
博客主页:小馒头学python
本文专栏: Python数据分析五十个小案例
专栏简介:分享五十个Python数据分析小案例

在现代电影行业中,数据分析已经成为提升用户体验和电影推荐的关键工具。通过分析电影评分数据,我们可以揭示出用户的评分偏好、热门电影的特点以及不同电影类型的受欢迎程度。本文将展示如何使用Python中的Pandas库来分析电影评分数据,探索评分的分布、热门电影以及用户的评分偏好。
引言
电影评分数据通常包含大量的用户评分信息,反映了电影的受欢迎程度以及观众的评价。通过对这些数据的分析,电影公司、推荐系统以及研究者可以更好地了解用户需求并作出相应的调整。例如,分析评分分布可以帮助我们识别评分过低或过高的电影,探索评分高的电影类型,进而为推荐系统提供优化建议。
本文将通过Pandas库分析电影评分数据,帮助大家探索以下问题:
- 电影评分的分布是怎样的?
- 哪些电影是最受欢迎的?
- 用户有哪些评分偏好?
数据获取与预处理
数据源介绍
我们使用的数据集包含了电影的评分信息,这些数据通常可以从IMDb、豆瓣或类似的公共平台获取。假设我们使用的CSV文件包含以下几列:
movie_id:电影IDtitle:电影名称genre:电影类型rating:电影的平均评分num_ratings:电影的评分次数user_id:评分用户的IDtimestamp:评分时间
首先我们需要生成一个脚本进行生成模拟的数据
import pandas as pd
import numpy as np
# 生成电影数据
movie_titles = ['The Shawshank Redemption', 'The Dark Knight', 'Inception', 'Fight Club', 'Pulp Fiction']
genres = ['Drama', 'Action', 'Sci-Fi', 'Drama', 'Crime']
ratings = [8.7, 9.0, 8.8, 8.8, 9.0]
num_ratings = [1200, 1500, 1100, 900, 1300]
user_ids = np.random.randint(1, 500, size=5000)
timestamps = np.random.randint(1000000000, 1600000000, size=5000) # 模拟时间戳(UNIX时间戳)
# 创建DataFrame
data = {
'movie_id': np.random.randint(1, 6, size=5000),
'title': np.random.choice(movie_titles, size=5000),
'genre': np.random.choice(genres, size=5000),
'rating': np.random.uniform(5, 10, size=5000),
'num_ratings': np.random.choice(num_ratings, size=5000),
'user_id': user_ids,
'timestamp': timestamps
}
df = pd.DataFrame(data)
# 保存为CSV文件
df.to_csv('movie_ratings.csv', index=False)
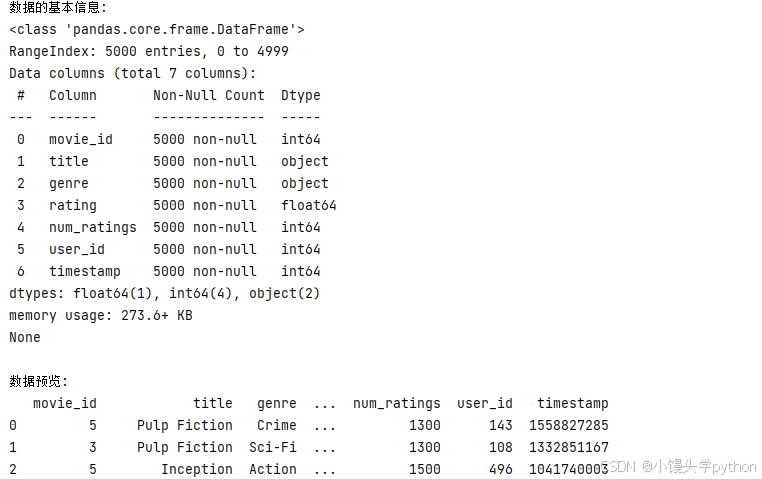
print(df.head())
运行结果如下

数据加载与清洗
首先,我们使用Pandas加载数据并进行基本的清洗工作。例如,去除缺失值和重复数据。
import pandas as pd
# 加载数据
df = pd.read_csv('movie_ratings.csv')
# 查看数据的基本信息
print(df.info())
# 处理缺失值
df = df.dropna() # 删除含有缺失值的行
# 处理重复数据
df = df.drop_duplicates()
# 确保数据类型正确
df['rating'] = df['rating'].astype(float)
df['num_ratings'] = df['num_ratings'].astype(int)
print(df.head())
评分数据查看
数据概览
加载并清洗数据后,我们先进行一些基本的统计分析,了解电影评分数据的整体情况。我们可以使用df.describe()来查看数据的摘要统计信息,如均值、标准差、最小值和最大值等。
# 基本统计分析
print(df['rating'].describe())
数据分布
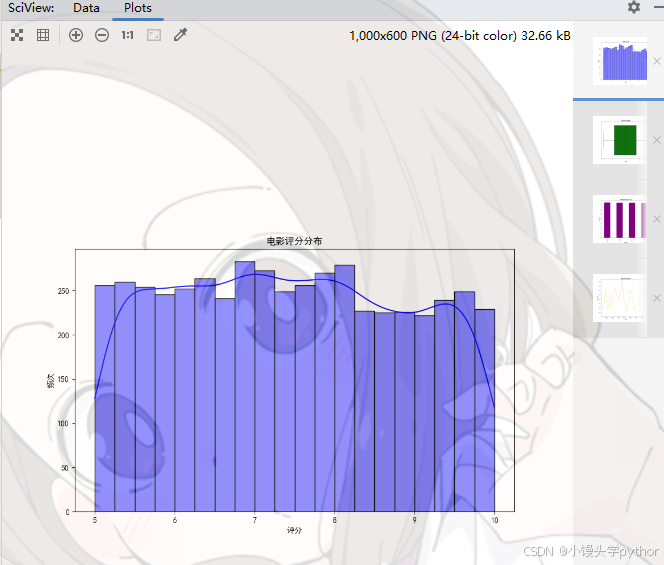
通过直方图和箱型图,我们可以直观地查看评分的分布情况,识别出评分的集中趋势以及异常值。
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制评分分布的直方图
plt.figure(figsize=(8, 6))
sns.histplot(df['rating'], bins=20, kde=True, color='blue')
plt.title('电影评分分布')
plt.xlabel('评分')
plt.ylabel('频次')
plt.show()
# 绘制箱型图查看评分的分布情况
plt.figure(figsize=(8, 6))
sns.boxplot(x=df['rating'], color='green')
plt.title('电影评分箱型图')
plt.xlabel('评分')
plt.show()
通过这些图表,我们可以看到大部分电影的评分集中在较高的区间(例如7到9分之间),同时也能看到少量评分极低和极高的电影。
电影评分分布分析
各评分区间的电影数量分析
我们可以根据评分区间对电影进行分类,统计各个区间的电影数量。例如,评分为1-3、4-6、7-9和10分的电影各有多少部。
# 定义评分区间
bins = [0, 3, 6, 9, 10]
labels = ['1-3', '4-6', '7-9', '10']
df['rating_category'] = pd.cut(df['rating'], bins=bins, labels=labels, right=False)
# 统计各评分区间的电影数量
rating_distribution = df['rating_category'].value_counts()
print(rating_distribution)
高评分与低评分电影比例
我们可以进一步探讨评分偏好的问题,找出高评分和低评分电影的比例。比如,评分在9分以上的电影占总电影数的比例。
# 计算评分大于等于9的电影占比
high_rated_movies = df[df['rating'] >= 9]
print(f"高评分电影占比: {len(high_rated_movies) / len(df) * 100:.2f}%")
热门电影分析
根据评分数筛选热门电影
热门电影通常有大量的评分,我们可以通过num_ratings(评分数)来筛选这些电影。找出评分次数最多的前10部电影。
# 按照评分数排序,找到评分数最多的前10部电影
top_rated_by_count = df.sort_values(by='num_ratings', ascending=False).head(10)
print(top_rated_by_count[['title', 'num_ratings', 'rating']])
根据平均评分找出评分最高的电影
除了考虑评分次数,电影的平均评分也很重要。我们可以根据rating对电影进行排序,找出评分最高的前10部电影。
# 按照评分排序,找到评分最高的前10部电影
top_rated_by_avg = df.sort_values(by='rating', ascending=False).head(10)
print(top_rated_by_avg[['title', 'rating', 'num_ratings']])
用户偏好分析
用户评分偏好分析
我们可以通过电影类型(genre)来分析用户的评分偏好。首先,统计每种电影类型的平均评分,并进行可视化。
# 计算每种类型的平均评分
genre_avg_rating = df.groupby('genre')['rating'].mean().sort_values(ascending=False)
print(genre_avg_rating)
# 绘制电影类型的平均评分
plt.figure(figsize=(10, 6))
genre_avg_rating.plot(kind='bar', color='purple')
plt.title('不同电影类型的平均评分')
plt.xlabel('电影类型')
plt.ylabel('平均评分')
plt.show()
评分时间趋势
用户的评分行为可能随时间变化而有所不同,尤其是在电影的上映周期内。我们可以通过timestamp列来分析评分的时间趋势。
# 转换时间戳为日期
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='s')
# 按照年份统计平均评分
df['year'] = df['timestamp'].dt.year
yearly_avg_rating = df.groupby('year')['rating'].mean()
# 绘制年度平均评分趋势
plt.figure(figsize=(10, 6))
yearly_avg_rating.plot(kind='line', color='orange')
plt.title('电影评分的年度趋势')
plt.xlabel('年份')
plt.ylabel('平均评分')
plt.show()
完整源码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 1. 数据加载与预处理
df = pd.read_csv('movie_ratings.csv')
# 查看数据基本信息
print("数据的基本信息:")
print(df.info())
# 查看前几行数据
print("\n数据预览:")
print(df.head())
# 处理缺失值
df = df.dropna() # 删除含有缺失值的行
# 处理重复数据
df = df.drop_duplicates()
# 确保数据类型正确
df['rating'] = df['rating'].astype(float)
df['num_ratings'] = df['num_ratings'].astype(int)
# 2. 评分数据探索
# 描述性统计
print("\n评分的描述性统计:")
print(df['rating'].describe())
# 3. 绘制评分分布
plt.figure(figsize=(10, 6))
sns.histplot(df['rating'], bins=20, kde=True, color='blue')
plt.title('电影评分分布')
plt.xlabel('评分')
plt.ylabel('频次')
plt.show()
# 评分的箱型图
plt.figure(figsize=(8, 6))
sns.boxplot(x=df['rating'], color='green')
plt.title('电影评分箱型图')
plt.xlabel('评分')
plt.show()
# 4. 评分区间分析
bins = [0, 3, 6, 9, 10]
labels = ['1-3', '4-6', '7-9', '10']
df['rating_category'] = pd.cut(df['rating'], bins=bins, labels=labels, right=False)
# 各评分区间的电影数量
rating_distribution = df['rating_category'].value_counts()
print("\n各评分区间的电影数量:")
print(rating_distribution)
# 5. 高评分与低评分电影比例
high_rated_movies = df[df['rating'] >= 9]
print(f"\n高评分电影占比: {len(high_rated_movies) / len(df) * 100:.2f}%")
# 6. 热门电影分析
# 按评分数排序,找到评分数最多的前10部电影
top_rated_by_count = df.sort_values(by='num_ratings', ascending=False).head(10)
print("\n评分次数最多的前10部电影:")
print(top_rated_by_count[['title', 'num_ratings', 'rating']])
# 按照评分排序,找到评分最高的前10部电影
top_rated_by_avg = df.sort_values(by='rating', ascending=False).head(10)
print("\n评分最高的前10部电影:")
print(top_rated_by_avg[['title', 'rating', 'num_ratings']])
# 7. 用户评分偏好分析
# 计算每种类型的平均评分
genre_avg_rating = df.groupby('genre')['rating'].mean().sort_values(ascending=False)
print("\n每种类型的平均评分:")
print(genre_avg_rating)
# 绘制电影类型的平均评分
plt.figure(figsize=(10, 6))
genre_avg_rating.plot(kind='bar', color='purple')
plt.title('不同电影类型的平均评分')
plt.xlabel('电影类型')
plt.ylabel('平均评分')
plt.show()
# 8. 评分时间趋势
# 转换时间戳为日期
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='s')
# 按照年份统计平均评分
df['year'] = df['timestamp'].dt.year
yearly_avg_rating = df.groupby('year')['rating'].mean()
# 绘制年度平均评分趋势
plt.figure(figsize=(10, 6))
yearly_avg_rating.plot(kind='line', color='orange')
plt.title('电影评分的年度趋势')
plt.xlabel('年份')
plt.ylabel('平均评分')
plt.show()
# 9. 结论
print("\n数据分析完成!")
print("1. 评分分布:电影评分大多集中在7-9分之间。")
print("2. 热门电影:高评分和大量评分数的电影通常会更受欢迎。")
print("3. 用户偏好:不同电影类型的评分存在显著差异,某些类型的电影得到更高的评分。")
运行部分截图
最后的简单的数据分析,也是最重要的
- 评分分布:电影评分大多集中在7-9分之间。
- 热门电影:高评分和大量评分数的电影通常会更受欢迎。
- 用户偏好:不同电影类型的评分存在显著差异,某些类型的电影得到更高的评分。
结论
通过对电影评分数据的分析,我们发现:
- 大多数电影的评分集中在7-9分之间,少部分电影评分过高或过低。
- 热门电影不仅需要大量的评分数,还要有较高的评分。
- 用户的评分偏好与电影类型密切相关,不同类型的电影有不同的评分分布。
这些发现为电影推荐系统、电影营销和电影产业的未来发展提供了有价值的见解。
参考文献
数据来源:IMDb、豆瓣
Pandas官方文档:https://pandas.pydata.org/pandas-docs/stable/