查了一些资料发现大部分的爬虫在liunx环境下运行,但本人想在windows下进行爬虫,好不容易把各种依赖装上了,但是如何在windows下pycharm中创建爬虫,以及调试和执行,进行了摸索。
参考了下面的两篇文章:
http://blog.csdn.net/ck4438707/article/details/52076220
http://blog.csdn.net/pleasecallmewhy/article/details/19642329
1.首先新建一个工程
并在工程里面建一个文件scrapyp.py,在文件中写入
from scrapy.cmdline import execute
execute() 在pycharm中点击右上角:edit configurations
则弹出如下框:
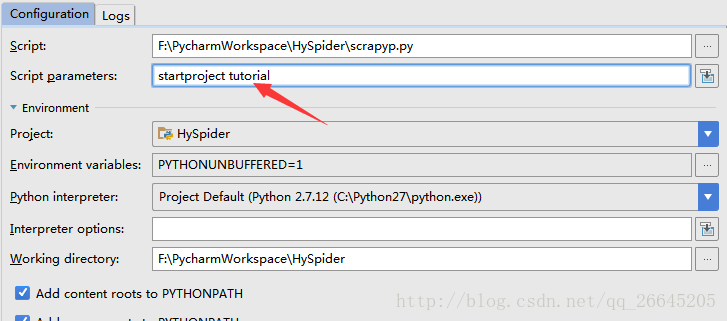
在红色箭头指示的位置,输入命名参数,创建一个爬虫,名称为tutorial,执行scrapyp.py文件。
在工程下面会出现如下结构:
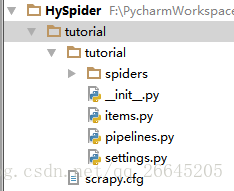
到此一个基本的爬虫框架出来了,后面需要再各个模块添加内容。
下面来简单介绍一下各个文件的作用:
scrapy.cfg:项目的配置文件
tutorial/:项目的Python模块,将会从这里引用代码
tutorial/items.py:项目的items文件
tutorial/pipelines.py:项目的pipelines文件
tutorial/settings.py:项目的设置文件
tutorial/spiders/:存储爬虫的目录
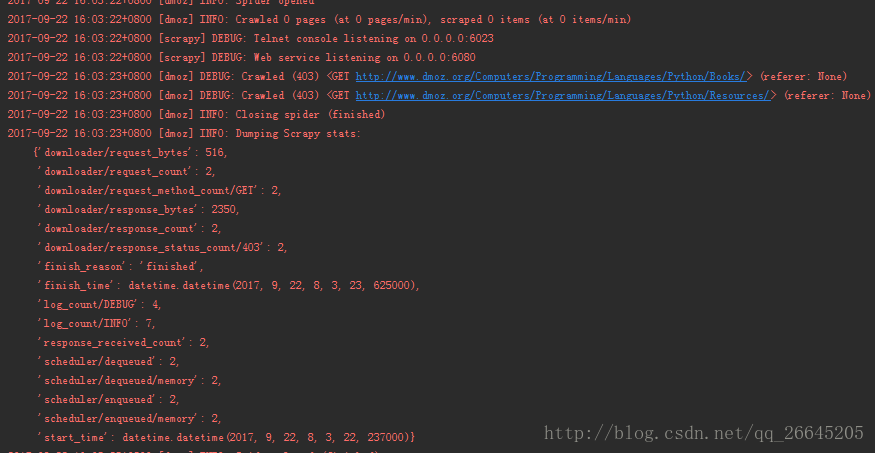
在此文件中放入如下代码,并执行可以看到爬取的内容:
from scrapy import cmdline
cmdline.execute("scrapy crawl dmoz".split())