所谓爬虫,就是将网页当成一个文档,在某段代码上,逐行读取,符合需求的取出来,爬完之后可以顺着连接再次发送请求
一:创建项目
选择磁盘下创建文件,此处我命名创建工作空间名位D:\PythonWorkspace
在当前路径打开控制台 输入命令创建项目
scrapy startproject xiao
进入spiders文件夹,创建执行类,该类的parse方法就是主要访问的方法
scrapy genspider 文件名 要爬取的网址
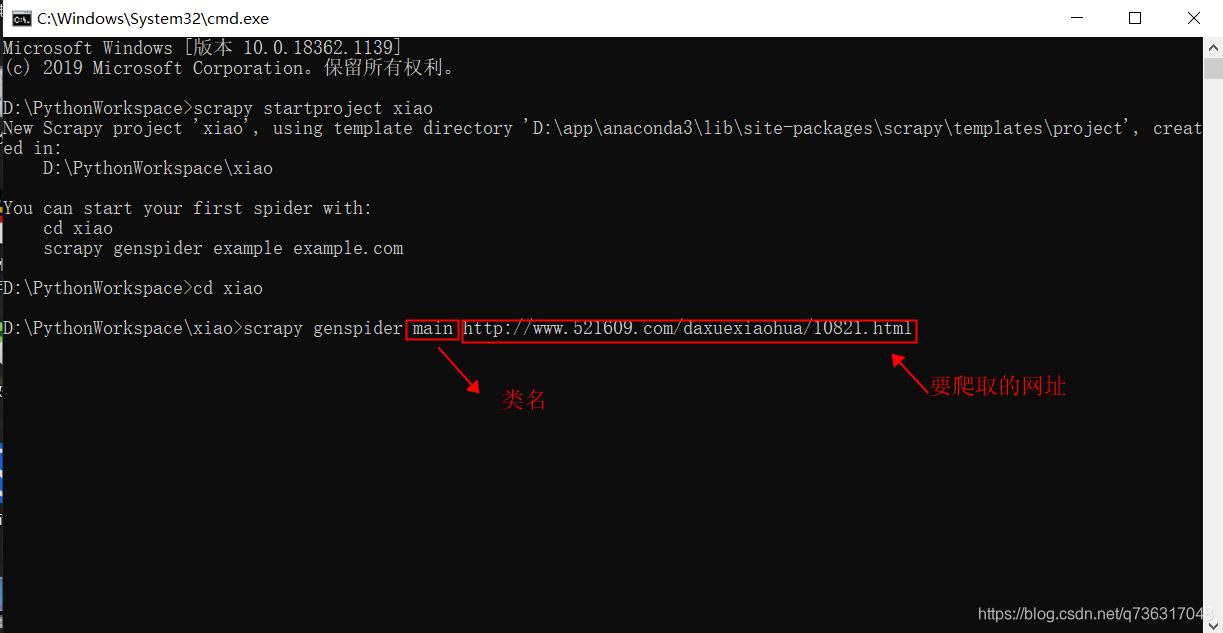
二:打开项目
使用PyCharm工具打开
下载安装及破解不再做演示
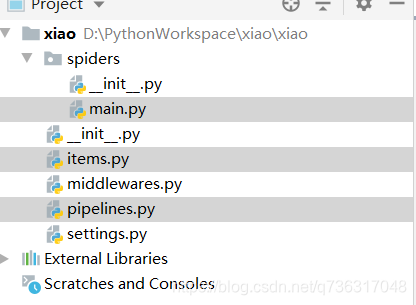
代码具体实现在这三个文件里
三:编写程序
这里爬取校花网: http://www.521609.com/daxuexiaohua/10821.html 绝对安全!
1.创建实体类
在items.py下。用于暂时存储相关数据,用于传输
#实体类
class XiaoItem(scrapy.Item):
# define the f