1、该Spark版本说明
1、依赖关系
- 该版本不包含Hadoop的依赖库。
- 适用于那些不直接需要Hadoop集群或者已经通过其他方式管理Hadoop依赖的用户。
- 用户可以在不依赖Hadoop的环境中运行Spark,或者如果已有一个Hadoop环境但希望使用Spark自带的Hadoop客户端库,也可以选择这个版本。
2、运行环境与配置
- 由于不包含Hadoop依赖,用户需要自行配置其他分布式文件系统(如Amazon S3、Alluxio等)或已存在的Hadoop环境(如果使用Spark自带的Hadoop客户端库)。
- 配置时可能需要设置额外的环境变量和配置文件,以确保Spark能够正确访问和使用其他存储系统。
3、使用场景与优势
- 适用于那些希望在不依赖Hadoop的环境中运行Spark的用户。
- 提供了更灵活的选择,允许用户根据自己的需求选择其他分布式文件系统或存储解决方案。
- 可能有助于降低对Hadoop生态系统的依赖,从而降低运维成本和复杂性。
2、Spark安装配置
2.1、安装包下载
上传spark-2.4.3-bin-without-hadoop.tgz至/opt目录下,或下载
cd /opt/
#下载
wget https://archive.apache.org/dist/spark/spark-2.4.3/spark-2.4.3-bin-without-hadoop.tgz2.2、解压spark-2.4.3-bin-without-hadoop.tgz
cd /opt/
tar xvf spark-2.4.3-bin-without-hadoop.tgz
sudo mv spark-2.4.3-bin-without-hadoop spark-2.4.3
2.3、配置spark环境变量以及备份配置文件
cd /opt/spark-2.4.3/conf
cp spark-env.sh.template spark-env.sh
cp spark-defaults.conf.template spark-defaults.conf
cp metrics.properties.template metrics.properties1、配置环境变量,/etc/profile文件配置
vi /etc/profile
#添加以下内容
export SPARK_HOME=/opt/spark-2.4.3
export PATH=$PATH:$SPARK_HOME/bin
#生效
source /etc/profile2、spark-env.sh文件配置
vim spark-env.sh
#在下面增加以下内容export JAVA_HOME=/opt/jdk1.8
export HADOOP_HOME=/opt/server/hadoop-2.7.2
export HADOOP_CONF_DIR=/opt/server/hadoop-2.7.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/server/hadoop-2.7.2/bin/hadoop classpath)
export SPARK_MASTER_HOST=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://127.0.0.1:9000/spark-eventlog"3、修改默认的配置文件
vim spark-defaults.conf
#在下面增加以下内容spark.master spark://dss20:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://dss20:9000/spark-eventlog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 3g
spark.eventLog.enabled true
spark.eventLog.dir hdfs://dss20:9000/spark-eventlog
spark.eventLog.compress true4、配置工作节点
vi workers
#添加以下内容
dss205、配置hive
cp /opt/server/hive-2.3.3/conf/hive-site.xml /opt/spark-2.4.3/conf6、验证应用程序
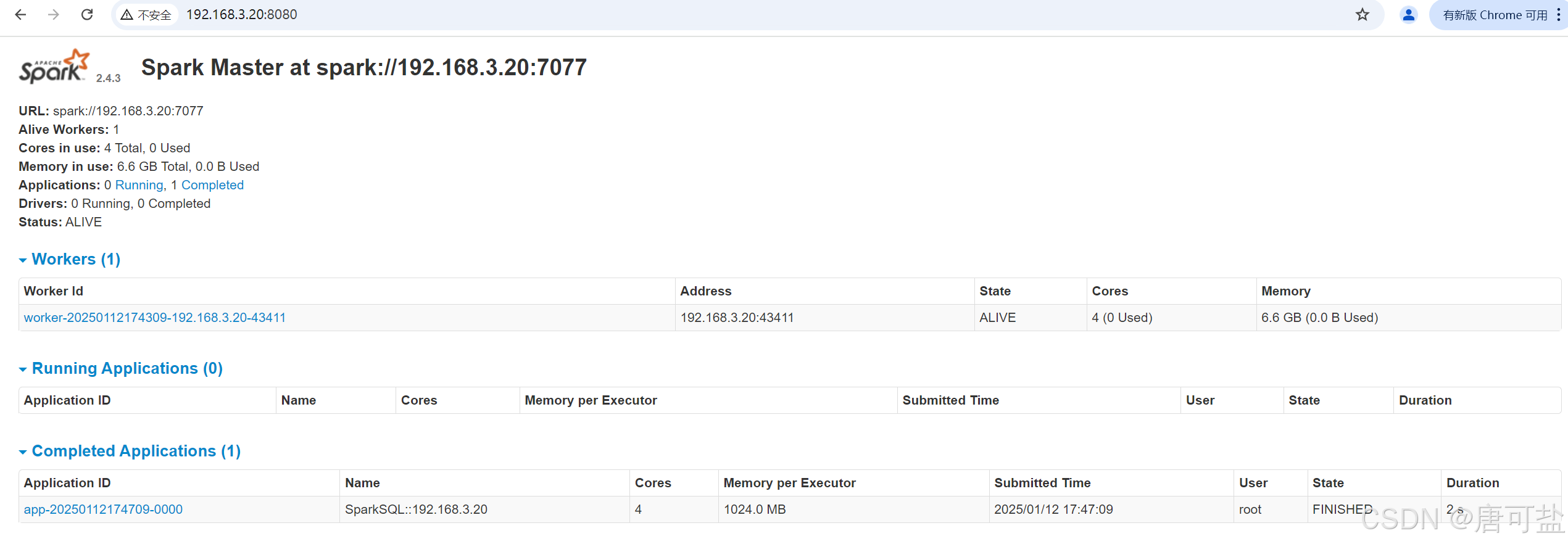
/opt/spark-2.4.3/sbin/start-all.sh7、验证安装
/opt/spark-2.4.3/bin/spark-sql -e "show databases"
访问spark的默认端口号为8080