B-A2(over A8XX)
Nvidia H20(over A8XX)
Nvidia A8XX
推理实例(单机8卡)
75% ~ 85%
100% ~ 120%
100%
推理实例(32卡)
70% ~ 80%
100% ~ 125%
100%
结语
综上所述, H20的核心价值体现在:
1、安全合规,官方保修;
2、高效组建大规模集群用于大模型训练,如FP8混合精度训练;
3、超大规模LLM推理表现超越前辈,擅长FP8计算;
4、价格适中,性价比极高
您好,H20是一种高性能硬件,可以用于大模型训练任务。如果您的推理服务中的前辈机性能不足,可以考虑购置H20来代替前辈机进行大模型训练任务。这样可以提高推理性能,同时成本也会下降。



-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-