函数调用大家都很熟悉了,写代码的人每天都在各种调用,那这个函数调用怎么实现的呢,通过栈实现的,调用对应入栈,退出对应出栈,这也是为什么递归层次太深会造成栈溢出的错误。但并不是说只能用栈实现,只是正好栈的先入后出,后入先出的特性正好满足函数调用的特性。如果感兴趣的可以研究研究其他的方式。下面就介绍一下函数栈。
在了解函数栈之前,需要大家先了解栈的原理(可以从这里了解一下在c++中关于堆和堆栈的区别_qianyayun19921028的博客-CSDN博客_c++堆栈区别),函数的栈空间叫做栈帧,函数栈就是由一个一个的栈帧组成,下面介绍一下栈帧。
首先简化版栈帧长这样,栈地址从高到底。
CPU 计算时会把很多变量放在寄存器中,根据硬件体系的不同,寄存器数量和作用也不同。一般在 x86 32位中,寄存器 %esp 保存了栈指针的值,也就是栈顶,而 %ebp 作为当前栈帧的帧指针,也就是当前栈帧的底部,所以通过 %esp 和 %ebp 就可以知道当前栈帧的头跟尾。除了这两个寄存器,还有其它一些通用寄存器(%eax、%edx等),用于保存程序执行的临时值。
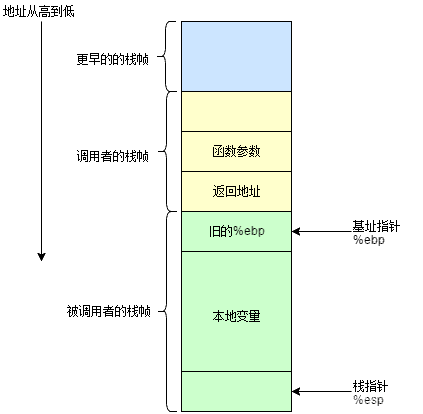
先来理论介绍:我们称调用函数A为caller,被调用函数B为callee,%esp何%ebp之间区域叫做栈,首先A的栈帧里面会存自己的临时变量、本地变量还有一些被保存的寄存器,在就是给B用的参数,在然后是返回地址(这里的是等B调用结束后,需要返回回来继续往下执行的地方)。关键是%esp和%ebp的转换,当函数B被调用的时候,B需要做两件事,1,将A的%ebp压入栈进行保存,此时%esp指向它,毕竟%ebp寄存器就一个,所以有新的函数入栈的时候就要先把老的保存起来,等到函数出栈在恢复。2、将%esp的值赋给%ebp,这时就成了B的栈底。这样我们就保存了A的%ebp,并且简历了一个新的栈帧。总结起来就是A负责把自己变量存起来,B要用的参数存起来,还有B返回时的地址。B负责把A的%ebp栈底存起来(方便待会回到A的时候通过存起来的地址网上取参数)。
函数实例:回头补充