博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
项目技术说明:
python语言、Flask框架、MySQL数据库、Echarts可视化、
评论多维度分析、NLP情感分析、LDA主题分析、Bayes评论分类
2、项目界面
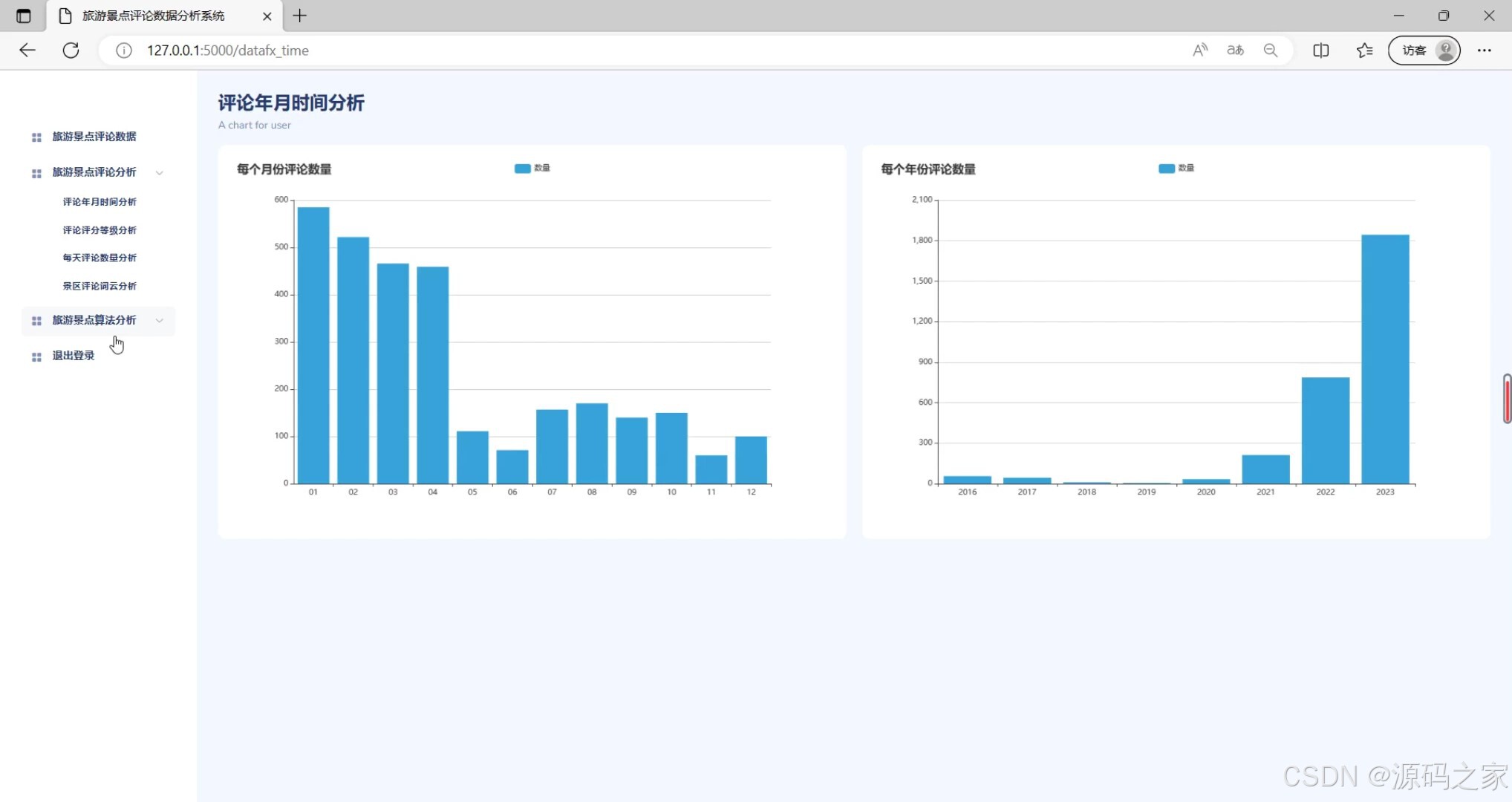
(1)评论年月时间分析
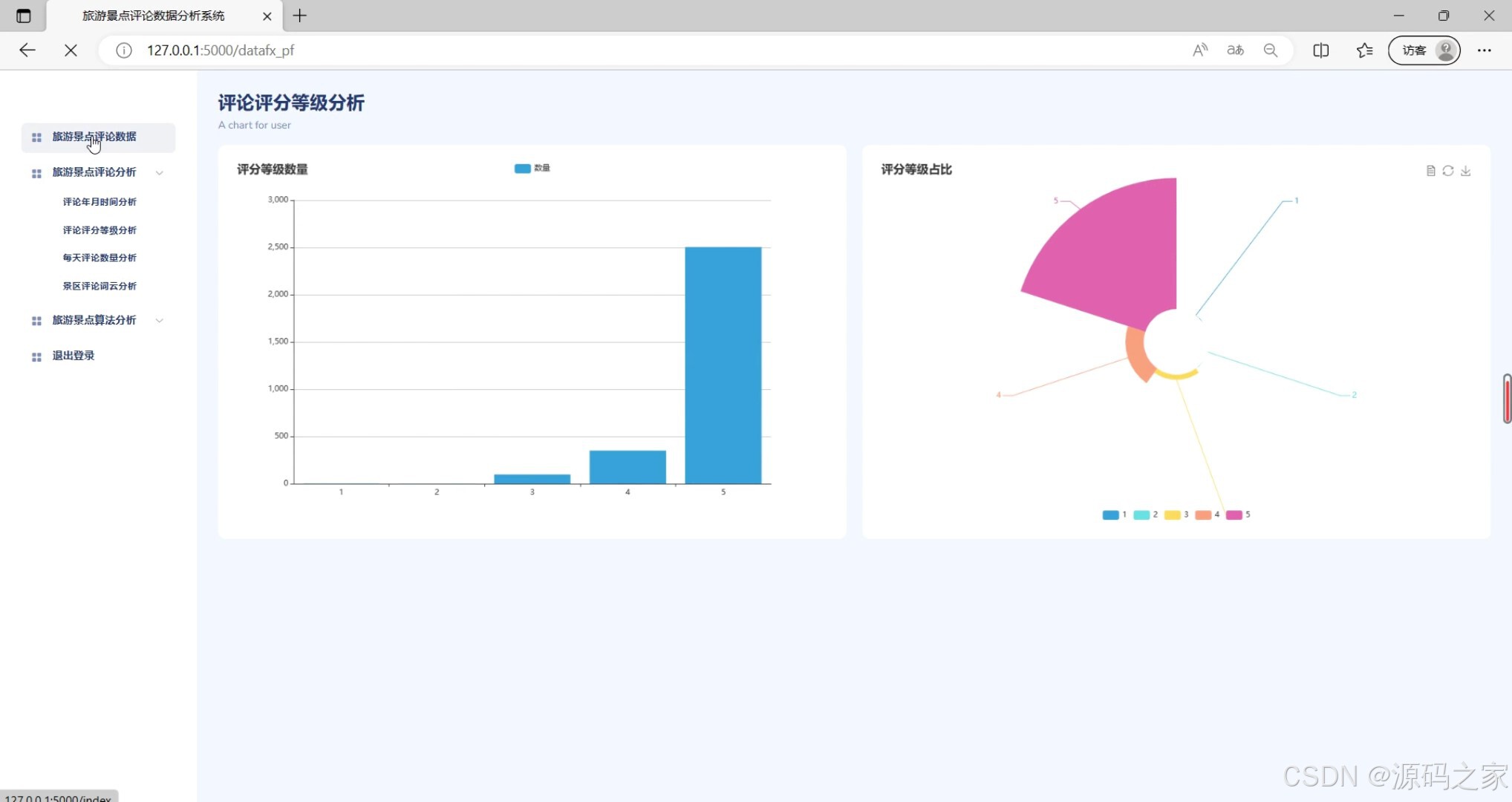
(2)评论评分等级分析
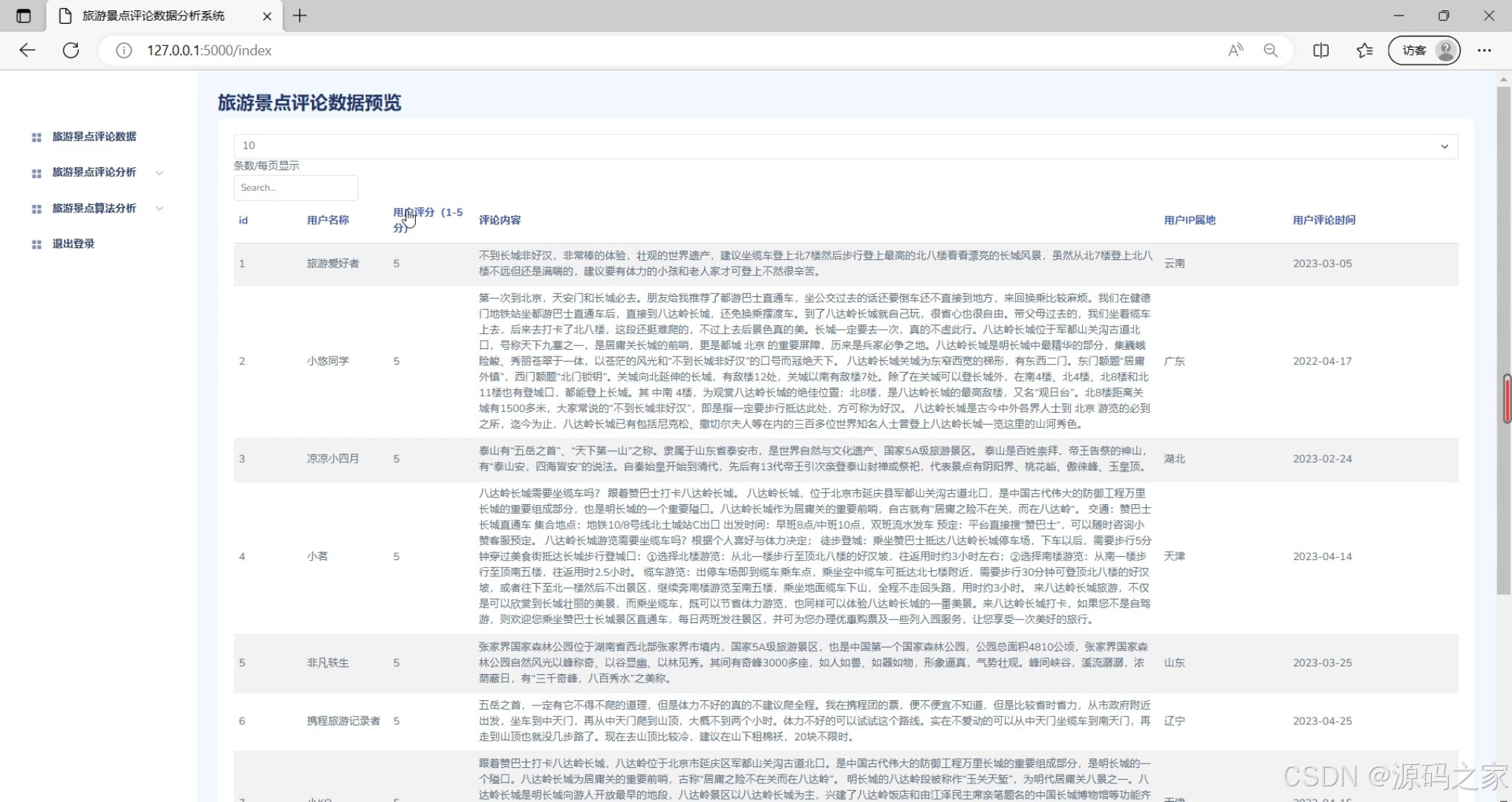
(3)旅游景点评论数据
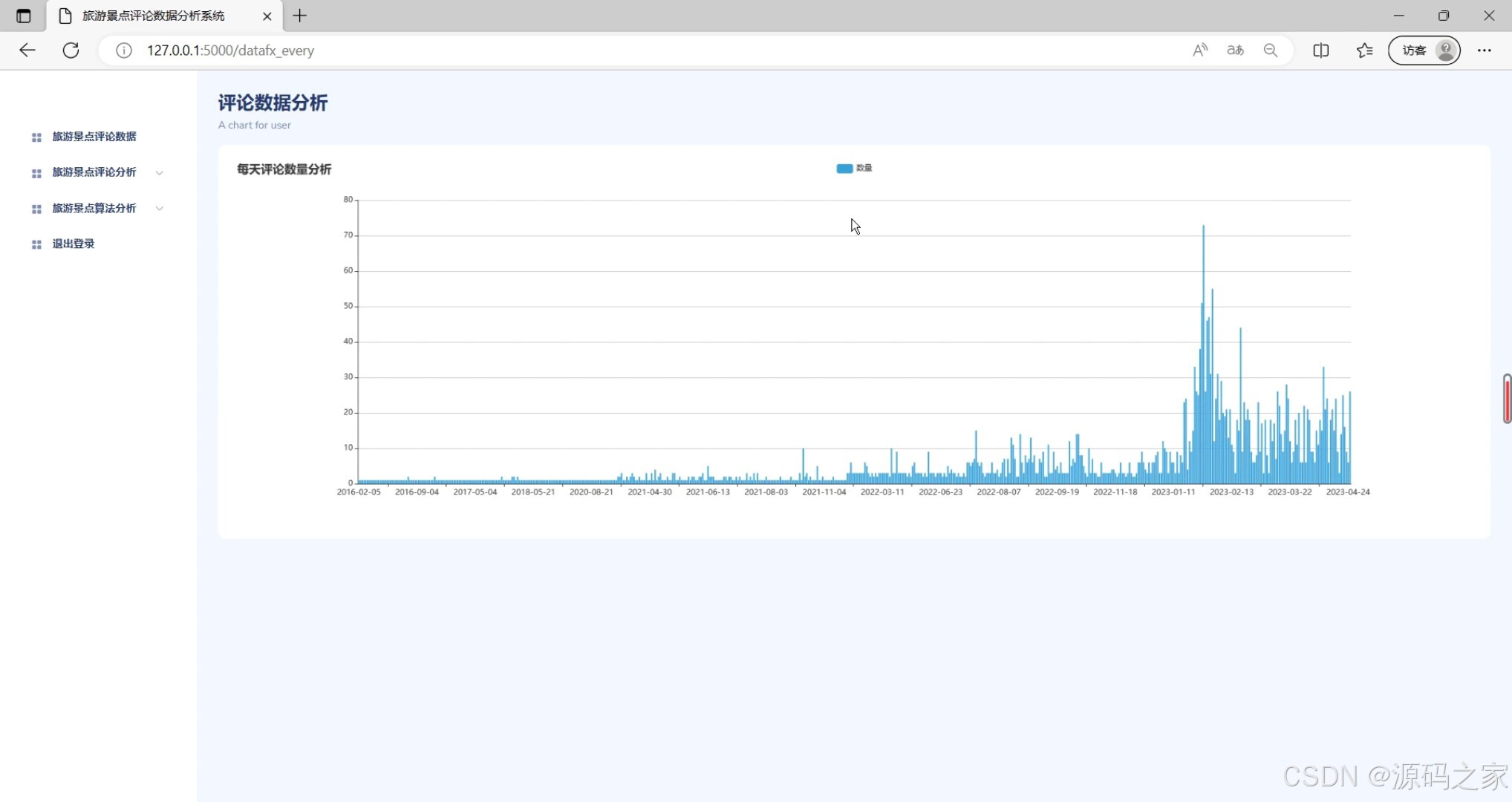
(4)评论数据分析
(5)景区评论词云图分析
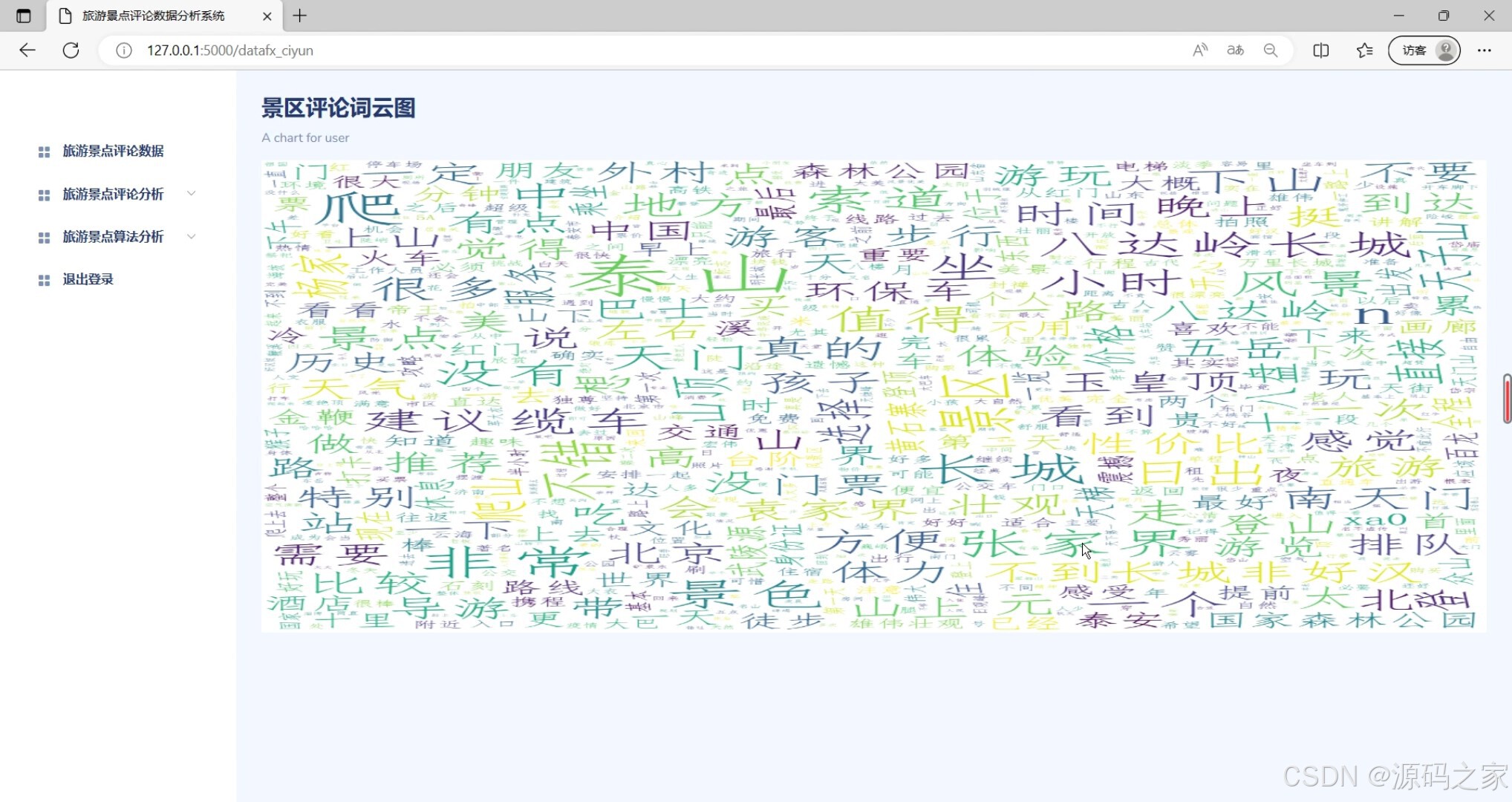
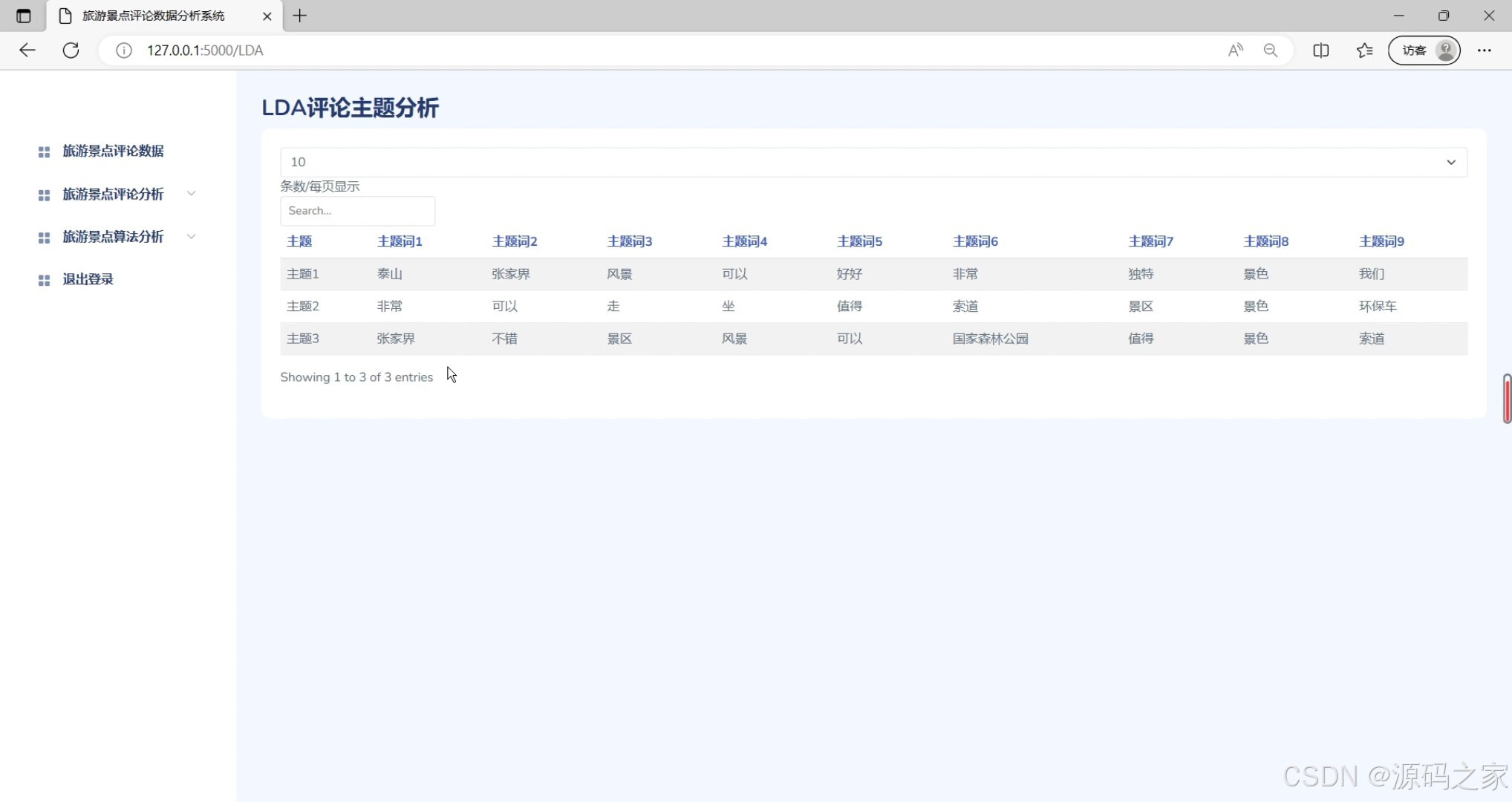
(6)LDA评论主题分析
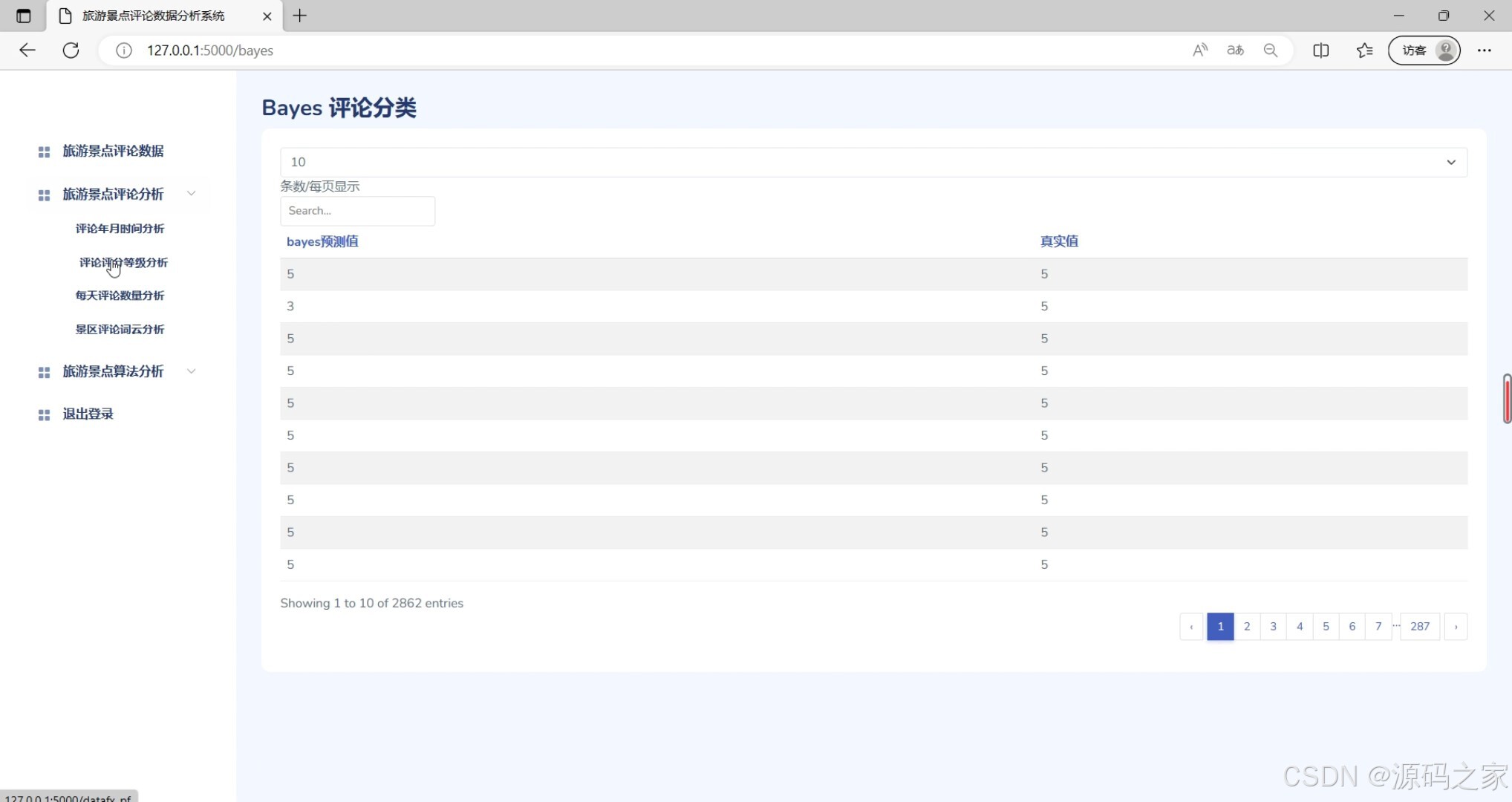
(7)Bayes评论分类
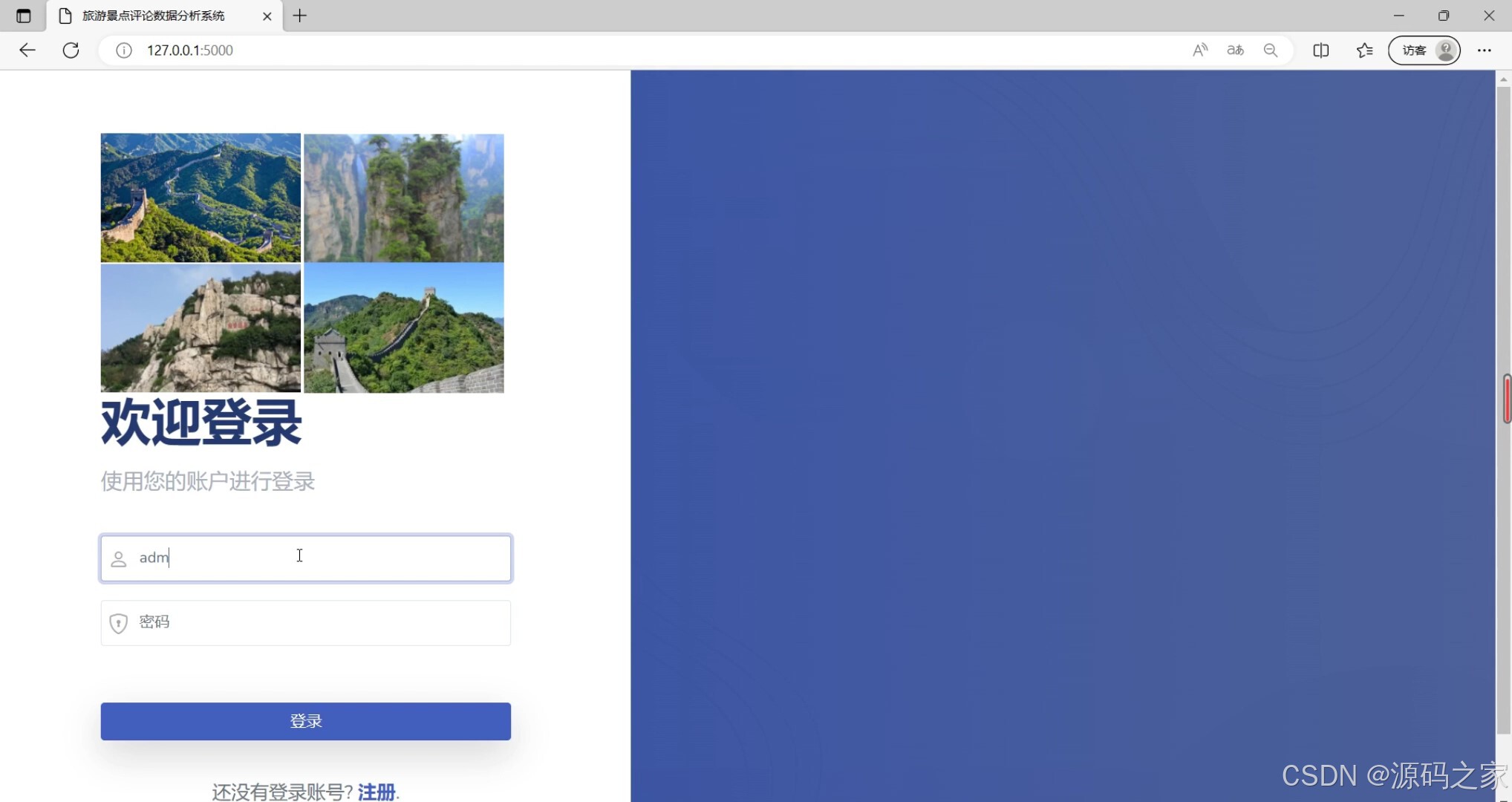
(8)注册登录界面
3、项目说明
- 评论数据分析模块
功能描述:该模块主要用于对收集到的评论数据进行多维度分析。它支持按年月时间分析评论的分布情况,以及根据评论的评分等级进行统计,帮助用户了解评论的时间趋势和评分分布。
界面元素:包括评论年月时间分析图表、评论评分等级分析图表等。 - 旅游景点评论数据展示模块
功能描述:该模块用于展示特定旅游景点的评论数据,包括评论内容、评论者、评论时间等详细信息。它帮助用户深入了解景点的口碑和游客反馈。
界面元素:包括旅游景点评论数据列表、评论内容展示区等。 - 评论数据可视化模块
功能描述:该模块利用Echarts等可视化工具,将评论数据以图表形式直观展示。它支持多种图表类型,如柱状图、饼图等,帮助用户更好地理解数据趋势和分布。
界面元素:包括各种可视化图表,如评论数据分析图表、景区评论词云图等。 - NLP情感分析模块
功能描述:该模块利用自然语言处理技术(NLP)对评论进行情感分析,判断评论的情感倾向(如正面、负面、中性)。它帮助用户了解游客对景点或产品的整体情感态度。
技术实现:基于情感字典或词袋模型进行情感分析,考虑否定词和程度副词的影响,提高分析的准确性。 - LDA主题分析模块
功能描述:该模块利用LDA(Latent Dirichlet Allocation)算法对评论进行主题分析,提取评论中的关键主题和话题。它帮助用户了解游客关注的焦点和热点话题。
界面元素:包括LDA评论主题分析图表,展示不同主题的比例和关键词。 - Bayes评论分类模块
功能描述:该模块利用贝叶斯分类算法对评论进行分类,将评论划分为不同的类别(如好评、中评、差评)。它帮助用户快速识别评论的类别,便于后续处理和分析。
界面元素:包括Bayes评论分类结果展示区,展示评论的分类标签和数量。 - 用户注册登录模块
功能描述:该模块为用户提供注册和登录功能,确保用户能够安全地访问系统并管理自己的数据。它支持用户名、密码等信息的验证和存储。
界面元素:包括注册登录界面,包含用户名、密码输入框、验证码等。
综上所述,这个系统包含了多个功能模块,每个模块都承担着不同的功能和角色,共同构成了系统的完整性和实用性。通过这些模块,用户可以全面了解评论数据的多维度信息,进行情感分析、主题分析和分类等操作,为旅游景点的运营和管理提供有力的支持。
4、核心代码
import pandas as pd
import jieba
import pymysql
import re
sql = 'select id,nickname, score, content, productColor, creationTime from data '
con = pymysql.connect(host='127.0.0.1', user='root', passwd='123456', port=3306, db='comment', charset='utf8')
df = pd.read_sql(sql,con)
postive = pd.read_sql(sql,con)
postive = postive[postive['score'] == 5].drop_duplicates()
print(postive)
negtive = pd.read_sql(sql,con)
negtive = negtive[negtive['score'] == 1].drop_duplicates()
print(negtive)
# 文本去重(文本去重主要是一些系统自动默认好评的那些评论 )
# 文本分词
mycut = lambda s: ' '.join(jieba.cut(s)) # 自定义分词函数
po = postive.content.apply(mycut)
ne = negtive.content.apply(mycut)
# 停用词过滤(停用词文本可以自己写,一行一个或者用别人整理好的,我这是用别人的)
with open(r'stopwords.txt', encoding='utf-8') as f: #这里的文件路径最好改成自己的本地绝对路径
stop = f.read()
stop = [' ', ''] + list(stop[0:]) # 因为读进来的数据缺少空格,我们自己添加进去
po['1'] = po[0:].apply(lambda s: s.split(' ')) # 将分词后的文本以空格切割
po['2'] = po['1'].apply(lambda x: [i for i in x if i not in stop]) # 过滤停用词
# 在这里我们也可以用到之前的词云图分析
# post = []
# for word in po:
# if len(word)>1 and word not in stop:
# post.append(word)
# print(post)
# wc = wordcloud.WordCloud(width=1000, font_path='simfang.ttf',height=800)#设定词云画的大小字体,一定要设定字体,否则中文显示不出来
# wc.generate(' '.join(post))
# wc.to_file(r'..\yun.png')
ne['1'] = ne[0:].apply(lambda s: s.split(' '))
ne['2'] = ne['1'].apply(lambda x: [i for i in x if i not in stop])
from gensim import corpora, models
# 负面主题分析
neg_dict = corpora.Dictionary(ne['2'])
neg_corpus = [neg_dict.doc2bow(i) for i in ne['2']]
neg_lda = models.LdaModel(neg_corpus, num_topics=3, id2word=neg_dict)
# 正面主题分析
pos_dict = corpora.Dictionary(po['2'])
pos_corpus = [pos_dict.doc2bow(i) for i in po['2']]
pos_lda = models.LdaModel(pos_corpus, num_topics=3, id2word=pos_dict)
pos_theme = pos_lda.show_topics()
# 展示主题
pos_theme = pos_lda.show_topics()
# 取出高频词
pattern = re.compile(r'[\u4e00-\u9fa5]+')
pattern.findall(pos_theme[0][1])
pos_key_words = []
for i in range(3):
pos_key_words.append(pattern.findall(pos_theme[i][1]))
pos_key_words = pd.DataFrame(data=pos_key_words, index=['主题1', '主题2', '主题3'])
pos_key_words.to_csv('lda.csv')
from snownlp import SnowNLP
import pandas as pd
import pymysql
def main():
sql = 'select id,nickname, score, content, productColor, creationTime from data order by creationTime'
con = pymysql.connect(host='127.0.0.1', user='root', passwd='123456', port=3306, db='comment', charset='utf8')
df = pd.read_sql(sql, con)
df.drop_duplicates(keep='first', inplace=True)
df = df.dropna()
content = df['content'].tolist()
contentlist = []
for x in content:
contentlist.append(SnowNLP(x).sentiments)
df['nlp'] = contentlist
df = df[['nickname', 'score', 'content', 'nlp']]
df.to_csv('nlp.csv')
print(df)
main()
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】、就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,查看下方👇🏻👇🏻