毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:Python语言、Flask框架、知识图谱、机器学习、智能医疗问答、数据库
医疗问答模块、医疗查询模块、反馈建议模块、医疗问答咨询记录模块、数据可视化模块、注册登录模块、后台管理模块
2、项目界面
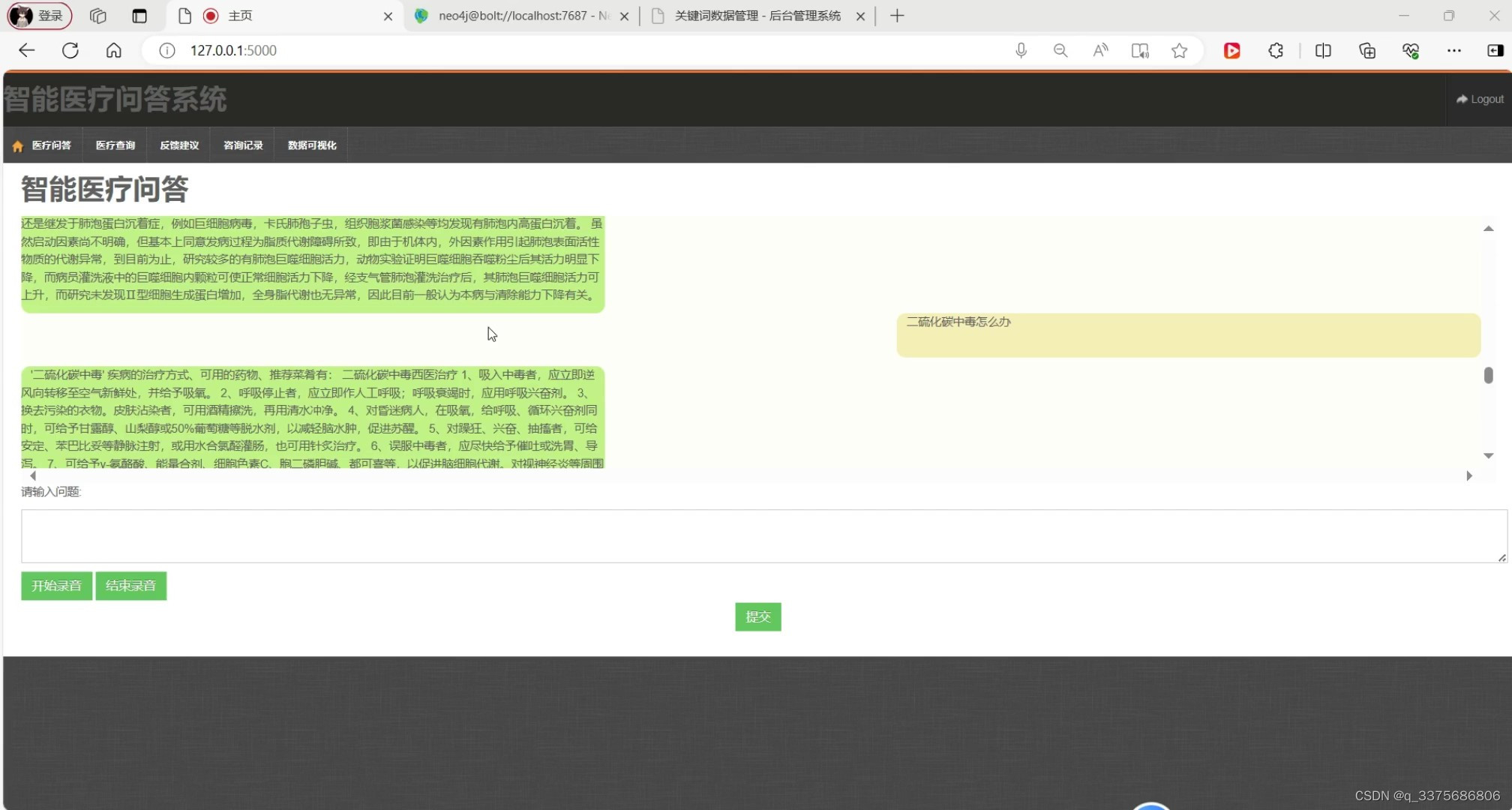
(1)医疗问答模块
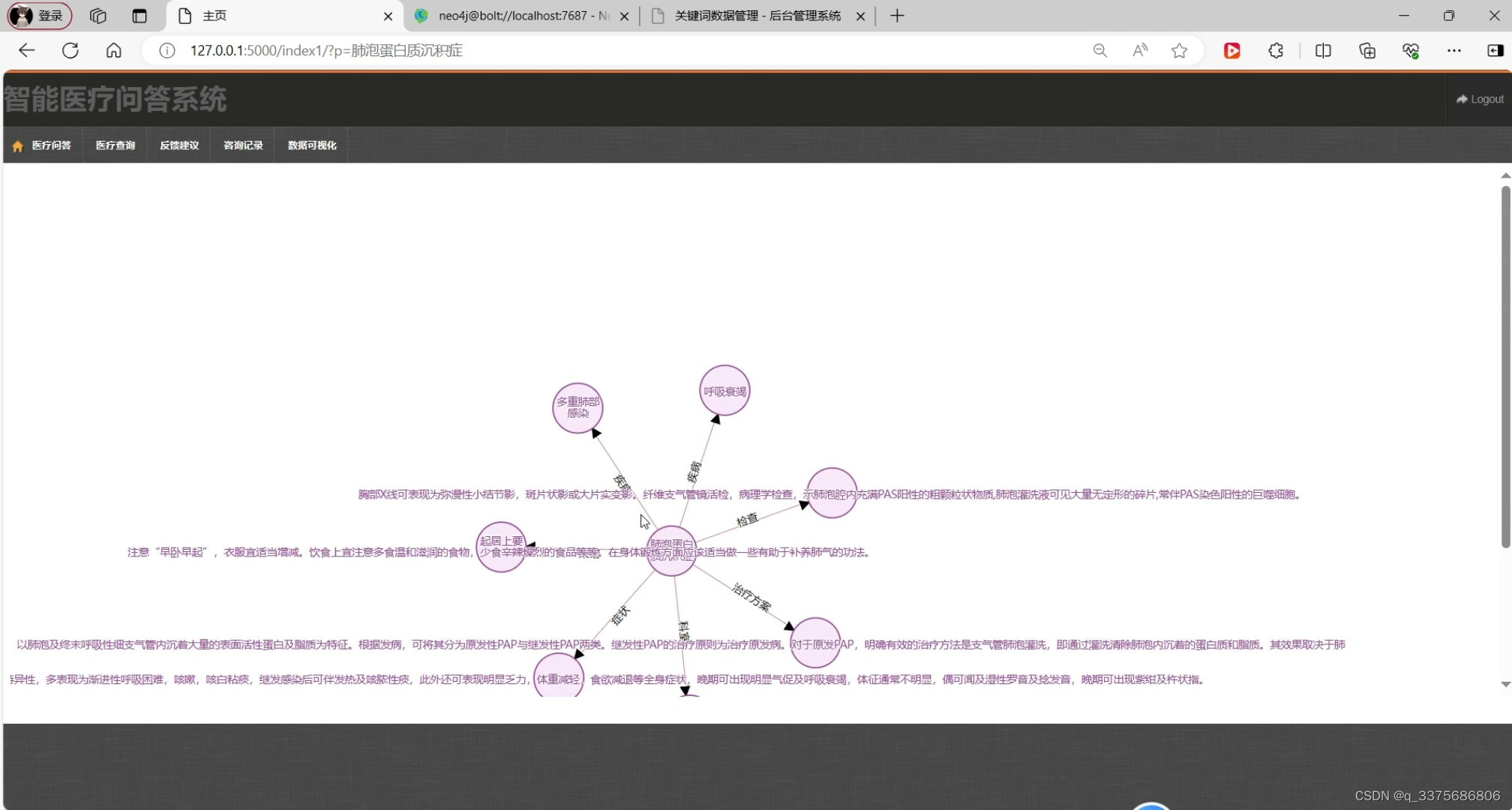
(2)医疗查询模块----知识图谱
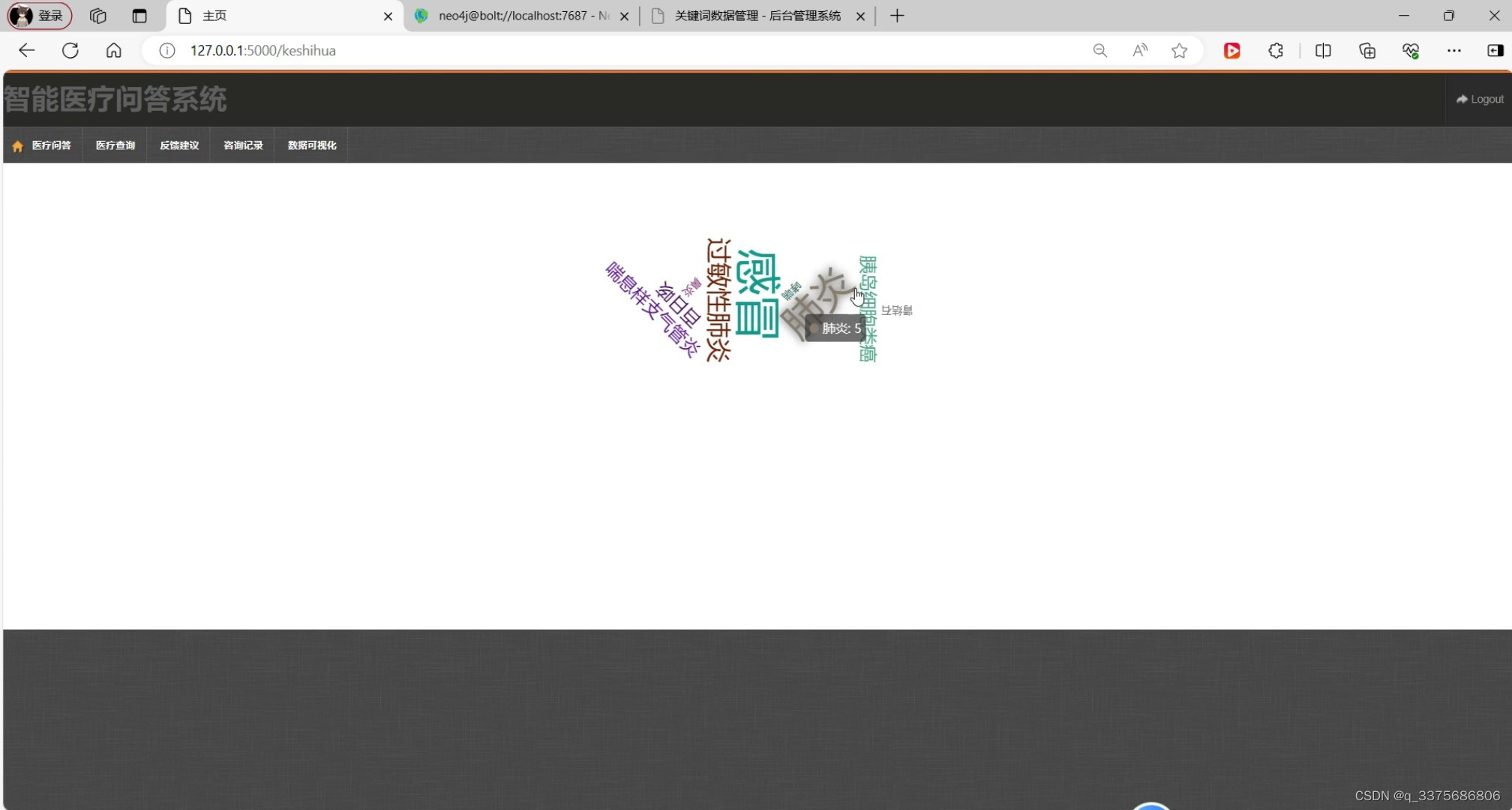
(3)数据可视化模块
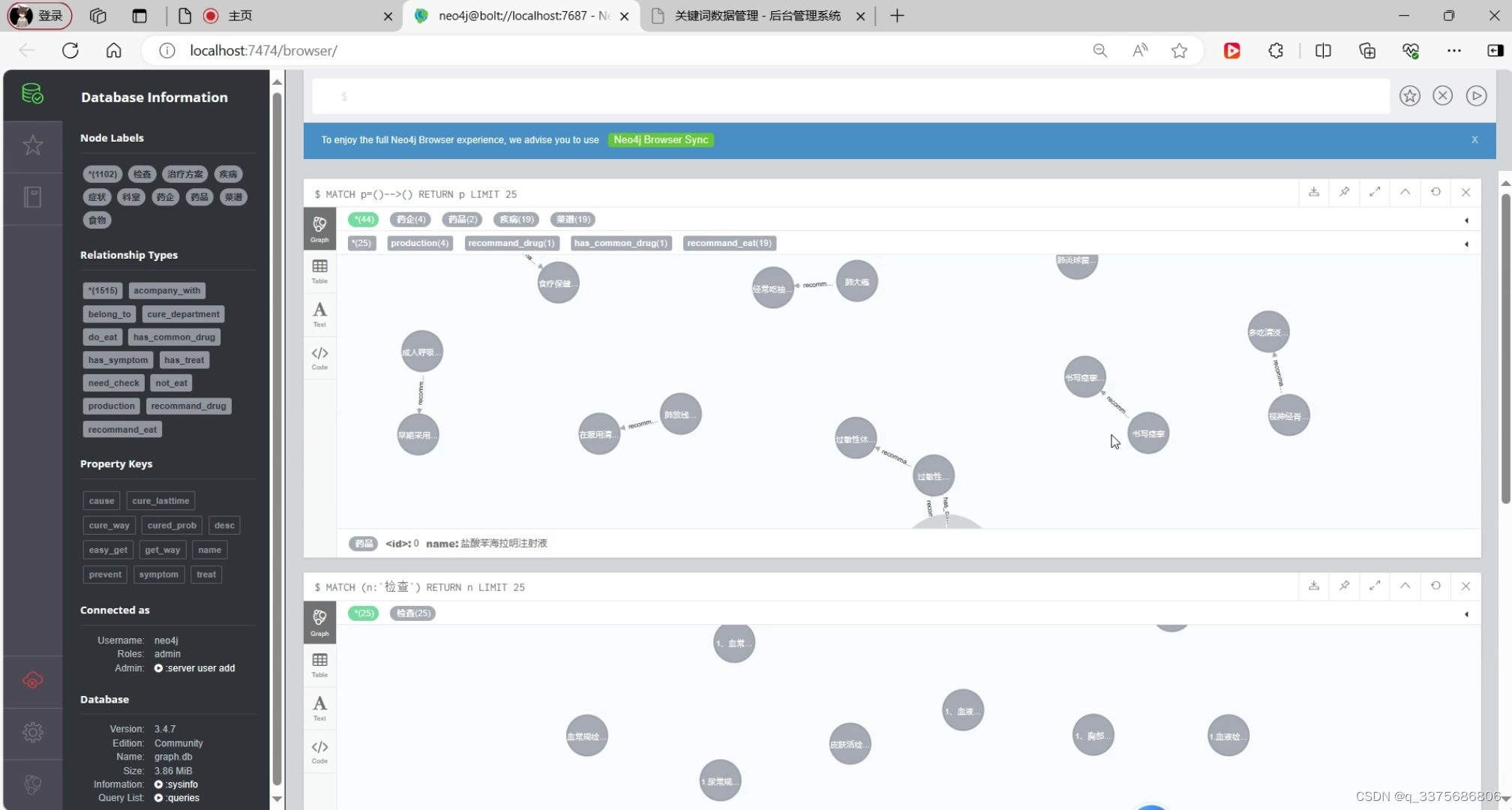
(4)知识图谱—neo4j图数据库
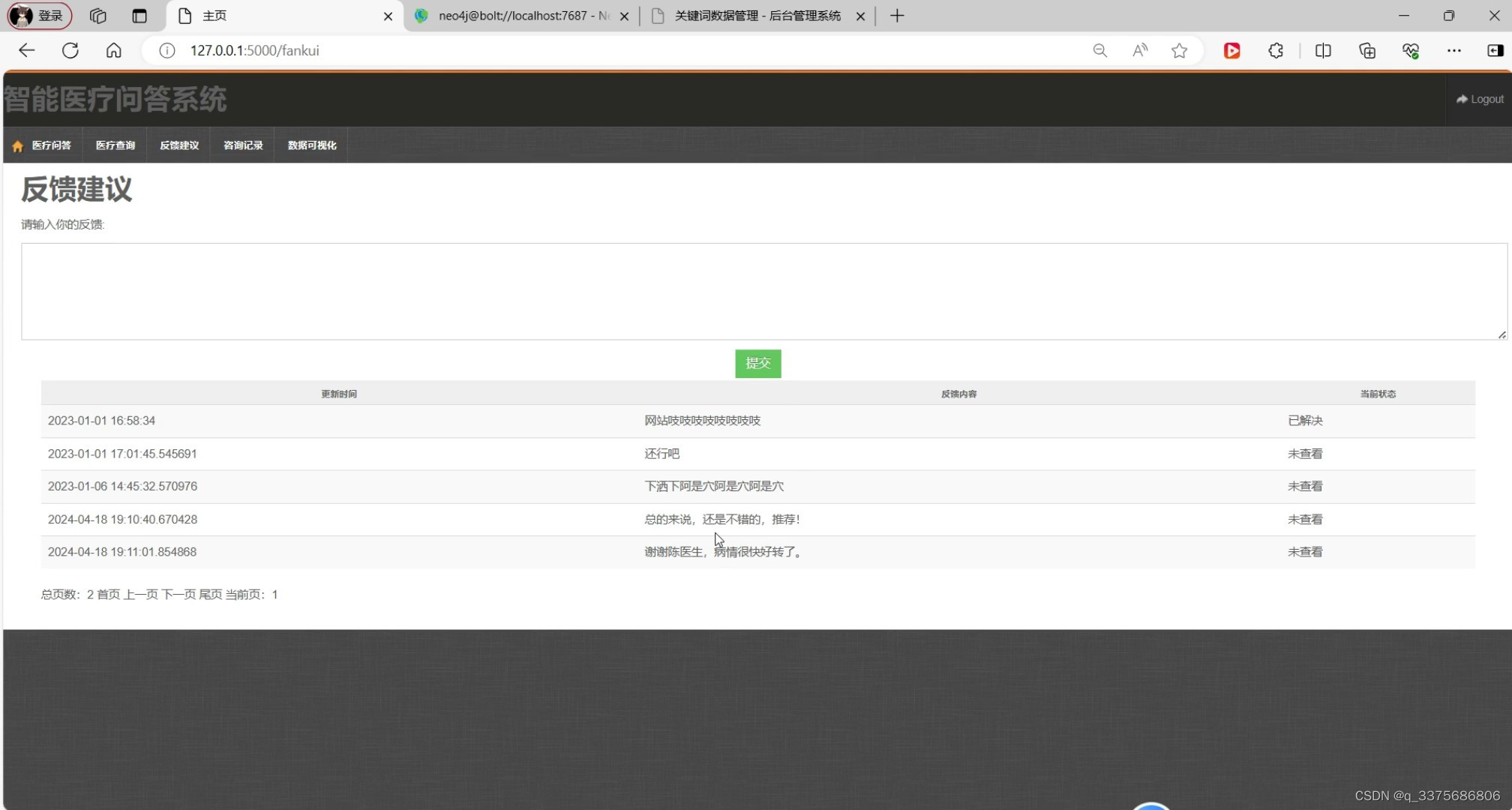
(5)反馈建议模块
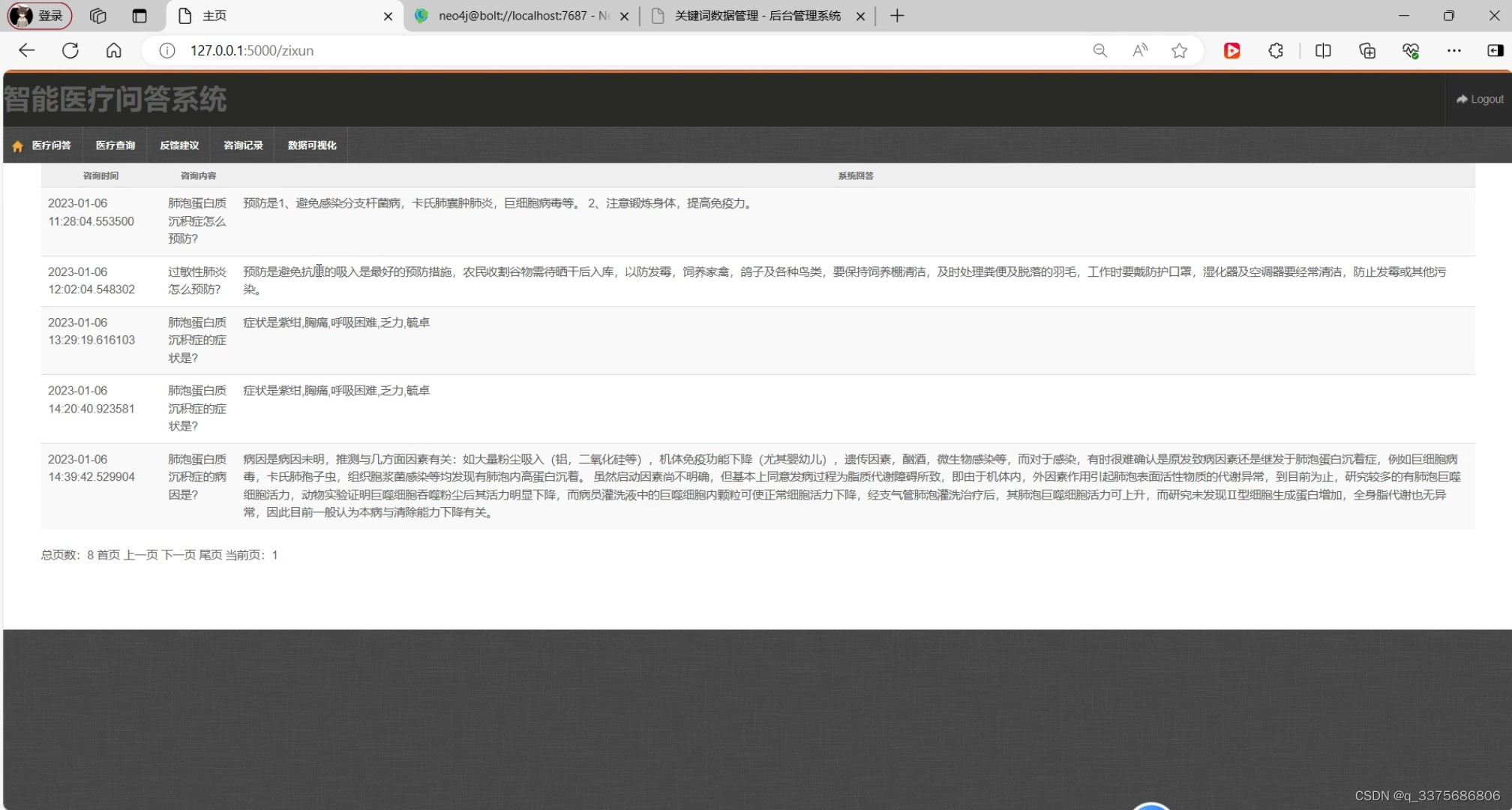
(6)咨询记录模块
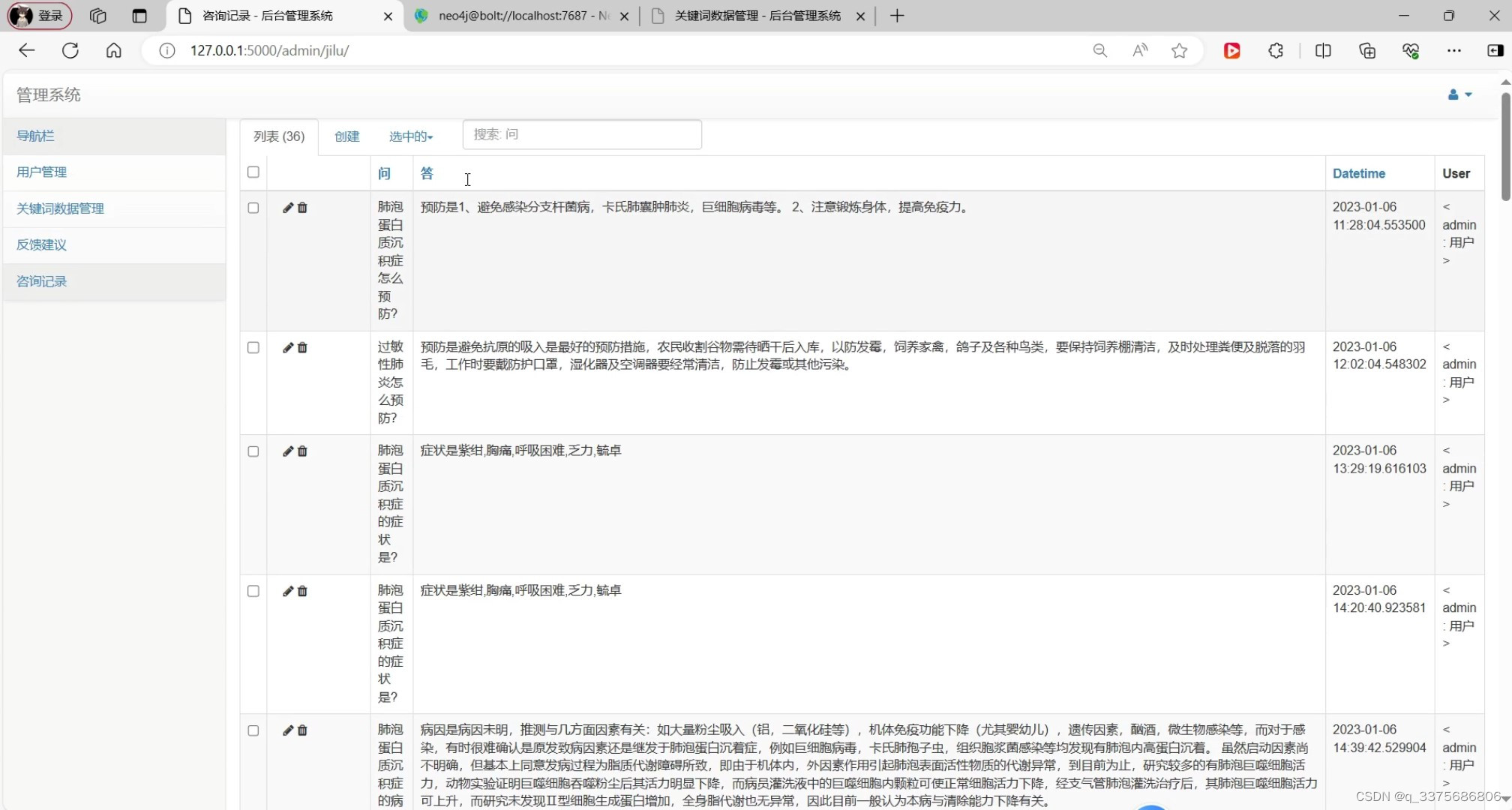
(7)后台数据管理模块
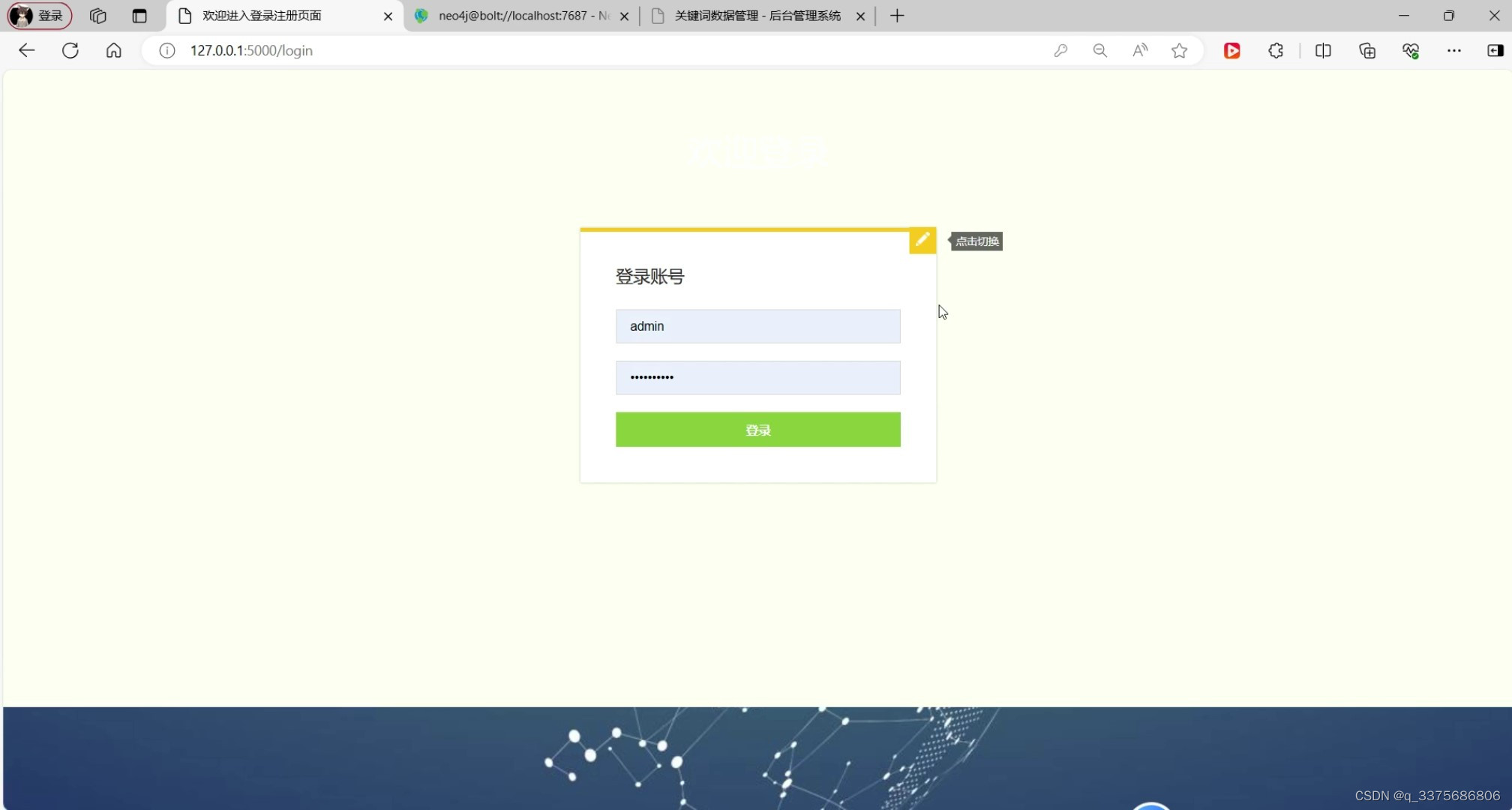
(8)注册登录模块
3、项目说明
随着信息技术的飞速发展,智慧医疗问答系统正逐渐成为医疗领域的一项重要创新。该系统集成了Python语言、Flask框架、知识图谱、机器学习等多项先进技术,旨在为患者和医疗工作者提供便捷、高效、准确的医疗咨询和服务。以下是对该系统的详细介绍。
一、系统概述
智慧医疗问答系统是一个智能化的在线医疗服务平台,其核心功能包括医疗问答、医疗查询、反馈建议、医疗问答咨询记录、数据可视化、注册登录以及后台管理等模块。该系统通过自然语言处理技术、机器学习算法和知识图谱技术,实现了对医疗知识的智能理解和回答,为患者提供了更加便捷、高效的医疗咨询体验。
二、系统特点
智能化:系统采用先进的自然语言处理技术和机器学习算法,能够准确理解用户的查询意图,并根据知识图谱中的医疗知识进行智能回答。这种智能化的问答方式不仅提高了回答的准确性,还大大减少了人工客服的工作量。
高效性:系统具备快速响应和高效处理的能力,能够在短时间内为用户提供准确的医疗咨询和解答。同时,系统还支持多用户并发访问,能够满足大量用户的咨询需求。
准确性:系统基于知识图谱技术构建,包含了丰富的医疗知识和专业术语。在回答用户问题时,系统能够准确匹配相关知识点,并给出专业的解答和建议。这种基于知识图谱的回答方式确保了回答的准确性和权威性。
可视化:系统还具备数据可视化功能,可以将用户的咨询记录、问题分类等信息以图表、图形等形式进行展示。这种可视化方式有助于医疗工作者更好地了解用户需求和服务效果,为优化服务质量和提升用户满意度提供了有力支持。
三、系统模块介绍
医疗问答模块:该模块是系统的核心功能之一,能够为用户提供智能化的医疗咨询和解答。用户可以通过自然语言输入问题,系统会根据知识图谱中的医疗知识进行智能回答。
医疗查询模块:该模块提供了丰富的医疗信息查询功能,包括疾病查询、药品查询、医院查询等。用户可以通过输入关键词或选择分类进行查询,系统会根据用户需求返回相关的医疗信息。
反馈建议模块:该模块允许用户对系统的回答和服务进行评价和反馈,提出自己的建议和意见。系统会根据用户反馈不断优化和改进服务质量。
医疗问答咨询记录模块:该模块记录了用户的咨询历史和问题分类等信息,为医疗工作者提供了有价值的数据支持。同时,用户也可以随时查看自己的咨询记录和问题解答。
数据可视化模块:该模块将用户的咨询记录、问题分类等信息以图表、图形等形式进行展示,帮助医疗工作者更好地了解用户需求和服务效果。
注册登录模块:该模块为用户提供了注册和登录功能,确保用户信息的安全性和隐私性。同时,系统还提供了用户信息管理功能,允许用户随时修改个人信息和设置。
后台管理模块:该模块为医疗工作者提供了后台管理功能,包括用户管理、知识图谱管理、数据统计分析等。医疗工作者可以通过后台管理系统对系统进行配置和管理,确保系统的正常运行和安全性。
四、总结
智慧医疗问答系统是一个集成了多项先进技术的智能化医疗服务平台。该系统不仅具备高效、准确、智能的医疗咨询功能,还提供了丰富的医疗信息查询和数据可视化功能。通过该系统,患者和医疗工作者可以更加便捷地获取医疗知识和服务支持,为提升医疗服务质量和效率提供了有力支持。
4、核心代码
# -*- coding: utf-8 -*-
from py2neo import Graph
import json
import re
class Neo4jToJson(object):
"""知识图谱数据接口"""
def __init__(self):
"""初始化数据"""
# 与neo4j服务器建立连接
self.graph = Graph('http://localhost:7474',auth=('neo4j','neo4j' ))
self.links = []
self.nodes = []
def all(self):
# 取出所有节点数据
nodes_data_all = self.graph.run("MATCH (n) RETURN n").data()
# node名存储
nodes_list = []
for node in nodes_data_all:
nodes_list.append(node['n']['name'])
for name1 in nodes_list:
# 获取知识图谱中相关节点数据
try:
nodes_data = self.graph.run("MATCH (n)--(b) where n.name='" + name1 + "' return n,b").data()
links_data = self.graph.run("MATCH (n)-[r]-(b) where n.name='" + name1 + "' return r").data()
self.get_select_nodes(nodes_data)
self.get_links(links_data)
except:
continue
# 数据格式转换
neo4j_data = {'links': self.links, 'nodes': self.nodes}
neo4j_data_json = json.dumps(neo4j_data, ensure_ascii=False).replace(u'\xa0', u'')
return neo4j_data_json
def get_sql(self,sql):
nodes_data_all = self.graph.run(sql).data()
def post(self,name):
# 传过来的数据
select_name = name
# 取出所有节点数据
nodes_data_all = self.graph.run("MATCH (n) RETURN n").data()
# node名存储
nodes_list = []
for node in nodes_data_all:
nodes_list.append(node['n']['name'])
# 根据前端的数据,判断搜索的关键字是否在nodes_list中存在,如果存在返回相应数据,否则返回全部数据
for name1 in nodes_list:
if select_name in name1:
# 获取知识图谱中相关节点数据
nodes_data = self.graph.run("MATCH (n)--(b) where n.name='" + name1 + "' return n,b").data()
links_data = self.graph.run("MATCH (n)-[r]-(b) where n.name='" + name1 + "' return r").data()
self.get_select_nodes(nodes_data)
self.get_links(links_data)
break
# 数据格式转换
neo4j_data = {'links': self.links, 'nodes': self.nodes}
neo4j_data_json = json.dumps(neo4j_data, ensure_ascii=False).replace(u'\xa0', u'')
return neo4j_data_json
def get_links(self, links_data):
"""知识图谱关系数据获取"""
links_data_str = str(links_data)
links = []
i = 1
dict = {}
# 正则匹配
links_str = re.sub("[\!\%\[\]\,\。\{\}\-\:\'\(\)\>]", " ", links_data_str).split(' ')
for link in links_str:
if len(link) > 1:
if i == 1:
dict['source'] = link
elif i == 2:
dict['name'] = link
elif i == 3:
dict['target'] = link
self.links.append(dict)
dict = {}
i = 0
i += 1
return self.links
def get_select_nodes(self, nodes_data):
"""获取知识图谱中所选择的节点数据"""
dict_node = {}
for node in nodes_data:
name = node['n']['name']
tag = re.findall("_\d+:(.*?) ",str(node['n']))[0]
dict_node['name'] = name
dict_node['tag'] = tag
self.nodes.append(dict_node)
dict_node = {}
break
for node in nodes_data:
name = node['b']['name']
tag = re.findall("_\d+:(.*?) ",str(node['b']))[0]
dict_node['name'] = name
dict_node['tag'] = tag
self.nodes.append(dict_node)
dict_node = {}
def get_all_nodes(self, nodes_data):
"""获取知识图谱中所有节点数据"""
dict_node = {}
for node in nodes_data:
name = node['n']['name']
tag = node['n']['tag']
dict_node['name'] = name
dict_node['tag'] = tag
self.nodes.append(dict_node)
dict_node = {}
return self.nodes
if __name__ == '__main__':
data_neo4j = Neo4jToJson()
data = data_neo4j.graph.run("""MATCH (p:疾病名称)-[:症状]->(c:症状)
WHERE c.name CONTAINS '精神沉郁、 目光呆滞、反应极慢'
RETURN p.name""").data()
print(data)
print(list(data[0].values())[0])
# data = data_neo4j.all()
# print(data)
# null = 'null'
# print(eval(data))
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻