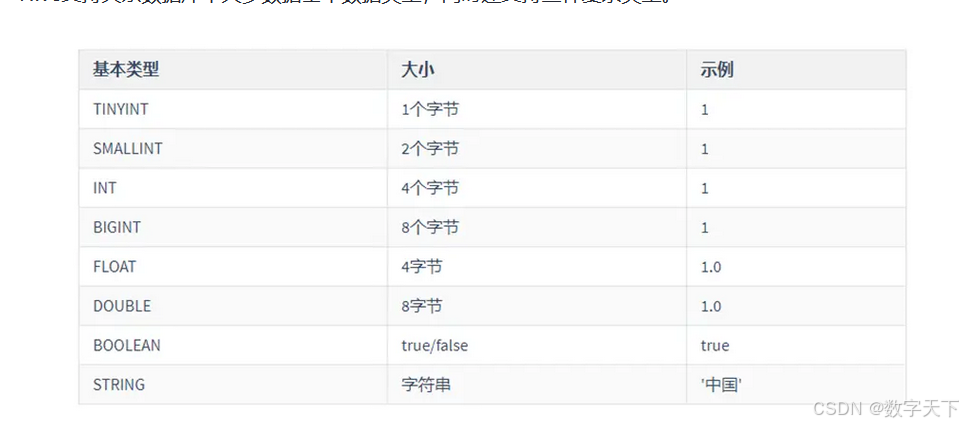
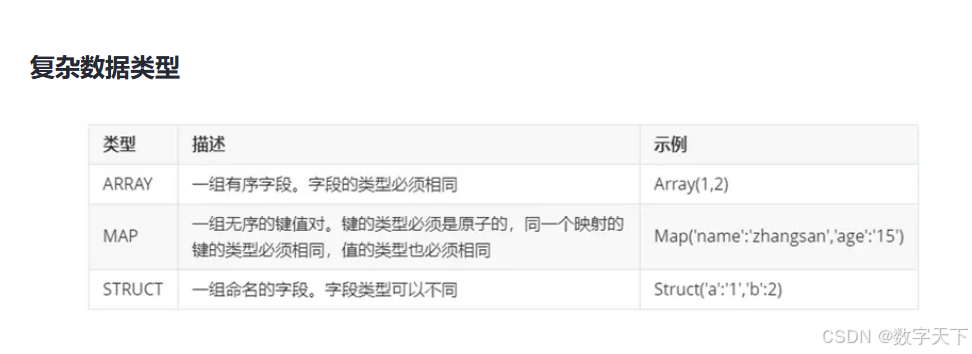
Hive支持关系数据库中大多数据基本数据类型,同时还支持三种复杂类型。
示例:
Hive表
创建表
– 直接建表法
create table t_page_view (
page_id bigint comment ‘页面ID’,
page_name string comment ‘页面名称’,
page_url string comment ‘页面URL’
)
comment ‘页面视图’
partitioned by (ds string comment ‘当前时间,用于分区字段’)
stored as parquet
location ‘/user/hive/warehouse/t_page_view’;
– 查询建表法
create table t_page_view2 as select * from t_page_view;
– like建表法(克隆表)
create table t_page_view3 like t_page_view;
Hive表类型
内部表
Hive中默认创建的是内部表,内部表的数据由Hive来管理。在 drop表的时候,表的数据和元数据都会被删除。
CREATE TABLE pokes (
foo INT,
bar STRING
);
外部表
外部表的数据不由Hive管理。Hive可以创建外部表和 HDFS、HBase 和 Elasticsearch 等进行整合。drop外部表时,只会删除元数据,不会删除真实数据。外部表关键字EXTERNAL。
CREATE EXTERNAL TABLE IF NOT EXISTS tb_station (
station string,
lon string,
lat string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
LOCATION ‘/user/test/coordinate/’;
内部表与外部表转换
– 内部表转外部表
alter table tableA set TBLPROPERTIES(‘EXTERNAL’=‘true’);
– 外部表转内部表
alter table tableA set TBLPROPERTIES(‘EXTERNAL’=‘false’);
分区表
Hive表的数据是存储在HFDS中对应的目录中,普通表的数据直接存储在这个目录下,而分区表存储时,会再划分子目录来存储,一个分区对应一个子目录。主要作用是来优化查询性能。在Hive表查询的时候,如果指定了分区字段作为筛选条件,那么只需要到对应的分区目录下去检索数据即可,减少了处理的数据量,从而有效的提高了效率。在对分区表进行查询时,尽量使用分区字段作为筛选条件。
CREATE TABLE invites (
foo INT,
bar STRING
)
PARTITIONED BY (ds STRING);
桶表
分桶是将数据分解成更容易管理的若干部分的技术,桶表示对数据源数据文件本身来拆分数据。桶是更为细粒度的数据范围划分。Hive采用对列进行哈希,然后对桶的个数取模的方式决定该条记录存放在哪个桶当中。
创建桶表时,需要指定桶的个数,分桶的依据字段,Hive就可以自动将数据分桶存储。
查询时,只需要遍历一个桶里的数据,或者遍历部分桶,这样就提高了查询效率。
示例:
CREATE TABLE ods.tb_ad_action_d (
op_time STRING,
user_id STRING,
task_id STRING,
event_name STRING
)
CLUSTERED BY (user_id)
SORTED BY(task_id)
INTO 10 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’
STORED AS TEXTFILE;
CLUSTERED BY:是指根据user_id的值进行哈希后模除分桶个数,根据得到的结果,确定这行数据分入哪个桶中。
SORTED BY:指定桶中的数据以哪个字段进行排序,排序的好处是,在 join 操作时能够获得很高的效率。
INTO 10 BUCKETS:指定一共分多少个桶。
常用HiveQL整理
Database
– 创建database
create database IF NOT EXISTS ods;
USE database_name;
USE DEFAULT;
– 删除database
drop database if exists ods;
Table
– 创建内部表(默认)
create table trade_detail(
id bigint,
account string,
income double,
expenses double,
time string)
row format delimited
fields terminated by ‘\t’;
– 创建分区表
create table td_part(
id bigint,
account string,
income double,
expenses double,
time string)
partitioned by (logdate string)
row format delimited
fields terminated by ‘\t’;
– 创建外部表
create external table td_ext(
id bigint,
account string,
income double,
expenses double,
time string)
row format delimited
fields terminated by ‘\t’
location ‘/data/td_ext’;
– 创建外部分区表
create external table td_part_ext(
id bigint,
account string,
income double,
expenses double,
time string)
partitioned by (logdate string)
stored as parquet tblproperties(“parquet.compress”=“SNAPPY”)
location ‘/data/td_part_ext’;
drop table if exists td_part_ext;
Alter
– 修改表明
ALTER TABLE page_view RENAME to page_view_new;
– 修改字段
ALTER TABLE page_view CHANGE ip ip_address string AFTER refererurl;
– 添加字段
ALTER TABLE page_view ADD COLUMNS (name string comment ‘view name’);
– 添加分区
ALTER TABLE page_view ADD IF NOT EXISTS PARTITION (dt=‘20190705’) LOCATION=‘/data/page_view/dt=20190705’;
– 修改location
ALTER TABLE page_view PARTITION(dt=‘20190706’) SET LOCATION “/data/page_view/dt=20190706”;
– 修改分隔符
ALTER TABLE page_view SET SERDEPROPERTIES (‘field.delim’ = ‘,’);
– 删除分区
ALTER TABLE page_view DROP PARTITION (dt=‘2008-08-08’, country=‘us’);
Show
– 查看创建表语句
show create table td_part;
– 查看表分区
show partitions td_part;
修复分区
– 修复分区
msck repair table page_view;
数据导入
– 将本地文件导入到hive
load data local inpath ‘/home/hadoop/student’ overwrite into table student partition(state=‘Sichuan’, city=‘Chengdu’);
– 将hdfs上文件导入到hive
load data inpath ‘/user/hadoop/add.txt’ into table student partition(state=‘Sichuan’, city=‘Chengdu’);
– 从别的表中查询出相应的数据并导入到hive表中
insert into table test partition(age=‘25’) select id ,name from wyp where age=‘25’;
– 在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中
create table tmp as select * from student where age>‘18’;
数据导出
– 导出到本地文件系统
insert overwrite local directory ‘/home/hadoop/student’ select * from student;
– 导出到hdfs
insert overwrite directory ‘/user/hadoop/student’ select * from student;
– 将查询结果插入到表中(追加)
insert into table student_new select id,name from student where age=‘25’;
– 将查询结果插入到表中(覆盖)
insert into table student_new select id,name from student where age=‘25’;