喜欢白鹿,所以看了看她的微博,然后滋生了爬取她的微博图片的想法。sese使人进步,嘿哈...
首先打开微博,登录,通过搜索,进入白鹿的主页。
按F12后,通过网络抓包。
没过多久,我们就发现了微博存储的链接为:
https://weibo.com/ajax/statuses/mymblog?uid=2616380702&page=1&feature=0
很明显有一个uid是需要获得的,仔细一看这个uid其实就是所谓的user_id,也就是博主主页的id。
因为要爬取的是多页,所以我们继续下拉,看看下一页的结构和第一页的结构有什么不同,于是获得了:
https://weibo.com/ajax/statuses/mymblog?uid=2616380702&page=2&feature=0&since_id=5123969932591936kp2
明显,第二页,以及之后的页面,仅仅是多了一个page和since_id。
我们去第一个链接中,尝试寻找第二页的since_id,很快就找到了:
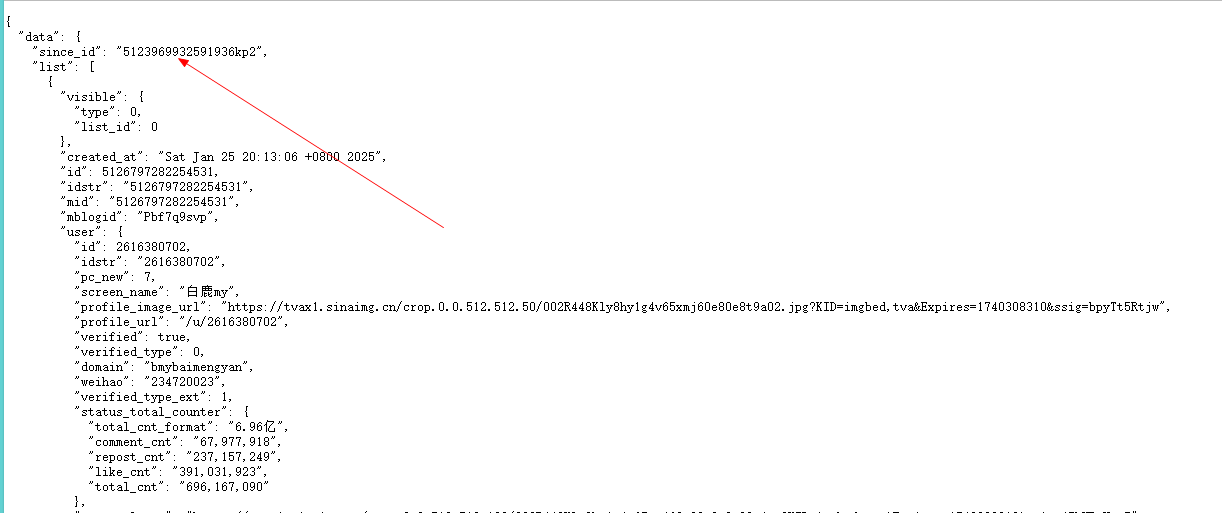
这样,我们代码的大概思路就出现了:先访问第一个链接,获取到第二页的since_id,构建第二页的链接,然后找到第三页的since_id......
但是,当我们使用requests时,发现:
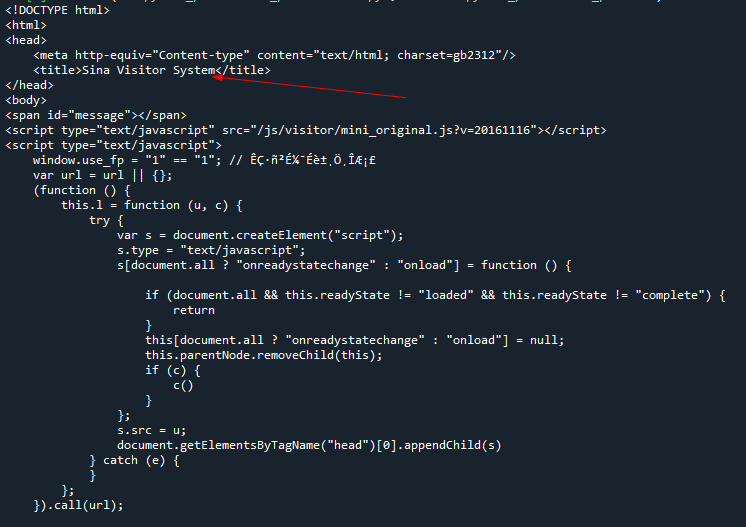
需要登录,由于没有写过session函数,于是我们只好换用selenium尝试了。
由于已经提前写好了浏览器访问以及配置了相应的浏览器驱动,所以我们直接调用函数即可获得代码,省去了不少的事情:
import functions.func_main as fun
url='https://weibo.com/ajax/statuses/mymblog?uid=2616380702&page=1&feature=0'
resp=fun.bro(url,5,head=False)
print(resp)
这里的head是指有无头的浏览器,使用selenium登录微博,并访问网页找到since_id:
#获得下一页的since_id
since_id=re.findall('"since_id":"([0-9A-z]+)",', resp)[0]
print(since_id)
这样,基本的初始链接的构建参数我们就已经拿到了。[since_id,uid,page]
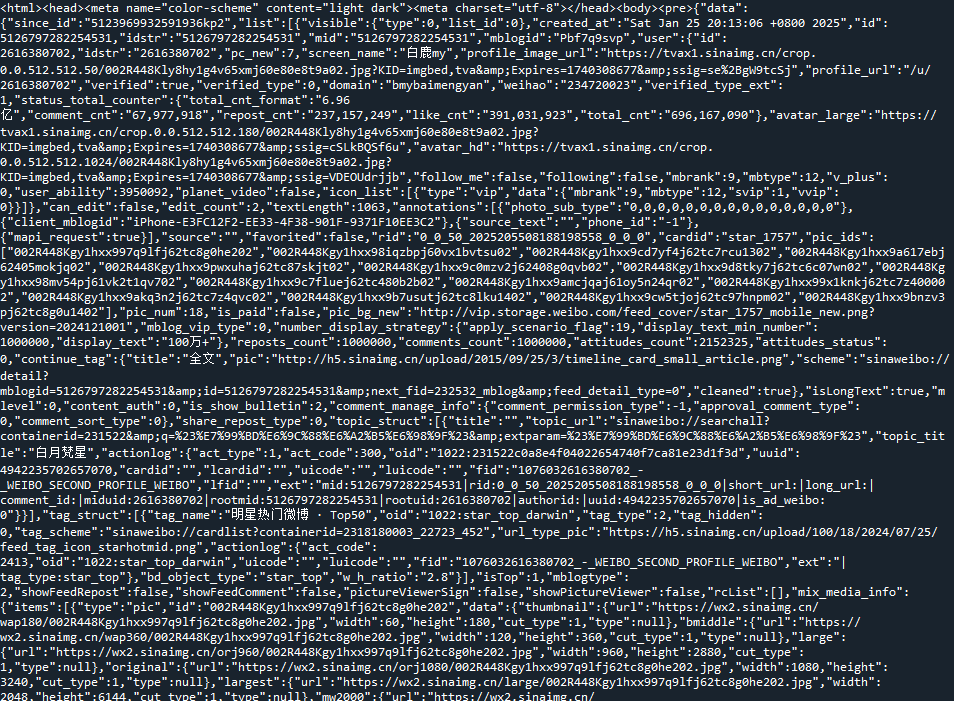
下面访问第一页,发现它是一个json文件:
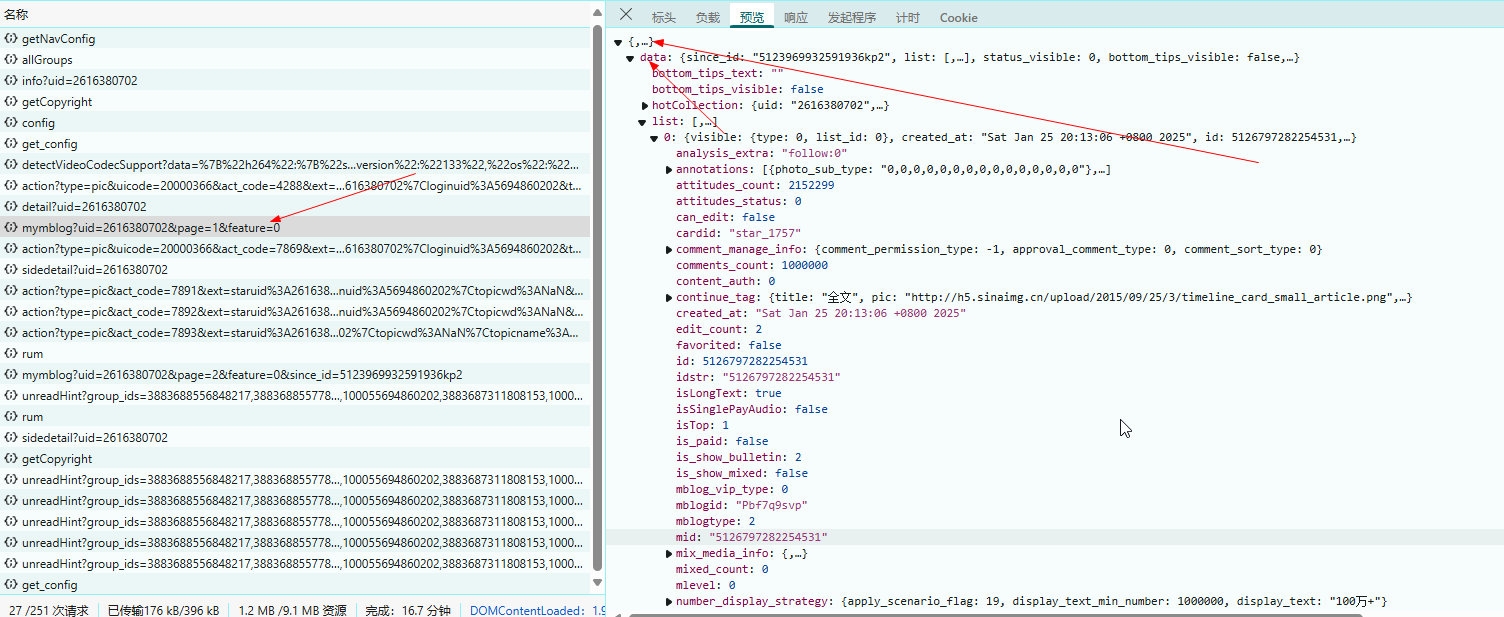
不过,实际上我们细心观测会发现,它的图片都是放在一个名叫“pic_infos”的字段里的;如果一个微博没有图片,就没有这个字段,如果我们用json,不可避免地要写很多其他东西,所以我决定直接找图片。
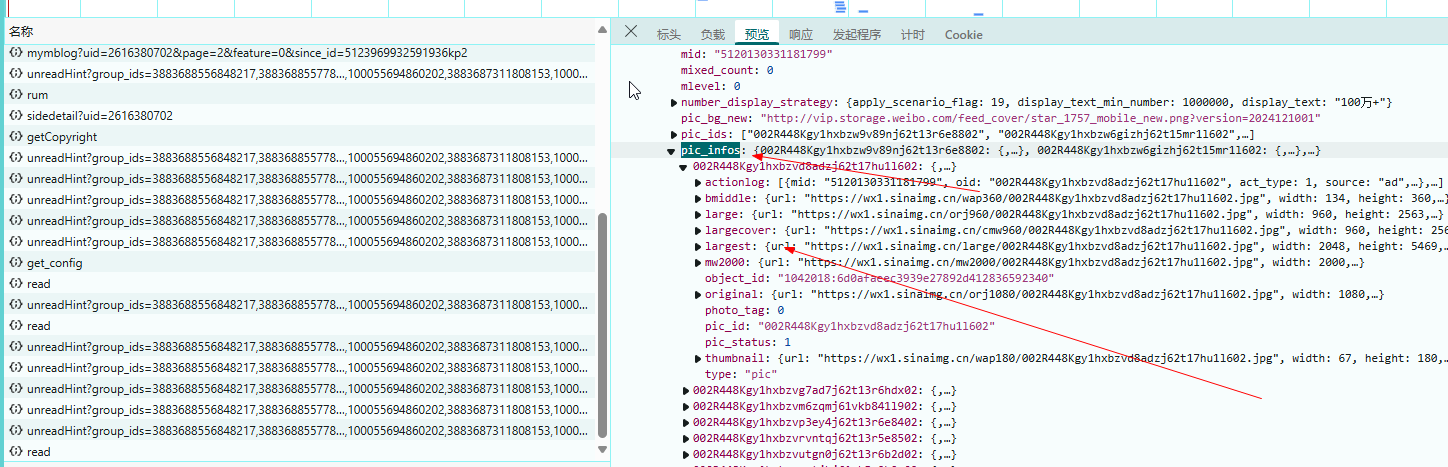
#获得该页的所有图片链接
img_lst=re.findall('"largest":{"url":"(https://wx[0-9]+.sinaimg.cn/large/[0-9A-z]+.[jpgnewbp]+)"', wb_data)
print(img_lst)
对re法则修修改改,终于拿到了图片链接,如下:
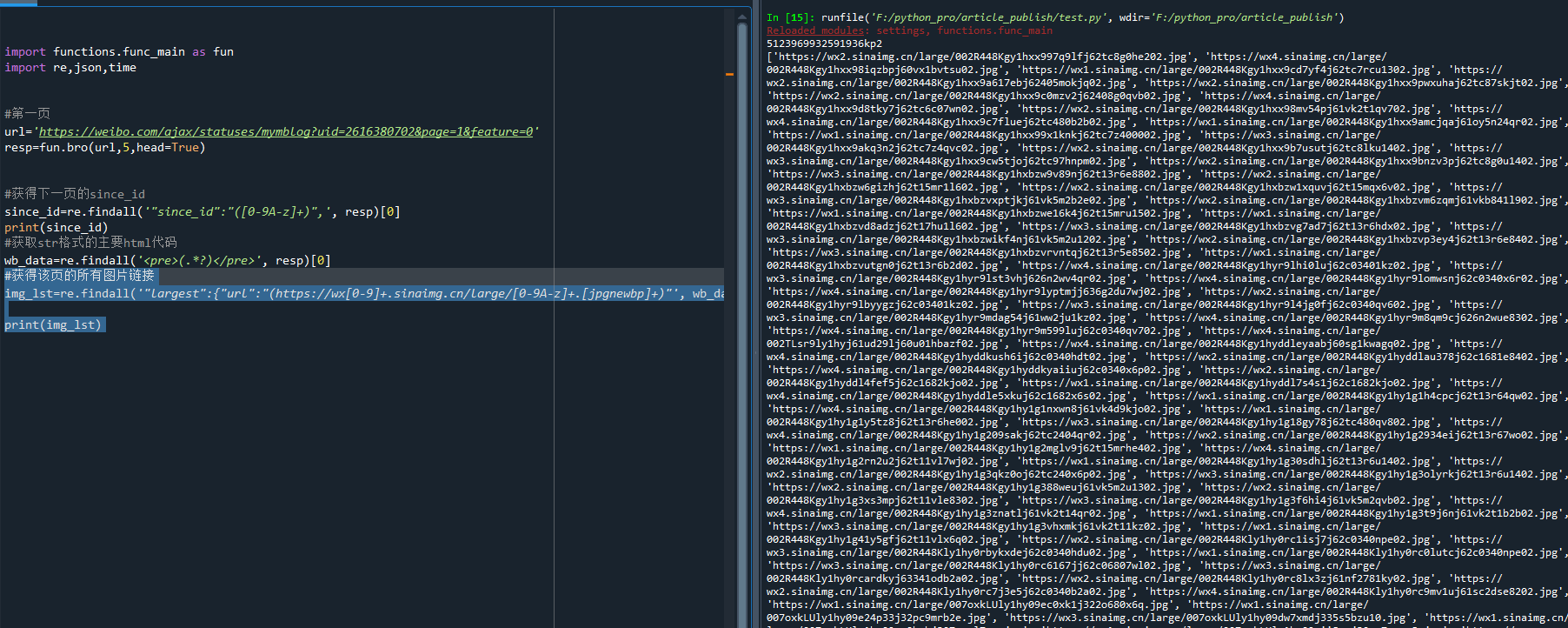
我们复制一个图片到浏览器打开看看:

真是一场酣畅淋漓的对决!遇到这种情况,一定是referer的问题啦,我们于是狠下心,直接下载几张图片看看。
test_imgs=img_lst[0:9]
fun.download_images(test_imgs, '微博_白鹿')

这里的download_images是我们自己写的一个下载图片的函数,在其中使用了一个requests方法,headers中的referer设置为微博链接。
打开文件夹,看到图片确实下载下来了:
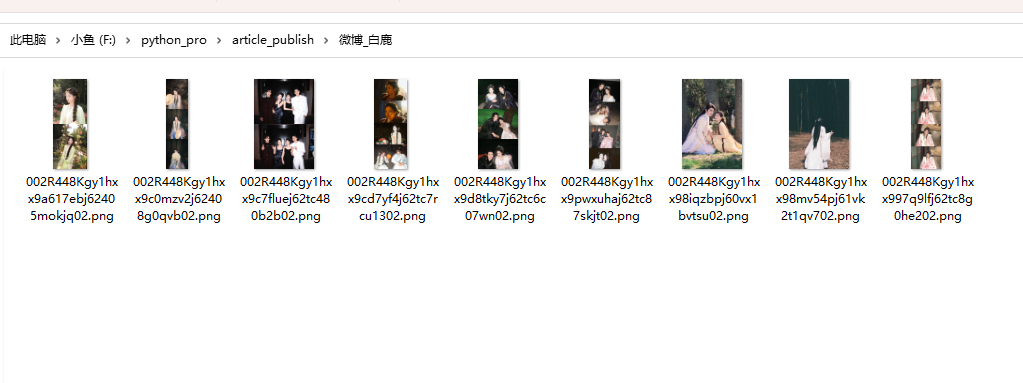
也就是说,这一页的图片,其实我们已经可以轻松下载了。
不过还不够,我要打10个,完整代码:
import functions.func_main as fun
import re,time
#根据链接,获取since_id和该页的html代码
def weibo_since_data_and_resp(url):
#第一页
resp=fun.bro(url,5,head=True)
#获得下一页的since_id
since_id=re.findall('"since_id":"([0-9A-z]+)",', resp)[0]
print(since_id)
return since_id ,resp
#传入网页源码resp,解析图片链接并下载到文件夹save_path
def weibo_down_pics(resp,save_path):
wb_data=re.findall('<pre>(.*?)</pre>', resp)[0]
#获得该页的所有图片链接
img_lst=re.findall('"largest":{"url":"(https://wx[0-9]+.sinaimg.cn/large/[0-9A-z]+.[jpgnewbp]+)"', wb_data)
fun.download_images(img_lst, save_path)
def weibo_start(uid,stop_page,save_path):
start_url=f'https://weibo.com/ajax/statuses/mymblog?uid={uid}&page=1&feature=0'
#当只爬取第一页时,不必获取第二页的since_id
if stop_page<=1:
print('开始爬取第1页...')
resp=fun.bro(start_url,5,head=True)
weibo_down_pics(resp, save_path)
else:
#爬取第一页
print('开始爬取第1页...')
first_resp=weibo_since_data_and_resp(start_url)
resp=first_resp[1]
weibo_down_pics(resp, save_path)
#开始爬取其他页
#获取第二页的since_id
since_id=first_resp[0]
#设置从第2页爬取到stop_page页
page=2
while True:
print(f'开始爬取第{page}页')
url=f'https://weibo.com/ajax/statuses/mymblog?uid={uid}&page={page}&feature=0&since_id={since_id}'
s_r=weibo_since_data_and_resp(url)
since_id=s_r[0]
print(f'获取到下一页的since_id:{since_id}')
#这是本页的数据
resp=s_r[1]
weibo_down_pics(resp, save_path)
time.sleep(10)
print(f'第{page}个页面下载完毕!')
if page>stop_page:
print(f'你要爬取的是前{stop_page}页,当前已到达,所以退出啦!')
break
page=page+1
uid=2616380702
stop_page=2
save_path='微博_白鹿'
weibo_start(uid,stop_page,save_path)
经过这个代码,我们可以自由选择从第一页爬取到第几页,并且图片页可以通过多线程下载到save_path文件夹中。
至此,我们简单的爬取白鹿微博图片的爬虫就完成啦!
当然,这里我使用了functions.func_main这个自己写的函数,所以方便了许多,该函数包括了user-agent和我自己收集的代理ip,还有许多其他功能的爬虫常用函数,如果你想使用该微博案例,必须要下载它,并安装requirements.txt中的库依赖库,同时需要修改中的浏览器驱动路径,并配置同自己谷歌浏览器相适配的浏览器驱动路径。当然,你也可以往其中添加自己的函数,方便使用。
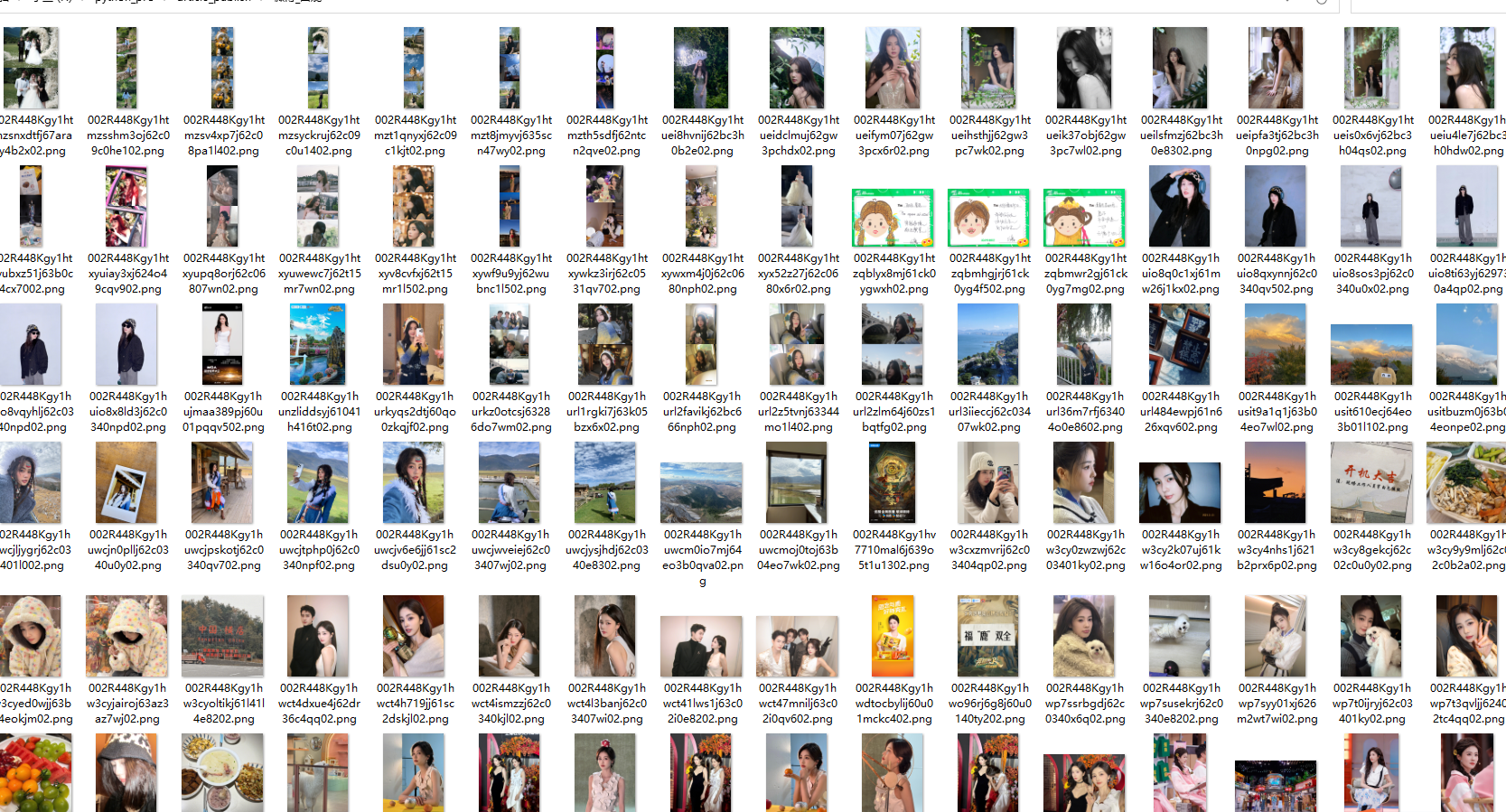
以下是爬取的成果,2页一共560张白鹿的微博图片,嘿嘿:
functions函数链接
链接:中国移动云盘分享
提取码:d8g8
复制内容打开移动云盘PC客户端,操作更方便哦