算法是为了解决某类问题或完成某一任务而设计的一组步骤或规则。在计算机科学中,算法是程序的核心部分,涉及到如何通过有效的方式处理数据、解决问题。
1. 排序算法
排序算法将一组数据按某种顺序排列,常见的排序算法包括:
1.1冒泡排序(Bubble Sort)
冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复地交换相邻的元素,将较大的元素逐渐“冒泡”到数组的末尾。该算法的核心思想是:对比相邻元素,如果它们的顺序错误(即前一个元素大于后一个元素),就交换它们。这个过程重复进行,直到数组排序完成。
冒泡排序的步骤:
- 从数组的第一个元素开始,依次比较相邻的两个元素。
- 如果前一个元素比后一个元素大,就交换它们的位置。
- 每一轮比较后,最大的元素会“冒泡”到数组的末尾。
- 继续对剩余未排序的部分重复以上步骤,直到整个数组有序。
冒泡排序的时间复杂度:
- 最坏情况:O(n²),当数组完全逆序时,需要进行最多的交换和比较。
- 最好情况:O(n),当数组已经是有序的时(优化后的冒泡排序),只需要一趟遍历。
- 平均情况:O(n²)
冒泡排序的空间复杂度:
- O(1),因为冒泡排序只需要常数的额外空间。
代码示例
public class BubbleSortDemo {
public static void main(String[] args) {
// 示例无序数组
int[] arr = {64, 34, 25, 12, 22, 11, 90};
// 调用冒泡排序方法
bubbleSort(arr);
// 输出排序后的数组
System.out.println("排序后的数组:");
for (int num : arr) {
System.out.print(num + " ");
}
}
// 冒泡排序方法
public static void bubbleSort(int[] arr) {
int n = arr.length;
// 外层循环,控制排序的轮数
for (int i = 0; i < n - 1; i++) {
// 内层循环,进行相邻元素的比较与交换
for (int j = 0; j < n - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
// 交换 arr[j] 和 arr[j + 1]
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
}
- 外层循环:控制排序的轮数,每一轮都会将当前最大的元素移动到数组的末尾,所以需要
n-1次外层循环。 - 内层循环:进行相邻元素的比较和交换。每一轮内层循环结束后,最大的元素就会“冒泡”到数组的末尾,因此内层循环的范围逐渐缩小。
- 交换操作:如果当前元素大于下一个元素,就交换这两个元素的位置。
总结:
- 优点:
- 实现简单。
- 稳定排序,两个相等的元素在排序后相对顺序不变。
- 缺点:
- 效率较低,尤其在数据量较大时,性能不佳。时间复杂度为 O(n²)。
- 适用场景:
- 当数据规模较小时,或当数据已接近有序时,冒泡排序的表现较好。
1.2选择排序(Selection Sort)
选择排序(Selection Sort)是一种简单的排序算法,其基本思想是:每一轮选择未排序部分中的最小(或最大)元素,将其与未排序部分的第一个元素交换。通过不断选择最小元素并交换,最终整个数组会变成有序。
选择排序的步骤:
- 从数组的第一个元素开始,找到剩余元素中的最小值(或最大值)。
- 将找到的最小值(或最大值)与当前元素交换。
- 将已排序部分的范围扩展一位,继续选择未排序部分的最小值,重复步骤2,直到数组排序完成。
选择排序的时间复杂度:
- 最坏情况:O(n²)
- 最好情况:O(n²)
- 平均情况:O(n²)
选择排序的时间复杂度是固定的,因为无论数据是否已经部分排序,外层循环总是会执行 n-1 次,而内层循环需要进行约 n-i 次比较。
选择排序的空间复杂度:
- 空间复杂度:O(1),因为选择排序只需要常数的额外空间。
public class SelectionSortDemo {
public static void main(String[] args) {
// 示例无序数组
int[] arr = {64, 25, 12, 22, 11};
// 调用选择排序方法
selectionSort(arr);
// 输出排序后的数组
System.out.println("排序后的数组:");
for (int num : arr) {
System.out.print(num + " ");
}
}
// 选择排序方法
public static void selectionSort(int[] arr) {
int n = arr.length;
// 外层循环,控制排序的轮数
for (int i = 0; i < n - 1; i++) {
int minIndex = i; // 假设当前元素是最小的
// 内层循环,找到剩余部分的最小元素
for (int j = i + 1; j < n; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j; // 更新最小元素的索引
}
}
// 交换最小元素和当前元素
if (minIndex != i) {
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
}
}
}
运行截图
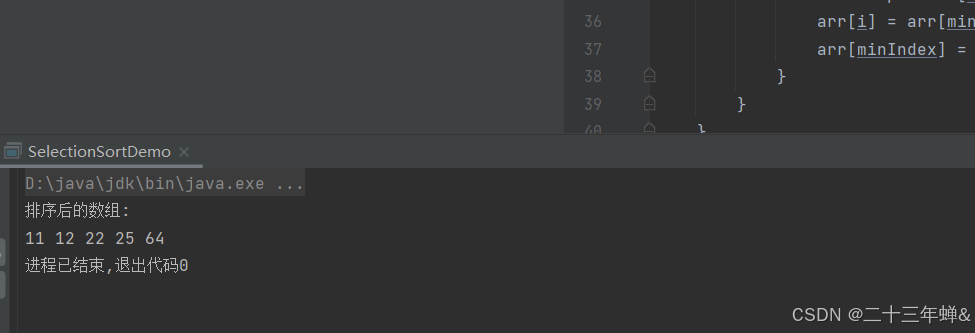
- 外层循环:外层循环控制排序的轮数,每一轮会选择未排序部分的最小元素并将其放到已排序部分的末尾。
- 内层循环:内层循环在未排序部分中查找最小的元素,并更新最小元素的索引
minIndex。 - 交换操作:内层循环结束后,交换当前元素和找到的最小元素的位置。注意,如果当前元素已经是最小元素,则不进行交换。
- 时间复杂度:每一轮外层循环内都需要进行
n-i次比较,因此总的时间复杂度为 O(n²)。
总结:
- 选择排序的特点是每一轮选择最小(或最大)元素,然后放到当前未排序部分的起始位置。
- 它的优点是简单直观,适用于小规模的数据排序,但在大规模数据时效率较低,时间复杂度为 O(n²),不适合用在需要高效排序的场合。
- 它的空间复杂度是 O(1),因为它是就地排序,不需要额外的空间来存储临时数据。
1.3插入排序(Insertion Sort)
插入排序(Insertion Sort)是一种简单的排序算法,它的基本思想是:将一个待排序的元素插入到已经排序好的部分中,使得插入后数组依然保持有序。可以将其想象成像打扑克牌时,玩家将手中的牌一张一张地插入到已经排序好的部分,最终形成一个有序的牌序。
插入排序的步骤:
- 从第二个元素开始,将其与前面的元素进行比较,找出合适的位置插入。
- 插入时,如果当前元素小于前一个元素,则将前一个元素后移一位。
- 重复此过程,直到数组排序完成。
插入排序的时间复杂度:
- 最坏情况:O(n²),当数组是逆序排列时,每一轮都需要将当前元素与前面所有元素进行比较和移动。
- 最好情况:O(n),当数组已经是有序时,每一轮只需进行一次比较。
- 平均情况:O(n²),在一般情况下需要进行多次比较和移动。
插入排序的空间复杂度:
- 空间复杂度:O(1),插入排序是就地排序算法,不需要额外的存储空间。
插入排序的特点:
- 稳定性:插入排序是一种稳定的排序算法,即相等的元素不会交换位置。
- 适用于小规模数据:由于它的时间复杂度较高,插入排序适合在数据量较小的时候使用。
public class InsertionSortDemo {
public static void main(String[] args) {
// 示例无序数组
int[] arr = {64, 34, 25, 12, 22, 11, 90};
// 调用插入排序方法
insertionSort(arr);
// 输出排序后的数组
System.out.println("排序后的数组:");
for (int num : arr) {
System.out.print(num + " ");
}
}
// 插入排序方法
public static void insertionSort(int[] arr) {
int n = arr.length;
// 从第二个元素开始,依次插入
for (int i = 1; i < n; i++) {
int key = arr[i]; // 当前元素
int j = i - 1;
// 向前比较并移动元素,为当前元素插入位置腾出空间
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j]; // 向右移动元素
j = j - 1;
}
// 将当前元素插入到找到的位置
arr[j + 1] = key;
}
}
}
运行截图
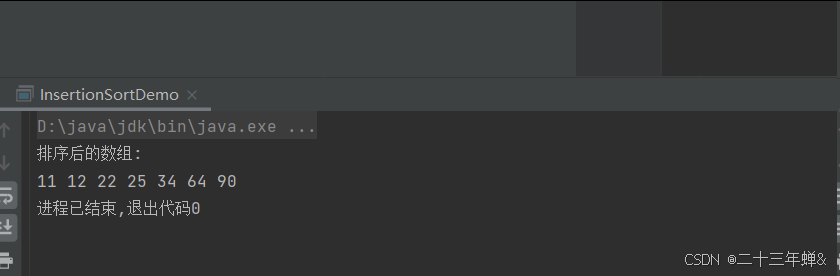
1.4快速排序(Quick Sort)
快速排序是一种基于分治思想的高效排序算法,常用于对大量无序数据的排序。它通过选取一个基准值(Pivot),将数组分为两部分,再递归地对两部分排序。
算法步骤
-
选择基准值(Pivot):
- 从数组中选择一个元素作为基准值,通常是第一个、最后一个、或随机选取。
-
分区(Partition):
- 将数组重新排列,使得所有小于基准值的元素移到基准值的左边,大于基准值的元素移到右边,基准值位于正确的位置。
-
递归排序:
- 对基准值左边和右边的子数组分别递归地执行快速排序。
-
完成排序:
- 当子数组长度为 0 或 1 时,停止递归。
算法特点
- 时间复杂度:
- 最好情况:O(n log n)(每次分区均匀分割数组)
- 平均情况:O(n log n)
- 最坏情况:O(n²)(当数组完全有序或完全逆序,基准值选取不当时)
- 空间复杂度:
- O(log n)(递归调用栈的空间)
- 排序稳定性:
- 不稳定排序(可能改变相同元素的相对位置)。
快速排序实现
public class QuickSortDemo {
public static void main(String[] args) {
int[] arr = {10, 7, 8, 9, 1, 5};
// 调用快速排序
quickSort(arr, 0, arr.length - 1);
// 输出排序后的数组
System.out.println("排序后的数组:");
for (int num : arr) {
System.out.print(num + " ");
}
}
// 快速排序方法
public static void quickSort(int[] arr, int low, int high) {
if (low < high) {
// 获取分区索引
int pi = partition(arr, low, high);
// 对左子数组递归排序
quickSort(arr, low, pi - 1);
// 对右子数组递归排序
quickSort(arr, pi + 1, high);
}
}
// 分区方法
public static int partition(int[] arr, int low, int high) {
int pivot = arr[high]; // 选择最后一个元素作为基准值
int i = low - 1; // i 指向较小元素的索引
for (int j = low; j < high; j++) {
// 如果当前元素小于或等于基准值
if (arr[j] <= pivot) {
i++;
// 交换 arr[i] 和 arr[j]
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// 交换基准值和 i+1 的位置,使基准值位于正确位置
int temp = arr[i + 1];
arr[i + 1] = arr[high];
arr[high] = temp;
return i + 1; // 返回基准值索引
}
}
运行结果

总结
- 快速排序是一种高效的排序算法,平均时间复杂度为 O(n log n),适合处理大规模随机数据。
- 在实际应用中,优化快速排序(如随机选择基准值或三向切分)可以显著提高性能。
- 尽管快速排序存在最坏情况,但通过优化技术可以有效避免性能退化。
1.5归并排序(Merge Sort)
归并排序是一种基于**分治法(Divide and Conquer)**的排序算法,将一个大问题分解为多个子问题,分别解决后再合并子问题的解,最终得到整体有序的结果。
基本思想
- 分解:将数组递归地分成两半,直到每个子数组的长度为 1。
- 解决:将左右两个子数组排序,并合并成一个有序数组。
- 合并:将两个有序子数组合并为一个有序数组。
归并排序的核心在于 合并两个有序数组,确保合并后的结果依然有序。
归并排序的特点:
- 时间复杂度:O(n log n)
- 分解为 log n 层,每一层合并的复杂度为 O(n)。
- 空间复杂度:O(n)
- 需要额外的临时数组存储合并结果。
- 稳定性:稳定排序(两个相等元素排序后相对位置不变)。
- 适用场景:适合处理大规模数据,尤其在外部排序中(如磁盘数据排序)。
代码实现
public class MergeSort {
public static void main(String[] args) {
int[] arr = {38, 27, 43, 3, 9, 82, 10};
System.out.println("排序前数组:");
printArray(arr);
// 调用归并排序方法
mergeSort(arr, 0, arr.length - 1);
System.out.println("排序后数组:");
printArray(arr);
}
// 归并排序主方法
public static void mergeSort(int[] arr, int left, int right) {
if (left < right) {
int mid = left + (right - left) / 2; // 计算中间点
// 递归分解左半部分
mergeSort(arr, left, mid);
// 递归分解右半部分
mergeSort(arr, mid + 1, right);
// 合并两个有序子数组
merge(arr, left, mid, right);
}
}
// 合并两个有序子数组的方法
public static void merge(int[] arr, int left, int mid, int right) {
int n1 = mid - left + 1; // 左子数组长度
int n2 = right - mid; // 右子数组长度
// 创建临时数组
int[] leftArr = new int[n1];
int[] rightArr = new int[n2];
// 拷贝数据到临时数组
for (int i = 0; i < n1; i++) {
leftArr[i] = arr[left + i];
}
for (int j = 0; j < n2; j++) {
rightArr[j] = arr[mid + 1 + j];
}
// 合并临时数组到原数组
int i = 0, j = 0, k = left;
while (i < n1 && j < n2) {
if (leftArr[i] <= rightArr[j]) {
arr[k] = leftArr[i];
i++;
} else {
arr[k] = rightArr[j];
j++;
}
k++;
}
// 拷贝剩余元素(如果有)
while (i < n1) {
arr[k] = leftArr[i];
i++;
k++;
}
while (j < n2) {
arr[k] = rightArr[j];
j++;
k++;
}
}
// 打印数组方法
public static void printArray(int[] arr) {
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
}
代码解析
-
mergeSort方法:- 将数组递归分成两半,直到每个子数组只有一个元素。
- 使用
merge方法将两个有序子数组合并。
-
merge方法:- 使用两个临时数组
leftArr和rightArr存储左右子数组。 - 通过双指针遍历两个临时数组,将较小的元素放回原数组中。
- 最后将剩余元素(如果有)拷贝回原数组。
- 使用两个临时数组
-
时间复杂度:
- 每一层分解的时间复杂度是 O(n),共
log n层,因此总复杂度为 O(n log n)。
- 每一层分解的时间复杂度是 O(n),共
-
空间复杂度:
- 由于使用了临时数组,空间复杂度为 O(n)。
执行结果
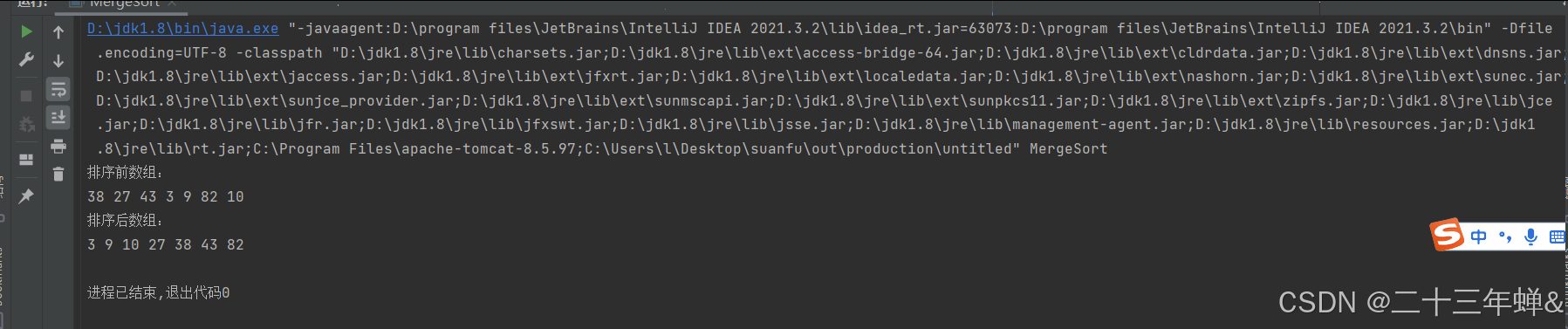
归并排序的优势与劣势:
优势:
- 稳定性:归并排序是稳定的排序算法。
- 时间复杂度稳定:无论数据如何分布,时间复杂度始终为 O(n log n)。
- 适合大数据量:特别适合处理外部排序(数据量超出内存时)。
劣势:
- 空间复杂度高:需要额外的临时存储空间。
- 不适合小规模数据:与插入排序等相比,小规模数据时开销较大。
应用场景
- 外部排序:当数据量太大,无法一次性加载到内存时,归并排序特别适合。
- 稳定性要求高的场景:需要保证相同元素的相对位置不变。
总结
归并排序是一种 稳定、高效 的排序算法,适合处理大规模数据。但由于空间复杂度较高,在小规模数据或内存受限的场景下,可能不是最优选择。
1.6堆排序(Heap Sort)
堆排序是一种基于堆(Heap) 数据结构的选择排序算法,利用堆的性质对数组进行排序。堆是一种完全二叉树,分为最大堆和最小堆:
- 最大堆:任意节点的值都大于等于其子节点的值,根节点是最大值。
- 最小堆:任意节点的值都小于等于其子节点的值,根节点是最小值。
堆排序通常采用最大堆来实现升序排序,或者最小堆来实现降序排序。
堆排序的基本步骤
-
构建大顶堆(最大堆):
- 将无序数组调整为一个最大堆。
- 堆的根节点(下标为 0)为最大值。
-
交换堆顶元素和最后一个元素:
- 将堆顶元素(最大值)与数组末尾元素交换,然后缩小堆的范围。
-
调整堆:
- 重新将剩余的元素调整为最大堆,保证堆的性质。
-
重复步骤 2 和 3:
- 直到所有元素排序完成。
堆排序的特点
- 时间复杂度:O(n log n)
- 堆的构建需要 O(n),每次调整堆的时间复杂度为 O(log n),共需执行 n-1 次调整。
- 空间复杂度:O(1)(原地排序,不需要额外空间)。
- 稳定性:不稳定排序。
- 适用场景:适合数据量大、不要求稳定排序的场景。
堆排序的实现
public class HeapSort {
public static void main(String[] args) {
int[] arr = {4, 10, 3, 5, 1, 2};
System.out.println("排序前数组:");
printArray(arr);
// 执行堆排序
heapSort(arr);
System.out.println("排序后数组:");
printArray(arr);
}
// 堆排序主方法
public static void heapSort(int[] arr) {
int n = arr.length;
// 1. 构建最大堆
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
// 2. 交换堆顶元素和末尾元素,并调整堆
for (int i = n - 1; i > 0; i--) {
// 交换堆顶元素与当前末尾元素
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
// 调整剩余元素为最大堆
heapify(arr, i, 0);
}
}
// 调整堆的方法
public static void heapify(int[] arr, int n, int i) {
int largest = i; // 初始化最大值为当前节点
int left = 2 * i + 1; // 左子节点
int right = 2 * i + 2; // 右子节点
// 如果左子节点大于根节点
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
// 如果右子节点大于当前最大值
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
// 如果最大值不是根节点,交换并递归调整
if (largest != i) {
int swap = arr[i];
arr[i] = arr[largest];
arr[largest] = swap;
// 递归调整被交换的子树
heapify(arr, n, largest);
}
}
// 输出数组的方法
public static void printArray(int[] arr) {
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
}
代码解析
-
构建最大堆:
- 从最后一个非叶子节点开始(
n / 2 - 1),逐个向上调整子树,使每个子树都满足最大堆的性质。
- 从最后一个非叶子节点开始(
-
调整堆(heapify 方法):
- 比较当前节点与左右子节点,找出最大值。
- 如果最大值不是当前节点,交换节点,并递归地对受影响的子树进行调整。
-
排序过程:
- 每次将堆顶元素(最大值)与末尾元素交换,然后缩小堆的范围,继续调整堆。
-
时间复杂度分析:
- 构建堆的时间复杂度为 O(n)。
- 每次调整堆的时间复杂度为 O(log n),总共需要调整 n-1 次。
- 所以总体时间复杂度为 O(n log n)。
执行结果
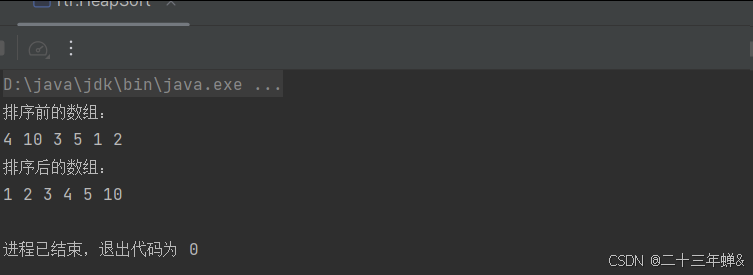
堆排序的优缺点
优点:
- 时间复杂度稳定:无论数据如何分布,时间复杂度始终为 O(n log n)。
- 空间复杂度低:原地排序,不需要额外的存储空间。
- 适合大数据排序:尤其适合数据量大、要求时间复杂度稳定的场景。
缺点:
- 不稳定排序:相等元素的顺序可能被改变。
- 实现复杂:代码逻辑相对较复杂,构建堆和调整堆需要较多操作。
应用场景
- 数据量大、内存受限:堆排序不需要额外的空间,适用于内存敏感的场景。
- 优先队列:堆排序是实现优先队列的基础,应用于任务调度、事件驱动等场景。
- Top K 问题:利用堆排序快速找到前 K 个最大或最小的元素。
总结
堆排序是一种时间复杂度稳定、空间复杂度低的排序算法,适合处理大数据排序问题。虽然其实现较为复杂,但它在实际应用中(如优先队列、Top K 问题)具有重要的作用。
1.7计数排序(Counting Sort)
计数排序是一种非比较排序算法,适用于整数排序问题。它通过统计每个元素的出现次数,将数据映射到计数数组中,再根据计数数组生成有序结果。计数排序在特定情况下具有O(n) 的时间复杂度,适合范围有限的正整数排序。
基本思想
- 找到待排序数组中的最大值和最小值,用来确定计数数组的范围。
- 创建一个计数数组
count,记录每个元素出现的次数。 - 将计数数组中的值累加,用于确定每个元素在有序数组中的位置。
- 根据计数数组,逐个将元素放入目标数组中。
- 最终得到排序后的数组。
计数排序的特点
- 时间复杂度:O(n + k)(
n是待排序元素个数,k是计数数组的长度,即范围 [min, max] 的大小)。 - 空间复杂度:O(k)(需要额外的计数数组)。
- 稳定性:稳定排序(如果实现中记录元素的相对位置,则排序后相同元素的相对顺序不变)。
- 适用场景:适用于数据范围较小、数据分布相对均匀的整数排序。
计数排序实现
public class CountingSort {
public static void main(String[] args) {
int[] arr = {4, 2, 2, 8, 3, 3, 1};
System.out.println("排序前数组:");
printArray(arr);
// 执行计数排序
countingSort(arr);
System.out.println("排序后数组:");
printArray(arr);
}
public static void countingSort(int[] arr) {
if (arr == null || arr.length == 0) {
return;
}
// 找到数组中的最大值和最小值
int max = arr[0], min = arr[0];
for (int num : arr) {
if (num > max) {
max = num;
}
if (num < min) {
min = num;
}
}
// 创建计数数组并统计每个元素的出现次数
int range = max - min + 1; // 范围 [min, max]
int[] count = new int[range];
for (int num : arr) {
count[num - min]++;
}
// 计算每个元素在排序后数组中的位置
for (int i = 1; i < count.length; i++) {
count[i] += count[i - 1];
}
// 创建临时数组存放排序结果
int[] output = new int[arr.length];
for (int i = arr.length - 1; i >= 0; i--) { // 从后往前遍历,保证稳定性
int num = arr[i];
output[count[num - min] - 1] = num;
count[num - min]--;
}
// 将排序后的结果拷贝回原数组
System.arraycopy(output, 0, arr, 0, arr.length);
}
// 打印数组的方法
public static void printArray(int[] arr) {
for (int num : arr) {
System.out.print(num + " ");
}
System.out.println();
}
}
代码解析
-
找到最大值和最小值:
- 遍历数组,确定
max和min,用来计算计数数组的范围。
- 遍历数组,确定
-
构建计数数组:
count[num - min]表示元素num的出现次数。
-
累加计数数组:
- 将计数数组中的值进行累加,
count[i]表示元素i + min在结果数组中的最后位置。
- 将计数数组中的值进行累加,
-
生成排序后的数组:
- 倒序遍历原数组,根据计数数组中的位置,将元素放入结果数组。
-
拷贝结果:
- 将排序后的数组拷贝回原数组。
执行结果
排序前数组:
4 2 2 8 3 3 1
排序后数组:
1 2 2 3 3 4 8
计数排序的优缺点
优点:
- 线性时间复杂度:在数据范围较小时表现极为高效。
- 稳定排序:原始相同元素的相对顺序保持不变。
- 无需比较:通过计数数组直接排序。
缺点:
- 额外空间消耗:需要额外的计数数组,空间复杂度为 O(k)。
- 数据范围限制:当数据范围过大时(如范围为 0 到 10^6),会导致计数数组占用过多内存。
- 不适合浮点数或负数:计数排序需要整数键值的映射。
优化与扩展
1. 支持负数
通过记录最小值 min,将所有数据映射到非负数范围:
count[num - min]++;
2. 应用于字符排序
计数排序可以直接用于字符的排序(ASCII 或 Unicode 值):
char[] arr = {'c', 'b', 'a', 'd'};
3. 改进空间效率
当数据范围很大但实际分布稀疏时,可以用哈希表代替计数数组。
总结
-
计数排序适合场景:
- 数据范围有限且为整数类型。
- 需要稳定排序的场景。
-
不适合场景:
- 数据范围过大导致内存浪费。
- 浮点数或高精度数值的排序。
计数排序通过非比较的方式,结合额外的计数数组,实现了高效的排序,在数据范围合适时是一种非常高效的选择。
1.8基数排序(Radix Sort)
基数排序(Radix Sort)是一种非比较型排序算法,通过对数值的每一位(个位、十位、百位等)进行分组和排序来实现有序排列。它特别适合于整数排序或固定长度字符串排序,尤其是在数据范围不大的情况下表现出色。
基本思想
-
按位排序:
- 从最低位(个位)开始,对数据进行排序;
- 然后依次按照十位、百位、千位等排序,直到最高位。
-
分桶和排序:
- 每一位的排序使用稳定排序算法(通常是计数排序)。
-
逐步有序:
- 每一轮基于某一位的排序后,整个数组在当前位上是有序的。随着处理的位数增加,数组最终完全有序。
算法特点
-
时间复杂度:
- O(d × (n + k)),其中:
d是数字的位数(或字符串的最大长度);n是待排序的元素数量;k是每位的可能取值(如基数为 10 时,k = 10)。
- O(d × (n + k)),其中:
-
空间复杂度:
- O(n + k),需要额外的空间用于计数或分桶。
-
稳定性:
- 基数排序是稳定排序,相同元素的相对顺序保持不变。
-
适用场景:
- 数据为非负整数、固定长度的字符串或数字范围较小的情况。
基数排序的优缺点
优点:
- 时间复杂度低:
- 对位数固定的整数排序,基数排序的时间复杂度接近 O(n),性能优异。
- 稳定性:
- 基数排序是稳定的,相同元素的顺序不会改变。
- 适合特定场景:
- 如银行卡号、手机号等大规模整数排序,基数排序非常高效。
缺点:
- 依赖数据特性:
- 仅适用于整数或固定长度字符串排序,不适合浮点数或负数。
- 空间开销大:
- 需要额外的计数数组或桶来支持排序。
- 位数敏感:
- 数据位数较多或取值范围较大时,效率会降低。
基数排序的实现
实现步骤
- 找到数据中的最大值,确定排序的位数
d。 - 从最低位开始,使用计数排序对数组按照当前位进行排序。
- 对每一位重复上述过程,直到最高位。
Java 实现代码
import java.util.Arrays;
public class RadixSort {
public static void main(String[] args) {
int[] arr = {170, 45, 75, 90, 802, 24, 2, 66};
System.out.println("排序前:");
System.out.println(Arrays.toString(arr));
// 执行基数排序
radixSort(arr);
System.out.println("排序后:");
System.out.println(Arrays.toString(arr));
}
// 基数排序主方法
public static void radixSort(int[] arr) {
// 找到数组中的最大值,确定最高位数
int max = getMax(arr);
// 从个位开始,对每一位进行计数排序
for (int exp = 1; max / exp > 0; exp *= 10) {
countingSortByDigit(arr, exp);
}
}
// 找到数组中的最大值
public static int getMax(int[] arr) {
int max = arr[0];
for (int num : arr) {
if (num > max) {
max = num;
}
}
return max;
}
// 按位数(exp)对数组进行计数排序
public static void countingSortByDigit(int[] arr, int exp) {
int n = arr.length;
int[] output = new int[n]; // 存储排序结果
int[] count = new int[10]; // 计数数组,范围为 0-9
// 统计每个数字在当前位上的出现次数
for (int i = 0; i < n; i++) {
int digit = (arr[i] / exp) % 10;
count[digit]++;
}
// 将计数数组转化为位置信息(累加)
for (int i = 1; i < 10; i++) {
count[i] += count[i - 1];
}
// 根据当前位上的数字,从后向前遍历原数组,构建排序后的数组
for (int i = n - 1; i >= 0; i--) {
int digit = (arr[i] / exp) % 10;
output[count[digit] - 1] = arr[i];
count[digit]--;
}
// 将排序结果拷贝回原数组
System.arraycopy(output, 0, arr, 0, n);
}
}
2. 查找算法
查找算法用于在数据结构中查找特定元素:
- 二分查找(Binary Search)——只适用于已排序数组
- 线性查找(Linear Search)
- 哈希查找(Hashing)
2.1二分查找(Binary Search)
二分查找是通过将已排序数组分成两半,逐步缩小查找范围的算法。每次比较目标值与中间元素,根据大小关系决定继续查找左半边或右半边,直到找到目标或确定元素不存在。
package 二分查找;
public class BinarySearchDemo {
public static void main(String[] args) {
// 示例已排序数组
int[] arr = {1, 3, 5, 7, 9, 11, 13, 15, 17, 19};
int target = 7;
// 调用二分查找方法
int result = binarySearch(arr, target);
// 输出查找结果
if (result != -1) {
System.out.println("元素 " + target + " 的索引是: " + result);
} else {
System.out.println("元素 " + target + " 未找到");
}
}
// 二分查找方法
public static int binarySearch(int[] arr, int target) {
int left = 0, right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2; // 计算中间索引
if (arr[mid] == target) {
return mid; // 找到目标值,返回索引
}
if (arr[mid] < target) {
left = mid + 1; // 目标值在右半部分
} else {
right = mid - 1; // 目标值在左半部分
}
}
return -1; // 未找到目标值
}
}
代码优化
public class BinarySearchDemo {
public static void main(String[] args) {
// 示例已排序数组
int[] arr = {1, 3, 5, 7, 9, 11, 13, 15, 17, 19};
int target = 7;
// 调用二分查找方法
int result = binarySearchBasic(arr, target);
// 输出查找结果
if (result != -1) {
System.out.println("元素 " + target + " 的索引是: " + result);
} else {
System.out.println("元素 " + target + " 未找到");
}
}
// 二分查找方法
public static int binarySearchBasic(int[] a, int target) {
int i = 0, j = a.length - 1; // 设置指针和初值
// 只要区间内有元素未比较,继续循环
while (i <= j) {
// 通过无符号右移 >>> 1 计算中间索引,避免溢出
int m = (i + j) >>> 1;
if (target < a[m]) {
// 目标值在左侧,调整右边界
j = m - 1;
} else if (a[m] < target) {
// 目标值在右侧,调整左边界
i = m + 1;
} else {
// 找到了目标值,返回索引
return m;
}
}
// 未找到目标值,返回 -1
return -1;
}
}
-
(i + j) >>> 1:- 使用无符号右移运算符计算中间索引,避免当
i和j很大时发生整型溢出。传统的(i + j) / 2在某些情况下可能会导致溢出错误。 - 无符号右移运算符比除法计算更高效。
- 使用无符号右移运算符计算中间索引,避免当
-
循环条件:
i <= j意味着当区间内有未比较的元素时继续循环。- 当
i > j时,表示没有找到目标值。
-
分支逻辑:
- 如果目标值小于中间值,说明目标值在左侧,因此调整右边界为
j = m - 1。 - 如果目标值大于中间值,说明目标值在右侧,因此调整左边界为
i = m + 1。 - 如果目标值等于中间值,直接返回中间索引
m。
- 如果目标值小于中间值,说明目标值在左侧,因此调整右边界为
2.2线性查找(Linear Search)
线性查找是一种最简单的查找算法,它通过从数据集的第一个元素开始,依次检查每个元素,直到找到目标元素或遍历完所有元素为止。
特点:
- 时间复杂度: 最坏情况和平均情况均为 O(n),其中 n 是数据集的元素个数。
- 空间复杂度: O(1),不需要额外的存储空间。
- 适用情况: 适用于无序或小规模的数组或链表。
算法步骤:
- 从第一个元素开始,检查该元素是否是目标值。
- 如果是目标值,返回该元素的索引。
- 如果不是,继续检查下一个元素,直到找到目标值或遍历完整个数据集。
- 如果没有找到目标元素,返回标识未找到的值(如 -1 或 null)。
代码实现
public class LinearSearch {
// 线性查找方法
public static int linearSearch(int[] arr, int target) {
// 遍历数组
for (int i = 0; i < arr.length; i++) {
if (arr[i] == target) {
return i; // 找到目标值,返回索引
}
}
return -1; // 未找到目标值,返回-1
}
public static void main(String[] args) {
// 测试数组
int[] arr = {2, 3, 4, 10, 40};
int target = 10;
// 调用线性查找方法
int result = linearSearch(arr, target);
if (result != -1) {
System.out.println("目标值 " + target + " 的索引是 " + result);
} else {
System.out.println("目标值未找到");
}
}
}
代码解释
linearSearch(int[] arr, int target):该方法接收一个整数数组和目标值,逐一检查数组中的元素,找到目标值时返回索引。如果未找到,返回 -1。main方法:定义了一个测试数组,设置目标值,调用linearSearch方法并输出结果。
2.3哈希查找(Hashing)
哈希查找是一种通过哈希表(或哈希映射)来实现快速查找的算法。它利用哈希函数将数据的键映射到哈希表的某个位置,从而能够在常数时间内进行查找操作。
基本原理:
- 哈希函数: 将输入数据(键)映射到一个固定大小的表中,生成一个唯一的索引值。
- 哈希表: 一个数组或数据结构,存储映射后的数据。
- 冲突: 如果两个不同的键通过哈希函数计算得到相同的索引位置,则称为哈希冲突。常用的冲突解决方法有链式法(链表法)和开放地址法。
哈希表结构:
- 桶(Bucket): 存储映射后的数据。
- 键(Key): 数据的标识符,通过哈希函数计算得到位置。
- 值(Value): 与键关联的数据。
哈希查找的步骤:
- 对目标值应用哈希函数,将其映射到哈希表中的某个位置。
- 如果该位置没有被占用,直接存储该元素。
- 如果该位置已经被占用(发生冲突),使用冲突解决策略(如链式法、开放地址法)来处理。
- 查找操作时,通过相同的哈希函数计算出目标元素的位置,并返回结果。
哈希查找的优缺点:
优点:
- 查找、插入和删除操作的平均时间复杂度为 O(1)。
- 适用于大规模数据的查找。
缺点:
- 需要一个好的哈希函数来保证均匀分布,否则会导致大量的冲突。
- 处理哈希冲突时可能导致性能下降。
- 如果哈希表过小,哈希冲突严重,性能会受到影响。
哈希函数的设计:
哈希函数的质量直接影响哈希查找的性能。常见的哈希函数设计方法包括:
- 除法法(Division Method):
hash(key) = key % table_size - 乘法法(Multiplication Method):
hash(key) = floor(table_size * (key * A % 1))其中,A 是一个常数,0 < A < 1。
常见的哈希冲突解决方法:
-
链式法(Separate Chaining):
- 每个桶(桶的元素是一个链表)存储所有映射到该桶的位置的元素。
- 冲突时,新的元素被添加到链表中。
-
开放地址法(Open Addressing):
- 通过探查(如线性探查、二次探查等)来寻找一个空桶,来处理冲突。
哈希查找的实现
import java.util.LinkedList;
class HashTable {
private LinkedList<Integer>[] table;
// 构造函数:初始化哈希表大小
public HashTable(int size) {
table = new LinkedList[size];
for (int i = 0; i < size; i++) {
table[i] = new LinkedList<>();
}
}
// 哈希函数:将键映射到哈希表的位置
private int hash(int key) {
return key % table.length;
}
// 插入元素
public void insert(int key) {
int index = hash(key);
table[index].add(key);
}
// 查找元素
public boolean search(int key) {
int index = hash(key);
return table[index].contains(key);
}
// 删除元素
public void delete(int key) {
int index = hash(key);
table[index].remove(Integer.valueOf(key));
}
}
public class Main {
public static void main(String[] args) {
HashTable ht = new HashTable(10);
// 插入元素
ht.insert(15);
ht.insert(25);
ht.insert(35);
// 查找元素
System.out.println("查找 25: " + ht.search(25)); // 输出 true
System.out.println("查找 30: " + ht.search(30)); // 输出 false
// 删除元素
ht.delete(25);
System.out.println("查找 25: " + ht.search(25)); // 输出 false
}
}
3. 图算法
用于处理图结构(如社交网络、地图等):
- 深度优先搜索(DFS,Depth-First Search)
- 广度优先搜索(BFS,Breadth-First Search)
- Dijkstra算法(最短路径)
- A*算法(最短路径)
- Kruskal算法(最小生成树)
- Prim算法(最小生成树)
3.1深度优先搜索(DFS,Depth-First Search)
基本思想:
- 使用回溯的方式,沿着某一路径尽可能深入,直到无法深入为止,然后返回上一步尝试其他路径,直到所有可能的路径都被遍历。
特点:
- 使用 栈 作为辅助数据结构。
- 可以通过递归或显式使用栈实现。
- 遍历的顺序是“先子节点,后兄弟节点”。
应用场景:
- 判断连通性(如图中是否有环)。
- 求解迷宫问题。
- 拓扑排序。
实现步骤:
- 标记当前节点为访问过。
- 遍历当前节点的所有相邻节点,如果未访问过,递归调用 DFS。
- 回溯到上一个节点,继续检查未访问的其他路径。
递归实现
适合简单场景,利用函数调用栈实现深度优先搜索。
import java.util.*;
public class DFSRecursive {
public static void dfs(Map<Integer, List<Integer>> graph, int node, Set<Integer> visited) {
// 标记当前节点为已访问
visited.add(node);
System.out.print(node + " "); // 处理当前节点
// 遍历所有邻居节点
for (int neighbor : graph.getOrDefault(node, new ArrayList<>())) {
if (!visited.contains(neighbor)) {
dfs(graph, neighbor, visited);
}
}
}
public static void main(String[] args) {
// 使用邻接表表示图
Map<Integer, List<Integer>> graph = new HashMap<>();
graph.put(1, Arrays.asList(2, 3));
graph.put(2, Arrays.asList(4, 5));
graph.put(3, Arrays.asList(6));
graph.put(4, Arrays.asList());
graph.put(5, Arrays.asList(6));
graph.put(6, Arrays.asList());
Set<Integer> visited = new HashSet<>();
System.out.println("DFS 递归实现:");
dfs(graph, 1, visited); // 从节点 1 开始遍历
}
}
显式栈实现
适合迭代方式,避免递归栈溢出,适合处理大规模图。
import java.util.*;
public class DFSIterative {
public static void dfsIterative(Map<Integer, List<Integer>> graph, int start) {
Stack<Integer> stack = new Stack<>(); // 用栈模拟递归
Set<Integer> visited = new HashSet<>(); // 记录访问过的节点
stack.push(start); // 初始化,将起始节点压入栈
while (!stack.isEmpty()) {
int node = stack.pop(); // 取出栈顶节点
if (!visited.contains(node)) {
visited.add(node); // 标记当前节点为已访问
System.out.print(node + " "); // 处理当前节点
// 将所有未访问的邻居节点压入栈(注意压入顺序)
for (int neighbor : graph.getOrDefault(node, new ArrayList<>())) {
if (!visited.contains(neighbor)) {
stack.push(neighbor);
}
}
}
}
}
public static void main(String[] args) {
// 使用邻接表表示图
Map<Integer, List<Integer>> graph = new HashMap<>();
graph.put(1, Arrays.asList(2, 3));
graph.put(2, Arrays.asList(4, 5));
graph.put(3, Arrays.asList(6));
graph.put(4, Arrays.asList());
graph.put(5, Arrays.asList(6));
graph.put(6, Arrays.asList());
System.out.println("DFS 显式栈实现:");
dfsIterative(graph, 1); // 从节点 1 开始遍历
}
}
迷宫求解(DFS 应用)
题目:
给定一个迷宫(矩阵表示),起点为 (0, 0),终点为 (n-1, m-1)。找到一条从起点到终点的路
import java.util.*;
public class MazeSolver {
// 迷宫中的四个方向(上下左右)
private static final int[][] DIRECTIONS = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
public static boolean dfsMaze(int[][] maze, int x, int y, List<int[]> path, boolean[][] visited) {
int n = maze.length, m = maze[0].length;
// 如果到达终点
if (x == n - 1 && y == m - 1) {
path.add(new int[]{x, y});
return true;
}
// 标记当前点为已访问
visited[x][y] = true;
path.add(new int[]{x, y});
// 遍历四个方向
for (int[] direction : DIRECTIONS) {
int newX = x + direction[0];
int newY = y + direction[1];
if (newX >= 0 && newX < n && newY >= 0 && newY < m && maze[newX][newY] == 0 && !visited[newX][newY]) {
if (dfsMaze(maze, newX, newY, path, visited)) {
return true;
}
}
}
// 回溯
path.remove(path.size() - 1);
return false;
}
public static void main(String[] args) {
// 迷宫:0 表示可通行,1 表示墙
int[][] maze = {
{0, 0, 1},
{1, 0, 1},
{0, 0, 0}
};
int n = maze.length, m = maze[0].length;
List<int[]> path = new ArrayList<>();
boolean[][] visited = new boolean[n][m];
if (dfsMaze(maze, 0, 0, path, visited)) {
System.out.println("找到路径:");
for (int[] p : path) {
System.out.println(Arrays.toString(p));
}
} else {
System.out.println("无路径可到达终点。");
}
}
}
总结
递归 vs 显式栈
- 递归实现:代码简洁,但可能存在递归深度限制。
- 显式栈实现:避免了递归深度限制,更灵活,适合处理较大的图。
应用场景
- 图遍历:搜索所有可能的路径。
- 迷宫求解:找到从起点到终点的路径。
- 检测连通性:判断图中是否所有节点连通。
- 检测图中环:在深度优先搜索中发现已经访问的节点即可判断是否存在环。
Java 提供了强大的数据结构(如 Stack 和 Set),使得实现 DFS 非常高效灵活
3.2广度优先搜索(BFS, Breadth-First Search)
广度优先搜索是一种用于图或树的遍历算法。它从起始节点开始,按照层次逐层进行搜索,先访问当前节点的所有邻居,再访问下一层的节点。
算法思想
- 使用队列(Queue)作为辅助数据结构。
- 将起始节点加入队列,并标记为已访问。
- 依次从队列中取出节点,访问其所有未访问的邻居,并将它们加入队列。
- 重复以上步骤,直到队列为空。
特点
- 数据结构:队列。
- 遍历顺序:先访问当前层的所有节点,再访问下一层。
- 复杂度:
- 时间复杂度:O(V + E)(V为顶点数,E为边数)
- 空间复杂度:O(V)(队列最大存储节点数)
- 适用场景:
- 最短路径(无权图)。
- 判断图是否连通。
- 层次遍历(如树的层序遍历)
Java 实现 BFS
import java.util.*;
public class BFS {
public static void bfs(Map<Integer, List<Integer>> graph, int start) {
Queue<Integer> queue = new LinkedList<>(); // 使用队列实现 BFS
Set<Integer> visited = new HashSet<>(); // 记录访问过的节点
queue.add(start); // 将起始节点加入队列
visited.add(start); // 标记为已访问
while (!queue.isEmpty()) {
int node = queue.poll(); // 取出队列头部节点
System.out.print(node + " "); // 处理当前节点
// 遍历邻居节点
for (int neighbor : graph.getOrDefault(node, new ArrayList<>())) {
if (!visited.contains(neighbor)) {
visited.add(neighbor); // 标记邻居为已访问
queue.add(neighbor); // 将邻居加入队列
}
}
}
}
public static void main(String[] args) {
// 使用邻接表表示图
Map<Integer, List<Integer>> graph = new HashMap<>();
graph.put(1, Arrays.asList(2, 3));
graph.put(2, Arrays.asList(4, 5));
graph.put(3, Arrays.asList(6));
graph.put(4, Arrays.asList());
graph.put(5, Arrays.asList(6));
graph.put(6, Arrays.asList());
System.out.println("BFS 遍历:");
bfs(graph, 1); // 从节点 1 开始遍历
}
}
应用场景与示例
1. 最短路径(无权图)
在无权图中,BFS 可以找到从起点到终点的最短路径。
import java.util.*;
public class ShortestPathBFS {
public static int shortestPath(Map<Integer, List<Integer>> graph, int start, int end) {
Queue<Integer> queue = new LinkedList<>();
Map<Integer, Integer> distance = new HashMap<>(); // 记录每个节点的距离
queue.add(start);
distance.put(start, 0);
while (!queue.isEmpty()) {
int node = queue.poll();
// 遍历邻居节点
for (int neighbor : graph.getOrDefault(node, new ArrayList<>())) {
if (!distance.containsKey(neighbor)) { // 如果邻居未访问
distance.put(neighbor, distance.get(node) + 1);
queue.add(neighbor);
// 如果到达终点
if (neighbor == end) {
return distance.get(neighbor);
}
}
}
}
return -1; // 如果终点不可达,返回 -1
}
public static void main(String[] args) {
// 使用邻接表表示图
Map<Integer, List<Integer>> graph = new HashMap<>();
graph.put(1, Arrays.asList(2, 3));
graph.put(2, Arrays.asList(4, 5));
graph.put(3, Arrays.asList(6));
graph.put(4, Arrays.asList());
graph.put(5, Arrays.asList(6));
graph.put(6, Arrays.asList());
System.out.println("最短路径长度:");
System.out.println(shortestPath(graph, 1, 6)); // 从节点 1 到 6 的最短路径
}
}
2. 二分图检测
通过 BFS 检测一个图是否是二分图
import java.util.*;
public class BipartiteGraph {
public static boolean isBipartite(Map<Integer, List<Integer>> graph, int start) {
Map<Integer, Integer> colors = new HashMap<>(); // 节点的颜色
Queue<Integer> queue = new LinkedList<>();
queue.add(start);
colors.put(start, 0); // 给起始节点染色(0 或 1)
while (!queue.isEmpty()) {
int node = queue.poll();
int currentColor = colors.get(node);
// 遍历邻居
for (int neighbor : graph.getOrDefault(node, new ArrayList<>())) {
if (!colors.containsKey(neighbor)) { // 如果未染色
colors.put(neighbor, 1 - currentColor); // 染成相反颜色
queue.add(neighbor);
} else if (colors.get(neighbor) == currentColor) {
return false; // 如果邻居颜色相同,说明不是二分图
}
}
}
return true;
}
public static void main(String[] args) {
// 示例图1:二分图
Map<Integer, List<Integer>> graph1 = new HashMap<>();
graph1.put(1, Arrays.asList(2, 3));
graph1.put(2, Arrays.asList(1, 4));
graph1.put(3, Arrays.asList(1, 4));
graph1.put(4, Arrays.asList(2, 3));
// 示例图2:非二分图
Map<Integer, List<Integer>> graph2 = new HashMap<>();
graph2.put(1, Arrays.asList(2, 3));
graph2.put(2, Arrays.asList(1, 3));
graph2.put(3, Arrays.asList(1, 2));
System.out.println("图1是否是二分图:" + isBipartite(graph1, 1)); // 输出 true
System.out.println("图2是否是二分图:" + isBipartite(graph2, 1)); // 输出 false
}
}
总结
优点
- 能够找到无权图的最短路径。
- 遍历顺序层次分明。
缺点
- 在稠密图中,空间占用较高(因为需要维护队列和访问记录)。
应用场景
- 最短路径:解决无权图的最短路径问题。
- 图的连通性:判断图中节点是否连通。
- 层次遍历:按层访问图或树的节点。
- 二分图检测:检查图是否可以分为两个不相交的集合。
3.3 Dijkstra算法(最短路径)
Dijkstra算法是一种用于计算单源最短路径的经典算法,适用于加权图,要求图的权重为非负
基本思想:
- 使用贪心思想,逐步找到起点到所有其他节点的最短路径。
算法思想
- 初始时,设置起点到所有点的距离为无穷大(∞),起点到自己的距离为 0。
- 从未访问的节点中选择当前距离最小的节点,作为当前节点。
- 更新当前节点的所有邻居节点的距离:
- 如果通过当前节点到达邻居的距离更短,则更新邻居节点的距离。
- 标记当前节点为已访问,重复以上步骤,直到所有节点都被访问,或终点的最短路径已确定。
特点
- 贪心算法:每次选择当前最短路径的节点进行扩展。
- 数据结构:使用优先队列(如堆)优化性能。
- 复杂度:
- 时间复杂度:O((V + E) * log(V)),使用优先队列实现时。
- 空间复杂度:O(V),用于存储距离数组和访问记录。
- 局限性:不能处理负权图(因为负权边可能导致更新距离出错)。
Java 实现 Dijkstra 算法
import java.util.*;
public class Dijkstra {
// Dijkstra 算法计算单源最短路径
public static Map<String, Integer> dijkstra(Map<String, Map<String, Integer>> graph, String start) {
// 存储每个节点到起点的最短距离
Map<String, Integer> distances = new HashMap<>();
for (String node : graph.keySet()) {
distances.put(node, Integer.MAX_VALUE); // 初始距离为 ∞
}
distances.put(start, 0); // 起点到自己的距离为 0
// 优先队列,存储 (距离, 节点) 的二元组
PriorityQueue<Node> pq = new PriorityQueue<>(Comparator.comparingInt(node -> node.distance));
pq.add(new Node(start, 0));
// 已访问的节点集合
Set<String> visited = new HashSet<>();
while (!pq.isEmpty()) {
Node current = pq.poll();
String currentNode = current.name;
// 如果当前节点已访问过,则跳过
if (visited.contains(currentNode)) {
continue;
}
visited.add(currentNode);
// 更新邻居节点的最短距离
Map<String, Integer> neighbors = graph.getOrDefault(currentNode, new HashMap<>());
for (Map.Entry<String, Integer> neighborEntry : neighbors.entrySet()) {
String neighbor = neighborEntry.getKey();
int weight = neighborEntry.getValue();
// 如果未访问,更新距离
if (!visited.contains(neighbor)) {
int newDistance = distances.get(currentNode) + weight;
if (newDistance < distances.get(neighbor)) {
distances.put(neighbor, newDistance);
pq.add(new Node(neighbor, newDistance));
}
}
}
}
return distances;
}
// 定义一个节点类,用于优先队列
static class Node {
String name;
int distance;
Node(String name, int distance) {
this.name = name;
this.distance = distance;
}
}
public static void main(String[] args) {
// 创建图(加权邻接表)
Map<String, Map<String, Integer>> graph = new HashMap<>();
graph.put("A", Map.of("B", 1, "C", 4));
graph.put("B", Map.of("A", 1, "C", 2, "D", 5));
graph.put("C", Map.of("A", 4, "B", 2, "D", 1));
graph.put("D", Map.of("B", 5, "C", 1));
// 计算从节点 A 到其他节点的最短路径
Map<String, Integer> distances = dijkstra(graph, "A");
// 输出结果
System.out.println("从 A 出发的最短路径:");
distances.forEach((node, distance) -> System.out.println(node + " -> " + distance));
}
}
算法总结
优点
- 能够求解带权无向图和有向图的单源最短路径问题。
- 使用优先队列优化后效率较高,适合稠密图。
局限性
- 不适用于包含负权边的图。如果有负权边,可使用 Bellman-Ford 算法。
复杂度
- 时间复杂度:
- 使用优先队列:O((V + E) * log(V)),V 为节点数,E 为边数。
- 空间复杂度:
- O(V + E),用于存储图结构和辅助数据。
Dijkstra 算法是解决单源最短路径问题的经典方法,配合优先队列实现,能高效解决实际应用问题。
3.4A*算法(最短路径)
A*算法是一种高效的图搜索算法,结合了Dijkstra算法的优势(找到最短路径)和启发式搜索的高效性(利用目标方向的信息加速搜索),特别适合用于路径规划问题。
算法思想
A*算法维护两个关键值:
g(x):起点到当前节点x的实际代价(路径长度)。h(x):当前节点x到目标节点的估计代价(启发式函数值)。
总代价函数: f(x)=g(x)+h(x)f(x) = g(x) + h(x)
- g(x) 是当前已经走过的路径的真实代价。
- h(x) 是预估剩余路径的代价,h(x) 必须满足:
- 非负性:h(x)≥0h(x) \geq 0
- 一致性:h(x)≤实际代价h(x) \leq \text{实际代价}
算法通过优先搜索 f(x) 最小的节点来找到最优解。
特点
- 优于 Dijkstra:
- Dijkstra 算法只考虑已走过的路径代价 g(x)g(x),属于“盲目搜索”。
- A* 算法通过启发式函数 h(x)h(x) 指引搜索方向,大幅提升效率。
- 适用场景广泛:
- 适用于多种图和路径规划问题。
- 启发式函数的选择:
- 启发式函数是算法效率的核心:
- 欧几里得距离:适用于直线距离优化问题。
- 曼哈顿距离:适用于格子地图中的移动问题。
- 0 启发值:等价于 Dijkstra 算法。
- 启发式函数是算法效率的核心:
伪代码
function A*(graph, start, goal, heuristic):
初始化优先队列 openSet,将 (f(start), start) 加入
初始化距离表 g,所有节点的初始值为 ∞,起点 start 的 g 值为 0
初始化估计代价表 f,f(start) = g(start) + h(start)
初始化路径表 parent,用于记录路径
while openSet 不为空:
当前节点 current = openSet 中 f 值最小的节点
if current == goal:
返回路径(通过 parent 重建)
将 current 从 openSet 移除
遍历 current 的所有邻居 neighbor:
临时代价 tentative_g = g(current) + 当前边的权重
if tentative_g < g(neighbor):
更新 g(neighbor) = tentative_g
更新 f(neighbor) = g(neighbor) + h(neighbor)
将 neighbor 加入 openSet
更新 parent(neighbor) = current
如果无法找到目标,返回失败
Java 实现
代码示例
以下是一个完整的 Java 实现 A* 算法的代码示例,适用于地图中的路径规划。
import java.util.*;
public class AStar {
// 定义节点类
static class Node {
String name; // 节点名称
int g; // 起点到当前节点的代价
int f; // 总代价:f = g + h
Node parent; // 父节点(用于路径重建)
Node(String name, int g, int f, Node parent) {
this.name = name;
this.g = g;
this.f = f;
this.parent = parent;
}
}
// A* 算法实现
public static List<String> aStar(Map<String, Map<String, Integer>> graph, String start, String goal, Map<String, Integer> heuristic) {
PriorityQueue<Node> openSet = new PriorityQueue<>(Comparator.comparingInt(node -> node.f));
Map<String, Integer> g = new HashMap<>(); // 记录每个节点的 g 值
Set<String> closedSet = new HashSet<>(); // 已访问节点集合
g.put(start, 0);
openSet.add(new Node(start, 0, heuristic.get(start), null));
while (!openSet.isEmpty()) {
Node current = openSet.poll();
// 如果当前节点是目标节点,则返回路径
if (current.name.equals(goal)) {
return reconstructPath(current);
}
closedSet.add(current.name);
// 遍历当前节点的邻居
for (Map.Entry<String, Integer> neighborEntry : graph.getOrDefault(current.name, new HashMap<>()).entrySet()) {
String neighbor = neighborEntry.getKey();
int weight = neighborEntry.getValue();
// 如果邻居已经访问过,跳过
if (closedSet.contains(neighbor)) continue;
int tentative_g = g.getOrDefault(current.name, Integer.MAX_VALUE) + weight;
if (tentative_g < g.getOrDefault(neighbor, Integer.MAX_VALUE)) {
g.put(neighbor, tentative_g);
int f = tentative_g + heuristic.get(neighbor);
openSet.add(new Node(neighbor, tentative_g, f, current));
}
}
}
return new ArrayList<>(); // 无路径可到达
}
// 重建路径
private static List<String> reconstructPath(Node node) {
List<String> path = new ArrayList<>();
while (node != null) {
path.add(node.name);
node = node.parent;
}
Collections.reverse(path);
return path;
}
public static void main(String[] args) {
// 图的邻接表表示
Map<String, Map<String, Integer>> graph = new HashMap<>();
graph.put("A", Map.of("B", 1, "C", 4));
graph.put("B", Map.of("A", 1, "C", 2, "D", 5));
graph.put("C", Map.of("A", 4, "B", 2, "D", 1));
graph.put("D", Map.of("B", 5, "C", 1));
// 启发式函数(估计代价 h 值)
Map<String, Integer> heuristic = new HashMap<>();
heuristic.put("A", 7);
heuristic.put("B", 6);
heuristic.put("C", 2);
heuristic.put("D", 0);
// A* 搜索
List<String> path = aStar(graph, "A", "D", heuristic);
System.out.println("最短路径:" + path);
}
}
运行结果
最短路径:[A, B, C, D]
应用场景
1. 地图导航
- 比如 Google Maps 中,从起点到目的地的最短路径规划。
- 启发式函数可以使用欧几里得距离(直线距离)或曼哈顿距离。
2. 游戏开发
- 用于 AI 寻路问题(如迷宫中的角色移动)。
- 启发式函数结合地图格子坐标的距离。
3. 机器人路径规划
- 确定机器人从当前位置到目标位置的最优路径。
总结
优点
- 结合了 Dijkstra 和启发式搜索的优势。
- 通过启发式函数有效减少搜索范围,提高搜索效率。
缺点
- 需要合理设计启发式函数,函数设计不当可能导致效率低或错误。
- 适用性较强,但在某些特殊情况下(如启发式函数完全错误)会退化为暴力搜索。
复杂度
- 时间复杂度:O(E) 或 O(V^2)(取决于图的稀疏性和启发式函数)。
- 空间复杂度:O(V),需要维护优先队列和距离表。
A* 是路径规划领域的核心算法,在导航、游戏开发和机器人领域有着广泛应用。
3.5 Kruskal算法(最小生成树)
Kruskal算法是用来求解最小生成树(MST, Minimum Spanning Tree)的一种经典算法。最小生成树是一个连通图的子图,它包含了所有的节点,且没有回路,并且边的总权重最小。
Kruskal算法的步骤:
- 边排序:将图中的所有边按权重从小到大排序。
- 初始化:每个顶点初始化为一个独立的集合(通常用并查集实现),即每个顶点是自己的父节点。
- 遍历边:从最小的边开始遍历,如果该边连接的两个顶点属于不同的集合,则将这条边加入到最小生成树中,并将这两个集合合并。
- 终止条件:当最小生成树包含了所有的顶点时,算法终止。
关键数据结构:
- 并查集(Union-Find):用于检查两个顶点是否属于同一集合,并支持高效地合并两个集合。
find(x):找到x所在集合的根节点。union(x, y):合并x和y所在的集合。
Kruskal算法的时间复杂度:
- 边排序的时间复杂度是 O(E log E),其中 E 是边的数量。
- 每次查找和合并操作的时间复杂度是 O(α(V)),其中 V 是顶点数量,α是反阿克曼函数,几乎可以认为是常数。
因此,整体时间复杂度是 O(E log E),这是由于排序的主导作用。
用Java实现Kruskal算法求解最小生成树的代码。代码包含了并查集(Union-Find)数据结构,主要通过排序边,并结合并查集来选择加入最小生成树的边。
Java实现Kruskal算法:
import java.util.*;
// 边类
class Edge implements Comparable<Edge> {
int start, end, weight;
public Edge(int start, int end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public int compareTo(Edge other) {
return this.weight - other.weight; // 按权重升序排序
}
}
// 并查集(Union-Find)类
class UnionFind {
int[] parent;
int[] rank;
public UnionFind(int n) {
parent = new int[n];
rank = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i; // 初始时,每个节点是自己的父节点
rank[i] = 0; // 初始化秩为0
}
}
// 查找根节点,并进行路径压缩
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 路径压缩
}
return parent[x];
}
// 合并两个集合
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
// 根据秩合并树
if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
}
}
// Kruskal算法实现
public class KruskalMST {
public static List<Edge> kruskal(int n, List<Edge> edges) {
// 按照边的权重排序
Collections.sort(edges);
// 并查集初始化
UnionFind uf = new UnionFind(n);
List<Edge> mst = new ArrayList<>(); // 存储最小生成树的边
// 遍历排序后的边,选择合适的边
for (Edge edge : edges) {
int u = edge.start;
int v = edge.end;
// 如果u和v不在同一集合,则加入最小生成树
if (uf.find(u) != uf.find(v)) {
mst.add(edge);
uf.union(u, v); // 合并集合
}
}
return mst;
}
public static void main(String[] args) {
// 创建边
List<Edge> edges = new ArrayList<>();
edges.add(new Edge(0, 1, 1)); // A-B, 权重 1
edges.add(new Edge(0, 2, 3)); // A-C, 权重 3
edges.add(new Edge(1, 2, 2)); // B-C, 权重 2
edges.add(new Edge(1, 3, 4)); // B-D, 权重 4
edges.add(new Edge(2, 3, 5)); // C-D, 权重 5
int n = 4; // 顶点数(A, B, C, D)
// 求最小生成树
List<Edge> mst = kruskal(n, edges);
// 打印最小生成树的边
System.out.println("最小生成树的边:");
for (Edge edge : mst) {
System.out.println("从顶点 " + edge.start + " 到顶点 " + edge.end + ",权重:" + edge.weight);
}
}
}
3.6Prim算法(最小生成树)
Prim算法是一种用于求解最小生成树(Minimum Spanning Tree,MST)的经典算法。最小生成树是指在一个连通无向图中,包含图中所有节点的一个子图,且总边权重最小,并且无环。
Prim算法的核心思想是贪心法,通过逐步扩展已选节点集合,选择权重最小的边,直到构建出最小生成树。
算法思想
- 从任意一个节点开始,将其加入生成树。
- 在所有连接已选节点和未选节点的边中,选择权重最小的边。
- 将边的另一端节点加入生成树。
- 重复步骤 2 和 3,直到所有节点都被加入生成树。
特点
- 贪心算法:每次选择当前权重最小的边。
- 适用场景:适用于稠密图(边数较多)情况。
- 复杂度:
- 使用优先队列优化:O(E * log(V)),E为边数,V为节点数。
- 不使用优先队列:O(V^2)。
Java 实现
import java.util.*;
public class Prim {
// 定义一个边类
static class Edge {
int src; // 边的起点
int dest; // 边的终点
int weight; // 边的权重
Edge(int src, int dest, int weight) {
this.src = src;
this.dest = dest;
this.weight = weight;
}
}
// Prim算法实现
public static List<Edge> primAlgorithm(Map<Integer, List<Edge>> graph, int start) {
PriorityQueue<Edge> priorityQueue = new PriorityQueue<>(Comparator.comparingInt(e -> e.weight));
Set<Integer> visited = new HashSet<>();
List<Edge> mst = new ArrayList<>();
// 将起始节点的所有边加入优先队列
visited.add(start);
priorityQueue.addAll(graph.getOrDefault(start, new ArrayList<>()));
while (!priorityQueue.isEmpty()) {
// 取出权重最小的边
Edge edge = priorityQueue.poll();
// 如果目标节点未被访问
if (!visited.contains(edge.dest)) {
visited.add(edge.dest);
mst.add(edge);
// 将目标节点的所有未访问邻边加入优先队列
for (Edge nextEdge : graph.getOrDefault(edge.dest, new ArrayList<>())) {
if (!visited.contains(nextEdge.dest)) {
priorityQueue.add(nextEdge);
}
}
}
}
return mst;
}
public static void main(String[] args) {
// 图的邻接表表示(无向图)
Map<Integer, List<Edge>> graph = new HashMap<>();
graph.put(1, Arrays.asList(new Edge(1, 2, 1), new Edge(1, 3, 4)));
graph.put(2, Arrays.asList(new Edge(2, 1, 1), new Edge(2, 3, 2), new Edge(2, 4, 5)));
graph.put(3, Arrays.asList(new Edge(3, 1, 4), new Edge(3, 2, 2), new Edge(3, 4, 1)));
graph.put(4, Arrays.asList(new Edge(4, 2, 5), new Edge(4, 3, 1)));
// 执行 Prim 算法
List<Edge> mst = primAlgorithm(graph, 1);
// 输出结果
System.out.println("最小生成树的边:");
for (Edge edge : mst) {
System.out.println("起点:" + edge.src + " -> 终点:" + edge.dest + ",权重:" + edge.weight);
}
}
}
4. 动态规划算法
动态规划用于解决可以分解为子问题的优化问题
4.1 斐波那契数列(Fibonacci)
问题描述
斐波那契数列是一个递推数列,定义如下:
- F(0) = 0,F(1) = 1
- F(n) = F(n-1) + F(n-2),n ≥ 2
实现方法
递归实现
public class FibonacciRecursive {
public static int fibonacci(int n) {
if (n <= 1) return n; // 终止条件
return fibonacci(n - 1) + fibonacci(n - 2); // 递归公式
}
public static void main(String[] args) {
int n = 10;
System.out.println("Fibonacci(" + n + ") = " + fibonacci(n));
}
}
动态规划实现
public class FibonacciDP {
public static int fibonacci(int n) {
if (n <= 1) return n;
int[] dp = new int[n + 1];
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
public static void main(String[] args) {
int n = 10;
System.out.println("Fibonacci(" + n + ") = " + fibonacci(n));
}
}
优化的动态规划(O(1)空间)
public class FibonacciOptimized {
public static int fibonacci(int n) {
if (n <= 1) return n;
int a = 0, b = 1;
for (int i = 2; i <= n; i++) {
int temp = a + b;
a = b;
b = temp;
}
return b;
}
public static void main(String[] args) {
int n = 10;
System.out.println("Fibonacci(" + n + ") = " + fibonacci(n));
}
}
4.2 背包问题(Knapsack Problem)
问题描述
给定容量为 W 的背包和 n 个物品,每个物品有重量 wt[i] 和价值 val[i],求在不超过背包容量的情况下,使得总价值最大。
动态规划实现
- 状态定义:
dp[i][w]表示前i个物品在容量w下的最大价值。 - 转移方程:
- 不选择物品
i:dp[i][w] = dp[i-1][w] - 选择物品
i:dp[i][w] = dp[i-1][w-wt[i-1]] + val[i-1] - 综合:
dp[i][w] = max(dp[i-1][w], dp[i-1][w-wt[i-1]] + val[i-1])
- 不选择物品
public class Knapsack {
public static int knapsack(int[] wt, int[] val, int W) {
int n = wt.length;
int[][] dp = new int[n + 1][W + 1];
for (int i = 1; i <= n; i++) {
for (int w = 0; w <= W; w++) {
if (wt[i - 1] <= w) {
dp[i][w] = Math.max(dp[i - 1][w], dp[i - 1][w - wt[i - 1]] + val[i - 1]);
} else {
dp[i][w] = dp[i - 1][w];
}
}
}
return dp[n][W];
}
public static void main(String[] args) {
int[] wt = {1, 2, 3};
int[] val = {6, 10, 12};
int W = 5;
System.out.println("最大价值:" + knapsack(wt, val, W));
}
}
4.3 最长公共子序列(Longest Common Subsequence, LCS)
问题描述
给定两个字符串 text1 和 text2,找到它们的最长公共子序列长度(不要求连续)。
动态规划实现
- 状态定义:
dp[i][j]表示字符串text1[0..i-1]和text2[0..j-1]的最长公共子序列长度。 - 转移方程:
- 如果
text1[i-1] == text2[j-1]:dp[i][j] = dp[i-1][j-1] + 1 - 否则:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
- 如果
public class LongestCommonSubsequence {
public static int longestCommonSubsequence(String text1, String text2) {
int m = text1.length(), n = text2.length();
int[][] dp = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (text1.charAt(i - 1) == text2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n];
}
public static void main(String[] args) {
String text1 = "abcde";
String text2 = "ace";
System.out.println("最长公共子序列长度:" + longestCommonSubsequence(text1, text2));
}
}
优化的动态规划(O(n) 空间)
public class LongestCommonSubsequenceOptimized {
public static int longestCommonSubsequence(String text1, String text2) {
int m = text1.length(), n = text2.length();
int[] dp = new int[n + 1];
for (int i = 1; i <= m; i++) {
int prev = 0; // 上一行的 dp[j-1]
for (int j = 1; j <= n; j++) {
int temp = dp[j];
if (text1.charAt(i - 1) == text2.charAt(j - 1)) {
dp[j] = prev + 1;
} else {
dp[j] = Math.max(dp[j], dp[j - 1]);
}
prev = temp; // 更新上一行的 dp[j-1]
}
}
return dp[n];
}
public static void main(String[] args) {
String text1 = "abcde";
String text2 = "ace";
System.out.println("最长公共子序列长度:" + longestCommonSubsequence(text1, text2));
}
}
4.4 斐波那契数列(Fibonacci)
斐波那契数列(Fibonacci Sequence)是一个由意大利数学家莱昂纳多·斐波那契(Leonardo Fibonacci)提出的数列。数列中的每个数(从第三个开始)都等于前两个数的和。
数列定义:
斐波那契数列的前两个数是 0 和 1,后面的数是由前两个数相加得出的,即:
- F(0) = 0
- F(1) = 1
- F(n) = F(n-1) + F(n-2) (对于 n ≥ 2)
斐波那契数列的前几个数:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ...
斐波那契数列的计算方法:
-
递归法: 递归是斐波那契数列的自然定义方式,但递归方法的时间复杂度较高,通常不适合直接用于计算较大的数字。
-
迭代法: 迭代方法通过不断更新前两个数来计算斐波那契数列,可以有效避免重复计算,时间复杂度为 O(n)。
-
动态规划法: 动态规划使用一个数组来保存每一步的计算结果,避免了递归中的重复计算。时间复杂度为 O(n),空间复杂度为 O(n)。
Java实现斐波那契数列
递归实现:
public class Fibonacci {
public static int fibonacci(int n) {
if (n <= 1) {
return n;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}
public static void main(String[] args) {
int n = 10; // 计算斐波那契数列的第10个数
System.out.println("斐波那契数列第" + n + "个数是:" + fibonacci(n));
}
}
迭代实现:
public class Fibonacci {
public static int fibonacci(int n) {
if (n <= 1) {
return n;
}
int a = 0, b = 1;
for (int i = 2; i <= n; i++) {
int temp = a + b;
a = b;
b = temp;
}
return b;
}
public static void main(String[] args) {
int n = 10; // 计算斐波那契数列的第10个数
System.out.println("斐波那契数列第" + n + "个数是:" + fibonacci(n));
}
}
动态规划实现:
public class Fibonacci {
public static int fibonacci(int n) {
if (n <= 1) {
return n;
}
int[] dp = new int[n + 1];
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
public static void main(String[] args) {
int n = 10; // 计算斐波那契数列的第10个数
System.out.println("斐波那契数列第" + n + "个数是:" + fibonacci(n));
}
}
时间复杂度:
- 递归法:时间复杂度是 O(2^n),因为会有大量的重复计算。
- 迭代法:时间复杂度是 O(n),每次迭代只进行一次常数时间的运算。
- 动态规划法:时间复杂度是 O(n),并且空间复杂度是 O(n),因为需要保存每一步的结果。
如果只关心空间复杂度,还可以将动态规划优化成常数空间复杂度 O(1),只保存前两个数的值。
常数空间优化的动态规划实现:
public class Fibonacci {
public static int fibonacci(int n) {
if (n <= 1) {
return n;
}
int a = 0, b = 1;
for (int i = 2; i <= n; i++) {
int temp = a + b;
a = b;
b = temp;
}
return b;
}
public static void main(String[] args) {
int n = 10; // 计算斐波那契数列的第10个数
System.out.println("斐波那契数列第" + n + "个数是:" + fibonacci(n));
}
}
总结:
斐波那契数列是一个经典的递归问题,在实际应用中常用来优化动态规划或分治算法。
4.5 最长公共子序列(Longest Common Subsequence)
最长公共子序列(LCS, Longest Common Subsequence)问题是一个经典的动态规划问题。给定两个序列,求出它们的最长公共子序列。子序列是指通过删除一些元素(可以不删除任何元素)而不改变顺序得到的序列。
问题描述:
- 输入:两个序列
X和Y。 - 输出:它们的最长公共子序列的长度。
递推公式:
设 dp[i][j] 表示序列 X[0..i-1] 和 Y[0..j-1] 的最长公共子序列的长度,递推公式为:
- 如果
X[i-1] == Y[j-1],则:dp[i][j] = dp[i-1][j-1] + 1 - 如果
X[i-1] != Y[j-1],则:dp[i][j] = max(dp[i-1][j], dp[i][j-1])
动态规划解法:
- 定义一个二维数组
dp,其中dp[i][j]表示字符串X[0..i-1]和Y[0..j-1]的最长公共子序列的长度。 - 初始条件:
dp[0][j] = 0和dp[i][0] = 0,即当其中一个序列为空时,最长公共子序列的长度为 0。 - 遍历两个序列,按递推公式更新
dp数组。
Java实现:
public class LCS {
// 求解最长公共子序列的长度
public static int longestCommonSubsequence(String X, String Y) {
int m = X.length();
int n = Y.length();
// 创建dp数组,dp[i][j]表示X[0..i-1]与Y[0..j-1]的LCS长度
int[][] dp = new int[m + 1][n + 1];
// 填充dp数组
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
// 如果字符相同
if (X.charAt(i - 1) == Y.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// 如果字符不同,取上一个状态的最大值
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// 最后一个元素即为LCS的长度
return dp[m][n];
}
// 反向推导LCS的具体内容
public static String printLCS(String X, String Y) {
int m = X.length();
int n = Y.length();
int[][] dp = new int[m + 1][n + 1];
// 填充dp数组
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (X.charAt(i - 1) == Y.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// 反向推导LCS的字符串
StringBuilder lcs = new StringBuilder();
int i = m, j = n;
while (i > 0 && j > 0) {
if (X.charAt(i - 1) == Y.charAt(j - 1)) {
lcs.append(X.charAt(i - 1)); // 如果相同,字符加入LCS
i--;
j--;
} else if (dp[i - 1][j] >= dp[i][j - 1]) {
i--; // 向上移动
} else {
j--; // 向左移动
}
}
return lcs.reverse().toString(); // 反转得到正确的LCS字符串
}
public static void main(String[] args) {
String X = "AGGTAB";
String Y = "GXTXAYB";
// 计算LCS的长度
int length = longestCommonSubsequence(X, Y);
System.out.println("最长公共子序列的长度: " + length);
// 打印LCS
String lcs = printLCS(X, Y);
System.out.println("最长公共子序列: " + lcs);
}
}
代码说明:
longestCommonSubsequence(String X, String Y):这个方法返回两个字符串X和Y的最长公共子序列的长度。我们通过构建一个二维的动态规划数组dp来实现该功能。printLCS(String X, String Y):这个方法返回两个字符串X和Y的最长公共子序列的具体内容。我们通过反向追溯dp数组来构造LCS字符串。
运行结果:
最长公共子序列的长度: 4
最长公共子序列: GTAB
时间复杂度:
- 时间复杂度:O(m * n),其中 m 和 n 分别是两个字符串的长度。我们需要填充一个大小为
m * n的dp数组。 - 空间复杂度:O(m * n),我们使用了一个大小为
m * n的二维数组来存储每一对子序列的LCS长度。
优化空间复杂度:
如果只关心最长公共子序列的长度,可以将空间复杂度优化为 O(n):
- 只保留当前和上一行的
dp数组,减少空间消耗。
总结:
最长公共子序列(LCS)是一个典型的动态规划问题,广泛应用于文本比较、版本控制和生物序列比对等领域。
5. 贪心算法
贪心算法是一种逐步构建解的算法,每一步都选择当前最优解(局部最优解),最终期望得到问题的全局最优解。
特点
- 贪心选择性质:通过局部最优选择,能达到全局最优。
- 无后效性:当前步骤的选择不会影响后续步骤。
- 适用场景:只适用于满足贪心选择性质和无后效性的优化问题。
5.1 最小生成树(如Prim、Kruskal)
最小生成树问题是图论中的一个经典问题。对于一个连通无向图,最小生成树是一个包含图中所有顶点的树,使得总边权值之和最小。
1. Kruskal 算法 (Java 实现)
核心思路
- 按边的权值从小到大排序。
- 逐步选择权值最小的边,加入生成树,确保不会形成环。
- 使用 并查集 检测是否会形成环。
示例代码
import java.util.*;
class Edge implements Comparable<Edge> {
int src, dest, weight;
public Edge(int src, int dest, int weight) {
this.src = src;
this.dest = dest;
this.weight = weight;
}
@Override
public int compareTo(Edge other) {
return this.weight - other.weight;
}
}
public class KruskalMST {
static int findParent(int v, int[] parent) {
if (v != parent[v]) {
parent[v] = findParent(parent[v], parent); // 路径压缩
}
return parent[v];
}
static void union(int v1, int v2, int[] parent, int[] rank) {
int root1 = findParent(v1, parent);
int root2 = findParent(v2, parent);
if (root1 != root2) {
if (rank[root1] > rank[root2]) {
parent[root2] = root1;
} else if (rank[root1] < rank[root2]) {
parent[root1] = root2;
} else {
parent[root2] = root1;
rank[root1]++;
}
}
}
public static void main(String[] args) {
int V = 4; // 节点数
List<Edge> edges = new ArrayList<>();
edges.add(new Edge(0, 1, 10));
edges.add(new Edge(0, 2, 6));
edges.add(new Edge(0, 3, 5));
edges.add(new Edge(1, 3, 15));
edges.add(new Edge(2, 3, 4));
// 按边权值排序
Collections.sort(edges);
// 初始化并查集
int[] parent = new int[V];
int[] rank = new int[V];
for (int i = 0; i < V; i++) {
parent[i] = i;
rank[i] = 0;
}
// Kruskal 算法主逻辑
List<Edge> mst = new ArrayList<>();
for (Edge edge : edges) {
int root1 = findParent(edge.src, parent);
int root2 = findParent(edge.dest, parent);
if (root1 != root2) { // 如果不形成环
mst.add(edge);
union(root1, root2, parent, rank);
}
}
// 输出最小生成树
System.out.println("最小生成树的边:");
for (Edge edge : mst) {
System.out.println("(" + edge.src + ", " + edge.dest + ", 权值: " + edge.weight + ")");
}
}
}
输入
图的边:[(0, 1, 10), (0, 2, 6), (0, 3, 5), (1, 3, 15), (2, 3, 4)]
输出
最小生成树的边:
(2, 3, 权值: 4)
(0, 3, 权值: 5)
(0, 1, 权值: 10)
2. Prim 算法 (Java 实现)
核心思路
- 从任意起始点开始,选取权值最小的边加入生成树。
- 使用一个优先队列维护与生成树相连的最小权值边。
- 每次选取最小权值边,并将新加入的顶点更新到优先队列中。
示例代码
import java.util.*;
class PrimMST {
static class Edge {
int src, dest, weight;
public Edge(int src, int dest, int weight) {
this.src = src;
this.dest = dest;
this.weight = weight;
}
}
public static void primMST(int V, List<Edge>[] graph) {
boolean[] visited = new boolean[V];
PriorityQueue<Edge> pq = new PriorityQueue<>(Comparator.comparingInt(e -> e.weight));
// 从节点 0 开始
visited[0] = true;
pq.addAll(graph[0]);
List<Edge> mst = new ArrayList<>();
while (!pq.isEmpty() && mst.size() < V - 1) {
Edge edge = pq.poll();
if (visited[edge.dest]) continue;
// 将边加入最小生成树
mst.add(edge);
visited[edge.dest] = true;
// 将新加入顶点的所有边加入优先队列
for (Edge next : graph[edge.dest]) {
if (!visited[next.dest]) {
pq.add(next);
}
}
}
// 输出最小生成树
System.out.println("最小生成树的边:");
for (Edge edge : mst) {
System.out.println("(" + edge.src + ", " + edge.dest + ", 权值: " + edge.weight + ")");
}
}
public static void main(String[] args) {
int V = 4; // 节点数
List<Edge>[] graph = new ArrayList[V];
for (int i = 0; i < V; i++) {
graph[i] = new ArrayList<>();
}
// 添加边
graph[0].add(new Edge(0, 1, 10));
graph[0].add(new Edge(0, 2, 6));
graph[0].add(new Edge(0, 3, 5));
graph[1].add(new Edge(1, 0, 10));
graph[1].add(new Edge(1, 3, 15));
graph[2].add(new Edge(2, 0, 6));
graph[2].add(new Edge(2, 3, 4));
graph[3].add(new Edge(3, 0, 5));
graph[3].add(new Edge(3, 1, 15));
graph[3].add(new Edge(3, 2, 4));
primMST(V, graph);
}
}
输入
图的边:[(0, 1, 10), (0, 2, 6), (0, 3, 5), (1, 3, 15), (2, 3, 4)]
输出
最小生成树的边:
(0, 3, 权值: 5)
(3, 2, 权值: 4)
(0, 1, 权值: 10)
两种算法的对比
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Kruskal 算法 | 简单易实现,适合稀疏图 | 边排序需要时间,依赖并查集 | 图的边较少时(稀疏图) |
| Prim 算法 | 更高效,适合稠密图 | 需要优先队列,邻接表更高效 | 图的边较多时(稠密图) |
总结
- Kruskal 算法 更关注边的排序与合并操作,适合边数较少的图。
- Prim 算法 更关注从顶点出发动态选择边,适合边数较多的图。
- 根据具体图的稀疏程度选择合适的算法,都是实现最小生成树的经典方法。
5.2活动选择问题(Activity Selection Problem)
活动选择问题是一个经典的贪心算法问题,目标是从一组具有开始时间和结束时间的活动中选择尽可能多的活动,且这些活动互不冲突(即一个活动的开始时间不能早于前一个活动的结束时间)。
问题描述
给定 n 个活动的开始时间和结束时间,要求选择尽可能多的活动参与,满足活动之间没有时间重叠。
输入
- 两个数组
start[]和end[],分别表示每个活动的开始时间和结束时间。
输出
- 可以选择的最大活动数量。
贪心算法的核心思想
-
按活动结束时间排序:
- 为了保证我们可以安排尽可能多的活动,优先选择结束时间最早的活动。这样,剩余的时间可以容纳更多的活动。
-
选择第一个活动:
- 选择第一个结束时间最早的活动,然后检查下一个不冲突的活动。
-
跳过冲突的活动:
- 如果一个活动的开始时间早于当前选择活动的结束时间,则跳过该活动。
贪心算法步骤
- 将所有活动按结束时间从小到大排序。
- 初始化一个变量
lastSelectedEnd,表示最后被选择的活动的结束时间(初始值为负无穷)。 - 遍历所有活动:
- 如果当前活动的开始时间大于等于
lastSelectedEnd:- 选择该活动。
- 更新
lastSelectedEnd为当前活动的结束时间。
- 如果当前活动的开始时间大于等于
- 输出被选择的活动数量。
import java.util.Arrays;
import java.util.Comparator;
public class ActivitySelection {
// 活动类,用于存储开始时间和结束时间
static class Activity {
int start;
int end;
public Activity(int start, int end) {
this.start = start;
this.end = end;
}
}
public static int maxActivities(Activity[] activities) {
// 按活动结束时间排序
Arrays.sort(activities, Comparator.comparingInt(a -> a.end));
int count = 0; // 被选择的活动数量
int lastEndTime = 0; // 上一个被选择活动的结束时间
for (Activity activity : activities) {
// 如果当前活动的开始时间大于等于上一个活动的结束时间
if (activity.start >= lastEndTime) {
count++; // 选择该活动
lastEndTime = activity.end; // 更新最后选择活动的结束时间
}
}
return count;
}
public static void main(String[] args) {
// 示例输入:活动的开始时间和结束时间
Activity[] activities = {
new Activity(1, 3),
new Activity(2, 5),
new Activity(3, 4),
new Activity(0, 6),
new Activity(5, 7),
new Activity(8, 9),
new Activity(5, 9)
};
// 输出最大活动数量
System.out.println("最大可选活动数量: " + maxActivities(activities));
}
}
时间复杂度
- 排序的复杂度:O(n log n)(基于结束时间排序)。
- 选择活动的复杂度:O(n)。
- 总时间复杂度:O(n log n)。
总结
- 活动选择问题是贪心算法的经典案例,通过先排序再逐一选择活动,可以在 O(n log n) 的时间复杂度内完成问题求解。
- 核心思想是优先选择结束时间最早的活动,以便留下更多的时间给后续活动。
5.3霍夫曼编码(Huffman Coding)
霍夫曼编码是一种基于贪心策略的最优前缀编码(Prefix Code),常用于数据压缩(如文件压缩、图像压缩等)。它通过对字符的频率进行分析,利用频率高的字符分配较短的编码,频率低的字符分配较长的编码,从而实现压缩。
核心思想
- 使用一棵二叉树表示编码结构,树的每条边代表 0 或 1。
- 低频字符在树的深层位置,编码更长;高频字符在树的浅层位置,编码更短。
- 编码结果是前缀编码:任何字符的编码都不是其他字符编码的前缀,这确保了解码时不会产生歧义。
霍夫曼编码的步骤
输入:
给定一组字符及其出现的频率。
输出:
每个字符的霍夫曼编码。
实现步骤:
- 统计字符频率:
- 计算每个字符在文本中出现的频率。
- 构造最小堆:
- 将每个字符及其频率视为一个节点,存入最小堆。
- 构造霍夫曼树:
- 每次从最小堆中取出两个最小频率的节点,合并为一个新节点,新节点的频率为两个子节点频率之和。
- 将新节点插入最小堆,重复直到堆中只有一个节点(根节点)。
- 生成编码:
- 从根节点出发,为左子树分配
0,为右子树分配1,递归生成每个字符的霍夫曼编码。
- 从根节点出发,为左子树分配
- 压缩数据:
- 用生成的编码替换原字符,压缩文本。
示例
输入:
字符集和对应频率:
字符: A B C D E F
频率: 5 9 12 13 16 45
输出:
霍夫曼编码:
F: 0
C: 100
D: 101
A: 1100
B: 1101
E: 111
霍夫曼树结构:
[100]
/ \
[55] F
/ \
[25] E
/ \
A B
/ \
C D
时间复杂度
- 最小堆构造:O(n log n),
n是字符个数。 - 构造霍夫曼树:O(n log n),因为最小堆中插入与删除操作的复杂度为 O(log n)。
- 总时间复杂度:O(n log n)。
Java 实现
import java.util.PriorityQueue;
// 霍夫曼树节点类
class HuffmanNode implements Comparable<HuffmanNode> {
char ch;
int frequency;
HuffmanNode left;
HuffmanNode right;
// 构造方法
public HuffmanNode(char ch, int frequency) {
this.ch = ch;
this.frequency = frequency;
}
@Override
public int compareTo(HuffmanNode node) {
return this.frequency - node.frequency;
}
}
public class HuffmanCoding {
public static void printCodes(HuffmanNode root, String code) {
if (root == null) return;
// 如果是叶子节点,打印字符和对应编码
if (root.left == null && root.right == null) {
System.out.println(root.ch + ": " + code);
return;
}
// 递归遍历左右子树
printCodes(root.left, code + "0");
printCodes(root.right, code + "1");
}
public static void main(String[] args) {
// 示例输入:字符和对应频率
char[] chars = { 'A', 'B', 'C', 'D', 'E', 'F' };
int[] freq = { 5, 9, 12, 13, 16, 45 };
// 构造最小堆
PriorityQueue<HuffmanNode> pq = new PriorityQueue<>();
// 初始化堆
for (int i = 0; i < chars.length; i++) {
pq.add(new HuffmanNode(chars[i], freq[i]));
}
// 构造霍夫曼树
while (pq.size() > 1) {
HuffmanNode left = pq.poll();
HuffmanNode right = pq.poll();
// 合并两个最小频率节点
HuffmanNode newNode = new HuffmanNode('-', left.frequency + right.frequency);
newNode.left = left;
newNode.right = right;
pq.add(newNode);
}
// 生成霍夫曼编码
HuffmanNode root = pq.poll();
System.out.println("霍夫曼编码:");
printCodes(root, "");
}
}
示例输出
霍夫曼编码:
A: 1100
B: 1101
C: 100
D: 101
E: 111
F: 0
应用场景
- 文件压缩:
- 如 ZIP、RAR 等压缩工具。
- 通信编码:
- 如图片(JPEG)、视频(MPEG)中的数据压缩。
- 传感器数据:
- 在嵌入式设备中,通过霍夫曼编码减少数据传输大小。
总结
霍夫曼编码是一种最优前缀编码,用于无损压缩。通过频率分配短码和长码,它能够显著提高压缩效率。学习霍夫曼编码可以帮助理解数据压缩原理以及如何设计高效的编码算法。
霍夫曼编码的步骤
输入:
给定一组字符及其出现的频率。
输出:
每个字符的霍夫曼编码。
实现步骤:
- 统计字符频率:
- 计算每个字符在文本中出现的频率。
- 构造最小堆:
- 将每个字符及其频率视为一个节点,存入最小堆。
- 构造霍夫曼树:
- 每次从最小堆中取出两个最小频率的节点,合并为一个新节点,新节点的频率为两个子节点频率之和。
- 将新节点插入最小堆,重复直到堆中只有一个节点(根节点)。
- 生成编码:
- 从根节点出发,为左子树分配
0,为右子树分配1,递归生成每个字符的霍夫曼编码。
- 从根节点出发,为左子树分配
- 压缩数据:
- 用生成的编码替换原字符,压缩文本。
6. 回溯算法
回溯算法是一种通过探索所有可能的解来解决问题的算法,特别适用于约束满足问题(Constraint Satisfaction Problems)。它通过逐步构建解的路径,当发现当前路径不能得到问题的解时,就回溯到上一步重新尝试。
1. 八皇后问题 (N-Queens Problem)
问题描述
在 N×N 的棋盘上放置 N 个皇后,使得任意两个皇后不在同一行、同一列或同一对角线上。
Java 实现(回溯法)
import java.util.ArrayList;
import java.util.List;
public class NQueens {
public static void main(String[] args) {
int n = 8; // 棋盘大小
List<List<String>> solutions = solveNQueens(n);
System.out.println("共有解法数量: " + solutions.size());
for (List<String> solution : solutions) {
for (String row : solution) {
System.out.println(row);
}
System.out.println();
}
}
public static List<List<String>> solveNQueens(int n) {
List<List<String>> solutions = new ArrayList<>();
int[] queens = new int[n]; // queens[i] 表示第 i 行皇后所在的列
solve(0, n, queens, solutions);
return solutions;
}
private static void solve(int row, int n, int[] queens, List<List<String>> solutions) {
if (row == n) {
solutions.add(generateBoard(queens, n));
return;
}
for (int col = 0; col < n; col++) {
if (isSafe(row, col, queens)) {
queens[row] = col;
solve(row + 1, n, queens, solutions);
}
}
}
private static boolean isSafe(int row, int col, int[] queens) {
for (int i = 0; i < row; i++) {
if (queens[i] == col || Math.abs(queens[i] - col) == Math.abs(i - row)) {
return false; // 同列或同对角线冲突
}
}
return true;
}
private static List<String> generateBoard(int[] queens, int n) {
List<String> board = new ArrayList<>();
for (int i = 0; i < n; i++) {
char[] row = new char[n];
for (int j = 0; j < n; j++) {
row[j] = '.';
}
row[queens[i]] = 'Q';
board.add(new String(row));
}
return board;
}
}
2. 数独问题 (Sudoku)
问题描述
在一个 9×9 的棋盘上填入数字 1到 9,使得:
- 每行的数字不重复。
- 每列的数字不重复。
- 每个 3×3 小方块的数字不重复。
Java 实现(回溯法)
public class SudokuSolver {
public static void main(String[] args) {
char[][] board = {
{'5', '3', '.', '.', '7', '.', '.', '.', '.'},
{'6', '.', '.', '1', '9', '5', '.', '.', '.'},
{'.', '9', '8', '.', '.', '.', '.', '6', '.'},
{'8', '.', '.', '.', '6', '.', '.', '.', '3'},
{'4', '.', '.', '8', '.', '3', '.', '.', '1'},
{'7', '.', '.', '.', '2', '.', '.', '.', '6'},
{'.', '6', '.', '.', '.', '.', '2', '8', '.'},
{'.', '.', '.', '4', '1', '9', '.', '.', '5'},
{'.', '.', '.', '.', '8', '.', '.', '7', '9'}
};
solveSudoku(board);
printBoard(board);
}
public static void solveSudoku(char[][] board) {
solve(board);
}
private static boolean solve(char[][] board) {
for (int row = 0; row < 9; row++) {
for (int col = 0; col < 9; col++) {
if (board[row][col] == '.') {
for (char num = '1'; num <= '9'; num++) {
if (isValid(board, row, col, num)) {
board[row][col] = num;
if (solve(board)) {
return true;
}
board[row][col] = '.'; // 回溯
}
}
return false;
}
}
}
return true;
}
private static boolean isValid(char[][] board, int row, int col, char num) {
for (int i = 0; i < 9; i++) {
if (board[row][i] == num || board[i][col] == num || board[row / 3 * 3 + i / 3][col / 3 * 3 + i % 3] == num) {
return false;
}
}
return true;
}
private static void printBoard(char[][] board) {
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
System.out.print(board[i][j] + " ");
}
System.out.println();
}
}
}
3. 组合问题 (Combination Problem)
问题描述
给定正整数 n 和 k,从 11到 n 中选出 k 个数的所有组合。
Java 实现(回溯法)
import java.util.ArrayList;
import java.util.List;
public class Combinations {
public static void main(String[] args) {
int n = 4, k = 2;
List<List<Integer>> result = combine(n, k);
System.out.println(result);
}
public static List<List<Integer>> combine(int n, int k) {
List<List<Integer>> result = new ArrayList<>();
backtrack(n, k, 1, new ArrayList<>(), result);
return result;
}
private static void backtrack(int n, int k, int start, List<Integer> combination, List<List<Integer>> result) {
if (combination.size() == k) {
result.add(new ArrayList<>(combination));
return;
}
for (int i = start; i <= n; i++) {
combination.add(i);
backtrack(n, k, i + 1, combination, result);
combination.remove(combination.size() - 1); // 回溯
}
}
}
输出
n = 4, k = 2
[[1, 2], [1, 3], [1, 4], [2, 3], [2, 4], [3, 4]]
总结
| 问题 | 算法类型 | 解法特点 | 应用场景 |
|---|---|---|---|
| 八皇后问题 | 回溯法 | 递归逐行放置皇后,确保无冲突 | 博弈问题、优化问题 |
| 数独问题 | 回溯法 | 对空格尝试填数,递归验证有效性 | 数独求解、逻辑推理 |
| 组合问题 | 回溯法 | 递归生成组合,剪枝避免重复 | 子集求解、排列组合问题 |
7. 分治算法
分治算法将问题分解成子问题,分别解决后合并结果:
- 快速排序(Quick Sort)
- 归并排序(Merge Sort)
- 二分查找(Binary Search)
以下是 快速排序(Quick Sort)、归并排序(Merge Sort) 和 二分查找(Binary Search) 的详细解释及 Java 实现。
1. 快速排序 (Quick Sort)
算法简介
快速排序是一种 分治法 排序算法,通过选择一个基准(pivot),将数组划分为两部分:一部分小于基准,一部分大于基准,递归地对两部分排序。
时间复杂度
- 最坏情况:O(n2)O(n^2)(当基准总是最大或最小值时)。
- 平均情况:O(nlogn)O(n \log n)。
- 空间复杂度:O(logn)O(\log n)(递归栈深度)。
Java 实现
import java.util.Arrays;
public class QuickSort {
public static void quickSort(int[] arr, int low, int high) {
if (low < high) {
int pivotIndex = partition(arr, low, high);
quickSort(arr, low, pivotIndex - 1); // 左子数组
quickSort(arr, pivotIndex + 1, high); // 右子数组
}
}
private static int partition(int[] arr, int low, int high) {
int pivot = arr[high]; // 选择最后一个元素作为基准
int i = low - 1; // i 表示小于 pivot 的区域结束位置
for (int j = low; j < high; j++) {
if (arr[j] <= pivot) { // 将小于 pivot 的元素移到左边
i++;
swap(arr, i, j);
}
}
swap(arr, i + 1, high); // 将 pivot 放到正确位置
return i + 1; // 返回 pivot 的索引
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
public static void main(String[] args) {
int[] arr = {10, 7, 8, 9, 1, 5};
System.out.println("原始数组: " + Arrays.toString(arr));
quickSort(arr, 0, arr.length - 1);
System.out.println("快速排序结果: " + Arrays.toString(arr));
}
}
输出
原始数组: [10, 7, 8, 9, 1, 5]
快速排序结果: [1, 5, 7, 8, 9, 10]
2. 归并排序 (Merge Sort)
算法简介
归并排序是一种 分治法 排序算法,将数组分为两半,分别排序后合并。它是稳定排序算法。
时间复杂度
- 最坏情况:O(nlogn)O(n \log n)。
- 平均情况:O(nlogn)O(n \log n)。
- 空间复杂度:O(n)O(n)。
Java 实现
import java.util.Arrays;
public class MergeSort {
public static void mergeSort(int[] arr, int left, int right) {
if (left < right) {
int mid = left + (right - left) / 2;
// 分别排序左半部分和右半部分
mergeSort(arr, left, mid);
mergeSort(arr, mid + 1, right);
// 合并两个有序数组
merge(arr, left, mid, right);
}
}
private static void merge(int[] arr, int left, int mid, int right) {
int n1 = mid - left + 1; // 左半部分长度
int n2 = right - mid; // 右半部分长度
int[] leftArray = new int[n1];
int[] rightArray = new int[n2];
// 复制数据到左右数组
for (int i = 0; i < n1; i++) leftArray[i] = arr[left + i];
for (int j = 0; j < n2; j++) rightArray[j] = arr[mid + 1 + j];
// 合并左右数组
int i = 0, j = 0, k = left;
while (i < n1 && j < n2) {
if (leftArray[i] <= rightArray[j]) {
arr[k++] = leftArray[i++];
} else {
arr[k++] = rightArray[j++];
}
}
// 复制剩余元素
while (i < n1) arr[k++] = leftArray[i++];
while (j < n2) arr[k++] = rightArray[j++];
}
public static void main(String[] args) {
int[] arr = {12, 11, 13, 5, 6, 7};
System.out.println("原始数组: " + Arrays.toString(arr));
mergeSort(arr, 0, arr.length - 1);
System.out.println("归并排序结果: " + Arrays.toString(arr));
}
}
输出
原始数组: [12, 11, 13, 5, 6, 7]
归并排序结果: [5, 6, 7, 11, 12, 13]
3. 二分查找 (Binary Search)
算法简介
二分查找在一个已排序的数组中查找目标值。它每次将数组范围减半,直到找到目标或范围为空。
时间复杂度
- 最坏情况:O(logn)O(\log n)。
- 空间复杂度:O(1)O(1)。
Java 实现
public class BinarySearch {
public static int binarySearch(int[] arr, int target) {
int left = 0, right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid; // 找到目标
} else if (arr[mid] < target) {
left = mid + 1; // 向右查找
} else {
right = mid - 1; // 向左查找
}
}
return -1; // 未找到目标
}
public static void main(String[] args) {
int[] arr = {1, 3, 5, 7, 9, 11};
int target = 7;
int index = binarySearch(arr, target);
if (index != -1) {
System.out.println("目标值 " + target + " 在索引: " + index);
} else {
System.out.println("目标值 " + target + " 未找到");
}
}
}
输出
目标值 7 在索引: 3
总结
| 算法 | 特点 | 时间复杂度 | 空间复杂度 | 适用场景 |
|---|---|---|---|---|
| 快速排序 | 分治算法,递归实现,原地排序 | O(nlogn)O(n \log n) | O(logn)O(\log n) | 高效排序,适合大规模数据 |
| 归并排序 | 稳定排序,分治算法,适合链表 | O(nlogn)O(n \log n) | O(n)O(n) | 数据量大且稳定性有要求 |
| 二分查找 | 在有序数组中查找目标值,简单高效 | O(logn)O(\log n) | O(1)O(1) | 有序数据查找 |
这些算法各自适用于不同的场景,了解其实现细节和适用性能够帮助解决各种实际问题。
8. 线性规划与图算法
是用于求解最优化问题的重要方法,它们分别适用于不同场景:线性规划(Linear Programming) 是求解数学优化问题的通用方法,而 图算法(Graph Algorithms) 是解决网络优化问题(如最大流最小割)的强大工具。以下是详细介绍以及它们的实现思路。
8.1单纯形算法(Simplex Algorithm)
线性规划简介
线性规划是一种数学优化方法,目标是优化线性目标函数,同时满足一组线性约束条件。

单纯形算法简介
单纯形算法是求解线性规划问题的一种高效方法,通过从一个可行解的顶点出发,沿着多面体边界移动到目标函数值最大的顶点。
核心步骤:
- 将问题转化为标准形式,引入松弛变量。
- 从初始的基本可行解出发。
- 选择进入基变量(目标函数系数最小的变量)。
- 选择离开基变量(满足最小比值规则的变量)。
- 更新单纯形表,重复以上步骤,直到所有目标函数系数为非负值。
Java 实现算法
public class Simplex {
public static void main(String[] args) {
// 示例:最大化 z = 3x1 + 5x2
// 约束:
// x1 + x2 <= 4
// 2x1 + x2 <= 6
// x1, x2 >= 0
double[][] A = { { 1, 1 }, { 2, 1 } }; // 系数矩阵
double[] b = { 4, 6 }; // 约束右边的值
double[] c = { 3, 5 }; // 目标函数系数
double maxValue = simplex(A, b, c);
System.out.println("最优解的目标值: " + maxValue);
}
public static double simplex(double[][] A, double[] b, double[] c) {
int m = A.length; // 约束数量
int n = A[0].length; // 变量数量
// 初始化单纯形表
double[][] table = new double[m + 1][n + m + 1];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
table[i][j] = A[i][j];
}
table[i][n + i] = 1; // 松弛变量
table[i][n + m] = b[i];
}
for (int j = 0; j < n; j++) {
table[m][j] = -c[j];
}
// 单纯形算法主循环
while (true) {
// 检查是否已经达到最优解
int pivotCol = -1;
for (int j = 0; j < n + m; j++) {
if (table[m][j] < 0) {
pivotCol = j;
break;
}
}
if (pivotCol == -1) break; // 所有系数为非负,达到最优
// 找到离开基的行
int pivotRow = -1;
double minRatio = Double.MAX_VALUE;
for (int i = 0; i < m; i++) {
if (table[i][pivotCol] > 0) {
double ratio = table[i][n + m] / table[i][pivotCol];
if (ratio < minRatio) {
minRatio = ratio;
pivotRow = i;
}
}
}
if (pivotRow == -1) throw new RuntimeException("无界解");
// 更新单纯形表
double pivotValue = table[pivotRow][pivotCol];
for (int j = 0; j <= n + m; j++) {
table[pivotRow][j] /= pivotValue;
}
for (int i = 0; i <= m; i++) {
if (i != pivotRow) {
double factor = table[i][pivotCol];
for (int j = 0; j <= n + m; j++) {
table[i][j] -= factor * table[pivotRow][j];
}
}
}
}
return table[m][n + m]; // 返回目标函数的最大值
}
}
8.2最大流最小割算法(Max Flow Min Cut)
最大流问题简介
在一个流网络中,目标是计算从源点 sss 到汇点 ttt 的最大流量。
最小割问题简介
最小割问题是将网络分割为两个部分,使得源点和汇点分属不同部分,且割边的容量之和最小。
最大流与最小割定理
一个流网络的 最大流 等于从源到汇的 最小割 的总容量。
Edmonds-Karp 算法简介
Edmonds-Karp 算法是 Ford-Fulkerson 方法的改进版,使用 BFS 查找增广路径,从而避免无效路径重复搜索。
核心步骤:
- 初始化残余网络(Residual Graph)。
- 使用 BFS 查找增广路径。
- 沿增广路径更新残余网络。
- 重复步骤 2 和 3,直到不存在增广路径。
- 返回累积的最大流量。
Java 实现Edmonds-Karp 算法
import java.util.*;
public class MaxFlow {
public static int maxFlow(int[][] capacity, int source, int sink) {
int n = capacity.length;
int[][] residual = new int[n][n];
for (int i = 0; i < n; i++) {
System.arraycopy(capacity[i], 0, residual[i], 0, n);
}
int[] parent = new int[n]; // 用于存储增广路径
int maxFlow = 0;
// 不断寻找增广路径
while (bfs(residual, source, sink, parent)) {
int flow = Integer.MAX_VALUE;
// 计算路径上的最小残余容量
int v = sink;
while (v != source) {
int u = parent[v];
flow = Math.min(flow, residual[u][v]);
v = u;
}
// 更新残余网络
v = sink;
while (v != source) {
int u = parent[v];
residual[u][v] -= flow;
residual[v][u] += flow;
v = u;
}
maxFlow += flow;
}
return maxFlow;
}
private static boolean bfs(int[][] residual, int source, int sink, int[] parent) {
Arrays.fill(parent, -1);
parent[source] = source;
Queue<Integer> queue = new LinkedList<>();
queue.add(source);
while (!queue.isEmpty()) {
int u = queue.poll();
for (int v = 0; v < residual.length; v++) {
if (parent[v] == -1 && residual[u][v] > 0) {
parent[v] = u;
if (v == sink) return true;
queue.add(v);
}
}
}
return false;
}
public static void main(String[] args) {
int[][] capacity = {
{0, 16, 13, 0, 0, 0},
{0, 0, 10, 12, 0, 0},
{0, 4, 0, 0, 14, 0},
{0, 0, 9, 0, 0, 20},
{0, 0, 0, 7, 0, 4},
{0, 0, 0, 0, 0, 0}
};
System.out.println("最大流: " + maxFlow(capacity, 0, 5));
}
}
总结对比
| 算法 | 适用问题 | 时间复杂度 | 优点 |
|---|---|---|---|
| 单纯形算法 | 线性规划问题,最优资源分配 | 最坏 O(2n)O(2^n)O(2n) | 能求解通用线性规划问题 |
| Edmonds-Karp | 最大流问题,网络优化 | O(VE2)O(VE^2)O(VE2) | BFS 逐层查找增广路径,简单易实现 |
| 最大流最小割 | 网络分割问题、流量优化 | 与最大流相同 | 提供最大流等价的分割策略 |
两种算法解决的场景不同,但都在优化问题中占据重要地位。
9. 并查集(Union-Find)算法
是一种用于管理元素分组的数据结构。它支持以下两种主要操作:
- 查找(Find):确定某个元素属于哪个集合(即找到集合的代表元素)。
- 合并(Union):将两个集合合并为一个集合。
并查集常用于解决图中的连通性问题,例如:
- 判断两个节点是否在同一个连通分量中。
- 计算连通分量的数量。
- Kruskal 算法中,用于判断是否会形成环。
核心思想
-
通过数组表示集合:
- 每个元素指向一个父节点,最终形成一棵树。
- 根节点(代表元素)是集合的标识。
-
优化操作:
- 路径压缩(Path Compression):在查找操作中,将路径上的所有节点直接连接到根节点,减少树的高度。
- 按秩合并(Union by Rank):在合并操作中,总是将高度较小的树连接到高度较大的树,从而减少树的高度。
并查集的基本操作
1. 初始化
将每个元素初始化为一个独立的集合:
- 每个元素是自己的父节点。
2. 查找(Find)
递归找到集合的根节点,同时优化路径:
- 将路径上的所有节点直接指向根节点。
3. 合并(Union)
将两个集合合并:
- 比较两个集合的高度(或大小),将小树合并到大树下。
时间复杂度
- 单次操作的最坏时间复杂度:O(logn)O(\log n)。
- 使用路径压缩和按秩合并优化后:接近于 O(1)O(1)(即均摊时间复杂度为 O(α(n))O(\alpha(n)),其中 α(n)\alpha(n) 是反阿克曼函数,增长极慢)。
Java 实现
基础实现(路径压缩和按秩合并优化)
public class UnionFind {
private int[] parent; // 存储每个节点的父节点
private int[] rank; // 存储树的秩(近似高度)
// 初始化并查集
public UnionFind(int size) {
parent = new int[size];
rank = new int[size];
for (int i = 0; i < size; i++) {
parent[i] = i; // 每个节点的初始父节点是自己
rank[i] = 1; // 初始秩为 1
}
}
// 查找操作(带路径压缩)
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 路径压缩
}
return parent[x];
}
// 合并操作(按秩合并)
public void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX; // rootY 挂到 rootX 下
} else if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY; // rootX 挂到 rootY 下
} else {
parent[rootY] = rootX; // 任意选择一个为根
rank[rootX]++; // 增加树的高度
}
}
}
// 判断两个节点是否属于同一集合
public boolean isConnected(int x, int y) {
return find(x) == find(y);
}
public static void main(String[] args) {
UnionFind uf = new UnionFind(10); // 创建大小为 10 的并查集
// 合并一些节点
uf.union(1, 2);
uf.union(2, 3);
uf.union(4, 5);
// 检查连通性
System.out.println("1 和 3 是否连通: " + uf.isConnected(1, 3)); // true
System.out.println("1 和 4 是否连通: " + uf.isConnected(1, 4)); // false
// 查找操作示例
System.out.println("3 的根节点: " + uf.find(3)); // 1
System.out.println("5 的根节点: " + uf.find(5)); // 4
}
}
示例输入与输出
输入:
操作序列:
- 合并节点
1和2。 - 合并节点
2和3。 - 合并节点
4和5。 - 判断节点
1和3是否连通。 - 判断节点
1和4是否连通。 - 查找节点
3和5的根节点。
输出:
1 和 3 是否连通: true
1 和 4 是否连通: false
3 的根节点: 1
5 的根节点: 4
应用场景
1. 网络连通性
- 判断两个节点是否在同一个连通分量中。
- 计算连通分量的数量。
2. 最小生成树
- 在 Kruskal 算法中使用并查集判断是否会形成环。
3. 动态连通性问题
- 处理动态网络中节点之间的连通性问题,例如动态合并服务器集群。
4. 社交网络
- 判断用户是否属于同一个社交圈。
扩展问题:并查集在图算法中的应用
Kruskal 最小生成树
在 Kruskal 算法中,并查集用于判断两个顶点是否已经在同一个连通分量中。如果是,则跳过当前边;否则,加入边并合并两顶点所在的集合。
Kruskal 算法示例:
import java.util.*;
public class KruskalMST {
static class Edge implements Comparable<Edge> {
int src, dest, weight;
public Edge(int src, int dest, int weight) {
this.src = src;
this.dest = dest;
this.weight = weight;
}
@Override
public int compareTo(Edge other) {
return this.weight - other.weight;
}
}
public static int kruskalMST(int n, List<Edge> edges) {
Collections.sort(edges); // 按权值排序
UnionFind uf = new UnionFind(n); // 创建并查集
int mstWeight = 0;
for (Edge edge : edges) {
if (!uf.isConnected(edge.src, edge.dest)) {
uf.union(edge.src, edge.dest);
mstWeight += edge.weight;
}
}
return mstWeight;
}
public static void main(String[] args) {
int n = 4; // 节点数
List<Edge> edges = Arrays.asList(
new Edge(0, 1, 10),
new Edge(0, 2, 6),
new Edge(0, 3, 5),
new Edge(1, 3, 15),
new Edge(2, 3, 4)
);
System.out.println("最小生成树的总权值: " + kruskalMST(n, edges));
}
}
输出:
最小生成树的总权值: 19
总结

并查集是一种高效的数据结构,特别适合解决动态连通性和最小生成树问题。通过路径压缩和按秩合并的优化,其性能几乎可以视为常数时间复杂度。
10. 矩阵运算与数值算法
用于处理矩阵及数值计算:
- 矩阵乘法(Matrix Multiplication)
- 高斯消元法(Gaussian Elimination)
- 快速傅里叶变换(FFT)
矩阵运算和数值算法是科学计算和工程应用中的重要工具,广泛用于计算机图形学、信号处理、机器学习、物理模拟等领域。以下分别介绍 矩阵乘法、高斯消元法 和 快速傅里叶变换(FFT) 的原理及实现。
1. 矩阵乘法(Matrix Multiplication)

矩阵运算与数值算法
矩阵运算和数值算法是科学计算和工程应用中的重要工具,广泛用于计算机图形学、信号处理、机器学习、物理模拟等领域。以下分别介绍 矩阵乘法、高斯消元法 和 快速傅里叶变换(FFT) 的原理及实现。
1. 矩阵乘法(Matrix Multiplication)
算法简介
矩阵乘法是两个矩阵相乘的运算,计算规则是:
C[i][j]=∑k=1nA[i][k]⋅B[k][j]C[i][j] = \sum_{k=1}^n A[i][k] \cdot B[k][j]C[i][j]=k=1∑nA[i][k]⋅B[k][j]
其中:
- AAA 是 m×nm \times nm×n 的矩阵。
- BBB 是 n×pn \times pn×p 的矩阵。
- CCC 是 m×pm \times pm×p 的结果矩阵。
时间复杂度

矩阵运算与数值算法
矩阵运算和数值算法是科学计算和工程应用中的重要工具,广泛用于计算机图形学、信号处理、机器学习、物理模拟等领域。以下分别介绍 矩阵乘法、高斯消元法 和 快速傅里叶变换(FFT) 的原理及实现。
1. 矩阵乘法(Matrix Multiplication)
算法简介
矩阵乘法是两个矩阵相乘的运算,计算规则是:
C[i][j]=∑k=1nA[i][k]⋅B[k][j]C[i][j] = \sum_{k=1}^n A[i][k] \cdot B[k][j]C[i][j]=k=1∑nA[i][k]⋅B[k][j]
其中:
- AAA 是 m×nm \times nm×n 的矩阵。
- BBB 是 n×pn \times pn×p 的矩阵。
- CCC 是 m×pm \times pm×p 的结果矩阵。
时间复杂度
- 传统算法:O(m⋅n⋅p)O(m \cdot n \cdot p)O(m⋅n⋅p)
- Strassen算法(更高效的分治法):O(nlog27)≈O(n2.81)O(n^{\log_2 7}) \approx O(n^{2.81})O(nlog27)≈O(n2.81)
Java 实现
public class MatrixMultiplication {
public static void main(String[] args) {
int[][] A = {
{1, 2, 3},
{4, 5, 6}
};
int[][] B = {
{7, 8},
{9, 10},
{11, 12}
};
int[][] result = multiplyMatrices(A, B);
printMatrix(result);
}
public static int[][] multiplyMatrices(int[][] A, int[][] B) {
int m = A.length;
int n = A[0].length;
int p = B[0].length;
int[][] C = new int[m][p];
for (int i = 0; i < m; i++) {
for (int j = 0; j < p; j++) {
for (int k = 0; k < n; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
return C;
}
public static void printMatrix(int[][] matrix) {
for (int[] row : matrix) {
for (int value : row) {
System.out.print(value + " ");
}
System.out.println();
}
}
}
2. 高斯消元法(Gaussian Elimination)
算法简介
高斯消元法用于求解线性方程组,也可用于计算矩阵的逆或行列式。它通过消元操作将矩阵化为上三角形式,然后通过回代求解未知数。
步骤
- 消元:逐列对矩阵进行消元,使得对角线以下的元素为零。
- 回代:从最后一行开始逐步求解。
时间复杂度
- O(n3):适用于 n×n 矩阵。
Java 实现
public class GaussianElimination {
public static void main(String[] args) {
double[][] A = {
{2, 1, -1},
{-3, -1, 2},
{-2, 1, 2}
};
double[] b = {8, -11, -3};
double[] solution = gaussianElimination(A, b);
System.out.println("解向量:");
for (double x : solution) {
System.out.printf("%.2f ", x);
}
}
public static double[] gaussianElimination(double[][] A, double[] b) {
int n = A.length;
// 消元过程
for (int k = 0; k < n; k++) {
// 确保主对角线元素不为零
for (int i = k + 1; i < n; i++) {
double factor = A[i][k] / A[k][k];
for (int j = k; j < n; j++) {
A[i][j] -= factor * A[k][j];
}
b[i] -= factor * b[k];
}
}
// 回代求解
double[] x = new double[n];
for (int i = n - 1; i >= 0; i--) {
x[i] = b[i];
for (int j = i + 1; j < n; j++) {
x[i] -= A[i][j] * x[j];
}
x[i] /= A[i][i];
}
return x;
}
}
3 快速傅里叶变换(FFT)



JAVA实现
public class FFT {
public static void main(String[] args) {
int N = 8;
Complex[] x = new Complex[N];
for (int i = 0; i < N; i++) {
x[i] = new Complex(i, 0); // 输入信号
}
Complex[] result = fft(x);
System.out.println("FFT 结果:");
for (Complex c : result) {
System.out.println(c);
}
}
public static Complex[] fft(Complex[] x) {
int N = x.length;
if (N == 1) return new Complex[]{x[0]};
// 偶数和奇数部分递归计算
Complex[] even = new Complex[N / 2];
Complex[] odd = new Complex[N / 2];
for (int i = 0; i < N / 2; i++) {
even[i] = x[2 * i];
odd[i] = x[2 * i + 1];
}
Complex[] q = fft(even);
Complex[] r = fft(odd);
// 合并
Complex[] y = new Complex[N];
for (int k = 0; k < N / 2; k++) {
Complex wk = Complex.exp(new Complex(0, -2 * Math.PI * k / N)).multiply(r[k]);
y[k] = q[k].add(wk);
y[k + N / 2] = q[k].subtract(wk);
}
return y;
}
}
// 复数类
class Complex {
private final double re;
private final double im;
public Complex(double re, double im) {
this.re = re;
this.im = im;
}
public Complex add(Complex other) {
return new Complex(this.re + other.re, this.im + other.im);
}
public Complex subtract(Complex other) {
return new Complex(this.re - other.re, this.im - other.im);
}
public Complex multiply(Complex other) {
double real = this.re * other.re - this.im * other.im;
double imag = this.re * other.im + this.im * other.re;
return new Complex(real, imag);
}
public static Complex exp(Complex c) {
return new Complex(Math.cos(c.im), Math.sin(c.im));
}
@Override
public String toString() {
return String.format("%.4f + %.4fi", re, im);
}
}
总结
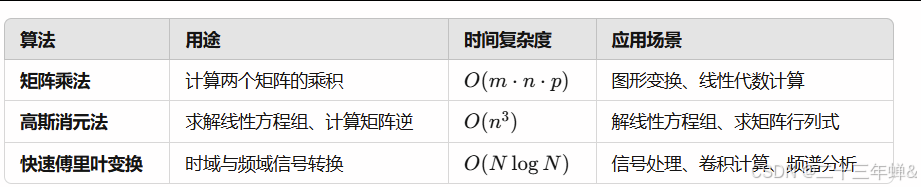
11. 搜索与优化算法
搜索与优化算法是用于在大规模搜索空间中找到最优解或近似最优解的技术。以下分别介绍 模拟退火(Simulated Annealing)、遗传算法(Genetic Algorithm) 和 粒子群算法(Particle Swarm Optimization)。
1. 模拟退火(Simulated Annealing, SA)
算法简介
模拟退火是一种启发式优化算法,灵感来源于物理中的退火过程。通过以一定概率接受“次优解”来跳出局部最优,逐步找到全局最优解。
核心思想:
- 随机生成一个初始解。
- 每次随机扰动解,生成新解。
- 如果新解更优,则接受新解;否则以一定概率接受(概率随“温度”降低逐渐变小)。
- 温度逐渐下降,算法收敛到最优解。
伪代码
- 初始化当前解 xxx,设置初始温度 TTT。
- 在当前温度 TTT 下:
- 生成新解 xnewx_{\text{new}}xnew。
- 计算目标值变化 ΔE\Delta EΔE。
- 如果 ΔE<0\Delta E < 0ΔE<0,接受新解。
- 否则,以概率 P=e−ΔE/TP = e^{-\Delta E / T}P=e−ΔE/T 接受新解。
- 降低温度 TTT。
- 重复以上步骤,直到温度趋近于零。
Java 实现
import java.util.Random;
public class SimulatedAnnealing {
public static void main(String[] args) {
double initialTemperature = 10000;
double coolingRate = 0.003;
double minTemperature = 0.1;
// 初始解
double currentSolution = generateRandomSolution();
double bestSolution = currentSolution;
Random random = new Random();
while (initialTemperature > minTemperature) {
// 生成一个新解
double newSolution = currentSolution + (random.nextDouble() - 0.5);
// 计算目标函数值
double currentEnergy = objectiveFunction(currentSolution);
double newEnergy = objectiveFunction(newSolution);
// 决定是否接受新解
if (acceptanceProbability(currentEnergy, newEnergy, initialTemperature) > random.nextDouble()) {
currentSolution = newSolution;
}
// 更新最佳解
if (objectiveFunction(currentSolution) < objectiveFunction(bestSolution)) {
bestSolution = currentSolution;
}
// 降低温度
initialTemperature *= 1 - coolingRate;
}
System.out.println("最佳解:" + bestSolution);
System.out.println("目标值:" + objectiveFunction(bestSolution));
}
// 目标函数(示例:求解 y = x^2 的最小值)
private static double objectiveFunction(double x) {
return x * x;
}
// 接受概率计算
private static double acceptanceProbability(double currentEnergy, double newEnergy, double temperature) {
if (newEnergy < currentEnergy) {
return 1.0;
}
return Math.exp((currentEnergy - newEnergy) / temperature);
}
// 生成随机解
private static double generateRandomSolution() {
Random random = new Random();
return random.nextDouble() * 10 - 5; // 范围 [-5, 5]
}
}
2. 遗传算法(Genetic Algorithm, GA)
算法简介
遗传算法是一种基于自然选择和遗传学的优化算法。它通过模拟生物进化过程(选择、交叉、变异)来找到问题的最优解。
核心步骤:
- 初始化:随机生成一组解(称为种群)。
- 选择:根据适应度函数选择优良解。
- 交叉:将两个解的部分信息进行组合,生成新解。
- 变异:对新解的部分信息随机改变,增加多样性。
- 迭代:重复以上步骤,直到满足终止条件。
Java 实现
以下示例以求解函数 f(x)=x2f(x) = x^2f(x)=x2 的最小值为例:
import java.util.Random;
public class GeneticAlgorithm {
public static void main(String[] args) {
int populationSize = 100;
int generations = 1000;
double mutationRate = 0.01;
double[] population = initializePopulation(populationSize);
Random random = new Random();
for (int generation = 0; generation < generations; generation++) {
// 评估适应度
double[] fitness = evaluateFitness(population);
// 选择父代
double[] parents = selectParents(population, fitness);
// 交叉和变异
for (int i = 0; i < populationSize; i++) {
if (random.nextDouble() < mutationRate) {
parents[i] = mutate(parents[i]);
}
}
// 更新种群
population = parents;
}
// 找到最佳解
double bestSolution = findBestSolution(population);
System.out.println("最佳解:" + bestSolution);
System.out.println("目标值:" + objectiveFunction(bestSolution));
}
// 初始化种群
private static double[] initializePopulation(int size) {
double[] population = new double[size];
Random random = new Random();
for (int i = 0; i < size; i++) {
population[i] = random.nextDouble() * 10 - 5; // 范围 [-5, 5]
}
return population;
}
// 目标函数(适应度)
private static double objectiveFunction(double x) {
return x * x;
}
// 计算适应度
private static double[] evaluateFitness(double[] population) {
double[] fitness = new double[population.length];
for (int i = 0; i < population.length; i++) {
fitness[i] = 1.0 / (1.0 + objectiveFunction(population[i])); // 适应度越大越好
}
return fitness;
}
// 选择父代
private static double[] selectParents(double[] population, double[] fitness) {
double[] parents = new double[population.length];
Random random = new Random();
for (int i = 0; i < parents.length; i++) {
int index = random.nextInt(population.length);
if (random.nextDouble() < fitness[index]) {
parents[i] = population[index];
}
}
return parents;
}
// 变异操作
private static double mutate(double value) {
Random random = new Random();
return value + (random.nextDouble() - 0.5);
}
// 找到最佳解
private static double findBestSolution(double[] population) {
double best = population[0];
for (double value : population) {
if (objectiveFunction(value) < objectiveFunction(best)) {
best = value;
}
}
return best;
}
}
3.粒子群算法(Particle Swarm Optimization, PSO)
算法简介
粒子群算法模拟了鸟群觅食行为,通过一组粒子在解空间中搜索最优解。每个粒子根据自己的历史经验和群体经验调整位置。
核心步骤:
- 初始化一组粒子的初始位置和速度。
- 每个粒子根据目标函数计算适应度。
- 更新粒子的速度和位置,使其靠近最佳解。
- 重复迭代,直到收敛。
Java 实现
import java.util.Random;
public class ParticleSwarmOptimization {
public static void main(String[] args) {
int numParticles = 30;
int iterations = 1000;
double w = 0.5; // 惯性权重
double c1 = 1.5; // 自我认知因子
double c2 = 1.5; // 群体认知因子
double[] positions = new double[numParticles];
double[] velocities = new double[numParticles];
double[] personalBest = new double[numParticles];
double globalBest = Double.MAX_VALUE;
Random random = new Random();
// 初始化粒子
for (int i = 0; i < numParticles; i++) {
positions[i] = random.nextDouble() * 10 - 5; // 范围 [-5, 5]
personalBest[i] = positions[i];
if (objectiveFunction(positions[i]) < objectiveFunction(globalBest)) {
globalBest = positions[i];
}
}
// 粒子群优化
for (int iter = 0; iter < iterations; iter++) {
for (int i = 0; i < numParticles; i++) {
// 更新速度
velocities[i] = w * velocities[i]
+ c1 * random.nextDouble() * (personalBest[i] - positions[i])
+ c2 * random.nextDouble() * (globalBest - positions[i]);
// 更新位置
positions[i] += velocities[i];
// 更新个人最佳
if (objectiveFunction(positions[i]) < objectiveFunction(personalBest[i])) {
personalBest[i] = positions[i];
}
// 更新全局最佳
if (objectiveFunction(personalBest[i]) < objectiveFunction(globalBest)) {
globalBest = personalBest[i];
}
}
}
System.out.println("最佳解:" + globalBest);
System.out.println("目标值:" + objectiveFunction(globalBest));
}
private static double objectiveFunction(double x) {
return x * x;
}
}
总结
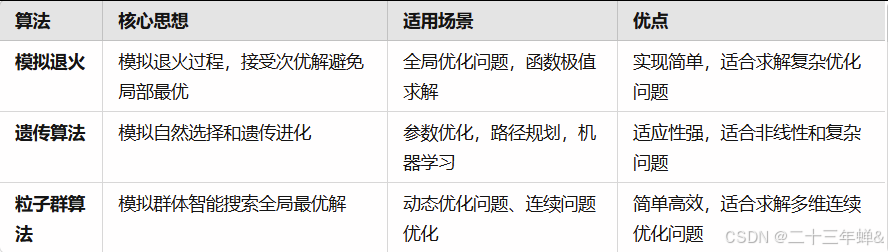
12. 加密与安全算法
加密和安全算法是网络安全和信息保护的核心技术,广泛用于数据传输、存储、认证等场景。以下介绍 对称加密算法(如 AES)、非对称加密算法(如 RSA) 和 哈希算法(如 SHA) 的核心原理和 Java 实现。
1. 对称加密算法(如 AES)
算法简介
- 对称加密是指加密和解密使用相同的密钥。
- AES (Advanced Encryption Standard) 是一种广泛应用的分组对称加密算法:
- 支持 128、192、256 位密钥。
- 将明文分为 128 位的块进行加密。
适用场景
- 文件加密
- 数据库加密
- 数据传输中的加密保护
Java 实现
以下代码示例使用 AES 进行加密和解密:
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.SecretKey;
import javax.crypto.spec.SecretKeySpec;
import java.util.Base64;
public class AESExample {
public static void main(String[] args) throws Exception {
String plaintext = "Hello, AES!";
// 生成密钥
KeyGenerator keyGen = KeyGenerator.getInstance("AES");
keyGen.init(128); // AES 支持 128, 192, 256 位密钥
SecretKey secretKey = keyGen.generateKey();
// 加密
String encryptedText = encrypt(plaintext, secretKey);
System.out.println("加密后的文本: " + encryptedText);
// 解密
String decryptedText = decrypt(encryptedText, secretKey);
System.out.println("解密后的文本: " + decryptedText);
}
public static String encrypt(String plaintext, SecretKey key) throws Exception {
Cipher cipher = Cipher.getInstance("AES");
cipher.init(Cipher.ENCRYPT_MODE, key);
byte[] encryptedBytes = cipher.doFinal(plaintext.getBytes());
return Base64.getEncoder().encodeToString(encryptedBytes);
}
public static String decrypt(String encryptedText, SecretKey key) throws Exception {
Cipher cipher = Cipher.getInstance("AES");
cipher.init(Cipher.DECRYPT_MODE, key);
byte[] decodedBytes = Base64.getDecoder().decode(encryptedText);
byte[] decryptedBytes = cipher.doFinal(decodedBytes);
return new String(decryptedBytes);
}
}
2. 非对称加密算法(如 RSA)
算法简介
- 非对称加密使用一对密钥:公钥用于加密,私钥用于解密。
- RSA 是一种常见的非对称加密算法:
- 基于大整数因式分解的困难性。
- 通常用于加密短消息或加密密钥。
适用场景
- 安全密钥交换
- 数字签名
- 数据加密和认证
Java 实现
以下代码使用 RSA 加密和解密:
import javax.crypto.Cipher;
import java.security.*;
import java.util.Base64;
public class RSAExample {
public static void main(String[] args) throws Exception {
String plaintext = "Hello, RSA!";
// 生成密钥对
KeyPairGenerator keyPairGen = KeyPairGenerator.getInstance("RSA");
keyPairGen.initialize(2048); // RSA 支持 1024, 2048, 4096 位密钥
KeyPair keyPair = keyPairGen.generateKeyPair();
PublicKey publicKey = keyPair.getPublic();
PrivateKey privateKey = keyPair.getPrivate();
// 加密
String encryptedText = encrypt(plaintext, publicKey);
System.out.println("加密后的文本: " + encryptedText);
// 解密
String decryptedText = decrypt(encryptedText, privateKey);
System.out.println("解密后的文本: " + decryptedText);
}
public static String encrypt(String plaintext, PublicKey publicKey) throws Exception {
Cipher cipher = Cipher.getInstance("RSA");
cipher.init(Cipher.ENCRYPT_MODE, publicKey);
byte[] encryptedBytes = cipher.doFinal(plaintext.getBytes());
return Base64.getEncoder().encodeToString(encryptedBytes);
}
public static String decrypt(String encryptedText, PrivateKey privateKey) throws Exception {
Cipher cipher = Cipher.getInstance("RSA");
cipher.init(Cipher.DECRYPT_MODE, privateKey);
byte[] decodedBytes = Base64.getDecoder().decode(encryptedText);
byte[] decryptedBytes = cipher.doFinal(decodedBytes);
return new String(decryptedBytes);
}
}
3. 哈希算法(如 SHA)
算法简介
- 哈希算法是一种单向加密算法,将输入数据映射为固定长度的哈希值。
- SHA (Secure Hash Algorithm) 是一种常见的哈希算法:
- SHA-1 生成 160 位哈希值(已不安全)。
- SHA-256、SHA-512 是常用的安全哈希算法。
适用场景
- 密码存储
- 数据完整性验证
- 数字签名
Java 实现
以下代码使用 SHA-256 计算字符串的哈希值:
import java.security.MessageDigest;
import java.util.Base64;
public class SHAExample {
public static void main(String[] args) throws Exception {
String plaintext = "Hello, SHA!";
String hash = hashSHA256(plaintext);
System.out.println("原始文本: " + plaintext);
System.out.println("SHA-256 哈希值: " + hash);
}
public static String hashSHA256(String plaintext) throws Exception {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte[] hashBytes = digest.digest(plaintext.getBytes());
return Base64.getEncoder().encodeToString(hashBytes);
}
}
总结
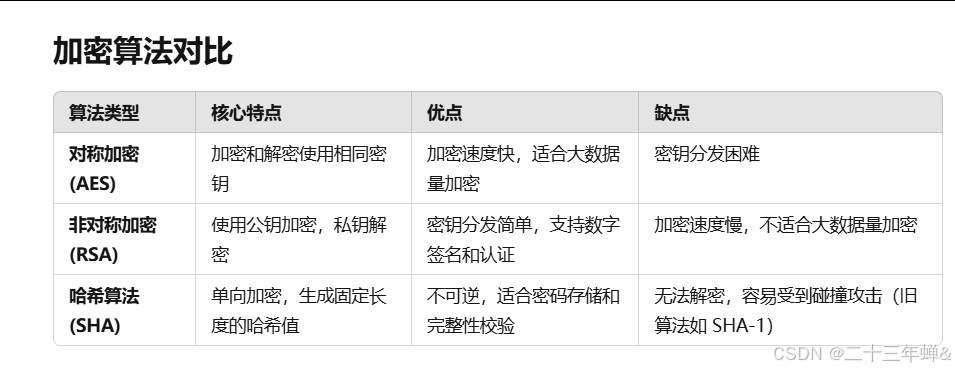
实际应用场景
-
对称加密 (AES):
- 数据库文件加密
- SSL/TLS 数据传输加密
-
非对称加密 (RSA):
- SSL/TLS 的密钥交换
- 数字证书和数字签名
-
哈希算法 (SHA):
- 密码的存储与验证(如
bcrypt和SHA-256) - 数据完整性校验(如文件的 SHA-256 校验值)
- 密码的存储与验证(如