准备虚拟环境
接下来所有的操作基本都是在NX系统上进行,在win10上只有简单的下载应用与goooooogle。
直接打开终端使用su root转到root用户。
有个地方要注意:一开始我是在anaconda的py虚拟环境做的,一顿操作下来最后还提示需要安装虚拟环境,着实让人目不清头脑。迫不得已又装了venv重新来一遍。至于为啥anaconda不能用就不深究了。想试一下的可以安装arm64版本:传送地址。下载arm64版本。

venv的安装和使用:Python虚拟环境:venv与Conda的不同,如何选择?。总结就是几步:使用apt安装----创建虚拟环境(其实就是一个文件夹)----初始化or激活虚拟环境-----进入虚拟环境,用完后退出。由于不同系统、不同虚拟环境操作命令存在差异,篇幅有限在此不再一一列出,步骤就是上面的几步。退出之后所有py环境都会在这个文件夹里,做到环境隔离了。
ps:创建venv虚拟环境的时候,一定要指明Python的版本,否则后面就会遇到版本不对应问题。如何在virtualenv环境中安装指定的python版本
1 #创建python2.7虚拟环境
2 virtualenv -p /usr/bin/python2.7 ENV2.7
3
4 #创建python3.4虚拟环境
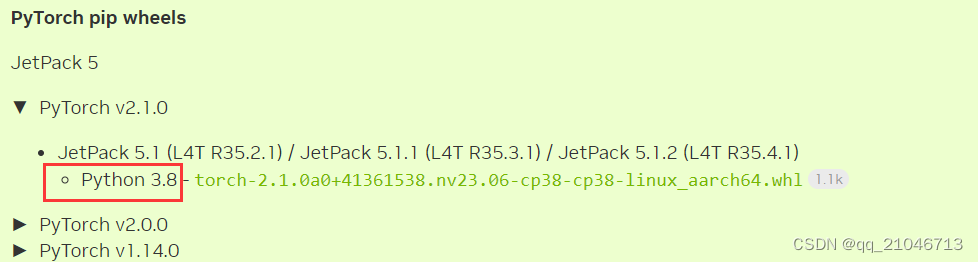
5 virtualenv -p /usr/local/bin/python3.4 ENV3.4目前20231116使用的是python3.8,因为这个关系到硬件GPU加速的最高支持版本号。在英伟达的官网显示如下。
确认虚拟环境
在安装好虚拟环境后,在用户(root)的前面会出现虚拟环境名(这个就是跟虚拟环境文件夹名称对应的)如下

可以使用python -V查看一下版本号,得到3.8版本即可。
开始安装Whisper
在虚拟环境中运行命令
pip install -U openai-whisper不出意外的话会得到一堆报错或者很慢很慢,这个应该是跟源有一定关系,比如报错如下
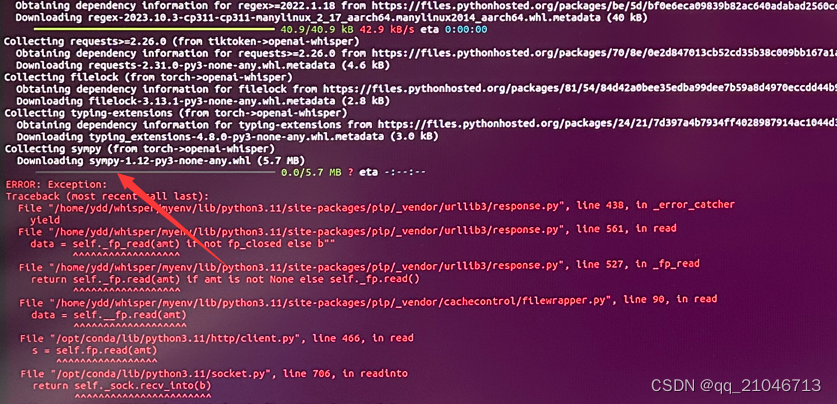
这个情况基本都是下载失败,注意看其中失败的包名。一直自动安装是行不通了,我们可以手动装,使用这个命令用清华的源进行单独安装(xxxxx等于包名)。后续还会有很多这类报错,报哪个就手动装哪个,反复执行上面的安装命令。不想手动装的可以把源配置好。
pip install xxxxx -i https://pypi.tuna.tsinghua.edu.cn/simple/
换成
pip install sympy -i https://pypi.tuna.tsinghua.edu.cn/simple/如果执行安装命令后很顺利从头到尾都没有报错或者解决了所有报错,那么将会得到如下结果,列出了各个依赖包的版本即是完成Whisper安装。

在GitHub中还指明了,需要安装ffmpeg和rust,这两个直接apt-get install xxx即可。
使用Whisper
安装完成我们试一下命令(说明:应用 音频文件路径/文件 使用的语言模型 直接指明转中文否则有30s的自动识别时间 使用硬件GPU加速),每一个模型,第一次使用都会先下载。
whisper audio.mp3 --model medium --language Chinese --device cuda顺利的话能运行,使用jtop就看到GPU占用率很高表明正常运行。如果出问题,将会收到这样的报错:

意思是CPU不支持FP16,尝试转向FP32。这个情况基本就能看出自己的pytorch不支持GPU硬件加速而报错的了。
让pytorch支持GPU
这方面参考比较零散,先参考PC端的操作一下。如何在linux中安装OpenAI开源的项目Whisper。先试一下自己的环境是否真的不支持,在上面的参考文件中有这么一段
python
import torch
torch.__version__
torch.cuda.is_available()
其中最后一句是关键,只有返回Ture,才能让Whisper使用显卡进行转录,否则是使用CPU进行转录。如果最后一句返回的是False,那么可能是你安装的PyTorch版本中使用的CUDA版本和你服务器中已经安装的CUDA版本不一致。
把现有的pytorch卸载了,此时不能再pip install xxx进行安装。我们需要去英伟达官网下载一个支持GPU的pytorch来安装。这个可以参考,做图像类的一般都配置过,比如Nvida jetson nano 学习 : Aarch64 平台 安装GPU版本的 pytorch里面就讲到了,下载时候需要对应的版本,使用jtop查看
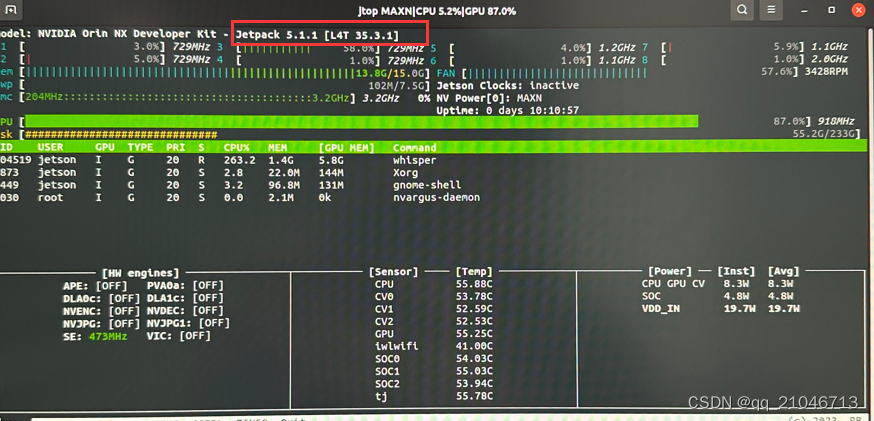
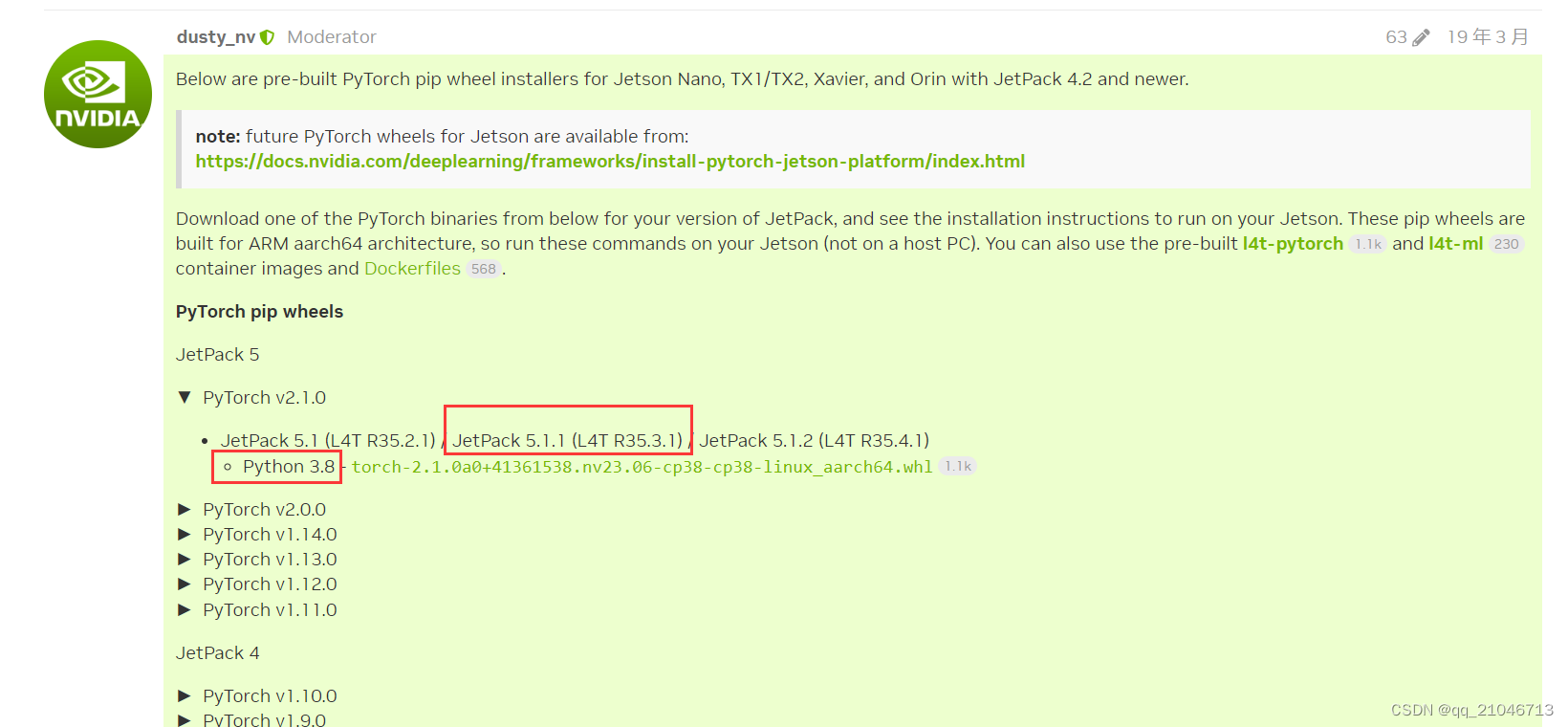
下载后的pytorch包使用如下命令安装,如果一开始就指定了py虚拟环境为py3.8那会很顺利装上。
pip3 install torch-1.8.0-cp36-cp36m-linux_aarch64.whl如果一开始忘记指明虚拟环境py版本,这个命令是装不上的,总不能把虚拟环境删了从来一遍吧。 参考了其它方法也是不理想,要么是删了要么是修改虚拟环境变量py版本,甚至还有自己动手编译的,~可怕。其实我们可以这样,它就是个py读取的并安装包,只要找到对应的py应用版本来解释它就可以了。先看看这个系统上有哪些python版本(包括虚拟环境和宿主机)

于是安装命令就变成,
pip3.8 install torch-1.8.0-cp36-cp36m-linux_aarch64.whl安装如下
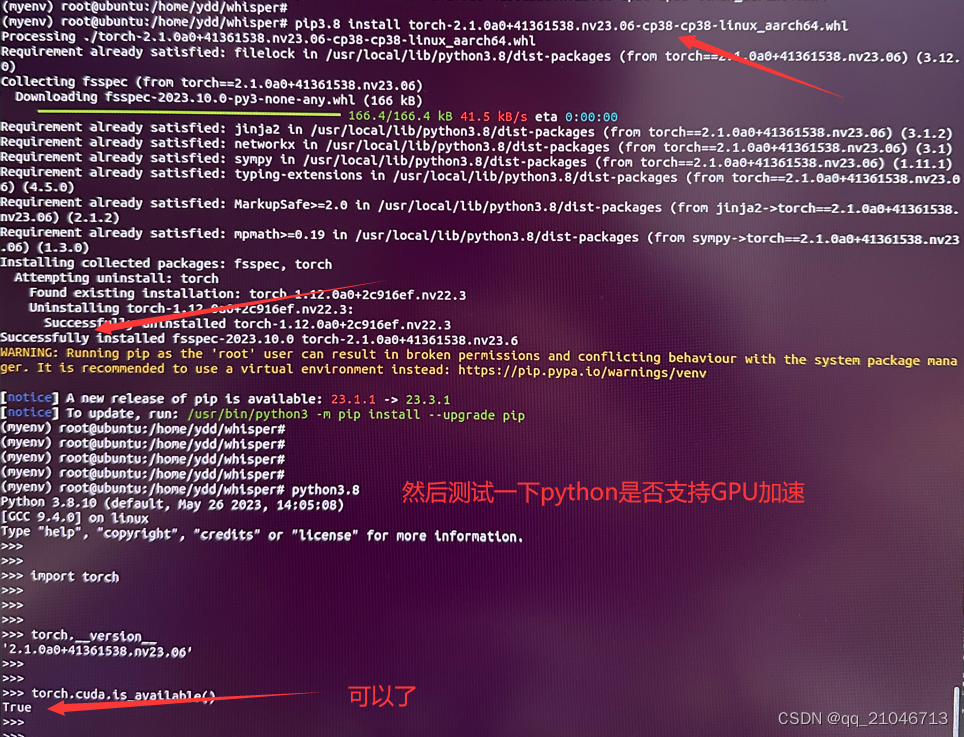
之后,运行所需的环境将安装完毕,回到上面的“使用whisper”进行转换即可。我们可以使用TTS(文字转语音)生成一个MP3或者自己录一段。 TTSMaker在线生成工具。转换过程如下

GPU会直接被加载爆满,1024个核心全速运转,30s的视频转了1分钟左右,使用的是medium模型,这个模型1.4G,效果还是可以的。使用tiny等小模型转出来的效果很差劲。此时显存已经压到~10G了,再大的模型不能运行了,根据说明,模型越大转换越好,前提硬件要能撑得住。转换过程是不能单独输出的,转换完成会一次性输出,同时文件夹下会生成6个文件存放结果。如果需要转换过程输出,可以使用--task参数,但是目前只支持英文。
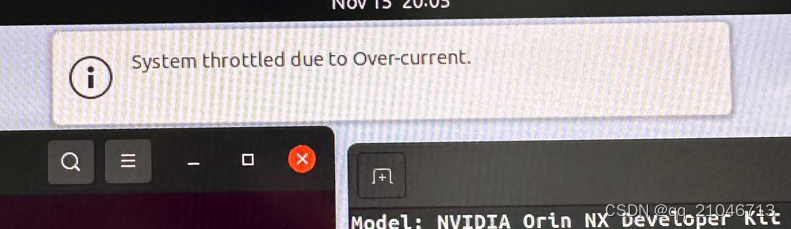
在系统满负荷运行的时候会弹出这个提示,系统限流,解决方法是设置电流
echo 5000 > /sys/devices/c250000.i2c/i2c-7/7-0040/iio:device0/crit_current_limit_0项目需求并不是要一次性转出,后续再研究研究........
#end