链接:https://www.zhihu.com/question/35436669/answer/62753889
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
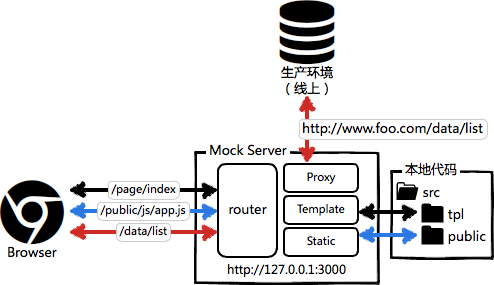
要完整运行前端代码,通常并不需要完整的后端环境,我们只要在mock server中实现以下几点就行了:
- 能渲染模板
- 实现请求路由映射
- 数据接口代理到生产或者测试环境
请求路由映射,实现原理就是要让本地的mock server有一个router,能接收所有HTTP请求,然后在router中根据线上的路由约定,实现一套一样的规则,这个也不难,不赘述了。
最后数据接口代理。与前端相关的HTTP请求一共就3种响应情况:
- 渲染页面的请求;
- 静态资源的请求;
- 获取数据的请求。
至于题主说的url一致性问题,其实不存在的。你的这个 http://www.foo.com/bar 的数据请求,在js中应该这样写:
$.get('/bar', callback)
这种写法,省略了host,在线下开发时,其最终结果是请求 http://127.0.0.1:3000/bar,而由于我们在mock server中实现了路由规则,这个请求实际上被代理到了测试/生产环境去获取数据。而当你把代码部署到线上时,其访问真实请求地址又自动变成了你期望的 http://www.foo.bar,正常运行。
画个图总结一下:
<img src="/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvOWZmOGI2OWU3NzBlMDRiMTE5ZTQ1ZWUxZjYwNDE5M2EucG5n" data-rawwidth="494" data-rawheight="285" class="origin_image zh-lightbox-thumb" width="494" data-original="https://pic4.zhimg.com/dabc8dd12b7b238e9d3fad9f65e974bf_r.png">
补充一些Tips:
- 由于Mock Server需要具备渲染模板的能力,因此可能需要一种轻量的服务端跨平台server实现方案,如果是java的后端,可以考虑使用jetty,一个1.8M的jar即可;如果是php的后端,可以考虑使用php 5.4以后内置的server,启动命令是 php -S 127.0.0.1:3000 router.php;如果是Nodejs,那就很简单了,估计都不需要Mock Server,本地也可以跑的
- 当代理数据接口的生产/测试环境不具备新接口的时候,Mock Server要在本地制造假数据响应请求,可以使用 http://beta.json-generator.com/ 这类在线的JSON数据生成工具,非常方便。
很多前端工程师以为前端分离的唯一途径是接入NodeJS作为UI层,其实不是的,还有一种方案就是这种Mock Server,前端工程师直接写后端模板,效果有时候甚至更好,而且对已有前后端架构的改动成本最小。
前言
随着现在已经变得越来越复杂了,虽然包括我们计蒜客在内的很多公司在团队上分为了前端和后端团队,但是项目中的前端和后端耦合性较高,很容易会出现牵一发而动全身,以及前后端不能同步开发的问题。
我们遇到了一些什么问题?
-
前端无法调试后端未完成的 API:如果后端同学还没有完成 API 开发,那么前端同学就不能对这个 API 进行开发。之前我们都是在代码里直接通过给变量赋假数据,又或者是在后端 Controller 里直接 return JSON 的方式来进行调试的。这样的方式很容易会出现的情况就是,每次提交 commit 都要把它删除掉,有时忘了没有删除掉,那么提交历史就会变得很脏。
-
没有自动化测试:前端对接口的调用没有做自动化的测试。
-
前端需要依赖后端开发环境:前端需要后端环境来在本地测试,像我们使用的方案就是 Vagrant + 虚拟机的来开发。这样的方式其实很笨重,不但每次启动虚拟机都得等一段时间,而且会占用一定的 CPU 和内存资源,拖慢机器。然而,前端需要的只是数据。
如何去解决这些问题? ——前后端分离
为什么我们要前后端分离?
虽然 Facebook 提出了以 功能 划分而不是以 前后端 划分的 全栈式 协作模式,但全栈工程师数量之少、培训成本之高,导致了这种模式并不适合于所有的公司,尤其是我们这种创业公司。
于是很自然地,大部分的互联网公司都分成了前端团队和后端团队。在软件设计中,我们有一个思想就是 Separation of Concerns (Soc) ,也就是 关注点分离 的思想。既然我们采用了前后端由不同团队开发的模式,那么我们应该有 分治 的思想,也就是说,我们要尽可能更多地关注自己从事的领域。
如何做前后端分离?
方案一:采用 SPA 架构
业界很多公司会采用 SPA(Single Page Application,单页应用)的架构,这种架构是天然的前后端分离的。所有的数据都是后端通过 JSON 的形式来传递到前端,前端本身也有自己的 MV* 框架,从物理上实现了前后端分离。
而这样做的的缺点也是明显的,它的学习成本和开发成本比起传统的页面要高很多,而且对 SEO 不友好。再加上历史遗留的原因,很多项目从一开始便没有采用这种架构,所以这种方案不适合我们。
方案二:淘宝 UED 的大前端方案
这是淘宝 UED 提出的「大前端」方案,之前没看过的同学可以看一下:
前后端分离的思考与实践(六)这种方案的思想是非常先进的,在前端 HTML/CSS/JS 和后端 Java 之间,架设了一层 NodeJS,把 View 层和 Controller 层都交由前端团队去开发,后端团队只负责 Modal 层。然而,这种方案对项目的改动将非常大,改造成本非常高,结合我们团队目前状况,这个方案也不适合我们。
方案三:构建 Mock Server
Mock Server 的概念非常简单,就是在开发环境构建一个模拟的服务器,然后构建假数据(Mock Data),再利用构建的假数据来进行开发。
它的好处非常多:
- 灵活性高:它小到可以只拦截一个 HTTP 请求,对某一个 API 进行调试;大到前端可以完全使用 Mock Server 进行开发,在本地完全不需要跑后端服务器。所以它可以以非常平滑柔和的方式融入到前端项目的开发当中。
- 构建简单:我们甚至只需要通过 Fiddler 或者 Charles 等抓包拦截软件,就可以完成一个 Mock Server 的构建。
- 能自动生成 API:由于数据和接口都是确定的,所以我们可以利用它来创建 API 文档,便于前后端开发。
- 能为自动化测试铺路:同样是由于数据和接口都是确定的,所以我们还可以利用它来做单元测试。
定案
综合几个方案,从改造成本(包括技术难度和时间)、改造平滑度、获得的回报方面来考虑,最后决定使用 方案三 ,也就是 构建 Mock Server 。
如何对我们的项目进行改造?
Created with Raphaël 2.1.2 请求拦截(实现 API 调试) 页面渲染(实现带有数据的页面调试) 结合模板引擎的页面渲染 构建整站的 Mock Data,生成完整的 API 文档 View 层分离,前端完全脱离后端开发,进入 Mock-based 式开发 开始构建自动化测试系统
接下来,我会根据我们 Mock Server 工程推动的进度,对每一阶段都会进行详细描述。通过这一步一步循序渐进的改造,我们最终可以实现低成本、高回报的前后端分离工程。