1、Hive说明及安装准备
1.1、什么是Hive
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。
Hive由Facebook实现并开源。
1.2、为什么使用Hive
1、使用Hadoop MapReduce直接处理数据所面临的问题
- 人员学习成本太高 需要掌握java语言;
- MapReduce实现复杂查询逻辑开发难度太大;
2、使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免直接写MapReduce,减少开发人员的学习成本
- 支持自定义函数,功能扩展很方便
- 背靠Hadoop,擅长存储分析海量数据集
3、Hive和Hadoop关系
- 从功能来说,数据仓库软件,至少需要具备下述两种能力:
存储数据的能力、分析数据的能力
- Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
- 这样突然发现Hive没啥用,不过是套壳Hadoop罢了。其实不然,Hive的最大的魅力在于用户专注于编写HQL,
Hive帮您转换成为MapReduce程序完成对数据的分析。
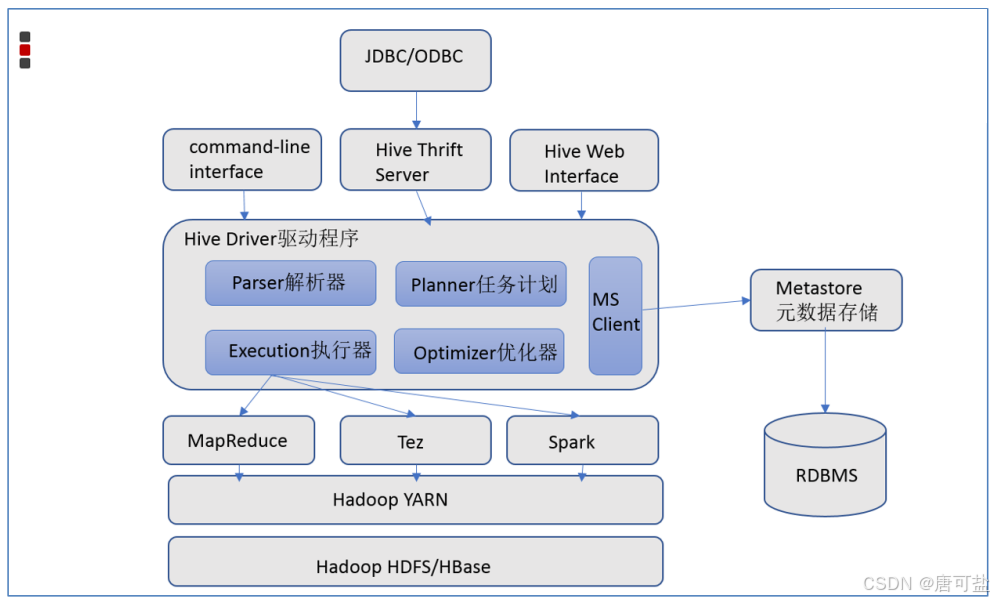
1.3、Hive架构图
1.4、安装包下载
上传Hive安装包apache-hive-2.3.3-bin.tar.gz到dss20 /opt/server目录下,或下载
cd /opt/server/
#下载
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz2、Hive安装
2.1、解压apache-hive-2.3.3-bin.tar.gz
#进入/opt/server
#cd /opt/server
#解压
tar zxvf apache-hive-2.3.3-bin.tar.gz
[root@dss20 server]# ll
总用量 226788
drwxr-xr-x. 10 root root 184 1月 12 14:12 apache-hive-2.3.3-bin
-rw-r--r--. 1 root root 232229830 1月 12 14:12 apache-hive-2.3.3-bin.tar.gz
drwxr-xr-x. 3 root root 26 1月 12 10:58 data
drwxr-xr-x. 10 10011 10011 161 1月 12 12:38 hadoop-2.7.22.2、 解决Hive与Hadoop之间guava版本差异
查看Hive的guava版本
cd /opt/server/hive-2.3.3/lib
ls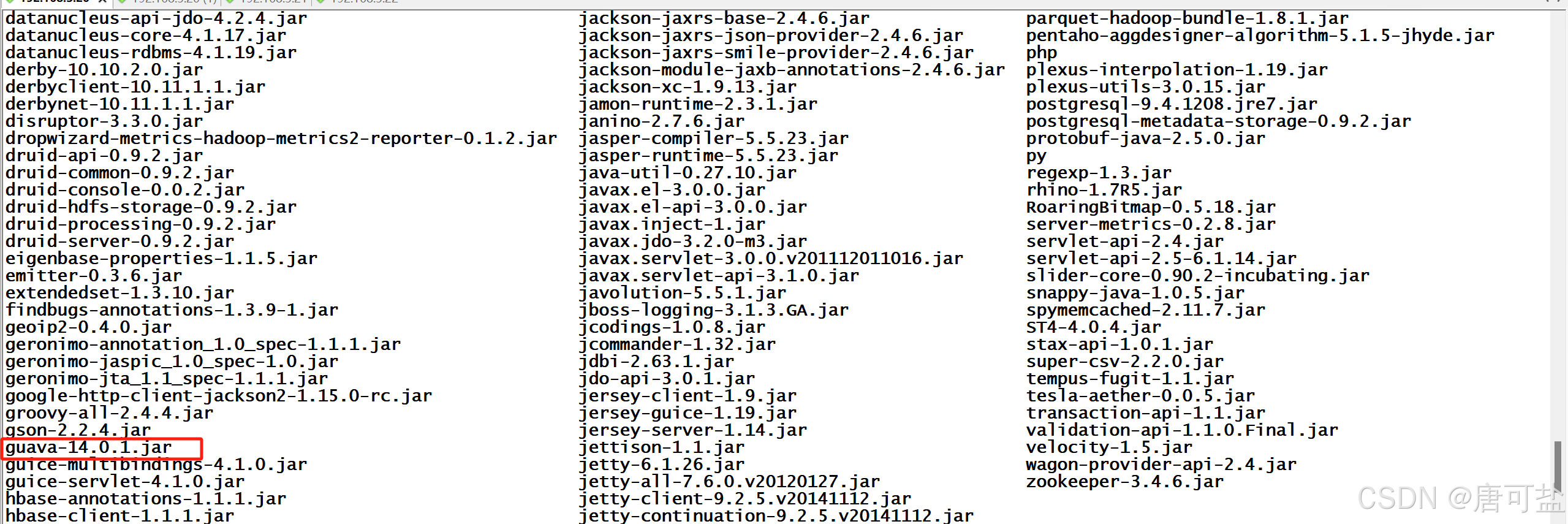
查看Hadoop的guava版本
cd /opt/server/hadoop-2.7.2/share/hadoop/common/lib
ls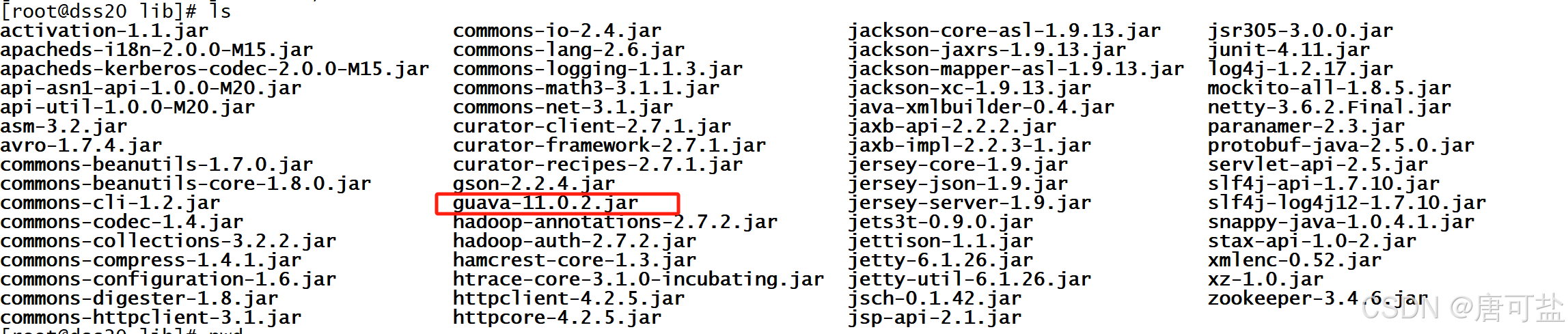
替换Hive中guava的jar包,如下:
cd /opt/server/hive-2.3.3/lib
#删除hive中的guava
rm -rf guava-14.0.1.jar
#复制Hadoop中的guava到Hive中
cp /opt/server/hadoop-2.7.2/share/hadoop/common/lib/guava-11.0.2.jar ../lib/
#查看
cd ..
ls
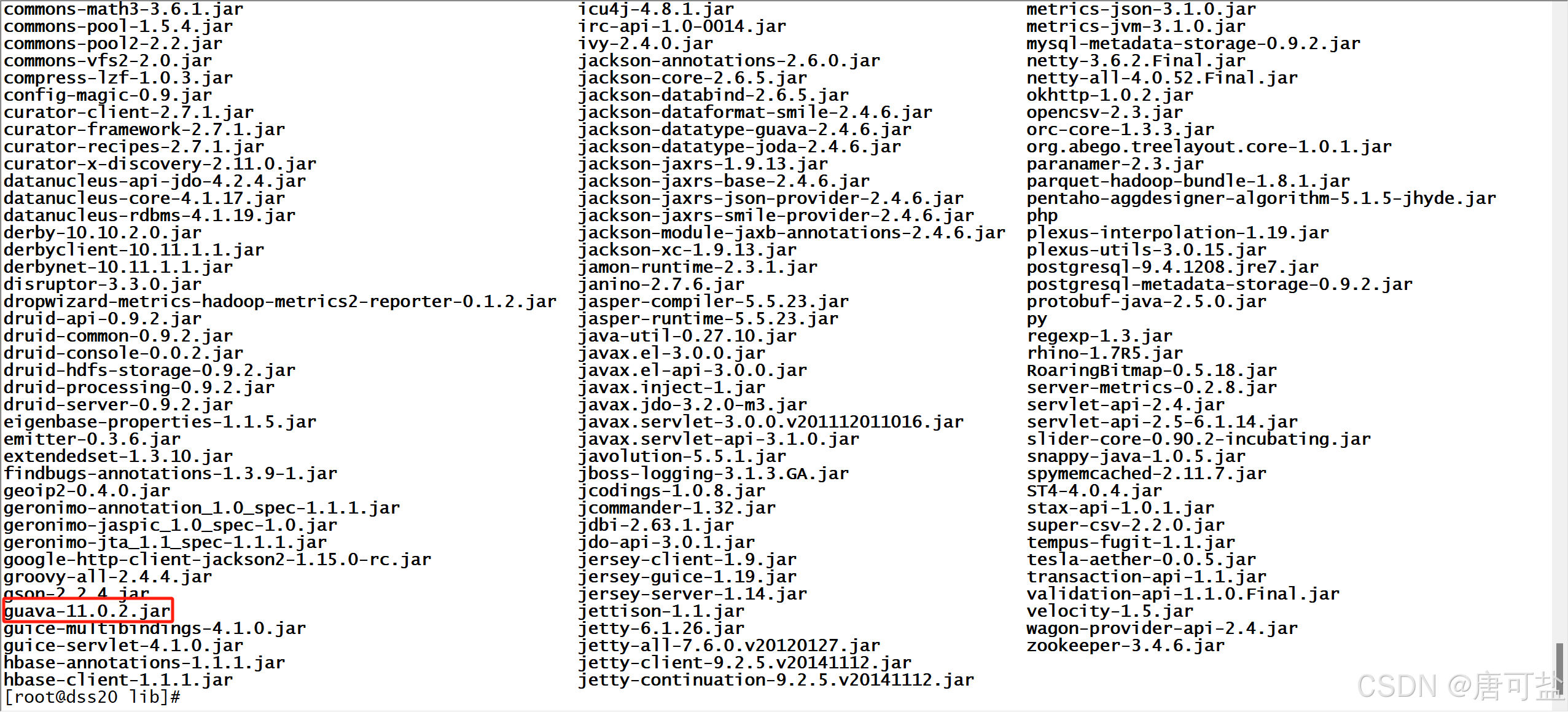
2.2、修改配置文件
1、hive-env.sh文件配置
cd /opt/server/hive-2.3.3/conf
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
#在最下方添加以下内容export HADOOP_HOME=/opt/server/hadoop-2.7.2
export HIVE_CONF_DIR=/opt/server/hive-2.3.3/conf
export HIVE_AUX_JARS_PATH=/opt/server/hive-2.3.3/conf/lib2、hive-site.xml文件配置
cd /opt/server/hive-2.3.3/conf
vim hive-site.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://dss20:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>dss20</value>
</property>
<!-- 远程模式部署metastore metastore地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://dss20:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>2.3、上传mysql jdbc驱动到hive安装包lib下
#上传mysql-connector-java-5.1.32.jar至/opt/server/hive-2.3.3/lib
#进入/opt/server/hive-2.3.3/lib目录
cd /opt/server/hive-2.3.3/lib
#查看
ls或下载mysql jdbc驱动hive安装包lib下:
cd /soft
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.49.tar.gz
tar xvf mysql-connector-java-5.1.49.tar.gz
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar /opt/server/hive-2.3.3/lib/
2.4、初始化元数据
cd /opt/server/hive-2.3.3
#初始化成功会在mysql中创建74张表
bin/schematool -dbType mysql -initSchema
2.5、在hdfs创建hive存储目录
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
3、启动hive
3.1、启动metastore服务
1、前台启动并开启debug日志
[root@dss20 lib]# /opt/server/hive-2.3.3/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console
2025-01-12 15:57:30: Starting Hive Metastore Server
2、进程挂起 关闭使用jps+ kill -9
[root@dss20 lib]# jps
5056 DataNode
4913 NameNode
5315 ResourceManager
5416 NodeManager
12348 RunJar
13039 Jps
[root@dss20 lib]# kill -9 123483.2、验证安装
hive -e "show databases"