本系列文章主要介绍如何在工程实践中使用卡尔曼滤波器,分七个小节介绍:
二.卡尔曼滤波器开发实践之二: 一个简单的位置估计卡尔曼滤波器
三.卡尔曼滤波器(EKF)开发实践之三: 基于三个传感器的海拔高度数据融合
四.卡尔曼滤波器(EKF)开发实践之四: ROS系统位姿估计包robot_pose_ekf详解
五.卡尔曼滤波器(EKF)开发实践之五: 编写自己的EKF替换robot_pose_ekf中EKF滤波器
六.卡尔曼滤波器(UKF)开发实践之六: 无损卡尔曼滤波器(UKF)进阶-白话讲解篇 也就是本文
七.卡尔曼滤波器(UKF)开发实践之七: 无损卡尔曼滤波器(UKF)进阶-实例篇
-----------------------------------------正文开始-------------------------------------------------
序言:
什么是无损卡尔曼滤波器?
无损卡尔曼滤器(Unscented Kalman Filter)是在卡尔曼滤波和变换的基础上发展而来的,它是利用无损变换(UT)使线性假设下的卡尔曼滤波应用于非线性系统。
KF/EKF算法简单易操作,在工业中有广泛的应用。但是它也存在很多缺点:
- 需要计算非线性模型的雅克比矩阵,计算大,易出错,难得到;
- 忽略高阶项,估计精度大受影响;
- 模型不确定性的鲁棒性很差;
- 在系统达到平稳状态时,将丧失对突变状态的跟踪能力;
- 如果系统的误差传播函数不能很好的话用线性函数来逼近,可能会导致滤波器发散。
- 因为偏导数高阶导数省略问题和雅克比矩阵计算难度的问题,让EKF的效果不是很好。
无损变换(UT)就是针对EKF算法的缺点提出的,UT的主要思想是“近似概率分布要比近似非线性函数更容易”。UT变换计算均值和协方差,通过含有均值和协方差的确定的点集(称作sigma points)来近似概率分布,通过系统的非线性模型,产生繁衍的sigma point,经过选择合适的权值估计均值和协方差。避免了求解雅克比矩阵。这种方法把系统当作“黑盒”来处理,因而不依赖于非线性的具体形式。
UKF和EKF计算复杂度相当,但是UKF具有更高的估计精度,满足了具有各种特殊要求的非线性滤波和控制方面的应用,在实现上也比EKF更为简单。
上面这段话,大家要记住要点:
- UKF是对非线性函数的概率分布(均值μ和方差σ^2)进行近似(sigma points),用一系列确定的样本来逼近状态的后验概率分布;
- EKF 是通过偏导数或连续差分,经雅克比矩阵,对非线性函数( f(x) )本身进行近似(线性化),但是忽略了高阶导数.
再简单回顾下高斯分布:
高斯分布一般指正态分布, 若随机变量X服从一个数学期望为μ、方差为σ2的正态分布或高斯分布,记为N(μ,σ2)。其概率密度函数(PDF)为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。
一维正态分布
若随机变量X服从一个位置参数为μ 、尺度参数为σ的概率分布,且其概率密度函数为
:
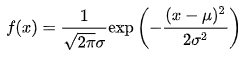
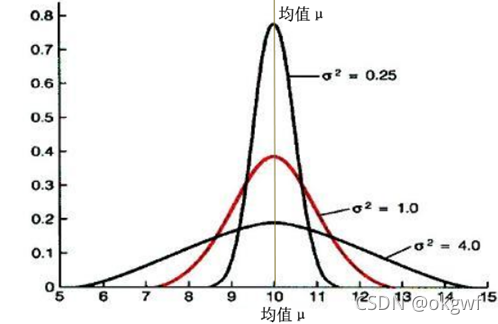
而方差σ2则表示高斯分布的曲线的横向尺度程度.如图:
而实际使用中符合高斯分布的数据形态一般如下:
而对于一个非线性数据分布,可能会是这样:
-----------------------------------------------------------------------------------------------------------
好了, 上面介绍了准备知识,下面我们将进入正题.
------------------------------------------------------------------------------------------------------------
据UKF中系统的噪声的存在方式,将其分为加性噪声算法和隐含噪声算法,对于两种噪声算法,UKF滤波的处理方式分为两种,分别是简化的UKF算法(加性噪声)和扩维的UKF算法(隐含噪声),这里仍然假设噪声是高斯分布的。
加性噪声算法: 我们可以理解为直接加噪声矩阵,就像前几节介绍的KF和EKF中对Q_k和R_k的处理那样.其实也就是那样处理预测过程噪音和传感器噪音的.
隐含噪声算法: 不是直接加噪声矩阵,而是把预测过程噪音直接放到扩维后的系统状态列向量X_k中,把传感器噪音直接放到扩维后的测量值列向量Z_k中, 和系统真实的状态值和测量值一起参与计算.
Note: 本文将以加性噪声算法为例,来介绍UKF的算法思想.
一. 先展示下UKF算法流程公式:
首先,确定系统的状态转移函数(矩阵)和预测协方差矩阵,控制矩阵和控制向量 预测过程噪音矩阵, 状态值转测量值函数和传感器噪音矩阵:
系统状态列向量,维数:n;
:系统测量值列向量,维数m;
: 系统的状态转移函数f(x). 一般就是系统状态转移方程,比如运动学方程等形式. 如果你仍然习惯于KF/EKF中公式(1)的形式,就需要提供
,
,
,也是可以的,各有好处;
:状态值转测量值函数h(x),注意:这里写的仍然是函数,而不是之前的矩阵H_k.
- 准备好预测过程噪音矩阵
(nxn),传感器噪音矩阵:
(mxm).
- 初始化最优估计值列向量:
; 最优预测协方差矩阵
.
Note: 这里f(x),h(x), 已经完全代替之前的状态转移矩阵F_k和雅各比矩阵H_k. 不管f(x)和h(x)线性还是非线性,正如上面所说: UKF是对非线性函数的概率分布(均值μ和方差σ^2)进行近似(sigma points),而不是对非线性函数进行线性化近似.
其次,需要准备算法需要的参数:
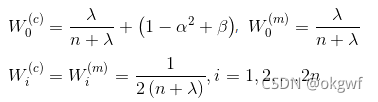
- λ为尺度参数,调整其值可以提高逼近精度,n为状态列向量x_k的维度。
- a的取值一般在[1e−4,1)区间内. 比如我们取: a = 1e-3
- k为第二个尺度参数,通常设置为3或3-n。 n为状态列向量维数,或状态值个数
- β为状态分布参数, 高斯分布的变量. β = 2 时最优. 如果状态变量是标量的话,则 β=0最优
上面参数配置好后,我们知道UKF会生成2n个sigma points点,加上最优期望值列向量自己,共2n+1个.形成一个n x (2n+1)的矩阵Xsig. 矩阵Xsig具有如下结构:
对于第一个sigma points点,求其期望值时,使用:
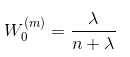
对于第一个sigma points点,求其方差时,使用:
除第一个点以外的其他sigma points点, 求其期望或求方差都用:
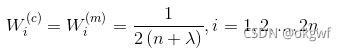
以上,必要的参数准备完毕.
以下是我总结的UKF算法公式.
| 第1步 | |
| 第2步 | 或 |
| 第3步 |
|
| 第4步 | |
| 第5步 | |
| 第6步 | |
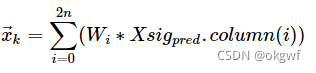
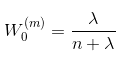
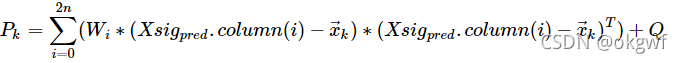
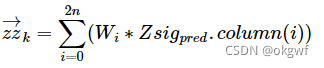

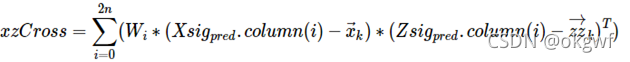
上述,根据我对UKF的理解,编的公式, 不, 是编辑的公式, 不知道大家是否能理解.
二. 白话讲解UKF的算法思想及6个步骤.
根据方差σ^2和标准差σ概念的定义, 标准差σ是各数据偏离平均值(均值)的距离的平均数. 而均值就是最理想中心值, 在高斯分布中用μ表示分布的均值.
用高斯分布曲线表示一般是这样:
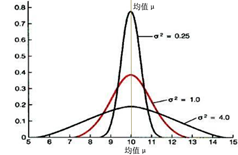
但通过这样形态来理解UKF算法,比较抽象. 我们用高斯分布的时域图来表示(因为UKF思路是把非线性分布近似为线性分布.).
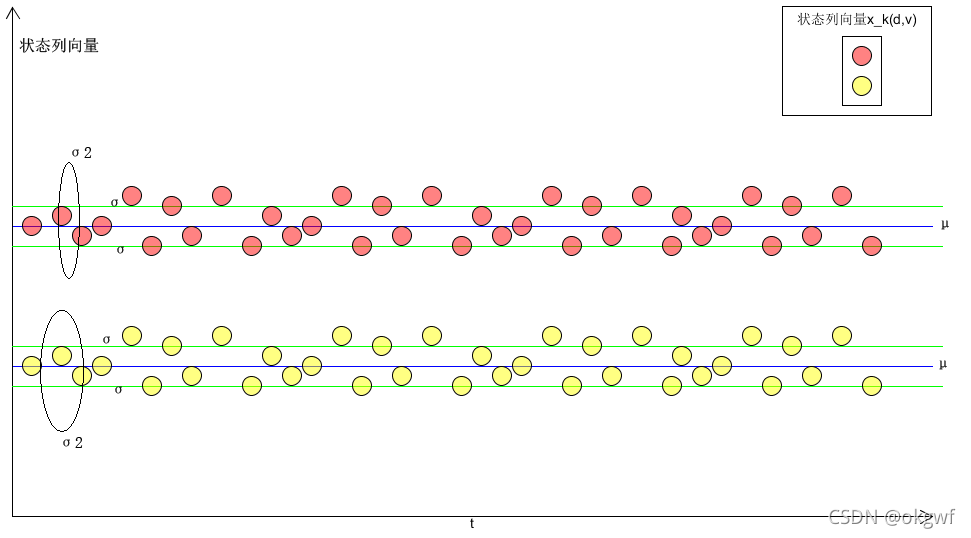
如图: 对于我们的状态列向量X_k(d,v),d:表示位移,v:表速度.当状态向量X_k在我们的kf系统中状态转移时, 假如它们都符合高斯分布,那么状态值,d和v分量都有自己的分布: 以位置参数为:μ 、尺度参数为:σ的概率分布N(μ,σ2).
不管各自的方差在分布中具体是个圆还是个椭圆,但它总有个标准差σ. 而标准差是各数据偏离平均值(均值)的距离的平均数. 以下我就以上图为依据,介绍下UKF算法.
第(0)步, 任何时候我们总有一个最优估计值和最优协方差矩阵,哪怕它只是初始状态(各个状态分量都有自己的均值μ和方差σ2).
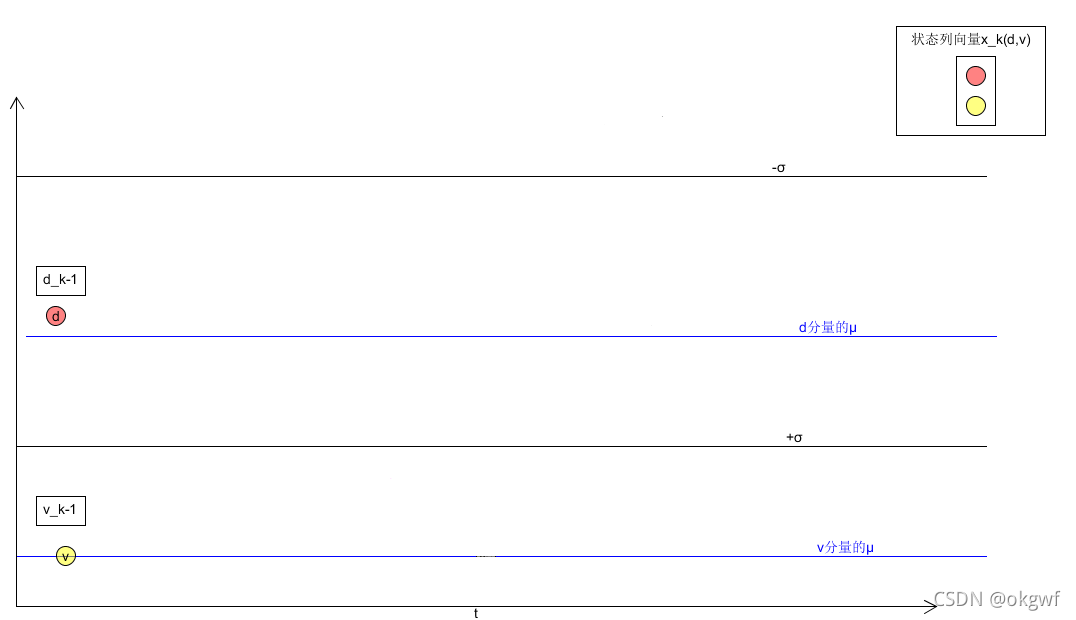
第(1)步, 生成sigma point矩阵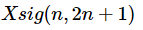 ,公式如下:
,公式如下:
我们对当前状态x_k-1生成的Xsig矩阵,具有n行an+1列, 每列对应一个类似状态向量X_post 的列向量.第0列是X_post本身,第1至n列是对应于均值μ上方约等于(-σ)若干倍位置的n个sigma points(没有point是要理解为一个类似X_post的列向量);第n+1至2n列是对应于均值μ下方约等于σ若干倍位置的n个sigma points.
以上面图为例,Xsig矩阵大致结构为:
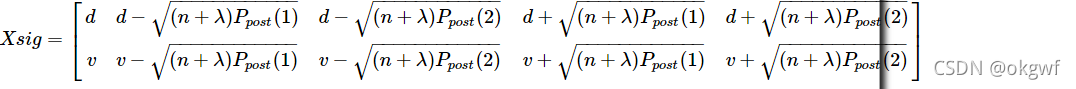
生成sigma points Xsig矩阵后,我们通过系统状态列向量在时域状态转移来看: (注: 为了方便分析我们放大了状态分量位移d. 图中红色部分). 而分量速度v其实也在做同样的事.):
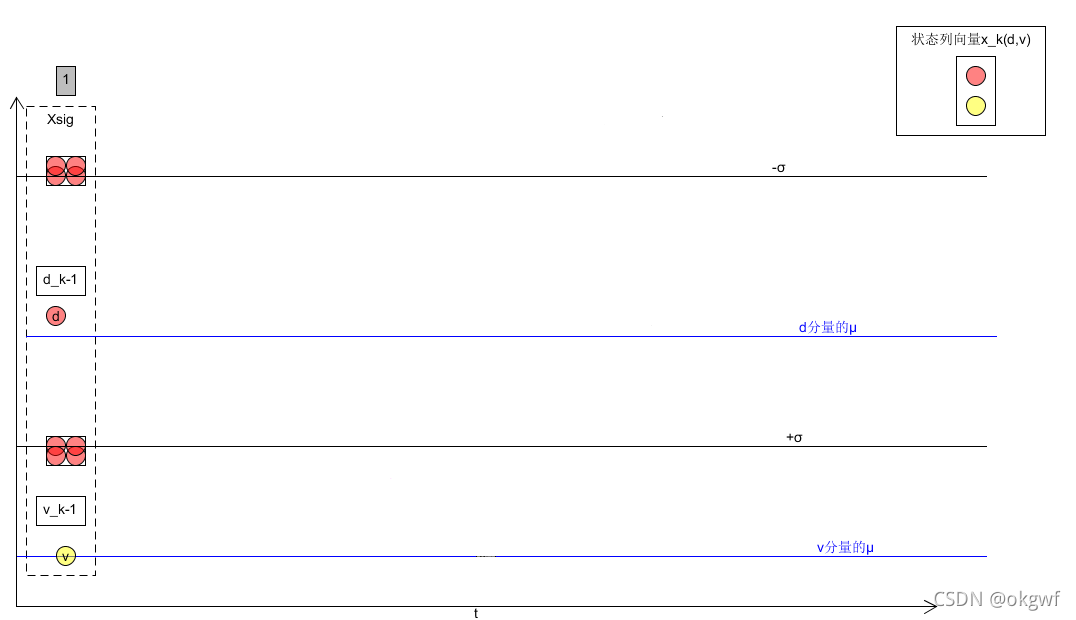
如图: 现在我们有2n+1个sigma point了(每个sigma point都是一个(d,v)列向量,图中只画出d分量的).
第(2)步, 对生成的矩阵Xsig中每个sigma points 按照状态转移方程进行预测,得到矩阵Xsig_pred.你可以只用系统状态方程,也可以用EKF中熟悉的公式(1): x_k = F_k * x_k-1 + B_k * u_k (B_k * u_k按需要,非必需).
或
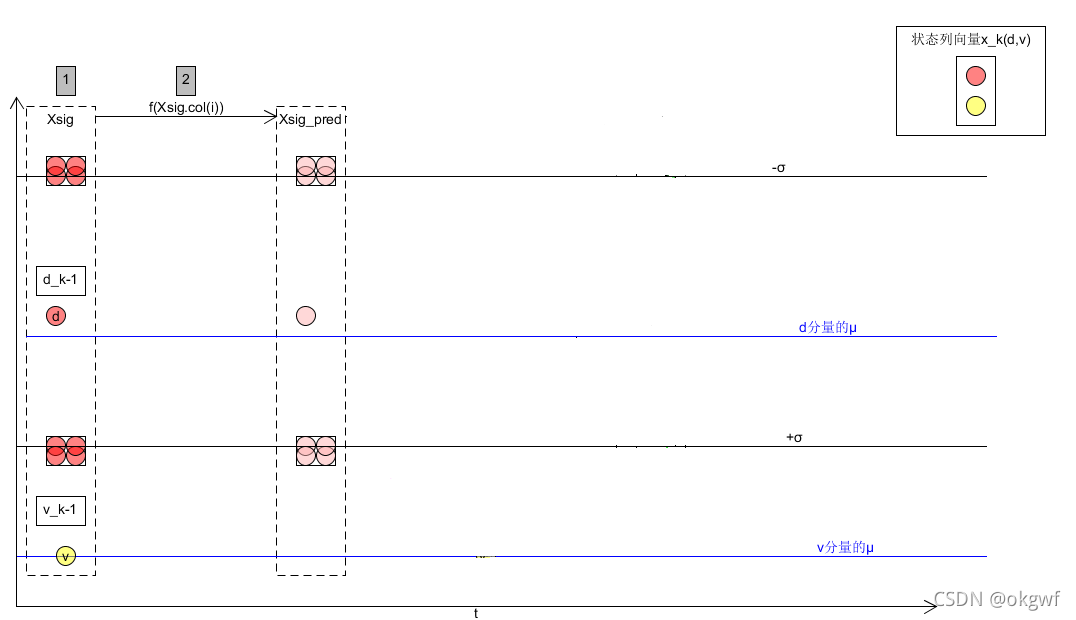
如图: 我们将得到经系统状态转移方程预测到新的2n+1个(d,v) sigma point. 得到新的矩阵Xsig_pred.
第(3)步,对预测出的矩阵Xsig_pred中每个(d,v)向量,按照预先设置的权值列向量W,计算其先验估计值x_k和先验协方差矩阵P_k.
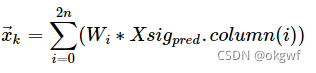
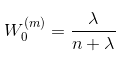
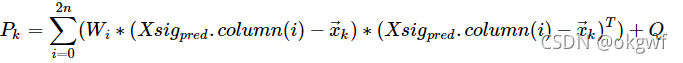
当i=0时:

第(4)步,根据第(2)步得到的Xsig_pred, 经状态值转测量值函数h(x),(看我们这里说h(x)是函数),转换2n+1个sigma预测测量值矩阵Zsig_pred:
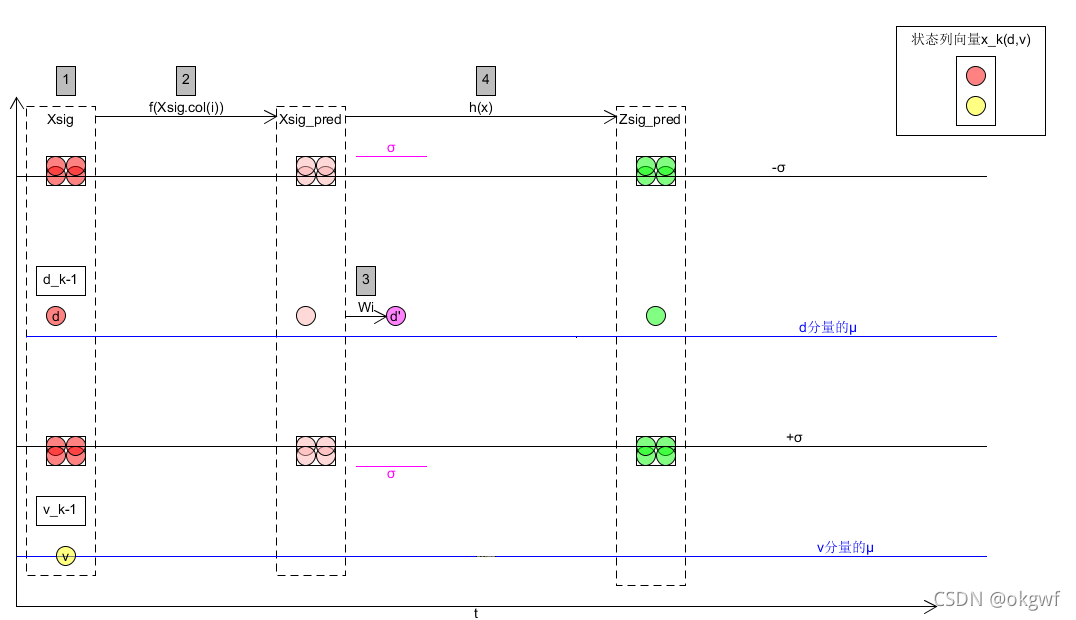
我们把从预测的2n+1个sigma point,经状态值转测量值函数h(x),得到了预测测量值m行,2n+1列的Zsig_pred. 这里要主要你的h(x)函数组,保证最终生成和测量值列向量行数m一样的Zsig_pred.
第(5)步, 把上一步得到的n行2n+1列的Zsig_pred,按照预先设置的权值列向量W,计算其估计值向量zz_k和协方差矩阵ZP_k(这一步和第3步类似, 但要主要对第0列设置权值注意事项,和预测先验估计值是不一样的):
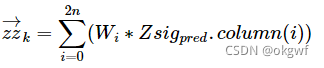
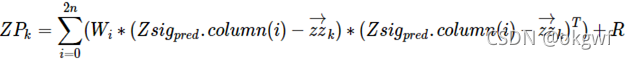
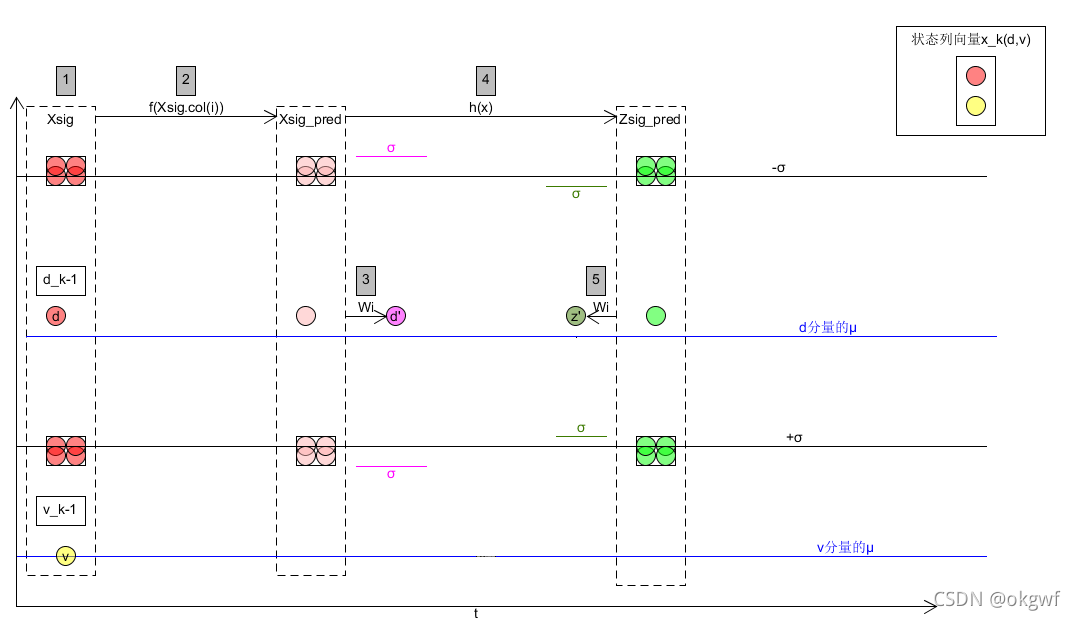
到这里,我们得到一个预测的测量值zz_k(图中绿色圆圈z')和先验协方差矩阵ZP_k(图中绿色σ).
第(6)步, 现在我们已经有了三个分布.
第一个分布: 先验估计值x_k和先验协方差矩阵P_k;
第二个分布: 预测测量值zz_k和预测测量值协方差矩阵ZP_k.
第三个分布: 测量值z_k和测量值噪音协方差矩阵.
而算法通过一个cross-correlation 公式对预测的先验估计值和预测测量值之间的差来平衡kalman gain,其中细节我也有待弄清楚,但有公式在套用即可.
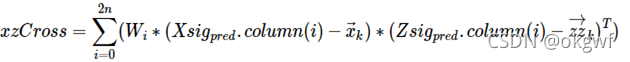
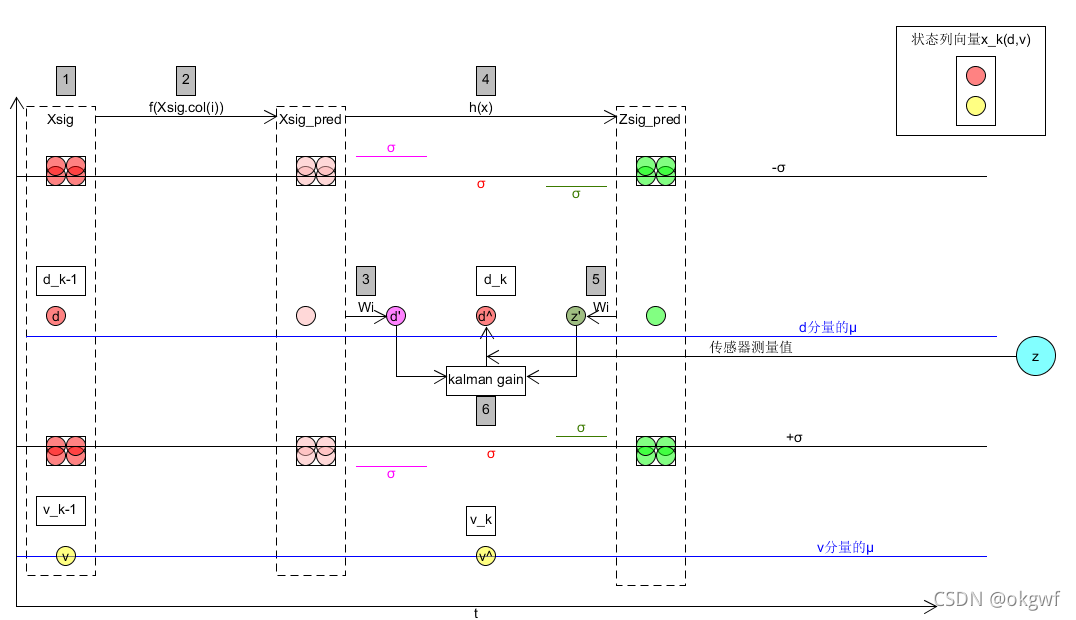
如图: 我们得到了新的最优估计值x_post(d_k,v_k)和最优协方差矩阵P_post. Note: 请忽略各点在水平时域的间距,只是为了演示步骤.
个人感觉第(6)步总思想和KF/EKF后三个方程的思路很类似: 我们有2个高斯分布N1(μ1,(σ)^2), N2(μ2,(σ_2)^2), 对同一个状态进行了预测,那我们是应该更相信分布N1还是更相信分布N2呢? 最好的办法就是求两个分布的交集. 也就是把两个分布的高斯方程相乘得到一个新的分布,即N1(μ1,(σ)^2) * N2(μ2,(σ_2)^2) = N3(μ3,(σ_3)^2)这个新的分布就是最优估计分布. 如下来自网上图:
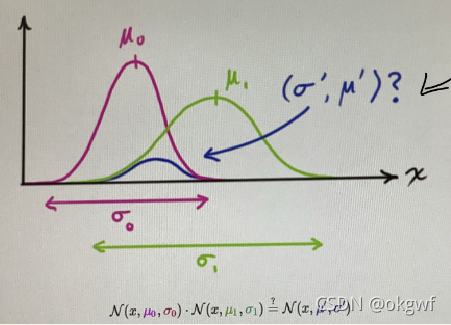
推导工程大致如下:

进一步可以推导出:

进一步手工鼠标画笔推导:
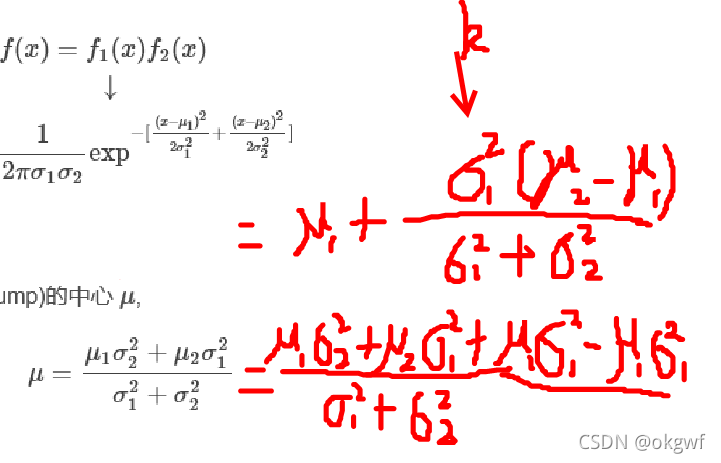

上面两个推导,我们设置公共项为K,有:
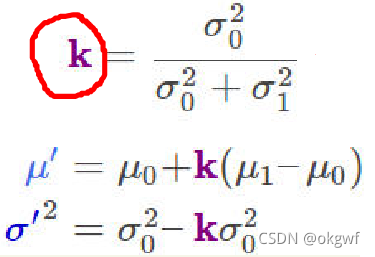
当然,这是对KF/EKF五大公式的推导,但对比UKF最后一步.很是相似,可见也是利用了两个高斯分布相乘求交集的一种推导.
写的不好,请多包涵!
有不足之处欢迎留言指正,共同进步,谢谢!
另外别忘了点个赞哦.
参考:
无损卡尔曼滤波器(Unscented Kalman Filter, UKF)#附MATLAB代码_小伟啊的博客-CSDN博客