深度学习中的文字序列数据
二维文字序列
在文字数据中,样本与样本之间的联系是语义的联系,语义的联系即是词与词之间、字与字之间的联系,因此在文字序列中每个样本是一个单词或一个字(对英文来说大部分时候是一个单词,偶尔也可以是更小的语言单位,如字母或半词),故而在中文文字数据中,一张二维表往往是一个句子或一段话,而单个样本则表示单词或字。
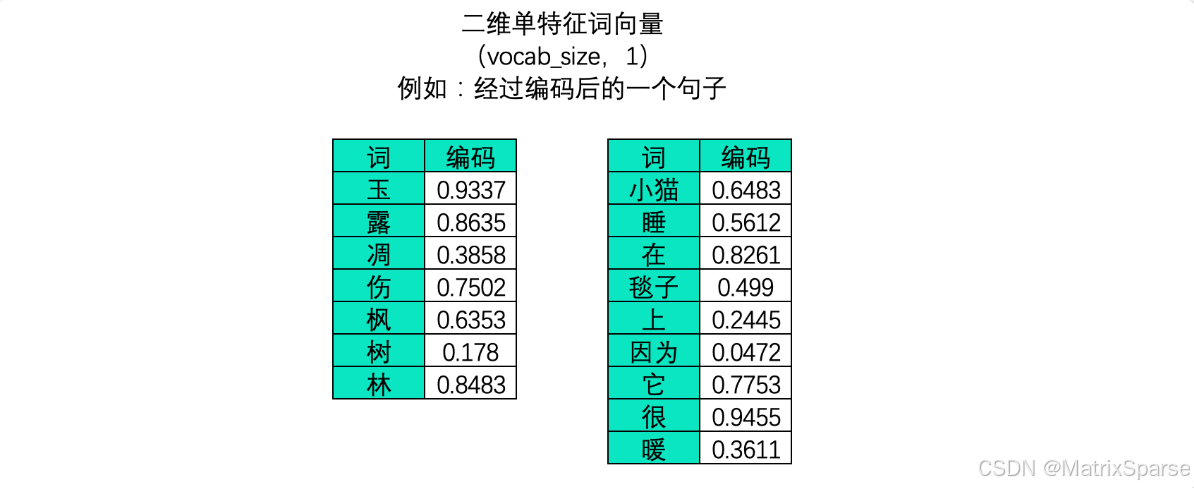
此时,不能够打乱顺序的维度是vocab_size,它代表了一个句子/一段话中的字词总数量。一个句子或一段话越长,vocab_size也就会越大,因此这一维度的作用与时间序列中的time_step一致,vocab_size在许多时候也被称之为是序列长度(sequence_length)。同样,vocab_size这一维度上的顺序就是算法需要学习的语义顺序。
算法是不能认知文字数据的,因此我们必须将文字数据转化为“数字”来进行表示,这个过程叫做“编码”。编码是一个复杂的过程,但是现在我们不必对其进行深究,我们只需要知道,我们可以像上面的图像中一样将一个单词编码成一个数字,也可以将单词编码成一个序列。大部分时候,我们需要学习的肯定不止一个句子,当每个句子被编码成矩阵后,就会构成高维的多特征词向量。由于在实际训练时,所有句子或段落长度都一致的可能性太小(即所有句子的vocab_size都一致的可能性太小),因此我们往往为短句子进行填充、或将长句子进行裁剪,让所有的特征词向量保持在同样的维度。
- 三维文字序列
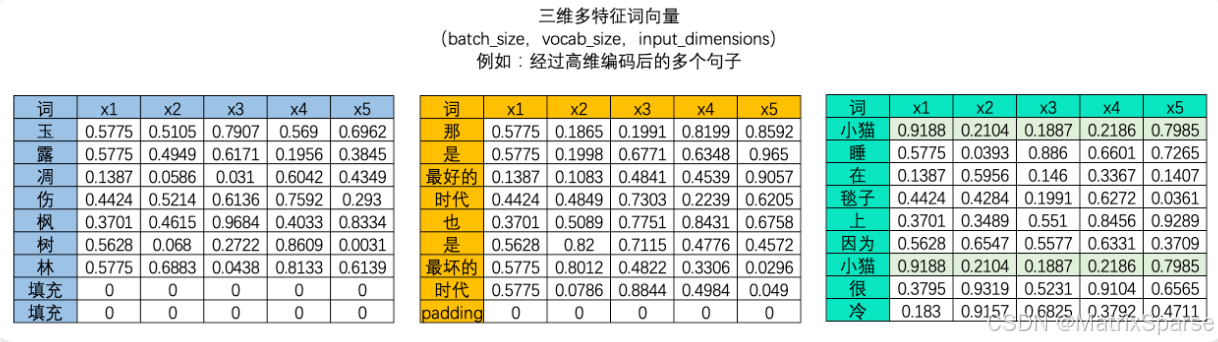
分词操作
原始文本数据大多是段落,但是输入到深度学习中的文字数据的样本却是词或字,因此文字数据大部分时候需要进行“分词”。分词是将连续的文本切分成一个个具有独立意义的词或词组的过程,良好的分词可以降低算法理解文本的难度,可以很好地提升模型的性能。例如,将诗句“玉露凋伤枫树林”分为[“玉露”,“调伤”,“枫树林”]三个词,可能会比将其分为[“玉”,“露”,“凋”,“伤”,“枫”,“树”,“林”]7个字更容易理解,要求每个字都自带完整的语义其实会有些困难。
由于不同的语言有不同的特色,因此每种语言所使用的分词方式也大不相同。例如,英文等拉丁语系的语言天然就有空格来分割不同的单词,只要按照空格进行分词就能够自然得到很好的结果,而中文日文韩文等语言却没有空格来进行辅助,有时分词的结果可能会造成巨大的误解。例如,经典的“吃烧烤不给你带”这一句子,分割成[“吃”,“烧烤”,“不给”,“你”,“带”]和[“吃”,“烧烤”,“不”,“给你”,“带”]就会令语义有所不同,因此中文还面临着“断句”的挑战。
现在对于不同语言的分词,我们都有丰富的手段可以操作:
中文分词:
基于词典的方法:最经典的方法,例如最大匹配法、最小匹配法等,它们基于预先定义的字典来执行分词。在使用何种方法之前需要先构造词典。
基于统计的方法:例如HMM(隐马尔科夫模型)和CRF(条件随机场)。
深度学习方法:例如基于Bi-LSTM的分词模型。
经典工具——
- jieba:是一个Python的第三方库。支持三种分词模式:精确模式、全模式和搜索引擎模式。速度相对较快,使用简单。可以自定义添加词典。
- HanLP:不仅仅是分词工具,还包括词性标注、命名实体识别等多种NLP任务。支持多种分词算法,如CRF、感知机等。同时支持繁体中文和简体中文。提供了丰富的预处理和后处理功能。
- THULAC(清华大学THU词法分析工具包):不仅支持分词,还提供词性标注功能。使用条件随机场(CRF)模型。
- FudanNLP(复旦大学NLP工具集):提供了分词、词性标注、命名实体识别等功能。使用结构化感知机模型。
- LTP(语言技术平台):由哈工大社会计算与信息检索研究中心开发。提供全套中文NLP处理工具,包括分词、词性标注、句法分析等。使用感知机模型。
- SNLP (Stanford NLP for Chinese) :斯坦福大学开发的NLP工具,支持多种语言,其中包括中文。提供分词、词性标注、命名实体识别等功能,基于都使用基于深度学习的方法。
选择哪种工具主要取决于特定任务的需求和使用场景。对于大部分应用,例如简单的文本预处理,jieba可能就足够了。但如果需要更深入的语言学特性或高准确性的处理,可能需要考虑如HanLP或LTP这样的更全面的工具。在NLP部分后续的代码实战环节,我们将展示使用各式分词工具的代码与结果。英文分词:
空白字符分词:由于英文单词之间通常由空格分隔,所以简单的空格分词在很多情况下都很有效。
基于规则的方法:如NLTK、spaCy等工具提供的分词方法。
子词分词:如BPE或SentencePiece,它们可以将英文单词进一步切分成常见的子词或字符级别的片段。
词、字与Token
Token(读音tow·kn)是自然语言处理世界中的重要概念,这个概念没有官方中文译名,但我们可以根据该词语在众多论文中的语境对其进行如下定义:Token是当前分词模式下的最小语义单元,根据分词方式的不同,它可能是一个单词(upstair)、一个半词(up,stair)或一个字母(u,p,s,t…),也可能是一个短语(攀登高峰)、一个词语(攀登、高峰)或一个字(攀,登,高,峰)。之前我们提到,分词是将连续的文本切分成一个个具有独立意义的词或词组的过程,其实本质上来说分词就是分割Token的过程,因此文字数据表单中的一行行样本也就是一个个token。
Token在自然语言处理世界中有什么意义呢?首先,它是语义的最小组成部分,同时也是大部分深度学习算法输入数据时的“单一样本”。Token的数量代表了样本的数量,也就代表了当前文本的长度和当前算法需要处理的数据量,直接对当前算法运行需要多少资源(算力、时间、电力)产生影响,也就会影响模型开发、模型训练、模型调用的成本。在NLP和大语言模型的世界中,OpenAI等模型开发厂商是以Token使用程度来进行计价和使用限制的,我们也以大模型训练和微调时所必须使用的token数量来衡量大模型的性能。随着大模型的发展,Token已成为NLP世界中广受认可的数据量/模型吞吐量计量单位——
OpenAI规定的GPT3.5在一次对话中允许的token总量

OpenAI规定的pay-as-you-go(充值型)大模型计费方法和使用限制

在OpenAI官网上,我们甚至能够直接找到计算当前文本Token的工具Tokenizer。同时,OpenAI还非常贴心地为我们准备了一篇Github文档专门用于讲解如何计算一篇文案的Token、如何选择最省token的方式来节省费用,感兴趣的大家可以去进行阅读。
如果你还想挖掘更多宝藏内容,请关注公众号“智界元枢”。