毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
1、项目介绍
技术栈:
Python语言、Flask后端框架、 bootstrap前端框架 、 MySQL数据库 、Echarts可视化大屏、 51job招聘网站数据
2、项目界面
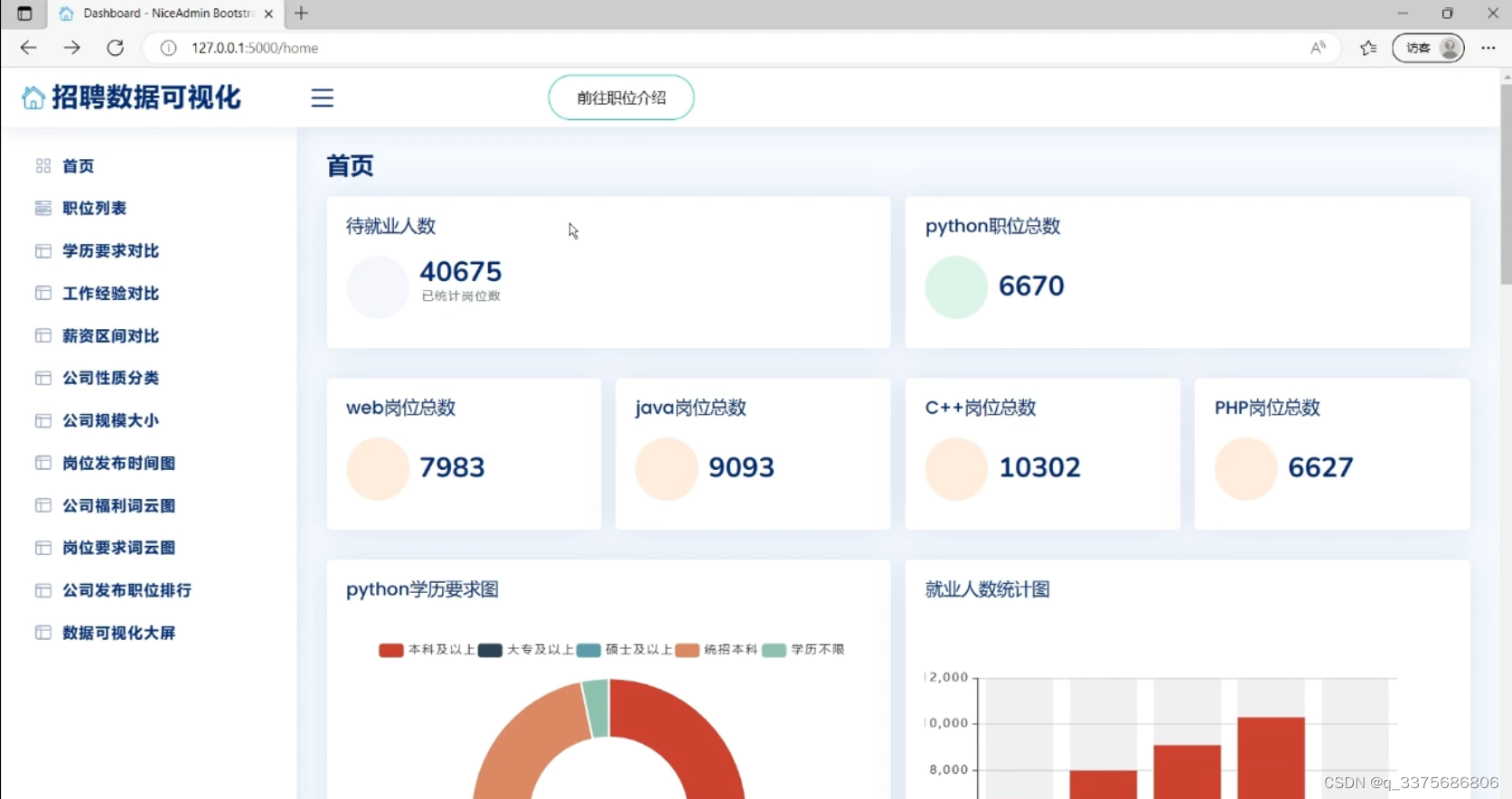
1、招聘数据可视化大屏

2、招聘数据概况
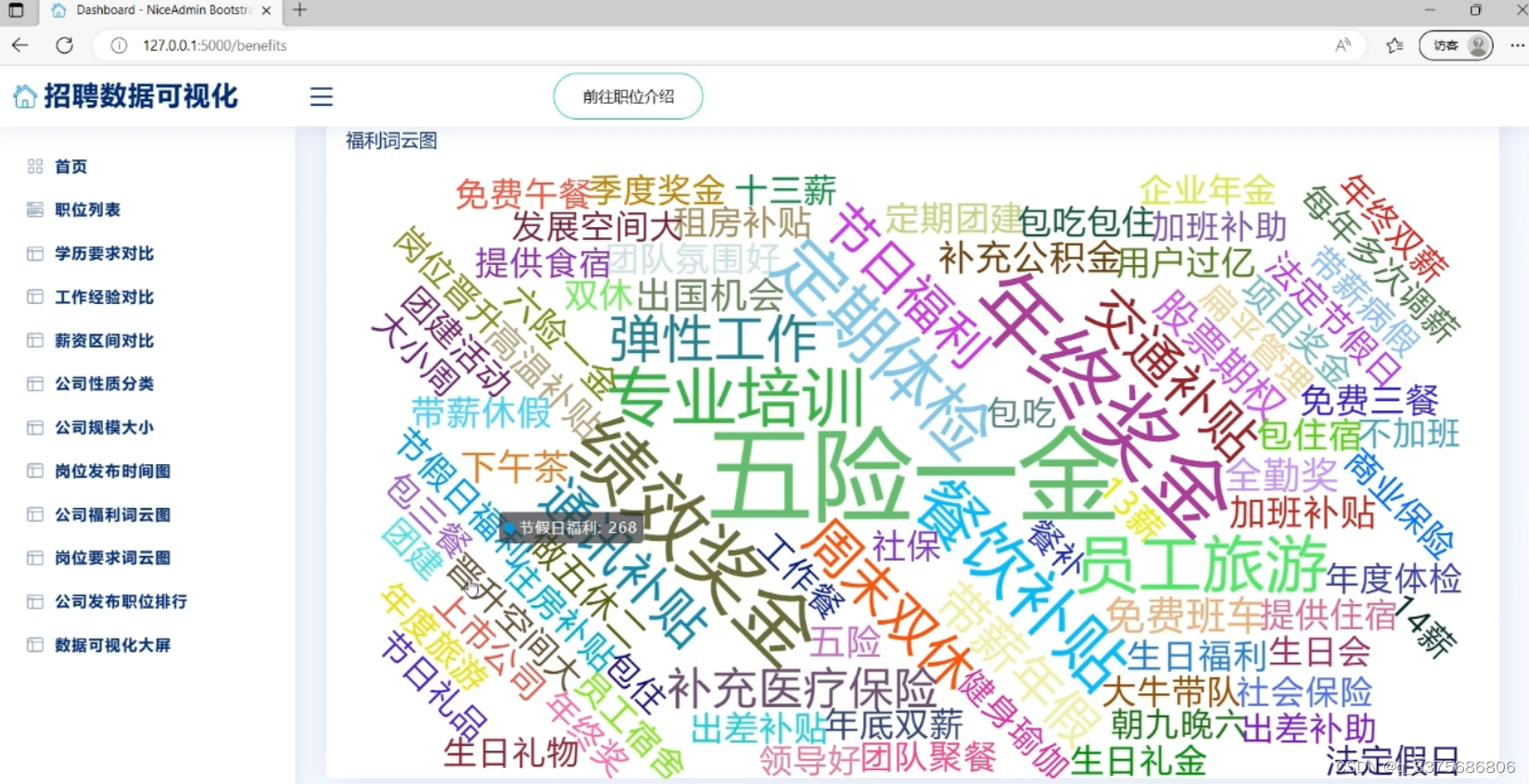
3、福利词云图
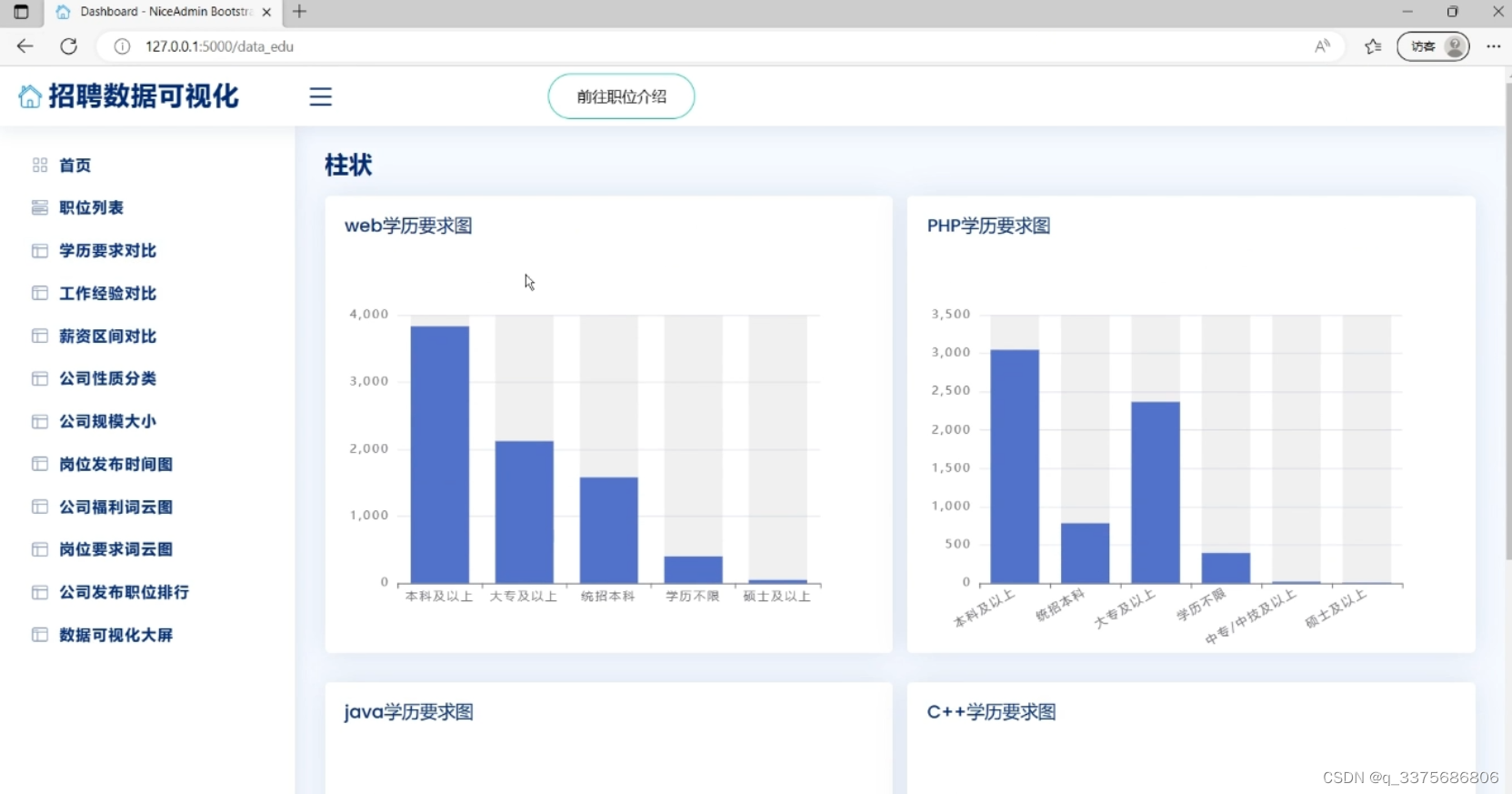
4、柱状图分析
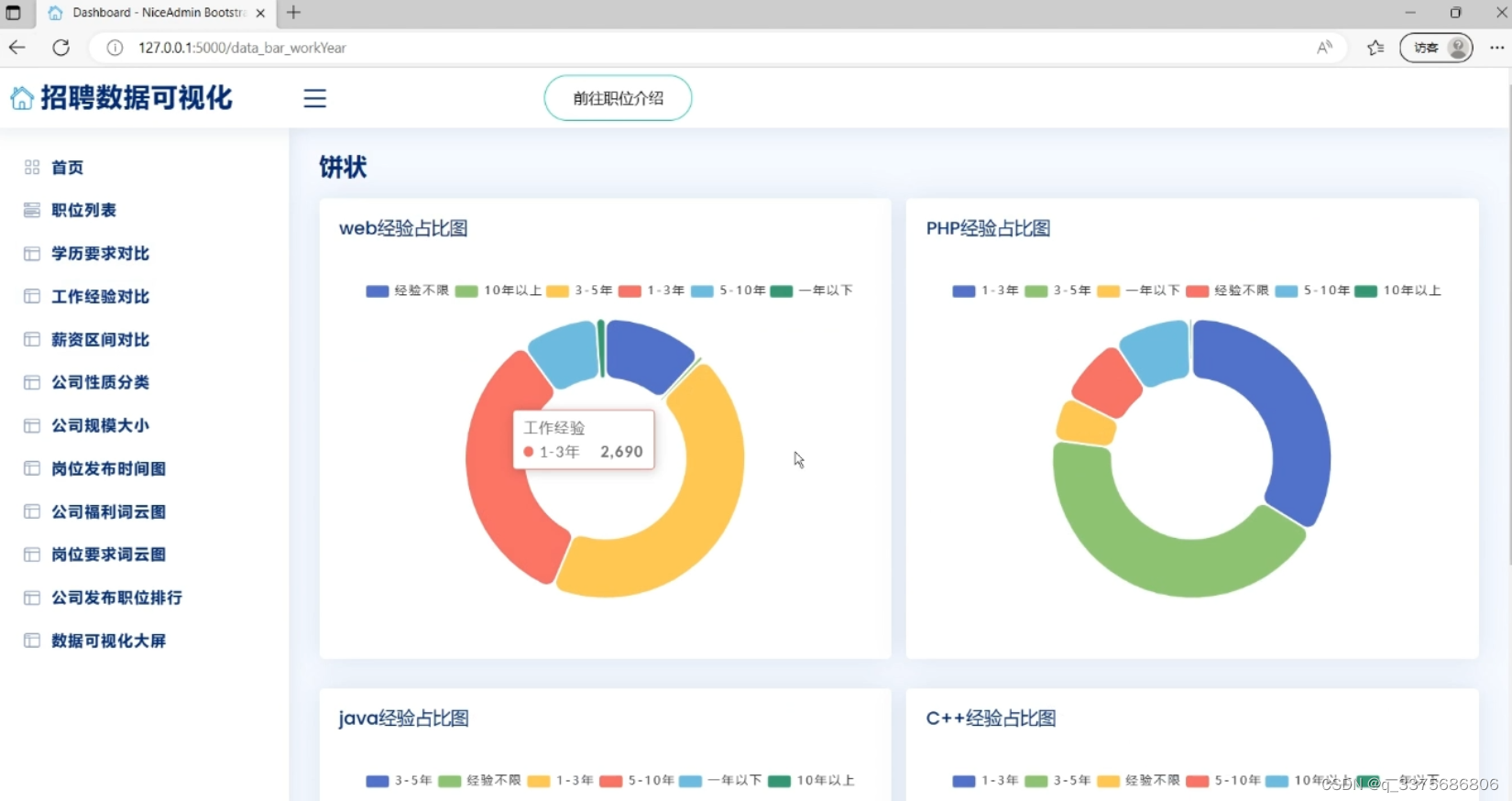
5、饼状图分析
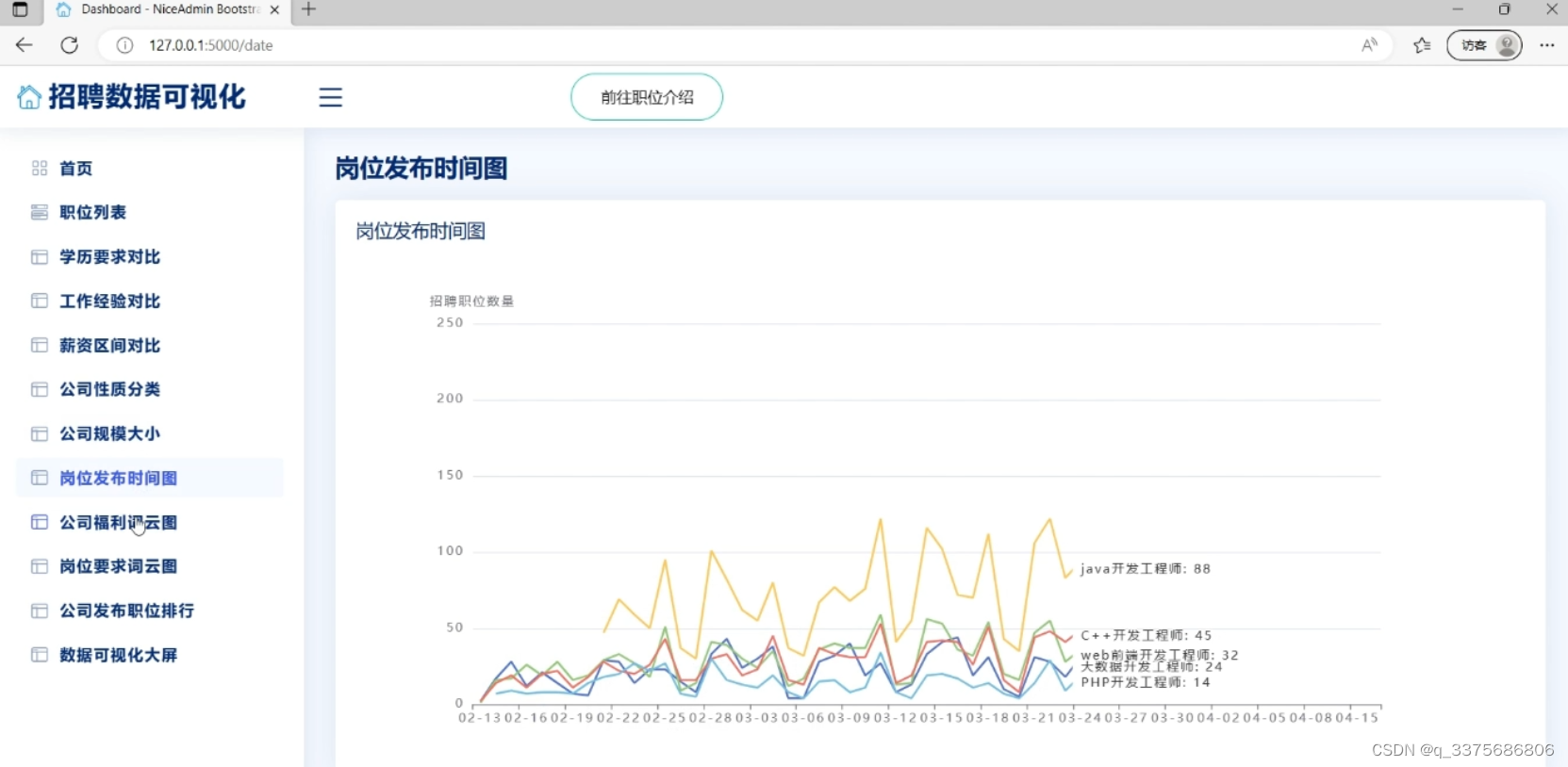
6、岗位发布时间图
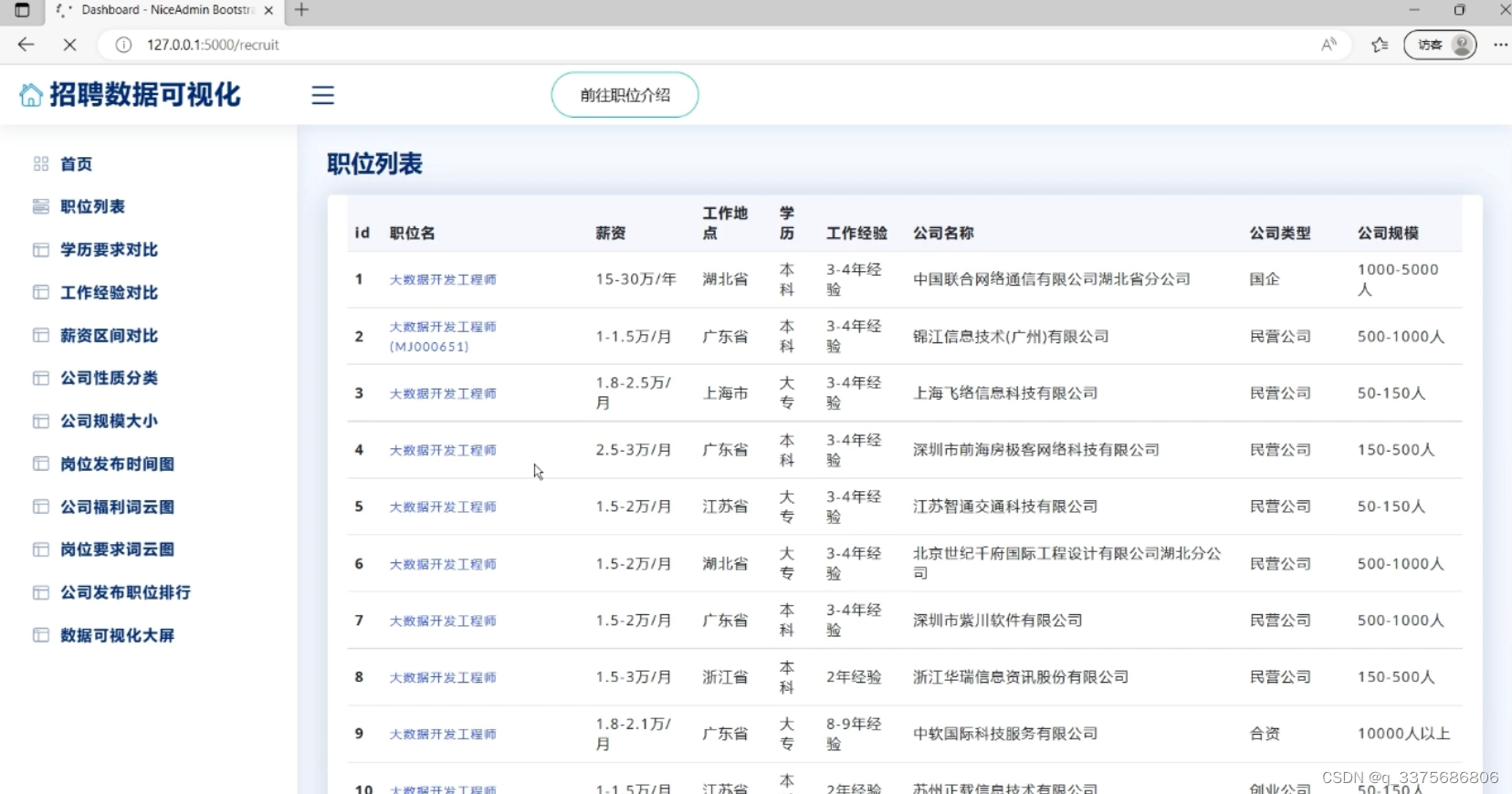
7、招聘数据
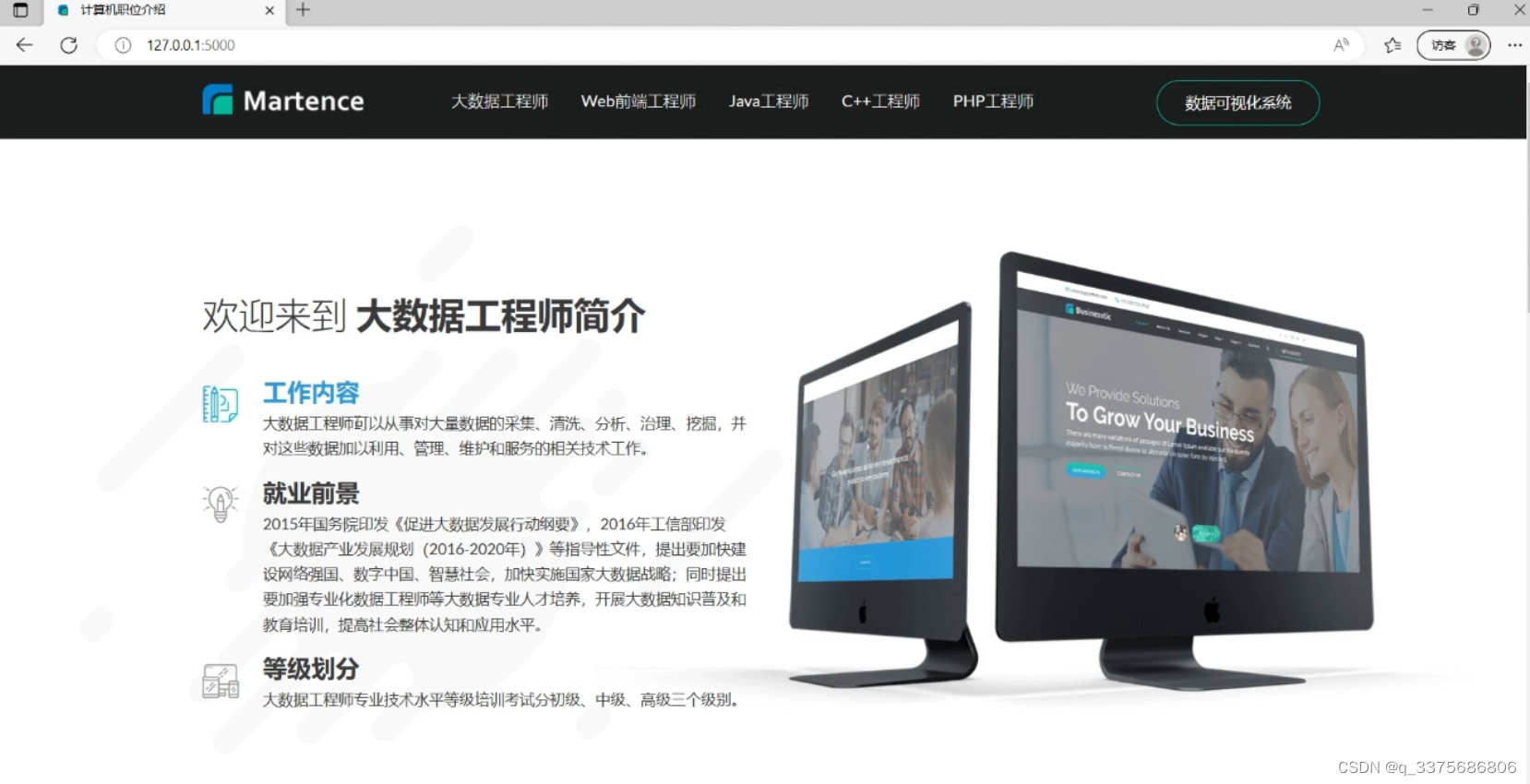
8、职位介绍
3、项目说明
Flask框架是一种轻量级的Python web框架,被广泛应用于Web开发领域。前程无忧是中国领先的人力资源服务提供商,招聘数据可视化大屏系统是基于Flask框架开发的一种数据展示平台。
该系统通过收集前程无忧的招聘数据,并结合数据可视化技术,将数据以直观的方式展示在大屏上。这样的系统对于企业来说非常有价值,因为它可以帮助企业更好地了解招聘市场的状况,以及行业的人才需求和趋势。
数据可视化大屏系统的主要功能包括:
-
数据收集和处理:系统会定期从前程无忧的数据库中获取最新的招聘数据,并进行数据清洗和处理,确保数据的准确性和完整性。
-
数据可视化:系统会将招聘数据以图表、表格等形式展示在大屏上,用户可以直观地了解各种招聘指标的变化趋势,比如职位数量、薪资水平、行业分布等。同时,系统还支持用户自定义的数据可视化需求,可以根据不同的业务需求进行定制化展示。
-
实时更新:系统会定时更新数据,确保展示的数据与实际情况保持同步。用户可以随时查看最新的招聘数据,以便做出更准确的决策。
-
多维度分析:系统支持多维度的数据分析,用户可以通过选择不同的维度进行数据筛选和对比,以便更深入地了解市场情况和行业趋势。
总而言之,Flask框架前程无忧招聘数据可视化大屏系统是一种利用数据可视化技术展示前程无忧招聘数据的平台,帮助企业更好地了解市场和行业的招聘动态,以便做出更明智的决策。
4、部分代码
import SQLUtils
from demoAgent import settingAgent
import jieba
from flask import Flask, render_template, request
import Setting
from flask import jsonify
import recruitPage
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='aaa515')
app = Flask(__name__)
db, all_table = recruitPage.create_mysql_ORM(app=app)
# 数据处理
jieba.setLogLevel(jieba.logging.INFO)
app_Agent = settingAgent()
app_data = app_Agent.init_flask()
con_sql = app_Agent.py_sql()
def get_sql_data(sql_ment):
con_sql.ping(reconnect=True)
mysql = con_sql.cursor()
data = []
for s in sql_ment:
mysql.execute(s)
datas = mysql.fetchall()
data.append(datas)
mysql.close()
return data
def set_salary(tuple):
salary_10 = 0
salary_20 = 0
salary_30 = 0
salary_40 = 0
salary_50 = 0
for i in tuple:
if int(i[1].split("·")[0]) <= 10:
salary_10 += 1
if 10 < int(i[1].split("·")[0]) <= 20:
salary_20 += 1
if 20 < int(i[1].split("·")[0]) <= 30:
salary_30 += 1
if 30 < int(i[1].split("·")[0]) <= 40:
salary_40 += 1
if int(i[1].split("·")[0]) >= 50:
salary_50 += 1
data_dict = {
"10k以下": salary_10,
"10k-20k": salary_20,
"20k-30k": salary_30,
"30k-40k": salary_40,
"50k以上": salary_50,
}
data = [
{"name": "10k以下", "value": salary_10},
{"name": "10k-20k", "value": salary_20},
{"name": "20k-30k", "value": salary_30},
{"name": "30k-40k", "value": salary_40},
{"name": "50k以上", "value": salary_50},
]
return data
def radar_edu(tuple):
data = []
for i in tuple:
data.append({"name": i[0], "value": i[1]})
return data
def map(tuple):
data = []
for i in tuple:
data.append({"name": i[0], "value": i[1]})
return data
def word_cloud(tuple):
data_srt = ""
for s in tuple:
data_srt = data_srt + s[1]
words = jieba.lcut(data_srt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
# print(items)
# 列表排序sort(reverse=True 降序,可迭代列表元素,key代表数据(列表数据))
items.sort(key=lambda x: x[1], reverse=True)
# print(items)
data = []
for w in items:
if w[1] >= 1000:
data.append(
{"name": w[0], "value": w[1]}
)
return data
def count_desc(tuple):
data = []
for i in range(0, 7):
data.append(tuple[i][1])
return data
def sount_desc_salary(tuple):
data = []
for i in range(0, 7):
# print(tuple[i])
data.append(tuple[i][2])
# print(data)
return data
def all_data(tuple):
return tuple[0][1]
def jin_wei_data(tuple):
data = []
for i in tuple:
temp = []
temp.append(i[1])
temp.append(i[2])
data.append({i[0]: temp})
return data
def data_names(tuple):
data = []
for d in tuple:
data.append({"name": d[0], "value": d[1]})
return data
def apiAgent(sql_index):
data = get_sql_data(Setting.bigList[sql_index])
data_map_data = []
for j in jin_wei_data(data[12]):
for key in j.keys():
for m in map(data[13]):
if m["name"] == key:
temp_list = []
for x in j[key]:
temp_list.append(x)
temp_list.append(m["value"])
data_map_data.append({
"name": m["name"],
"value": temp_list
})
data_dict = {
"data_name": data_names(data[0]),
"data_salary": set_salary(data[1]),
"data_edu": radar_edu(data[2]),
"data_bar": map(data[3]),
"data_bar_workYear": map(data[4]),
"data_word_cloud": word_cloud(data[5]),
"data_name_desc": count_desc(data[6]),
"data_salary_desc": sount_desc_salary(data[7]),
"data_raozhi_desc": sount_desc_salary(data[8]),
"data_jinyan_desc": sount_desc_salary(data[9]),
"data_edu_desc": sount_desc_salary(data[10]),
"data_all_data": all_data(data[11]),
"all_map_data": data_map_data,
}
return data_dict
# 首页
# 职位数
@app.route("/data_all_data_python")
def data_all_data():
return jsonify({"data": data_dict["data_all_data"]})
@app.route("/data_all_data_web")
def data_all_data_web():
return jsonify({"data": data_dict_web["data_all_data"]})
@app.route("/data_all_data_java")
def data_all_data_java():
return jsonify({"data": data_dict_java["data_all_data"]})
@app.route("/data_all_data_C")
def data_all_data_C():
return jsonify({"data": data_dict_C["data_all_data"]})
@app.route("/data_all_data_PHP")
def data_all_data_PHP():
return jsonify({"data": data_dict_PHP["data_all_data"]})
@app.route('/home')
def home():
count=data_dict["data_all_data"]+data_dict_web["data_all_data"]+data_dict_java["data_all_data"]+data_dict_C["data_all_data"]+data_dict_PHP["data_all_data"]
return render_template("/home.html", count=count,python=data_dict["data_all_data"],web=data_dict_web["data_all_data"],java=data_dict_java["data_all_data"],C=data_dict_C["data_all_data"],PHP=data_dict_PHP["data_all_data"])
@app.route("/data_data_desc")
def data_data_desc():
d = SQLUtils.date_data()[2]
data = [d.get('大数据开发工程师'), d.get('web前端开发工程师'), d.get('C++开发工程师'), d.get('PHP开发工程师'), d.get('java开发工程师'), d.get('month')]
return jsonify({"data": data})
@app.route("/data_name_desc_data")
def data_name_desc_data():
return jsonify({"data": data_dict["data_name_desc"]})
# python学历要求
@app.route("/data_edu_data")
def data_edu_data():
return jsonify({"data": data_dict["data_edu"]})
@app.route("/data_edu")
def data_edu():
return render_template("/bar1.html")
#获取不同职位的岗位数量
@app.route('/job_count')
def job_count():
con_sql1 = app_Agent.py_sql()
c = con_sql1.cursor()
c.execute(Setting.jobCount)
# con_sql.commit()
res = c.fetchall()
c.close()
con_sql1.close()
job = []
count = []
for r in res:
job.append(r[1])
count.append(str(r[0]))
resdata = {
'job': job,
'count': count
}
return jsonify(resdata)
#现地区岗位排行
@app.route("/location")
def location():
# print('执行location')
data = []
dic = {}
list_name = ['select * from name_db where id >= 1']
location_name = get_sql_data(list_name)
for i in location_name:
for n in i:
location = n[5]
if dic.get(location) == None:
dic[location] = 1
else:
dic[location] = dic[location] + 1
# print(dic)
for k,v in dic.items():
if k.__contains__('市'):
k = k.replace('市', '')
elif k.__contains__('省'):
k = k.replace('省', '')
elif k.__contains__('自治区'):
k = k.replace('自治区', '')
if k.__contains__('维吾尔'):
k = k.replace('维吾尔', '')
elif k.__contains__('回族'):
k = k.replace('回族', '')
elif k.__contains__('特别行政区'):
k = k.replace('特别行政区', '')
d = {
'name': k,
'value': v
}
data.append(d)
data = sorted(data, key=lambda data: data['value'], reverse=True)
data = data[:15]
return jsonify({"data": data})
# python需求词云
@app.route("/word_cloud_python_data")
def word_python_data():
return jsonify({"data": data_dict["data_word_cloud"]})
# 面板大图
@app.route('/sct')
def sct():
return render_template("/sct.html")
# 大地图
@app.route("/locations")
def locations():
# print('执行location')
data = []
dic = {}
list_name = ['select * from name_db where id >= 1']
location_name = get_sql_data(list_name)
for i in location_name:
for n in i:
location = n[5]
if dic.get(location) == None:
dic[location] = 1
else:
dic[location] = dic[location] + 1
# print(dic)
for k,v in dic.items():
if k.__contains__('市'):
k = k.replace('市', '')
elif k.__contains__('省'):
k = k.replace('省', '')
elif k.__contains__('自治区'):
k = k.replace('自治区', '')
if k.__contains__('维吾尔'):
k = k.replace('维吾尔', '')
elif k.__contains__('回族'):
k = k.replace('回族', '')
elif k.__contains__('特别行政区'):
k = k.replace('特别行政区', '')
d = {
'name': k,
'value': v
}
data.append(d)
data = sorted(data, key=lambda data: data['value'], reverse=True)
return jsonify({"data": data})
# 就业人数
@app.route("/data_name_desc")
def data_name_desc():
return render_template("bar2.html")
# 地区词云
@app.route("/word_cloud")
def word_region():
return render_template("wordcloud2.html")
# 职位数量
@app.route("/job_data", methods=["GET"])
def job_data():
key = SQLUtils.job_data()
return jsonify({"k": key})
@app.route("/data_name")
def data_name():
return jsonify({"data": data_dict["data_name"]})
@app.route("/data_name_web")
def data_name_web():
return jsonify({"data": data_dict_web["data_name"]})
if __name__ == '__main__':
# app.run(debug=True)
app.run()
源码获取:
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的头像和用户名就可以找到我啦🍅
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻