实验目的
(1)、掌握计算机操作系统管理进程、处理机、存储器、文件系统的基本方法。
(2)、了解现代计算机操作系统的工作原理,具有初步分析、设计操作系统的能力。
(3)、通过阅读xv6操作系统代码,理解其是如何实现操作系统中的各种管理功能,在系统程序设计能力方面得到提升。
实验要求
(1)、阅读Chapter1 Operating system interfaces,回答以下问题:
a)user/sh.c (L168-169).
if(fork1() == 0)
为什么fork1()返回值为0时才进入if语句内部?
runcmd(parsecmd(buf));
阅读runcmd的代码,其中:
$echo README对应的cmd->type是哪个?
相应的,$ls; echo “hello world“ 对应的cmd->type是哪个?
而ls | wc 对应的cmd->type是哪个?给出你的答案,并从代码中给出解释。
b)阅读user/sh.c (L83)对应的switch分支及相关代码,请说明这个输出重定向命令
$ls > test.txt
如何确保test.txt接收ls命令的输出呢?
c)user/sh.c (L101-123):
第二、三个if语句中,管道的读端口和写端口都通过close语句关闭了,请问还怎么保证pcmd->left的输出进入管道的写端口,而pcmd->right的输入进入管道的读端口?
为什么在父进程这里,还需要有两个close语句?以及两个wait语句?
(2)、阅读Chapter2 Operating system organization,回答以下问题:
a)请上网查找资料,解释在RISC-V平台上,CPU的hartid代表什么。
当$make CPUS=1 qemu-gdb时,qemu只虚拟了一个CPU。请问为何这个CPU的hartid一定是0?
(3)、阅读Chapter 7 Scheduling,回答以下问题:
a)试解释一下yield函数、scheduler函数和sched函数的用途。
b)结合书本,确定xv6使用的是哪种调度算法。给出你的理由(通过分析代码证明你的观点)。
c)(kernel/proc.c:455) 有一个疑问,似乎每次xv6都是从进程表开头开始查找Runnable的进程。如果刚从CPU切换下来的进程恰好是进程表的第一个PCB,会不会调度器永远都选择它进行调度?
(4)、阅读Chapter3 Page tables,回答以下问题:
a)请阅读walk函数(kernel/vm.c:86),计算理论上一个进程页表所支持的最大虚拟地址空间。
b)kernel/kalloc.c (内存分配)
阅读kinit2、freerange、kfree、kalloc四个函数。
kmem中的freelist指针指向空闲物理块链表。空闲物理块链表中的节点为run结构体。但是可以看到这个结构体只有指向下一个节点的指针。请解释这个链表中的空闲物理块保存在哪里呢?
(5)、阅读Chapter6 Locking,回答以下问题:
a)阅读7.3 Code: Scheduling,请回答在调度器和被调度的进程之间,如何确保p->lock的锁定(acquire)和释放(release)能够两两配对?
实验内容
(1)、阅读Chapter1 Operating system interfaces,回答以下问题:
a)user/sh.c (L168-169).
if(fork1() == 0)
为什么fork1()返回值为0时才进入if语句内部?
runcmd(parsecmd(buf));
首先观察fork1函数,可以看出它调用fork函数创建新进程后判断该进程pid是否为-1。
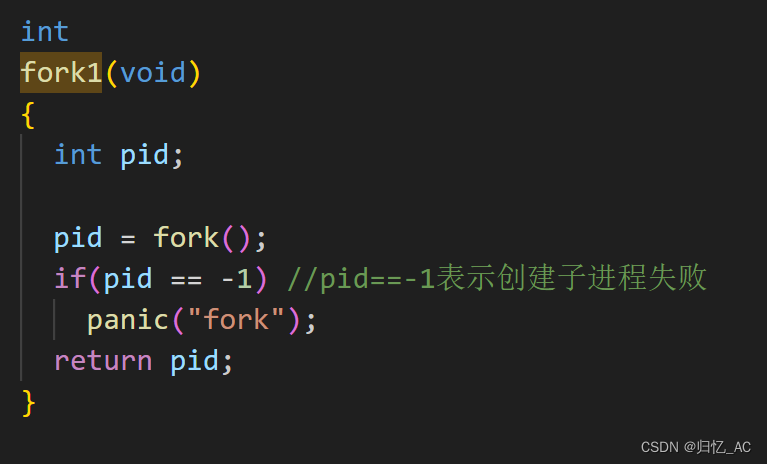
接下来再观察fork函数,找到其返回值为-1的情况,可以看出其创建子进程失败时返回-1。

找到fork函数返回值为0的情况,得知返回值为0表示该进程是子进程。

因此,当fork1()返回0时,说明当前进程是子进程,接下来调用runcmd函数去在子进程中执行相应的程序
为什么需要在子进程中执行命令呢?
在Unix系统中,shell是用户与操作系统交互的主要界面。当用户在shell中输入命令时,shell需要对命令进行解析,并调用对应的程序或命令来执行该命令。由于命令的执行需要创建新的进程,因此通常在Unix系统中,shell会通过fork()系统调用创建一个新的子进程来执行命令,而在父进程中则等待子进程的执行结果。
在xv6中,为了简化操作系统的实现,操作系统提供了一个基本的用户态shell,该shell是通过用户输入一条条命令并在操作系统中创建新的进程来实现的。在这个shell中,每个命令都需要在子进程中执行,在一个shell中,当用户输入一个命令时,如果在父进程中直接执行该命令,会导致原shell进程的状态被改变,而且如果该命令出现错误导致进程崩溃,也会导致整个shell崩溃。因此,xv6的设计者选择在子进程中处理各种命令,以保持shell的稳定性
另外,通过在子进程中处理命令,还可以允许shell支持并发执行多个命令。由于每个子进程是独立的,因此它们可以并发地执行不同的命令,从而提高了shell的效率和性能。
阅读runcmd的代码,其中:
$echo README对应的cmd->type是哪个?
相应的,$ls; echo “hello world“ 对应的cmd->type是哪个?
而ls | wc 对应的cmd->type是哪个?给出你的答案,并从代码中给出解释。
看到源码一共有5种类型




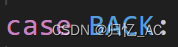
EXEC: 执行一个可执行文件
REDIR: 重定向输入输出
LIST: 命令列表,包含多个命令
PIPE: 管道
BACK:返回
查阅中文文档相关内容

echo README命令对应的cmd->type
在xv6中,runcmd()函数会接收到一个cmd_t类型的命令结构体指针,这个结构体包含了命令的类型以及相关的参数和选项信息。在runcmd()函数中,根据命令的类型,会进行相应的处理和执行。当命令只包含一个可执行文件时,cmd->type应该为EXEC。对于echo README命令,它只是简单地输出一个字符串,因此它对应的是EXEC类型,表示执行一个可执行文件。
ls; echo “hello world”对应的cmd->type
对于包含多个命令的命令行,xv6会将它们按顺序组合成一个命令列表,并且逐个执行。这个命令列表的类型就是LIST。对于$ls; echo "hello world"命令,它包含两个命令,因此对应的cmd->type就是LIST。
ls | wc 对应的cmd->type
在xv6的shell中,管道(pipeline)是通过将两个命令的标准输出和标准输入连接起来实现的。在shell中,如果用户输入了形如"command1 | command2"的命令,shell会将这个命令分为两个子命令,即command1和command2,并且用管道符号“|”将它们连接在一起。对于ls | wc命令,它包含两个命令,分别是ls和wc,它们通过管道连接在一起,因此它对应的是PIPE类型,表示管道。
在中文文档中也能找到管道的说明:

b)阅读user/sh.c (L83)对应的switch分支及相关代码,请说明这个输出重定向命令
$ls > test.txt
如何确保test.txt接收ls命令的输出呢?
在xv6的shell中,当用户输入$ls > test.txt命令时,shell会将这个命令解析为REDIR类型的命令,因为它包含了一个输出重定向符号“>”。其中ls命令的输出会被重定向到test.txt文件中。具体而言,在shell中,当遇到REDIR类型的命令时,shell会将命令行参数中的输入/输出重定向符号进行处理,然后将重定向操作交给runcmd函数来处理。
在runcmd函数中,当cmd的类型为REDIR时,shell会先尝试打开test.txt文件,并将它的文件描述符与标准输出文件描述符1进行重定向。然后,shell会创建一个子进程来执行ls命令,这时ls命令的输出会被重定向到test.txt文件中,而不是输出到屏幕上。最后,shell会等待子进程的结束,并检查子进程的返回值。
因此,通过重定向标准输出文件描述符1,shell可以确保test.txt接收ls命令的输出。这个过程中涉及到的命令类型包括REDIR和EXEC。
c)user/sh.c (L101-123):
第二、三个if语句中,管道的读端口和写端口都通过close语句关闭了,请问还怎么保证pcmd->left的输出进入管道的写端口,而pcmd->right的输入进入管道的读端口?
PIPE部分代码如下图所示
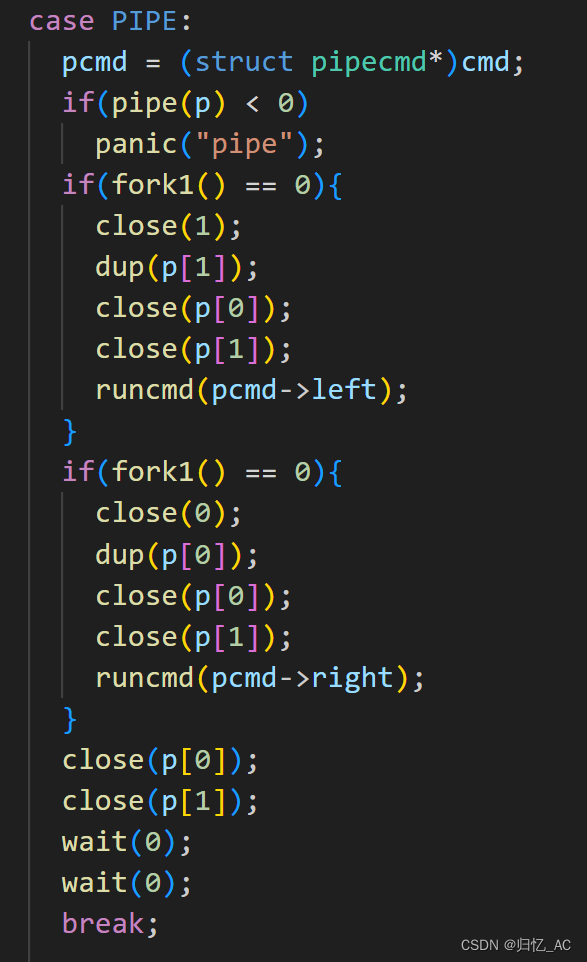
首先将cmd强制转换为一个pipecmd类型的指针pcmd。然后使用pipe系统调用创建一个管道,管道的读端口和写端口分别是p[0]和p[1]。接下来,通过fork1()函数创建两个子进程,分别处理管道的左侧和右侧命令。
在左侧子进程中,首先关闭标准输出(文件描述符1),然后通过dup系统调用将p[1]复制为标准输出的文件描述符,这样子进程输出的数据就会写入管道。接着,关闭管道的读端口和写端口,最后通过runcmd函数执行左侧命令。右侧子进程的过程类似,只不过它将标准输入(文件描述符0)重定向到管道的读端口p[0],这样右侧命令就可以读取管道中的数据。在两个子进程运行完后,父进程关闭管道的读端口和写端口,并且使用wait函数等待两个子进程退出。
在第二、三个if语句中,管道的读端口和写端口都通过close语句关闭了。这是因为在xv6中,进程之间通过管道进行通信时,需要使用一对文件描述符来实现。其中,一个描述符用于读取数据,另一个用于写入数据。当一个进程需要向另一个进程发送数据时,它会将数据写入其写入端口,而另一个进程则通过其读取端口读取这些数据。当两个进程之间的通信完成后,它们都需要关闭与管道相关的文件描述符,以确保管道资源能够被及时释放。
在第二、三个if语句中,关闭管道读端口和写端口并不会影响数据的传输。因为当一个进程写入管道时,数据会被存储在管道缓冲区中,直到另一个进程从管道中读取这些数据。因此,当一个进程关闭其写入端口时,管道缓冲区中的数据仍然可以被另一个进程读取。
为什么在父进程这里,还需要有两个close语句?以及两个wait语句?
因为当一个进程使用管道与另一个进程通信时,它需要保证管道的读写操作在适当的时机进行。具体来说,当一个进程完成向管道写入数据时,它必须关闭其写入端口以通知另一个进程可以从管道中读取数据了。而当另一个进程从管道中读取完所有数据时,它也必须关闭其读取端口以通知另一个进程可以继续向管道中写入数据。
因此,在父进程中,第一个close语句用于关闭管道的写入端口,以通知另一个进程可以从管道中读取数据。第一个wait语句用于等待子进程结束,以确保所有数据都已经被写入管道。第二个close语句用于关闭管道的读取端口,以通知另一个进程可以继续向管道中写入数据。第二个wait语句用于等待另一个进程结束,以确保所有数据都已经被读取完毕。
(2)、阅读Chapter2 Operating system organization,回答以下问题:
a)请上网查找资料,解释在RISC-V平台上,CPU的hartid代表什么。
当$make CPUS=1 qemu-gdb时,qemu只虚拟了一个CPU。请问为何这个CPU的hartid一定是0?
在RISC-V架构中,hartid(hardware thread identifier)是指CPU核心的唯一标识符,每个CPU核心都有一个唯一的hartid值。
hartid是一个32位的无符号整数,可以通过RISC-V指令csrr获取,例如csrr a0, mhartid可以将hartid的值存储在寄存器a0中。
在xv6中,当通过make CPUS=1 qemu-gdb命令启动一个只虚拟了一个CPU的QEMU实例时,这个CPU的hartid一定是0,因为它是唯一的一个CPU核心,因此不需要进行区分。
如果使用make CPUS=2 qemu-gdb启动一个虚拟了两个CPU的QEMU实例,则第一个CPU的hartid为0,第二个CPU的hartid为1,以此类推。
(3)、阅读Chapter 7 Scheduling,回答以下问题:
a)试解释一下yield函数、scheduler函数和sched函数的用途。
第七章在以下部分提到过这三个函数:

通过查询网络得知:
yield函数、scheduler函数和sched函数都是xv6操作系统中proc.c文件下用于实现进程调度的函数。
yield函数
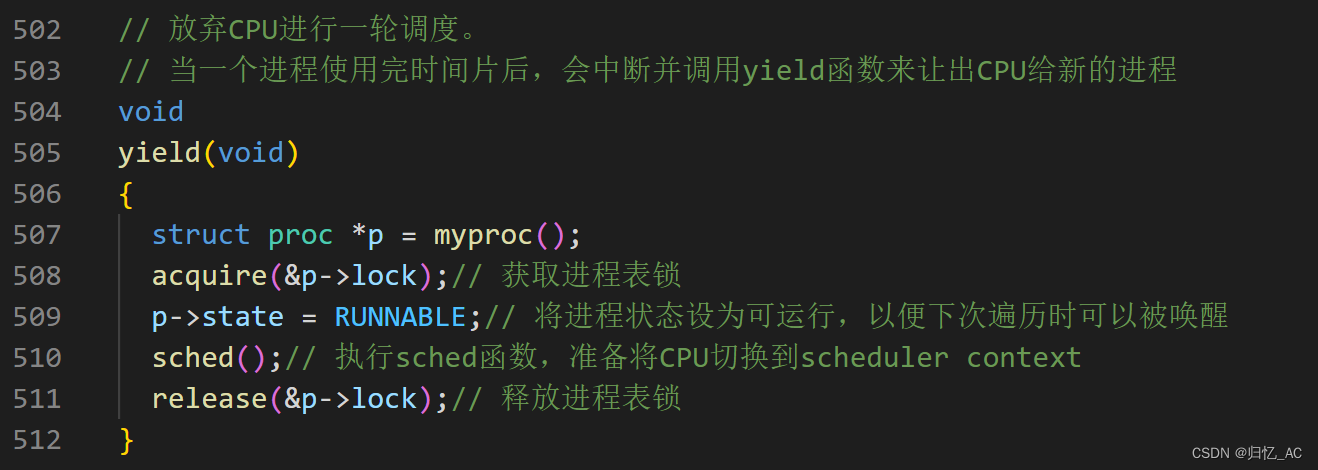
当一个进程使用完时间片后,会中断并调用yield函数来让出CPU给新的进程。
yield函数首先获取进程表锁,并将进程状态设为可运行,以便下次遍历时可以被唤醒。
之后执行sched函数,准备将CPU切换到scheduler context。最后释放进程表锁。
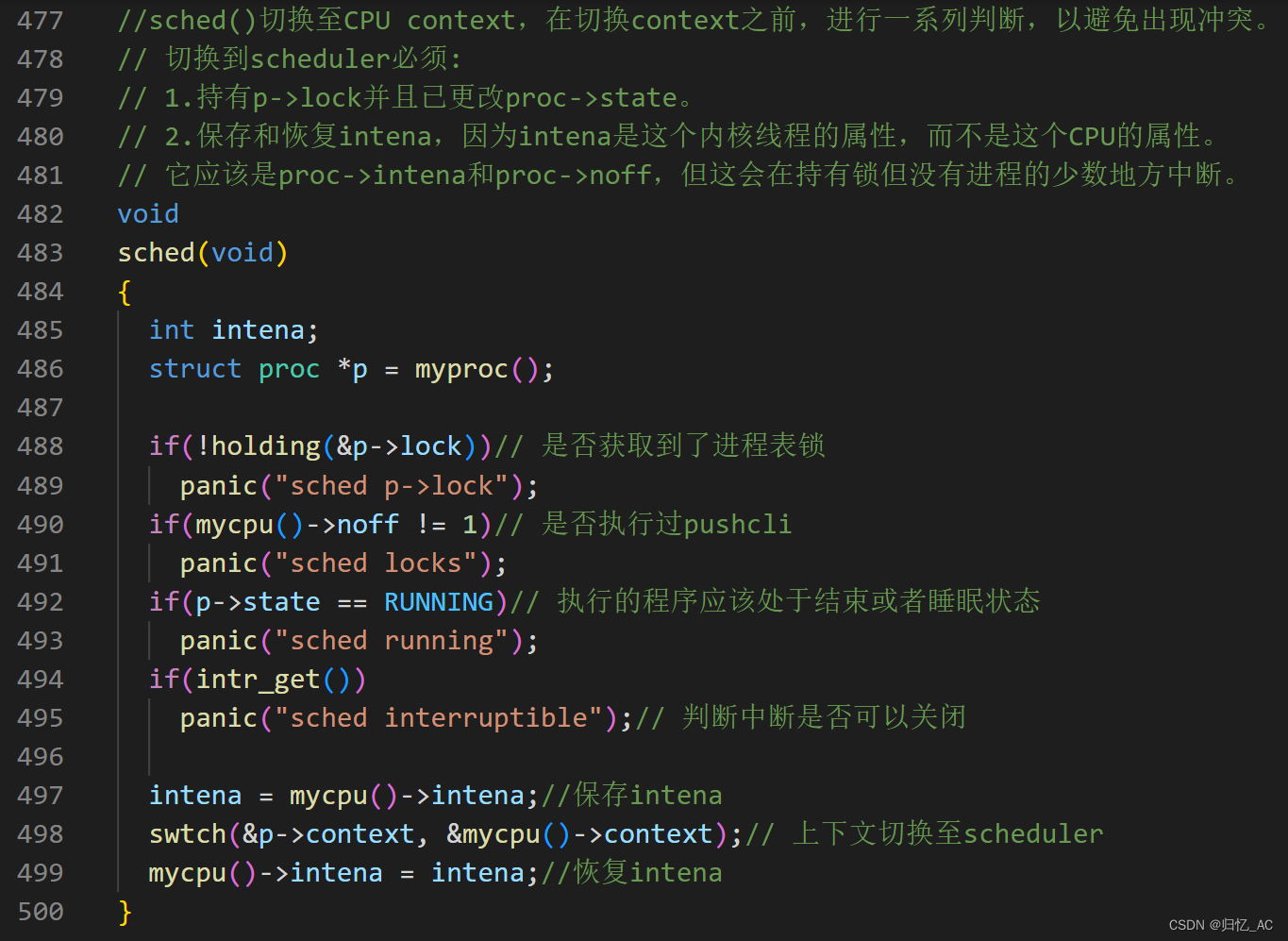
sched函数
sched()是切换至CPU context,并在切换context之前,进行一系列判断,以避免出现冲突的函数。
切换到scheduler必须:
1.持有p->lock并且已更改proc->state。
2.保存和恢复intena,因为intena是这个内核线程的属性,而不是这个CPU的属性。
检查完后调用scheduler()。
scheduler函数
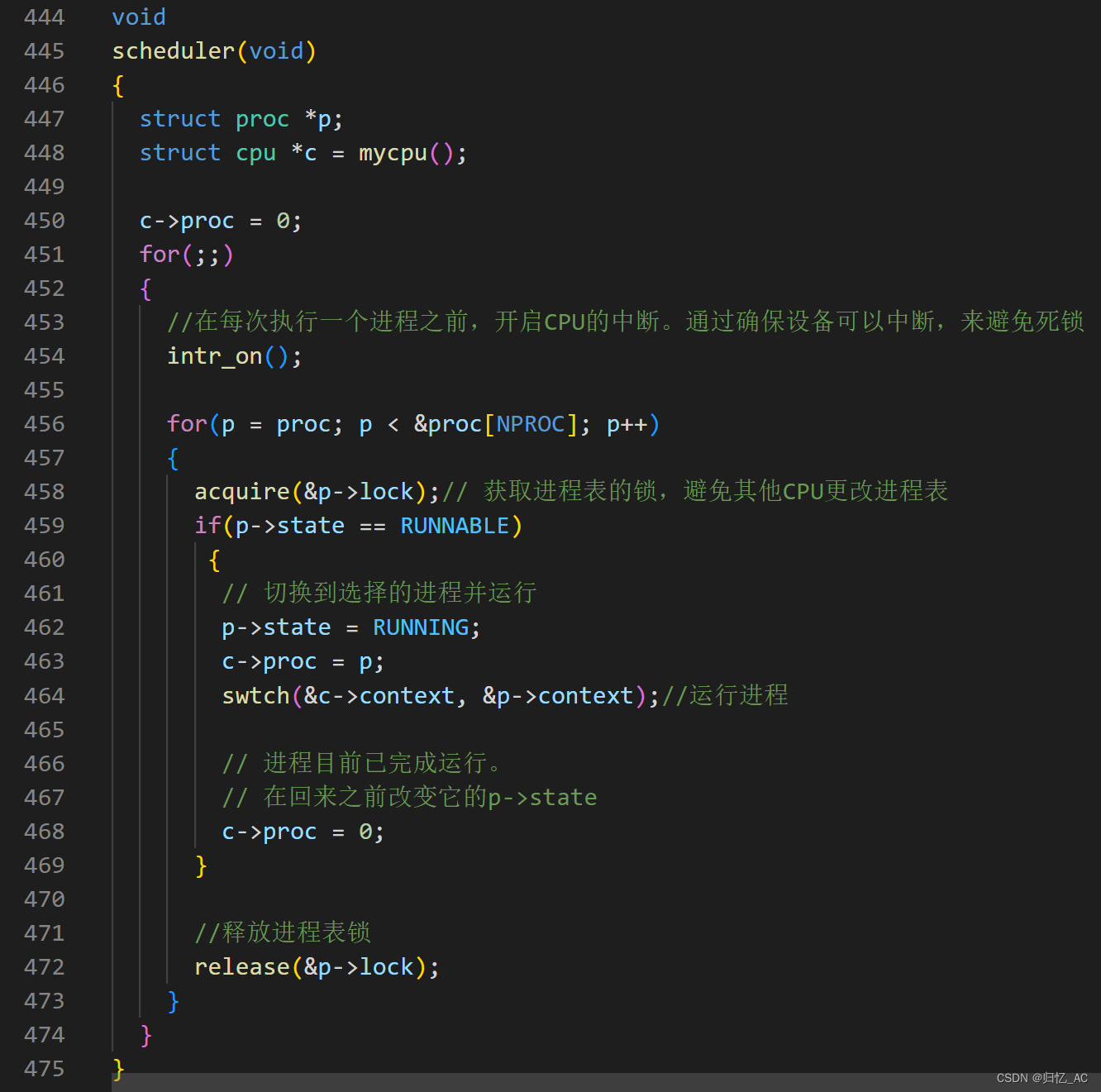
scheduler函数是xv6中的核心调度器函数,用于根据选择的调度算法从就绪队列中选择下一个要运行的进程。
scheduler函数的实现方式取决于所选的调度算法。
当CPU初始化之后,即调用scheduler(),循环从进程队列中选择一个进程执行。
计划程序永远不会返回。它循环执行以下操作:
1.选择要运行的进程。
2.swtch开始运行该进程。
3.最终该进程会转移控制权,通过swtch返回到调度程序。
b)结合书本,确定xv6使用的是哪种调度算法。给出你的理由(通过分析代码证明你的观点)。
为了确定采用了哪种调度算法,我们需要分析scheduler函数,代码如下:
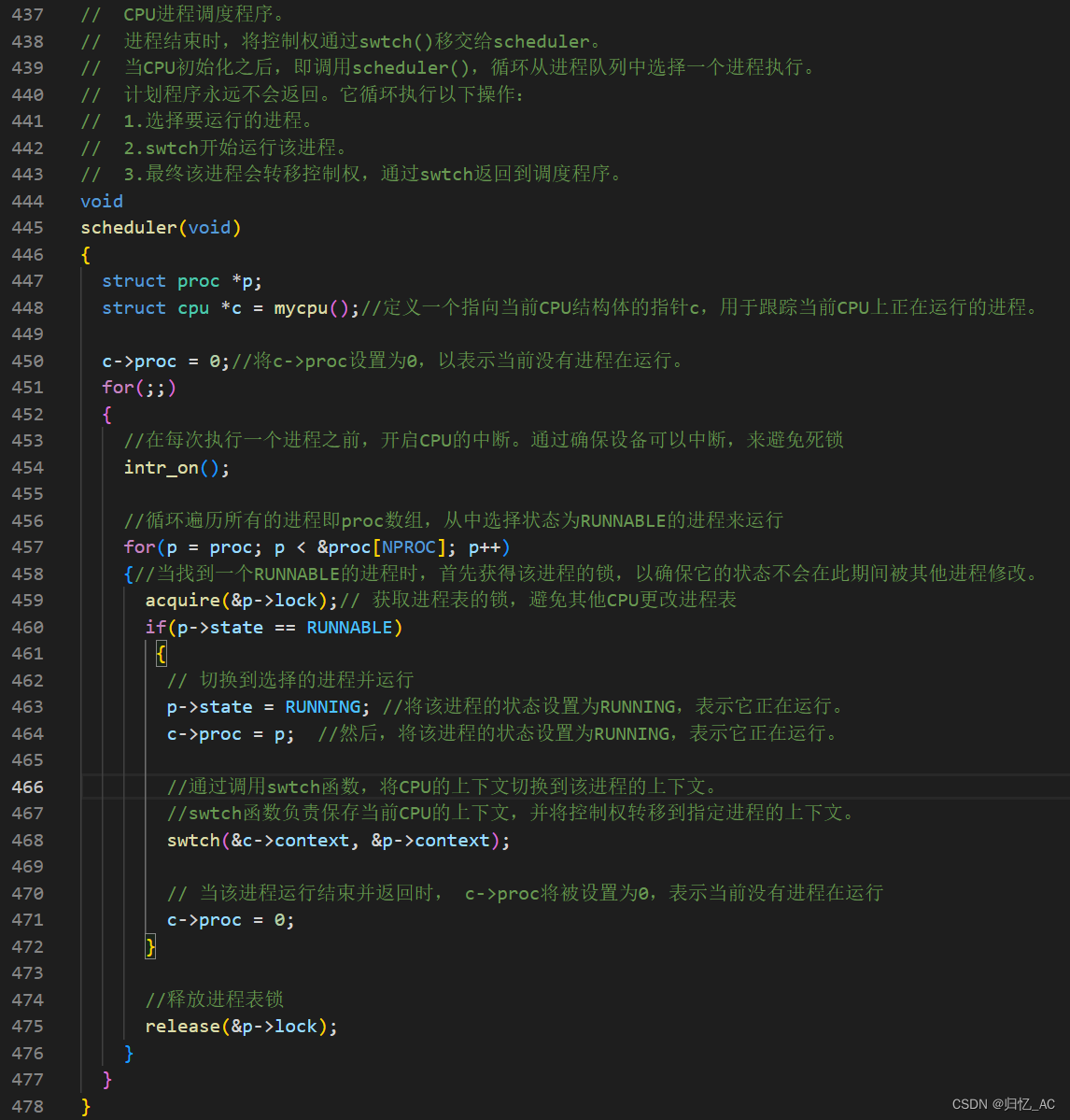
首先,定义一个指向当前CPU结构的指针c,用于跟踪当前CPU上正在运行的进程。然后,将c->proc设置为0,以表示当前没有进程在运行。
在每次执行一个进程之前,开启CPU的中断。通过确保设备可以中断,来避免死锁。

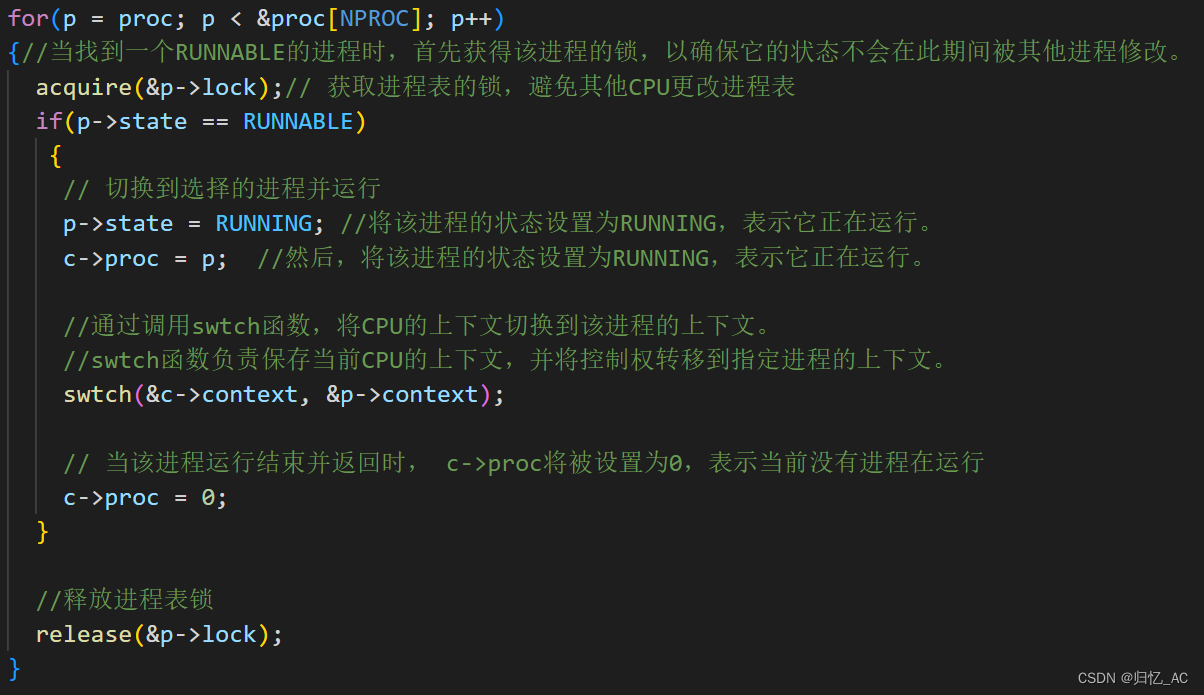
循环遍历存放进程的proc数组,从中选择状态为RUNNABLE的进程来运行。
当找到一个RUNNABLE的进程时,首先获得该进程的锁,以确保它的状态不会在此期间被其他进程修改。
然后,将该进程的状态设置为RUNNING,表示它正在运行。
将该进程的指针赋值给c->proc,表示该进程正在当前CPU上运行。
通过调用swtch函数,将CPU的上下文切换到该进程的上下文,swtch函数负责保存当前CPU的上下文,并将控制权转移到指定进程的上下文。
当该进程运行结束并返回时, c->proc将被设置为0表示当前没有进程在运行,并且释放锁。
这是一个简单的时间轮转调度算法。它遍历所有的进程,并按顺序选择每个RUNNABLE进程运行一定时间,然后切换到下一个RUNNABLE进程。如果进程的运行时间达到了一定的限制,也会强制切换到下一个进程。
c)(kernel/proc.c:455) 有一个疑问,似乎每次xv6都是从进程表开头开始查找Runnable的进程。如果刚从CPU切换下来的进程恰好是进程表的第一个PCB,会不会调度器永远都选择它进行调度?
不会,由前面for循环部分的代码可知,在执行完第一个进程后,并不会跳出for循环,而是接着遍历完整个进程表,寻找下一个RUNAABLE状态,故不会出现这种情况。

(4)、阅读Chapter3 Page tables,回答以下问题:
a)请阅读walk函数(kernel/vm.c:86),计算理论上一个进程页表所支持的最大虚拟地址空间。
walk函数的功能是通过给定的虚拟地址和页表指针,找到对应的页表项并返回指向该页表项的指针。
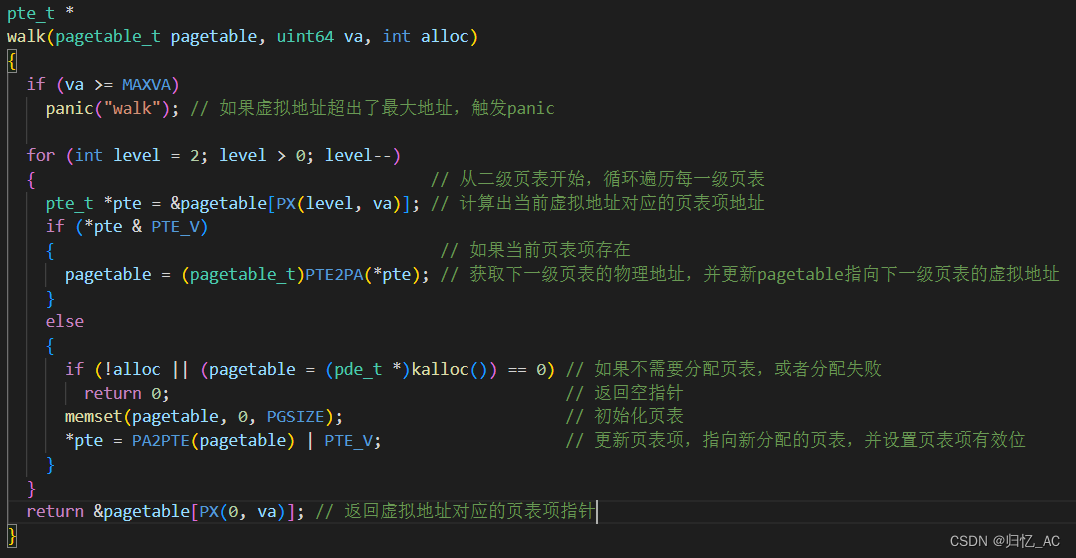
在xv6中,每个页表项对应着一个页面,每个页面的大小是PGSIZE,即4096字节。由于xv6使用了两级页表,因此一个页表能够映射的虚拟地址空间大小为PGSIZE * NPTENTRIES * NPTENTRIES,其中NPTENTRIES是每一级页表的条目数。
根据xv6中的定义,NPTENTRIES为512,因此一个页表能够映射的虚拟地址空间大小为PGSIZE * 512 * 512 = 256MB。一个进程的页表是由一组页表组成的,每个页表都可以映射256MB的虚拟地址空间。
因此,一个进程页表所支持的最大虚拟地址空间大小为256MB * NPDENTRIES,因此一个进程页表所支持的最大虚拟地址空间大小为256MB * 512 = 128GB。
b)kernel/kalloc.c (内存分配)
阅读kinit2、freerange、kfree、kalloc四个函数。
kmem中的freelist指针指向空闲物理块链表。空闲物理块链表中的节点为run结构体。但是可以看到这个结构体只有指向下一个节点的指针。请解释这个链表中的空闲物理块保存在哪里呢?
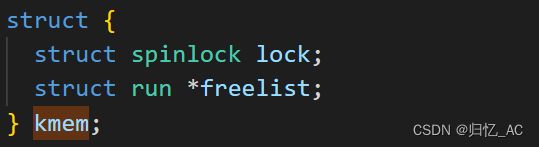
首先观察kallow.c中,用于内存页管理的结构体的定义。起初,锁struct spinlock lock是未启动的,调用kinit()后锁才被使用。其中struct run *freelist就是空闲物理块链表。
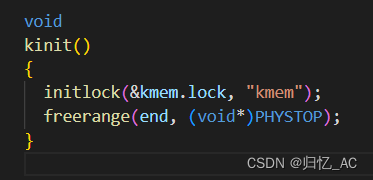
kinit函数用于初始化内核的内存管理系统,以便内核可以分配和释放物理内存。kinit函数中,调用了initlock函数和freerange函数。
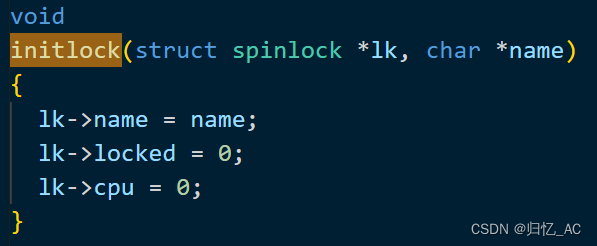
initlock函数初始化内核锁kmem.lock,锁被用于在内核中对物理内存的分配和释放进行同步。
freerange函数的作用是将一段物理地址空间从pa_start到pa_end之间的内存页设置为空闲状态,以便后续的内存分配可以使用这些空闲内存。
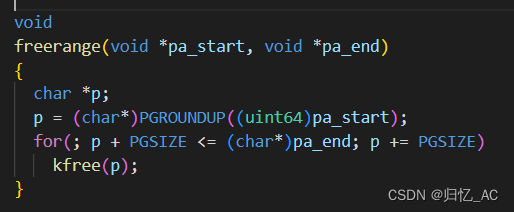
PGROUNDUP是一个宏定义,用于将一个地址向上对齐到页面边界。它的作用是保证对齐后的地址恰好是一个页面的起始地址。
PGROUNDUP((uint64)pa_start)用于将参数pa_start指向的物理地址向上对齐到页面边界,并将对齐后的地址赋值给指针变量p。这是因为内存管理系统中的页面大小固定为4KB,因此需要将空闲内存区域的起始地址对齐到页面边界,以便后续的内存分配可以按照页面大小进行。
然后,使用一个循环来遍历从p开始的每个页面,并将每个页表的首地址赋给p,直到p达到pa_end为止。在循环中,对于每个页面,调用kfree函数将其设置为空闲状态。
kfree函数用于将一个页框释放回空闲页框列表中。

首先判断该首地址是否内存对齐(即pa是否是页表首地址),以及是否在end----PHYSTOP范围内。
接着,函数会将 pa 所在的页框转换成 struct run 结构,然后将这个结构添加到内核管理的空闲页框列表 kmem.freelist 的头部。
最后,函数释放 kmem.lock,解除对内存管理数据结构的独占访问,允许其他线程执行相应的内存管理操作。
kalloc函数的作用是分配一个4096字节的物理内存页并返回内核可以使用的指针。如果无法分配内存,则返回0。

首先通过acquire()函数获得了kmem.lock的锁。然后,它从内核空间的自由空闲列表中获取一个空闲的物理内存页,即获取一个struct run结构体。
如果成功获取,则更新freelist,相当于从空闲页列表中移除r指向的内存页。然后,通过release()函数释放kmem.lock的锁。
如果成功获取了一个物理内存页,则将该页用5填充,以便之后检测该页帧是否被错误地使用。
最后,将物理页帧的指针转换为void指针并返回。
如果自由空闲列表为空,则函数返回空指针。在这种情况下,需要调用者考虑如何处理分配失败的情况。
kmem 是在操作系统内核的 memlayout.h 文件中定义的全局变量,它是用于管理内核空间内存的数据结构。在 kalloc() 和 kfree() 中,都会访问 kmem 中的 freelist 成员,以进行空闲内存块的分配和释放。
在xv6中,kmem中的freelist指针指向空闲物理块链表,链表中每个节点都是一个struct run结构体,表示一个空闲的物理内存块。每个物理内存块都是以一页大小(PGSIZE)为单位的,而每个物理内存块的地址就是该节点(struct run)的地址。所以kmem中的freelist指针实际上指向了一个struct run类型的内存块,也就是空闲物理块链表中的第一个节点。链表中每个节点只包含指向下一个节点的指针,因此可以通过这些指针遍历整个链表,找到一个空闲的物理内存块。
当需要分配一个物理内存块时,会从空闲物理块链表中取出第一个节点(即kmem.freelist指针所指向的节点),然后将kmem.freelist指针指向下一个节点,这样就从链表中移除了这个物理内存块。
当需要释放一个物理内存块时,会将其转换成一个struct run类型的节点,并将其加入到空闲物理块链表的头部,成为新的第一个节点。
因此,空闲物理块并没有被保存在一个特定的数据结构中,而是作为一个物理内存块的一部分,通过链表的指针链接在一起,形成一个空闲物理块链表。
(5)、阅读Chapter6 Locking,回答以下问题:
a)阅读7.3 Code: Scheduling,请回答在调度器和被调度的进程之间,如何确保p->lock的锁定(acquire)和释放(release)能够两两配对?
查阅中文文档中:

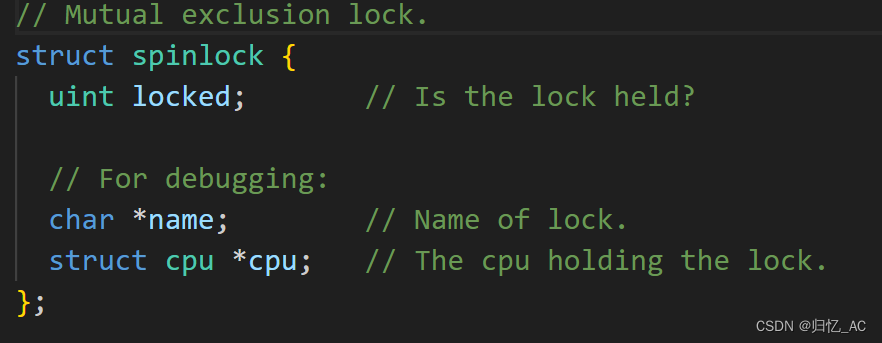
由第二段可知,锁需要在切换进程后仍然保持不变。为了实现这个要求,xv6使用了spinlock结构体实现多个进程/线程同步和互斥访问临界区。自旋锁的结构定义如下,其中最重要的就是 locked 元素,用来表示该锁是否已被某 CPU 取得,1 表示该锁已被某 CPU 取走,0 表示该锁空闲。
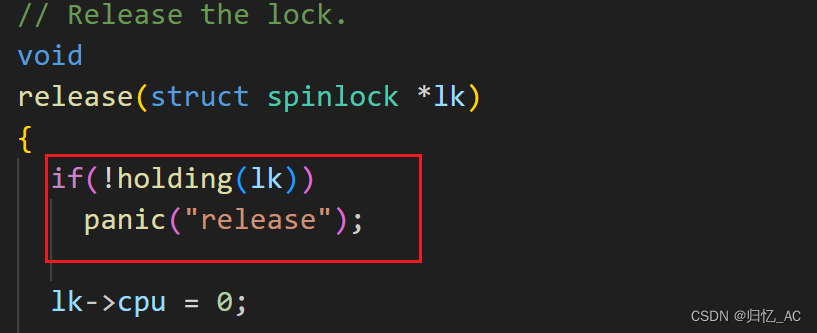
在使用acquire函数获取锁时,会调用holding函数判断该锁是否已被某CPU获取。若已被获取,则会导致当前CPU获取失败。

在调用release函数释放锁时,会调用holding函数判断该锁是否已被当前CPU获取。若未被当前CPU获取,则会导致释放锁失败。
实验小结
通过阅读xv6操作系统代码,理解了其如何实现操作系统中的各种管理功能,在系统程序设计能力方面得到提升。掌握了计算机操作系统管理进程、处理机、存储器、文件系统的基本方法;了解了现代计算机操作系统的工作原理;具备了初步分析、设计操作系统的能力。
(by 归忆)