前言
随着互联网的发展,前端开发也变的越来越复杂,从一开始的表单验证到现在动不动上千上万行代码的项目开发,团队协作就是我们不可避免的工作方式,为了更好地管理功能逻辑,模块化的概念也就渐渐产生了。
好的书籍????会分章节,好的代码得分模块。
JavaScript 在早期的设计中就没有模块、包甚至类的概念,虽然 ES6 中有了 class 关键字,那也只是个语法糖。随意随着项目复杂度的增加,开发者必然需要模拟类的功能,来隔离、封装、组织复杂的 JavaScript 代码,而这种封装和隔离,也被被我们称之为模块化。
模块就是一个实现特定功能的文件 or 代码块。随着前端工程体系建设的愈发成熟,或许模块化的概念已经在前端圈子里已经耳熟能详了。
但是对于很多开发者而言,ES6 中的 export、import,nodejs 中的 require、exports.xx、module.exports到底有什么区别?为什么又有 CommonJS,又有 AMD,CMD,UMD?区别是什么?甚至我们在编写 ts 文件的时候,还需要在配置文件里面说明什么模块方式,在项目中使用的时候,我们又是否真正知道,你用的到底是基于哪一种规范的模块化?
本文对你写代码没有一点帮助,但是如果你还对上述的问题存有疑惑或者想了解JavaScript 模块化的前世古今,那么我们开始吧~
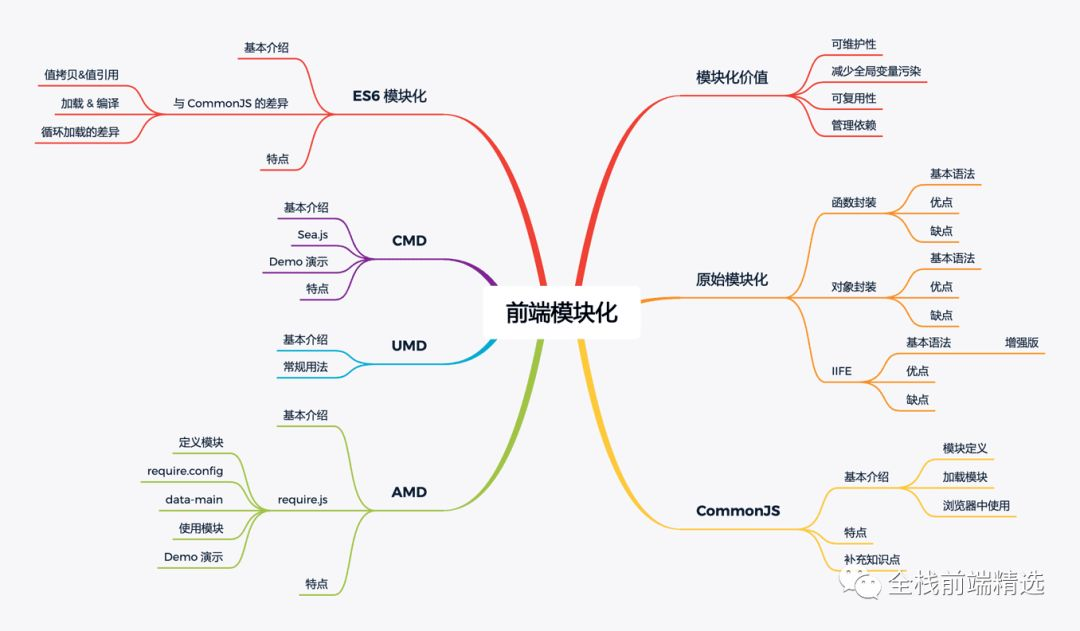
模块化的价值
所谓的模块化,粗俗的讲,就是把一大坨代码,一铲一铲分成一个个小小坨。当然,这种分割也必须是合理的,以便于你增减或者修改功能,并且不会影响整体系统的稳定性。
个人认为模块化具有以下几个好处:
可维护性,每一个模块都是独立的。良好的设计能够极大的降低项目的耦合度。以便于其能独立于别的功能被整改。至少维护一个独立的功能模块,比维护一坨凌乱的代码要容易很多。
减少全局变量污染,前端开发的初期,我们都在为全局变量而头疼,因为经常会触发一些难以排查且非技术性的 bug。当一些无关的代码一不小心重名了全局变量,我们就会遇到烦人的“命名空间污染”的问题。在模块化规范没有确定之前,其实我们都在极力的避免于此。(后文会介绍)
可复用性,前端模块功能的封装,极大的提高了代码的可复用性。这点应该就不用详细说明了。想想从 npm 上找 package 的时候,是在干啥?
方便管理依赖关系,在模块化规范没有完全确定的时候,模块之间相互依赖的关系非常的模糊,完全取决于 js 文件引入的顺序。粗俗!丝毫没有技术含量,不仅依赖模糊且难以维护。
原始模块化
对于某一工程作业或者行为进行定性的信息规定。主要是因为无法精准定量而形成的标准,所以,被称为规范。在模块化还没有规范确定的时候,我们都称之为原始模块化。
函数封装
回到我们刚刚说的模块的定义,模块就是一个实现特定功能的文件 or 代码块(这是我自己给定义的)。专业定义是,在程序设计中,为完成某一功能所需的一段程序或子程序;或指能由编译程序、装配程序等处理的独立程序单位;或指大型软件系统的一部分。而函数的一个功能就是实现特定逻辑的一组语句打包。并且 JavaScript 的作用域就是基于函数的。所以最原始之处,函数必然是作为模块化的第一步。
基本语法
//函数1 function fn1(){ //statement } //函数2 function fn2(){ //statement }
优点
有一定的功能隔离和封装
缺点
污染了全局变量
模块之间的关系模糊
对象封装
其实就是把变量名塞的深一点。。。

基本语法
let module1 = { let tag : 1, let name:'module1', fun1(){ console.log('this is fun1') }, fun2(){ console.log('this is fun2') } }
我们在使用的时候呢,就直接
`module1.fun2();`
优点
一定程度上优化了命名冲突,降低了全局变量污染的风险
有一定的模块封装和隔离,并且还可以进一步语义化一些
缺点
并没有实质上改变命名冲突的问题
外部可以随意修改内部成员变量,还是容易产生意外风险
IIFE
IIFE 就是立即执行函数,我们可以通过匿名闭包的形式来实现模块化
基本语法
let global = 'Hello, I am a global variable :)'; (function () { // 在函数的作用域中下面的变量是私有的 const myGrades = [93, 95, 88, 0, 55, 91]; let average = function() { let total = myGrades.reduce(function(accumulator, item) { return accumulator + item}, 0); return'Your average grade is ' + total / myGrades.length + '.'; } let failing = function(){ let failingGrades = myGrades.filter(function(item) { return item < 70;}); return'You failed ' + failingGrades.length + ' times.'; } console.log(failing()); console.log(global); }()); // 控制台显示:'You failed 2 times.' // 控制台显示:'Hello, I am a global variable :)'
这种方法的好处在于,你可以在函数内部使用局部变量,而不会意外覆盖同名全局变量,但仍然能够访问到全局变量
类似如上的 IIFE ,还有非常多的演进写法
比如引入依赖:
// module.js文件 (function(window, $) { let data = 'www.baidu.com' //操作数据的函数 function foo() { //用于暴露有函数 console.log(`foo() ${data}`) $('body').css('background', 'red') } function bar() { //用于暴露有函数 console.log(`bar() ${data}`) otherFun() //内部调用 } function otherFun() { //内部私有的函数 console.log('otherFun()') } //暴露行为 window.myModule = { foo, bar } })(window, jQuery)
// index.html文件 <!-- 引入的js必须有一定顺序 --> <script type="text/javascript" src="jquery-1.10.1.js"></script> <script type="text/javascript" src="module.js"></script> <script type="text/javascript"> myModule.foo() </script>
还有一种所谓的揭示模块模式 Revealing module pattern
var myGradesCalculate = (function () { // 在函数的作用域中下面的变量是私有的 var myGrades = [93, 95, 88, 0, 55, 91]; var average = function() { var total = myGrades.reduce(function(accumulator, item) { return accumulator + item; }, 0); return'Your average grade is ' + total / myGrades.length + '.'; }; var failing = function() { var failingGrades = myGrades.filter(function(item) { return item < 70; }); return'You failed ' + failingGrades.length + ' times.'; }; // 将公有指针指向私有方法 return { average: average, failing: failing } })(); myGradesCalculate.failing(); // 'You failed 2 times.' myGradesCalculate.average(); // 'Your average grade is 70.33333333333333.'
这和我们之前的实现方法非常相近,除了它会确保,在所有的变量和方法暴露之前都会保持私有.
优点
实现了基本的封装
只暴露对外的方法操作,有了 public 和 private 的概念
缺点
模块依赖关系模糊
CommonJS
上述的所有解决方案都有一个共同点:使用单个全局变量来把所有的代码包含在一个函数内,由此来创建私有的命名空间和闭包作用域。
虽然每种方法都比较有效,但也都有各自的短板。
随着大前端时代的到来,常见的 JavaScript 模块规范也就有了:CommonJS、AMD、CMD、UMD、ES6 原生。
基本介绍
CommonJS 是 JavaScript 的一个模块化规范,主要用于服务端Nodejs 中,当然,通过转换打包,也可以运行在浏览器端。毕竟服务端加载的模块都是存放于本地磁盘中,所以加载起来比较快,不需要考虑异步方式。
根据规范,每一个文件既是一个模块,其内部定义的变量是属于这个模块的,不会污染全局变量。
CommonJS 的核心思想是通过 require 方法来同步加载所依赖的模块,然后通过 exports 或者 module.exprots 来导出对外暴露的接口。
模块定义
CommonJS 的规范说明,一个单独的文件就是一个模块,也就是一个单独的作用域。并且模块只有一个出口,module.exports/exports.xxx
// lib/math.js const NAME='Nealayng'; module.exports.author = NAME; module.exports.add = (a,b)=> a+b;
加载模块
加载模块使用 require 方法,该方法读取文件并且执行,返回文件中 module.exports 对象
// main.js const mathLib = require('./lib/math'); console.log(mathLib.author);//Nealyang console.log(mathLib.add(1,2));// 3
在浏览器中使用 CommonJS
由于浏览器不支持 CommonJS 规范,因为其根本没有 module、exports、require 等变量,如果要使用,则必须转换格式。Browserify是目前最常用的CommonJS格式转换的工具,我们可以通过安装browserify来对其进行转换.但是我们仍然需要注意,由于 CommonJS 的规范是阻塞式加载,并且模块文件存放在服务器端,可能会出现假死的等待状态。
`npm i browserify -g`
然后使用如下命令
`browserify main.js -o js/bundle/main.js`
然后在 HTML 中引入使用即可。
有一说一,在浏览器中使用 CommonJS 的规范去加载模块,真的不是很方便。如果一定要使用,我们可以使用browserify编译打包,也可以使用require1k,直接在浏览器上运行即可。
特点
以文件为一个单元模块,代码运行在模块作用域内,不会污染全局变量
同步加载模块,在服务端直接读取本地磁盘没问题,不太适用于浏览器
模块可以加载多次,但是只会在第一次加载时运行,然后在加载,就是读取的缓存文件。需清理缓存后才可再次读取文件内容
模块加载的顺序,按照其在代码中出现的顺序
导出的是值的拷贝,这一点和 ES6 有着很大的不同(后面会介绍到)
补充知识点
其实在 nodejs 中模块的实现并非完全按照 CommonJS 的规范来的,而是进行了取舍。
Node 中,一个文件是一个模块->module
源码定义如下:
function Module(id = '', parent) { this.id = id; this.path = path.dirname(id); this.exports = {}; this.parent = parent; updateChildren(parent, this, false); this.filename = null; this.loaded = false; this.children = []; }
//实例化一个模块 varmodule = new Module(filename, parent);
CommonJS 的一个模块,就是一个脚本文件。require命令第一次加载该脚本,就会执行整个脚本,然后在内存生成一个对象。
{ id: '...', exports: { ... }, loaded: true, ... }
上面代码就是 Node 内部加载模块后生成的一个对象。该对象的id属性是模块名,exports属性是模块输出的各个接口,loaded属性是一个布尔值,表示该模块的脚本是否执行完毕。其他还有很多属性,这里都省略不介绍了。
以后需要用到这个模块的时候,就会到exports属性上面取值。即使再次执行require命令,也不会再次执行该模块,而是到缓存之中取值。也就是说,CommonJS 模块无论加载多少次,都只会在第一次加载时运行一次,以后再加载,就返回第一次运行的结果,除非手动清除系统缓存。
AMD
Asynchronous Module Definition:异步模块定义。
也就是解决我们上面说的 CommonJS 在浏览器端致命的问题:假死。
介绍
CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。AMD规范则是异步加载模块,允许指定回调函数。
由于其并非原生 js 所支持的那种写法。所以使用 AMD 规范开发的时候就需要大名鼎鼎的函数库 require.js 的支持了。
require.js
https://github.com/requirejs/requirejs
require.js 主要解决两个问题:
异步加载模块
模块之间依赖模糊
定义模块
`define(id,[dependence],callback)`
id,一个可选参数,说白了就是给模块取个名字,但是却是模块的唯一标识。如果没有提供则取脚本的文件名
dependence,以来的模块数组
callback,工厂方法,模块初始化的一些操作。如果是函数,应该只被执行一次。如果是对象,则为模块的输出值
使用模块
`require([moduleName],callback);`
moduleName,依赖的模块数组
callback,即为依赖模块加载成功之后执行的回调函数(前端异步的通用解决方案)
data-main
`<script src="scripts/require.js" data-main="scripts/app.js"></script>`
data-main 指定入口文件,比如这里指定 scripts 下的 app.js 文件,那么只有直接或者间接与app.js有依赖关系的模块才会被插入到html中。
require.config
通过这个函数可以对requirejs进行灵活的配置,其参数为一个配置对象,配置项及含义如下:
baseUrl——用于加载模块的根路径。
paths——用于映射不存在根路径下面的模块路径。
shims——配置在脚本/模块外面并没有使用RequireJS的函数依赖并且初始化函数。假设underscore并没有使用 RequireJS定义,但是你还是想通过RequireJS来使用它,那么你就需要在配置中把它定义为一个shim
deps——加载依赖关系数组
require.config({ //默认情况下从这个文件开始拉去取资源 baseUrl:'scripts/app', //如果你的依赖模块以pb头,会从scripts/pb加载模块。 paths:{ pb:'../pb' }, // load backbone as a shim,所谓就是将没有采用requirejs方式定义 //模块的东西转变为requirejs模块 shim:{ 'backbone':{ deps:['underscore'], exports:'Backbone' } } });
Demo 演示
创建项目
|-js |-libs |-require.js |-modules |-article.js |-user.js |-main.js |-index.html
定义模块
// user.js文件 // 定义没有依赖的模块 define(function() { let author = 'Nealyang' function getAuthor() { return author.toUpperCase() } return { getAuthor } // 暴露模块 })
//article.js文件 // 定义有依赖的模块 define(['user'], function(user) { let name = 'THE LAST TIME' function consoleMsg() { console.log(`${name} by ${user.getAuthor()}`); } // 暴露模块 return { consoleMsg } })
// main.js (function() { require.config({ baseUrl: 'js/', //基本路径 出发点在根目录下 paths: { //映射: 模块标识名: 路径 article: './modules/article', //此处不能写成article.js,会报错 user: './modules/user' } }) require(['article'], function(alerter) { article.consoleMsg() }) })()
// index.html文件 <!DOCTYPE html> <html> <head> <title>Modular Demo</title> </head> <body> <!-- 引入require.js并指定js主文件的入口 --> <script data-main="js/main" src="js/libs/require.js"></script> </body> </html>
如果我们需要引入第三方库,则需要在 main.js 文件中引入
(function() { require.config({ baseUrl: 'js/', paths: { article: './modules/article', user: './modules/user', // 第三方库模块 jquery: './libs/jquery-1.10.1'//注意:写成jQuery会报错 } }) require(['article'], function(alerter) { article.consoleMsg() }) })()
特点
异步加载模块,不会造成因网络问题而出现的假死装填
显式地列出其依赖关系,并以函数(定义此模块的那个函数)参数的形式将这些依赖进行注入
在模块开始时,加载所有所需依赖
CMD
基本介绍
CMD是阿里的玉伯提出来的,js 的函数为 sea.js,它和 AMD 其实非常的相似,文件即为模块,但是其最主要的区别是实现了按需加载。推崇依赖就近的原则,模块延迟执行,而 AMD 所依赖模块式提前执行(requireJS 2.0 后也改为了延迟执行)
//AMD define(['./a','./b'], function (a, b) { //依赖一开始就写好 a.test(); b.test(); }); //CMD define(function (requie, exports, module) { //依赖可以就近书写 var a = require('./a'); a.test(); ... //按需加载 if (status) { var b = requie('./b'); b.test(); } });
SeaJs
https://github.com/seajs/seajs

准确的说 CMD 是 SeaJS 在推广过程中对模块定义的规范化产物。
也可以说SeaJS 是一个遵循 CMD 规范的 JavaScript 模块加载框架,可以实现 JavaScript 的 CMD 模块化开发方式。
SeaJS 只是实现 JavaScript的模块化和按需加载,并未扩展 JavaScript 语言本身。SeaJS 的主要目的是让开发人员更加专注于代码本身,从繁重的 JavaScript 文件以及对象依赖处理中解放出来。
Seajs 追求简单、自然的代码书写和组织方式,具有如下核心特性:
简单友好的模块定义规范:Sea.js 遵循 CMD 规范,可以像 Node.js 一般书写模块代码。
自然直观的代码组织方式:依赖的自动加载、配置的简洁清晰,可以让我们更多地享受编码的乐趣。
Sea.js 还提供常用插件,非常有助于开发调试和性能优化,并具有丰富的可扩展接口。
Demo 演示
examples/ |-- sea-modules 存放 seajs、jquery 等文件,这也是模块的部署目录 |-- static 存放各个项目的 js、css 文件 | |-- hello | |-- lucky | `-- todo `-- app 存放 html 等文件 |-- hello.html |-- lucky.html `-- todo.html
我们从 hello.html 入手,来瞧瞧使用 Sea.js 如何组织代码。
在 hello.html 页尾,通过 script 引入 sea.js 后,有一段配置代码
// seajs 的简单配置 seajs.config({ base: "../sea-modules/", alias: { "jquery": "jquery/jquery/1.10.1/jquery.js" } }) // 加载入口模块 seajs.use("../static/hello/src/main")
sea.js 在下载完成后,会自动加载入口模块。页面中的代码就这么简单。
这个小游戏有两个模块 spinning.js 和 main.js,遵循统一的写法:
// 所有模块都通过 define 来定义 define(function(require, exports, module) { // 通过 require 引入依赖 var $ = require('jquery'); var Spinning = require('./spinning'); // 通过 exports 对外提供接口 exports.doSomething = ... // 或者通过 module.exports 提供整个接口 module.exports = ... });
上面就是 Sea.js 推荐的 CMD 模块书写格式。如果你有使用过 Node.js,一切都很自然。
以上实例,来源于官网 Example。更多 Demo 查看:https://github.com/seajs/examples
特点
相对自然的依赖声明风格,且社区不错
文件即模块
模块按需加载。
推崇依赖就近的原则,模块延迟执行
UMD
UMD 其实我个人还是觉得非常。。。。不喜欢的。ifElse 就 universal 了。。。。

基本介绍
UMD 是 AMD 和 CommonJS 的综合产物。如上所说,AMD 的用武之地是浏览器,非阻塞式加载。CommonJS 主要用于服务端 Nodejs 中使用。所以人们就想到了一个通用的模式 UMD(universal module definition)。来解决跨平台的问题。
没错!就是 ifElse 的写法。
核心思想就是:先判断是否支持Node.js的模块(exports)是否存在,存在则使用Node.js模块模式。
在判断是否支持AMD(define是否存在),存在则使用AMD方式加载模块。
常规用法
(function (window, factory) { if (typeof exports === 'object') { module.exports = factory(); } elseif (typeof define === 'function' && define.amd) { define(factory); } else { window.eventUtil = factory(); } })(this, function () { //module ... });
关于 UMD 更多的example 可移步github:https://github.com/umdjs/umd
ES6
如果你一直读到现在,那么恭喜你,我们开始介绍我们最新的模块化了!
通过上面的介绍我们知道,要么模块化依赖环境,要么需要引入额外的类库。说到底就是社区找到的一种妥协方案然后得到了大家的认可。但是归根结底不是官方呀。终于,ECMAScript 官宣了模块化的支持,真正的规范。
基本介绍
在ES6中,我们可以使用 import 关键字引入模块,通过 export 关键字导出模块,功能较之于前几个方案更为强大,也是我们所推崇的,但是由于ES6目前无法在所有浏览器中执行,所以,我们还需通过babel将不被支持的import编译为当前受到广泛支持的 require。
ES6 的模块化汲取了 CommonJS 和AMD 的优点,拥有简洁的语法和异步的支持。并且写法也和 CommonJS 非常的相似。
关于 ES6 模块的基本用法相比大家都比较熟悉了。这里我们主要和 CommonJS 对比学习。
与 CommonJS 的差异
两大差异:
CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
值拷贝&值引用
// lib/counter.js var counter = 1; function increment() { counter++; } function decrement() { counter--; } module.exports = { counter: counter, increment: increment, decrement: decrement }; // src/main.js var counter = require('../../lib/counter'); counter.increment(); console.log(counter.counter); // 1
在 main.js 当中的实例是和原本模块完全不相干的。这也就解释了为什么调用了 counter.increment() 之后仍然返回1。因为我们引入的 counter 变量和模块里的是两个不同的实例。
所以调用 counter.increment() 方法只会改变模块中的 counter .想要修改引入的 counter 只有手动一下啦:
counter.counter++; console.log(counter.counter); // 2
而通过 import 语句,可以引入实时只读的模块:
// lib/counter.js exportlet counter = 1; exportfunction increment() { counter++; } exportfunction decrement() { counter--; } // src/main.js import * as counter from'../../counter'; console.log(counter.counter); // 1 counter.increment(); console.log(counter.counter); // 2
加载 & 编译
因为 CommonJS 加载的是一个对象(module.exports),对象只有在有脚本运行的时候才能生成。而 ES6 模块不是一个对象,只是一个静态的定义。在代码解析阶段就会生成。
ES6 模块是编译时输出接口,因此有如下2个特点:
import 命令会被 JS 引擎静态分析,优先于模块内的其他内容执行
export 命令会有变量声明提升的效果,所以import 和 export 命令在模块中的位置并不影响程序的输出。
// a.js console.log('a.js') import { foo } from'./b'; // b.js exportlet foo = 1; console.log('b.js 先执行'); // 执行结果: // b.js 先执行 // a.js
// a.js import { foo } from'./b'; console.log('a.js'); exportconst bar = 1; exportconst bar2 = () => { console.log('bar2'); } exportfunction bar3() { console.log('bar3'); } // b.js exportlet foo = 1; import * as a from'./a'; console.log(a); // 执行结果: // { bar: undefined, bar2: undefined, bar3: [Function: bar3] } // a.js
循环加载的差异
“循环加载”(circular dependency)指的是,a脚本的执行依赖b脚本,而b脚本的执行又依赖a脚本。
// a.js var b = require('b'); // b.js var a = require('a');
循环加载如果处理不好,还可能导致递归加载,使得程序无法执行,因此应该避免出现。
在 CommonJS 中,脚本代码在 require 的时候,就会全部执行。一旦出现某个模块被"循环加载",就只输出已经执行的部分,还未执行的部分不会输出。
// a.js exports.done = false; var b = require('./b.js'); console.log('在 a.js 之中,b.done = %j', b.done); exports.done = true; console.log('a.js 执行完毕');
// b.js exports.done = false; var a = require('./a.js'); console.log('在 b.js 之中,a.done = %j', a.done); exports.done = true; console.log('b.js 执行完毕');
// main.js var a = require('./a.js'); var b = require('./b.js'); console.log('在 main.js 之中, a.done=%j, b.done=%j', a.done, b.done);
输出结果为:
在 b.js 之中,a.done = false b.js 执行完毕 在 a.js 之中,b.done = true a.js 执行完毕 在 main.js 之中, a.done=true, b.done=true
从上面我们可以看出:
在b.js之中,a.js没有执行完毕,只执行了第一行。
main.js执行到第二行时,不会再次执行b.js,而是输出缓存的b.js的执行结果,即它的第四行
ES6 处理“循环加载”与 CommonJS 有本质的不同。ES6 模块是动态引用,如果使用import从一个模块加载变量(即import foo from 'foo'),那些变量不会被缓存,而是成为一个指向被加载模块的引用,需要开发者自己保证,真正取值的时候能够取到值。
// a.mjs import {bar} from'./b'; console.log('a.mjs'); console.log(bar); exportlet foo = 'foo'; // b.mjs import {foo} from'./a'; console.log('b.mjs'); console.log(foo); exportlet bar = 'bar';
运行结果如下:
b.mjs ReferenceError: foo is not defined
上面代码中,执行a.mjs以后会报错,foo变量未定义.
具体的执行结果如下:
执行a.mjs以后,引擎发现它加载了b.mjs,因此会优先执行b.mjs,然后再执行a.mjs
执行b.mjs的时候,已知它从a.mjs输入了foo接口,这时不会去执行a.mjs,而是认为这个接口已经存在了,继续往下执行。
执行到第三行console.log(foo)的时候,才发现这个接口根本没定义,因此报错。
解决这个问题的方法,就是让b.mjs运行的时候,foo已经有定义了。这可以通过将foo写成函数来解决。
// a.mjs import {bar} from'./b'; console.log('a.mjs'); console.log(bar()); function foo() { return'foo' } export {foo}; // b.mjs import {foo} from'./a'; console.log('b.mjs'); console.log(foo()); function bar() { return'bar' } export {bar};
最后执行结果为:
b.mjs foo a.mjs bar
特点
每一个模块加载多次, JS只执行一次, 如果下次再去加载同目录下同文件,直接从内存中读取。一个模块就是一个单例,或者说就是一个对象
代码是在模块作用域之中运行,而不是在全局作用域运行。模块内部的顶层变量,外部不可见。不会污染全局作用域;
模块脚本自动采用严格模式,不管有没有声明use strict
模块之中,可以使用import命令加载其他模块(.js后缀不可省略,需要提供绝对 URL 或相对 URL),也可以使用export命令输出对外接口
模块之中,顶层的this关键字返回undefined,而不是指向window。也就是说,在模块顶层使用this关键字,是无意义的
参考文献
阮一峰 ES6
前端模块化详解(完整版)
理解CommonJS、AMD、CMD三种规范
前端模块化开发那点历史
JavaScript 模块化入门Ⅰ:理解模块
前端模块化开发的价值
关于奇舞周刊
《奇舞周刊》是360公司专业前端团队「奇舞团」运营的前端技术社区。关注公众号后,直接发送链接到后台即可给我们投稿。
