.ttf TTF字库文件格式详解
一、简述
TTF文件是苹果和微软共同推出的矢量字体文件
文件使用sfnt封装格式(和mp4容器格式类似),一个.ttf文件就是一个sfnt容器,容器里放入了很多表,每个表都有4个英文字符的名字。
sfnt容器头的信息:{sfnt版本号 + 有多少张表 + 搜索范围 + 入口选择 + 范围平移 + 所有的表索引}
每个表在前面都有一个tableentry地址索引,在所有表索引的最后是每个表的实际数据。
表索引的统一格式:{4个字母的表名 + 校验和 + 表数据的地址 + 表长度}
一些关键的表:
字体头head:字体版本号、创建时间、字体的最大最小像素、
字符索引cmap:Unicode等编码的汉字和字模字模索引进行对应,编码ID
字模索引loca:每个字模索引与实际字模数据地址的对应关系
字模glyf:所有文字的矢量轮廓数据
不重要的表:
最大需求表maxp:需要的内存
水平规格mmtx:
说明name:字体名字
水平布局hmtx:推荐的行间距
字距离调整表kerm:
二、详述
- 写在前面,苹果的官方英文协议文档网址,啃得动的可以啃:TrueType Reference Manual
| 编写人员 | 将狼才鲸 |
|---|---|
| 编写时间 | 2023-11-27 |
一、.ttf矢量字库
1)前言
- .ttf文件是电脑手机中最常用的字库文件,可以用来显示矢量文字、矢量图标、矢量单色图片,缩放后不失真。
- .ttf格式的文件是TrueType字体,由微软和苹果共同发布。
- 一个英文矢量字库只有数百K,一个中文矢量字库有几M到几十M。
- 一个字库文件里可以同时包含多套汉字编码,如Unicode。
- 每个汉字的编码,就是它在字库里面的索引。
- 字库文件里有索引表和每个文字的字模,硬件上每次解码只显示一个英文字母或者汉字,通过快速循环来显示一整行或者一整页。
2).ttf文件结构分析
- 我们以barbatri.ttf英文字库为例:
| 字库大小 | 字库内容 |
|---|---|
 |  |
- .ttf文件不能通过从文件中简单的搜索某几个固定的字符就得到索引参数或者某个文字的字模,而是需要完整的解析整个文件后,才能查索引得到某个字的字模数据。
- .ttf文件是由一个文件头+数十张表组成的,文件头中包含了表的数量和表的入口地址。
- .ttf文件的框架如下:
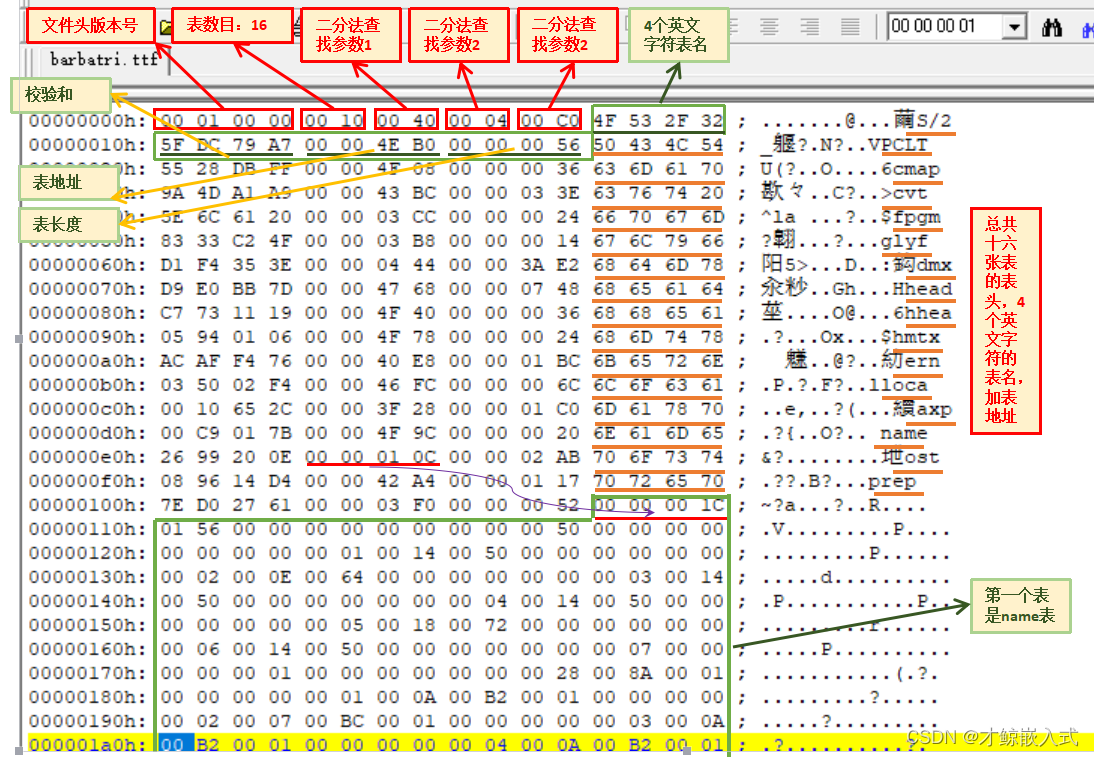
- 与文件二进制内容的对照:
3).ttf文件细节分析
-
当前这个字体文件中的16张表为OS/2、PCLT、cmap、cvt(0x20)、fpgm、glyf、hdmx、head、hhea、hmtx、kern、loca、maxp、name、post、prep,不是按在文件中存放的顺序排序的,先按大写字母的顺序排序,再按小写字母的顺序排序。
-
所有表中数据都是大端模式,和mp4封装格式类似。
-
一些表的简述:
| 表名 | 描述 |
|---|---|
| head | 字体头,字体的全局信息 |
| cmap | 字符代码到图元的映射,把字符代码映射为图元索引 |
| glyf | 图元数据,图元轮廓定义以及网格调整指令 |
| maxp | 最大需求表,字体中所需内存分配情况的汇总数据 |
| mmtx | 水平规格,图元水平规格 |
| loca | 位置表索引,把元索引转换为图元的位置 |
| name | 命名表,版权说明、字体名、字体族名、风格名等等 |
| hmtx | 水平布局,字体水平布局星系:上高、下高、行间距、最大前进宽度、最小左支撑、最小右支撑 |
| kerm | 字距调整表,字距调整对的数组 |
| post | PostScript信息,所有图元的PostScript FontInfo目录项和PostScript名 |
| PCLT | PCL,5数据、HP、PCL、5Printer、Language的字体信息:字体数、宽度、x高度、风格、记号集等等 |
| OS/2 | OS/2和Windows特有的规格,TrueType字体所需的规格集 |
-
硬件解码和显示一个字模时需要从字库文件中获取的参数有:
- 字模数据、最小的显示像素宽高、最大的像素宽高。
-
其中关键的表有:
- glyf:存放所有字模的矢量线条数据,也是占用空间最大的表;
- cmap:Unicode中文编码到第一级索引(元索引)的映射;
- loca:第一级索引(元索引)到具体字模(图元数据)的映射;
- maxp:图元的总数,有多少个字;
-
各个表的存储结构:
- Fixed是4字节。
-
head表:
typedef struct
{
uint16 majorVersion; /* Major version number of the font header table – set to 1. */
uint16 minorVersion; /* Minor version number of the font header table – set to 0. */
Fixed fontRevision; /* Set by font manufacturer. */
uint32 checkSumAdjustment; /* To compute : set it to 0, sum the entire font as uint32,
then store 0xB1B0AFBA - sum. If the font is used as a
component in a font collection file, the value of this field
will be invalidated by changes to the file structure and
font table directory, and must be ignored.
*/
uint32 magicNumber; /* Set to 0x5F0F3CF5. */
uint16 flags; /*
Bit 0: Baseline for font at y = 0;
Bit 1: Left sidebearing point at x = 0 (relevant only for
TrueType rasterizers) – see the note below regarding
variable fonts;
Bit 2: Instructions may depend on point size;
Bit 3: Force ppem to integer values for all internal scaler
math; may use fractional ppem sizes if this bit is clear;
Bit 4: Instructions may alter advance width(the advance
widths might not scale linearly);
Bit 5: This bit is not used in OFF, and should not be set in
order to ensure compatible behavior on all platforms.If
set, it may result in different behavior for vertical layout in
some platforms. (See 'head' table specification of "Apple's
TrueType Reference Manual" [7] for details regarding
behavior in Apple platforms.)
Bits 6 - 10: These bits are not used in OFF and should
always be cleared. (See 'head' table specification of
"Apple's TrueType Reference Manual"[7] for details
regarding legacy use in Apple platforms.)
Bit 11 : Font data is ‘lossless’ as a result of having been
subjected to optimizing transformation and / or
compression(such as font compression mechanisms
defined by ISO / IEC 14496 - 18, MicroType®5 Express,
WOFF2[24], or similar) where the original font
functionality and features are retained but the binary
compatibility between input and output font files is not
guaranteed.As a result of the applied transform, the
‘DSIG’ Table may also be invalidated.
Bit 12: Font converted(produce compatible metrics)
Bit 13 : Font optimized for ClearType®6.Note, fonts that
rely on embedded bitmaps(EBDT) for rendering should
not be considered optimized for ClearType, and therefore
should keep this bit cleared.
Bit 14: Last Resort font. If set, indicates that the glyphs
encoded in the cmap subtables are simply generic
symbolic representations of code point ranges and don’t
truly represent support for those code points. If unset,
indicates that the glyphs encoded in the cmap subtables
represent proper support for those code points
Bit 15: Reserved, set to 0
*/
uint16 unitsPerEm; /* Set to a value from 16 to 16384. Any value in this range
is valid.In fonts that have TrueType outlines, a power of
2 is recommended as this allows performance
optimization in some rasterizers. */
LONGDATETIME created; /* Number of seconds since 12:00 midnight that started
January 1st, 1904, in GMT / UTC time zone. 64 - bit integer */
LONGDATETIME modified; /* Number of seconds since 12 : 00 midnight that started
January 1st, 1904, in GMT / UTC time zone. 64 - bit integer */
int16 xMin; /* For all glyph bounding boxes. */
int16 yMin; /* For all glyph bounding boxes. */
int16 xMax; /* For all glyph bounding boxes. */
int16 yMax; /* For all glyph bounding boxes. */
uint16 macStyle; /* Bit 0: Bold(if set to 1);
Bit 1: Italic(if set to 1)
Bit 2 : Underline(if set to 1)
Bit 3 : Outline(if set to 1)
Bit 4 : Shadow(if set to 1)
Bit 5 : Condensed(if set to 1)
Bit 6 : Extended(if set to 1)
Bits 7 - 15 : Reserved(set to 0). */
uint16 lowestRecPPEM; /* Smallest readable size in pixels. */
int16 fontDirectionHint; /* Deprecated(Set to 2).
0: Fully mixed directional glyphs;
1: Only strongly left to right;
2: Like 1 but also contains neutrals;
-1: Only strongly right to left;
-2: Like - 1 but also contains neutrals. */
int16 indexToLocFormat; /* 0 for short offsets, 1 for long. */
int16 glyphDataFormat; /* 0 for current format. */
uint16 reserved; // only for aligned
} PACKED TTF_FontHeader_t;
- maxp表:
typedef struct
{
Fixed version; // 0x00010000 for version 1.0.
uint16 numGlyphs; // The number of glyphs in the font. 总共有多少个字符
uint16 maxPoints; // Maximum points in a non - composite glyph.
uint16 maxContours; // Maximum contours in a non - composite glyph.
uint16 maxCompositePoints; // Maximum points in a composite glyph.
uint16 maxCompositeContours; // Maximum contours in a composite glyph.
uint16 maxZones; // 1 if instructions do not use the twilight zone(Z0), or 2 if instructions do use Z0;
// should be set to 2 in most cases.
uint16 maxTwilightPoints; // Maximum points used in Z0.
uint16 maxStorage; // Number of Storage Area locations.
uint16 maxFunctionDefs; // Number of FDEFs, equal to the highest function number + 1.
uint16 maxInstructionDefs; // Number of IDEFs.
uint16 maxStackElements; // Maximum stack depth across Font Program('fpgm' table), CVT Program('prep' table) and
// all glyph instructions(in the 'glyf' table).
uint16 maxSizeOfInstructions;// Maximum byte count for glyph instructions.
uint16 maxComponentElements; // Maximum number of components referenced at "top level" for any composite glyph.
uint16 maxComponentDepth; // Maximum levels of recursion; 1 for simple components.
} PACKED TTF_MaximumProfile_t;
- cmap表:
typedef struct
{
uint16 Version; // Table version number(0)
uint16 numTables; // Number of encoding tables that follow, 下面有多少个字符集(GB2312、UTF-8等)
TTF_CmapEncodingRecord_t encodingRecords[TTF_MAXIUM_SUBTABLE_NUMMBER]; // 字符编码
TTF_CmapFormat4_t subtable[TTF_MAXIUM_SUBTABLE_NUMMBER];
} PACKED TTF_CmapHeader_t;
typedef struct
{
uint16 platformID; // Platform ID. 编码所使用的环境
uint16 encodingID; // Platform - specific encoding ID. 指定是哪种编码,例如可能是Format4(16位映射,在区域之间可能有一些保留的空白。而有一些编码可能并不会与字体中的glyph对应。)
Offset32 offset; // Byte offset from beginning of table to the subtable for this encoding, 该款编码表索引所在的位置
} PACKED TTF_CmapEncodingRecord_t;
typedef struct
{
uint16 format; // Format number is set to 4.
uint16 length; // This is the length in bytes of the subtable.
uint16 language; // For requirements on use of the language field, see subclause 5.2.2.2.1.
uint16 segCountX2; // 2 x segCount. 指定了有多少段,字体中连续编码区块的数目,每个段都有一个statrCode、endCode、idDelta和idRangeOffset,用于描述该段的字符映射
uint16 searchRange; // 2 x(2 * *floor(log2(segCount)))
uint16 entrySelector; // log2(searchRange / 2)
uint16 rangeShift; // 2 x segCount - searchRange
uint16 reserved; // only for aligned
Offset32 endCodeOffs; // uint16 endCode[segCount] End characterCode for each segment, last = 0xFFFF.
Offset32 startCodeOffs; // uint16 startCode[segCount] Start character code for each segment.
Offset32 idDeltaOffs; // int16 idDelta[segCount] Delta for all character codes in segment.
Offset32 idRangeOffsetOffs; // uint16 idRangeOffset[segCount] Offsets into glyphIdArray or 0
} PACKED TTF_CmapFormat4_t;
/* 字符编码进行映射时,首先查找到第1个endCode大于或等于它的段。如果该字符码大于该段的startCode,将使用idDelta和idRangeOffset去查找glyph索引,否则返回“丢失的字符”。为了标志段表结束,最后一个段的endCode必需设置为0xffff。这个段不需要包含任何映射。它简单地将字符码0xffff映射为“丢失的字符”,即glyph0。
如果idRangeOffset值不为0,该字符编码的映射依赖于glyphIndexArray。字符编码到startCode的偏移的量被用于加在idRangeOffset值中。最终这个数字用于表示从idRangeOffset自身地址到正确的glyphIdArray索引的偏移量。使用这种方法是因为在字体文件中,glyphIdArray是紧跟在idRangeOffset地址之后。 */
- glyf表:
- 图元数据(glyf表)是TrueType字体的核心信息,因此通常它是最大的表。因为的位置索引是一张单独的表,图元数据表就完全只是图元的序列而已,每个图元以图元头结构开始:
typedef struct
{
WORD numberOfContours; // contor number,negative if composite,该字的轮廓线数量,或者是负值(合成图元)
FWord xMin; // Minimum x for coordinate data. 该字左上角xy
FWord yMin; // Minimum y for coordinate data.
FWord xMax; // Maximum x for coordinate data. 该字右下角xy,也就是字的宽高,单位为像素
FWord yMax; // Maximum y for coordinate data.
}GlyphHeader;
- loca表:
- 每个项由Glyph Index, Offset, Glyph Length组成。
- 举例说明,下表:
Glyph Index Offset Glyph Length
0 0 100
1 100 150
2 250
... ... ...
n-1 1170 120
extra 1290
解释一下上面的:
根据规定,在任何的truetype字体中第一个图元都必须为丢失的图元,即index 0 指向的是没有找到的图元。Loca表有两个版本,长整型和短整型。版本的选择通过head表中的参数indexToLocFormat设定。
位置索引表中保存了n+1个图元数据表的索引,其中n是保存在最大需求表中的图元数量。最后一个额外的偏移量并不指向一个新图元,而是指向最后一个图元的偏移量和当前图元的偏移量和当前图元的偏移量间的差值得到图元的长度。
位置索引表中的每一个索引以无符号短整数对齐的,如果使用了短整数格式,索引表实际存储的是WORD偏移量,而不是BYTE偏移量。这使得短整数格式的位置索引表能支持128KB大小的图元数据表。
-
建议:.ttf文件的解析较为复杂,建议直接搜索开源的解析库,不要自己从头开始写。
-
参考网址:
三、结尾再说点
-
字库有点阵字库和矢量字库,有些嵌入式里面是使用的是点阵字库,而点阵字库一般是用工具从矢量字库中转出来的。
-
常用的字库有TTF字库。
-
一个矢量字库的后缀往往是.ttf,大小有好几M。
-
依靠编码方式,如GB2312、UTF-8等;矢量字库的每个字模都需要4字节地址偏移和2字节字模长度(举例)来指示在字库中的位置。
-
支持矢量字库的板子,往往需要用软件解析字库的.ttf文件,硬件上只负责选择一个个具体的字模,所以也需要熟悉.ttf文件的存放格式。
-
.ttf字体文件中存储的是TrueType字体。另一种字体是OpenType。
-
TrueType字体大端编码,和Windows、Linux编译器都不一样。
-
只使用.ttf关键字,而不加上sfnt的话,在中文环境中搜不到详细的描述,只有英文版中能搜到有用的信息。
-
.ttf文件存放的首先是描述自己有多上张表,然后是字体目录,接着具体每个字的字模可以任意顺序存储;.ttf文件由多个表组成,每个表都会字节对齐,不对齐的部分进行补0;
-
.ttf中每个表都有一个名字(和mp4中box名字类似);常用的表有cmap:一个字从索引到存储的映射;glyf:单个字的所有轮廓;head:整套字体的名称;
-
.ttf字体存放的组织格式称为sfnt,类比的话,如果.ttf是指视频文件,sfnt就是mp4容器格式。
-
.ttf字体文件中首先描述有多少张表,然后第一个表是映射表cmap,里面可能包含多个子表,不同的编码方案有一张表。
-
具体每个表的详细描述,可以使用ttf + 4个字母的表名进行搜索,也可以在下面链接中的苹果官网中查看。
-
参考网址:
如何知道一套字体未缩放时的默认宽高是多少像素呢?
em-square参考网格描述了一个字的初始面积(以像素为单位,长乘以宽),ascent、descent以及lineGap等值也是以em-square为基础的,字符的高度一般由ascent和descent共同决定
TextHeight= (Ascent - Descent) / EM-Square * TextSize
LineHeight= (Ascent - Descent + LineGap) / EM-Square * TextSize
Em-square的有效值是从16到16384,
获取.ttf字体默认宽高其实有一个更简单的方法,.ttf文件的文件头中有Xmin Xmax Ymin Ymax这4个值,
Xmax - Xmin就是所有字的未缩放时在屏幕上的原始像素Pixel宽度,Ymax - Ymin就是所有字的原始像素高度。
同样的,每个字也都有它各自的Xmin Xmax Ymin Ymax值,也就能算出每个字的默认未缩放的像素宽高,因为不是每个字每个标点都是等宽的。
我在网上搜了几天,都没搜到默认像素宽高的信息,这是我从字库解析源码里看出来的。
冷门干货 你知道Android 中1px的字到底有多高?
EM square
freetype的一些基本概念 -- EM
【CSS】内联格式化上下文 IFC(inline formatting context)