学前小故事
[我是redis]
你好,我是Redis,一个叫Antirez的男人把我带到了这个世界上。
说起我的诞生,跟关系数据库MySQL还挺有渊源的。

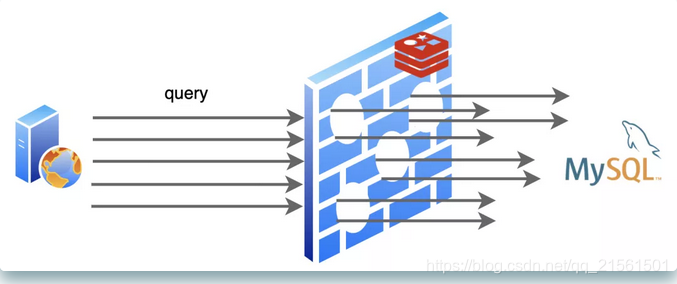
在我还没来到这个世界上的时候,MySQL过的很辛苦,互联网发展的越来越快,它容纳的数据也越来越多,用户请求也随之暴涨,而每一个用户请求都变成了对它的一个又一个读写操作,MySQL是苦不堪言。尤其是到“双11”、“618“这种全民购物狂欢的日子,都是MySQL受苦受难的日子。
据后来MySQL告诉我说,其实有一大半的用户请求都是读操作,而且经常都是重复查询一个东西,浪费它很多时间去进行磁盘I/O。
后来有人就琢磨,是不是可以学学CPU,给数据库也加一个缓存呢?于是我就诞生了!
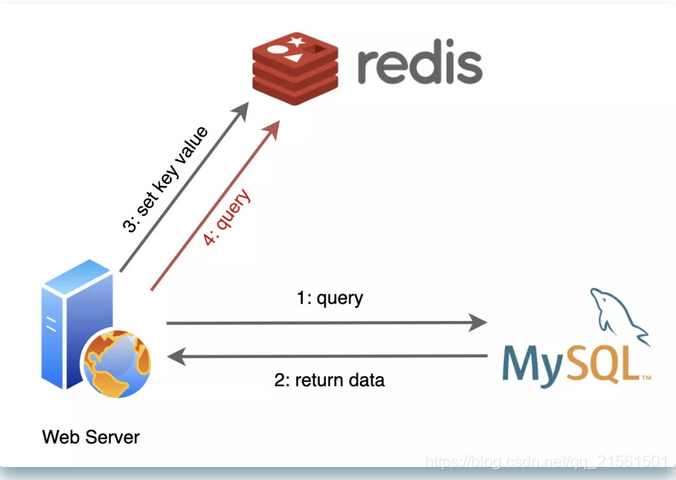
出生不久,我就和MySQL成为了好朋友,我们俩常常携手出现在后端服务器中。
应用程序们从MySQL查询到的数据,在我这里登记一下,后面再需要用到的时候,就先找我要,我这里没有再找MySQL要。
为了方便使用,我支持好几种数据结构的存储:
* String
* Hash
* List
* Set
* SortedSet
* Bitmap
因为我把登记的数据都记录在内存中,不用去执行慢如蜗牛的I/O操作,所以找我要比找MySQL要省去了不少的时间呢。
可别小瞧这简单的一个改变,我可为MySQL减轻了不小的负担!随着程序的运行,我缓存的数据越来越多,有相当部分时间我都给它挡住了用户请求,这一下它可乐得清闲自在了!
有了我的加入,网络服务的性能提升了不少,这都归功于我为数据库挨了不少枪子儿。
缓存过期 && 缓存淘汰
[缓存过期 && 缓存淘汰]
不过很快我发现事情不妙了,我缓存的数据都是在内存中,可是就算是在服务器上,内存的空间资源还是很有限的,不能无节制的这么存下去,我得想个办法,不然吃枣药丸。
不久,我想到了一个办法:给缓存内容设置一个超时时间,具体设置多长交给应用程序们去设置,我要做的就是把过期了的内容从我里面删除掉,及时腾出空间就行了。
超时时间有了,我该在什么时候去干这个清理的活呢?
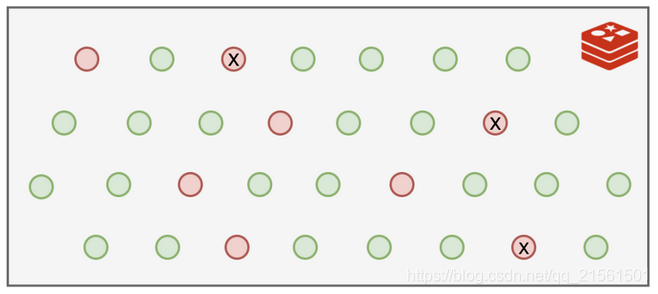
最简单的就是定期删除,我决定100ms就做一次,一秒钟就是10次!
我清理的时候也不能一口气把所有过期的都给删除掉,我这里面存了大量的数据,要全面扫一遍的话那不知道要花多久时间,会严重影响我接待新的客户请求的!
时间紧任务重,我只好随机选择一部分来清理,能缓解内存压力就行了。
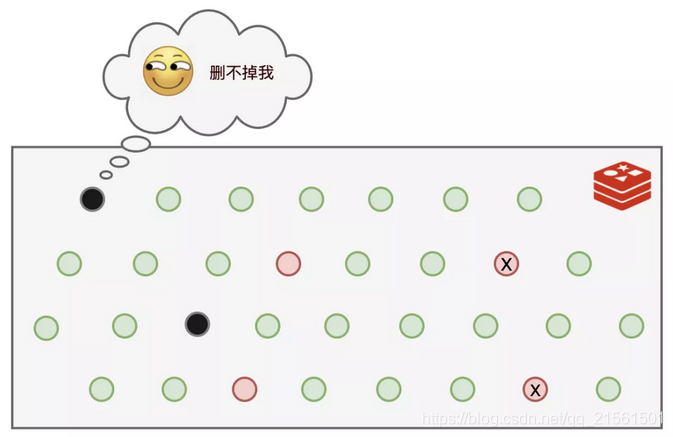
就这样过了一段日子,我发现有些个键值运气比较好,每次都没有被我的随机算法选中,每次都能幸免于难,这可不行,这些长时间过期的数据一直霸占着不少的内存空间!气抖冷!
我眼里可揉不得沙子!于是在原来定期删除的基础上,又加了一招:
那些原来逃脱我随机选择算法的键值,一旦遇到查询请求,被我发现已经超期了,那我就绝不客气,立即删除。
这种方式因为是被动式触发的,不查询就不会发生,所以也叫惰性删除!
可是,还是有部分键值,既逃脱了我的随机选择算法,又一直没有被查询,导致它们一直逍遥法外!而于此同时,可以使用的内存空间却越来越少。
而且就算退一步讲,我能够把过期的数据都删除掉,那万一过期时间设置的很长,还没等到我去清理,内存就吃满了,一样要吃枣药丸,所以我还得想个办法。
我苦思良久,终于憋出了个大招:内存淘汰策略,这一次我要彻底解决问题!
我提供了8种策略供应用程序选择,用于我遇到内存不足时该如何决策:
* noeviction:返回错误,不会删除任何键值
* allkeys-lru:使用LRU算法删除最近最少使用的键值
* volatile-lru:使用LRU算法从设置了过期时间的键集合中删除最近最少使用的键值
* allkeys-random:从所有key随机删除
* volatile-random:从设置了过期时间的键的集合中随机删除
* volatile-ttl:从设置了过期时间的键中删除剩余时间最短的键
* volatile-lfu:从配置了过期时间的键中删除使用频率最少的键
* allkeys-lfu:从所有键中删除使用频率最少的键
有了上面几套组合拳,我再也不用担心过期数据多了把空间撑满的问题了~
缓存穿透 && 布隆过滤器
[缓存穿透 && 布隆过滤器]
我的日子过的还挺舒坦,不过MySQL大哥就没我这么舒坦了,有时候遇到些烦人的请求,查询的数据不存在,MySQL就要白忙活一场!不仅如此,因为不存在,我也没法缓存啊,导致同样的请求来了每次都要去让MySQL白忙活一场。我作为缓存的价值就没得到体现啦!这就是人们常说的缓存穿透。
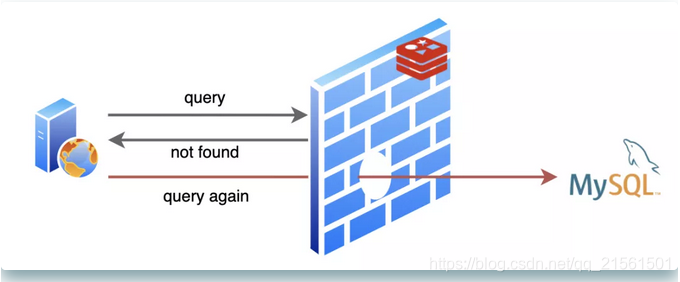
这一来二去,MySQL大哥忍不住了:“唉,兄弟,能不能帮忙想个办法,把那些明知道不会有结果的查询请求给我挡一下”
这时我想到了我的另外一个好朋友:布隆过滤器
我这位朋友别的本事没有,就擅长从超大的数据集中快速告诉你查找的数据存不存在(悄悄告诉你,我的这位朋友有一点不靠谱,它告诉你存在的话不能全信,其实有可能是不存在的,不过它他要是告诉你不存在的话,那就一定不存在)。
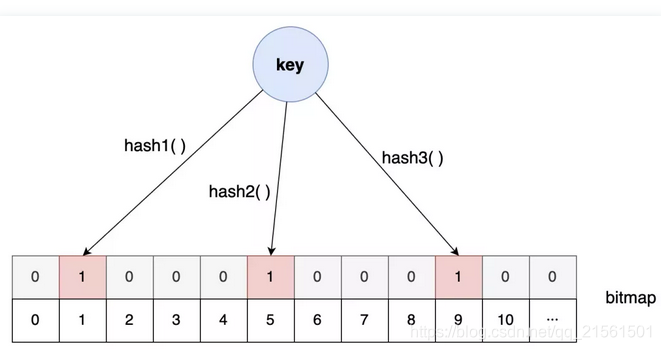
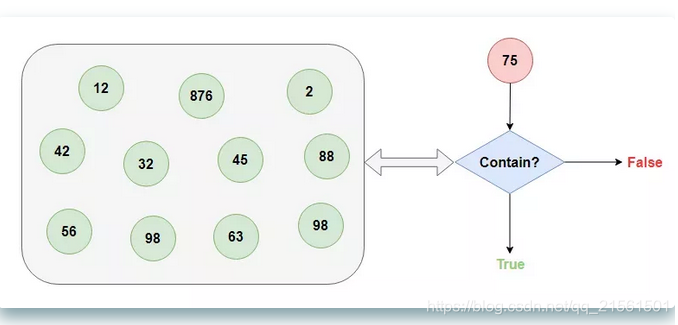
我把这位朋友介绍给了应用程序,不存在的数据就不必去叨扰MySQL了,轻松帮忙解决了缓存穿透的问题。
缓存击穿 && 缓存雪崩
[缓存击穿 && 缓存雪崩]
这之后过了一段时间太平日子,直到那一天···
有一次,MySQL那家伙正优哉游哉的摸鱼,突然一大堆请求给他怼了过去,给他打了一个措手不及。
一阵忙活之后,MySQL怒气冲冲的找到了我,“兄弟,咋回事啊,怎么一下子来的这么猛”
我查看了日志,赶紧解释到:“大哥,实在不好意思,刚刚有一个热点数据到了过期时间,被我删掉了,不巧的是随后就有对这个数据的大量查询请求来了,我这里已经删了,所以请求都发到你那里来了”
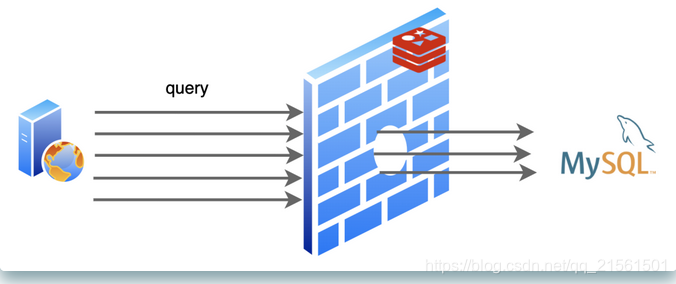
“你这干的叫啥事,下次注意点啊”,MySQL大哥一脸不高兴的离开了。
这一件小事我也没怎么放在心上,随后就抛之脑后了,却没曾想几天之后竟捅了更大的篓子。
那一天,又出现了大量的网络请求发到了MySQL那边,比上一次的规模大得多,MySQL大哥一会儿功夫就给干趴下了好几次!
等了好半天这一波流量才算过去,MySQL才缓过神来。
“老弟,这一次又是什么原因?”,MySQL大哥累的没了力气。
“这一次比上一次更不巧,这一次是一大批数据几乎同时过了有效期,然后又发生了很多对这些数据的请求,所以比起上一次这规模更大了”
MySQL大哥听了眉头一皱,“那你倒是想个办法啊,三天两头折磨我,这谁顶得住啊?”
“其实我也很无奈,这个时间也不是我设置的,要不我去找应用程序说说,让他把缓存过期时间设置的均匀一些?至少别让大量数据集体失效”
“走,咱俩一起去”
后来,我俩去找应用程序商量了,不仅把键值的过期时间随机了一下,还设置了热点数据永不过期,这个问题缓解了不少。哦对了,我们还把这两次发生的问题分别取了个名字:缓存击穿和缓存雪崩。
我们终于又过上了舒适的日子···
数据库和缓存保证一致性
一天,老板说「最近公司的用户越来越多了,但是服务器的访问速度越来越差的,阿旺帮我优化下,做好了给你画个饼!」。
程序员阿旺听到老板口中的「画饼」后就非常期待,没有任何犹豫就接下了老板给的这个任务。
阿旺登陆到了服务器,经过一番排查后,确认服务器的性能瓶颈是在数据库。
这好办,给服务器加上 Redis,让其作为数据库的缓存。
这样,在客户端请求数据时,如果能在缓存中命中数据,那就查询缓存,不用在去查询数据库,从而减轻数据库的压力,提高服务器的性能。
阿旺有了这个想法后,就准备开始着手优化服务器,但是挡在在他前面的是这样的一个问题。
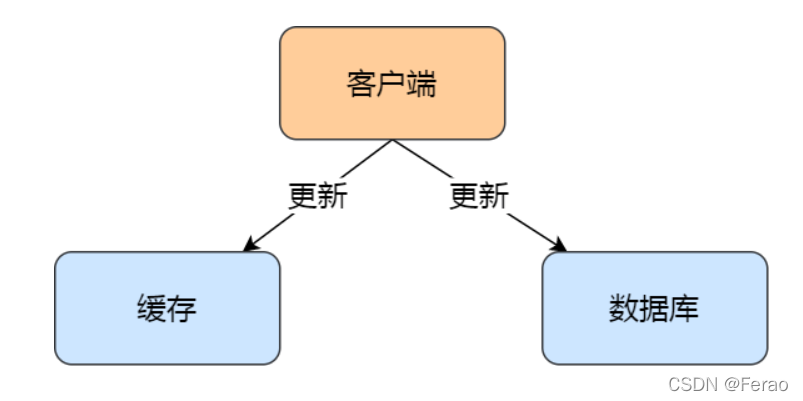
由于引入了缓存,那么在数据更新时,不仅要更新数据库,而且要更新缓存,这两个更新操作存在前后的问题:
• 先更新数据库,再更新缓存;
• 先更新缓存,再更新数据库;
先更新数据库,再更新缓存
[先更新数据库,还是先更新缓存?]
阿旺没想到太多,他觉得最新的数据肯定要先更新数据库,这样才可以确保数据库里的数据是最新的,于是他就采用了「先更新数据库,再更新缓存」的方案。
阿旺经过几个夜晚的折腾,终于「优化好了服务器」,然后就直接上线了,自信心满满跑去跟老板汇报。
老板不懂技术,自然也没多虑,就让后续阿旺观察下服务器的情况,如果效果不错,就跟阿旺谈画饼的事情。
阿旺观察了好几天,发现数据库的压力大大减少了,访问速度也提高了不少,心想这事肯定成的了。
好景不长,突然老板收到一个客户的投诉,客户说他刚发起了两次更新年龄的操作,但是显示的年龄确还是第一次更新时的年龄,而第二次更新年龄并没有生效。
老板立马就找了阿旺,训斥着阿旺说:「这么简单的更新操作,都有 bug?我脸往哪儿放?你的饼还要不要了?」
听到自己准备到手的饼要没了的阿旺瞬间就慌了,立马登陆服务器排查问题,阿旺查询缓存和数据库的数据后发现了问题。
数据库的数据是客户第二次更新操作的数据,而缓存确还是第一次更新操作的数据,也就是出现了数据库和缓存的数据不一致的问题。
这个问题可大了,阿旺经过一轮的分析,造成缓存和数据库的数据不一致的现象,是因为并发问题!
举个例子,比如「请求 A 」和「请求 B 」两个请求,同时更新「同一条」数据,则可能出现这样的顺序:
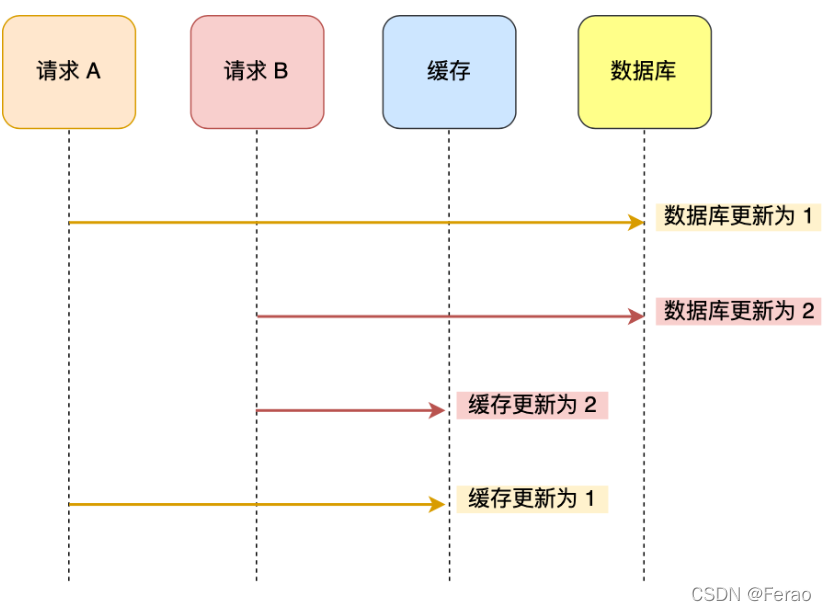
A 请求先将数据库的数据更新为 1,然后在更新缓存前,请求 B 将数据库的数据更新为 2,紧接着也把缓存更新为 2,然后 A 请求更新缓存为 1。
此时,数据库中的数据是 2,而缓存中的数据却是 1,出现了缓存和数据库中的数据不一致的现象。
先更新缓存,再更新数据库
[先更新缓存,再更新数据库?]
那换成「先更新缓存,再更新数据库」这个方案,还会有问题吗?
依然还是存在并发的问题,分析思路也是一样。
假设「请求 A 」和「请求 B 」两个请求,同时更新「同一条」数据,则可能出现这样的顺序:
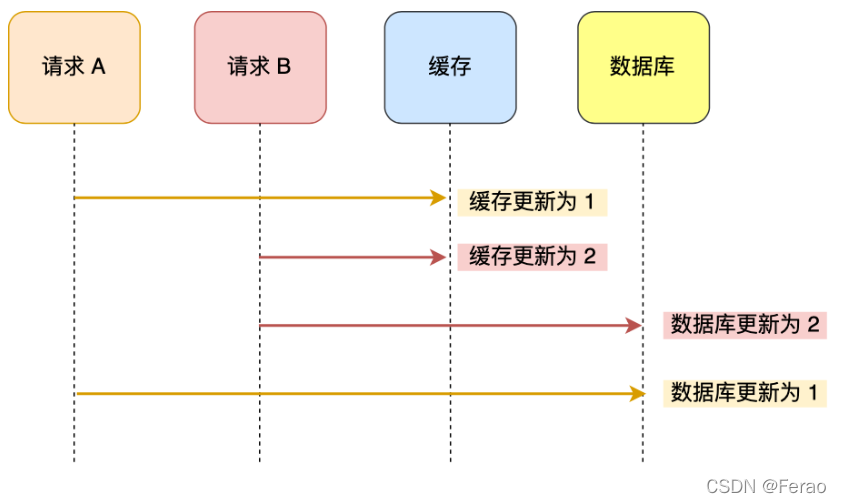
A 请求先将缓存的数据更新为 1,然后在更新数据库前,B 请求来了, 将缓存的数据更新为 2,紧接着把数据库更新为 2,然后 A 请求将数据库的数据更新为 1。
此时,数据库中的数据是 1,而缓存中的数据却是 2,出现了缓存和数据库中的数据不一致的现象。
所以,无论是「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题,当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象。
先更新数据库,还是先删除缓存?
[先更新数据库,还是先删除缓存?]
阿旺定位出问题后,思考了一番后,决定在更新数据时,不更新缓存,而是删除缓存中的数据。然后,到读取数据时,发现缓存中没了数据之后,再从数据库中读取数据,更新到缓存中。
阿旺想的这个策略是有名字的,是叫 Cache Aside 策略,中文是叫旁路缓存策略。
该策略又可以细分为「读策略」和「写策略」。
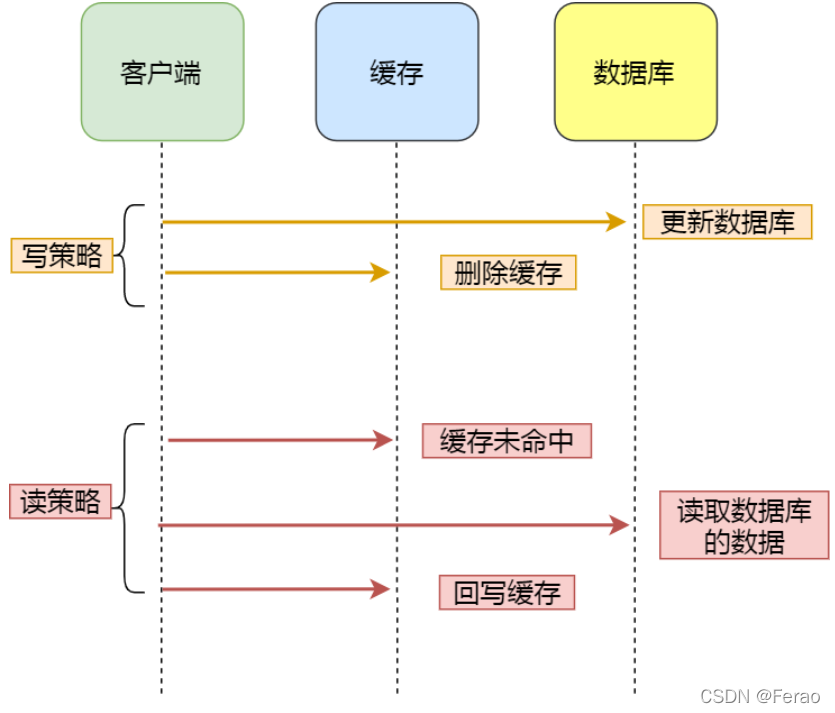
写策略的步骤:
• 更新数据库中的数据
• 删除缓存中的数据
读策略的步骤:
• 如果读取的数据命中了缓存,则直接返回数据
• 如果读取的数据没有命中缓存,则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户
阿旺在想到「写策略」的时候,又陷入更深层次的思考,到底该选择哪种顺序呢?
• 先删除缓存,再更新数据库;
• 先更新数据库,再删除缓存。
阿旺这次经过上次教训,不再「想当然」的乱选方案,因为老板这次给的饼很大啊,必须把握住。
于是阿旺用并发的角度来分析,看看这两种方案哪个可以保证数据库与缓存的数据一致性。
先删除缓存,再更新数据库
[先删除缓存,再更新数据库]
阿旺还是以用户表的场景来分析。
假设某个用户的年龄是 20,请求 A 要更新用户年龄为 21,所以它会删除缓存中的内容。这时,另一个请求 B 要读取这个用户的年龄,它查询缓存发现未命中后,会从数据库中读取到年龄为 20,并且写入到缓存中,然后请求 A 继续更改数据库,将用户的年龄更新为 21。
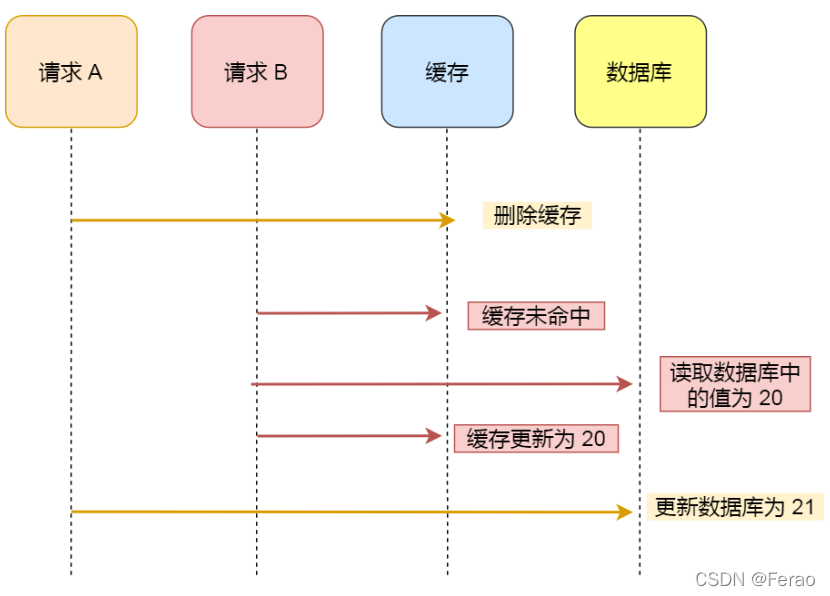
最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库的数据不一致。
可以看到,先删除缓存,再更新数据库,在「读 + 写」并发的时候,还是会出现缓存和数据库的数据不一致的问题。
先更新数据库,再删除缓存
[先更新数据库,再删除缓存]
继续用「读 + 写」请求的并发的场景来分析。
假如某个用户数据在缓存中不存在,请求 A 读取数据时从数据库中查询到年龄为 20,在未写入缓存中时另一个请求 B 更新数据。它更新数据库中的年龄为 21,并且清空缓存。这时请求 A 把从数据库中读到的年龄为 20 的数据写入到缓存中。
最终,该用户年龄在缓存中是 20(旧值),在数据库中是 21(新值),缓存和数据库数据不一致。
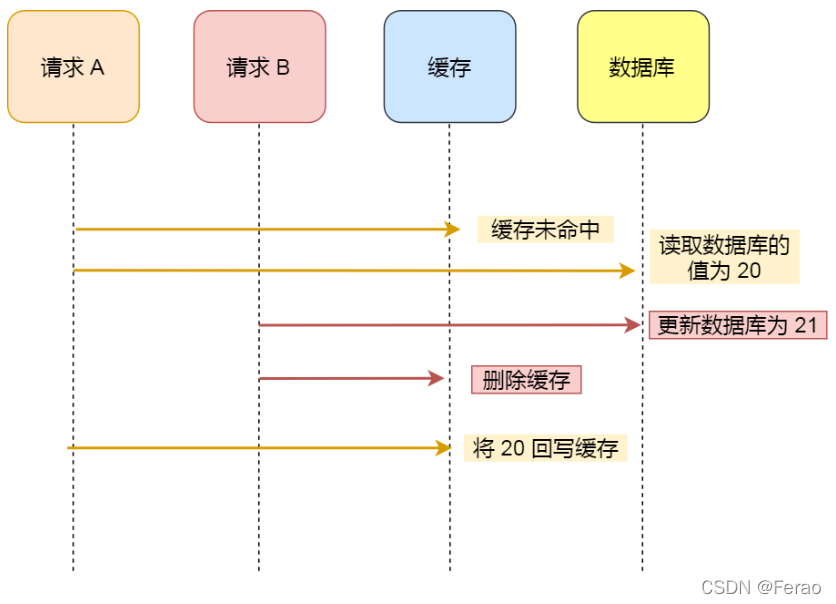
从上面的理论上分析,先更新数据库,再删除缓存也是会出现数据不一致性的问题,但是在实际中,这个问题出现的概率并不高。
因为缓存的写入通常要远远快于数据库的写入,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。
而一旦请求 A 早于请求 B 删除缓存之前更新了缓存,那么接下来的请求就会因为缓存不命中而从数据库中重新读取数据,所以不会出现这种不一致的情况。
所以,「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的。
而且阿旺为了确保万无一失,还给缓存数据加上了「过期时间」,就算在这期间存在缓存数据不一致,有过期时间来兜底,这样也能达到最终一致。
阿旺思考到这一步后,觉得自己真的是个小天才,因为他竟然想到了个「天衣无缝」的方案,他二话不说就采用了这个方案,又经过几天的折腾,终于完成了。
他自信满满的向老板汇报,已经解决了上次客户的投诉的问题了。老板觉得阿旺这小伙子不错,这么快就解决问题了,然后让阿旺在观察几天。
先更新数据库,再删除缓存(失败)
事情哪有这么顺利呢?结果又没过多久,老板又收到客户的投诉了,说自己明明更新了数据,但是数据要过一段时间才生效,客户接受不了。
老板面无表情的找上阿旺,让阿旺尽快查出问题。
阿旺得知又有 Bug 就更慌了,立马就登录服务器去排查问题,查看日志后得知了原因。
「先更新数据库, 再删除缓存」其实是两个操作,前面的所有分析都是建立在这两个操作都能同时执行成功,而这次客户投诉的问题就在于,在****删除缓存(第二个操作)的时候失败了,导致缓存中的数据是旧值。
好在之前给缓存加上了过期时间,所以才会出现客户说的过一段时间才更新生效的现象,假设如果没有这个过期时间的兜底,那后续的请求读到的就会一直是缓存中的旧数据,这样问题就更大了。
所以新的问题来了,如何保证「先更新数据库 ,再删除缓存」这两个操作能执行成功?
阿旺分析出问题后,慌慌张张的向老板汇报了问题。
老板知道事情后,又给了阿旺几天来解决这个问题,画饼的事情这次没有再提了。
阿旺会用什么方式来解决这个问题呢?
老板画的饼事情,能否兑现给阿旺呢?
[如何保证两个操作都能执行成功?]
这次用户的投诉是因为在删除缓存(第二个操作)的时候失败了,导致缓存还是旧值,而数据库是最新值,造成数据库和缓存数据不一致的问题,会对敏感业务造成影响。
举个例子,来说明下。
应用要把数据 X 的值从 1 更新为 2,先成功更新了数据库,然后在 Redis 缓存中删除 X 的缓存,但是这个操作却失败了,这个时候数据库中 X 的新值为 2,Redis 中的 X 的缓存值为 1,出现了数据库和缓存数据不一致的问题。
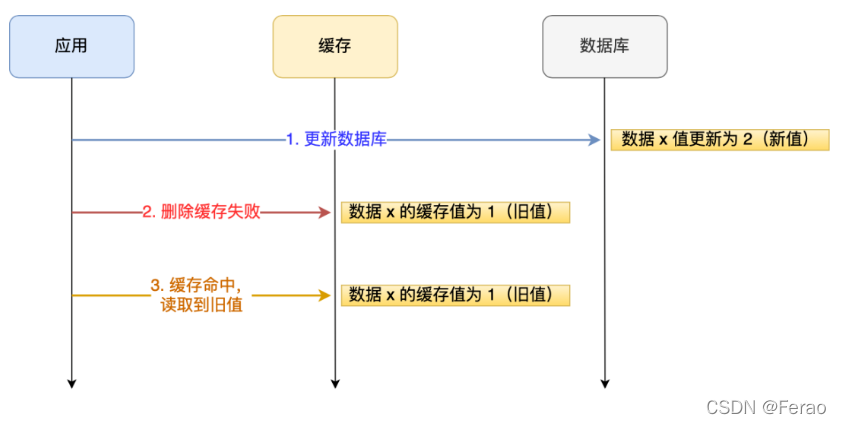
那么,后续有访问数据 X 的请求,会先在 Redis 中查询,因为缓存并没有 诶删除,所以会缓存命中,但是读到的却是旧值 1。
其实不管是先操作数据库,还是先操作缓存,只要第二个操作失败都会出现数据一致的问题。
问题原因知道了,该怎么解决呢?有两种方法:
• 重试机制
• 订阅 MySQL binlog,再操作缓存
重试机制
重试机制
我们可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
• 如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
• 如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
举个例子,来说明重试机制的过程。
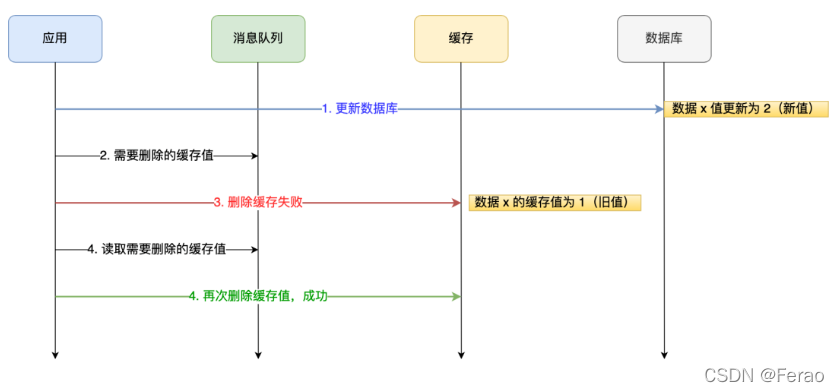
订阅 MySQL binlog
订阅 MySQL binlog,再操作缓存
「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
下图是 Canal 的工作原理:
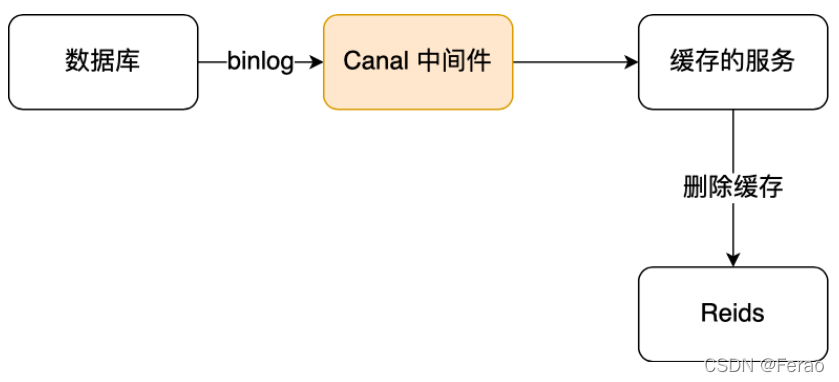
所以,如果要想保证「先更新数据库,再删缓存」策略第二个操作能执行成功,我们可以使用「消息队列来重试缓存的删除」,或者「订阅 MySQL binlog 再操作缓存」,这两种方法有一个共同的特点,都是采用异步操作缓存。
redis安装及使用
-
windows安装redis
-
下载地址
-
使用步骤
• 解压
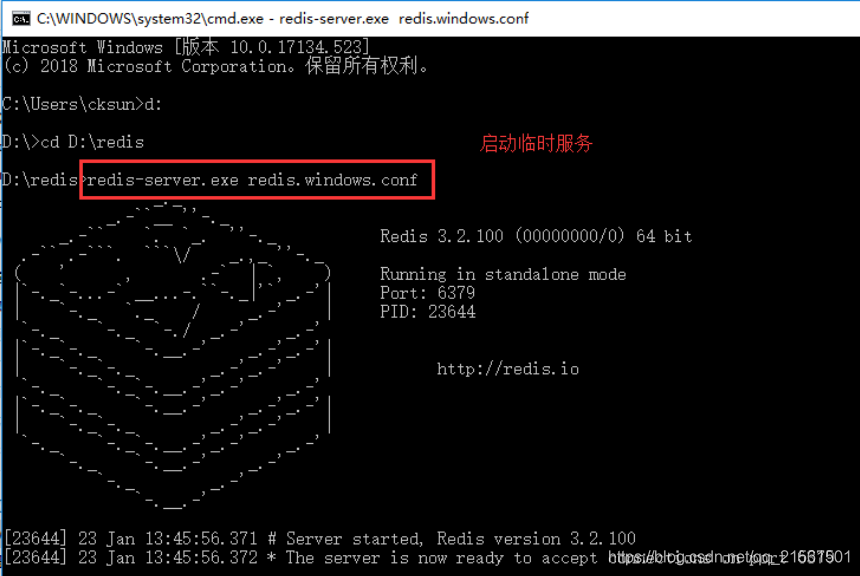
• 启动服务端临时服务打开cmd,进入到刚才解压到的目录,启动临时服务:redis-server.exe redis.windows.conf
通过这个命令,会创建redis临时服务,不会在window Service列表出现redis服务名称和状态,此窗口关闭,服务会自动关闭。
• 启动客户端临时服务
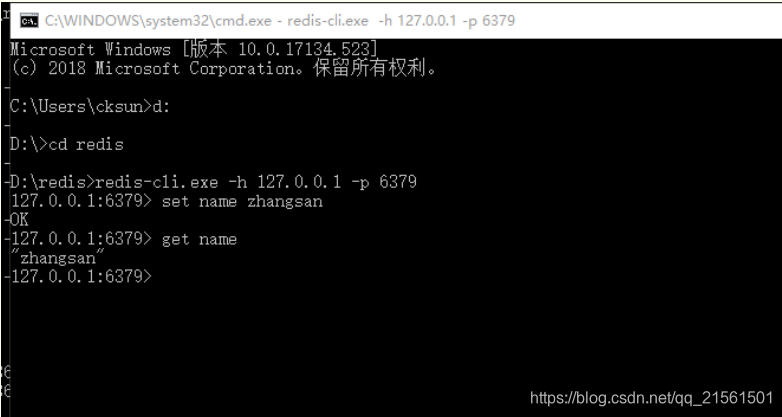
打开另一个cmd窗口,进入到刚才解压到的目录,启动临时服务: || redis-cli.exe -h 127.0.0.1 -p 6379
测试非关系型数据库redis是否部署成功,存入 键值对为name zhangsan 的数据 get name 即从redis 中获取键为Name 的 value 值。
• 打开redis.windows.conf,进行持久化配置、端口修改、登录密码等配置
• 自定义windows服务,脱离cmd窗口限制
• 安装redis图形化管理界面
• 简单主从redis服务器搭建 -
相关截图 [解压阶段]
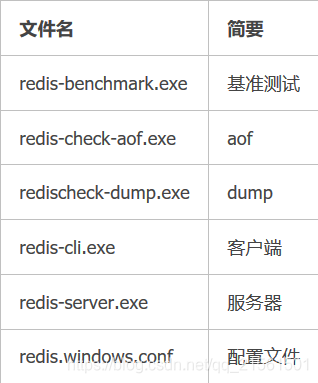
2.文件名简要
[注]redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-3.2.100.zip压缩包到 D 盘redis文件夹下。
[注]redis.windows.conf是redis的配置文件,用于持久化配置,端口修改等配置。
-
相关截图 [部署阶段]
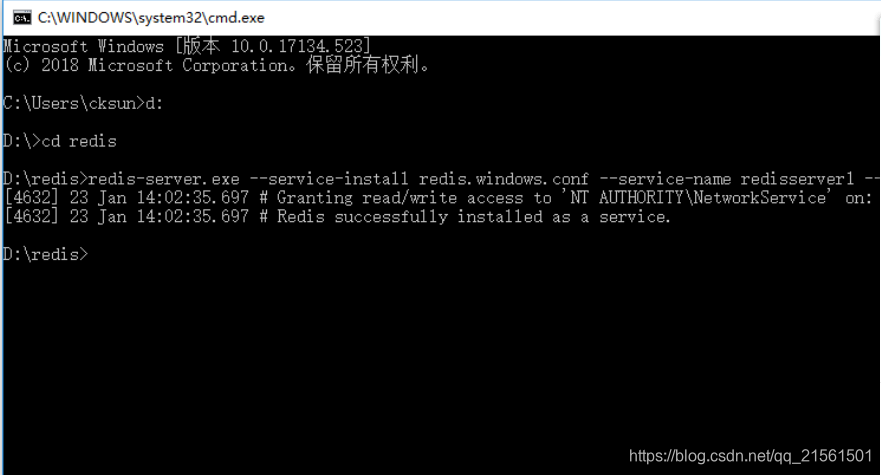
3.redis自定义windows服务安装,脱离cmd启动的局限;进入redis安装目录,安装服务 ||
redis-server.exe --service-install redis.windows.conf --service-name redisserver1 --loglevel verbose
4.查看服务安装状况 || cmd窗口 ->win+r -> services.msc[注]
启动服务:redis-server.exe --service-start --service-name redisserver1
停止服务:redis-server.exe --service-stop --service-name redisserver1
卸载服务:redis-server.exe --service-uninstall--service-name redisserver1主从服务器
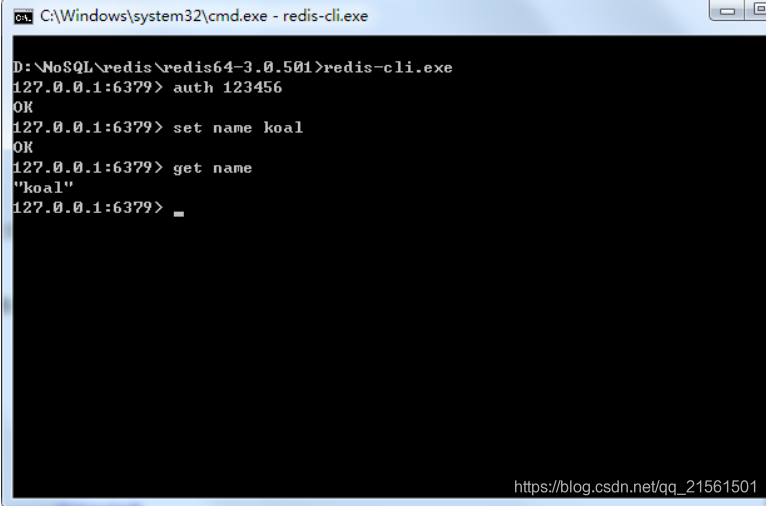
将d盘下新建一个文件夹叫redis2,把redis文件夹的东西拷贝到redis2文件夹下,将 redis-windows.conf配置文件中的ip 和端口号改一下,然后按照上面的步骤安装一个服务 即可 设置密码,redis-windows.conf配置文件中,找到 #requirepass foobared #号去掉,requirepass 密码 之后再启动服务后,要使用redis就需要输入密码了
-
-
linux安装redis
https://redis.io/ 安装包下载地址 tar -zxvf redis-5.0.8.tar.gz 解压安装包 yum install gcc- c++ (redis目录下)安装环境 gcc -v (redis目录下) make (redis目录下) make install (redis目录下) cd /usr/local/bin mkdir FeraoRedisConfig (bin 目录下) cp /usr/redis/redis-5.0.8/redis.conf FeraoRedisConfig (bin 目录下)之后使用这个配置文件进行启动 vim redis.conf (FeraoRedisConfig目录下) redis默认不是后台启动的,需要修改配置文件 更改daemonize yes redis-server FeraoRedisConfig/redis.conf (/usr/local/bin目录下) 通过指定配置文件启动 redis-cli -p 6379 (/usr/local/bin目录下) 使用redis-cli进行测试连接 ping 测试是否连接成功 ps -ef|grep redis 新开一个窗口,查看后台进程 shutdown 关闭redis连接(关闭redi服务步骤一) exit 退出(关闭redi服务步骤二)
Redis
-
基础知识
-
基础命令
dbsize 当前redis库的大小 select 7 切换redis库 keys * 当前redis库存储的所有key flushdb 清除当前redis库中所有数据 flushall 清除全部redis库中数据 config get requirepass 当前使用的密码 set requirepass "123456"设置密码 auth 123456 输入密码 info replication 查看当前库的信息 -
细节
1. redis默认有16个数据库(配置文件中内容),默认使用的是第0个 2. redis是单线程的 redis是基于内存操作,CPU不是redis性能瓶颈,redis的瓶颈是根据机器的内存和网络带宽。 并且redis是c语言写的,官方提供的数据未100000+的QPS,完全不比同样是使用key-value 的memecache差
-
redis 数据结构
redis存储的是(key,value)格式数据,其中Key都是字符串,value有5种不同的数据结构
* String
* List
* Set
* SortedSet
* Hash
* Bitmap
-
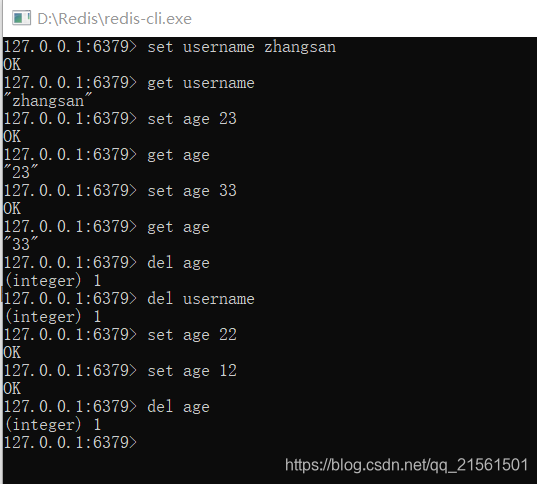
String(字符串)
操作 命令 存储 set key value 获取 get key 删除 del key -
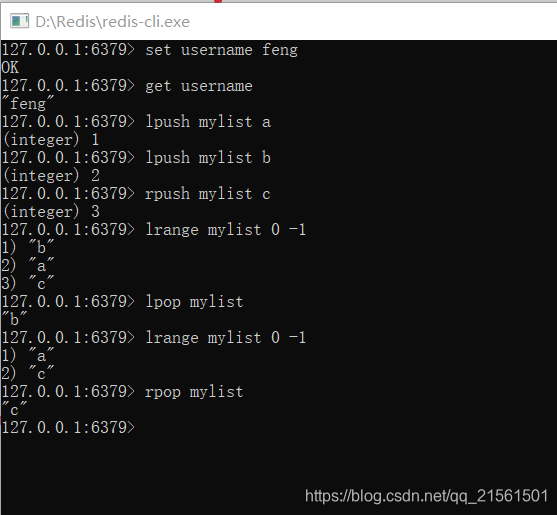
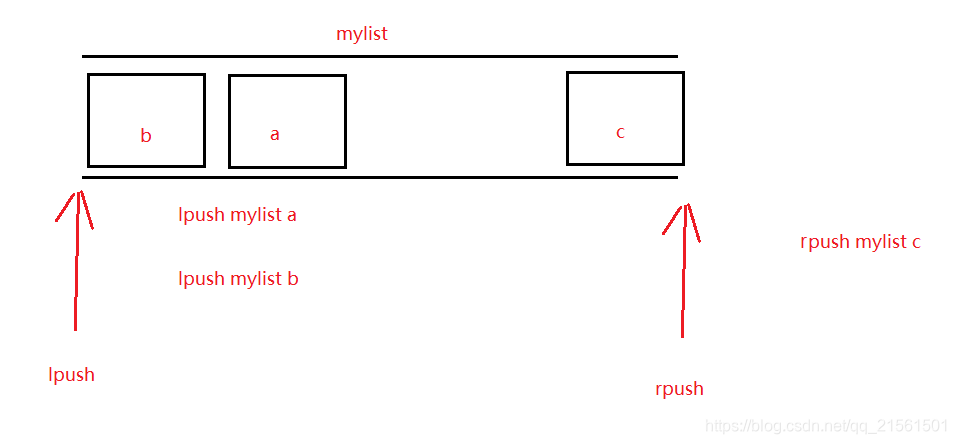
List(List有序列表)
操作 命令 存储(将元素加入列表左表 ) lpush key value 存储(将元素加入列表右边 ) rpush key value 获取 lrange key start end 删除( 删除列表最左边的元素,并将元素返回) lpop key 删除(删除列表最右边的元素,并将元素返回) rpop key -
Set(Set集合)
不允许重复元素
操作 命令 存储 sadd key value 获取 smembers key 删除(删除集合中某个元素) srem key value -
SortedSet(有序Set集合结构)
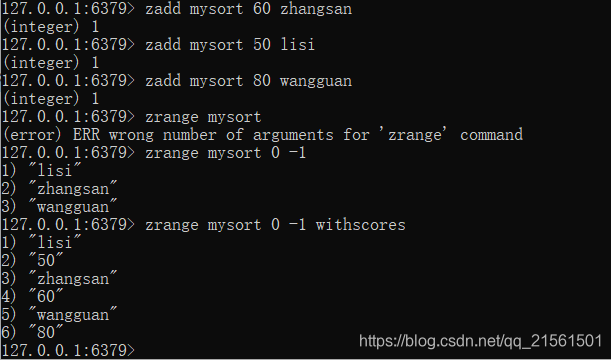
不允许重复元素,且元素有顺序,每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序
操作 命令 存储 zadd key score value 获取 zrange key start end 删除 zrem key value -
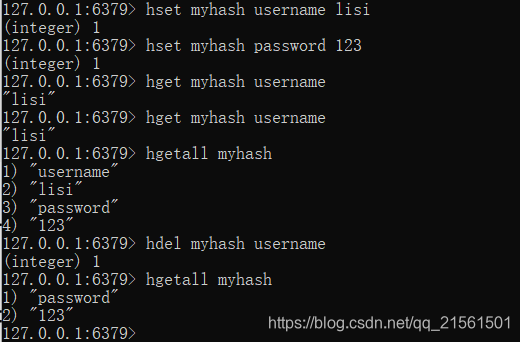
Hash(哈希结构)
操作 命令 存储 hset key field value 获取(获取指定的field对应的值 ) hget key field 获取(获取所有的field和value ) hgetall key 删除 hdel key field -
Bitmap()
在此基础上redis提供了通用的命令:
| 操作 | 命令 |
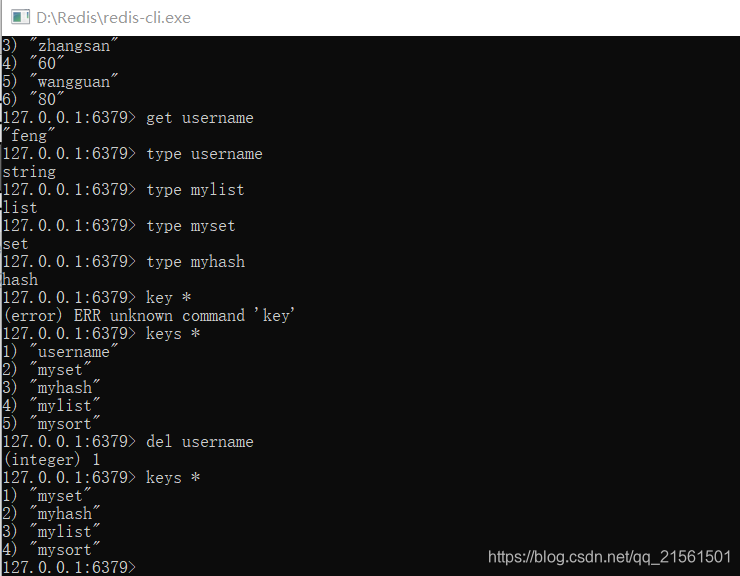
|---|---|
| 查询所有键 | key * |
| 获取键对应的value类型 | tepe key |
| 删除指定的Key,value | del key |
redis 配置文件
-
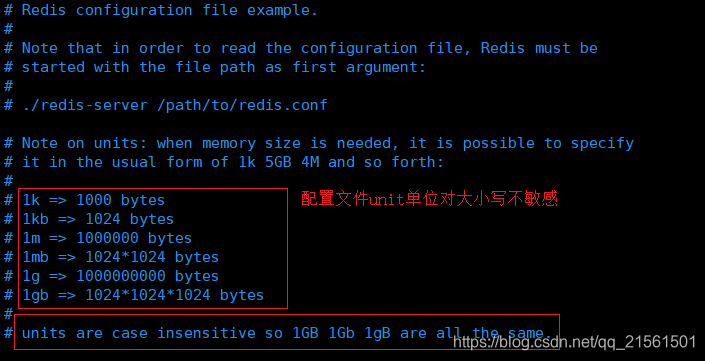
单位
-
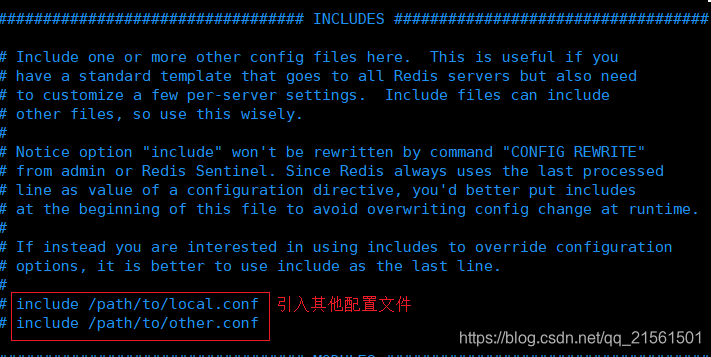
引入配置文件
-
网络
bind 127.0.0.1 绑定的ip protected-mode yew 保护模式 port 6379 端口设置 -
通用 GENERAL
Daemonize yes 以守护进程的方式进行,默认是no,开发者需要自己开启为yes pidfile /var/run/redis_6379.pid 如果以后台的方式运行,我们就需要制定一个pid文件 loglevel notice 日志水平(debug、verbose、notice、warning) logfile "" 日志的文件位置名 databases 16 数据库的数量,默认是16个数据库 always-show-logo yes 是否总是显示Logo -
快照
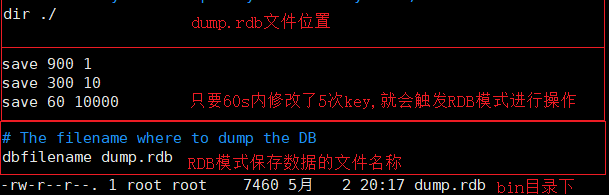
# 持久化,在规定时间内执行了多少次操作,则会持久化到文件rdb.aof # redis是内存数据库,如果没有持久化,那么数据断点及失 save 900 1 如果900s内,至少有一个Key进行了修改,redis进行持久化操作 save 300 10 如果300s内,至少10个key进行了修改,redis进行持久化操作 save 60 10000 如果60s内,至少10000个key进行了修改,redis进行进行持久化操作 stop-writes-on-bgsave-error yes 持久化如果出错,是否还需要继续工作 rdbcompression yes 是否压缩rdb文件,需要消耗一些cpu资源 rdbchecksum yes 保有rdb文件的时候,进行错误的检查校验 dir ./ 文件保存的目录 -
SECURITY(安全)
requirepass 123456 -
CLIENTS(限制)
maxclients 10000 设置能连接上redis的最大客户端的数量 maxmemory <bytes> redis配置最大的内存容量 maxmemory-policy noeviction 内存到达上限之后的处理策略 1.volatile-1ru: 只对设置了过期时间的Key进行LRU(默认值) 2.allkeys-1ru 删除1ru算法的key 3.volatile-random 随机删除即将过期key 4.allkeys-random 随机删除 5.volatile-ttl 删除即将过期的 6.noeviction 永不过期,返回错误 -
APPEND ONLY MODE (aof配置)
appendonly no 默认是不开启aof模式的,默认是使用rdb方式持久化的,在大部分庆康下,rdb够用 appendfilename "appendonly.aof" 持久化的文件的名字 # appendfsync always 每次修改都会sync,消耗性能 appendfsync everysec 每次执行一次sync,可能会丢失这1s的数据 # appendfsync no 不执行sync,这个时候操作系统自己同步数据,速度最快[注]redis启动时就通过配置文件来启动
持久化
redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以redis提供了持久化功能。
持久化功能分为RDB、AOF两种方式,在redis.windows.conf配置文件中可进行设置。
-
RDB模式
默认方式,不需要进行配置,在一定的间隔时间中,检测key的变化情况,然后持久化数据。由于间隔时间进行操作,意外宕机时最后一次数据会丢失。
-
配置方式
save 900 1 --> 900秒(15分钟)后,如果至少有1个键发生变化
save 300 10 --> 300秒(5分钟)后,如果至少有10个键发生变化
save 60 10000 --> 60秒(1分钟)后,如果至少有10000个键发生变化
-
触发机制
• sava的规则满足的情况下,会自动触发rdb规则
• 执行fushall命令,也会触发我们的rdb规则
• 退出redis,也会产生rdb文件 -
恢复方式
只需要将rdb文件放在redis启动目录下即可,redis启动的时候回自动检测dump.rdb,恢复数据
-
-
AOF模式
默认不开启,需要手动配置,AOF每一次修改都同步数据,文件的完整性更好;
-
配置方式
appendonly yes (开启aof)
appendfsync no (关闭aof,不进行持久化)
appendfsync always (每一次操作都进行持久化)
appendfsync everysec (每间隔一秒进行一次持久化)
-

同时开启两种持久化方式时,redis会优先载入aof文件来恢复原始的数据。
因为rdb文件只用作后备用途,建议只在Slave上持久化rdb,而且只要15分钟备份一次就够了,只保留save 900 1 这一条规则
redis掌握流程
nosql数据模型
CAP
BASE
五大基本数据类型
String
List
Set
Hash
ZSet
三大特殊数据类型
geo
hyperloglog
bitmap
Redis配置详解
Redis事务操作
Redis实现订阅发布
Redis主从复制
Redis哨兵模式(现在公司中所有的集群都用哨兵模式)
缓存穿透及解决方案
缓存击穿及解决方案
缓存雪崩及解决方案
基础API之Jedis详解
Springboot集成Redis操作
Redis的实践分析
redis 事务
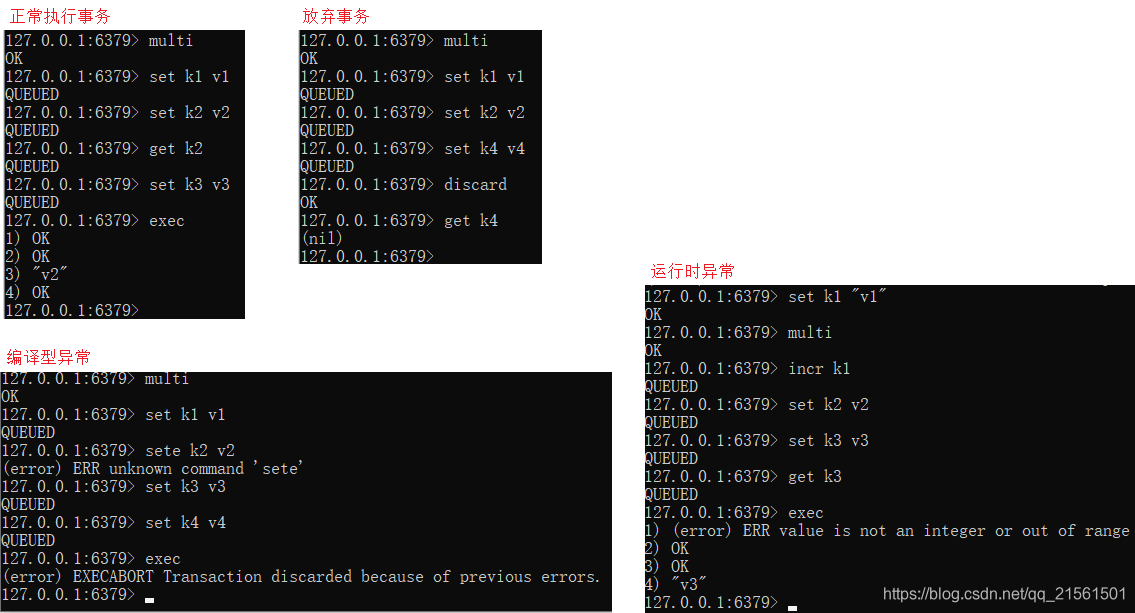
开启事务(multi),将一组命令入队,然后执行事务(exec)即可。
redis事务执行有以下四种情况:
• 正常执行事务
• 放弃事务
• 编译型异常(代码有问题命令出错,事务中所有的命令都不会被执行)
• 运行时异常(IO异常,如果事务队列中存在逻辑问题,那么执行命令的时候,其他命令是可以正常执行的,错误命令抛出异常)
redis主从复制
将一个 Redis 实例(称为主节点)的数据复制到其他 Redis 实例(称为从节点)的过程,叫做主从复制。主从复制可以实现的功能有:
• 数据备份
• 读写分离
• 负载均衡
主机数据更新后根据配置和策略,自动同步到从机的 master/slave 机制,Master 以写为主,Slave 以读为主。主少从多、主写从读、读写分离、主写同步复制到从。
-
主从复制的方式
主节点将数据同步到从节点的方式有两种:
• 全量复制:主节点将所有数据发送给从节点进行复制,适用于从节点第一次复制数据
• 增量复制:主节点只发送最新的修改数据给从节点进行复制,适用于从节点已经复制过数据
redis分布式锁
-
[set NX]命令
向Redis中添加一个key,只用当key不存在的时候才添加并返回1,存在则不添加返回0,该命令是原子性的。
如进程A获得锁并没有删除锁的Key时,进程B获取锁就会失败。通常会在NX后增加 PX 30000参数,用于设置超时时间,防止进程A中断,锁无法释放,导致系统中谁也拿不到锁。
redis 桌面管理器
链接:https://pan.baidu.com/s/1BE5SCyoF3IPetWKMhBQzwQ
密码:d4d8
Redis Desktop Manager 0.8的版本强烈建议你切换成0.9.3最后一版不收费的版本。用0.8版本进行1万条数据查询时经常卡死,或者链接超时。0.9.3却不会卡死很流畅。
redis 性能测试
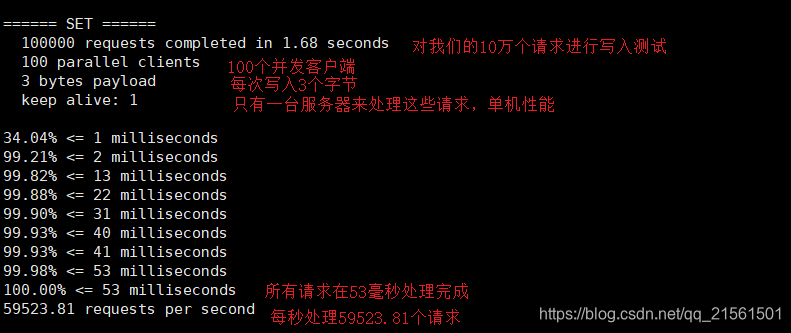
redis-benchmark,官方自带的性能测试工具,位于redis所在目录
redis-benchmark命令参数
-h 指定服务器主机名
-p 指定服务器端口
-s 指定服务器socket
-c 指定并发连接数
-n 指定请求数
-d 以字节的形式指定set/get值的数据大小
-k 1=keep alive 0=reconnect
-r set/get/incr 使用随机key,sadd使用随机值
-p 通过管道传输请求
-q 强制退出redis,仅显示query/sec值
--csv 以csv格式输出
自定义测试选项
redis-server FeraoRedisConfig/redis.conf 启动redis服务
redis-cli -p 6379 启动客户端
redis-benchmark -h localhost -p 6379 -c 100 -n 100000 发出测试命令(bin目录下)
redis API
单个reids中API的测试
测试key - value 的数据
/**
* 单机环境Redis操作:一台Redis服务器
*/
public class Standalone {
private static Jedis jedis;
static {
jedis = new Jedis("192.168.56.180", 6379);
jedis.auth("123456"); // 之前我在redis配置中配置了权限密码,这里需要设置
}
/**
* 测试key - value 的数据
* @throws InterruptedException
*/
@Test
public void testKey() throws InterruptedException {
System.out.println("清空数据:"+jedis.flushDB());
System.out.println("判断某个键是否存在:"+jedis.exists("username"));
System.out.println("新增<'username','wukong'>的键值对:"+jedis.set("username", "wukong"));
System.out.println("是否存在:"+jedis.exists("name"));
System.out.println("新增<'password','password'>的键值对:"+jedis.set("password", "password"));
Set<String> keys = jedis.keys("*");
System.out.println("系统中所有的键如下:"+keys);
System.out.println("删除键password:"+jedis.del("password"));
System.out.println("判断键password是否存在:"+jedis.exists("password"));
System.out.println("设置键username的过期时间为5s:"+jedis.expire("username", 5));
TimeUnit.SECONDS.sleep(2);
System.out.println("查看键username的剩余生存时间:"+jedis.ttl("username"));
System.out.println("移除键username的生存时间:"+jedis.persist("username"));
System.out.println("查看键username的剩余生存时间:"+jedis.ttl("username"));
System.out.println("查看键username所存储的值的类型:"+jedis.type("username"));
}
/***
* 字符串操作
* memcached和redis同样有append的操作,但是memcached有prepend的操作,redis中并没有。
* @throws InterruptedException
*/
@Test
public void testString() throws InterruptedException {
jedis.flushDB();
System.out.println("===========增加数据===========");
System.out.println(jedis.set("key1",