使用Stream流在处理大批量数据集合时效率更高,因为Steam流内部使用了并行流的概念。
一、Lambda表达式
1、基本格式:
(参数列表) -> {执行代码}
- 接口只有一个抽象方法需要重写时可以直接简化
- 在idea中,调用方法先写出匿名内部类,可以alt+enter转成lambda表达式
例一:
一般在创建线程并启动时使用匿名内部类的写法:
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("创建线程");
}
}).start();//启动线程
Java8可以使用Lambda的格式对其进行修改:
new Thread(()->{
System.out.println("创建线程");
}).start();//启动线程
例二:
请调用下面这个方法:
public static void printNum(IntPredicate predicate) {
int[] arr = {1,2,3,4,5,6};
for (int i : arr){
if (predicate.test(i)){
System.out.println(i);
}
}
}
- 普通写法:使用匿名内部类调用方法
printNum(new IntPredicate() {
@Override
public boolean test(int value) {
return value%2==0;
}
});
- JAVA8写法:
printNum((int value)->{
return value%2==0;
});
简写成:
printNum(value -> value%2==0);
例三:
现有涉及泛型接口的方法如下,其中Function是一个接口,先使用匿名内部类调用该方法。
public static <R> R typeConver(Function<String,R> function) {
String str = "1234";
R result = function.apply(str);
return result;
}
- 普通匿名内部类调用:(举例泛型指定成Integer类型)
Integer result = typeConver(new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.valueOf(s);
}
});
- Java8方式调用:(举例泛型指定成String类型)
String str1 = typeConver((String str) -> {
return str+"567";
});
简写成:
String str1 = typeConver(str -> str+"567");
例四:
现有方法定义如下,其中intConsumer是一个接口。调用该方法
public static void foreachArr(IntConsumer consumer) {
int[] arr ={1,2,3,4,5,6,7,8};
for (int i : arr) {
consumer.accept(i);
}
}
- 普通匿名内部类方式调用:
foreachArr(new IntConsumer() {
@Override
public void accept(int value) {
System.out.println(value);
}
});
- Java8lamdba方式:
foreachArr((int i)->{
System.out.println(i);
});
简写成:
foreachArr(i -> System.out.println(i));
2、简写规则
- 参数类型可以直接省略
- 方法体只有一句代码是大括号return和唯一句代码的分号可以省略
- 方法只有一个参数时,小括号可以省略
typeConver((String str) -> {
return str+"567";
});
简写成:
typeConver(str -> str+"567");
二、Stream流
使用Stream可以用来对集合或数组进行链状流式的操作。
注意事项:
- Stream流必须以终结操作结束,不然中间操作不会生效。
- 流是一次性的,一旦一个流经过一个终结操作后,这个流不能再被使用
- 不会影响原数据。(除非对流的原始对象直接操作)
1、案例:
现有这样一个集合,针对这个集合进行操作:
@Data
@NoArgsConstructor//生成一个无参数的构造方法
@AllArgsConstructor// 会生成一个包含所有变量的构造方法
@EqualsAndHashCode //用于后期去重使用
public class Author {
private long id;
private String name;
private Integer age;
private String intro;
private List<Book> books;
}
@Data
@NoArgsConstructor//生成一个无参数的构造方法
@AllArgsConstructor// 会生成一个包含所有变量的构造方法
@EqualsAndHashCode //用于后期去重使用
public class Book {
private long id;
private String name;
private String category;
private Integer score;
private String intro;//简介
}
public class Test {
private static List<Author> getAuthors() {
//数据初始化
Author author1 = new Author(1L,"1",11,"....",null);
Author author2 = new Author(2L,"2",22,"...",null);
Author author3 = new Author(3L,"3",33,"...",null);
Author author4 = new Author(4L,"4",44,"...",null);
//书籍列表
List<Book> book1 = new ArrayList<>();
List<Book> book2 = new ArrayList<>();
List<Book> book3 = new ArrayList<>();
book1.add(new Book(1L,"龙族","123",88,"。。。"));
book1.add(new Book(2L,"繁华","123",90,".。。"));
book2.add(new Book(3L,"渣渣","123",78,"。。。"));
book2.add(new Book(3L,"龙马","123",91,".。。"));
book2.add(new Book(4L,"牛马","123",85,".。。"));
book3.add(new Book(5L,"Java","123",95,"。。。"));
book3.add(new Book(6L,"Python","123",70,".。。"));
book3.add(new Book(6L,"C**","123",98,".。。"));
author1.setBooks(book1);
author2.setBooks(book2);
author3.setBooks(book3);
author4.setBooks(book3);
List<Author> authorList = new ArrayList<>(Arrays.asList(author1,author2,author3,author4));
return authorList;
}
}
例如:打印所有年龄小于18的作家的名字,并注意集合元素去重
public static void main(String[] args) {
List<Author> authors = getAuthors();
authors.stream()//把集合转换成流
.distinct()
.filter(author -> author.getAge() < 18)
.forEach(author -> System.out.println(author.getName()));
}
2、常用操作:
2.1创建流:
单列集合:集合对象.stream()
List<Author> authors = getAuthors();
Stream<Author> stream = authors.stream();
数组:Arrays.stream(数组) 或者使用 Stream.of创建
Integer[] arr = {1,2,3,4};
Stream<Integer> stream = Arrays.stream(arr);
Stream<Integer> stream = Stream.of(arr);
双列集合:map.entrySet().stream()转换成单列集合后再创建
Map<String,Integer> map = new HashMap<>();
map.put("张三",19);
map.put("张er",17);
map.put("li三",22);
Stream<Map.Entry<String,Integer>> stream = map.entrySet().stream();
2.2中间操作:
1、filter():
过滤Stream中所有不符合条件的元素(保留符合条件的元素)。例如:
List<Author> authors = getAuthors();
authors.stream()//把集合转换成流
.filter(author -> author.getAge() < 18) //保留年龄小于18的元素
.forEach(author -> System.out.println(author.getName()));
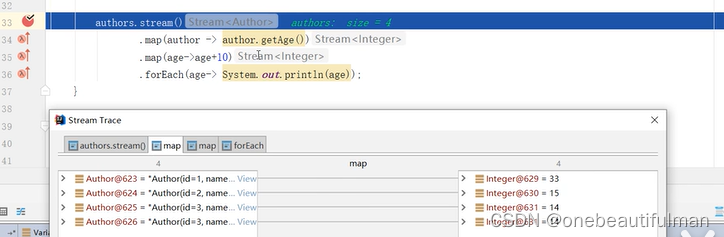
2、map():
对流中的元素转换或计算:
List<Author> authors = getAuthors();
authors.stream()//把集合转换成流
.map(author -> author.getAge()) //转换:将Stream流的Author元素转成int元素
.map(age -> age+10) //计算:将Stream流的Age元素都加10
.forEach(author -> System.out.println(author));
3、distinct():
该方法用于去除流中所有重复的元素(判断元素重复的标准是使用equals()比较返回true)。这是一个有状态的方法。
注意:distinct()方法依赖Object的equals方法,所以需要注意可能重写equals方法
List<Author> authors = getAuthors();
authors.stream()//把集合转换成流
.distinct()
.forEach(author -> System.out.println(author));
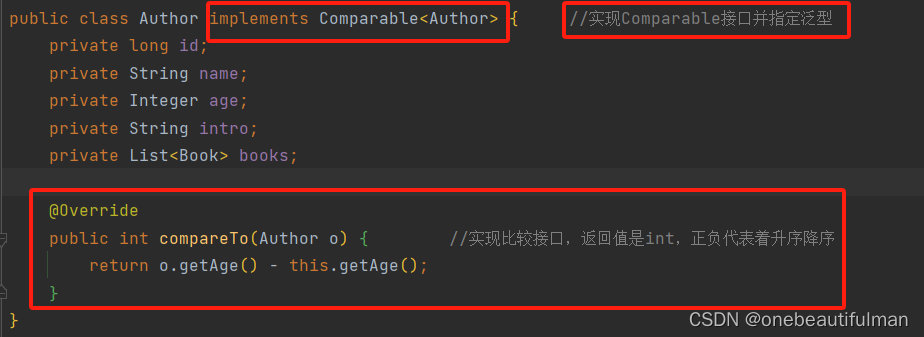
4、sorted:
对流中的元素进行排序
**空参sorted():**需要实现Comparable接口
List<Author> authors = getAuthors();
authors.stream()
.distinct()
.sorted()
.forEach(author -> System.out.println(author.getName()));
注意:sorted()会将流中的元素转成Comparable类型,需要流中的元素实现Comparable接口。而升序降序取决于实现Comparable接口中的compareTo方法。
有参sorted():
有参sorted()的升序降序取决于lambda中{}的比较正负,无需实现Comparable接口
List<Author> authors = getAuthors();
authors.stream()
.distinct()
.sorted((o1, o2) -> o1.getAge() - o2.getAge())
.forEach(author -> System.out.println(author.getName()));
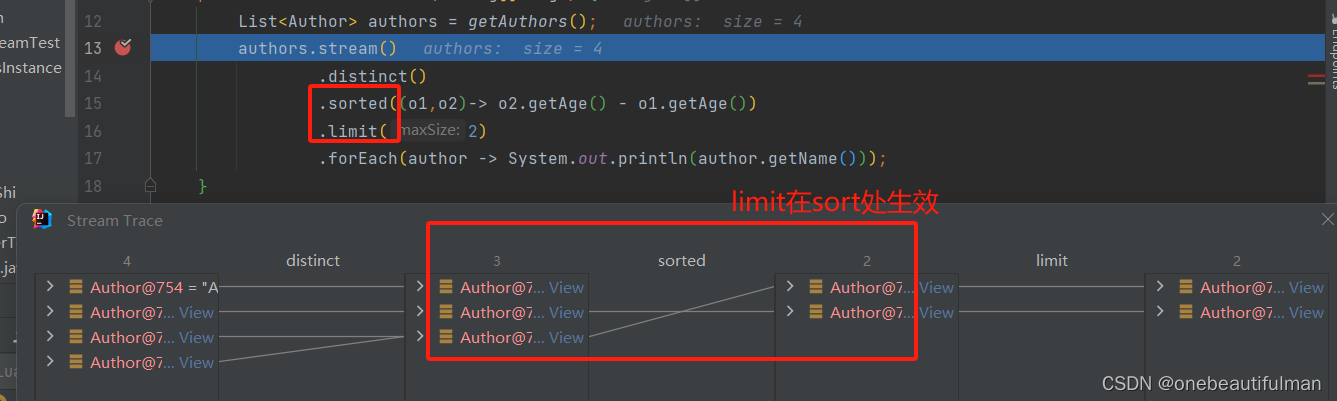
5、limit(long maxSize):
设置流的最大长度,比如只需要打印流中最大的三个元素就可以依次去重、排序、限制 得到。
6、skip(int类型)
跳过流中的前n个元素,返回剩下的元素
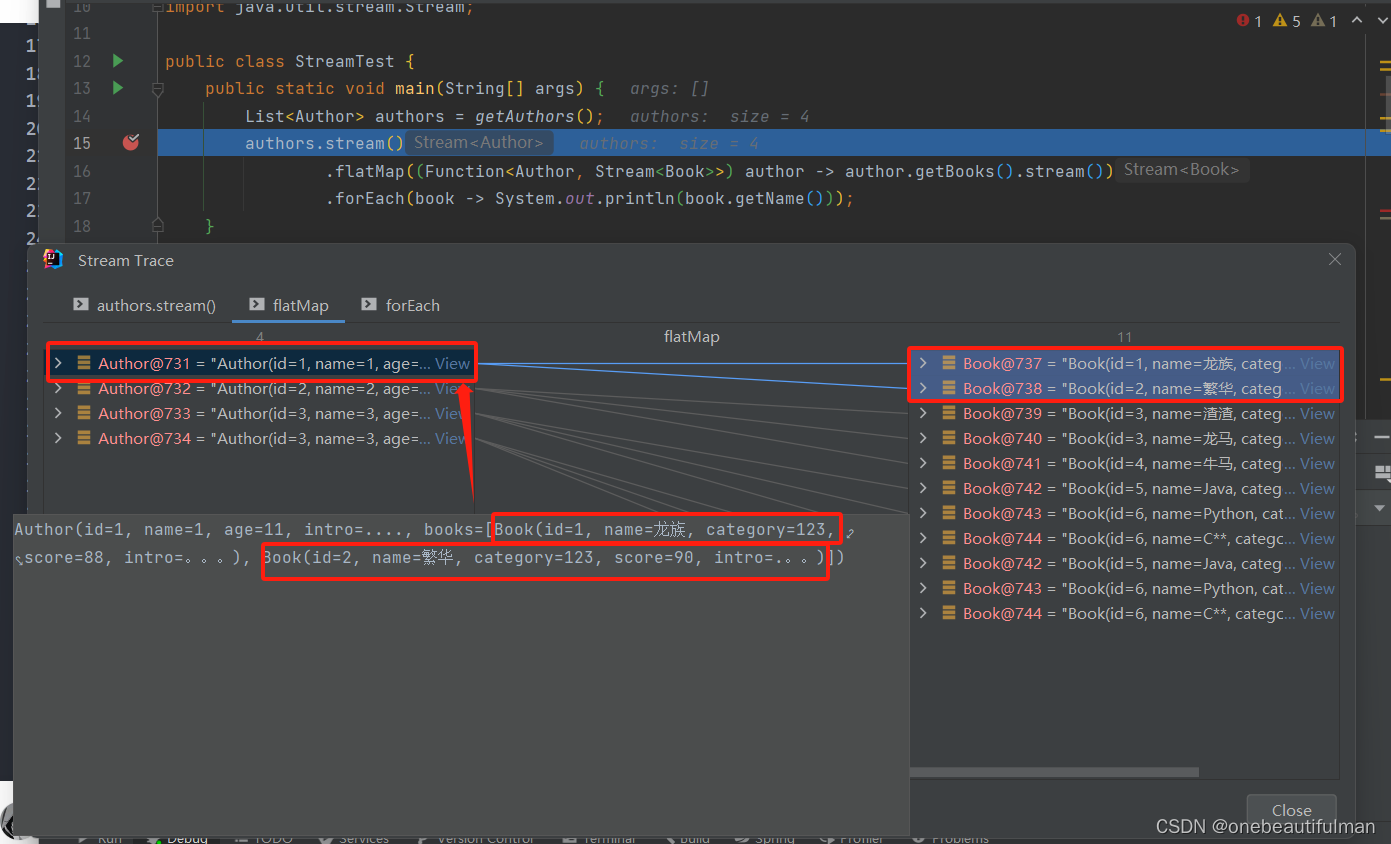
7、flatMap(元素->元素.getList().stream())
- 将流中每个元素的多条集合扩展成一个数据流,适合处理多重集合List<List<>>类型。
- 注意:代码最后要转换成Stream类型
2.3终结操作
Stream流必须以终结操作结束,不然中间操作不会生效。
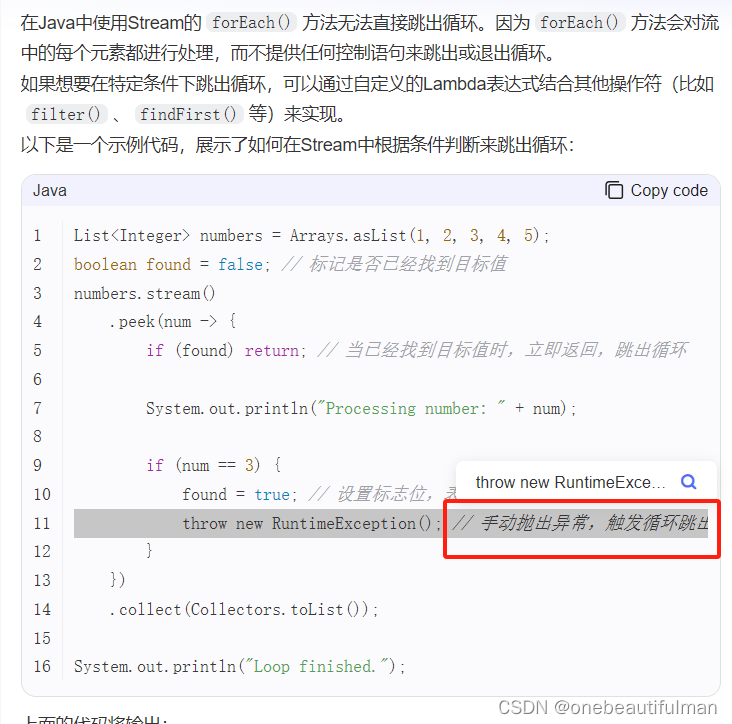
1、forEach():
遍历流中所有元素,对每个元素执行action。想要中断只能抛出异常(官方)
2、toArray():
将流中所有元素转换为一个数组。
3、count():
返回流中所有元素的数量。
4、min()或max()
返回流中所有元素的最小值或最大值,方法底层使用的是reduce方法。注意:
- 必须转换成int类型的流才可以比较,
- 方法返回值是 Optional类型
Optional<Integer> max = Stream<Integer>
.min((s1,s2) -> s1 - s2);
5、collect
使用Collectors类把流中的元素转成一个集合类型。
例子:
- 转成List集合:.collect(Collectors.toList());
//获取一个存放所有作者名字的List集合:
List<String> names = authors.stream()
.map(author -> author.getName())
.collect(Collectors.toList());
- 转成Set集合:.collect(Collectors.toSet());
//获取一个存放所有作者名字的Set集合:
Set<Book> books = authors.stream()
.flatMap(author -> author.getBooks().stream())
.collect(Collectors.toSet());
- 转成Map集合:.collect(Collectors.toMap())。注意:key不可重复
获取一个Map集合,key为作者名,value为List<Book>
Map<String,List<Book>> map = authors.stream()
.distinct()
.collect(Collectors.toMap(author -> author.getName(), author -> author.getBooks()));
6、Match匹配
- anyMatch():判断流中是否至少包含一个元素符合条件,返回值为Boolean
Boolean bl = authors.stream()
.anyMatch(author -> author.getAge() < 10);
- allMatch()判断流中是否全部元素都符合条件,返回值为Boolean
Boolean bl = authors.stream()
.allMatch(author -> author.getAge() < 99);
- noneMatch():判断流中是否全部元素都不符合条件,返回值为Boolean
Boolean bl = authors.stream()
.noneMatch(author -> author.getAge() < 99);
7、findAny()
返回流中的任意一个元素。
8、findFirst():
返回流中的第一个元素。
9、reduce归并:
对流中的数据按照指定的计算方式计算出一个结果。reduce的作用是把stream中的元素给组合起来,我们可以传入一个初始值,它会按照我们的计算方式依次拿流中的元素和在初始化值的基础上进行计算,计算结果再和后面的元素计算。
9.1、reduce(T identity, BinaryOperator accumulator):
格式:reduce(初始化值 , (参数1,参数2) -> {参数计算方式} )
注意:
- 传入初始化值
- 定义计算方式
- 注意reduce计算之前需要将流中元素map转换成int类型
//使用reduce求所有作者的年龄的和
Integer result = authors.stream()
.map(author -> author.getAge()) //转换成int类型
.reduce(0, (integer, integer2) -> integer + integer2);
//使用reduce求所有作者中年龄的最大值。注意初始值必须是最小的
Integer max = authors.stream()
.map(author -> author.getAge())
.reduce(Integer.MIN_VALUE, (integer, integer2) -> integer >= integer2?integer:integer2);
//使用reduce求所有作者中年龄的最小值。注意初始值必须是最大的
Integer min = authors.stream()
.map(author -> author.getAge())
.reduce(Integer.MAX_VALUE,((integer, integer2) -> integer <= integer2? integer:integer2));
9.2、reduce(BinaryOperator accumulator)
把流中的第一个元素作为初始值,执行定义计算的操作。
Optional<Integer> max = authors.stream()
.map(author -> author.getAge())
.reduce((integer, integer2) -> integer < integer2 ? integer: integer2);
9.3、reduce
3、基本数据类型优化:
每个方法操作基本数据类型时,都会对元素进行拆箱和装箱,所以可以先统一拆箱,再处理后统一装箱
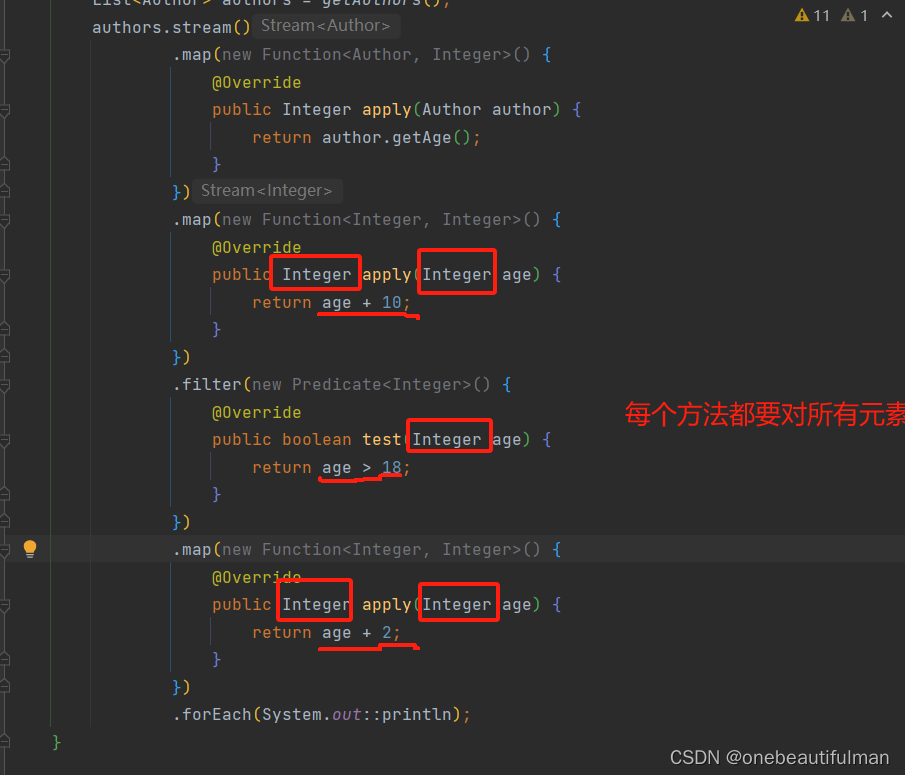
- mapToInt
- mapToLong
- mapToDouble

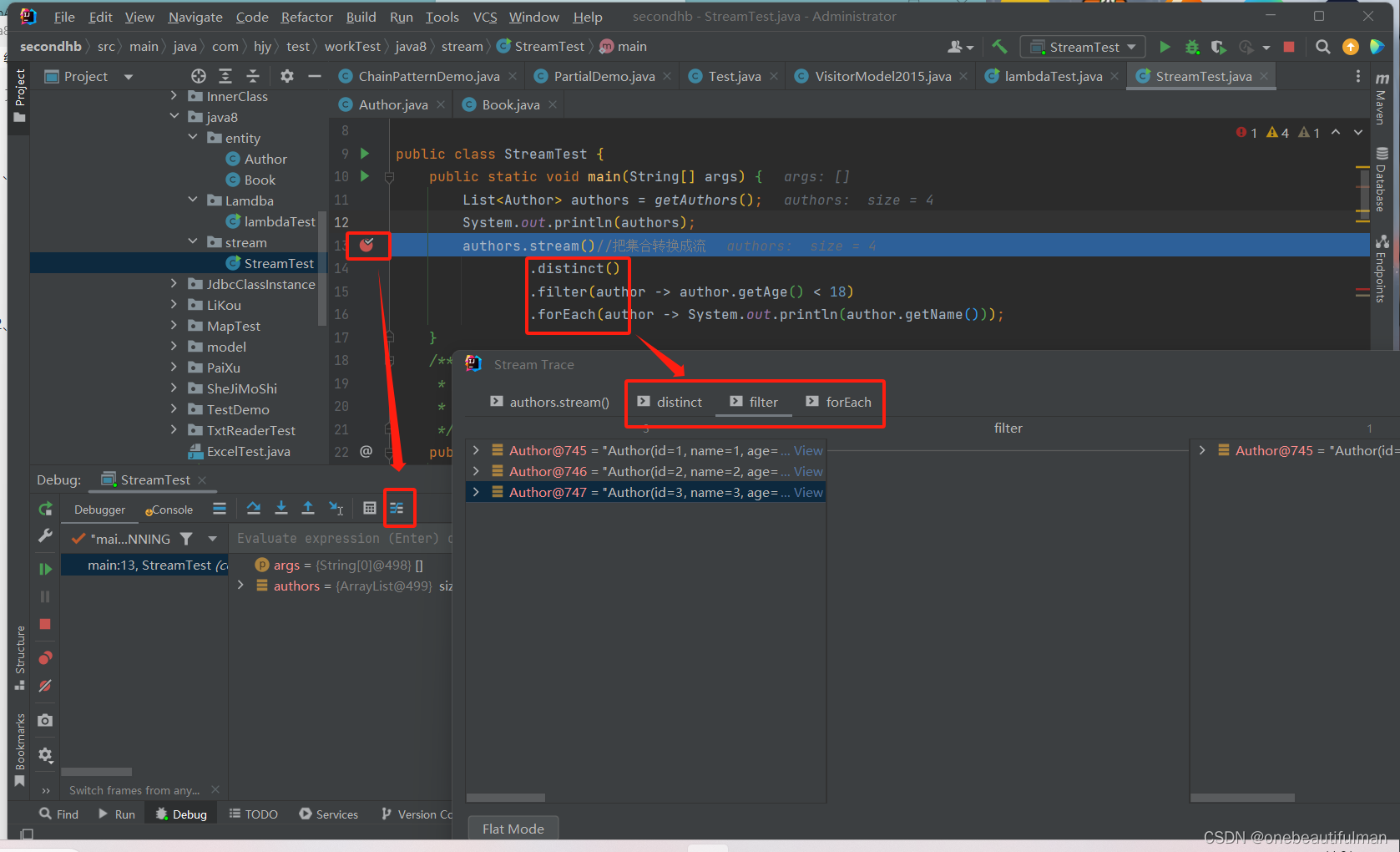
4、Stream流的调试:
5.并行流parallel()
使用多个线程并行处理流中的数据,最后将结果汇总返回
stream.parallel()

三、Optional
避免代码出现空指针异常。Optional类似包装类,可以把我们具体数据封装到Optional内部,然后我们去使用Optional中封装号的方法操作封装进去的数据就可以优雅的避免空指针异常。
1、创建对象
使用Optional的静态方法ofNullable来把数据封装成一个Optional对象。无论传入的参数是否为null都不会出现问题。
你可能会觉得还要加一行代码来封装数据比较麻烦。但是如果改造下getAuthor方法,让其的返回值就是封装好的Optional的话,我们在使用时就会方便很多。
而且在实际开发中我们的数据很多是从数据库获取的。Mybatis从3.5版本可以也已经支持Optional了。我们可以直接把dao方法的返回值类型定义成Optional类型,MyBastis会自己把数据封装成Optional对象返回。封装的过程也不需要我们自己操作。
2、过滤ifPresent
满足条件的保留
3、判断isPresent
满足条件返回true,返回值是Boolean类型
4、数据转换map
四、函数式接口
只有一个抽象方法的接口称为 函数式接口类似。java.util.function下的所有接口,类似Function接口、Consumer接口都是函数式接口
4.1常用的函数式接口
- Consumer消费接口
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
* @param t the input argument
*/
void accept(T t);
}
- Function计算转换接口
public interface Function<T, R> {
/**
* Applies this function to the given argument.
* @param t the function argument
* @return the function result
*/
R apply(T t);
}
- Predicate 判断接口
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
}
- Supplier生产型接口
根据抽象方法的参数列表和返回值类型知道,可以在方法中创建对象,把创建好的对象返回。
public interface Supplier<T> {
/**
* Gets a result.
* @return a result
*/
T get();
}
4.2常用的默认方法
Predicate判断接口:
- and方法:用来拼接多个条件
//获取年龄大于18岁,并且姓名长度大于1的作家名字
List<Author> authors = getAuthors();
authors.stream()
.filter(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getAge()>18;
}
}.and(new Predicate<Author>() {
@Override
public boolean test(Author author) {
return author.getName().length()>1;
}
})
)
.forEach(author -> System.out.println(author.getName()));
- or方法
- negate方法:取反操作
五、方法引用
进一步简化lambda表达式,使用方法引用符::
1、格式:
类名 或 对象名 :: 方法名
//原始Lambda
authors.stream()
.map(author -> author.getAge())
//简写Lambda
authors.stream()
.map(Author::getAge)
2、语法规则:
2.1 引用类的静态方法:
格式:
类名::方法名
引用类的静态方法前提:
- 如果在重写抽象方法中只有一行代码
- 并且这行代码调用了某个类的静态方法,
- 并且要重写的抽象方法中所有的参数都按照顺序传入了这个静态方法中
例如:
authors.stream().map(author -> author.getAge())
.map(new Function<Integer, String>() {
@Override
//抽象方法中只有一行代码,且valueOf是静态方法,且唯一参数age按顺序传入了valueOf静态方法中
public String apply(Integer age) {
return String.valueOf(age);
}
});
普通lambda:
authors.stream().map(author -> author.getAge())
.map(age -> String.valueOf(age));
方法引用简写:
authors.stream().map(author -> author.getAge())
.map(String::valueOf);
2.2 引用对象的实例方法:
格式:
对象名 :: 方法名
引用对象的实例方法前提:
- 如果在重写抽象方法中只有一行代码
- 并且这行代码调用了某个对象的成员方法,
- 并且要重写的抽象方法中所有的参数都按照顺序传入了这个成员方法中
例如:
StringBuilder sb = new StringBuilder();
authors.stream()
.map(author -> author.getName())
.forEach(new Consumer<String>() {
@Override
//抽象方法中只有一行代码,且append是成员方法,且唯一参数name按顺序传入了append成员方法中
public void accept(String name) {
sb.append(name);
}
});
普通lambda:
StringBuilder sb = new StringBuilder();
authors.stream()
.map(author -> author.getName())
.forEach(name -> sb.append(name));
方法引用简写:
StringBuilder sb = new StringBuilder();
authors.stream()
.map(author -> author.getName())
.forEach(sb :: append);
2.3 引用类的实例方法:
格式:
类名:: 方法名
引用类的实例方法前提:
- 如果我们在重写方法的时候,方法体中只有一行代码,
- 并且这行代码是调用了第一个参数的成员方法,
- 并且我们要把重写的抽象方法中剩余的参数都按顺序传入了这个成员方法中。
例如,现有以下接口和方法,要求截取字符串:
interface UseString {
String user(String str,int start, int length);
}
public static String subAuthorName(String str,UseString useString) {
int start = 0;
int length = 1;
return useString.user(str,start,length);
}
普通匿名表达式写法:
public static void main(String[] args) {
String str = subAuthorName("奶奶个熊", new UseString() {
@Override
//方法体中只有一行代码,第一个参数str的成员方法,剩余的参数都按顺序传入这个str的成员方法
public String user(String str, int start, int length) {
return str.substring(start, length);
}
});
}
普通lambda:
public static void main(String[] args) {
String str = subAuthorName("奶奶个熊", (str1, start, length) -> str1.substring(start, length));
}
方法引用简写:
public static void main(String[] args) {
String str = subAuthorName("奶奶个熊", String::substring);
System.out.println(str);
}
2.4 构造器引用
格式:
类名 :: new
构造器引用前提:
- 抽象方法体中只有一行代码
- 且这行代码是调用某个类的构造方法
- 且把重写的抽象方法中的所有参数都按顺序传入了这个构造方法
例如:
authors.stream()
.map(author -> author.getName())
.map(new Function<String, StringBuilder>() {
@Override
public StringBuilder apply(String name) {
return new StringBuilder(name);
}
})
.map(sb -> sb.append("sss").toString())
.forEach(str -> System.out.println(str));
普通lambda:
authors.stream()
.map(author -> author.getName())
.map(name -> new StringBuilder(name))
.map(sb -> sb.append("sss").toString())
.forEach(str -> System.out.println(str));
方法引用简写:
authors.stream()
.map(author -> author.getName())
.map(StringBuilder :: new)
.map(sb -> sb.append("sss").toString())
.forEach(str -> System.out.println(str));
的抽象方法中的所有参数都按顺序传入了这个构造方法
例如:
authors.stream()
.map(author -> author.getName())
.map(new Function<String, StringBuilder>() {
@Override
public StringBuilder apply(String name) {
return new StringBuilder(name);
}
})
.map(sb -> sb.append("sss").toString())
.forEach(str -> System.out.println(str));
普通lambda:
authors.stream()
.map(author -> author.getName())
.map(name -> new StringBuilder(name))
.map(sb -> sb.append("sss").toString())
.forEach(str -> System.out.println(str));
方法引用简写:
authors.stream()
.map(author -> author.getName())
.map(StringBuilder :: new)
.map(sb -> sb.append("sss").toString())
.forEach(str -> System.out.println(str));