Windows版Nginx添加nginx_upstream_check_module第三方模块实现不停服更新Tomcat
目标
蓝绿发布,无感更新代码,不停服重启tomcat,实现Nginx负载均衡的健康检查。主讲Windows添加nginx_upstream_check_module模块的方法。
前言
项目流量不断上升,ngx_req_status统计的并发经常莫名其妙堆的非常高。便搭建了ELK分析日志情况,分析后发现,在流量高峰区域后端常会有2分钟处于不可用状态,这段时间内,每台tomcat会返回两个504状态码,后续其它请求全部返回502状态码。这才想起自己是借助Nginx自带的ngx_http_upstream_module模块间接实现服务健康检查,这个方案弊端很大,并不能很好的实现后端的高可用。
旧方案
■ 1.配置
例:
upstream doman {
server 127.0.0.1:8080 max_fails=2 fail_timeout=140s;
server 192.168.1.1:8080 max_fails=2 fail_timeout=140s;
server 192.168.1.2:8080 max_fails=2 fail_timeout=140s;
}
解释:max_fails=2和fail_timeout=140s表示140s内2次连接失败,将把节点标记为不可用,并等待fail_timeout再次请求,判断是否连接是否成功。
■ 2.实现原理
假定为A、B、C三台Tomcat。
①关闭A-Tomcat。
②在140s内对Nginx进行多次请求(6次以上)
③有两个请求分流到A-Tomcat上,但是请求失败,Nginx将请求转发给其它Tomcat,同时Nginx判断A-Tomcat宕机,将A-Tomcat标为down,140s后才会再次尝试。
④更新代码并启动。
⑤待A-Tomcat完全启动好后,140s倒计时完成,Nginx重新分流到A-Tomcat上。
⑥分别对B、C进行相同操作流程。
■ 3.弊端
①Tomcat启动了并不代表项目启动好了,服务实为可不用,但正常接收请求。
一般的商业项目跑起来都要花不少时间,但是这段时间内Tomcat是已经启动好的,也就是说Tomcat开始启动后是可以接收请求的,但是项目未启动好,请求会一直处于等待状态,直到项目完全启动才会处理请求,又或者超时返回504。
这也就意味着——你得在Tomcat启动前保证,Nginx判断Tomcat处于down状态,并且将Tomcat重新标为up的时候,项目已经完全启动好,可以正常接收请求。
没有把握好这个尺度,在项目启动中分流过来,就会造成部分请求假死无响应,服务的不可用状态成为常态。
②被动健康检查
这是个被动的健康检查方案,除非你主动去心跳请求,否则从理论上悲观看待,你不能保证在Tomcat重新开启前,有足够多的请求分流到A-Tomcat上去触发它标记服务为down。也就是说,在你关闭Tomcat之后,必须得有对应的措施保证Nginx不再分流过来了,才能去开启Tomcat。
③fail_timeout必须设的久从而造成负面影响
再一点,fail_timeout必定得大于服务的启动时间,更准确来说当心跳请求触发标记为down就已经开始了倒计时,设置太短的话,服务还没完全启动,Nginx就把它标为up并分流过来,从而导致不可用。也就是说fail_timeout>Tomcat重启时间+②所提到的措施时间。
④偶尔发生的相对正常的错误码引起恶性循环
这个配置是被动健康检查,本身并不是为了热更新服务的。健康检查中不能轻易去关闭一台服务,为了确认宕机,所以设置max_fails偏大,为了增加服务的可用时间,防止休息太久,fail_timeout偏小,保证服务的健壮性和稳定性。而为热更新服务是恰恰相反的,max_fails偏小,越容易触发越好,fail_timeout偏大,因为Tomcat完全跑起来需要花不少时间。
也就是,如果你使用这种方案的话,例如我上面的配置。在系统处于流量高峰期时候,服务器稍微有点不稳定,A-Tomcat压力稍微有点大,140s内有两个请求504超时,Nginx马上就断定A-Tomcat宕机,不再分流过来,这么一来,B-Tomcat和C-Tomcat的压力骤增,也各有了两个504超时,Nginx也判断了他们宕机,从而导致无服务可用,最终实现整个系统宕机,Nginx返回502,错误日志为no live upstreams while connecting to upstream。
总结
心跳触发,重启时间把握,即便你再三强调,开发人员和运维人员也经常会不规范操作,导致服务不可用,后面引进jenkins自动化部署,这个问题算是解决了大半。而误触发宕机的问题是难以解决的,谁也不能保证系统偶尔的服务错误不会出现,本来不稳定只是小问题,你全停了就是大问题了,而且一停就是那么久。
第三方模块方案
■ nginx_upstream_check_module
■ 1.介绍
nginx_upstream_check_module,淘宝技术团队开发的nginx模块,主动地连接上游服务,心跳判断上游服务的健康状况。
■ 2.配置
① 默认值
默认值:
interval=30000 fall=5 rise=2 timeout=1000 default_down=true type=tcp
② 参考值
upstream doman {
# upstream 的负载均衡,weight 是权重,可以根据机器配置定义权重。weigth 参数表示权值,权值越高被分配到的几率越大。
server 127.0.0.1:8080 max_fails=10 fail_timeout=30s weight=5;
server 192.168.1.1:8080 max_fails=10 fail_timeout=30s weight=5;
server 192.168.1.2:8080 max_fails=10 fail_timeout=30s weight=2;
keepalive 256;
check interval=3000 rise=1 fall=5 timeout=2000 default_down=false type=http;
check_keepalive_requests 100;
check_http_send "HEAD /ping HTTP/1.1\r\nHost: 127.0.0.1\r\nConnection: keep-alive\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
③ 参数解释
interval:发送健康检查包的间隔
fall:连续失败fall次数down
rise:连续成功rise次数up
timeout:发送健康检查包的超时时间
default_down:初始上游服务状态
type:健康检查包的类型
/ping:自己编写的接口
在此,选用http1.1请求,类型HEAD,降低性能消耗,注意http1.1配上Host,否则返回400
Windows添加nginx_upstream_check_module
该模块在Windows下的编译有坑点,在此一一列出。
■ 1.编译流程参考
编译Windows版Nginx并添加模块参考前篇
https://blog.csdn.net/qq_24054301/article/details/112131057
■ 2.坑点解决
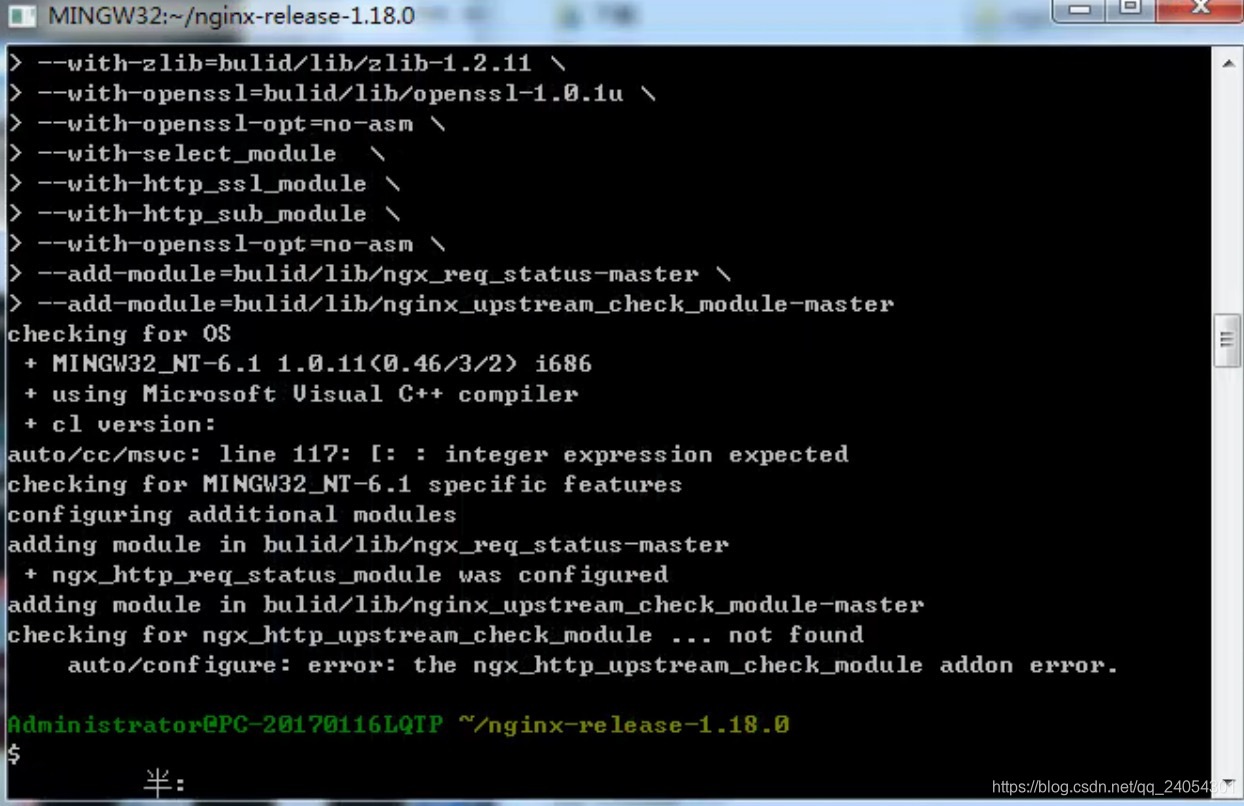
问题① checking for ngx_http_upstream_check_moudule … not found
解决方法:
修改config文件
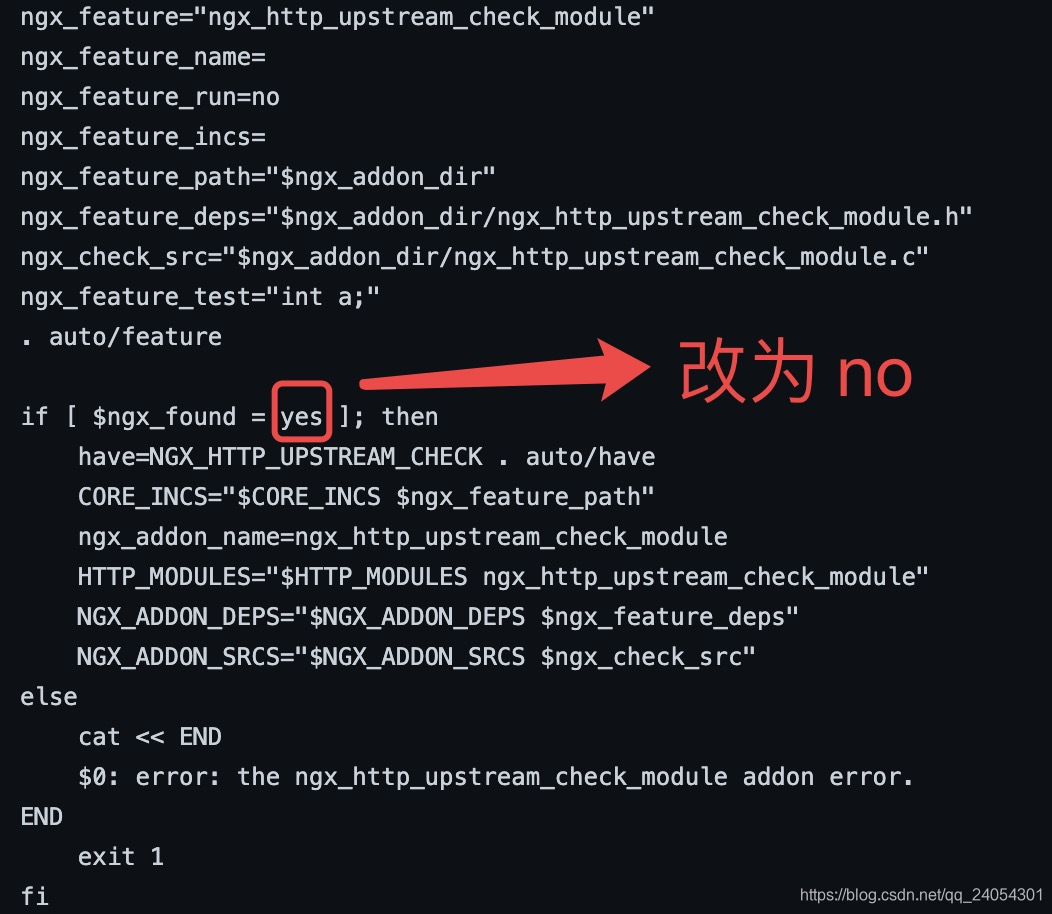
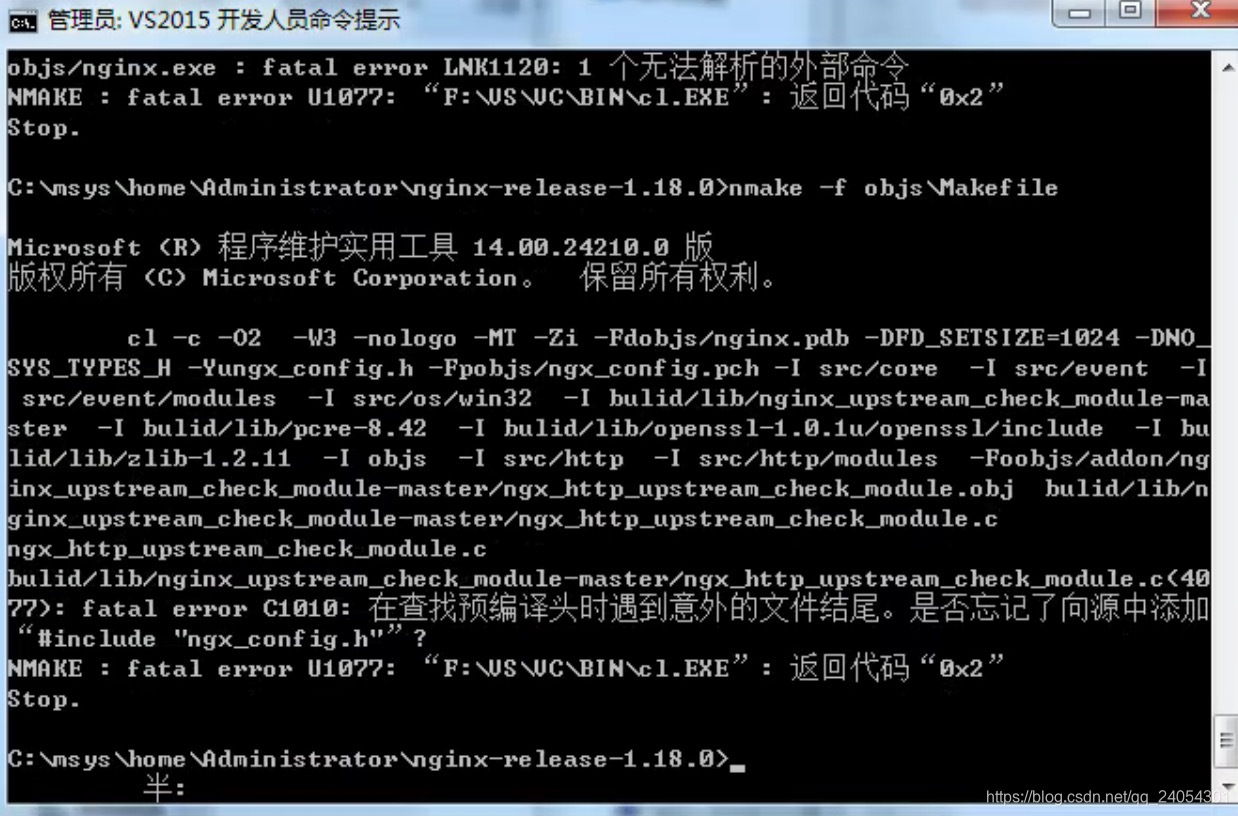
问题② 是否忘记了向源中添加。。。
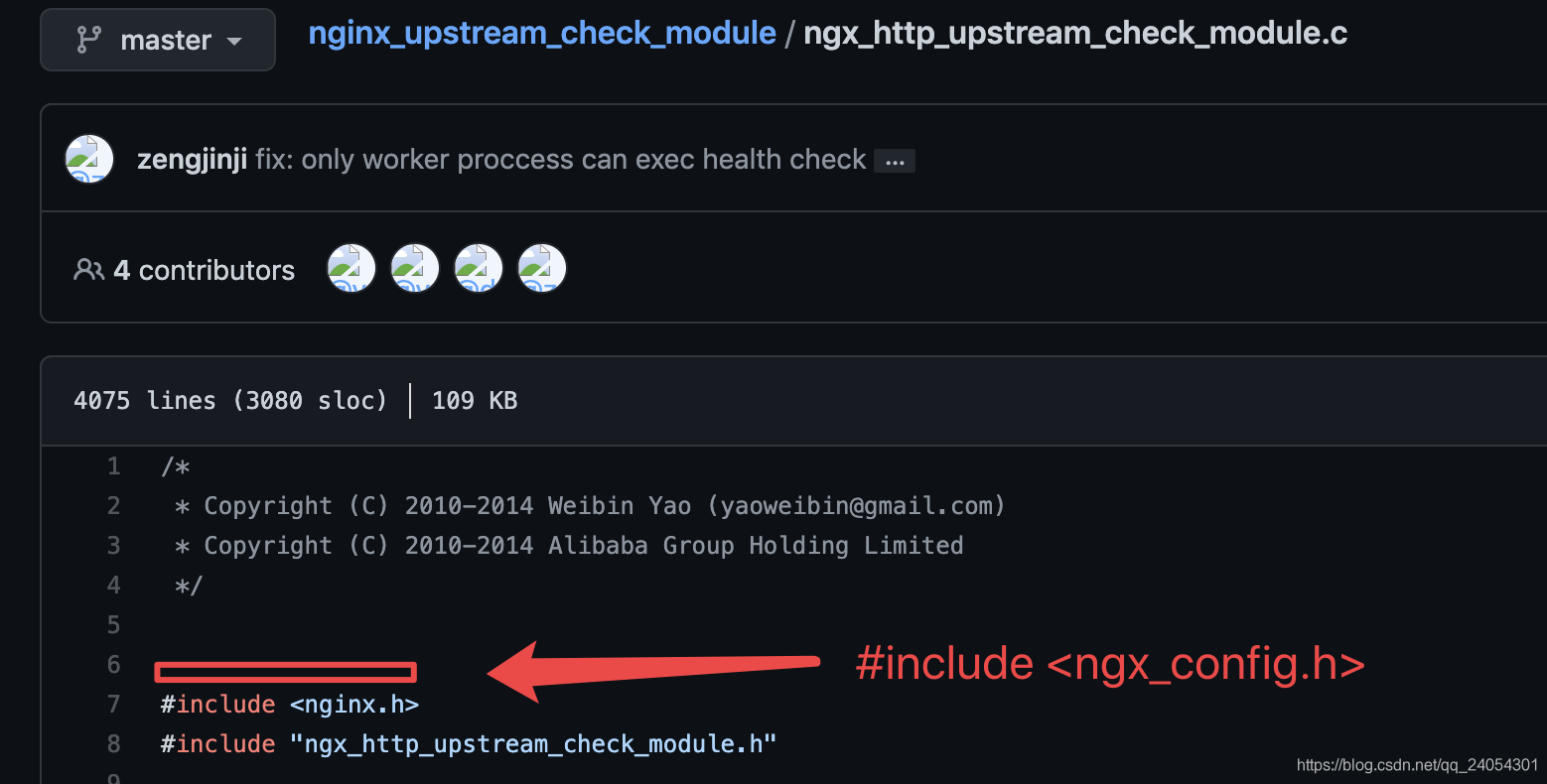
解决方法:
这个简单,按照提示追加对应的头文件
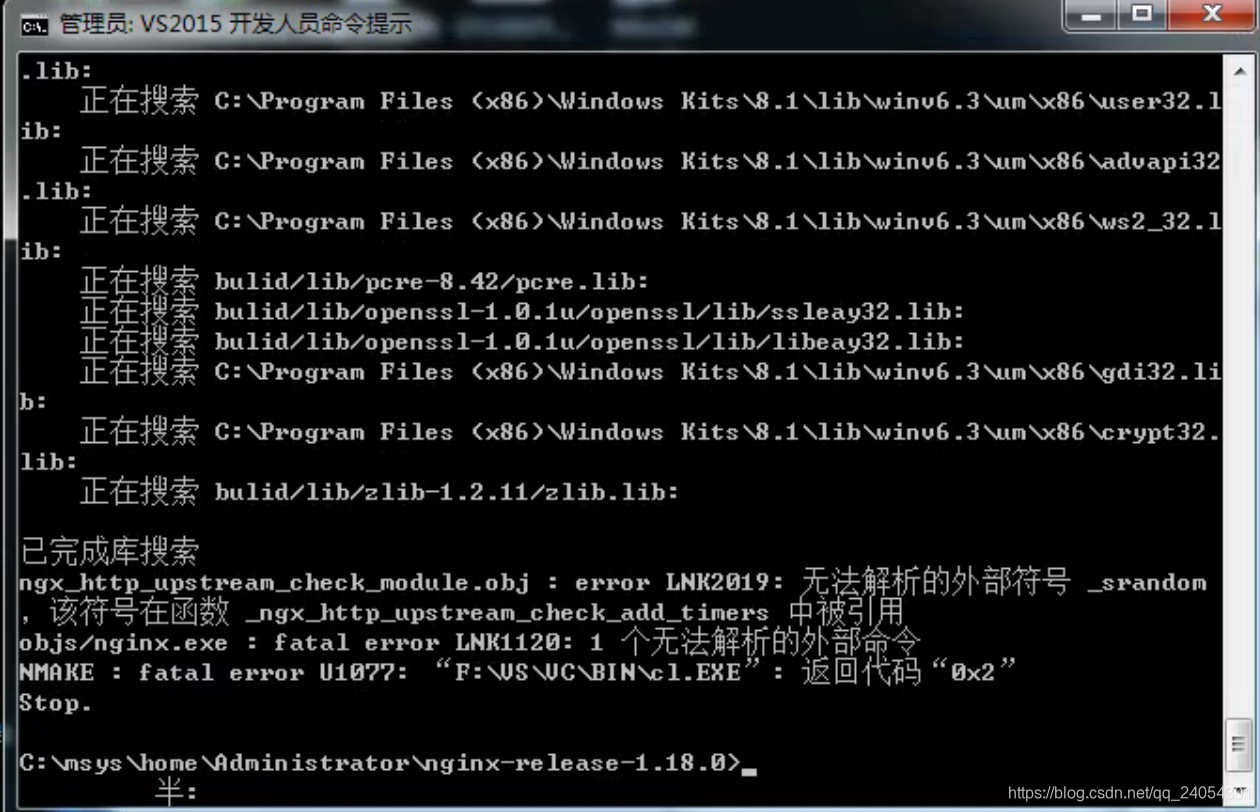
问题③无法解析的外部符号_srandom
解决方法:
搜索这个方法改为rand

■ 3.完成
成功,再发一遍成功的结果。。。
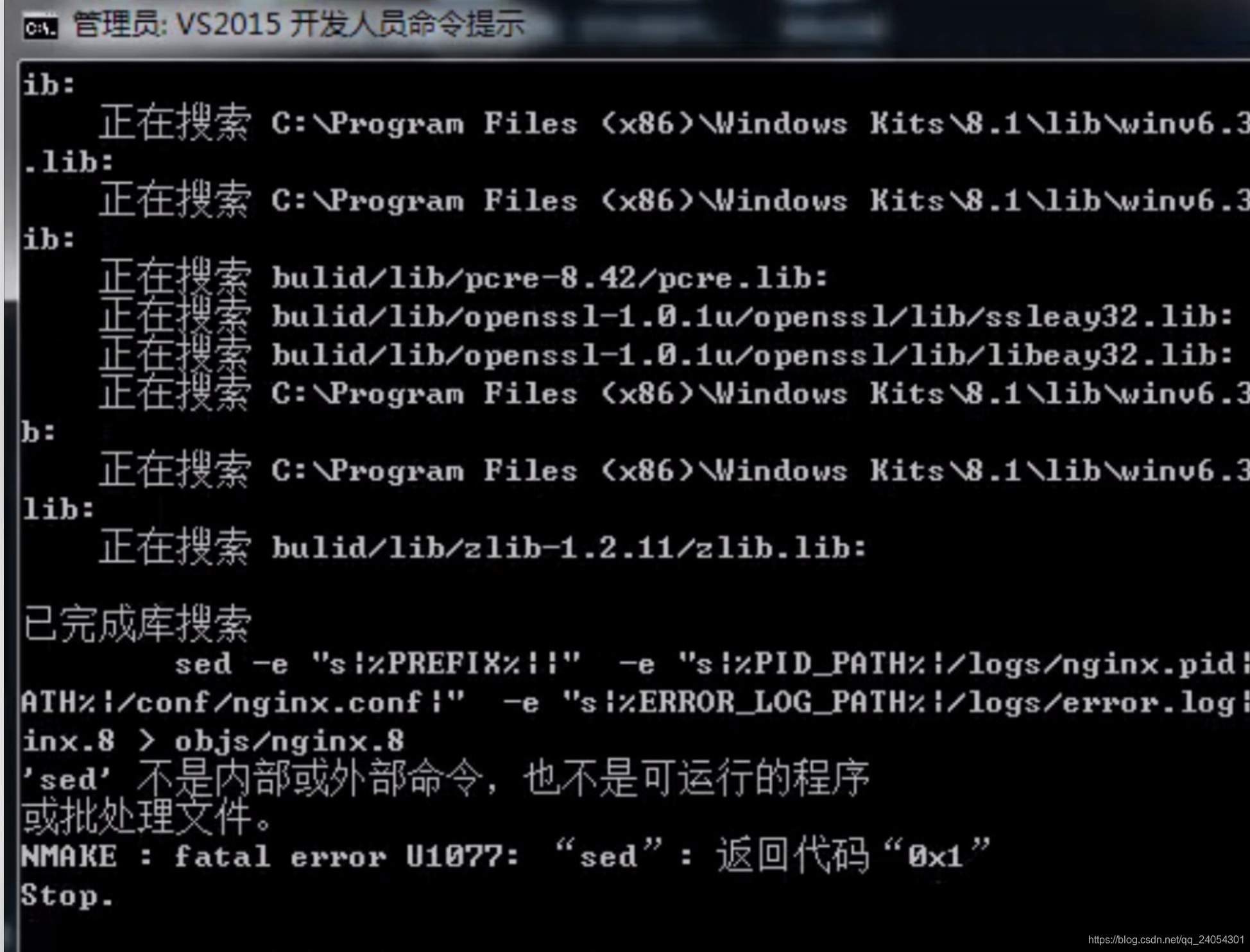
■ 4.效果

注意
注意!!!即使你使用了第三方健康检查模块,仍要为Nginx自带的健康检查设置参数。因为不配是有默认值的,max_fails=1 fail_timeout=10s。这个阀值很低,意味着只要有服务器报错类似504超时之类,Nginx就停止分流到这个上游服务10s。
两个方案的优劣势
对于平均上游qps超过十的系统来说,用Ng自带的健康检查模块在tomcat关闭的一瞬间,就会判断为down,而采用该模块是心跳检查,心跳期间的请求性能非常差。
最后
该模块很好的提供了一个不错的健康检查机制,不过仍要根据线上环境配置好参数。例如机子少,服务不稳定,而判断宕机阈值设置太低,很容易造成恶性循环,导致无服务可用——no live upstreams while connecting to upstream。