一 背景
最近总结自己的公众号的时候,发现一个问题:对于联邦学习的文章,基本都是在讲述纵向联邦学习,对于横向联邦学习的技术涉及较少,所以心血来潮之下,决定写几篇文章来压压箱子底。
❝横向联邦:现代移动设备可以访问大量适合学习模型的数据,这些数据反过来可以大大提高设备上的用户体验。例如,语言模型可以提高语音识别和文本输入,图像模型可以自动选择好的照片。然而,这些丰富的数据通常是隐私敏感的、数量很大的,或者两者兼有,这可能会阻止记录到数据中心并使用常规方法在那里进行分析训练。
❞
所以针对于此研发人员设计了一种新的模式,即让训练数据分布在移动设备上,并通过聚集本地计算的更新来学习共享模型。我们将这种模式称为联邦学习。
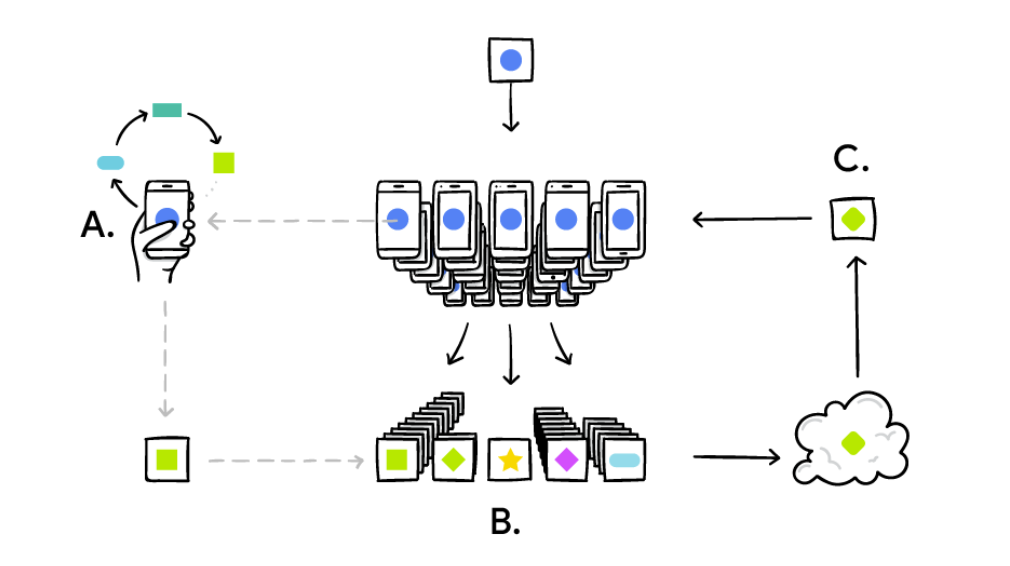
本篇文章作为介绍横向联邦学习的首作,主要讲解下横向联邦学习的模式、难点、参数的更新方式,后续文章会陆续从以下方面进行介绍;
-
高效的共享模型构建构建更新模式; -
构建更新共享模型中的隐私安全风险以及应对手段; -
横向联邦学习的前沿技术;
二 横向联邦学习面临的难题
❝任何问题都不是孤立存在的,都是有着千丝万缕的联系。其实对于横向联邦学习的场景,如果是熟悉机器学习框架的同学来说,可能不会感觉十分陌生。云端数据中心的分布式机器学习可以有成百上千的节点,对比横向联邦学习有一定的借鉴意义,都存在着节点更新的同步与异步的问题,节点梯度更新之后的问题、节点掉线的问题、数据的Non IID问题,但是横向联邦学习的场景更加复杂,基础设施相对云端的统一高速基建存在非常大的差异,同时加上隐私保护机制,这就造成了横向联邦学习的系统设计会更加的复杂,以支撑各种异构的底层基建。
❞
在云端分布式训练过程中,通信是严重的瓶颈,研发人员花了大量的精力进行优化,其模式特点进一步描述:
-
现有的工作通常要求客户端的数量远远小于每个客户端的示例数量; -
数据以IID的方式分布在客户端,每个节点有相同数量的数据点;
横向联邦学习与云端分布式训练有很多类似的地方,我们可以把云端的Worker机器看做是客户端,把每个Worker负责训练的数据看做是客户端独有的数据,但是从整体来说,还是有很大不同与挑战。
-
设备的异构性,不稳定; -
通信网络的异构性、不稳定、不可靠; -
数据的异构性,Non IID问题(云端数据与机器非私有隶属关系,可以通过Global Shuffle解决); -
框架的算法效率,通信的频率等; -
训练过程中的隐私性;
三 横向联邦学习的参数更新机制
本节主要介绍横向联邦学习的模型更新机制,先介绍两种
-
FedSGD -
FedAvg
下面我们就分别介绍下这两种模型更新机制的方法、不同与优缺点等;
3.1 FedSGD
类似于云端数据中心里面的分布式机器学习的同步模式,通过梯度的传输进行模型的全局更新。最近大量的深度学习的成功应用几乎完全依赖于随机梯度下降(SGD)的变体作为优化算法,因此,我们很自然地从SGD开始构建联邦优化的算法。我们可以通过使用所选设备上的所有数据来选择批处理,所以我们将这个简单的基线算法称为FedSGD。
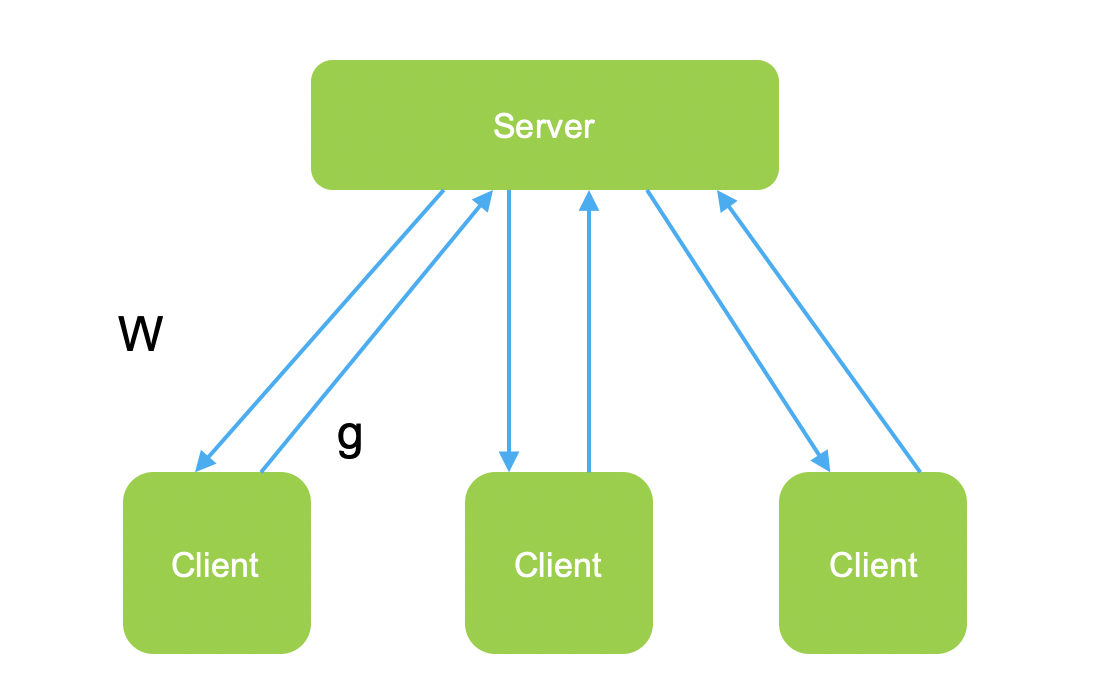
-
Client节点流程
-
客户端收到来自服务端的模型参数w的信息; -
客户端使用服务端的模型参数w进行本地模型的更新; -
客户端使用本地数据进行训练,并且计算本地梯度 ; -
客户端将计算的梯度 ,发送到服务端;
-
-
Server节点流程
-
服务端本轮训练选取n个客户端; -
服务端将目前模型参数广播到所有参与本轮训练的n个客户端; -
服务端等待接收本轮训练所有参与客户端的梯度信息 ; -
服务端计算整体的梯度 -
计算模型最新参数 ,并且更新参数,等待下一轮计算;
-
3.2 FedAvg
上面描述算法可以理解为一个端点的简单的一次平均,其中每个客户求解最小化其局部数据损失的模型,并对这些模型进行聚合以产生最终的全局模型。这种方法在带有IID数据的凸情况下得到了广泛的研究,众所周知,在最坏情况下,产生的全局模型并不比在单个客户端上训练模型更好,所以我们需要针对联邦学习研究一种新的模型更新方法。
我们在回顾下联邦学习中我们比较棘手的问题:
-
数据的IID问题 -
通信的问题
在云端分布式训练模式下,针对数据的IID问题,一般的解法是在云端训练之前,对大规模的样本数据进行全局Shuffle打散操作,将Non IID问题转化为IID问题。通信方面呢,有All Reduce模式以及一些其他流量包合并的机制,下面我们看看在联邦学习中如何解决这些问题。

FedAvg与FedSGD的不同点在于:
-
传递数据的不同:FedSGD传递的是梯度g,FedAvg传递的是模型参数w; -
传输效率不同:FedAvg会在本地经过多轮的训练,先对本地模型经过Loss的多轮优化,在同步最后的优化参数w到服务端。 -
模型聚合的方式不同:服务端针对客户端返回的参数w进行平均聚合,期望通过这种方式解决数据的Non IID问题。 -
安全性:FedAvg在本地经过多轮训练,对于模型的保护性更好。
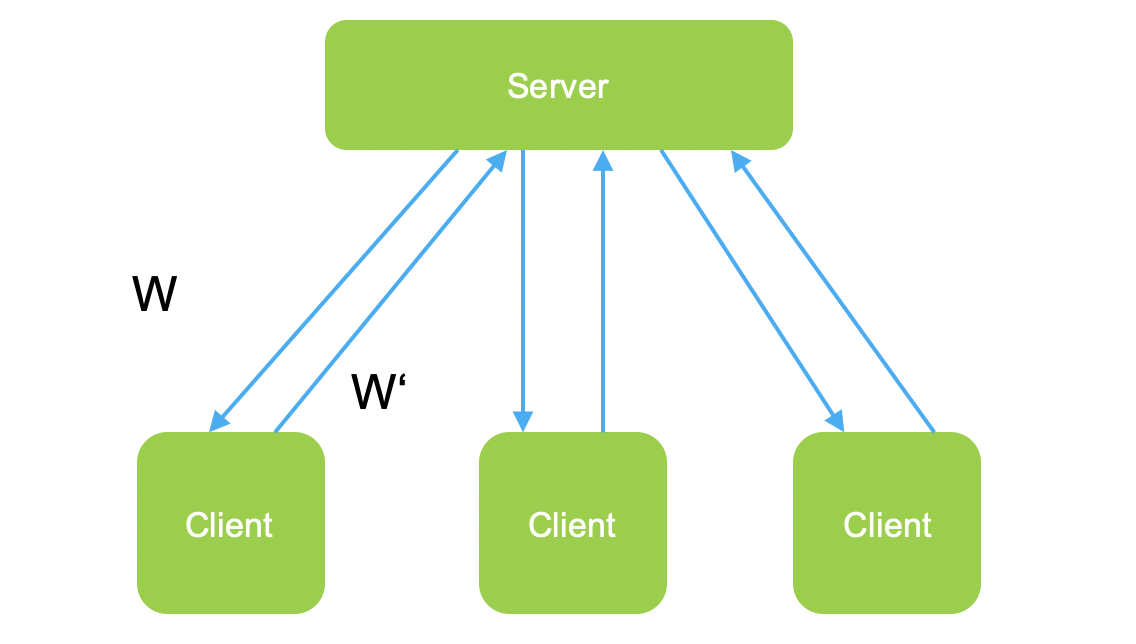
-
Client节点流程
-
客户端收到来自服务端的模型参数w的信息; -
客户端使用服务端的模型参数w进行本地模型的更新; -
客户端使用本地数据进行训练,并且计算本地梯度 ; -
客户端将计算的梯度 ,发送到服务端;
-
-
Server节点
-
服务端本轮训练选取n个客户端; -
服务端将目前模型参数广播到所有参与本轮训练的n个客户端; -
服务端等待接收本轮训练所有参与客户端的梯度信息 ; -
服务端计算整体的梯度 -
计算模型最新参数 ,并且更新参数,等待下一轮计算;
-
四 番外篇
❝个人介绍:杜宝坤,隐私计算行业从业者,从0到1带领团队构建了京东的联邦学习解决方案9N-FL,同时主导了联邦学习框架与联邦开门红业务。 框架层面:实现了电商营销领域支持超大规模的工业化联邦学习解决方案,支持超大规模样本PSI隐私对齐、安全的树模型与神经网络模型等众多模型支持。 业务层面:实现了业务侧的开门红业务落地,开创了新的业务增长点,产生了显著的业务经济效益。 个人比较喜欢学习新东西,乐于钻研技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从工程架构、大数据到机器学习算法与算法框架均有涉及。欢迎喜欢技术的同学和我交流,邮箱:「[email protected]」
❞
五 公众号导读
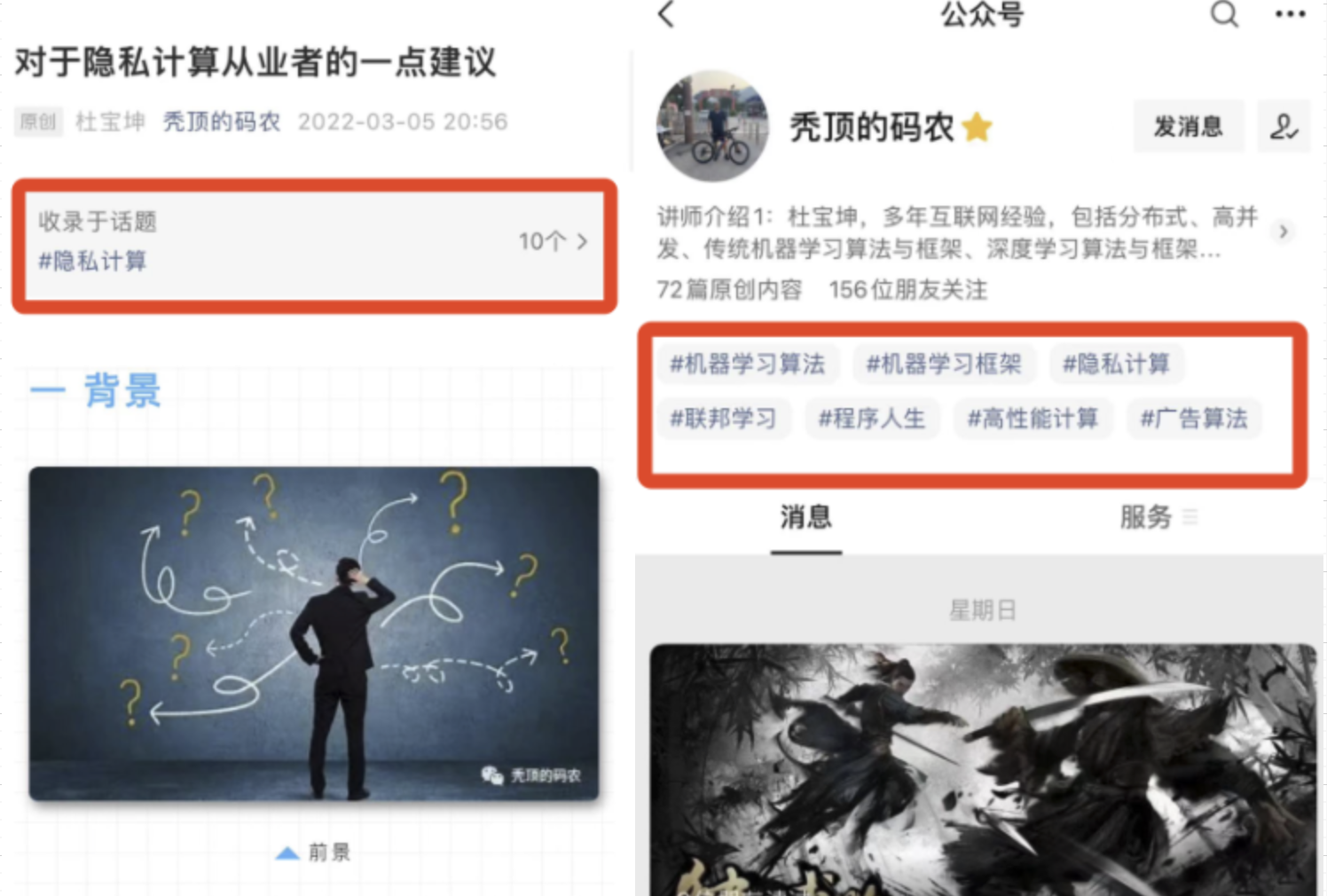
自己撰写博客已经很长一段时间了,由于个人涉猎的技术领域比较多,所以对高并发与高性能、分布式、传统机器学习算法与框架、深度学习算法与框架、密码安全、隐私计算、联邦学习、大数据等都有涉及。主导过多个大项目包括零售的联邦学习,社区做过多次分享,另外自己坚持写原创博客,多篇文章有过万的阅读。公众号「秃顶的码农」大家可以按照话题进行连续阅读,里面的章节我都做过按照学习路线的排序,话题就是公众号里面下面的标红的这个,大家点击去就可以看本话题下的多篇文章了,比如下图(话题分为:一、隐私计算 二、联邦学习 三、机器学习框架 四、机器学习算法 五、高性能计算 六、广告算法 七、程序人生),知乎号同理关注专利即可。
一切有为法,如梦幻泡影,如露亦如电,应作如是观。
本文由 mdnice 多平台发布