系统简介
高血压疾病是一种常见可防可控的慢性心脑血管疾病,在我国,每年因高血压导致死亡的案例也非常多见。它的临床并发症主要包括有急性脑卒中、心力衰竭及慢性的肾脏病等等。因此,建立合理有效的疾病诊断模型和探究引发高血压的致病因素对个人和医疗机构就显得尤为重要。建立合适的Logistic模型,对高血压的影响危险因素的估计和预测模型对数据的准确性进行了分析,采用传统的回归分析法对其模型进行了变量的筛选;对模型参数的分析和估计采用极大似然的方法,得到了患有高血压危险人群死亡概率的估计和logistic回归方程,并对其进行了预测。进而有效的引导和警醒了人们对于高血压的正确认知,提出了合理化的建议,有效的预防和控制了高血压的发生和患病率。
关键词 Logistic回归 高血压 患病率 影响因素
引 言
高血压是一种可防可控的慢性疾病,但每年因患有高血压而丧失生命的人也数不胜数,脑卒中、慢性肾脏病及心力衰竭是其主要并发症,它是引发慢性心脑血管系统疾病最主要的病因。由于高血压的死亡率较高,所以探究引发高血压致病的重要因素以及如何建立合理有效的高血压疾病诊断的模型对个人及相关的医疗机构就显得尤为重要。本研究论文在系统介绍了Logistic高血压回归疾病诊断模型的原理和其方法的基础上,探索了Logistic高血压回归疾病诊断模型在系统分析个人高血压的发生致病性和危险因素上的重要性和应用。本论文利用统计软件,分析某地区个人高血压的患病数据,找出了造成高血压患病率的重要危险因素,从而为研究者提出了合理化的建议,有效的预防和控制了高血压的发生和患病率。
本文通过建立Logistic回归模型,对导致引发高血压因素进行分析采用极大似然估计法得到预测患有高血压的回归方程。
本论文通过体重指数,饮食习惯,是否有高血压家族史,是否吸烟,是否喝酒,是否熬夜,睡眠状况和心率等几个方面来建立二元Logistic线性回归模型[1],分析这几个方面是否对高血压有显著的影响,得出主要因素,对人们的生活习惯给出合理化建议,降低高血压患病率。
Logistic线性回归模型是一种广义的线性回归模型。这种回归模型被科学家和人们常用在对疾病的早期诊断、经济上的风险预测、数据和信息的挖掘等医学研究领域。举个例子来说,医疗专家们提前研究了可能影响疾病发生的危险因素,并根据影响因素预测疾病发生的概率等。对于Logistic的回归理论和模型回归模型的诊断研究主要以下几方面:(1)模型诊断研究,周菲等(2014)先后提出了关于Logistic的回归理论和模型多重共线性的诊断及在临床医学研究中的实际应用;2017年,曾婕等(2017)对Logistic回归模型的统计诊断做了综述;(2)分析方法研究,何秀丽等(2004)对Logistic回归中的加权最小二乘估计做了研究;陈芝(2016)模拟退火结合Logistic算法在分类中的应用;刘明(2012)提出了Logistic模型预测的新思路。(3)模型应用方面,沈斌峰(2009)用回归结合logistic多元类型线性回归模型综合分析了体质健康指数BMI和回归年龄对是否患心血病的直接影响;王平(2009)用Logistic回归分析了篮球比赛每节比分对胜负的影响,李涛等(2009)对多元线性回归与Logistic回归分析的正确应用作了分析。宋佳莹等(2018)研究了Logistic回归在二分类型任务定价类型中的应用。
论文安排:
(1)知识复习。复习二项分布知识和二项分布应用,掌握一般线性回归原理与方法,学会统计分析的一般手段。
(2)文献研究。查阅资料,了解关于模型Logistic应用和回归的实际应用,掌握了Logistic应用和回归的基本研究方法和其原理,学会了如何对模型和数据进行了检验和分析;通过查阅高血压医学相关文献,了解关于致病危险因素导致原发性高血压的,包括体重指数,饮食习惯,是否有高血压家族史,是否吸烟,是否喝酒,是否熬夜,睡眠状况和心率等。
(3)统计调查。学会数据收集与整理。
(4)统计分析。学习统计软件使用,掌握Logistic回归方法,能对数据进行分析,能对模型给解释。
1.Logistic线性回归模型
1.1Logistic回归概念
Logistic线性回归分析模型它是一种较为广义的连续线性事件的回归分析模型[2]。它的一个实质原理就是将具有发生某一事件概率的因变量除以没有某一事件发生的概率。计算出来的结果,再对结果取对数,通过采取这一概率对数变换,改变了原来回归模型的取值区间之间的矛盾,也从根本上改变了因变量自变量之间的曲线关系。通过采用取对数的方法的往往可以使得变量之间的关系呈现出线性的关系。Logistic线性回归分析模型在实际意义上也是一种概率模型,它指的是某一种连续事物以其是否具有发生的事件概率为因变量,以某一事件影响的因素为一个自变量建立线性回归模型,分析的问题是某一个连续事件发生的概率与某一事件自量之间的线性关系问题。Logistic线性回归常被专家和研究人员用于经济的预测,数据的挖掘,疾病的自动诊断等。
本文Logistic回归分析主要处理的问题是单一变量与多变量之间的关系问题。这些变量和变量之间有两种常见的关系:一种是变量之间的确定性关系,这些变量之间的某些关系是完全确定的,称为变量之间的确定性关系[3],可以用函数来表示,给定后,的值就对应的确定下来了。而另外一类称为变量之间的相关关系:这些变量间虽然有一定的关系,但不能用函数间的关系式来表示,医学上就常常都会遇到这种密切相关的关系,利用这种关系,给出一些具有经验性的公式和方法来进行确定,比如一个人到底是否曾经患病等等,本文主要研究的是Logistic回归形式分析,研究的就是这种变量之间密切相关的关系。虽然所研究的这些变量间的这种相关关系不能用大家都熟悉而又完全确定的函数关系式表示出来,但它们在某种情况下有一定的关系,可以通过这种关系,用表达式表示出来,本文回归分析的主要研究任务就是寻找这种关系来建立表达式然后建立合适的模型,对其进行分析与预测[4]。
二元Logistic回归的分类与特征如表1所示[5]P128
表 1 二元Logistic回归的分类与特征
二元Logistic回归主要分为:
1.二项logistic回归,此回归的因变量为二分类的logistic回归,
2.多项式logistic回归,此回归的因变量为无序多分类得logistic回归,
3.累积logistic回归或序次logistic回归,此回归存在具有有序多类因变量的logistic回归。 例如,疾病的严重程度为高,中,低等。
1.2适用条件
Logistic回归模型的适用条件如表2所示
表 2 Logistic回归模型的适用条件
Logistic回归模型的适用条件
(1) 回归模型的因变量为二分类的分类变量或者是某一事件的发生概率,并且这些变量是数值型变量。重复计数现象指标不适用于Logistic回归。
(2) 回归模型的残差和因变量都要服从二项分布。二项分布对应的是分类变量,不是正态分布,进而不能用用最小二乘法,而是用最大似然法来解决方程的估计和检验问题。
(3)回归模型的自变量和Logistic概率是呈线性关系。
(4)各观测对象间相互独立[6]。
Logistic回归模型的原理: Logistic回归中如果直接采用线性的回归模型,给定确定是函数关系式,那么将会带来下面两个问题,一是使得变量之间产生普遍的非直线关系,二是使得方程的左右二边取值范围不同。Logistic回归方程中的因变量为概率,它的取值范围为,但是方程右边的取值范围是或者。这就是为什么引入Logistic回归。[7]
1.3Logistic分布函数
(1)
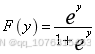
的取值范围在,函数值在之间取值,且函数图像是单调递增的 型曲线[8]。这种函数特征可应用于临床医学和流行病学描述其发生概率与影响因素之间的关系中。函数图像如下图:
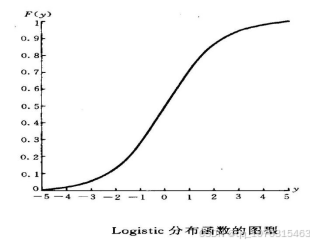
图 1 Logistic分布函数图
1.4Logistic的模型
对元线性回归模型[9]
(2)
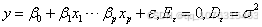
其中未知参数称为偏回归系数,显然有
(3)

式(3)称为 对的回归函数。
当因变量是一个二元变量,只取0与1两个值时,
是因变量,对其做Logistic变换,得
(4)

称为Logistic线性回归。
极大似然估计就是选取的估计值使得式(4)达到极大。由此得到Logistic回归模型为:
(5)

1.5回归系数的假设检验
对于回归系数的假设检验,就是检验总体回归系数是否为零。[10]P326检验方法有:
似然比检验
(1)首先检验引入的变量对模型是否具有贡献;
(2)其次对模型的回归系数进行整体的检验。
(3)似然比检验
(6)

为方程中个自变量的对数似然函数值;为增加一个自变量后的对数似然函数值。服从自由度为1的分布。若,则可以认为在检验水准下有统计学意义,可以引入方程,否则不能引入方程。
Wald检验
(7)
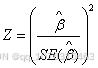
计分检验
通过比较似然比检验、Wald检验和计分检验,可以看出似然比检验是最可靠的。它是基于整个模型的拟合。而Wald检验考虑了所有因素的综合影响,当存在共线因素时,结果不可靠,因此Wald检验最差。计分检验结果与似然比检验结果基本一致[11]。
1.6Logistic回归模型的拟合优度检验
Logistic回归模型预测的理论频数分布是否符合实际的理论频数分布的检验常用方法如下[12]P224:
表 3 预测与实际的理论频数分布检验方法
常用方法如下:
(1)偏差检验 对样本含量的理论频数要求比较严格
(2)Pearson检验 对样本含量的理论频数要求比较严格
(3)Hosmer-Lemeshow检验 用于二分类因变量的Logistic回归分析,当样本容量大,自变量数目多且有连续型变量引入模型时,检验效果好[13]。
模型拟合优度检验:设实际频数分布和理论频数分布相符合,即模型的拟合优度较好。
2.基于Logistic回归的高血压患病模型
2.1数据的分析和处理
本文收集了某一地区是否患有高血压的数据。通过收集100个人是否患有高血压,从他们的性别,年龄,体重指数,饮食习惯,是否有高血压的家族史,是否吸烟,是否喝酒,是否熬夜,是否熬夜,睡眠状况,心率这几个方面来预测患高血压的影响因素[14]。
部分数据录入如图2所示:
图 2 部分数据图
详细数据见附录
2.2 Logistic高血压预测模型
2.2.1变量的筛选
表 4案例处理表
案例处理汇总
未加权的案例a N 百分比
选定案例 包括在分析中 100 100.0
缺失案例 0 .0
总计 100 100.0
未选定的案例 0 .0
总计 100 100.0
a. 如果权重有效,请参见分类表以获得案例总数。
本次案例选取了100个案例,并且100个案例都有效。
对原始数据的观测如下表:
表 5 分类表
分类表a,b
已观测 已预测
是否高血压 百分比校正
否 是
步骤 0 是否高血压 否 0 42 .0
是 0 58 100.0
总计百分比 58.0
a. 模型中包括常量。
b. 切割值为 .500
由上表的真实数据预测可知:本次研究的100个人中患有高血压的实际人数为58人,所占比例为58%
运用SPSS软件对数据进行初步筛选后得出的变量如表6。
表 6 变量选择结果
分类变量编码
频率 参数编码
(1) (2)
睡眠状况 很少 6 1.000 .000
偏少 13 .000 1.000
正常 81 .000 .000
饮食习惯 偏咸 53 1.000
清淡 47 .000
高血压家族史 无 42 1.000
有 58 .000
是否吸烟 否 68 1.000
是 32 .000
是否喝酒 否 35 1.000
是 65 .000
是否熬夜 否 40 1.000
是 60 .000
性别 男 50 1.000
女 50 .000
因变量:是否患高血压
通过表6,可以看出,筛选出的变量有:睡眠状况,饮食习惯,高血压家族遗传史,是否吸烟,是否喝酒,是否熬夜,性别
2.2.2模型的建立
以“是否患有高血压”作为因变量表示“患有高血压”,表示“没有患有高血压”,以睡眠状况,饮食习惯,高血压家族遗传史,是否吸烟,是否喝酒,是否熬夜,性别为自变量[15],通过SPSS软件对Logistic线性回归模型的参数进行极大似然估计,结果如表7所示:
表 7 Logistic的参数估计结果方程中的变量
Logistic线性回归模型的参数估计结果方程中的变量
回归系数B 标准误差S.E, Wals 自由度df P值Sig. Exp (B) EXP(B) 的 95% C.I.
下限 上限
步骤 1a 性别(1) -.753 .492 2.335 1 .126 .471 .179 1.237
年龄 .037 .046 .655 1 .418 1.038 .949 1.135
体重指数 -.051 .098 .273 1 .601 .950 .784 1.151
饮食习惯(1) 1.120 .460 5.928 1 .015 3.064 1.244 7.544
高血压家族史(1) -.570 .498 1.309 1 .253 .565 .213 1.502
是否吸烟(1) .004 .587 .000 1 .994 1.004 .318 3.174
是否喝酒(1) .015 .516 .001 1 .978 1.015 .369 2.790
是否熬夜(1) .622 .520 1.430 1 .232 1.863 .672 5.167
睡眠状况 1.099 2 .577
睡眠状况(1) -.488 1.050 .216 1 .642 .614 .078 4.805
睡眠状况(2) -.758 .746 1.032 1 .310 .469 .109 2.022
心率 -.036 .049 .545 1 .460 .965 .876 1.061
常量 2.739 4.263 .413 1 .521 15.467
a. 在步骤 1 中输入的变量: 性别, 年龄, 体重指数, 饮食习惯, 高血压家族史, 是否吸烟, 是否喝酒, 是否熬夜, 睡眠状况, 心率.
可以得到具体的线性回归模型:
(8)
通过分析上表,建立的二元Logistic线性回归模型,从表中可以看出饮食习惯的,它的值小于0.05,所以饮食习惯较为显著,其他几个影响因素的值都大于0.05,说明他们的影响相对与饮食习惯来说,没有饮食习惯的影响大。从而可以得出饮食习惯对高血压的患病有着重要的影响,表中的饮食习惯(1)表示饮食习惯偏咸,所以进而可以看出饮食习惯偏咸的人越容易患高血压。
2.2.3模型的预测
表 8 分类表
分类表a
已观测 已预测
是否高血压 百分比校正
否 是
步骤 1 是否高血压 否 23 19 54.8
是 10 48 82.8
总计百分比 71.0
a. 切割值为 .500
由上表可以看出通过二元Logistic回归方程进行预测的准确度达到71%,所以很好的证明了饮食习惯是影响高血压患病的重要因素。
2.2.4模型的检验
表 9 霍斯默—莱梅肖检验表
= Hosmer 和 Lemeshow 检验 =
步骤 卡方 df Sig.
1 5.898 8 .659
由上表的霍斯默—莱梅肖检验表得出,的值大于0.05,接受零假设,可以看出本次建立的二元Logistic回归模型能够与原始数据的拟合度状况较好,说明本次的回归方程能比较好的探究高血压的患病影响因素。
结 论
本文通过Logistic线性回归模型对所收集的某一地区可能对高血压患病有影响的几种因素的数据进行建模,采用逐步分析法对变量进行筛选,从而使效果达到很好的显著性,通过这次对模型的研究和分析,饮食对高血压的患病的影响因素尤为显著,所以线性回归模型的建立和拟合效果较好,所建立的模型对高血压的患病可能有很好的预测。通过这次的论文课题的,和对某一地区logistic线性回归数据和模型的研究和分析,我们虽然很明显的可以看出了饮食习惯对于高血压的患病可能有较为显著的直接影响,但同样的也可以直接看出性别,年龄,体重指数,是否有高血压的家族史,是否吸烟,是否喝酒,是否熬夜,睡眠状况,心率等对高血压的患病可能也有部分的直接影响,所以大家都应该得到充分的重视,尤其是我们要特别注意良好的饮食习惯,养成良好的饮食习惯对我们的身体健康至关重要。
建议:俗话说的好,好的身体是革命的本钱。大家不要因为知道高血压仅仅是一种慢性的心血管疾病,就那么不在乎。它的严重性和危害也不亚于任何的一种慢性疾病,在这里我们还是要强烈建议大家,从今天开始注意建立起自己的卫生和饮食习惯,不可以吃太咸的刺激性食品,改善自己的饮食口味,爱护好自己的身体,拥有更好的未来。
致 谢
时光荏苒,一转眼大学四年的时间即将过去,随着本次毕业论文设计的完成,我们也即将结束我们大学的生活。在这里我要感谢我的所有任课老师,是他们对我们的耐心教育,才让我的大学生活更加充实。当然,在这里我要特别的感谢我的毕业论文导师费绍金老师,他对我的毕业论文设计帮助非常的大,非常耐心的对我的毕业论文进行修改,提出了很多宝贵的建议,指出了我论文中的不足,他用严谨的态度和敬业的精神对待每一位学生,这种精神以后无论我走到哪,我都不会忘记。
感谢16信科1班的所有朝夕相伴的同学,四年的陪伴,也无法用言语表达,有一起奋斗的艰苦,也有一起娱乐的笑语,在这里我要祝大家都有幸福美好的未来。
在本次论文过程中,感谢老师们给了我们很多的选题,让我有了选择的方向。老师从选题指导、论文框架到细节修改,都给予了细致的指导,给出了很多宝贵的意见与建议,让我得益于此,然后才好继续进行论文的主题内容。没有老师帮助,我的论文也难以完成,所以我要再次感谢我的指导老师。
附 录
具体的原始数据如下:
性别 年龄 体重指数 饮食习惯 高血压家族史 是否吸烟 是否喝酒 是否熬夜 睡眠状况 心率 是否高血压
男 28 22.50 清淡 有 是 否 是 偏少 68 否
女 27 20.70 清淡 有 否 否 否 正常 71 是
男 30 24.20 清淡 有 是 否 是 正常 70 否
女 32 22.00 偏咸 无 否 是 是 正常 66 是
女 40 20.50 偏咸 无 否 否 否 正常 65 否
女 25 28.00 清淡 有 否 是 否 正常 68 是
男 33 28.00 清淡 无 否 是 是 正常 65 是
男 29 23.40 偏咸 有 否 是 是 正常 75 否
男 37 20.00 偏咸 无 否 否 是 正常 70 是
女 24 19.90 清淡 无 是 是 是 很少 67 是
男 31 21.40 偏咸 有 否 是 是 正常 67 否
女 28 19.60 清淡 有 否 是 否 正常 69 是
男 25 25.20 偏咸 无 否 是 否 正常 69 是
女 32 23.70 偏咸 有 是 否 是 正常 72 否
男 29 22.40 清淡 有 否 是 是 正常 69 否
男 35 23.80 清淡 有 否 是 否 正常 73 是
女 34 21.70 偏咸 无 是 否 否 正常 65 是
男 28 19.50 清淡 有 否 是 否 正常 80 是
女 36 18.30 偏咸 有 否 是 是 正常 68 是
男 35 22.10 偏咸 有 是 否 是 很少 70 是
男 32 25.80 偏咸 有 是 是 否 正常 65 是
女 29 27.30 清淡 有 否 是 是 偏少 65 否
女 30 20.50 清淡 无 否 否 是 正常 88 是
男 38 24.30 清淡 有 是 是 否 正常 70 是
女 28 19.50 偏咸 无 否 是 是 偏少 73 否
女 40 17.80 清淡 有 是 否 是 偏少 67 否
男 36 23.80 偏咸 有 否 否 否 正常 72 是
男 28 21.60 偏咸 有 是 否 是 正常 71 是
男 36 19.50 清淡 无 否 是 是 正常 65 否
女 23 19.60 偏咸 无 否 否 否 正常 66 是
男 22 22.10 偏咸 有 否 是 否 正常 67 否
女 21 25.80 清淡 无 否 是 是 正常 66 否
男 30 22.50 偏咸 有 否 是 是 正常 76 是
女 34 24.60 偏咸 无 否 否 是 正常 73 是
女 41 20.10 偏咸 无 是 是 是 正常 66 是
男 28 19.60 偏咸 无 否 是 是 正常 65 是
男 27 22.50 清淡 有 否 是 否 正常 70 是
女 33 21.50 清淡 无 否 是 否 正常 70 否
男 34 24.20 清淡 无 是 是 是 正常 71 否
女 37 20.10 偏咸 有 否 是 是 正常 68 是
女 28 20.50 偏咸 有 否 是 否 正常 72 是
男 29 18.70 偏咸 无 是 否 否 正常 66 否
男 26 19.80 清淡 有 否 是 否 正常 79 是
男 35 21.30 清淡 有 否 是 是 正常 69 是
男 26 22.60 清淡 有 是 否 是 很少 71 否
女 38 19.80 清淡 有 是 是 否 正常 64 否
女 26 22.60 偏咸 有 否 是 是 偏少 67 是
男 41 23.80 偏咸 无 否 否 是 正常 87 否
男 43 21.70 偏咸 有 是 是 否 正常 71 否
女 35 20.50 清淡 无 否 是 是 偏少 70 否
女 34 18.30 偏咸 有 是 否 是 偏少 65 是
男 26 22.10 清淡 有 否 否 否 正常 73 否
女 42 25.80 偏咸 有 是 否 是 正常 69 是
男 29 18.70 清淡 无 否 是 是 正常 65 否
女 32 17.60 清淡 无 否 否 否 正常 63 是
男 31 22.60 偏咸 有 否 否 否 正常 69 是
女 26 23.40 清淡 无 否 是 是 偏少 68 否
女 28 22.50 偏咸 有 否 是 是 正常 74 否
女 38 20.70 清淡 无 否 否 是 正常 72 否
女 35 19.60 偏咸 无 是 是 是 正常 66 是
男 25 22.00 偏咸 无 否 是 是 正常 70 否
男 42 21.60 清淡 有 否 是 否 正常 65 是
女 28 18.70 清淡 无 否 是 否 正常 70 否
女 31 22.60 清淡 无 是 是 是 正常 72 是
男 27 24.80 清淡 有 否 是 是 正常 69 否
男 33 22.30 偏咸 有 否 是 否 正常 72 是
女 29 19.50 清淡 无 是 否 否 正常 65 是
女 37 23.80 偏咸 有 否 是 否 正常 79 是
男 24 21.70 清淡 有 否 是 是 正常 68 否
男 29 19.50 偏咸 有 是 否 是 很少 68 是
女 35 17.60 偏咸 有 是 是 否 正常 65 是
女 34 22.10 偏咸 有 否 是 是 偏少 64 是
女 26 23.50 清淡 无 否 否 是 正常 86 否
男 42 25.60 清淡 有 是 否 否 正常 70 是
女 29 18.60 清淡 无 否 是 是 偏少 73 否
男 32 17.80 偏咸 有 是 否 是 偏少 68 是
男 31 25.60 偏咸 有 否 否 否 正常 72 否
女 26 20.10 偏咸 有 是 否 是 正常 70 是