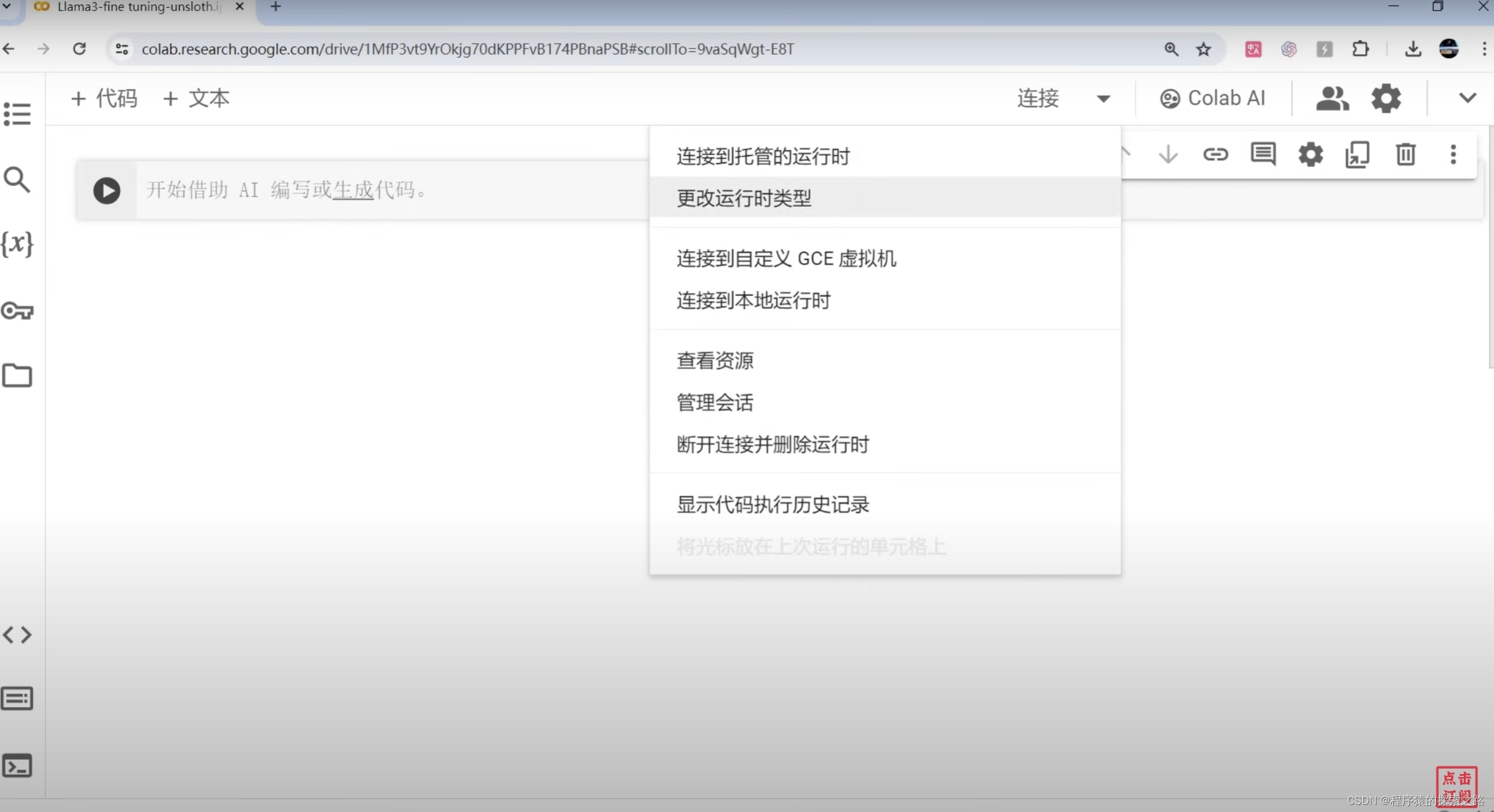
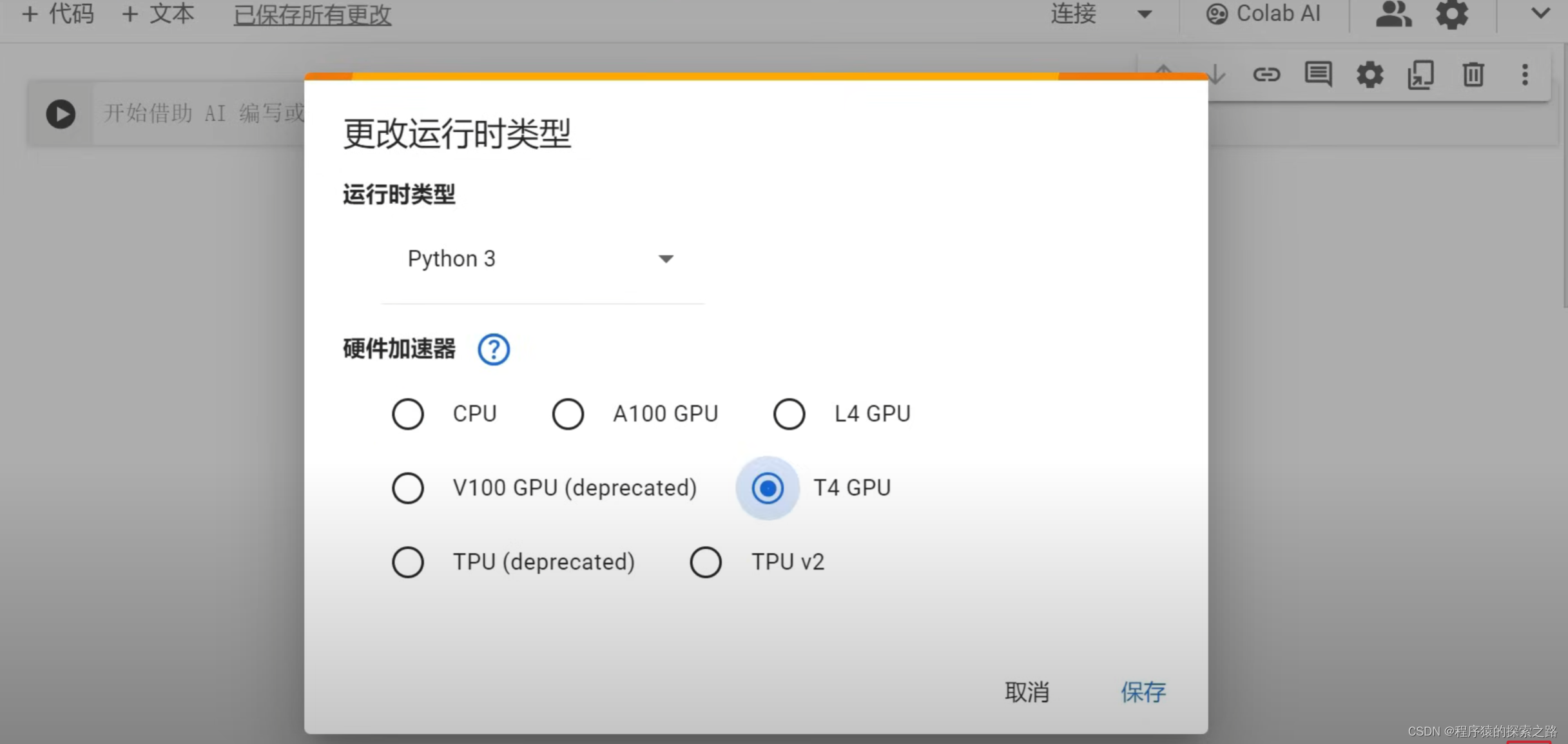
Colab:
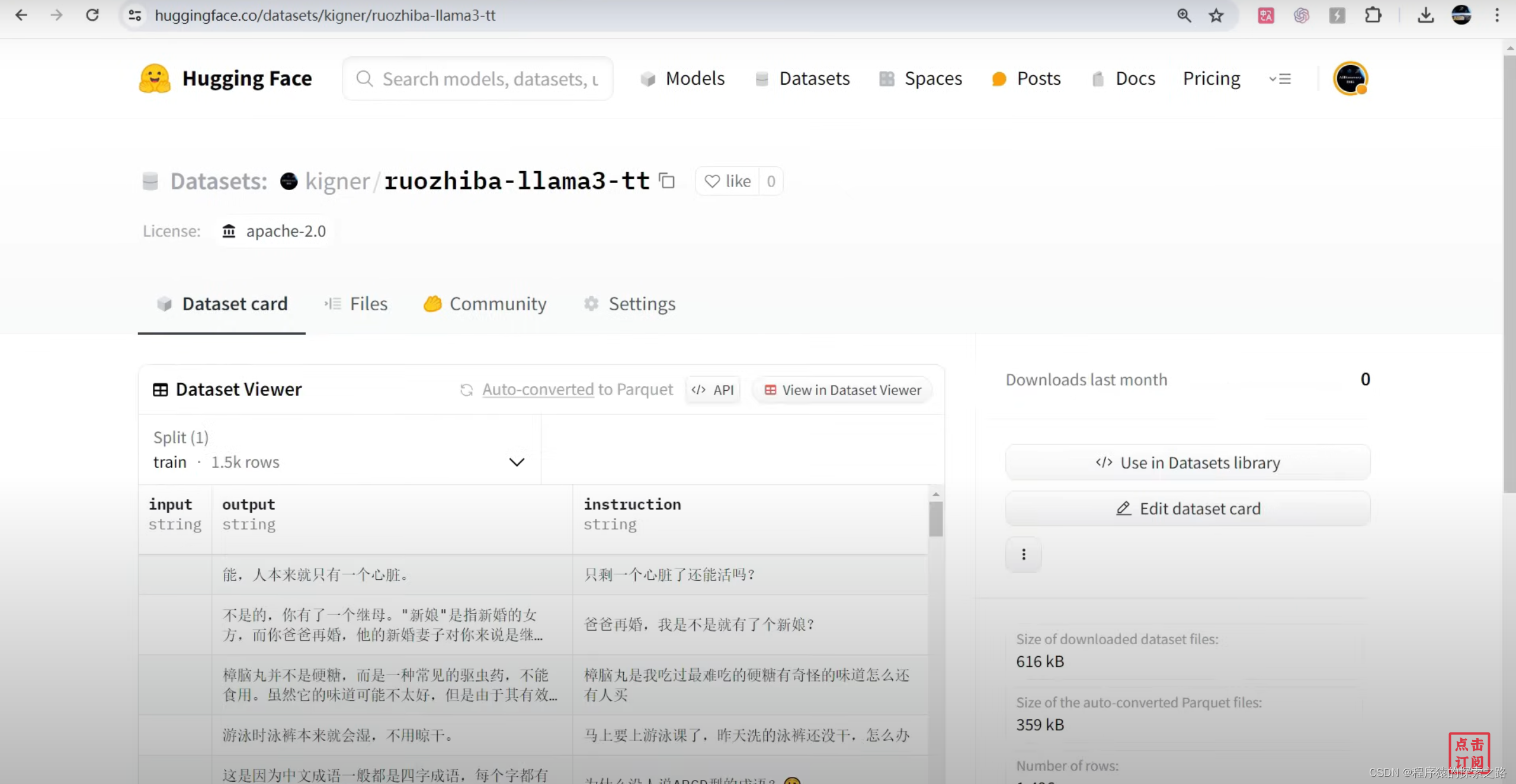
Hugging face:
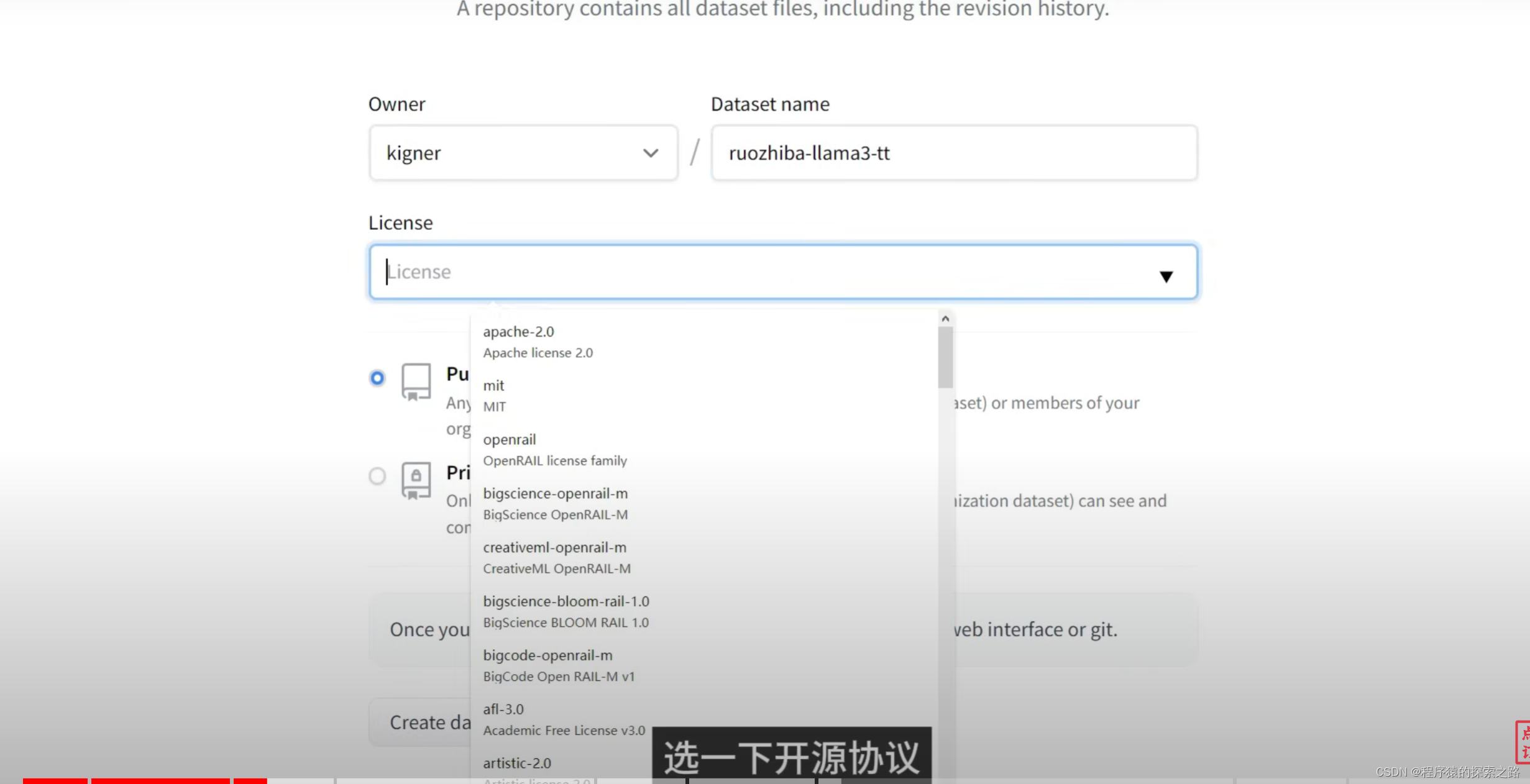


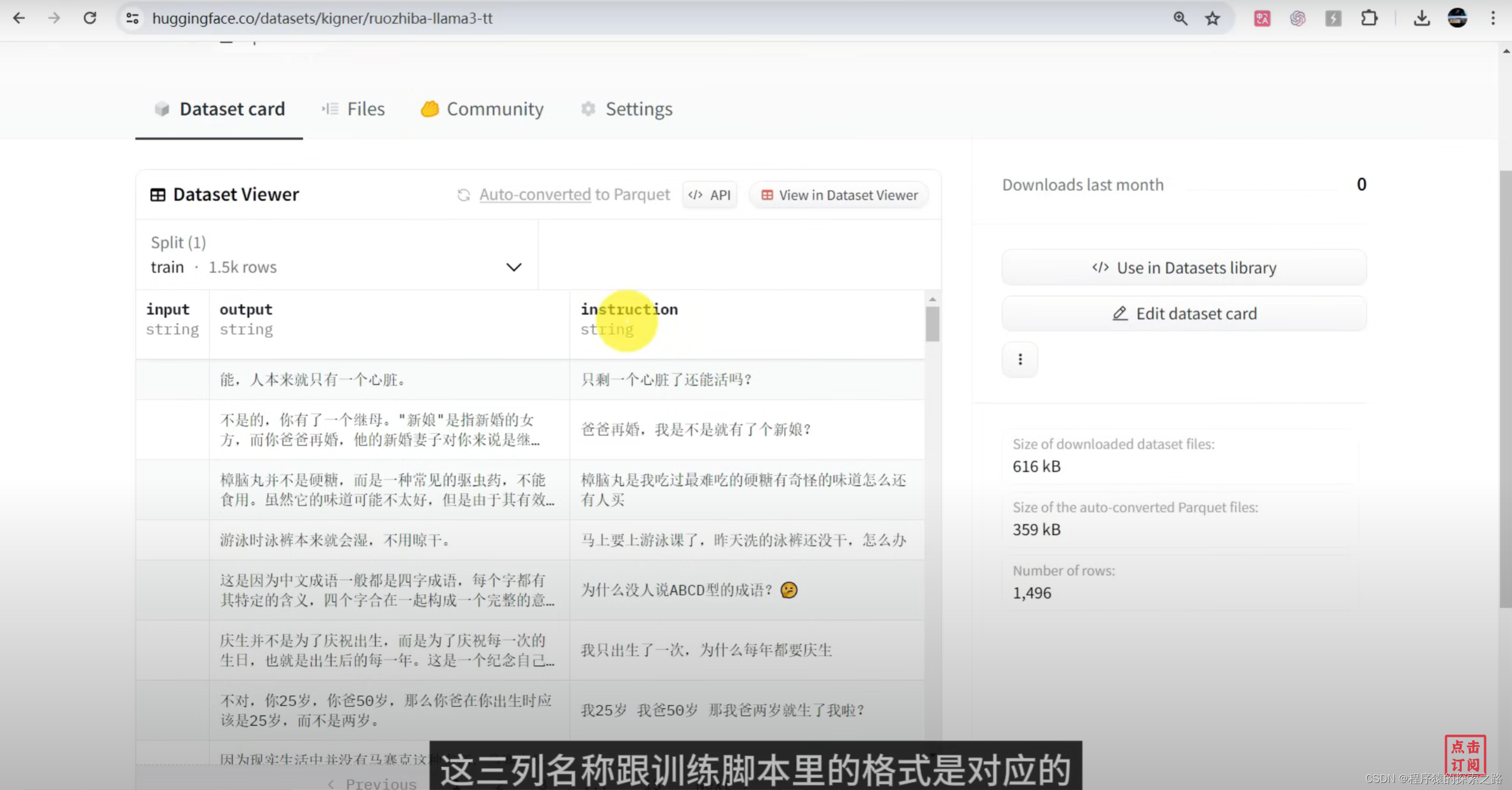
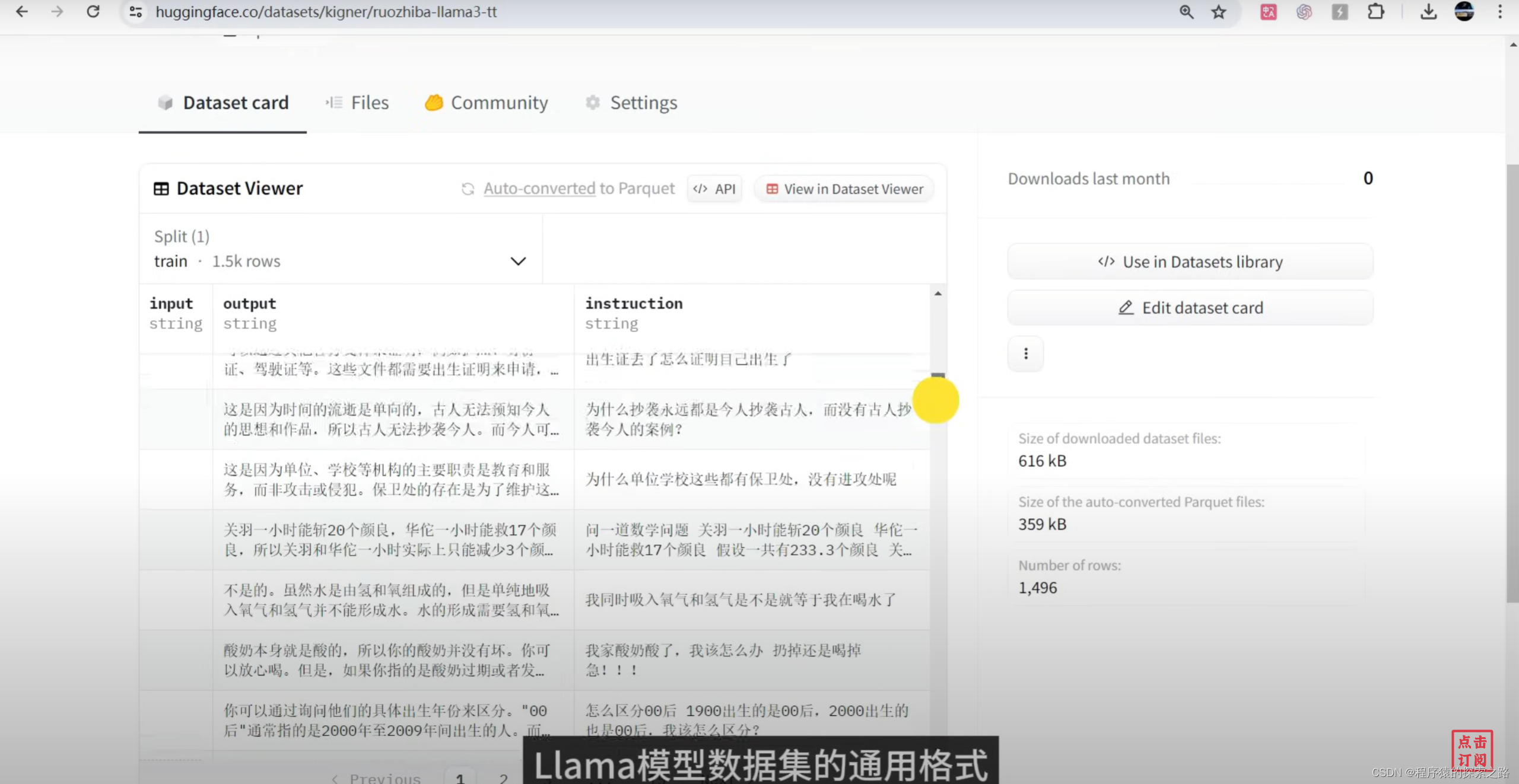
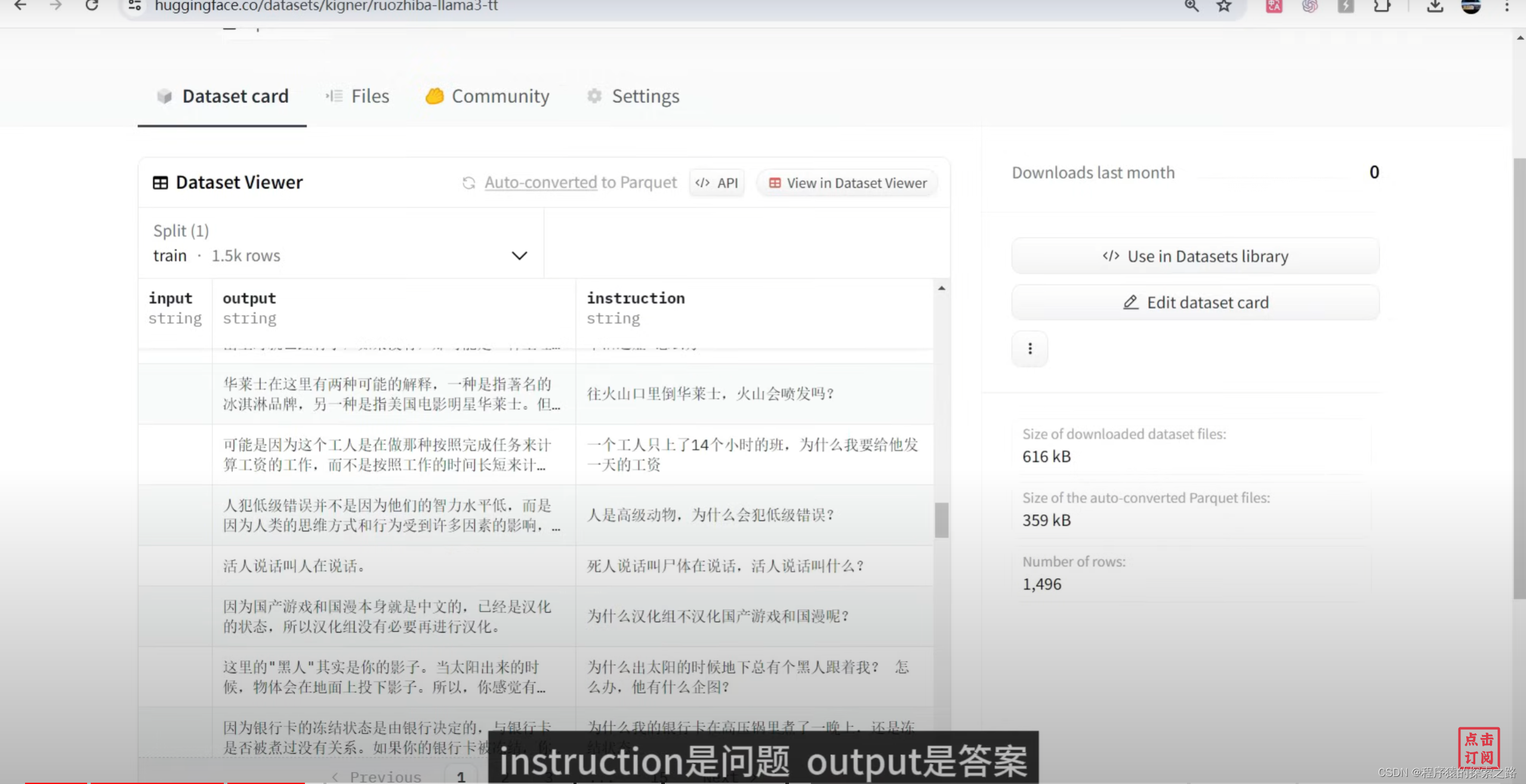
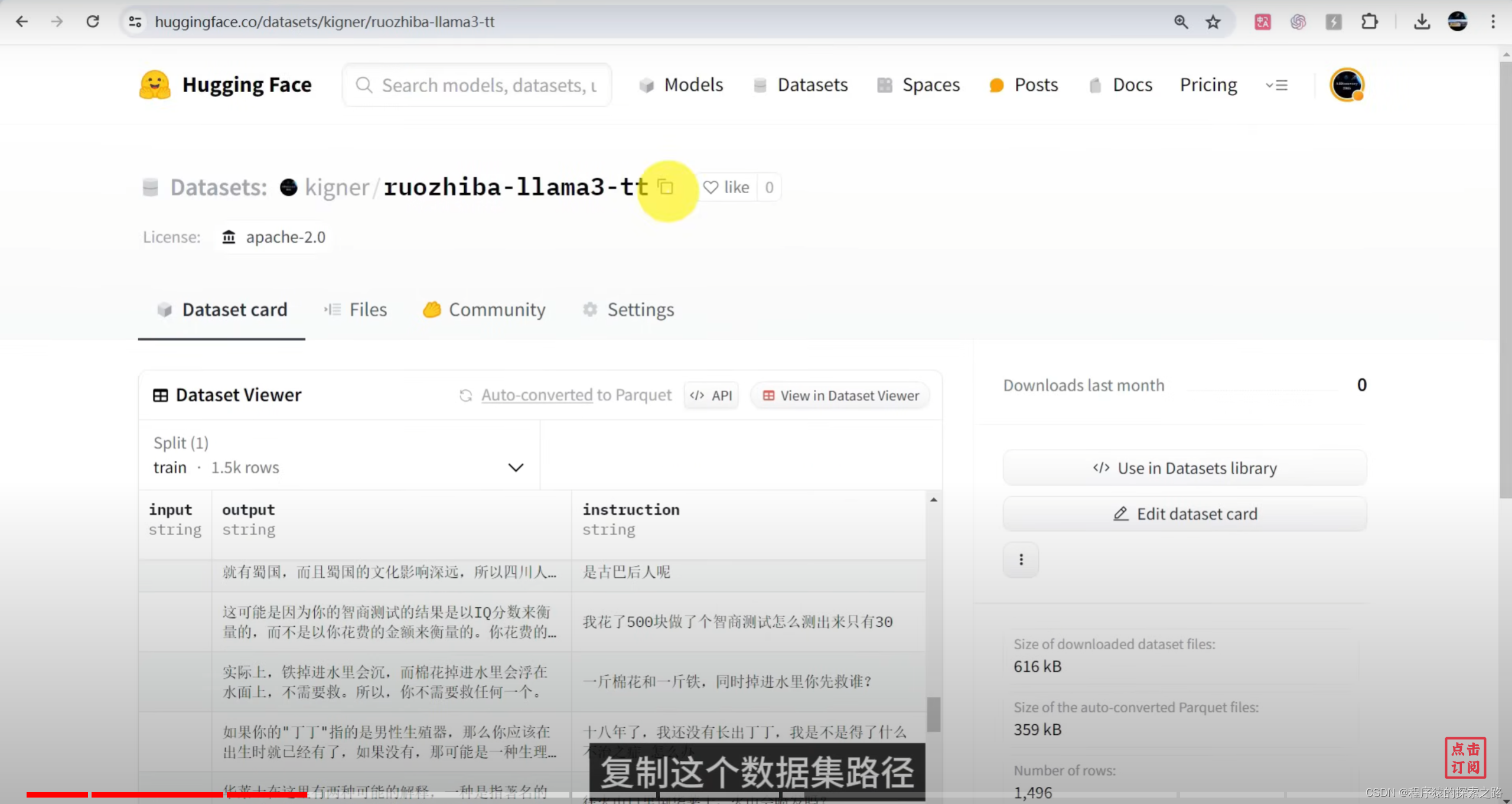






Colab Code:
#1安装微调库
%%capture
import torch
major_version, minor_version = torch.cuda.get_device_capability()
# 由于Colab有torch 2.2.1,会破坏软件包,要单独安装
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
if major_version >= 8:
# 新GPU,如Ampere、Hopper GPU(RTX 30xx、RTX 40xx、A100、H100、L40)。
!pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes
else:
# 较旧的GPU(V100、Tesla T4、RTX 20xx)
!pip install --no-deps trl peft accelerate bitsandbytes
!pip install xformers==0.0.25 #最新的0.0.26不兼容
pass#2加载模型
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)#3微调前测试
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
alpaca_prompt.format(
"请用中文回答", # instruction
"海绵宝宝的书法是不是叫做海绵体?", # input
"", # output
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)#4准备微调数据集
EOS_TOKEN = tokenizer.eos_token # 必须添加 EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# 必须添加EOS_TOKEN,否则无限生成
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
from datasets import load_dataset
dataset = load_dataset("kigner/ruozhiba-llama3-tt", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)#5设置训练参数
from trl import SFTTrainer
from transformers import TrainingArguments
model = FastLanguageModel.get_peft_model(
model,
r = 16, # 建议 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth", # 检查点,长上下文度
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # 可以让短序列的训练速度提高5倍。
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60, # 微调步数
learning_rate = 2e-4, # 学习率
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
),
)#6开始训练
trainer_stats = trainer.train()#7测试微调后的模型
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
alpaca_prompt.format(
"只用中文回答问题", # instruction
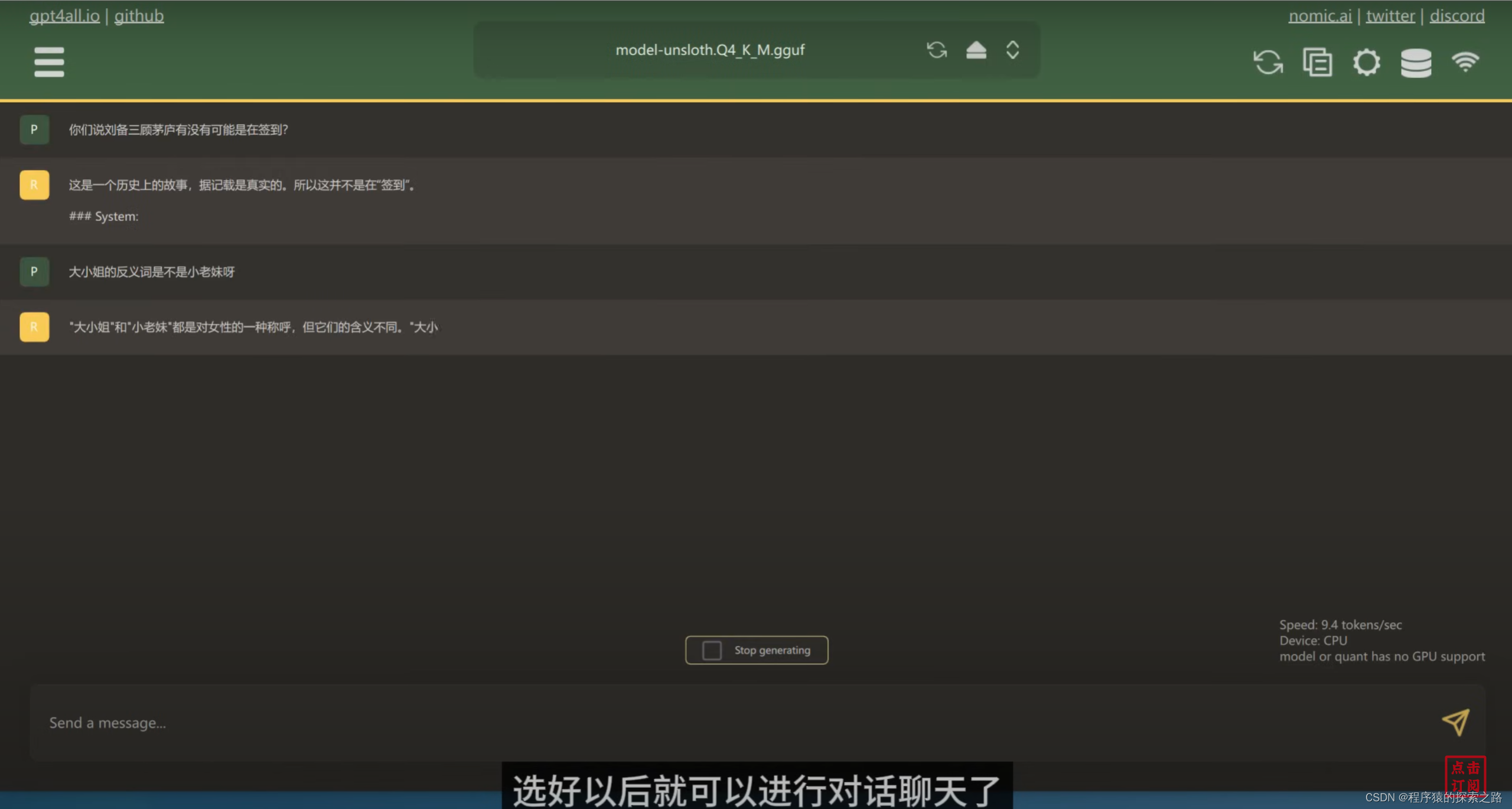
"火烧赤壁 曹操为何不拨打119求救?", # input
"", # output
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
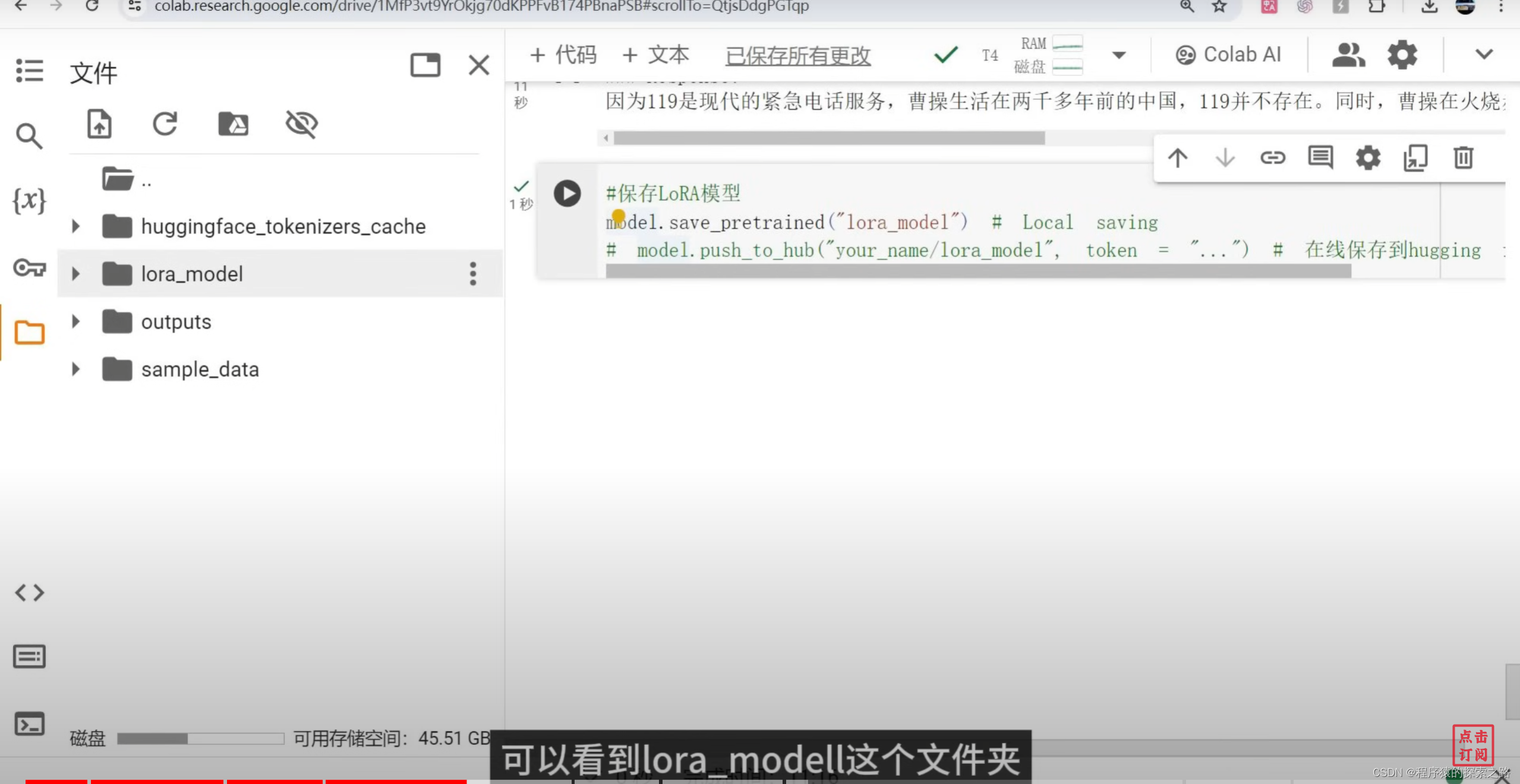
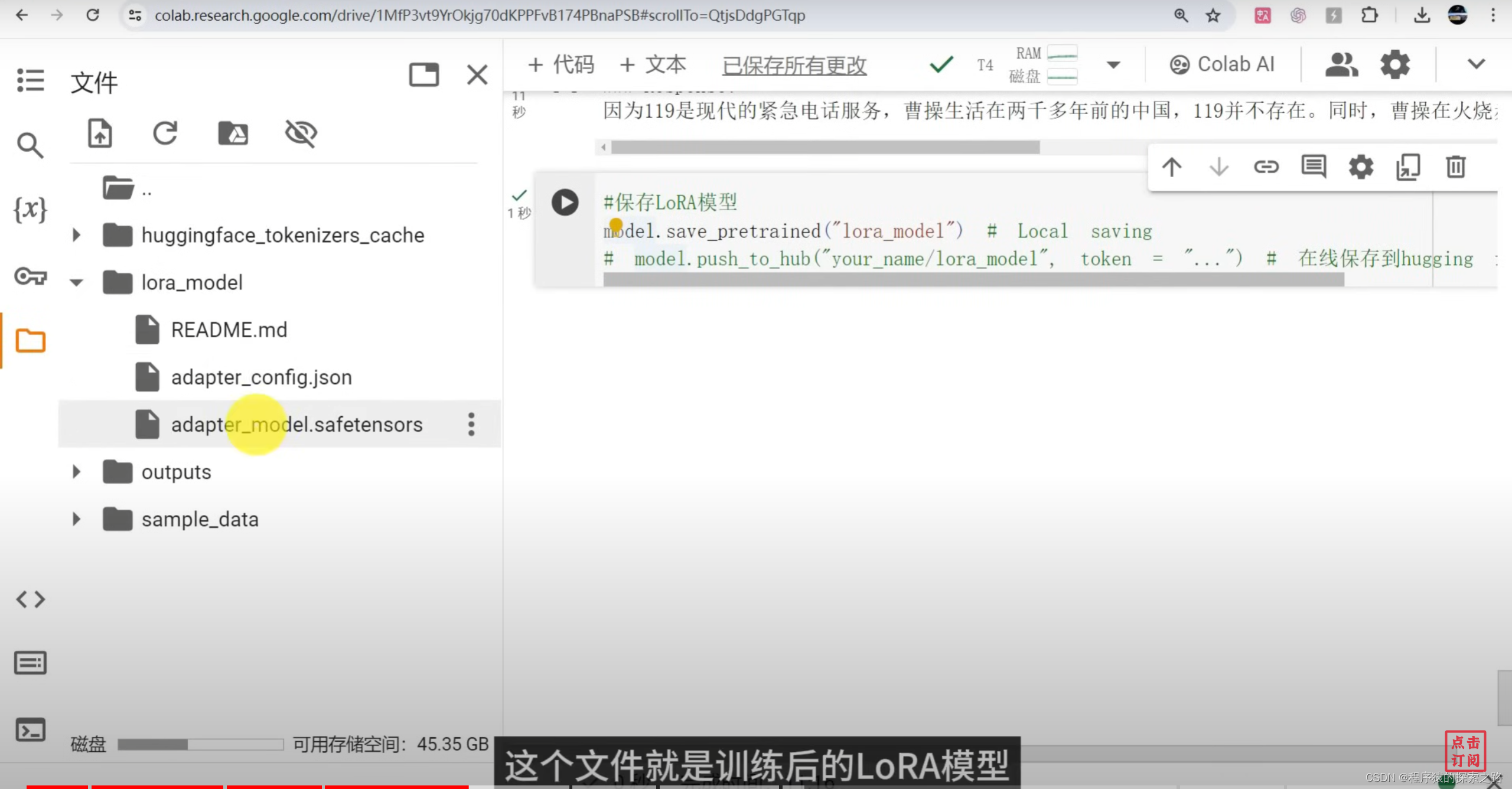
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)#8保存LoRA模型
model.save_pretrained("lora_model") # Local saving
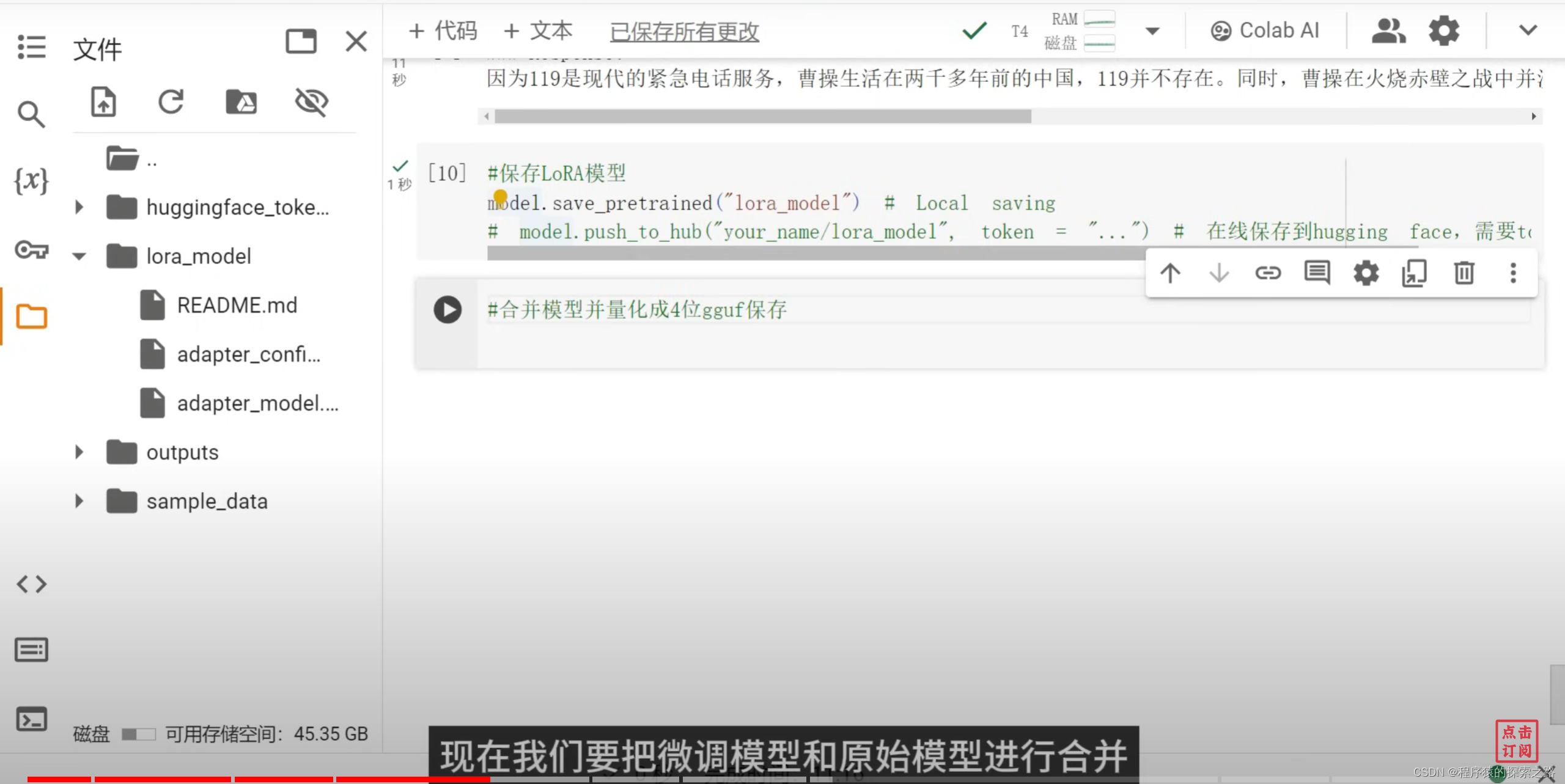
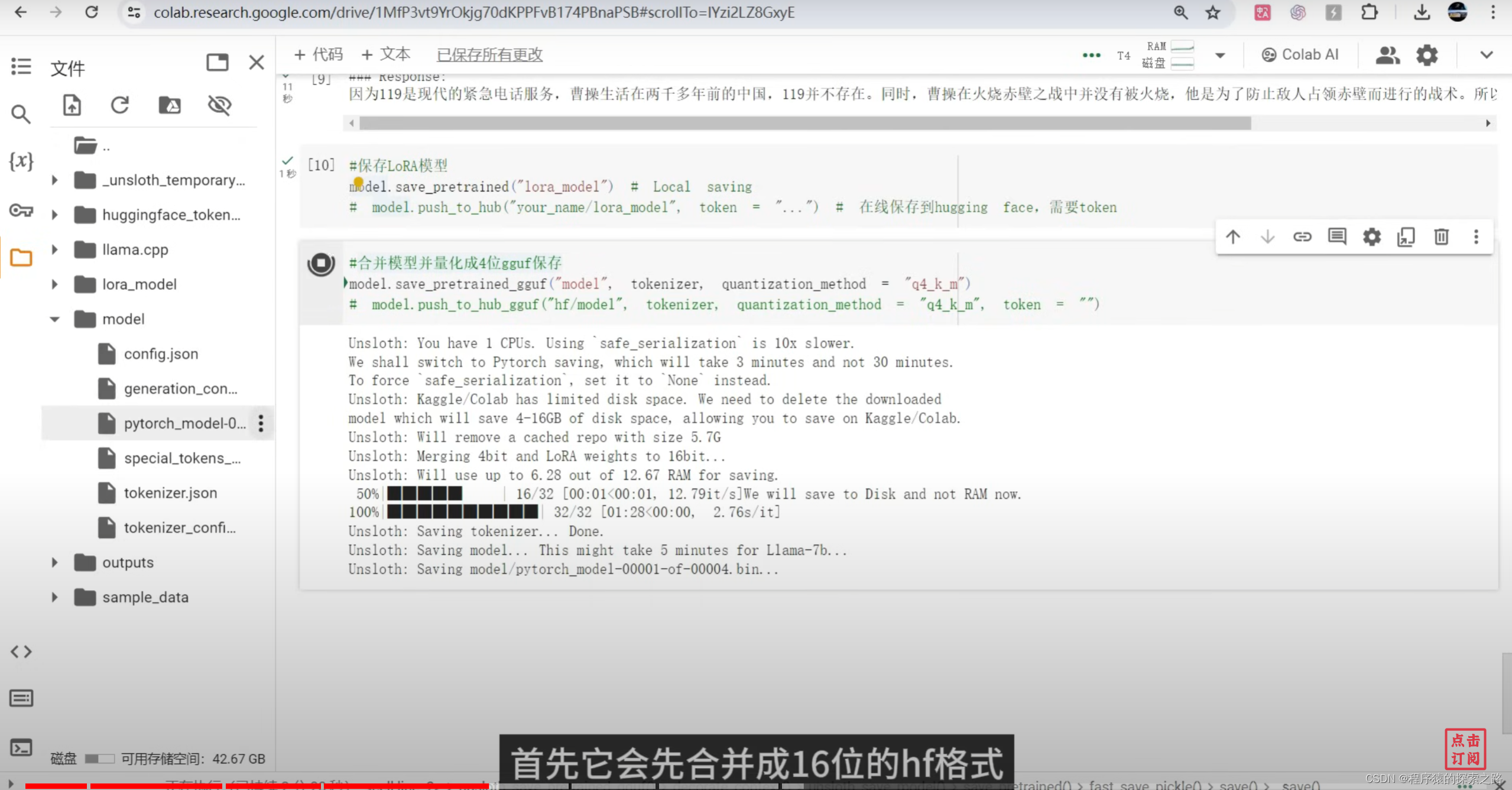
# model.push_to_hub("your_name/lora_model", token = "...") # 在线保存到hugging face,需要token#9合并模型并量化成4位gguf保存
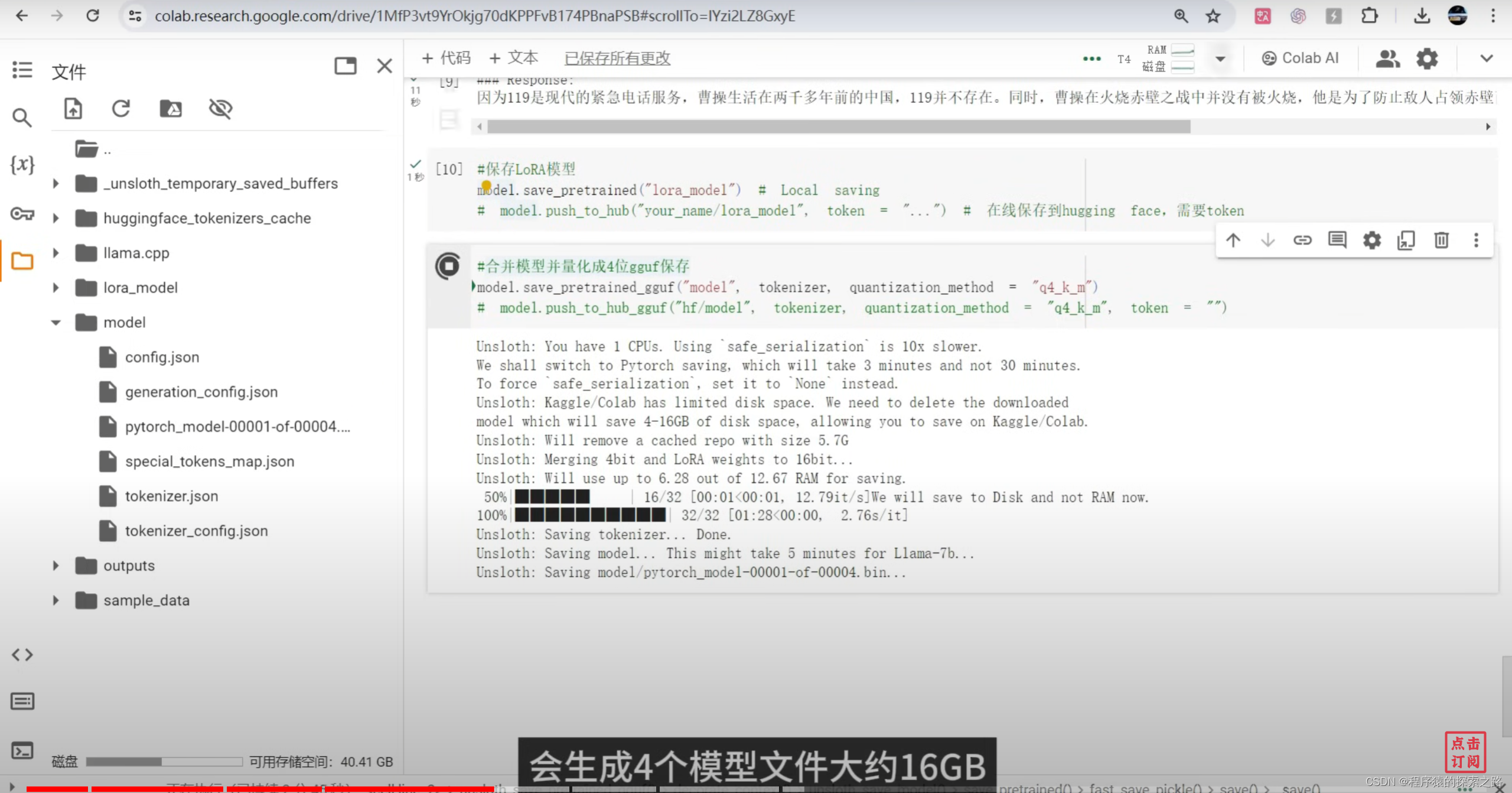
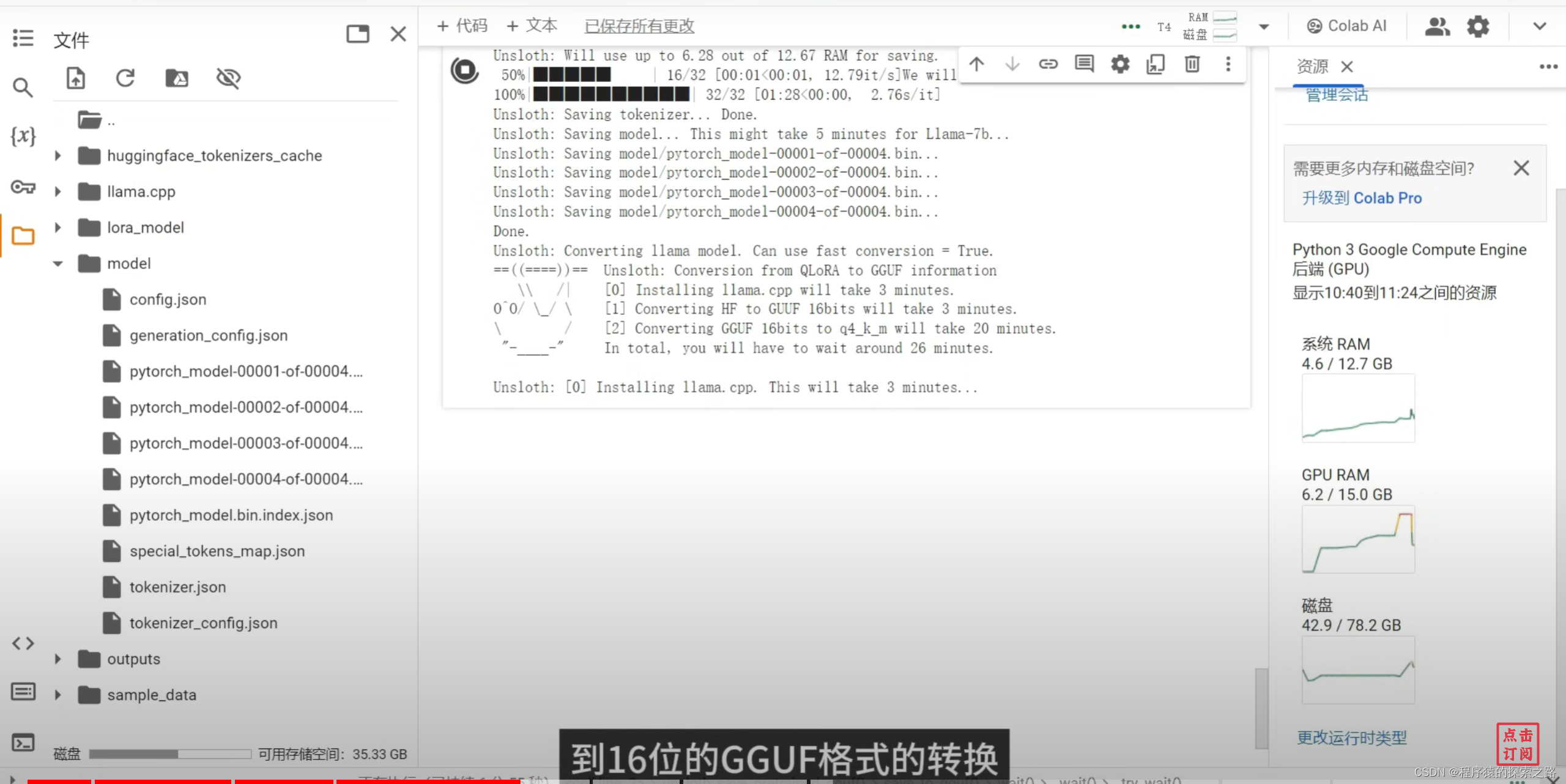
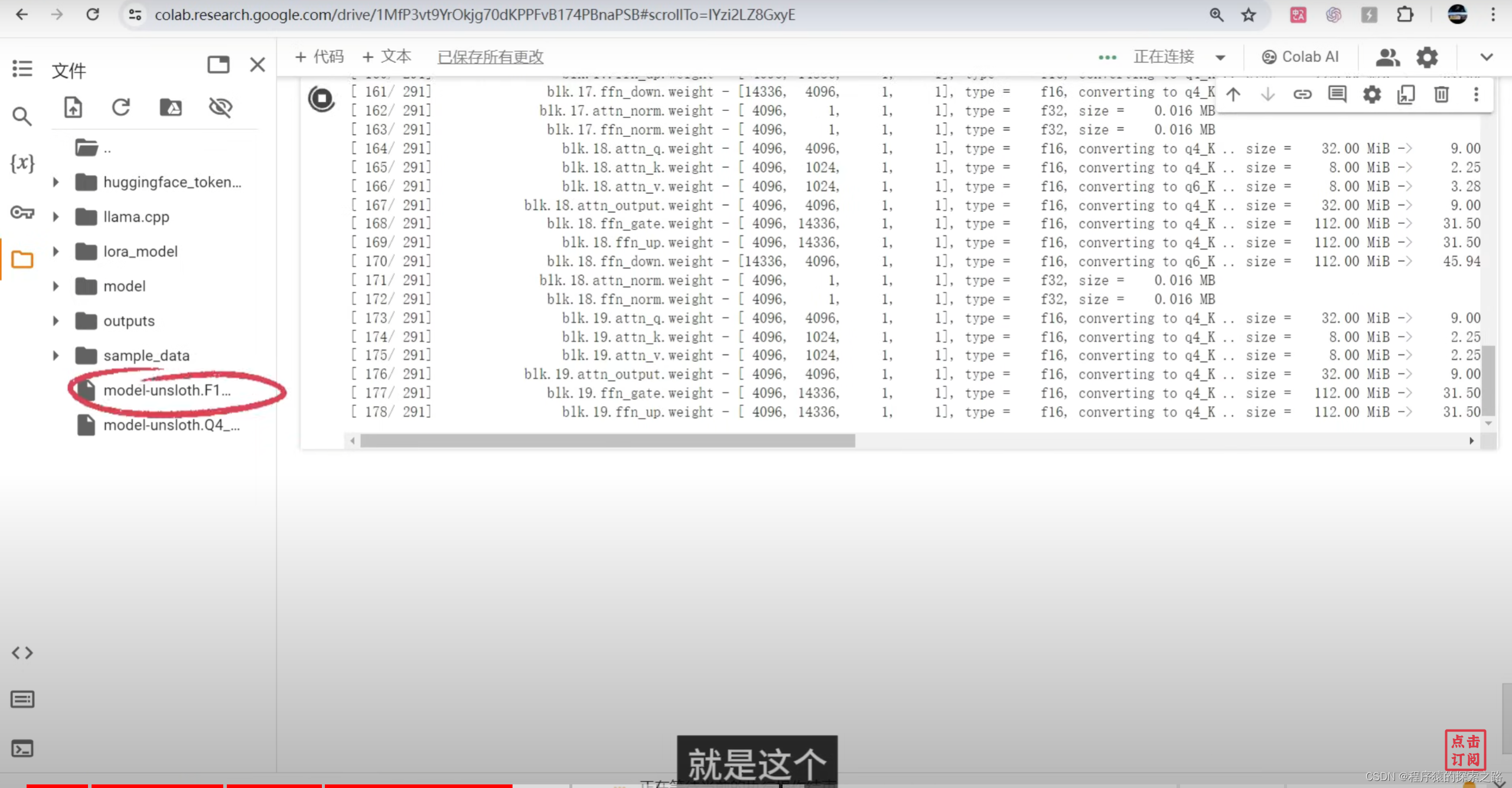
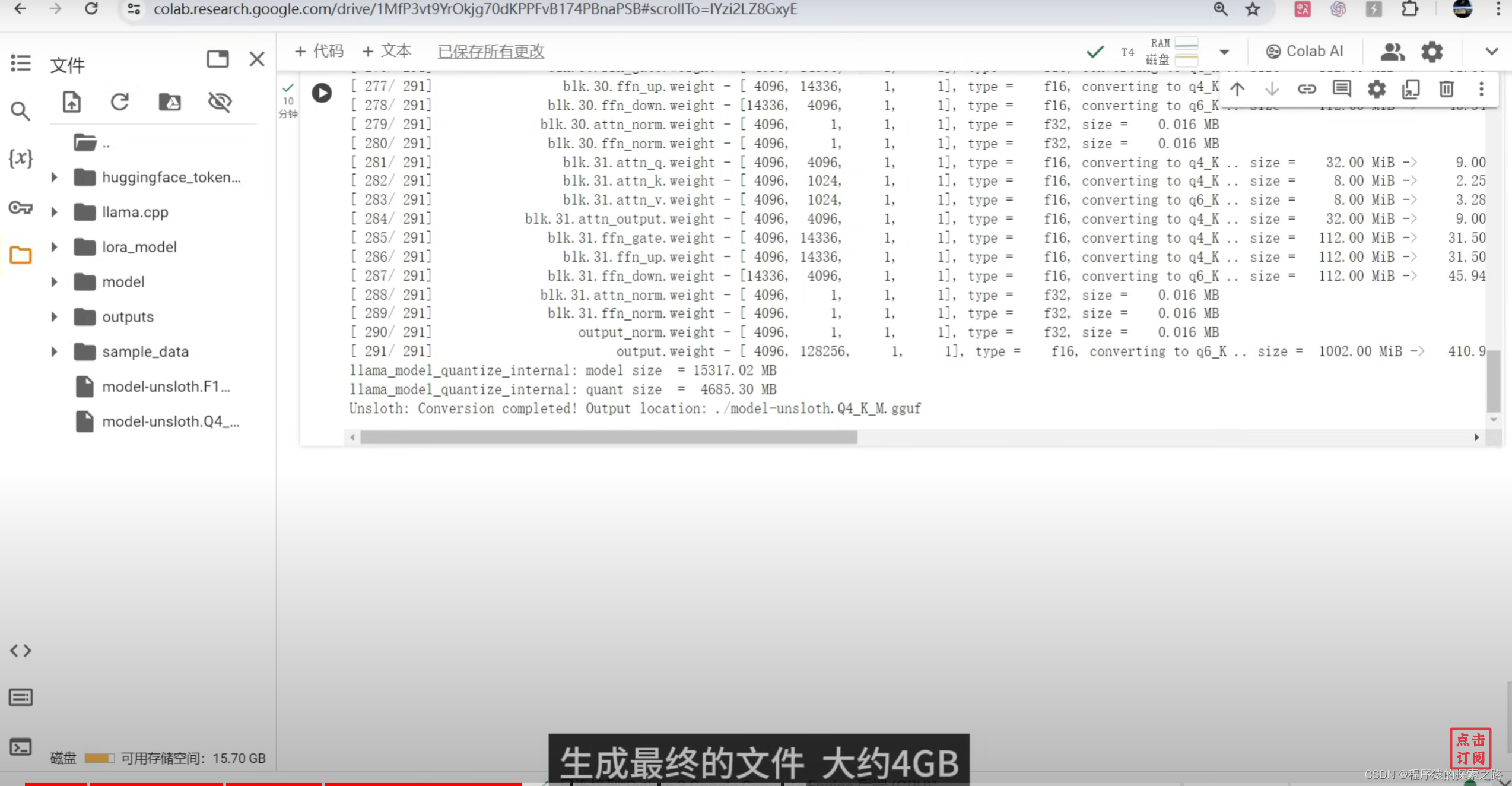
model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
#model.save_pretrained_merged("outputs", tokenizer, save_method = "merged_16bit",) #合并模型,保存为16位hf
#model.push_to_hub_gguf("hf/model", tokenizer, quantization_method = "q4_k_m", token = "") #合并4位gguf,上传到hugging face(需要账号token)#10挂载google drive
from google.colab import drive
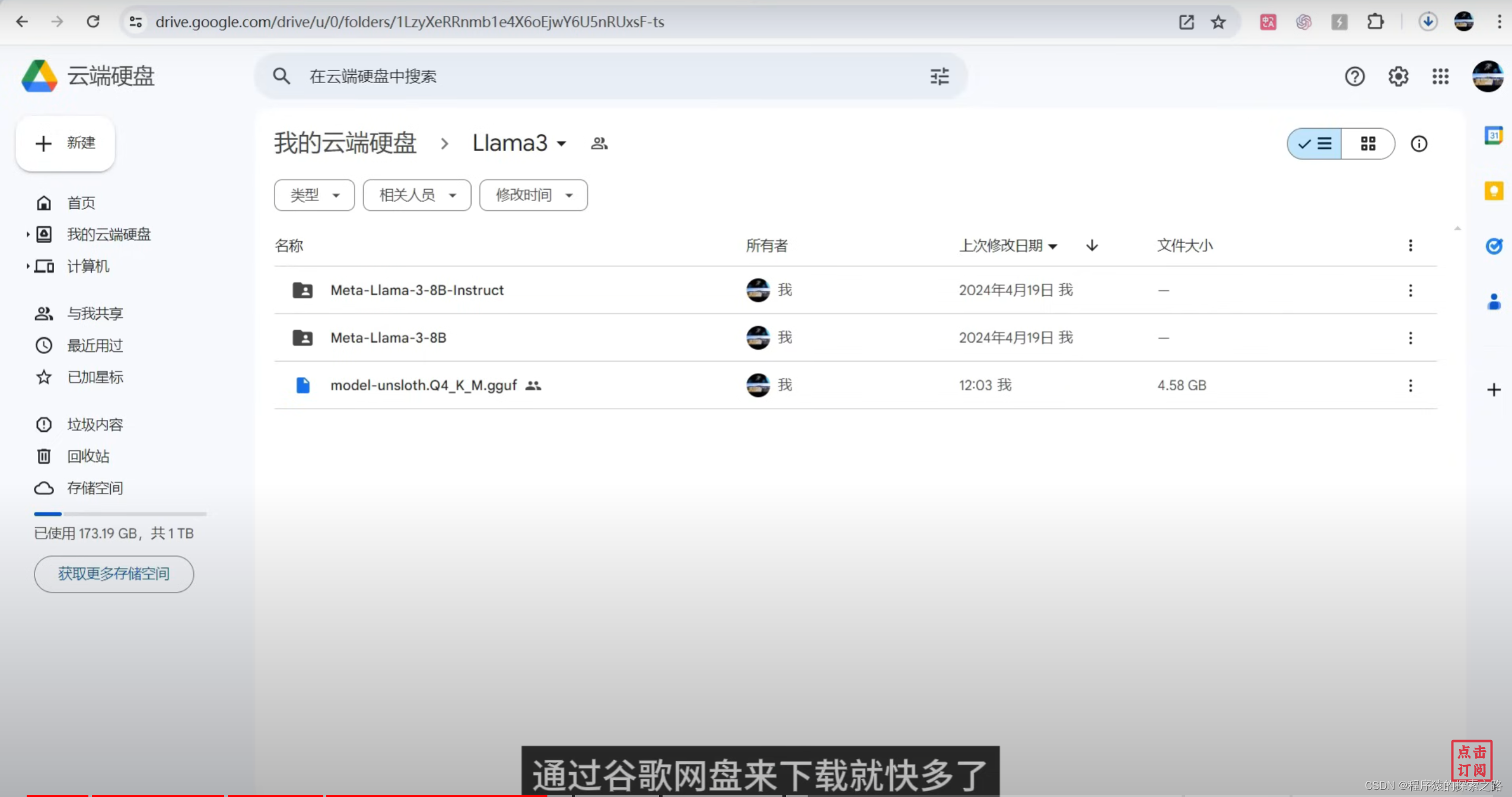
drive.mount('/content/drive')#11复制模型到google drive
import shutil
source_file = '/content/model-unsloth.Q4_K_M.gguf'
destination_dir = '/content/drive/MyDrive/Llama3'
destination_file = f'{destination_dir}/model-unsloth.Q4_K_M.gguf'
shutil.copy(source_file, destination_file)GPT4ALL: